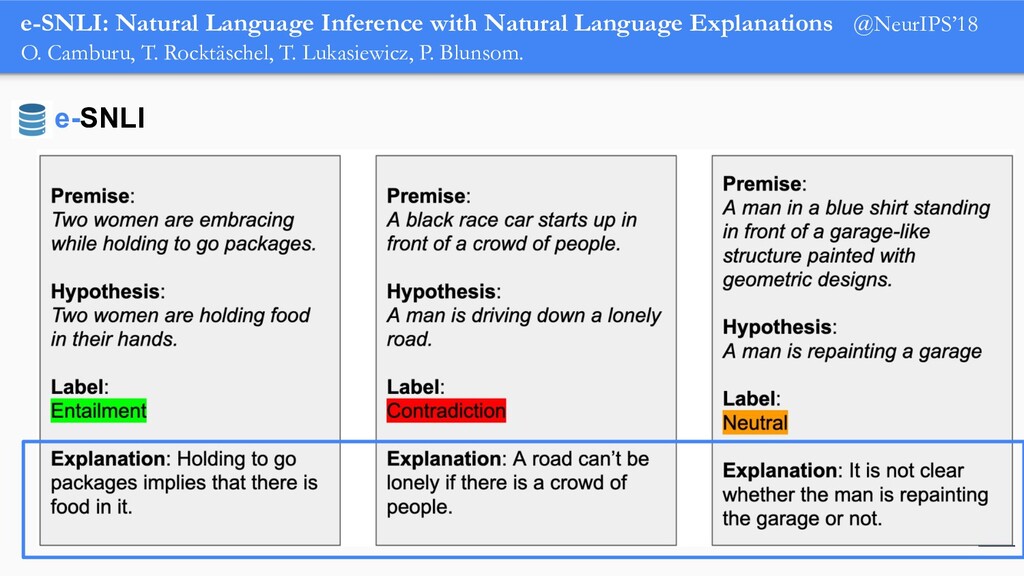
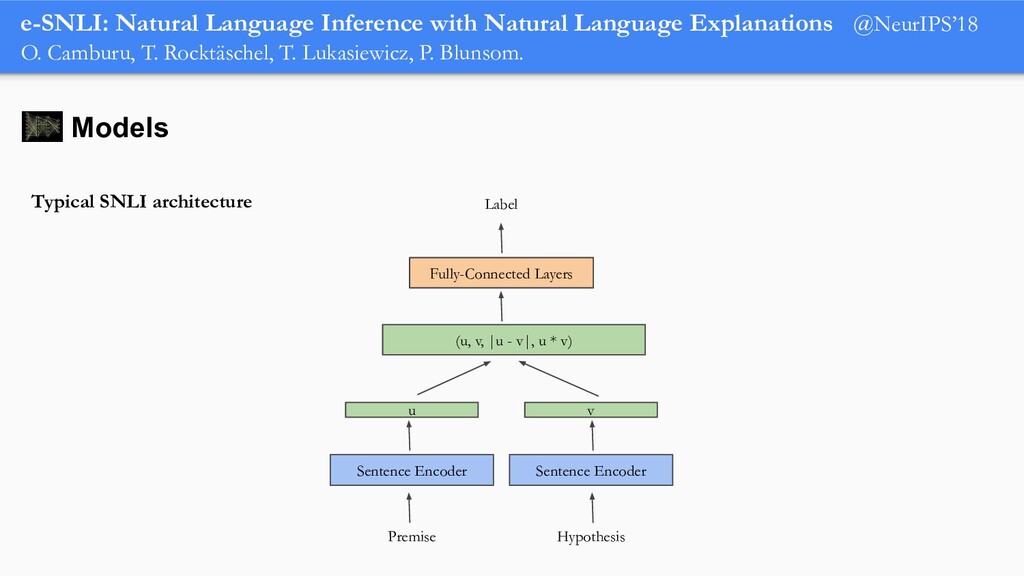
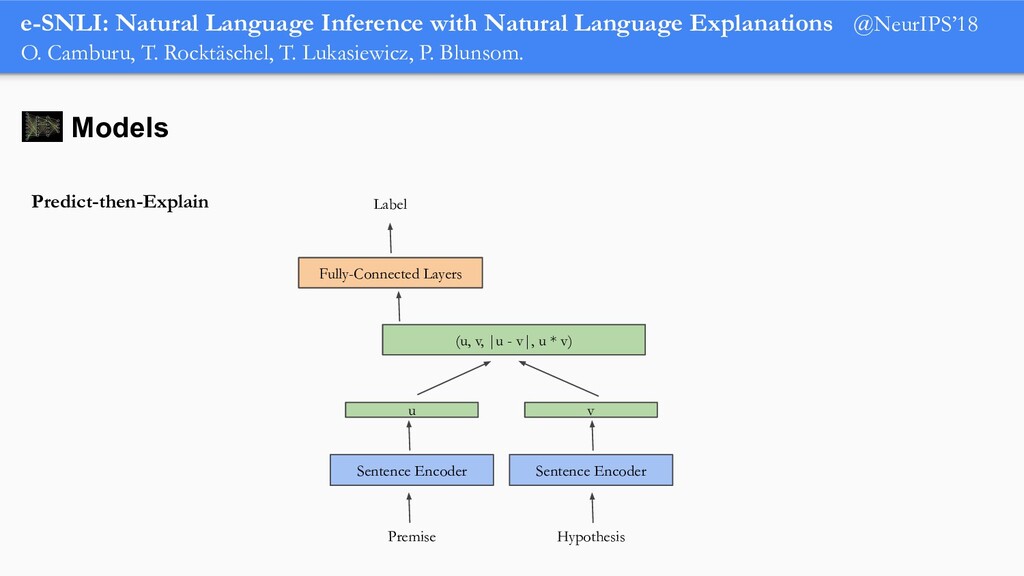
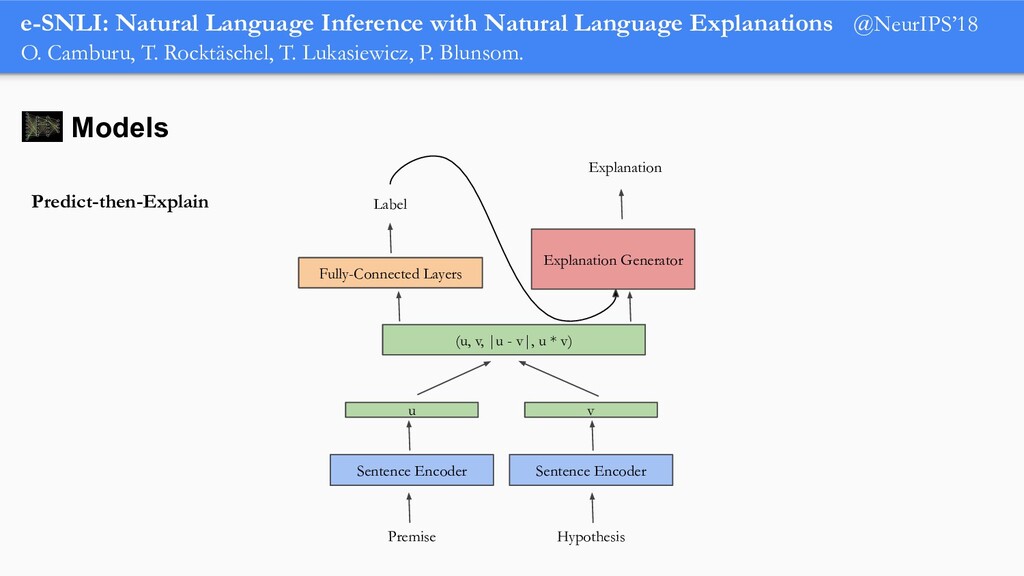
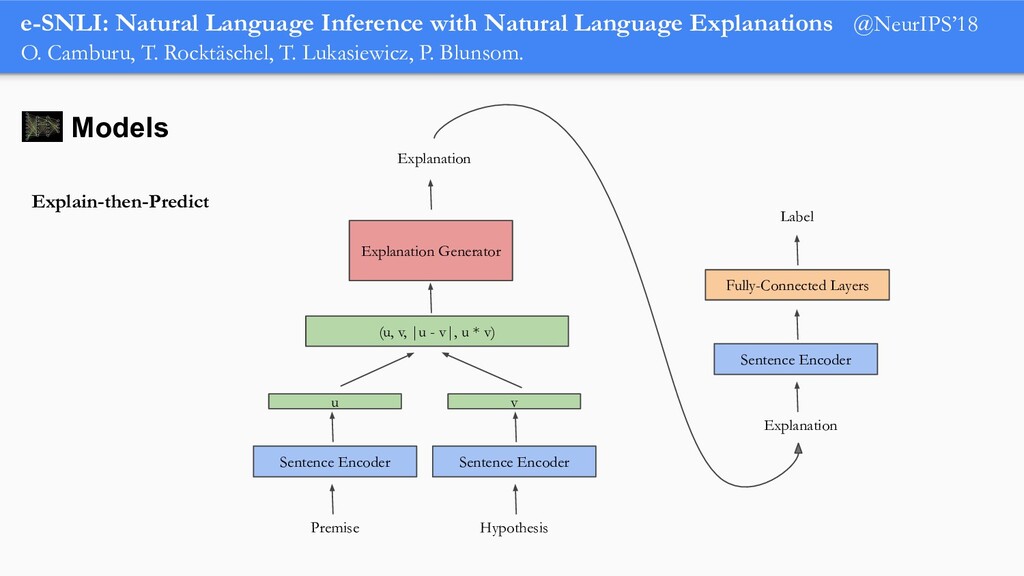
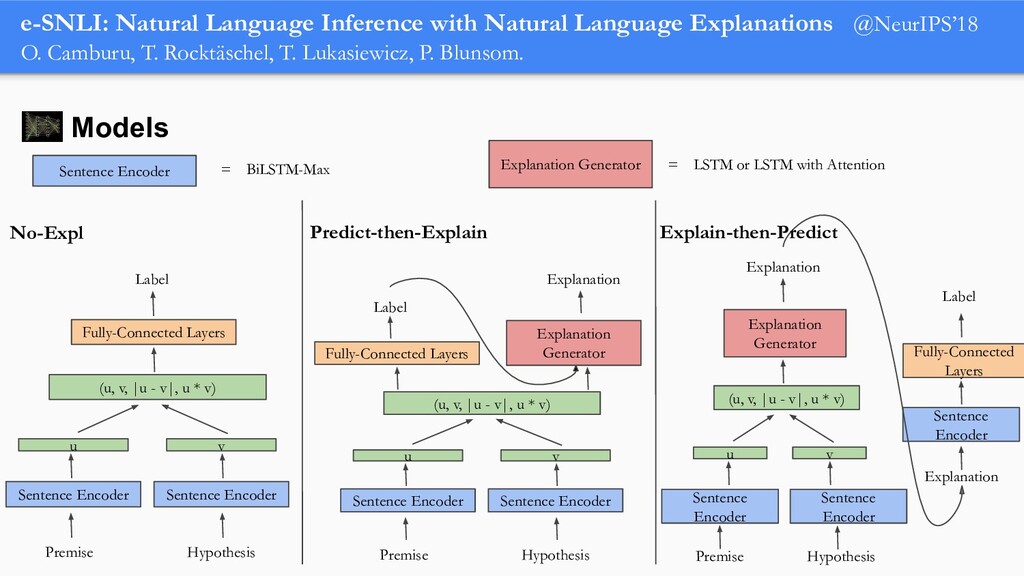
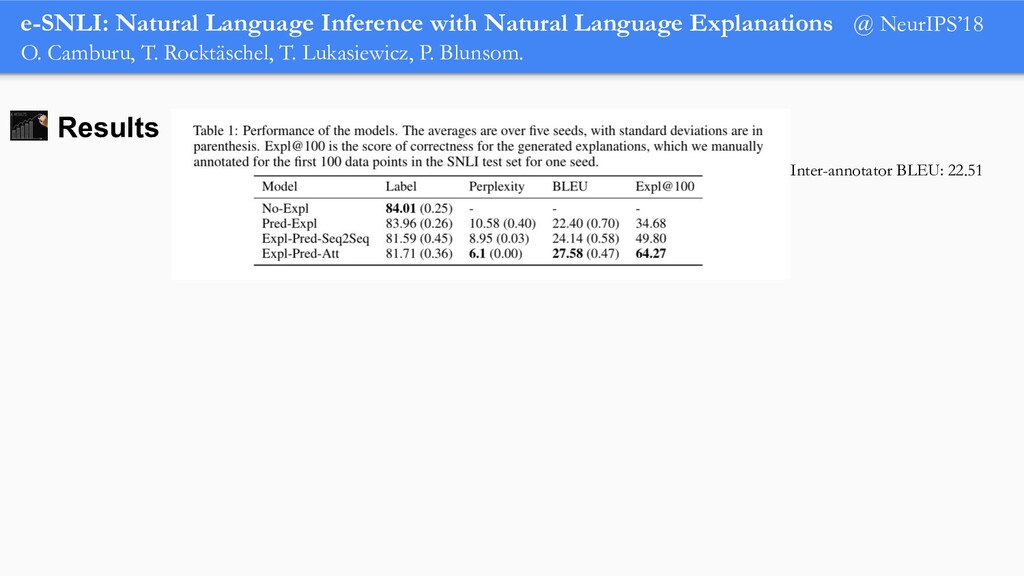
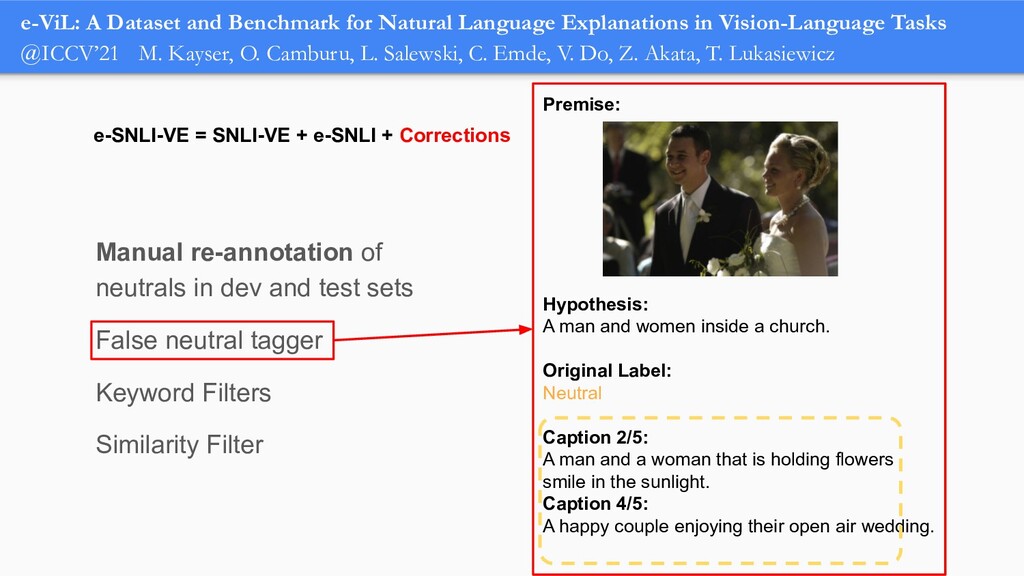
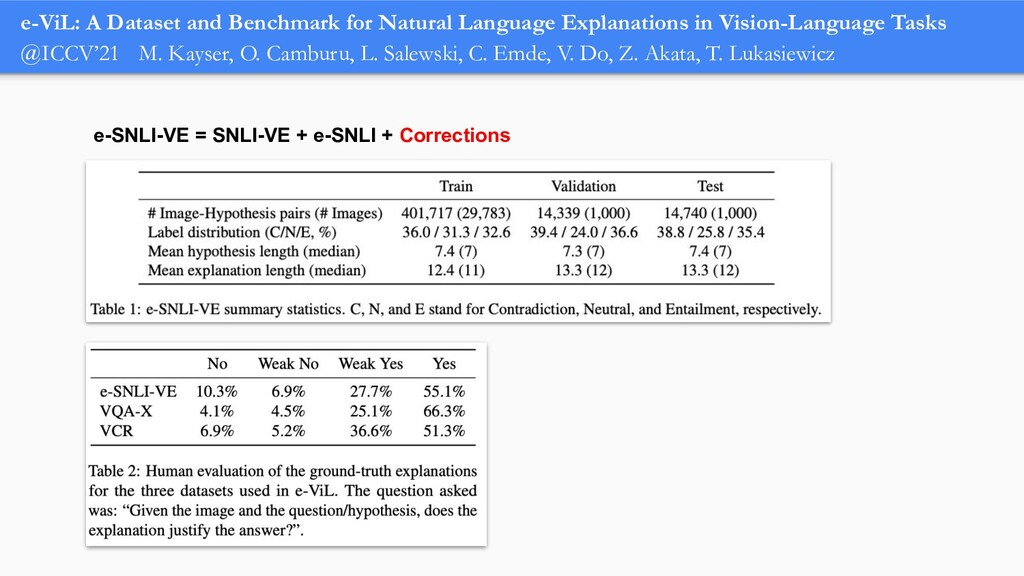
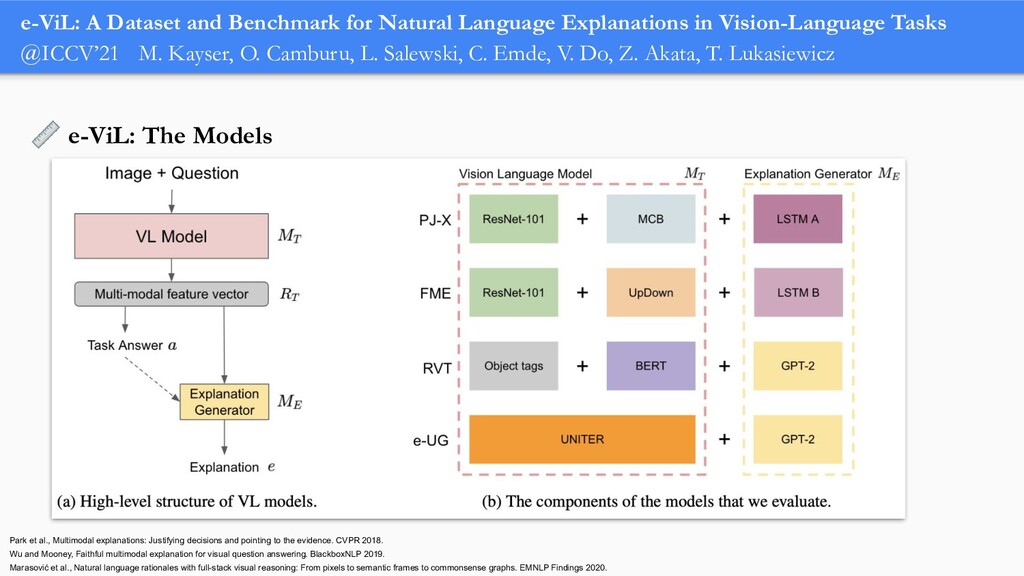
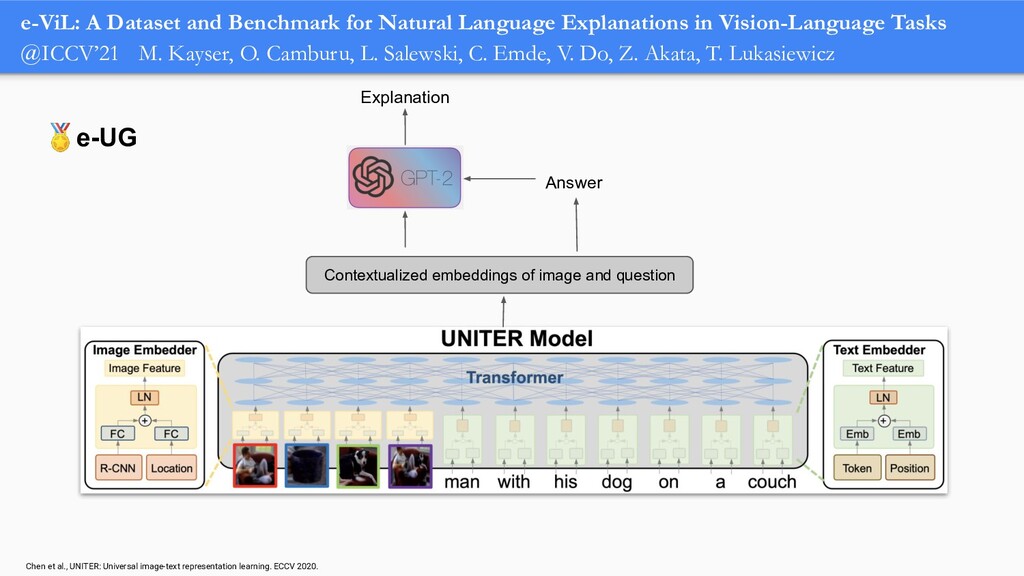
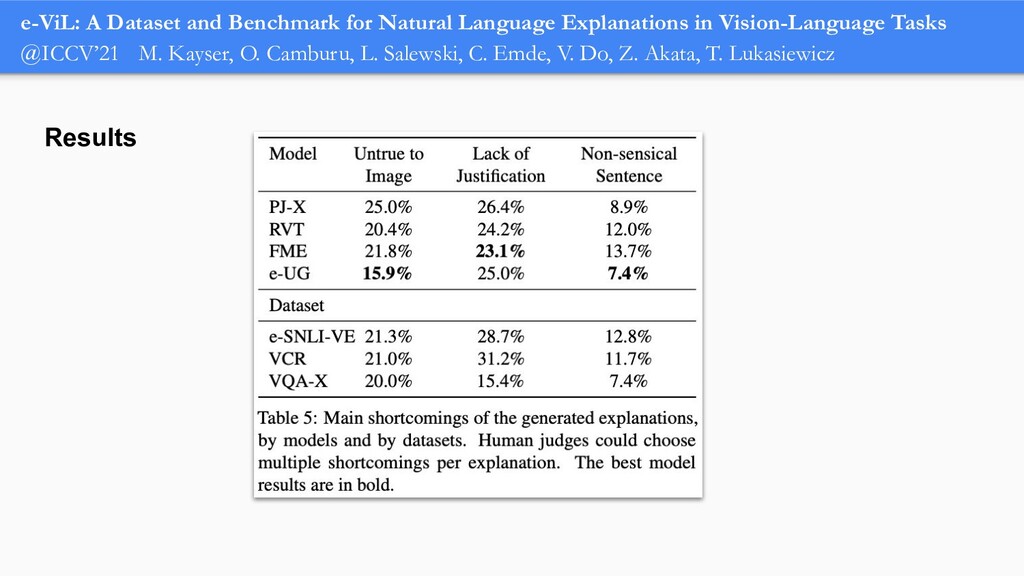
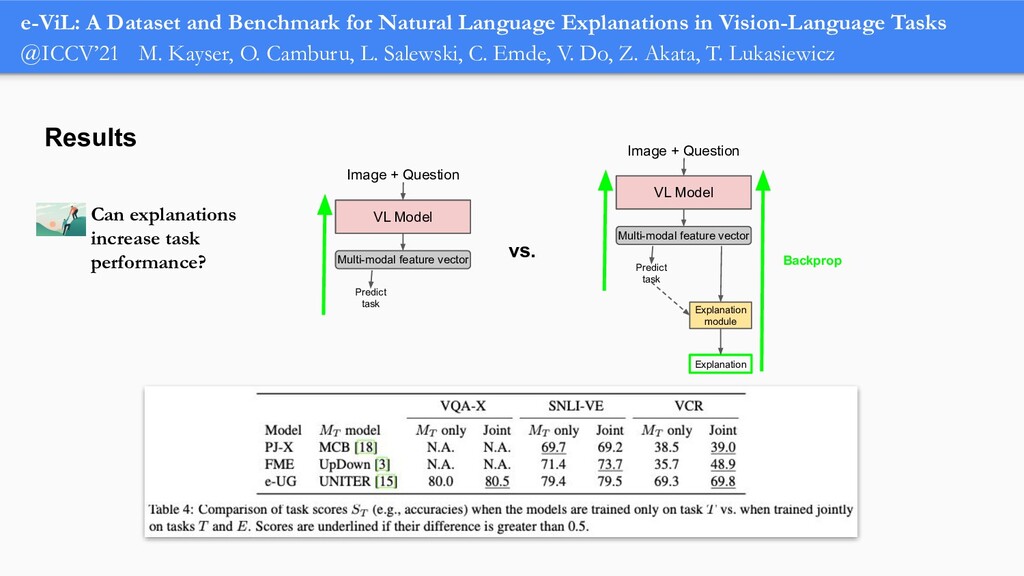
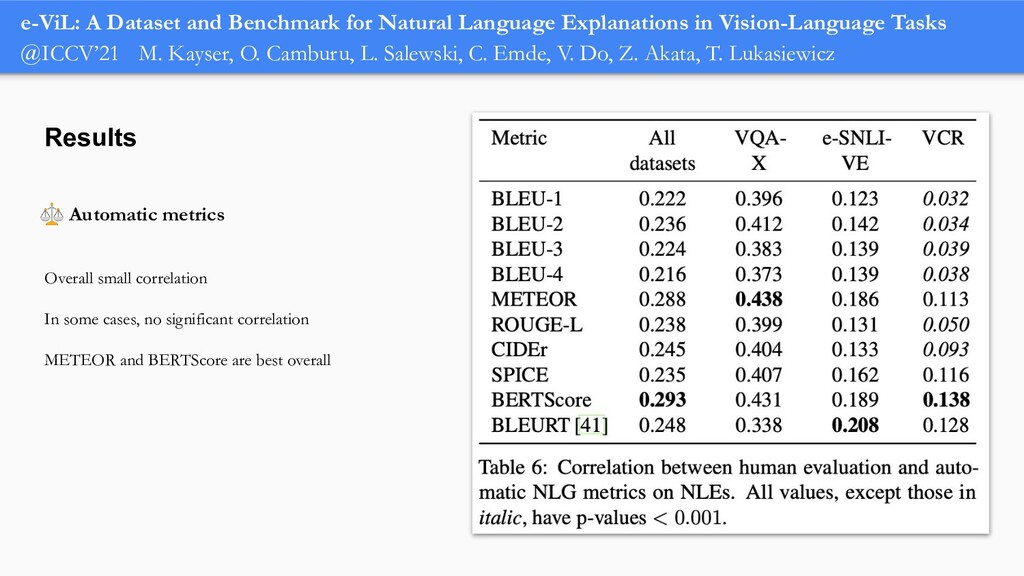
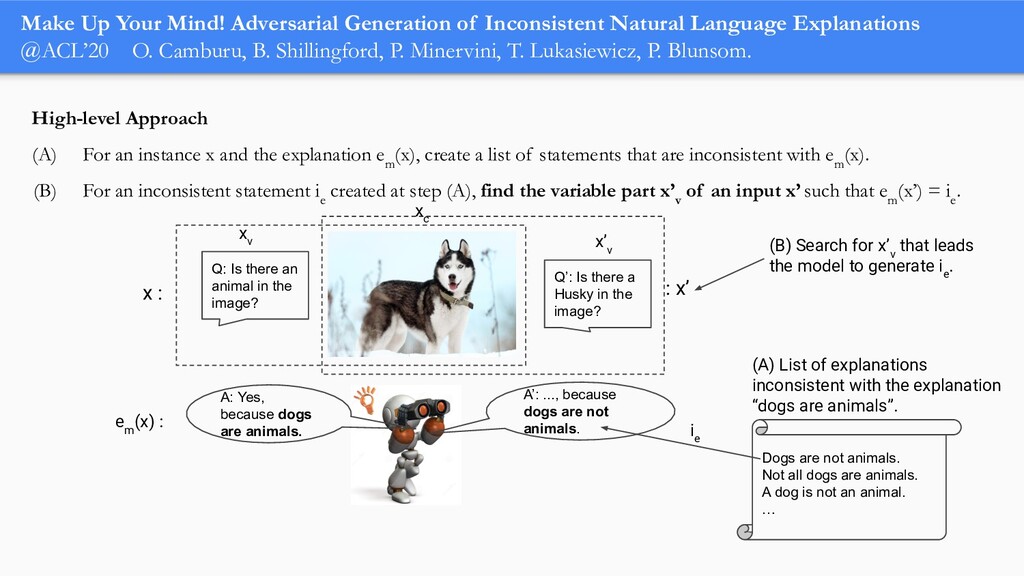
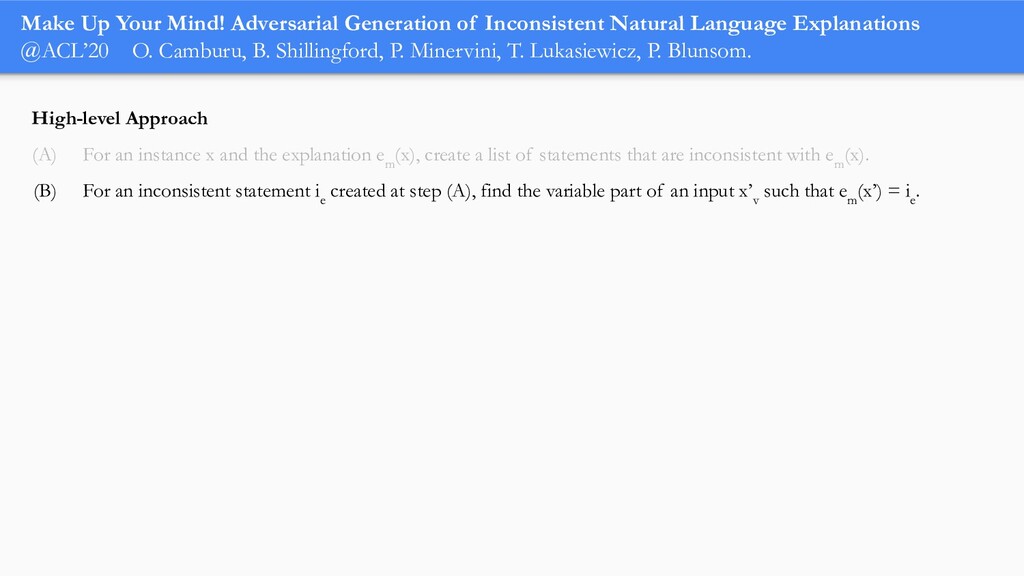
In order for machine learning to garner widespread public adoption, models must be able to provide human-understandable and robust explanations for their decisions. In this talk, we will focus on the emerging direction of building neural networks that learn from natural language explanations at training time and generate such explanations at testing time. We will see an extension of the large Stanford Natural Language Inference (SNLI) dataset with an additional layer of human-written natural language explanations for the entailment relations, called e-SNLI. We will see different types of architectures that incorporate these explanations into their training process and generate them at testing time. We will further see a similar approach for vision-language models, where we introduce e-SNLI-VE, a large dataset of visual-textual entailment with natural language explanations. We will also see e-ViL, a benchmark for natural language explanations in vision-language tasks, and e-UG, the current SOTA model for natural language explanation generation on such tasks. These large datasets of explanations open up a range of research directions for using natural language explanations both for improving models and for asserting their trust. However, models trained on such datasets may nonetheless generate inconsistent explanations. An adversarial framework for sanity checking models over generating such inconsistencies will be presented.
Seminar page: https://wing-nus.github.io/ir-seminar/speaker-oana
YouTube Video recording: https://www.youtube.com/watch?v=-bopzFou7jQ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}