Share
論文紹介 Jiaxin Shi, Michalis K. Titsias, and Andriy Mnih, "Sparse Orthogonal Variational Inference for Gaussian Processes," AISTATS 2020. http://proceedings.mlr.press/v108/shi20b.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![スパース近似の主結果 最小化したい目的関数は min 𝑞 KL[𝑞(𝒇∗, 𝒇, 𝒖)‖𝑝(𝒇∗, 𝒇, 𝒖|𝒚)] =](https://files.speakerdeck.com/presentations/7cf3b2695ce94e659fb6557e62f43c50/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
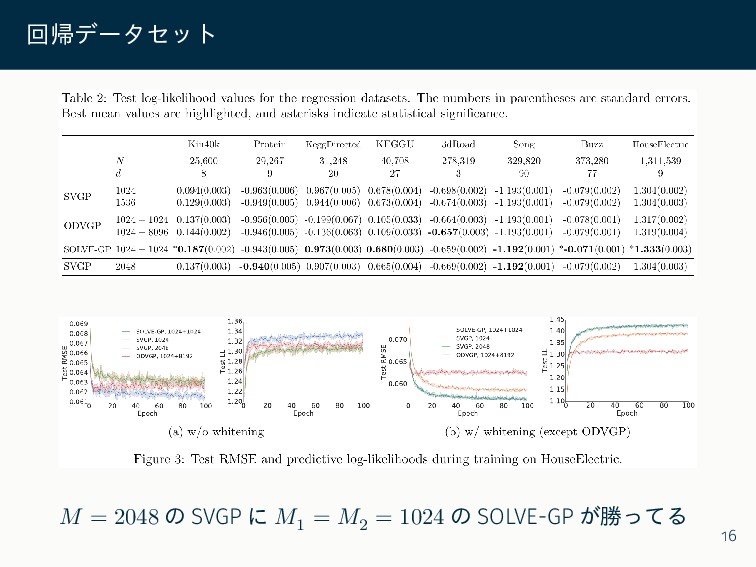
![1 次元回帰 文献 [1] の簡単な ℝ → ℝ の回帰を解いてみる. 𝑀](https://files.speakerdeck.com/presentations/7cf3b2695ce94e659fb6557e62f43c50/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] Snelson E., Ghahramani Z., “Sparse Gaussian processes using](https://files.speakerdeck.com/presentations/7cf3b2695ce94e659fb6557e62f43c50/slide_23.jpg){kind=link}