Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ガウス過程入門
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Takahiro Kawashima
November 16, 2022
Science
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ガウス過程入門
株式会社LabBase主催 LabTech Talk vol.59 にて使用した資料です.
Takahiro Kawashima
November 16, 2022
More Decks by Takahiro Kawashima
See All by Takahiro Kawashima
論文紹介:HalluCitation Matters
wasyro
0
130
引力・斥力を制御可能なランダム部分集合の確率分布
wasyro
0
420
集合間Bregmanダイバージェンスと置換不変NNによるその学習
wasyro
0
370
論文紹介:Precise Expressions for Random Projections
wasyro
1
640
論文紹介:Inter-domain Gaussian Processes
wasyro
0
210
論文紹介:Proximity Variational Inference (近接性変分推論)
wasyro
0
410
機械学習のための行列式点過程:概説
wasyro
0
2.2k
SOLVE-GP: ガウス過程の新しいスパース変分推論法
wasyro
1
1.6k
論文紹介:Stein Variational Gradient Descent
wasyro
0
2.1k
Other Decks in Science
See All in Science
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
280
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
Snowflake HCLS Meet Upヘルスケアユーザー会紹介
ktatsuya
0
110
Inside the Mind of an LLM
baggiponte
0
210
Amusing Abliteration
ianozsvald
1
240
機械学習 - 決定木からはじめる機械学習
trycycle
PRO
0
1.6k
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
560
AI bij literatuuronderzoek in de wetenschap
voginip
0
220
次代のデータサイエンティストへ~スキルチェックリスト、タスクリスト更新~
datascientistsociety
PRO
3
46k
AlgorithAlgorihms for Decision Making
mickey_kubo
0
100
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
610
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
400
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Navigating Weather and Climate Data
rabernat
0
410
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
530
Building the Perfect Custom Keyboard
takai
2
820
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Transcript
ガウス過程入門 川島 貴大 1, 2 LabTech Talk, November 16, 2022
1 総合研究大学院大学 統計科学専攻 2 国立精神・神経医療研究センター
目次 1. イントロ:機械学習における非線形性 2. ベイズ推論概論 3. ベイズ線形回帰からガウス過程回帰へ 4. ガウス過程の発展 5.
むすび 2
イントロ:機械学習における非線形性
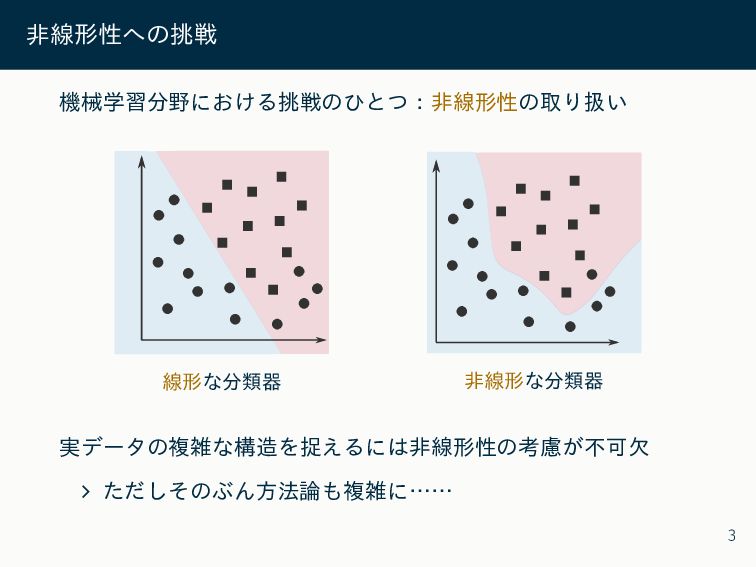
非線形性への挑戦 機械学習分野における挑戦のひとつ:非線形性の取り扱い 線形な分類器 非線形な分類器 実データの複雑な構造を捉えるには非線形性の考慮が不可欠 ∠ ただしそのぶん方法論も複雑に…… 3
さまざまな非線形モデル • 深層学習 • 非常に高い表現力 • 広範なタスクで高性能な万能性 •
大量のデータと計算リソースが必要 • 決定木・アンサンブル学習 • コンペなど多くの実問題で深層学習を超える精度 • 分類以外の問題への拡張性の低さ • ガウス過程・カーネル法 • 少数データでの安定性 • 回帰・分類を含め,多くのタスクに対する拡張性の高さ • 大規模なデータ・タスクにはしばしば不向き 4
ベイズ推論概論
ベイズの定理 ベイズの定理 確率変数 𝑋, 𝑌 について,次のベイズの定理が成り立つ: 𝑝(𝑋|𝑌 ) = 𝑝(𝑌
|𝑋)𝑝(𝑋) 𝑝(𝑌 ) . 𝑝(𝑋|𝑌 ) は条件付き分布で, 「𝑌 の値が得られたもとでの 𝑋 の 分布」を表す. ベイズ推論:ベイズの定理を応用した機械学習の枠組み ∠ ガウス過程もベイズ推論の一種 5
ベイズ推論 手元のデータを用いて,それを背後で支配する未知のパラメータ を求めるのが目標. D をデータ集合,𝜽 を未知パラメータとすると,ベイズ推論では 𝑝(𝜽|D) = 𝑝(D|𝜽)𝑝(𝜽) 𝑝(D)
∝ 𝑝(D|𝜽)𝑝(𝜽) を求める.各項はそれぞれ次のように呼ばれる: • 𝑝(𝜽):事前分布 • 𝑝(D|𝜽):尤度 • 𝑝(𝜽|D):事後分布 • 𝑝(D):分配関数(正規化定数) 6
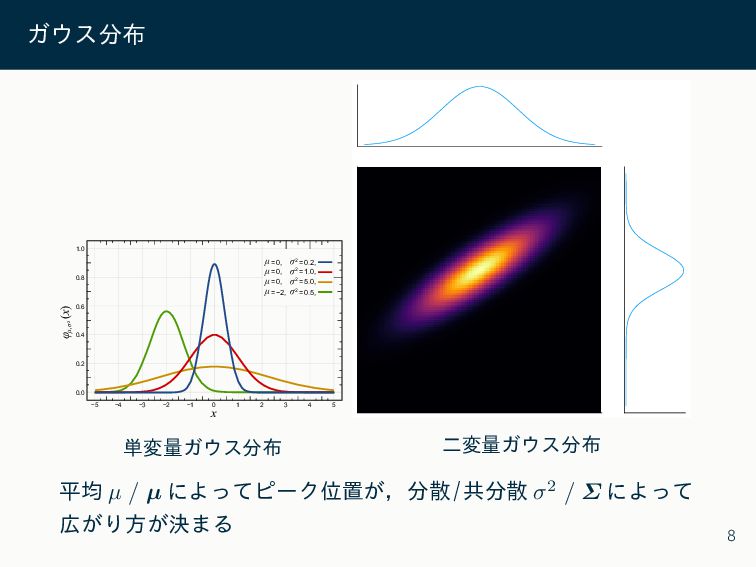
ガウス分布 ベイズ推論ではデータの特性に合わせてさまざまな確率分布が 用いられるが,今回の主役はガウス分布 (単変量)ガウス分布 N(𝑥|𝜇, 𝜎2) = 1 √ 2𝜋𝜎2
exp (− (𝑥 − 𝜇)2 2𝜎2 ) 多変量ガウス分布 N(𝒙|𝝁, 𝜮) = (2𝜋)− 𝐷 2 |𝜮|− 1 2 exp (− 1 2 (𝒙 − 𝝁)⊤𝜮−1(𝒙 − 𝝁)) 7
ガウス分布 - 3 - 2 - 1 φ μ,σ2 (
0.8 0.6 0.4 0.2 0.0 −5 −3 1 3 5 x 1.0 −1 0 2 4 −2 −4 x) 0, μ= 0, μ= 0, μ= −2, μ= 2 0.2, σ = 2 1.0, σ = 2 5.0, σ = 2 0.5, σ = 単変量ガウス分布 二変量ガウス分布 平均 𝜇 / 𝝁 によってピーク位置が,分散/共分散 𝜎2 / 𝜮 によって 広がり方が決まる 8
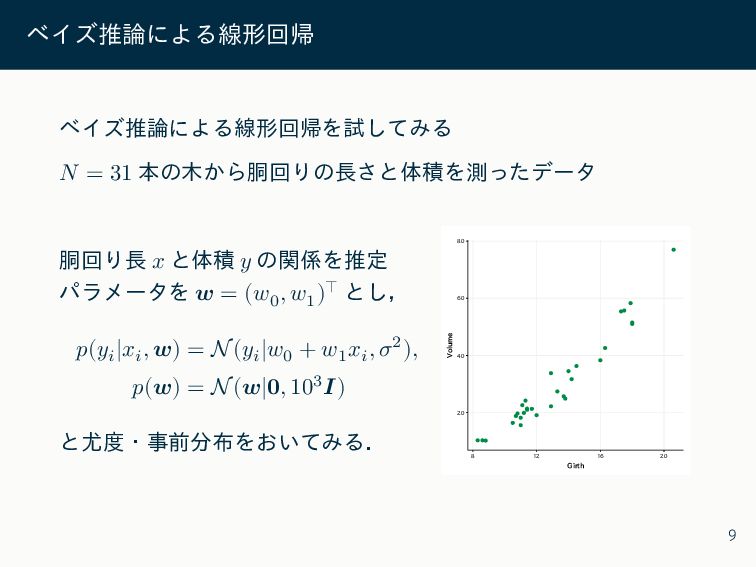
ベイズ推論による線形回帰 ベイズ推論による線形回帰を試してみる 𝑁 = 31 本の木から胴回りの長さと体積を測ったデータ 胴回り長 𝑥 と体積 𝑦
の関係を推定 パラメータを 𝒘 = (𝑤0 , 𝑤1 )⊤ とし, 𝑝(𝑦𝑖 |𝑥𝑖 , 𝒘) = N(𝑦𝑖 |𝑤0 + 𝑤1 𝑥𝑖 , 𝜎2), 𝑝(𝒘) = N(𝒘|𝟎, 103𝑰) と尤度・事前分布をおいてみる. 20 40 60 80 8 12 16 20 Girth Volume 9
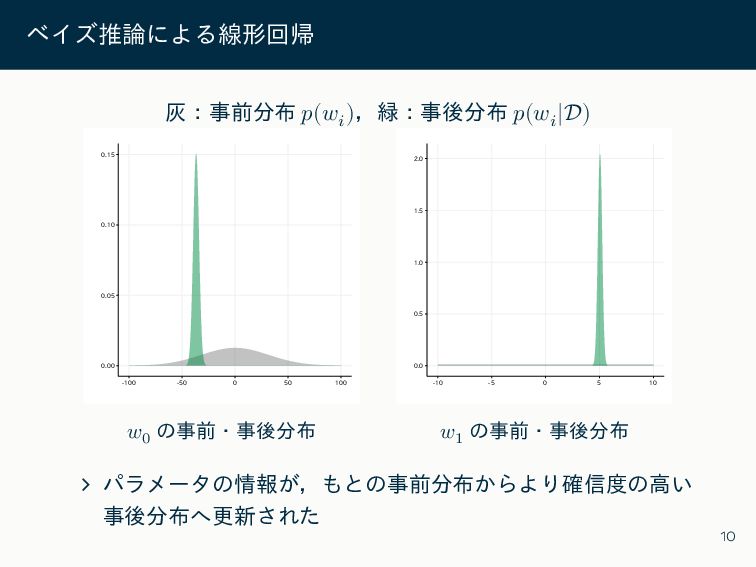
ベイズ推論による線形回帰 灰:事前分布 𝑝(𝑤𝑖 ),緑:事後分布 𝑝(𝑤𝑖 |D) 0.00 0.05 0.10 0.15
-100 -50 0 50 100 𝑤0 の事前・事後分布 0.0 0.5 1.0 1.5 2.0 -10 -5 0 5 10 𝑤1 の事前・事後分布 ∠ パラメータの情報が,もとの事前分布からより確信度の高い 事後分布へ更新された 10
ベイズ線形回帰からガウス過程回帰へ
基底関数によるベイズ線形回帰モデル 先ほどの例では尤度の平均を 𝑤0 + 𝑤1 𝑥 と与えたが,これを 𝒘⊤𝝓(𝑥) = 𝐿
∑ 𝑙=0 𝑤𝑙 𝜙𝑙 (𝑥) = 𝑤0 𝜙0 (𝑥) + 𝑤1 𝜙1 (𝑥) + ⋯ + 𝑤𝐿 𝜙𝐿 (𝑥) と一般化してみる1. ∠ たとえば 𝜙𝑙 (𝑥) = 𝑥𝑙 とおくと,𝐿 次の多項式回帰に すなわち { 𝑝(𝑦𝑖 |𝑥𝑖 , 𝒘) = N(𝑦𝑖 |𝒘⊤𝝓(𝑥𝑖 ), 𝜎2) (尤度) , 𝑝(𝒘) = N(𝒘|𝟎, 𝑠2𝑰) (事前分布) なる回帰モデルを設定する. 1ガウス過程の世界では 𝝓 は特徴写像と呼ばれる. 11
ベイズ線形回帰モデルの周辺化 { 𝑝(𝑦𝑖 |𝑥𝑖 , 𝒘) = N(𝑦𝑖 |𝒘⊤𝝓(𝑥𝑖 ),
𝜎2), 𝑝(𝒘) = N(𝒘|𝟎, 𝑠2𝑰) ここでパラメータ 𝒘 を同時分布 𝑝(𝒚, 𝒘|𝒙) = 𝑝(𝒚|𝒙, 𝒘)𝑝(𝒘) から 積分消去(周辺化)してしまうと,𝒚 の条件付き分布 𝑝(𝒚|𝒙) = N(𝒚|𝟎, 𝑠2𝜱𝜱⊤ + 𝜎2𝑰) が得られる.ここで 𝑁 × (𝐿 + 1) 行列 𝜱 の (𝑖, 𝑙) 成分は 𝜙𝑙 (𝑥𝑖 ). また 𝜱𝜱⊤ は 𝑁 × 𝑁 行列で,(𝑖, 𝑗) 成分は 𝝓(𝑥𝑖 )⊤𝝓(𝑥𝑗 ). ∠ 𝝓(𝑥𝑖 ) と 𝝓(𝑥𝑗 ) の内積 12
ベイズ線形回帰からガウス過程回帰へ 𝑝(𝒚|𝒙) = N(𝒚|𝟎, 𝑠2𝜱𝜱⊤ + 𝜎2𝑰) ガウス過程回帰では,𝝓(𝑥) の具体的な形式は直接与えずに,その 内積だけを指定する.
つまりカーネル関数と呼ばれる 2 変数関数 𝑘(𝑥, 𝑥′) をあらかじめ 決めておき,𝝓(𝑥𝑖 )⊤𝝓(𝑥𝑗 ) = 𝑘(𝑥𝑖 , 𝑥𝑗 ) と置き換えてしまう. すなわち 𝑘(𝑥𝑖 , 𝑥𝑗 ) を (𝑖, 𝑗) 成分にもつ 𝑁 × 𝑁 行列 𝑲 で, 𝜱𝜱 = 𝑲 と置き換える2: 𝑝(𝒚|𝒙) = N(𝒚|𝟎, 𝑲 + 𝜎2𝑰) 2ここでは簡単のため 𝑠2 も 𝑲 内に押し込めた. 13
ガウス過程回帰 ガウス過程回帰の尤度 𝑝(𝒚|𝑿) = N(𝒚|𝟎, 𝑲 + 𝜎2𝑰) ここでグラム行列 𝑲
は 𝑲 = ⎛ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ 𝑘(𝒙1 , 𝒙1 ) 𝑘(𝒙1 , 𝒙2 ) ⋯ 𝑘(𝒙1 , 𝒙𝑁 ) 𝑘(𝒙2 , 𝒙1 ) 𝑘(𝒙2 , 𝒙2 ) ⋯ 𝑘(𝒙2 , 𝒙𝑁 ) ⋮ ⋮ ⋱ ⋮ 𝑘(𝒙𝑁 , 𝒙1 ) 𝑘(𝒙𝑁 , 𝒙2 ) ⋯ 𝑘(𝒙𝑁 , 𝒙𝑁 ) ⎞ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ なる 𝑁 × 𝑁 の(半正定値対称)行列. カーネル関数 𝑘(𝑥, 𝑥′) は通常正定値性と呼ばれる性質を満たす ように設計するが,今回は割愛 14
ガウス過程回帰による予測 未知の入力点 𝒙∗ に対する出力 𝑦∗ の予測分布もガウス分布に関す る計算から求まる: ガウス過程回帰の予測分布 データ集合を D
= {(𝑦𝑖 , 𝒙𝑖 )𝑁 𝑖=1 } とする.ガウス過程回帰の 予測分布は 𝑝(𝒚∗|𝒙∗, D) = N(𝒌⊤ ∗ (𝑲 + 𝜎2𝑰)−1𝒚, 𝑘∗∗ − 𝒌⊤ ∗ (𝑲 + 𝜎2𝑰)−1𝒌∗ ). ここで 𝑘∗∗ = 𝑘(𝒙∗, 𝒙∗), 𝒌∗ = (𝑘(𝒙1 , 𝒙∗), 𝑘(𝒙2 , 𝒙∗), … , 𝑘(𝒙𝑁 , 𝒙∗))⊤. ∠ 尤度や予測分布が閉形式で書ける! 15
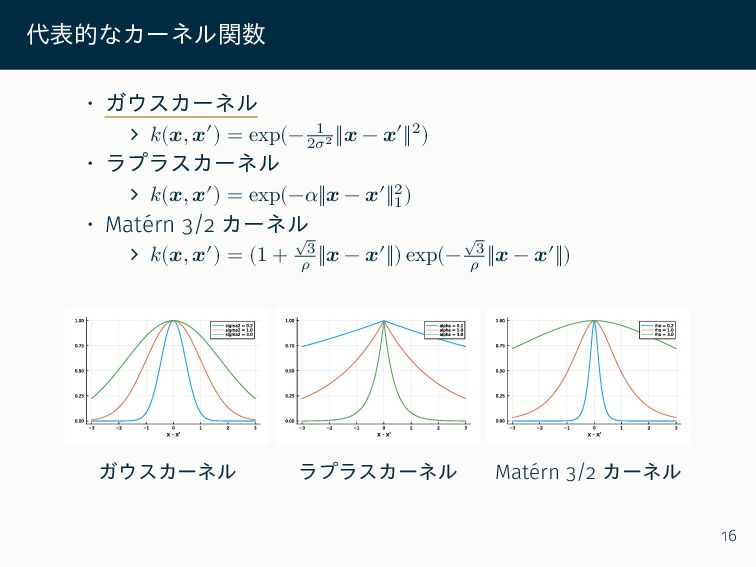
代表的なカーネル関数 • ガウスカーネル ∠ 𝑘(𝒙, 𝒙′) = exp(− 1 2𝜎2
‖𝒙 − 𝒙′‖2) • ラプラスカーネル ∠ 𝑘(𝒙, 𝒙′) = exp(−𝛼‖𝒙 − 𝒙′‖2 1 ) • Matérn 3/2 カーネル ∠ 𝑘(𝒙, 𝒙′) = (1 + √ 3 𝜌 ‖𝒙 − 𝒙′‖) exp(− √ 3 𝜌 ‖𝒙 − 𝒙′‖) ガウスカーネル ラプラスカーネル Matérn 3/2 カーネル 16
ガウス過程の特徴 ガウス過程の利点と欠点 解が閉形式で求まる ∠ カーネル関数のハイパーパラメータはうまく決定する必要 データ点ペアでの内積(≈ 類似度)さえ定義できれば使える ∠
画像・文字列・グラフなど,構造的なデータへの適用が可能 回帰以外のタスクへの拡張性(後述) 大きいデータセットへのスケールの難しさ(後述) 深層学習ほどの高い表現力は期待しにくい ∠ 良くも悪くもカーネル関数にモデルが大きく支配される 17
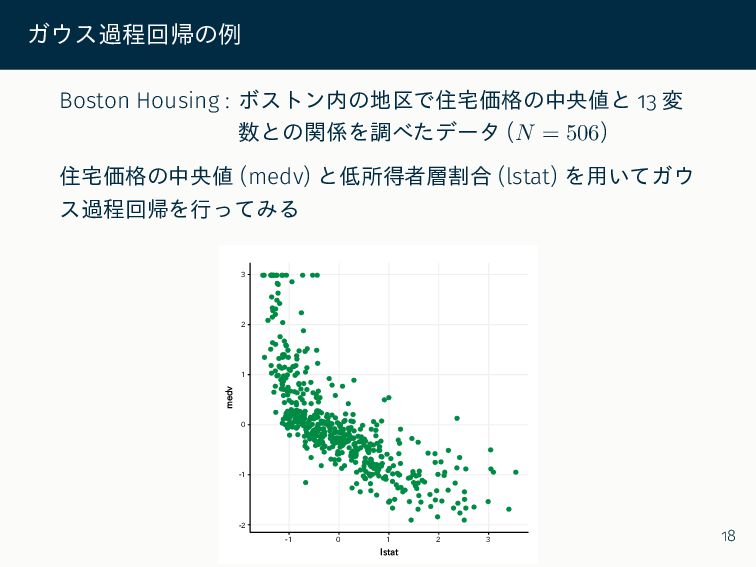
ガウス過程回帰の例 Boston Housing : ボストン内の地区で住宅価格の中央値と 13 変 数との関係を調べたデータ (𝑁 =
506) 住宅価格の中央値 (medv) と低所得者層割合 (lstat) を用いてガウ ス過程回帰を行ってみる -2 -1 0 1 2 3 -1 0 1 2 3 lstat medv 18
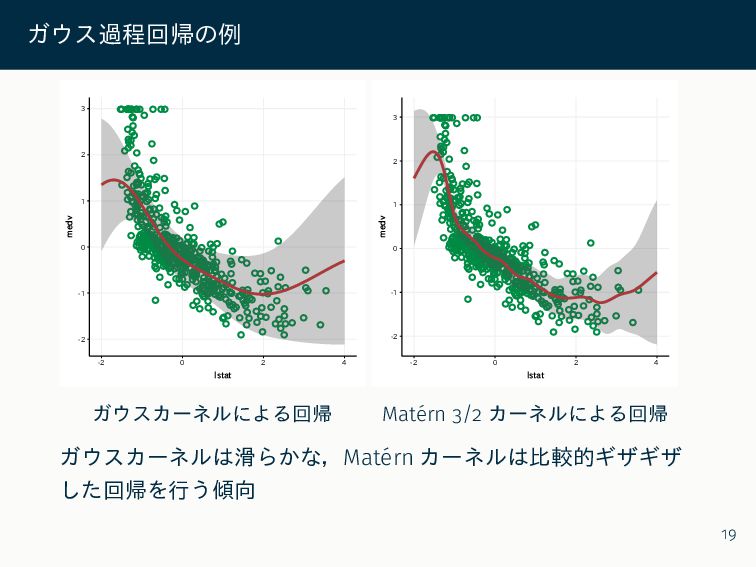
ガウス過程回帰の例 -2 -1 0 1 2 3 -2 0 2
4 lstat medv ガウスカーネルによる回帰 -2 -1 0 1 2 3 -2 0 2 4 lstat medv Matérn 3/2 カーネルによる回帰 ガウスカーネルは滑らかな,Matérn カーネルは比較的ギザギザ した回帰を行う傾向 19
ガウス過程の発展
ガウス過程の別解釈 先ほどはガウス過程回帰を線形回帰モデルから導出した. 一方,次のような確率モデルもガウス過程回帰と等価になる. ガウス過程回帰の補助変数表現 𝑝(𝒚|𝒇) = N(𝒚|𝒇, 𝜎2𝑰) 𝑝(𝒇|𝑿) =
N(𝒇|𝟎, 𝑲) 𝑝(𝒚, 𝒇|𝒙) = 𝑝(𝒚|𝒇)𝑝(𝒇|𝒙) から 𝒇 を積分消去すれば,ガウス過程 回帰の尤度と同じ形に. 入力 𝒙1 , … , 𝒙𝑁 の値が変わると,𝒇 の分布が変わる ∠ 𝒇 をある関数 𝑓(⋅) の関数値𝒇 = (𝑓(𝒙1 ), … , 𝑓(𝒙𝑁 ))⊤と解釈 20
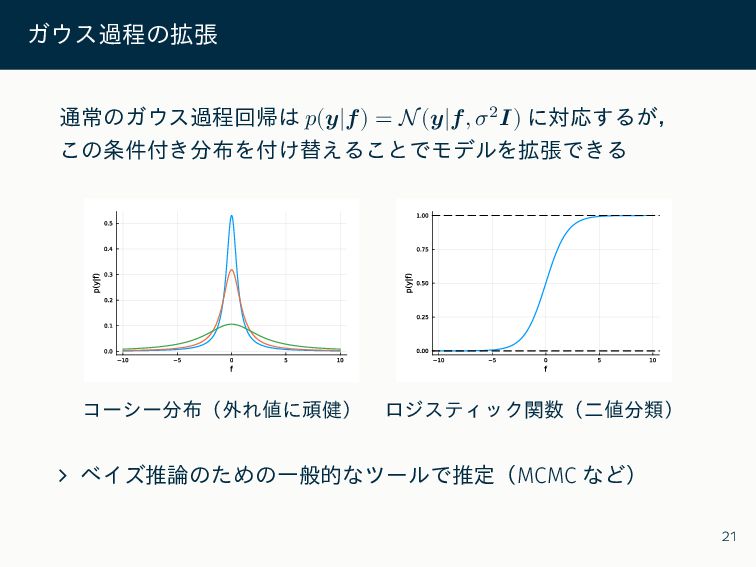
ガウス過程の拡張 通常のガウス過程回帰は 𝑝(𝒚|𝒇) = N(𝒚|𝒇, 𝜎2𝑰) に対応するが, この条件付き分布を付け替えることでモデルを拡張できる コーシー分布(外れ値に頑健) ロジスティック関数(二値分類)
∠ ベイズ推論のための一般的なツールで推定(MCMC など) 21
ガウス過程の計算問題 ガウス過程の各種計算を正確に行うには O(𝑁3) の計算量が必要 ∠ 主にグラム行列の逆行列 𝑲−1 の計算による ∠
大規模な問題にスケールしない ガウス過程の計算量削減に用いられる代表的なアプローチが 補助入力点によるもの. ∠ 入力空間上の少数の点にデータを “代表” させる 今回は比較的メジャーなスパース変分近似を紹介 22
スパース変分近似 ガウス過程回帰の尤度 𝑝(𝒚|𝑿) = N(𝟎, 𝑲ff + 𝜎2𝑰) は,入力空間 上に
𝑀 個の誘導点 𝒛1 , … , 𝒛𝑀 を導入することで, 𝑝(𝒚|𝒇) = N(𝒇, 𝜎2𝑰) 𝑝(𝒇|𝒖) = N(𝑲fu 𝑲−1 uu 𝒖, 𝑲ff − 𝑲fu 𝑲−1 uu 𝑲⊤ fu ) 𝑝(𝒖) = N(𝟎, 𝑲uu ) とさらに分解できる(𝒇, 𝒖 の積分消去でもとに戻る) . • 𝑲ff :(𝑖, 𝑗) 成分が 𝑘(𝒙𝑖 , 𝒙𝑗 ) の 𝑁 × 𝑁 行列 • 𝑲fu :(𝑖, 𝑚) 成分が 𝑘(𝒙𝑖 , 𝒛𝑚 ) の 𝑁 × 𝑀 行列 • 𝑲uu :(𝑙, 𝑚) 成分が 𝑘(𝒛𝑙 , 𝒛𝑚 ) の 𝑀 × 𝑀 行列 23
スパース変分近似 スパース変分近似では,𝒇, 𝒖 の事後分布を 𝑞(𝒇, 𝒖) = 𝑝(𝒇|𝒖)𝑞(𝒖) 𝑞(𝒖) =
N(𝒎, 𝜮) なる形に制限したときに,最も真の事後分布への近似が良くなる ように 𝒎, 𝜮 を決定する. 近似の良さは KL ダイバージェンスを用いて測る: 𝐷KL (𝑞‖𝑝) = ∫ 𝑞(𝒙) log 𝑞(𝒙) 𝑝(𝒙) 𝑑𝒙. ∠ 確率分布間の乖離度を示す代表的な指標 24
スパース変分近似 KL ダイバージェンス最小化により,𝑞(𝒎, 𝜮) の最適パラメータが 𝜮 = [𝑲−1 uu +
𝜎−2𝑲−1 uu 𝑲uf 𝑲fu 𝑲−1 uu ]−1, 𝒎 = 𝜎−2𝜮𝑲uf 𝒚 と求まる. ∠ 𝑁 × 𝑁 行列の逆行列が現れなくなった! 予測分布も同様に 𝑁 × 𝑁 の逆行列計算を回避して近似計算可能 各種計算量はO(𝑁3)からO(𝑁𝑀2)へ ∠ データ数 10k–100k オーダーでの学習が現実的に 25
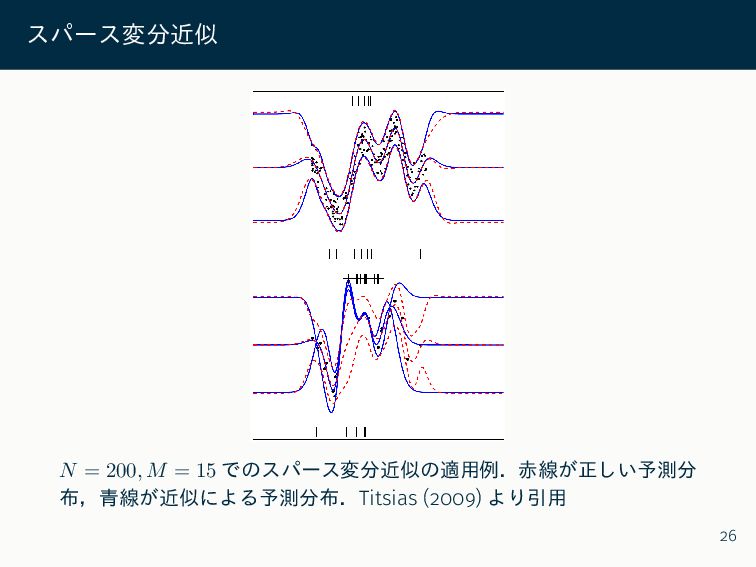
スパース変分近似 𝑁 = 200, 𝑀 = 15 でのスパース変分近似の適用例.赤線が正しい予測分 布,青線が近似による予測分布.Titsias (2009)
より引用 26
むすび
むすびに ガウス過程回帰について,ベイズ推論の基礎から概観. 今回触れられなかったトピックも多数: • ガウス過程を用いた次元削減や実験計画などの発展的タスク • カーネル関数やハイパーパラメータ選択の実際 • さらなる計算量削減のための手法 •
理論的側面 ガウス過程は理論・方法論・応用いずれも日進月歩でアツい! 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}