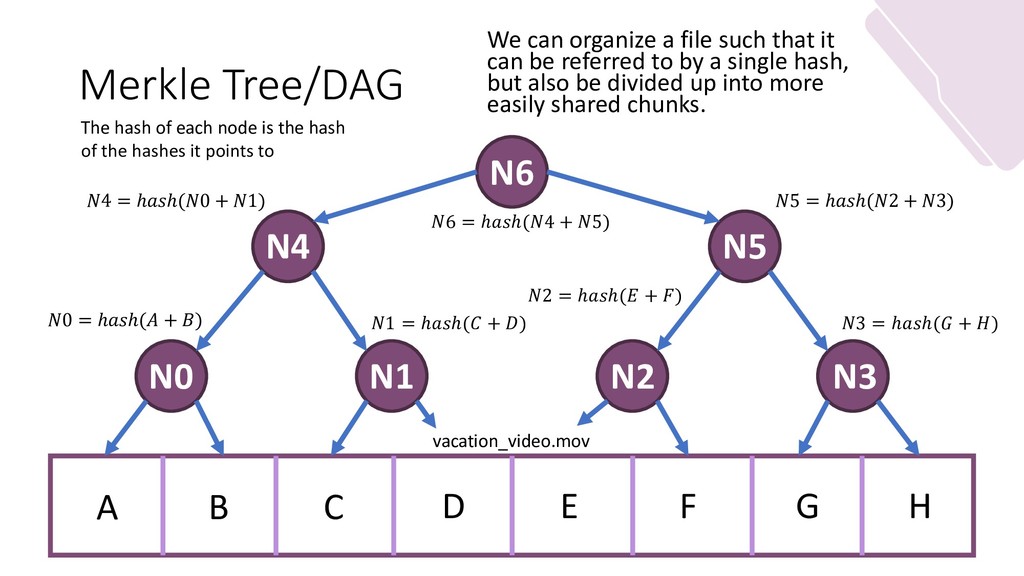
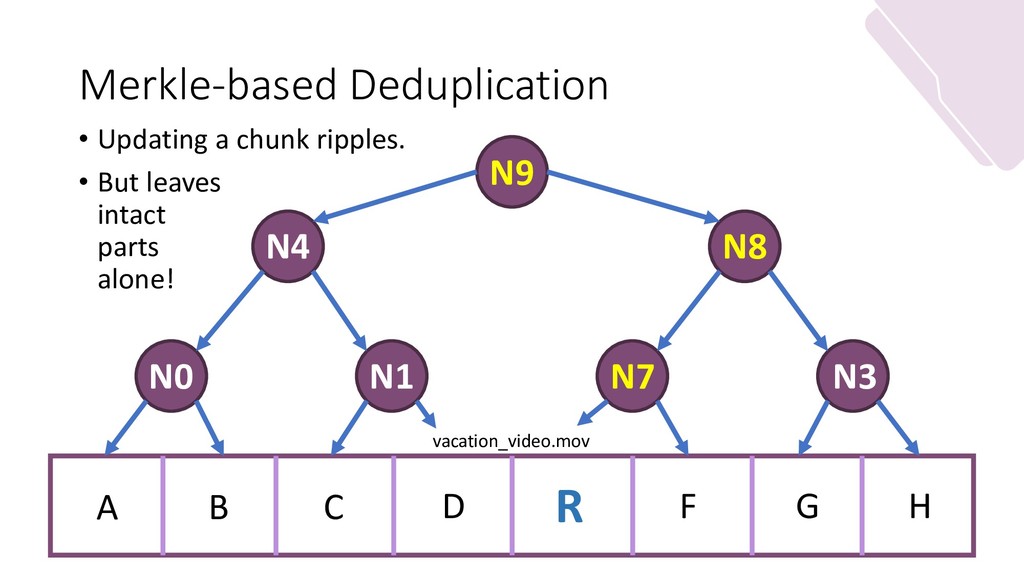
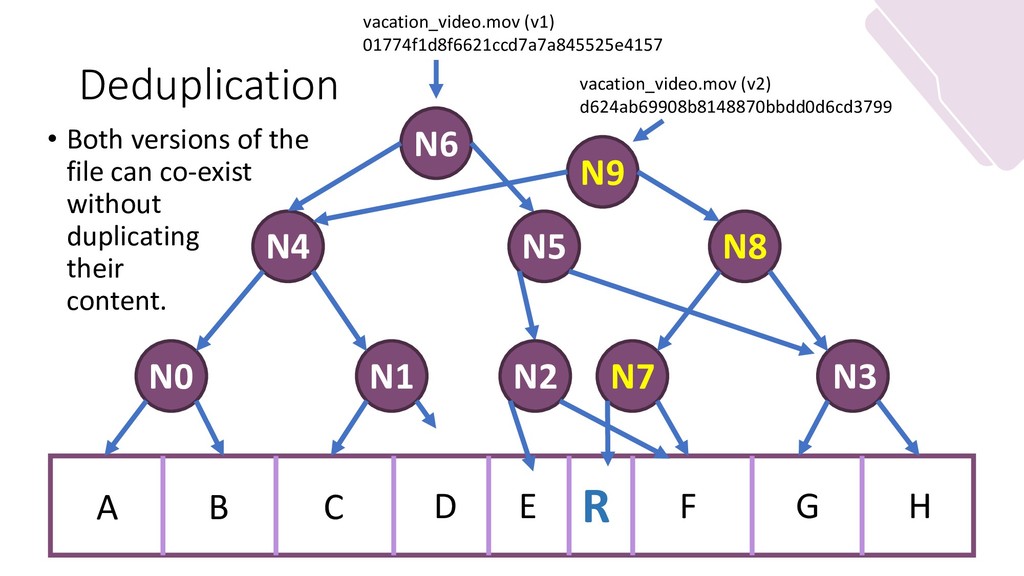
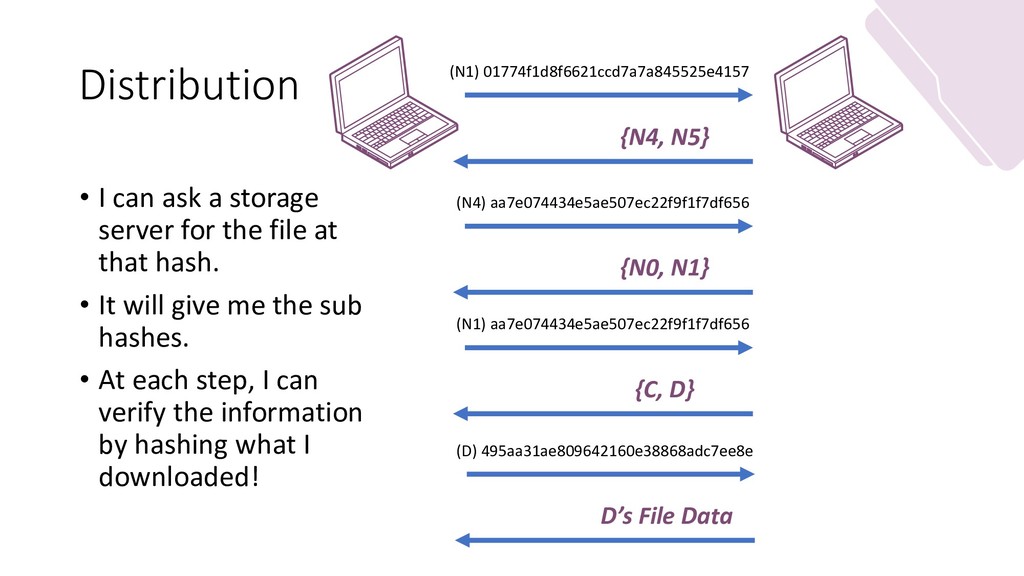
My slides for my guest lecture in a masters-level grad course in distributed systems. It focuses on distributed storage and file systems. It goes from NFS (client to server, centralization of writes) to IPFS (Kademlia, DHTs) while discussing the merits and function of new forms of file system layouts (Hash-based; Merkle DAGs.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
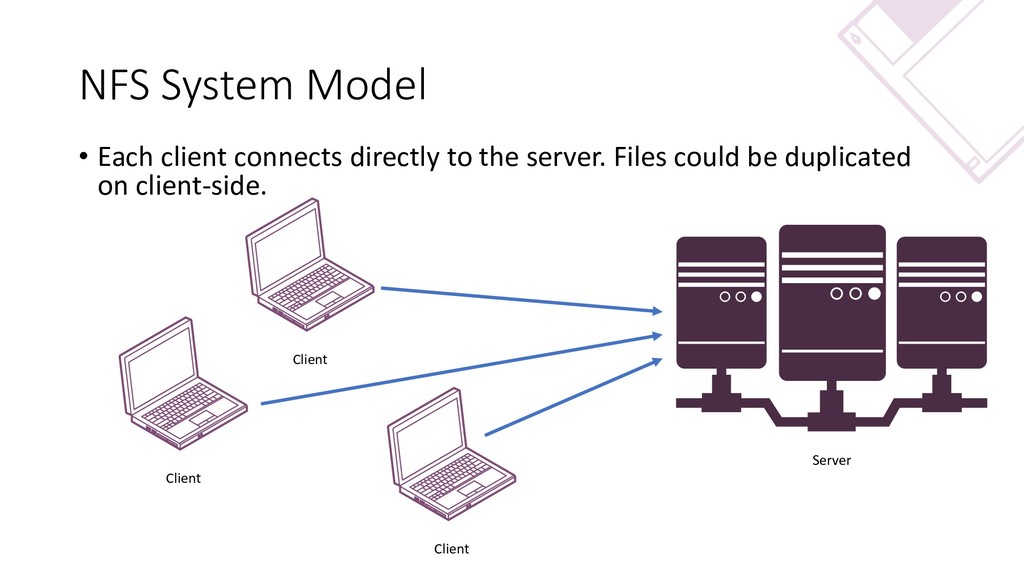{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Statelessness And Failure (NFS) [best] A client issues a series](https://files.speakerdeck.com/presentations/d2f1b8e3cc704009805a300b6075c133/slide_9.jpg){kind=link}
{kind=link}
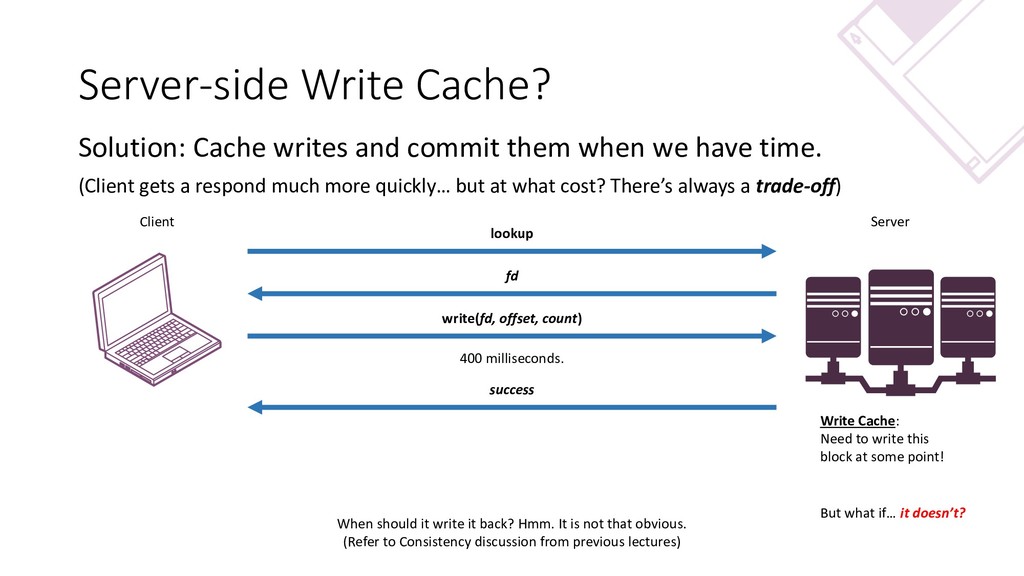{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
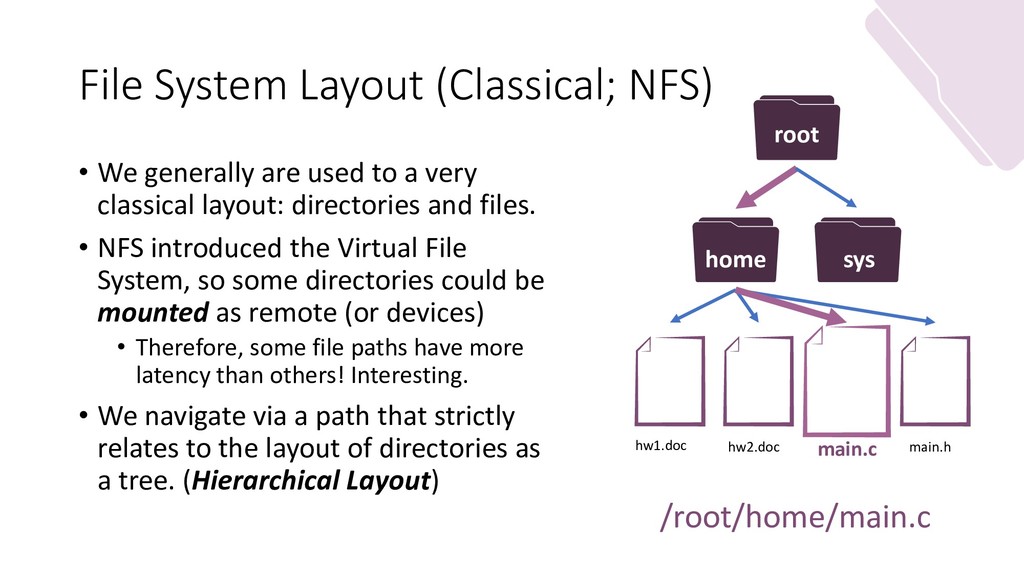{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
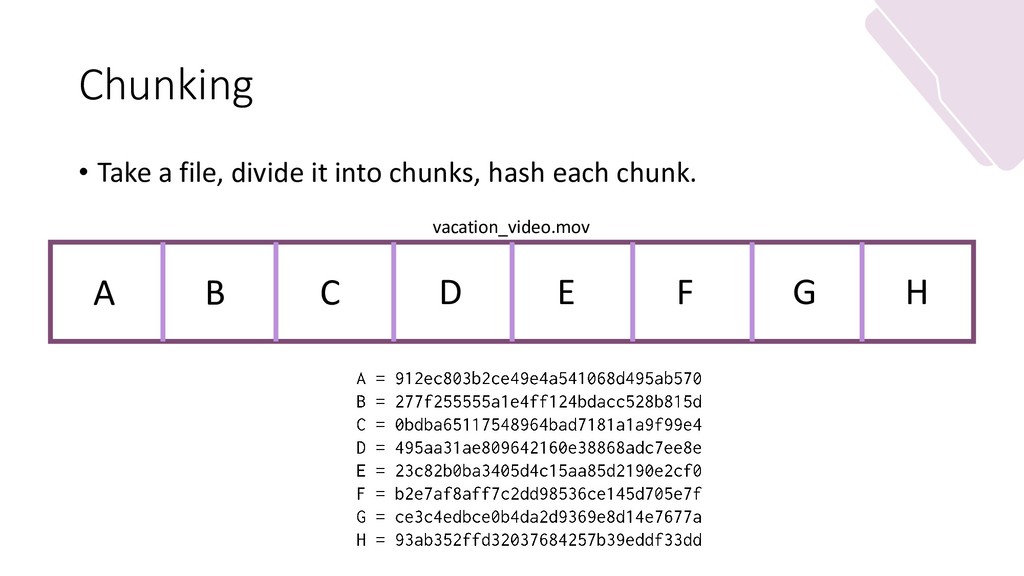{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
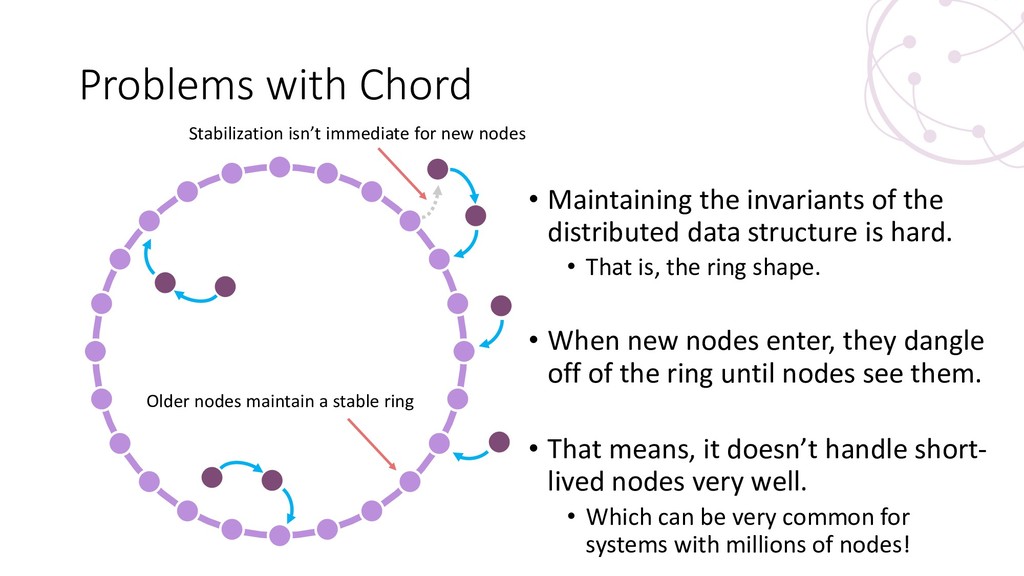{kind=link}
{kind=link}
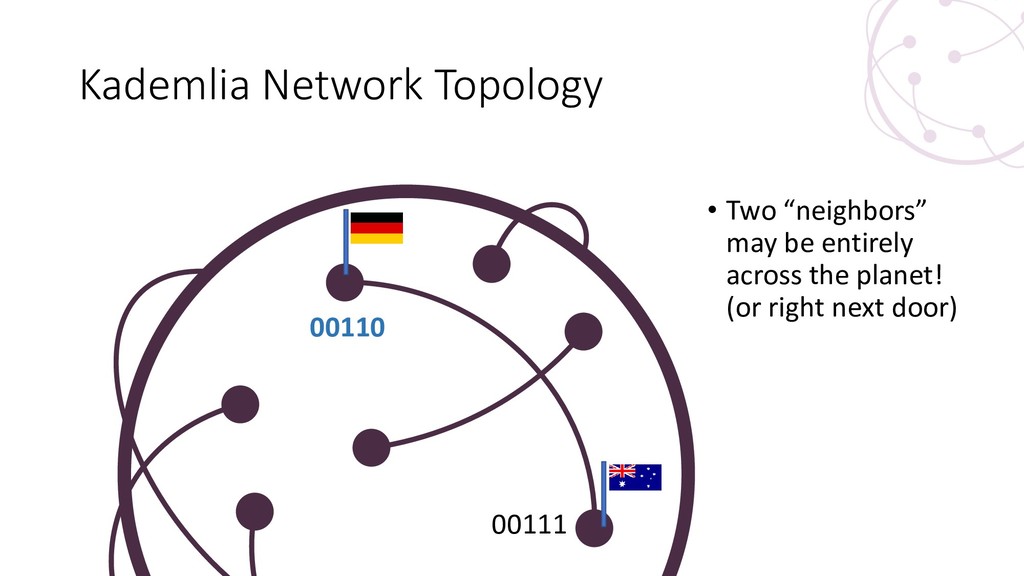{kind=link}
{kind=link}
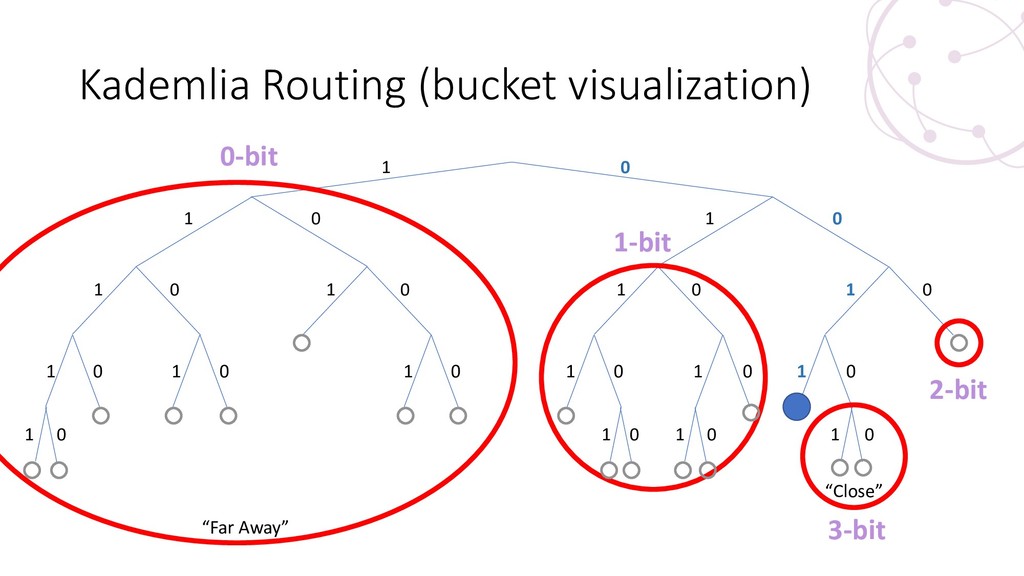{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}