Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BDA3 17章
Search
Takahiro Kawashima
May 29, 2018
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BDA3 17章
某輪読会で発表した際の資料.Gelmanら『Bayesian Data Analysis 3rd. Edition』17章
Takahiro Kawashima
May 29, 2018
More Decks by Takahiro Kawashima
See All by Takahiro Kawashima
論文紹介:HalluCitation Matters
wasyro
0
120
引力・斥力を制御可能なランダム部分集合の確率分布
wasyro
0
420
集合間Bregmanダイバージェンスと置換不変NNによるその学習
wasyro
0
360
論文紹介:Precise Expressions for Random Projections
wasyro
1
640
ガウス過程入門
wasyro
0
1.1k
論文紹介:Inter-domain Gaussian Processes
wasyro
0
210
論文紹介:Proximity Variational Inference (近接性変分推論)
wasyro
0
410
機械学習のための行列式点過程:概説
wasyro
0
2.2k
SOLVE-GP: ガウス過程の新しいスパース変分推論法
wasyro
1
1.6k
Featured
See All Featured
RailsConf 2023
tenderlove
30
1.5k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
How to Ace a Technical Interview
jacobian
281
24k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Git: the NoSQL Database
bkeepers
PRO
432
67k
Mind Mapping
helmedeiros
PRO
1
280
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Making the Leap to Tech Lead
cromwellryan
135
10k
A Tale of Four Properties
chriscoyier
163
24k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
320
Transcript
17 ষ: Models for robust inference ౡوେ May 30, 2018
ిؾ௨৴େֶ ঙݚڀࣨ B4
࣍ 1. Aspects of robustness 2. Overdispersed versions of standard
models 3. Posterior inference and computation 4. Robust inference for the eight schools 5. Robust regression using t-distributed errors 2
Aspects of robustness
Aspects of robustness ਖ਼نϩόετੑ͕͘ɼ֎ΕҰ͕ͭύϥϝʔλͷਪఆ ʹ༩͑ΔӨڹ͕େ͖͍ Eight Schools Λྫͱͯ͠ߟ͑ͯΈΔ 3
Aspects of robustness ෮श: Eight Schools • SAT-V ͱ͍͏ςετʹର͢ΔಛผิशͷޮՌΛղੳ •
8 ߍ͕ࢀՃ • 5 ষͰʮֶߍ͝ͱͷฏۉิशޮՌಉఔͩΖ͏ʯͱ͍͏ ղੳ݁Ռʹ 4
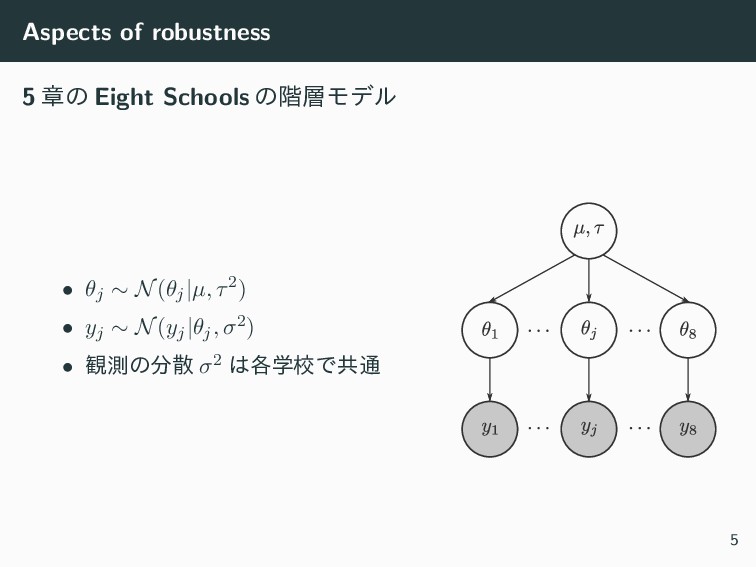
Aspects of robustness 5 ষͷ Eight Schools ͷ֊Ϟσϧ • θj
∼ N(θj|µ, τ2) • yj ∼ N(yj|θj, σ2) • ؍ଌͷࢄ σ2 ֶ֤ߍͰڞ௨ 5
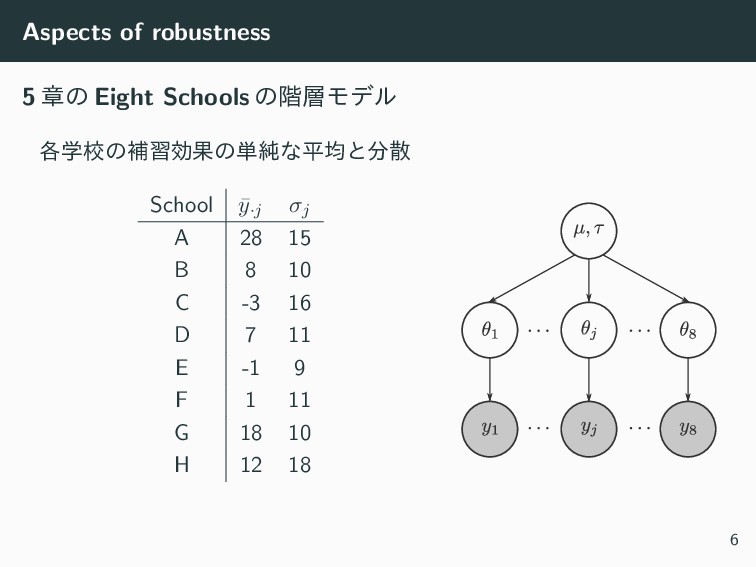
Aspects of robustness 5 ষͷ Eight Schools ͷ֊Ϟσϧ ֶ֤ߍͷิशޮՌͷ୯७ͳฏۉͱࢄ School
¯ y·j σj A 28 15 B 8 10 C -3 16 D 7 11 E -1 9 F 1 11 G 18 10 H 12 18 6
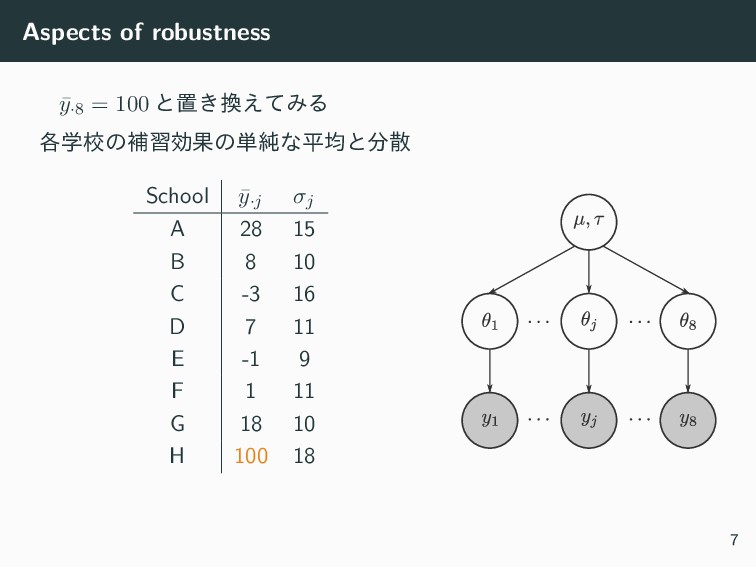
Aspects of robustness ¯ y·8 = 100 ͱஔ͖͑ͯΈΔ ֶ֤ߍͷิशޮՌͷ୯७ͳฏۉͱࢄ School
¯ y·j σj A 28 15 B 8 10 C -3 16 D 7 11 E -1 9 F 1 11 G 18 10 H 100 18 7
Aspects of robustness ¯ y·8 = 100 ͱஔ͖͑ͯΈΔ • τ
͕େ͖͍ʹͳΔ (θj ͷࢄ͕େ͖͘ͳΔ) • θj ͷਪఆ ˆ θj ͕΄΅؍ଌͷӨڹͷΈʹͳΔ (ࣜ 5.17) ˆ θj = 1 σ2 j ¯ y·j + 1 τ2 µ 1 σ2 j + 1 τ2 ֎Ε ¯ y·8 = 100 ͷਪఆྔͷӨڹখ͍ͨ͘͞͠ ˠͦ͢ͷ͍Λ༻͍Δ 8
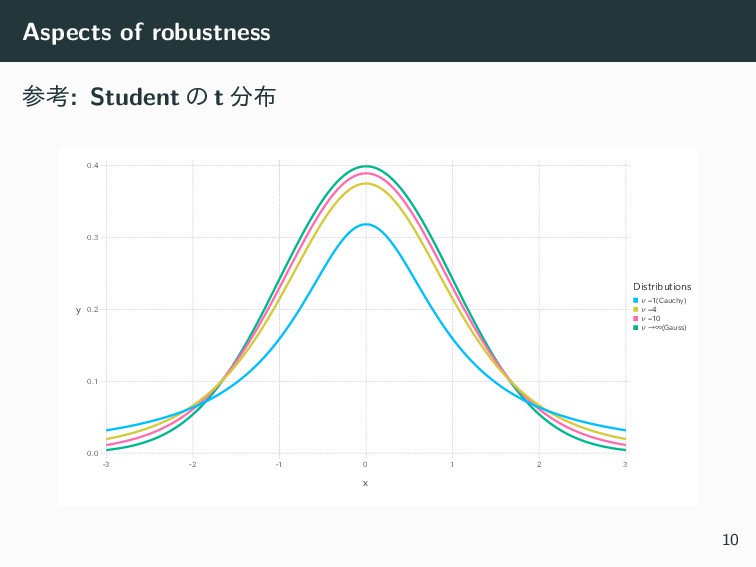
Aspects of robustness ͦ͢ͷ͍ͷݕ౼ 1. Student ͷ t (ࣗ༝
ν = 1 Ͱ Cauchy ɼν → ∞ Ͱਖ਼ ن) 2. ͕Γͷେ͖͍ͱͷࠞ߹Ϟσϧ t ͷࣗ༝ ν Λେ͖͍ͷ͔Βখ͍͞ͷʹม͑ͳ͕Β৭ʑ ࢼͯ͠ΈΔͷ͕Α͍ ˠ importance resampling(17.4 અ) 9
Aspects of robustness ࢀߟ: Student ͷ t x -3
-2 -1 0 1 2 3 ν=1(Cauchy) ν=4 ν=10 ν→∞(Gauss) Distributions 0.0 0.1 0.2 0.3 0.4 y 10
Overdispersed versions of standard models
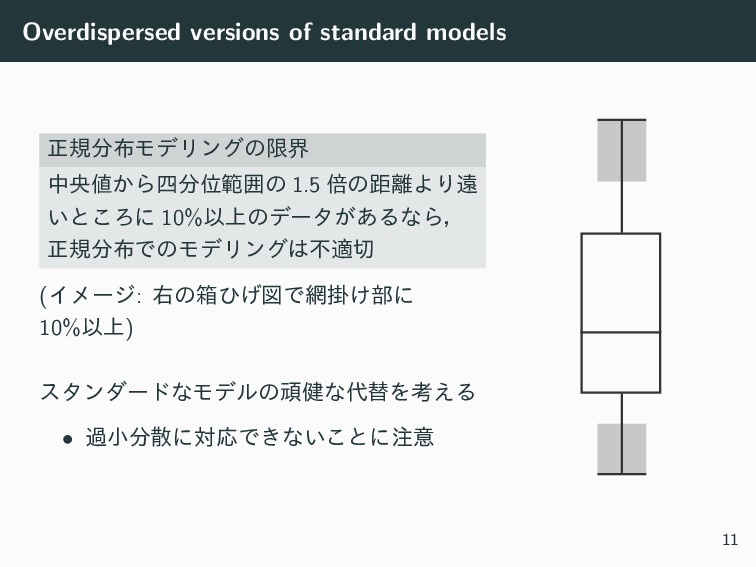
Overdispersed versions of standard models ਖ਼نϞσϦϯάͷݶք தԝ͔Β࢛Ґൣғͷ 1.5 ഒͷڑΑΓԕ ͍ͱ͜Ζʹ
10%Ҏ্ͷσʔλ͕͋ΔͳΒɼ ਖ਼نͰͷϞσϦϯάෆద (Πϝʔδ: ӈͷശͻ͛ਤͰֻ͚෦ʹ 10%Ҏ্) ελϯμʔυͳϞσϧͷؤ݈ͳସΛߟ͑Δ • աখࢄʹରԠͰ͖ͳ͍͜ͱʹҙ 11
Overdispersed versions of standard models ਖ਼نͷସͱͯ͠ͷ t • ͜Μͳͱ͖ʹ͏Α
1. ͨ·ʹҟৗͳσʔλ͕Ͱͯ͘Δ 2. ͨ·ʹۃͳΛڐ༰͍ͨ͠ύϥϝʔλͷࣄલ • ࣗ༝ ν = 1 Ͱ Cauchy ɼν → ∞ Ͱਖ਼ن • σʔλ͕ͨ͘͞Μ͋ΔͳΒ ν ະύϥϝʔλʹ • ν ͕খ͍͞ΛͱΒͳ͍Α͏ʹࣄલΛઃఆ͢ΔͷΦ εεϝ ˠ ν = 1, 2 ͷͱ͖ࢄ͕ଘࡏͤͣɼѻ͍ͮΒ͍ͨΊ 12
Overdispersed versions of standard models ਖ਼نͷସͱͯ͠ͷ t tν(yi|µ, σ2)
= ∫ ∞ 0 N(yi|µ, Vi)Inv-χ2(Vi|ν, σ2)dVi t 1. ݻఆͷฏۉ µ ͱ 2. ई͖ٯΧΠೋʹ͕ͨ͠͏ࢄ Vi Ͱද͞ΕΔਖ਼نͷࠞ߹ͱղऍͰ͖Δ 13
Overdispersed versions of standard models ϙΞιϯͷସͱͯ͠ͷෛͷೋ߲ ϙΞιϯ Poisson(yi|λ) = λyi
yi! exp(−λ) • mean(y) = λ, var(y) = λ • ฏۉͱࢄΛ͍ͨ͠ ˠෛͷೋ߲ 14
Overdispersed versions of standard models ϙΞιϯͷସͱͯ͠ͷෛͷೋ߲ ෛͷೋ߲ (p.578) NegBin(yi|α, β)
= ( yi + α − 1 α − 1 )( β β + 1 )α ( 1 β + 1 )yi κ := 1 α , λ := α β ͱ͓͘ͱ NegBin(yi|κ, λ) = λyi yi! Γ(1/κ + yi) Γ(1/κ)(1/κ + λ)yi (1 + κλ)−1/κ ͱมܗͰ͖Δ • mean(y) = λ, var(y) = λ(1 + κλ) ˠ͏Ε͍͠ 15
Overdispersed versions of standard models ϙΞιϯͷସͱͯ͠ͷෛͷೋ߲ ͪͳΈʹ NegBin(yi|r, p) =
Γ(r + yi) yi!Γ(r) (1 − p)rpyi ͱ͍͏දهΛ͢Δͱɼ NegBin(yi|a, 1 b + 1 ) = ∫ Poisson(yi|λ)Gamma(λ|a, b)dλ ͱͳΔ (ਢࢁຊ p.86, 87) 16
Overdispersed versions of standard models ೋ߲ͷସͱͯ͠ͷ Beta-Binomial ೋ߲ Binomial(yi|n,
p) = ( n yi ) pyi (1 − p)n−yi • mean(y) = np, var(y) = np(1 − p) • 1 − p ͷൣғ͕ [0, 1] ͷͨΊɼࢄ͕ฏۉΑΓେ͖͘ͳΒͳ͍ ͜ͱ͕Θ͔Δ ˠ Beta-Binomial 17
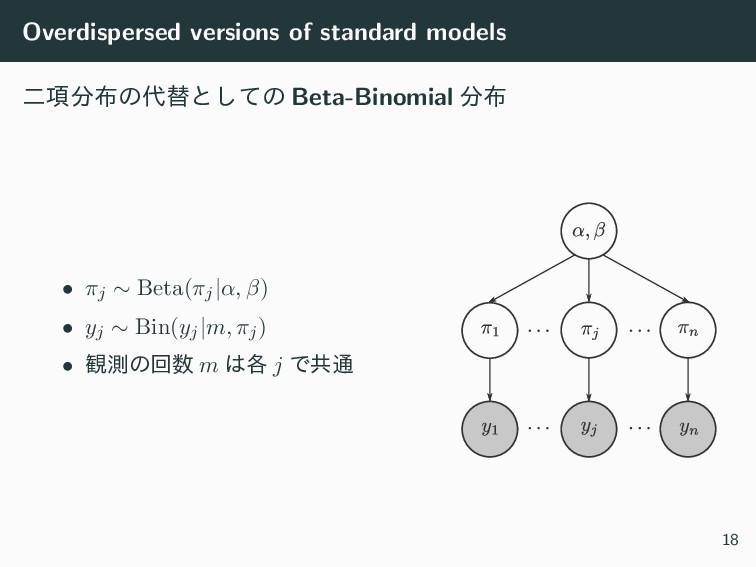
Overdispersed versions of standard models ೋ߲ͷସͱͯ͠ͷ Beta-Binomial • πj
∼ Beta(πj|α, β) • yj ∼ Bin(yj|m, πj) • ؍ଌͷճ m ֤ j Ͱڞ௨ 18
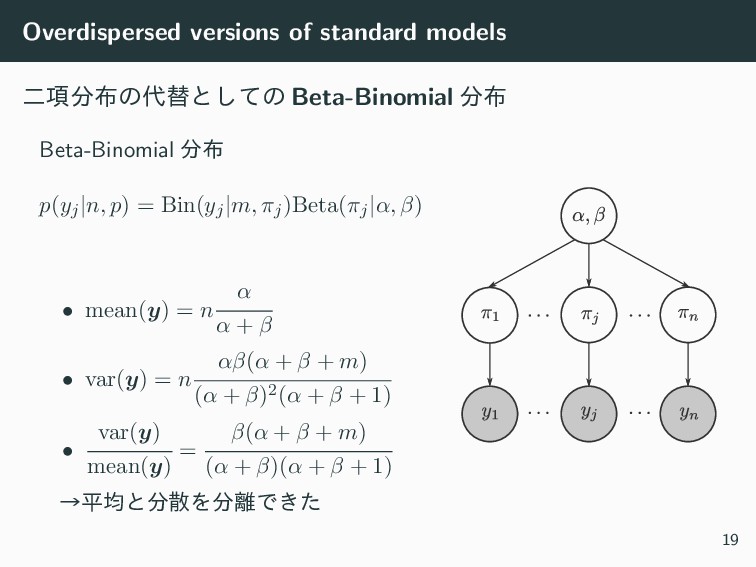
Overdispersed versions of standard models ೋ߲ͷସͱͯ͠ͷ Beta-Binomial Beta-Binomial
p(yj|n, p) = Bin(yj|m, πj)Beta(πj|α, β) • mean(y) = n α α + β • var(y) = n αβ(α + β + m) (α + β)2(α + β + 1) • var(y) mean(y) = β(α + β + m) (α + β)(α + β + 1) ˠฏۉͱࢄΛͰ͖ͨ 19
Overdispersed versions of standard models ೋ߲ͷସͱͯ͠ͷ Beta-Binomial • n
= 100, m = 30 • mean(y) = n α α + β • var(y) = n αβ(α + β + m) (α + β)2(α + β + 1) Ћ Ќ mean variance 0.1 0.1 50.0 629.2 1.0 1.0 50.0 266.7 10.0 10.0 50.0 59.5 100.0 100.0 50.0 28.6 1000.0 1000.0 50.0 25.4 20
Posterior inference and computation
Posterior inference and computation ຊઅͰѻ͏τϐοΫ 1. ࣄޙͷධՁ: ΪϒεαϯϓϦϯά 2. ηϯγςΟϏςΟͷղੳ:
importance weighting 3. ϩόετͳͷධՁ: importance resampling 21
Posterior inference and computation ه๏ͳͲ p0(θ|y): طʹσʔλ͔Βਪଌͨ͠ඇϩόετͳϞσϧͷࣄޙ ϕ: ϩόετੑʹؔΘΔϋΠύʔύϥϝʔλ (t
ͷࣗ༝ͳͲ) ҎԼ͔ΒͷαϯϓϦϯά͕త (ࣜ 17.2) p(θ|ϕ, y) = p(y|θ, ϕ)p(θ|ϕ) p(y|ϕ) ∝ p(y|θ, ϕ)p(θ|ϕ) ϕ ͕ൣғͱͯ͠༩͑ΒΕΔ߹ p(ϕ|y) ܭࢉ p(θ, ϕ|y) = p(θ|ϕ, y)p(ϕ|y) ∝ p(y|θ, ϕ)p(θ|ϕ)p(θ|ϕ) 22
Posterior inference and computation ΪϒεαϯϓϦϯά ࣄޙΛಘΔͷʹϚϧίϑ࿈γϛϡϨʔγϣϯ͕༗ޮ θ ͱજࡏύϥϝʔλͱͷ݁߹͔ΒͷαϯϓϦϯά • t
: Vi ɼෛͷೋ߲: λi ɼBeta-Binomial : πi 23
Posterior inference and computation ΪϒεαϯϓϦϯάͷྫ y = (y1, . .
. , yn) Λ yi ∼ tν(yi|µ, σ2) ͰϞσϦϯά tν(yi|µ, σ2) = ∫ ∞ 0 N(yi|µ, Vi)Inv-χ2(Vi|ν, σ2)dVi ࣄલ؆୯ͷͨΊ p(µ), p(logσ) Ұఆ p(µ, σ2, V |ν, y) ͷ݁߹ࣄޙ͔Β ν, σ2 ʹ͍ͭͯͷࣄޙΛ ߟ͑Δ 24
Posterior inference and computation ΪϒεαϯϓϦϯάͷྫ ҎԼͷαϯϓϦϯάΛ܁Γฦ͢ (12.1 અ) 1. Vi|µ,
σ2, ν, y ∼ Inv-χ2 ( Vi ν + 1, νσ2 + (yi − µ)2 ν + 1 ) 2. µ|σ2, V , ν, y ∼ N µ ∑ n i=1 1 Vi yi ∑ n i=1 1 Vi , 1 ∑ n i=1 1 Vi 3. p(σ2|µ, V , ν, y) ∝ Gamma ( σ2 nν 2 , ν 2 ∑ n i=1 1 Vi ) 25
Posterior inference and computation ΪϒεαϯϓϦϯάͷྫ • ν ͕ະͳΒ ν Λಈ͔͢εςοϓΛՃ֦͑ͯு
ˠΪϒεαϯϓϦϯάͰ͍͠ͷͰϝτϩϙϦε๏ͳͲ • ϚϧνϞʔμϧʹͳΔͷͰ simulated tempering(ϨϓϦΧަ MCMC) Λ͓͏ 26
Posterior inference and computation ࣄޙ༧ଌ͔ΒͷαϯϓϦϯά 1. ࣄޙ θ ∼ p(θ|ϕ,
y) ͔ΒαϯϓϦϯά 2. ༧ଌ ˜ y ∼ p(˜ y|θ, ϕ) ͔ΒαϯϓϦϯά 27
Posterior inference and computation importance weighting ʹΑΔϋΠύʔύϥϝʔλͷपลࣄޙ ͷܭࢉ • ϩόετͳΒ֎Ε͕͋ͬͯपลࣄޙ
p(ϕ|y) ͷӨ ڹখ͍ͣ͞ (ʁ) • पลࣄޙͷܭࢉʹΑͬͯײͷղੳ͕Մೳ p0(θ|y) ͔ΒͷαϯϓϦϯάΛطʹ࣮ߦࡁΈ • θs, s = 1, . . . , S ϩόετϞσϧ p(ϕ|y) ͷपลࣄޙΛۙࣅ 28
Posterior inference and computation importance weighting (13.11) ࣜΑΓ p(ϕ|y) ∝
p(ϕ)p(y|ϕ) = p(ϕ) ∫ p(y, θ|ϕ)dθ = p(ϕ) ∫ p(y|θ, ϕ)p(θ|ϕ)dθ = p(ϕ) ∫ p(y|θ, ϕ)p(θ|ϕ) p0(θ)p0(y|θ) p0(θ)p0(y|θ)dθ ∝ p(ϕ) ∫ p(y|θ, ϕ)p(θ|ϕ) p0(θ)p0(y|θ) p0(θ|y)dθ ≈ p(ϕ) [ 1 S S ∑ s=1 p(y|θs, ϕ)p(θs|ϕ) p0(θs)p0(y|θs) ] (17.3) 29
Posterior inference and computation importance weighting (17.3) ࣜ p(ϕ) [
1 S S ∑ s=1 p(y|θs, ϕ)p(θs|ϕ) p0(θs)p0(y|θs) ] ٻ·Δ ˠϩόετϞσϧͷύϥϝʔλ ϕ ͷࣄޙ͕ɼͱͷඇϩόε τͳϞσϧ͔ΒͷαϯϓϦϯά݁ՌΛ༻͍ͯۙࣅతʹಘΒΕΔ 30
Posterior inference and computation importance resampling ͰϩόετϞσϧͷۙࣅࣄޙΛಘΔ p0(θ|y) ͔ΒͷαϯϓϦϯά݁ՌΛطʹܭࢉࡁΈ •
θs, s = 1, . . . , S • ͨ͘͞ΜαϯϓϦϯά͓ͯ͘͠ɽS = 5000 ͱ͔ θ ͔Β importance ratio p(θs|ϕ, y) p0(θs|y) = p(θs|ϕ)p(y|θs, ϕ) p0(θs)p0(y|θs) ʹൺྫ͢Δ֬Ͱখ͍͞αϒαϯϓϧ (k = 500 ͱ͔) Λੜ͢Δ 31
Posterior inference and computation importance resampling(10.4 અ) importance ratio ͕ඇৗʹେ͖͍αϯϓϧ͕গଘࡏ͢Δঢ়گ
ˠ෮ݩநग़Ͱۙࣅࣄޙͷදݱྗ͕ஶ͘͠Լ͢Δ͓ͦΕ ˠ෮ݩநग़ͱඇ෮ݩநग़ͷதؒతͳखଓ͖ΛͱΔ 32
Posterior inference and computation importance resampling(10.4 અ) 1. importance ratio
ʹൺྫ͢Δ֬Ͱ θs ͔Βͻͱͭநग़͠ɼα ϒαϯϓϧʹՃ͑Δ 2. ಉ༷ʹαϒαϯϓϧʹՃ͑Δɽ͜͜Ͱطʹநग़ͨ͠αϯϓ ϧબ͠ͳ͍ 3. 1., 2. Λαϒαϯϓϧͷݸ͕ k ݸʹͳΔ·Ͱ܁Γฦ͢ ͱͷαϯϓϧ͕ແݶେͰαϒαϯϓϧ͕ेখ͚͞Εཧ తͳਖ਼ੑอূ͞Εͦ͏͕ͩʜʜ 33
Robust inference for the eight schools
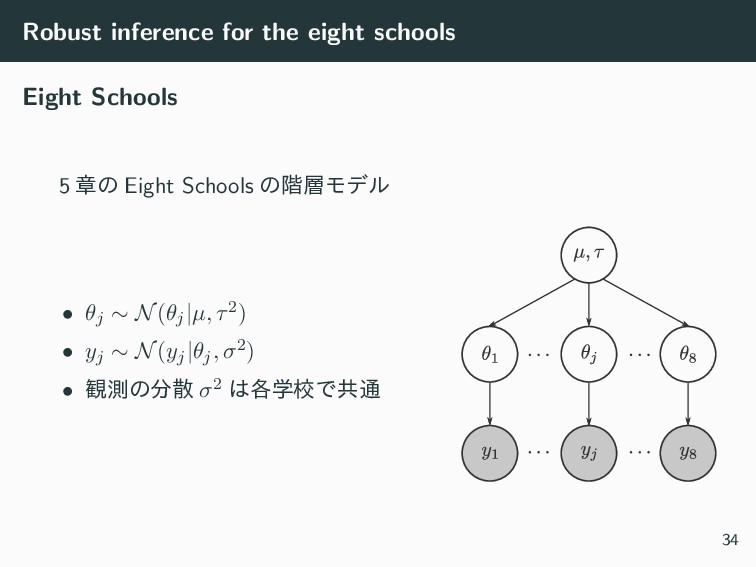
Robust inference for the eight schools Eight Schools 5 ষͷ
Eight Schools ͷ֊Ϟσϧ • θj ∼ N(θj|µ, τ2) • yj ∼ N(yj|θj, σ2) • ؍ଌͷࢄ σ2 ֶ֤ߍͰڞ௨ 34
Robust inference for the eight schools Eight Schools θj ͷࣄલʹ
Student ͷ t Λ༻͍Δ • θj ∼ tν(θj|µ, τ2) • yj ∼ N(yj|θj, σ2) ࣄޙ p(θj, µ, τ|ν, yj) ∝ p(yj|θj, µ, τ, ν)p(θj, µ, τ|ν). 5 ষͷϞσϧ p(θj, µ, τ|ν, yj) = p(θj, µ, τ|ν → ∞, yj). 35
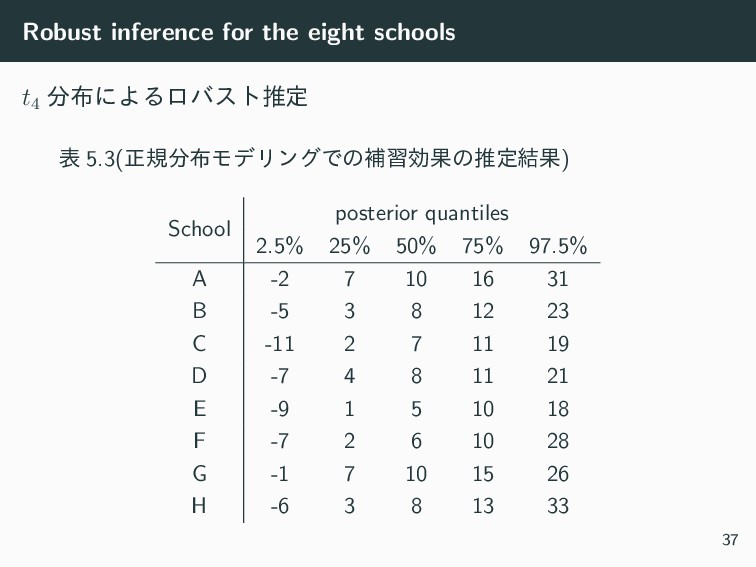
Robust inference for the eight schools t4 ʹΑΔϩόετਪఆ • ද
5.2 • ୯७ͳֶ֤ߍ͝ͱͷฏۉͱࢄ • ¯ y·1 ͕֎Ε School ¯ y·j σj A 28 15 B 8 10 C -3 16 D 7 11 E -1 9 F 1 11 G 18 10 H 12 18 36
Robust inference for the eight schools t4 ʹΑΔϩόετਪఆ ද 5.3(ਖ਼نϞσϦϯάͰͷิशޮՌͷਪఆ݁Ռ)
School posterior quantiles 2.5% 25% 50% 75% 97.5% A -2 7 10 16 31 B -5 3 8 12 23 C -11 2 7 11 19 D -7 4 8 11 21 E -9 1 5 10 18 F -7 2 6 10 28 G -1 7 10 15 26 H -6 3 8 13 33 37
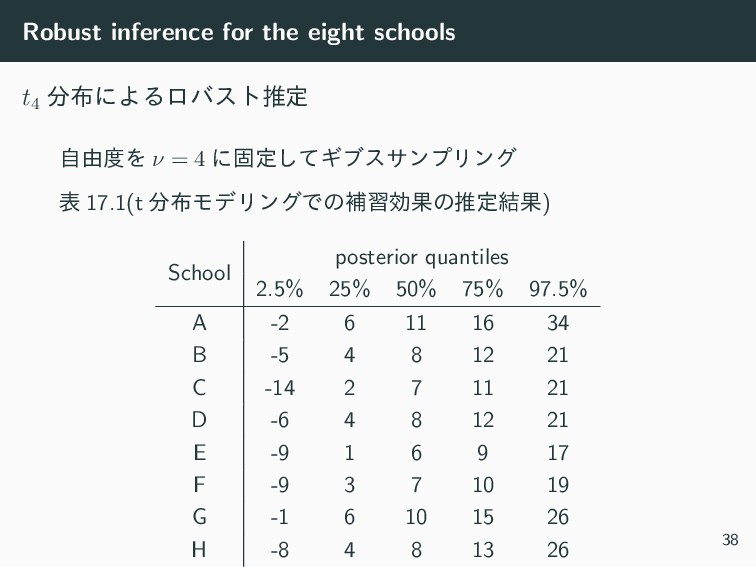
Robust inference for the eight schools t4 ʹΑΔϩόετਪఆ ࣗ༝Λ ν
= 4 ʹݻఆͯ͠ΪϒεαϯϓϦϯά ද 17.1(t ϞσϦϯάͰͷิशޮՌͷਪఆ݁Ռ) School posterior quantiles 2.5% 25% 50% 75% 97.5% A -2 6 11 16 34 B -5 4 8 12 21 C -14 2 7 11 21 D -6 4 8 12 21 E -9 1 6 9 17 F -9 3 7 10 19 G -1 6 10 15 26 H -8 4 8 13 26 38
Robust inference for the eight schools t4 ʹΑΔϩόετਪఆ ࣗ༝Λ ν
= 4 ʹݻఆͯ͠ΪϒεαϯϓϦϯά ˠ A ͳͲͷ shrinkage ͕গ͚ͩ͠·͠ʹͳ͍ͬͯΔ (͍͋͠) School posterior quantiles 2.5% 25% 50% 75% 97.5% A(ਖ਼نϞσϧ) -2 7 10 16 31 A(ϩόετϞσϧ) -2 6 11 16 34 39
Robust inference for the eight schools importance resampling ͷܭࢉ p0(θ,
µ, τ|y) ͔Β S = 5000 ճαϯϓϦϯά ν = 4 ͱ͠ɼ֤ θ ͷ importance ratio p(θ, µ, τ|y) p0(θ, µ, τ|y) = p(µ, τ|ν)p(θ|µ, τ, ν)p(y|θ, µ, τ, ν) p(y) p0(µ, τ)p0(θ|µ, τ)p0(y|θ, µ, τ) p0(y) ∝ p(θ|µ, τ, ν) p0(θ|µ, τ) = 8 ∏ j=1 tν(θj|µ, τ) N(θj|µ, τ) (17.5) ʹج͍ͮͯ k = 500 ͷαϒαϯϓϧΛੜ 40
Robust inference for the eight schools importance resampling ͷܭࢉ •
ࠓճͷϩόετੑͷධՁͰेͳۙࣅ • ߴਫ਼ͳਪ͕ඞཁͳ߹ͩͱ͖ͼ͍͠ ˠର importance ratio ͷͷ͕͓͔ͦ͢͠ͳ͜ͱʹͳͬͨͦ͏ t4 ͱਖ਼نͱͷͦ͢ͷߴ͞ͷࠩͷӨڹʁ 41
Robust inference for the eight schools ν ͷมԽʹ͏Ϟσϧͷײͷղੳ (ਤ 17.1)
• ν = 1, 2, 3(, 4), 5, 10, 30(, ∞) Ͱಉ༷ͷ MCMC γϛϡϨʔ γϣϯΛճͨ݁͠Ռ • ν ͷมԽʹΑΔ໌Β͔ͳޮՌͳͦ͞͏ • ν → ∞ ΑΓ ν = 30 ͷ΄͏͕ϩόετੑ͕ͦ͏ͳͷ ͳͥʁ • ν = 30 Ͱฏۉඪ४ภࠩॖখ͍ͯ͠Δͷͳͥʁ 42
Robust inference for the eight schools ν Λະύϥϝʔλͱͯ͠ѻ͏ ਤ 17.1
ΛݟΔݶΓɼਪఆͷ ν ͷґଘੑͦ͏ ˠपลࣄޙʹΑΔղੳ (importance weighting) ෆཁ 1 ν ∈ (0, 1] ʹ͍ͭͯҰఆͷࣄલΛઃఆ ͖݅ࣄલ p(µ, τ|ν) ∝ 1 ͕ improper ͳͷͰ p(µ, τ|ν) ∝ g(ν) ͱࣄલͷ ν ґଘੑΛදه ν ≤ 2 Ͱෆ߹ͳͷͰ µ, τ ΛͦΕͧΕதԝͱ࢛Ґ۠ؒͱͯ͠ ѻ͍ɼg(ν) ∝ 1 ͱ͢Δ 43
Robust inference for the eight schools ν Λະύϥϝʔλͱͯ͠ѻ͏ • ࣄޙͷ
ν ͷӨڹେ͖͘ͳ͍ (ਤ 17.1ɼਤ 17.2) • ν ͷґଘੑ͕ͬͱେ͖͚Εɼ(µ, τ, ν) ʹ͍ͭͯͷແ ใࣄલΛݕ౼͢Δ 44
Robust inference for the eight schools ߟ • தԝɼ50%͓Αͼ 95%۠ؒͰਖ਼نϞσϧͰ
insensitive ͩͬͨ • ͔͠͠ 99.9%۠ؒʹͳΔͱͷͦ͢ʹେ͖͘ґଘ͢Δͷ Ͱɼν ͷӨڹΛड͚͍͔͢ ˠࠓճͷྫͰ͋·Γؔ৺ͳ͍ 45
Robust regression using t-distributed errors
Robust regression using t-distributed errors ෮ॏΈ͖ઢܗճؼͱ EM ΞϧΰϦζϜ ௨ৗͷઢܗճؼϞσϧͰ֎ΕͷӨڹ͕େ͖͍ ˠޡ߲͕ࠩࣗ༝ͷখ͍͞
t ʹ͕ͨ͠͏ͱԾఆ Ԡม yi ͕આ໌ม Xi ʹΑͬͯ p(yi|Xi, β, σ2) = tν(yi|Xiβ, σ2) ͱ༩͑ΒΕΔ ͜Ε·Ͱͱಉ༷ɼtν Λਖ਼نͱई͖ٯΧΠೋͰߟ ͑Δ yi ∼ N(yi|Xiβ, Vi) Vi ∼ Inv-χ2(Vi|ν, σ2) 46
Robust regression using t-distributed errors ෮ॏΈ͖ઢܗճؼͱ EM ΞϧΰϦζϜ • p(β,
σ|ν, y) ͷࣄޙ࠷සΛΈ͚ͭΔ • p(β, logσ|ν, y) ∝ 1 ͷແใࣄલΛԾఆ ˠࣄޙ࠷සχϡʔτϯ๏ͳͲͰٻ·Δ • ผͷํ๏ͱͯ͠ɼVi Λʮܽଌʯͱࢥ͏ͱ EM ΞϧΰϦζϜͷ ΈͰѻ͑Δ 47
Robust regression using t-distributed errors ෮ॏΈ͖ઢܗճؼͱ EM ΞϧΰϦζϜ E εςοϓ
ਖ਼نϞσϧͷे౷ܭྔͷظΛٻΊΔ ࠓճ ∑ n i=1 1 Vi ʹ͍ͭͯߟ͑Δ Vi|yi,βold,σold,ν ∼ Inv-χ2 Vi ν+1, ν(σold)2 + (yi − Xiβold)2 ν + 1 (17.6) E ( 1 Vi |yi,βold,σold,ν ) = ν + 1 ν(σold)2 + (yi − Xiβold)2 48
Robust regression using t-distributed errors ิ: (17.6) ࣜͷ࣍ͷࣜͷಋग़ E (
1 Vi yi, βold, σold, ν ) มมʹΑͬͯٻΊΒΕΔ: x ∼ Inv-χ2(x|ν, s2) ͷͱ͖ɼy = 1 x ͷ͕ͨ͠͏֬ y ∼ Gamma ( y ν 2 , νs2 2 ) Ͱ͋Γɼ͜ΕΛ༻͍Δͱ 1 Vi ͷظ͕ٻ·Δ 49
Robust regression using t-distributed errors ෮ॏΈ͖ઢܗճؼͱ EM ΞϧΰϦζϜ M εςοϓ
W ର͕֯ Wi,i = 1 Vi ͷର֯ॏΈߦྻ ˆ βnew = (XT WX)−1XT Wy (ˆ σnew)2 = 1 n (y − X ˆ βnew)T W(y − X ˆ βnew) 50
Robust regression using t-distributed errors ෮ॏΈ͖ઢܗճؼͱ EM ΞϧΰϦζϜ ͜ͷ EM
ͷ෮෮ॏΈ͖࠷খೋ๏ͱՁ 1. ύϥϝʔλਪఆྔͷॳظ͕༩͑ΒΕ 2. ͦΕͧΕͷઆ໌มɾԠมʹ͍ͭͯɼ͕ࠩେ͖͚Ε ॏΈΛখ͘͢͞Δ ν Λະͱ͢ΔͳΒ ECME ΞϧΰϦζϜΛ͏ ˠࣗ༝Λߋ৽͢ΔεςοϓΛՃ 51
Robust regression using t-distributed errors ΪϒεαϯϓϥʔͱϝτϩϙϦε๏ ࣄޙ͔ΒͷαϯϓϦϯάΪϒεαϯϓϥʔϝτϩϙϦε ๏Ͱ࣮ݱՄೳ ύϥϝʔλಉ࣌ p(β,
σ2, V1, . . . , Vn|ν, y) ͔ΒͷαϯϓϦϯά 1. p(β, σ2|V1, . . . , Vnν, y) 2. p(V1, . . . , Vn|β, σ2ν, y) Vi|β, σ, ν, y ∼ Inv-χ2(Vi|ν, σ2) 3. ν ͕ະͳΒϝτϩϙϦε๏Ͱ ν Λಈ͔͢ ν ͕খ͍͞ͱ͖࠷ස͕ϚϧνϞʔμϧʹͳΓ͕ͪͰͭΒ͍ ˠॳظΛ͍Ζ͍Ζม͑ͯγϛϡϨʔγϣϯ͢Δͷ͕େࣄ 52
References I [1] Andrew Gelman, John B. Carlin, Hal S.
Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. Bayesian Data Analysis Third Edition. CRC Press, 2014. [2] ਢࢁರࢤ, ϕΠζਪʹΑΔػցֶशೖ. ߨஊࣾ, 2017.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References I [1] Andrew Gelman, John B. Carlin, Hal S.](https://files.speakerdeck.com/presentations/fd120aece6fb469ab8134383b2a2069d/slide_57.jpg){kind=link}