Random Projections (ランダム射影)の理論的考察を深めた以下の論文の紹介スライドです:
Michal Derezinski, Feynman T. Liang, Zhenyu Liao, Michael W. Mahoney, "
Precise expressions for random projections: Low-rank approximation and randomized Newton," NeurIPS2020
・論旨が追いやすくなるよう原論文から構成などは変えています
・なるべくself-containedな資料とするため,原論文には記載のないRandom Projections,劣ガウス分布,Implicit Regularizationそれぞれの概説を付け加えています
・画質の問題から,ブラウザ上でなくダウンロードしてお手元のPDFビューアで閲覧することをおすすめします
{kind=link}
{kind=link}
{kind=link}
{kind=link}
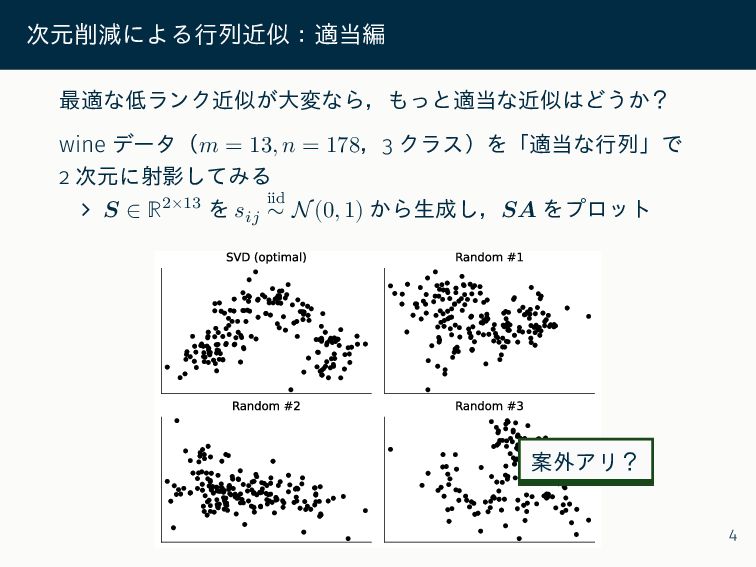{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
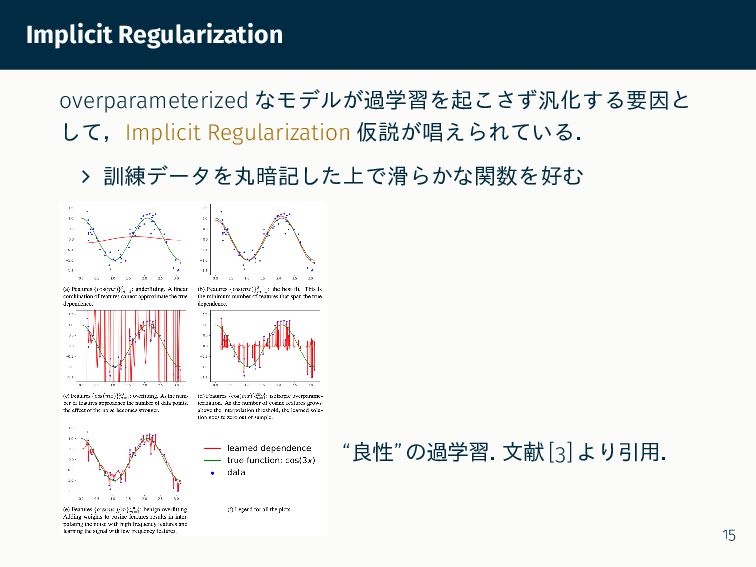{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
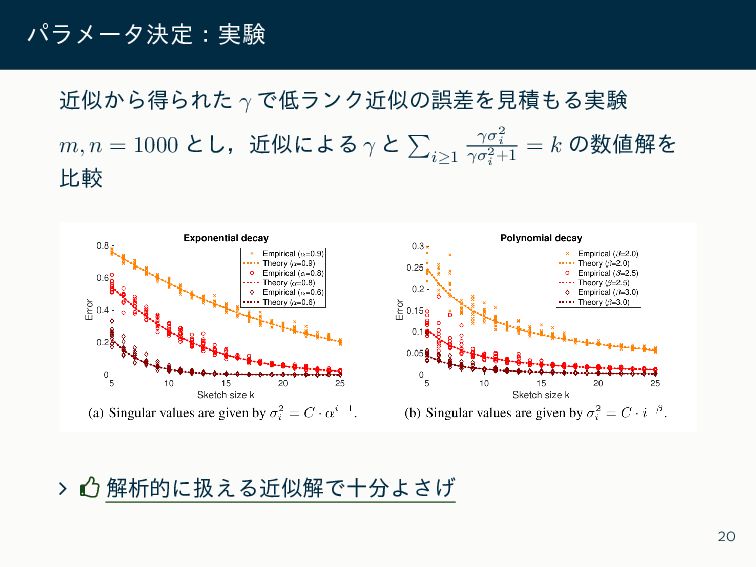{kind=link}
{kind=link}
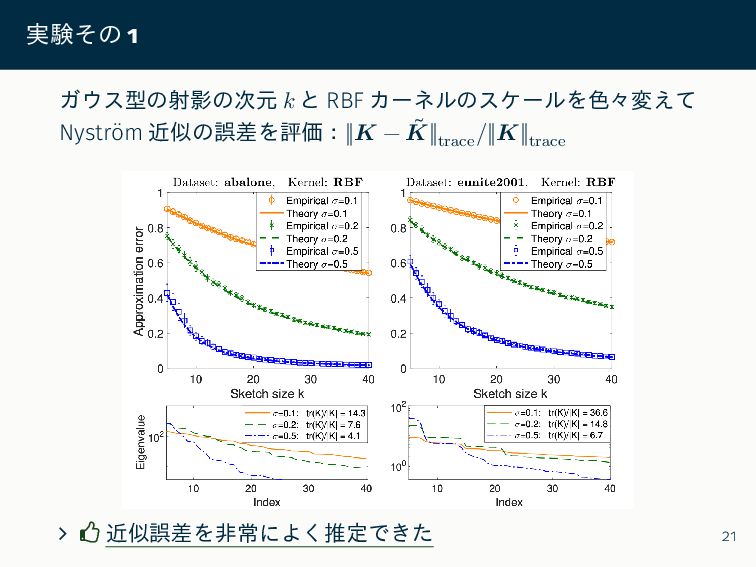{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References i [1] Papadimitriou, C. H., Raghavan, P., Tamaki, H.,](https://files.speakerdeck.com/presentations/4c1c7a8f5736468dad11462cc8e7e81e/slide_28.jpg){kind=link}