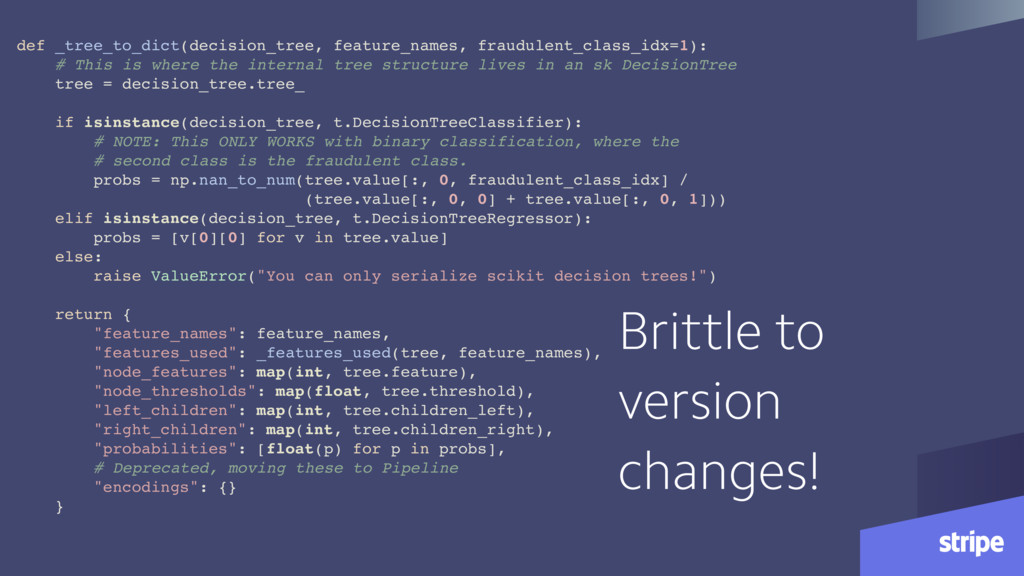
tree structure lives in an sk DecisionTree tree = decision_tree.tree_ if isinstance(decision_tree, t.DecisionTreeClassifier): # NOTE: This ONLY WORKS with binary classification, where the # second class is the fraudulent class. probs = np.nan_to_num(tree.value[:, 0, fraudulent_class_idx] / (tree.value[:, 0, 0] + tree.value[:, 0, 1])) elif isinstance(decision_tree, t.DecisionTreeRegressor): probs = [v[0][0] for v in tree.value] else: raise ValueError("You can only serialize scikit decision trees!") return { "feature_names": feature_names, "features_used": _features_used(tree, feature_names), "node_features": map(int, tree.feature), "node_thresholds": map(float, tree.threshold), "left_children": map(int, tree.children_left), "right_children": map(int, tree.children_right), "probabilities": [float(p) for p in probs], # Deprecated, moving these to Pipeline "encodings": {} } Brittle to version changes!
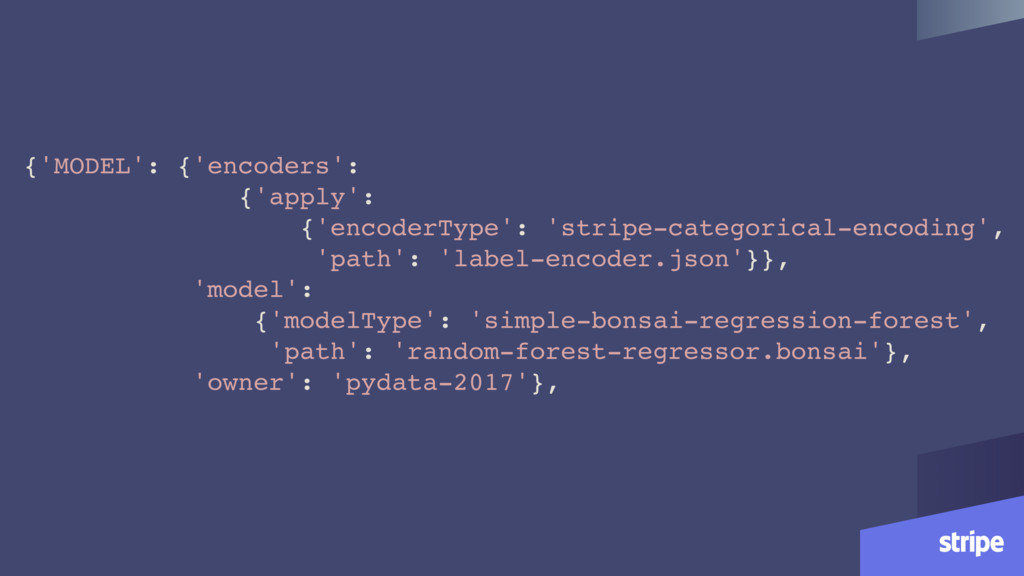
In [4]: model_package.model Out[4]: <scripts.ml.lib.diorama.serialize.model_package.Model…> In [5]: model_package.encoder.encoder_type Out[5]: 'stripe-categorical-encoding' In [6]: model_package.model.model_type Out[6]: 'simple-bonsai-regression-forest'
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In [2]: model_package = estimator.model_package In [3]: model_package.encoder Out[3]: <scripts.ml.lib.diorama.serialize.model_package.ApplyFeatureEncoder…>](https://files.speakerdeck.com/presentations/c9571e6caf3644c9a884580bffb7abd9/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x01\x 00\x00\x00\x1b@\x7f2=p\xa3\xd7\n@\x84\x13>E0n\xb4@z\xfd\xb6\xdbm\xb6\xdb@| \xeepc\xe7\x06>@\x7f\x02\x16B\xc8Y\x0b@\x82\x1b\xd7\n=p\xa4@\x82.y\xe7\x9ey \xe8@~\xbbm\xb6\xdbm\xb7@\x7f\xf8\xaf\x8a\xf8\xaf\x8b@~8q\xc7\x1cq\xc7@~\xd 7q\x1d\xc4w\x12@|\xb2I$\x92I%@\x80\x1cI$ \x92I%@\x80J\xe3\x8e8\xe3\x8e@~;^P\xd7\x946@\x80\xb4\xb4\xb4\xb4\xb4\xb5@\x 81\xa7\x89\xd8\x9d\x89\xd9@\x81\x9a\xaa\xaa\xaa\xaa\xab@| \xc9UUUUU@~\xd7\x0f\x0f\x0f\x0f\x0f@\x80l\xa1\xaf(k\xca@| <\xcc\xcc\xcc\xcc\xcd@}\xa0c\xe7\x06>p@z(\x00\x00\x00\x00\x00@zGE\xd1t] \x17@y\xae\xb3\xe4S\x06\xeb@q\xf7\x945\xe5\ry\x00\x00\x00\x1b\x00\x01\x02\x](https://files.speakerdeck.com/presentations/c9571e6caf3644c9a884580bffb7abd9/slide_27.jpg){kind=link}
![Contentment: S3 as Content-Addressed Store In [1]: estimator.to_contentment_hash() Out[1]: ‘sha256.Q5NJ5DVQC…’](https://files.speakerdeck.com/presentations/c9571e6caf3644c9a884580bffb7abd9/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}