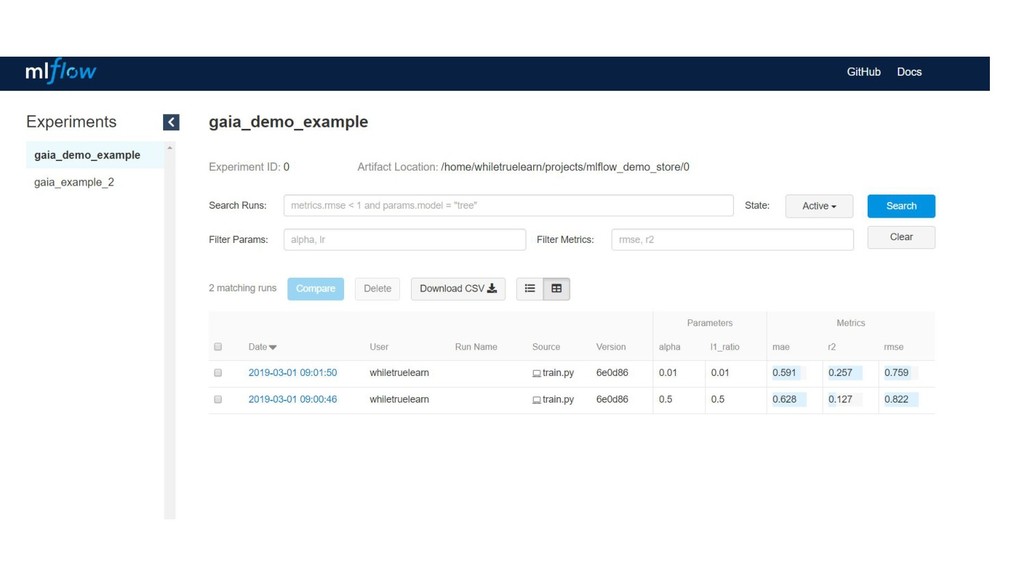
what code was used. - Remember what hyperparameters / config was used. - Remember what the results of experiments are. - Remember to save the model somewhere maybe? - Compare the results between different experiments.
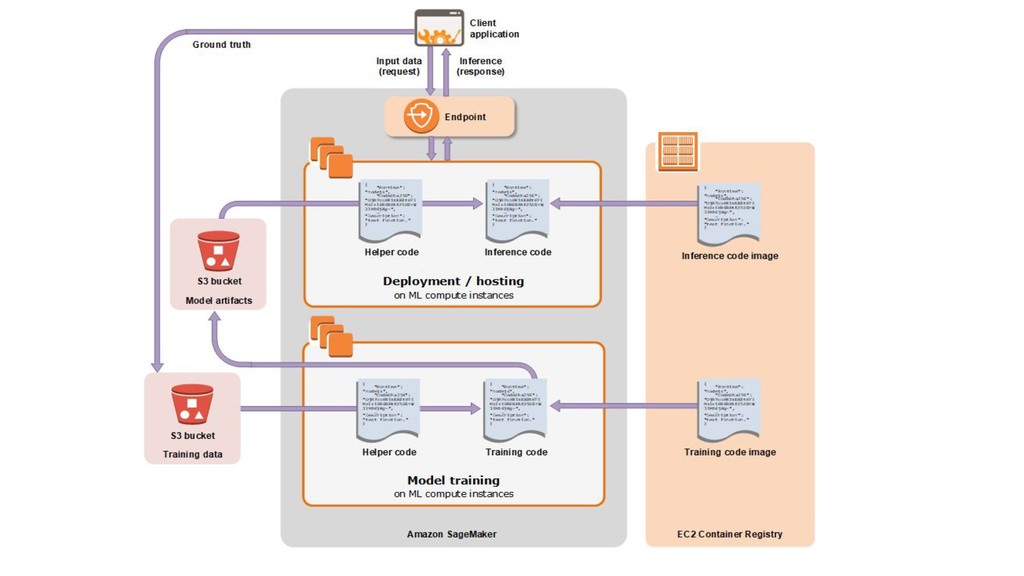
my training data increase. - Should handle all my training dependencies well. - Should be executed remotely - Should be cost effective. - Should be able to train multiple models in parallel. - Should be framework agnostic. - Should track everything about experiment - Should allow optional deployment of the model built.
+ heuristics - It’s most of the time an ensemble of models. - Important to ensure that the glue code is bug free. - Enables a CI/CD based deployment of models. - Remember good SE practices apply in ML as well. - The build of this codebase should be an artifact from the CI/CD pipeline.
from the get go. - Important to have artifacts of different experiments saved properly. - Important to have a cost effective yet scalable way of training models. - Write good code.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}