How does Elasticsearch work in a resilient and performant way?
This talk is a deep dive into its internals:
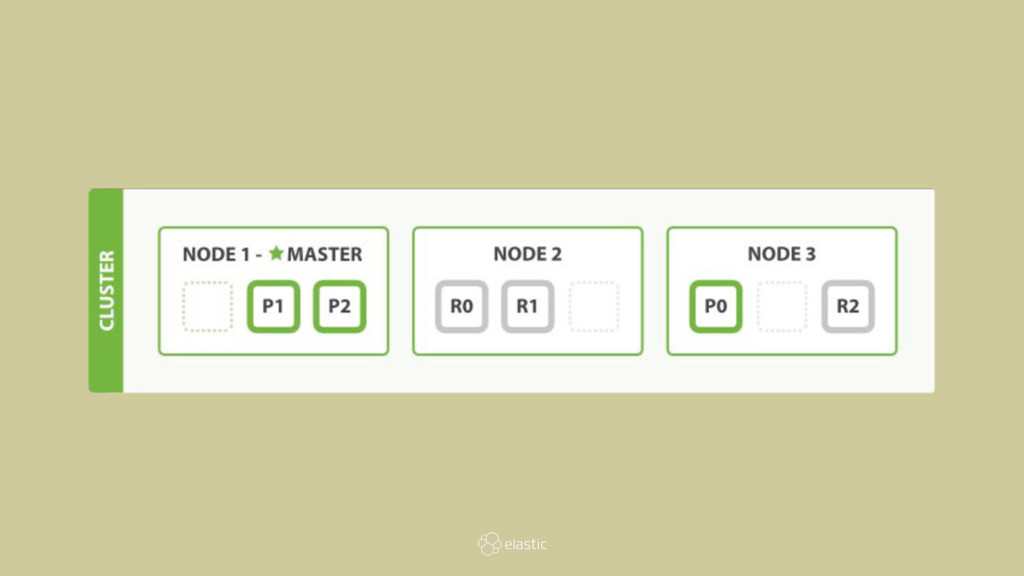
* What are the different node types?
* How is the master node selected?
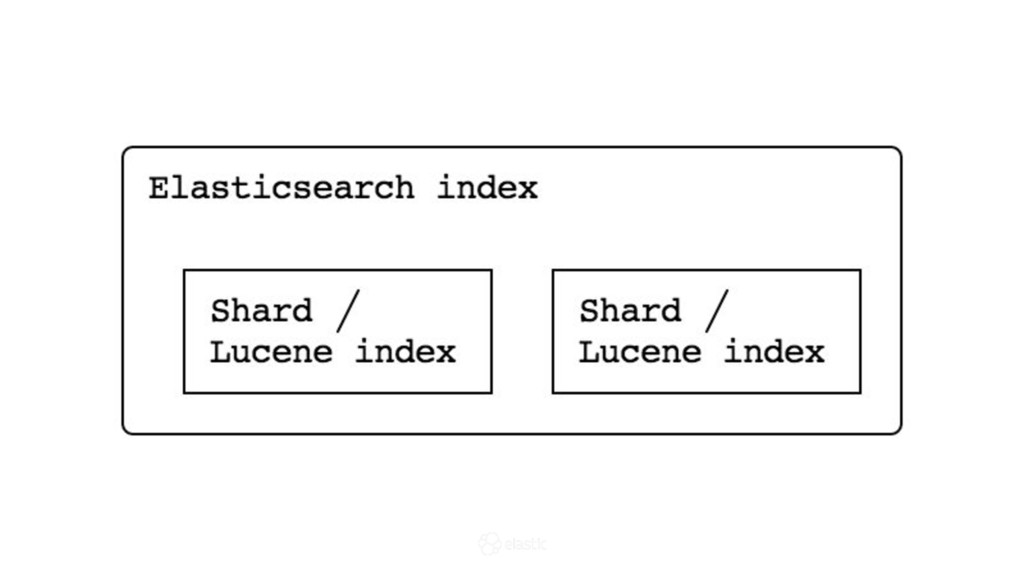
* How are indexes spread over shards and how are they allocated?
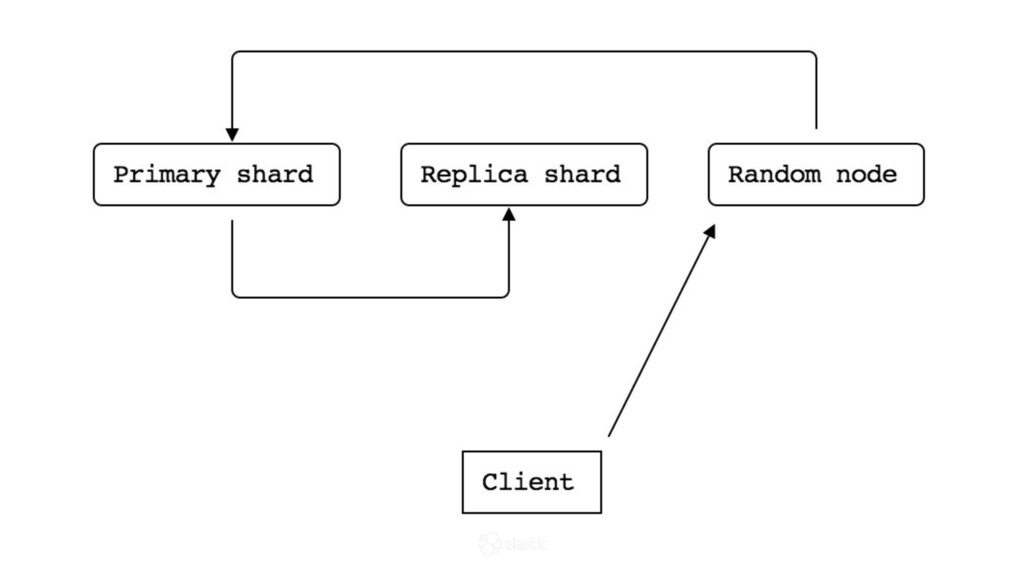
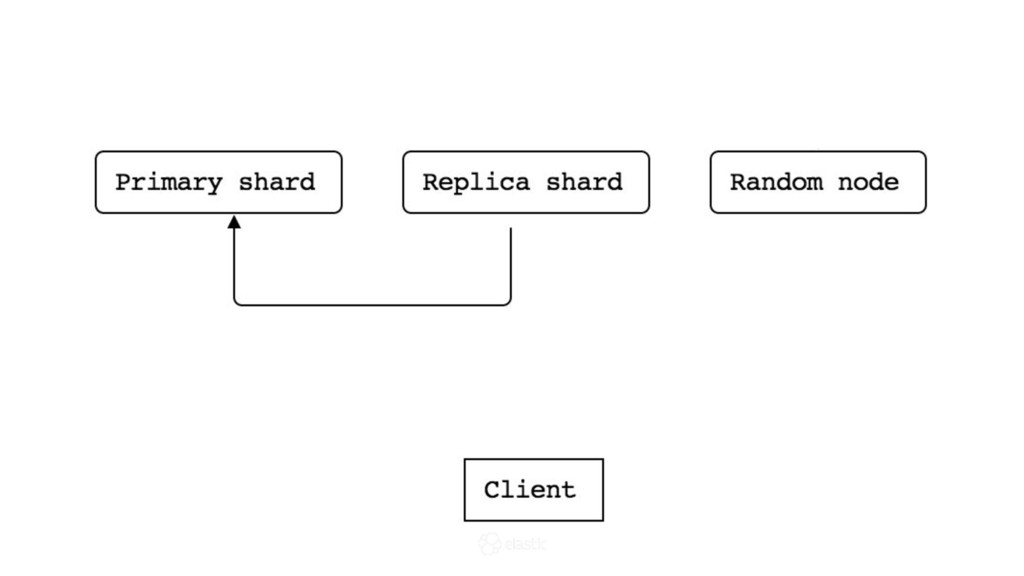
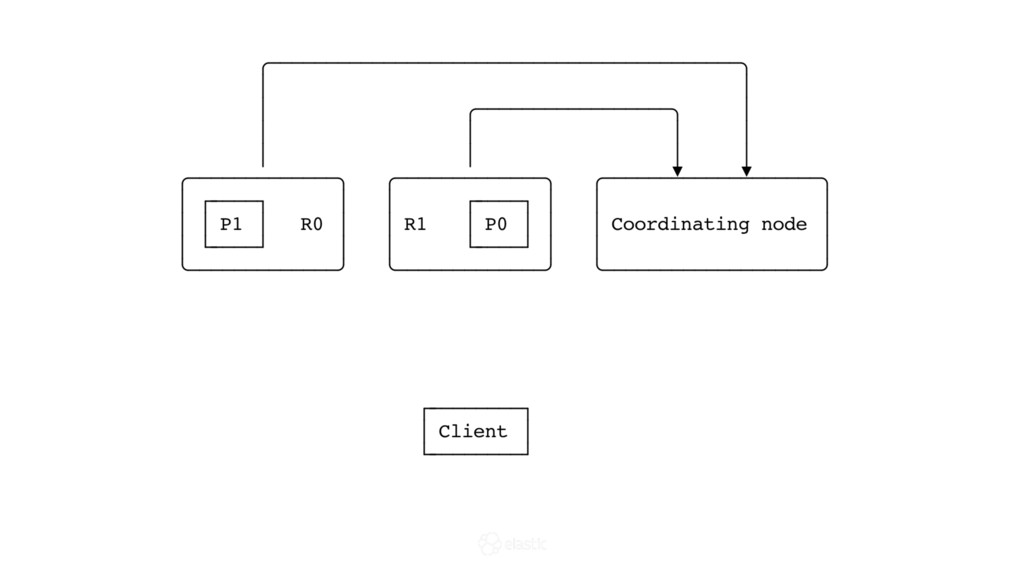
* What is the replication protocol?
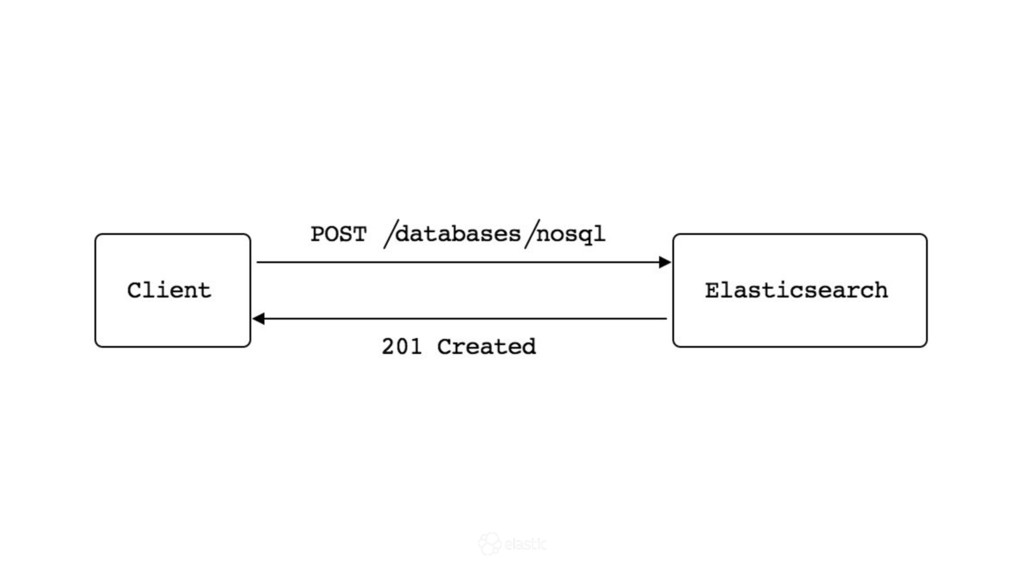
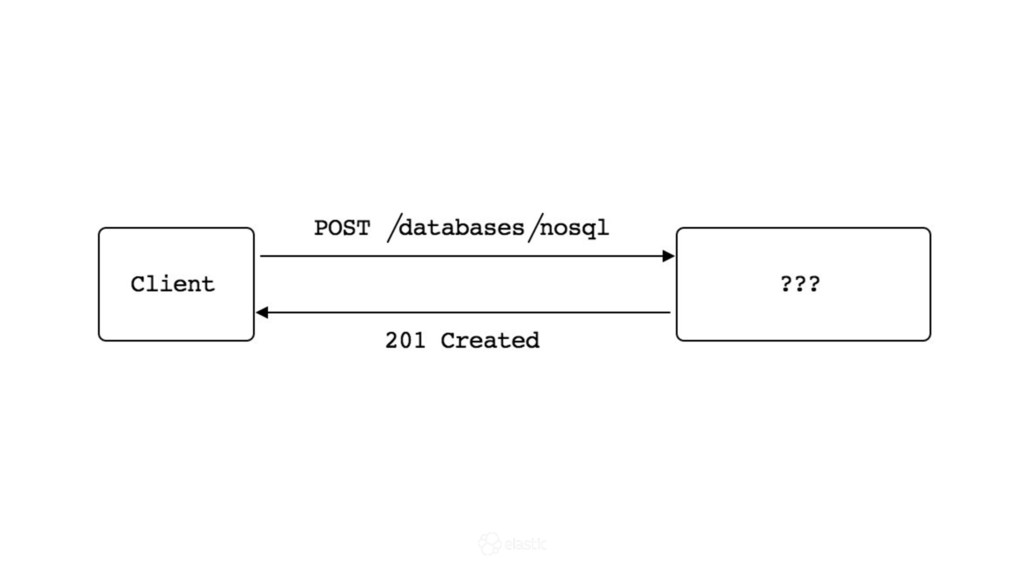
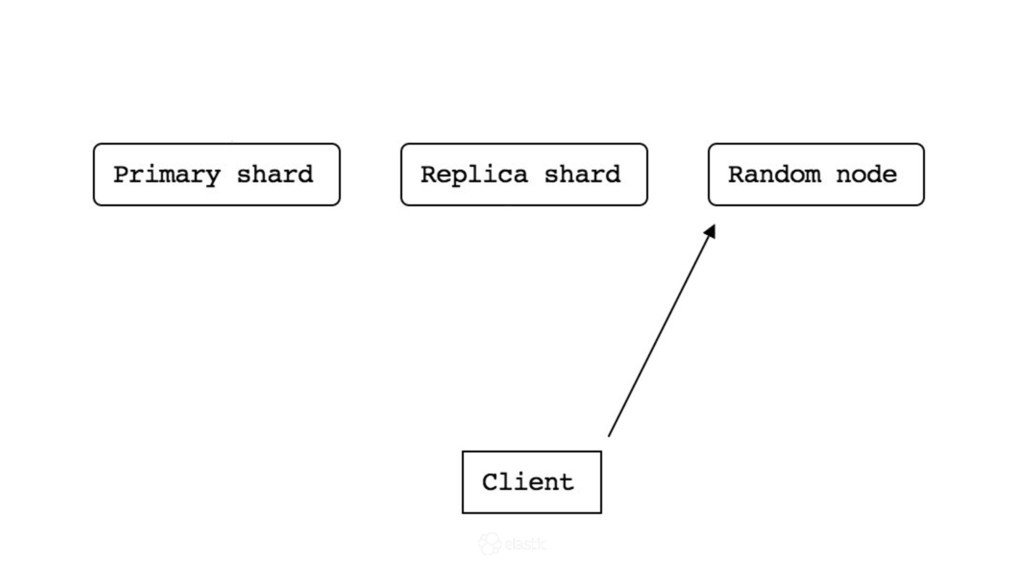
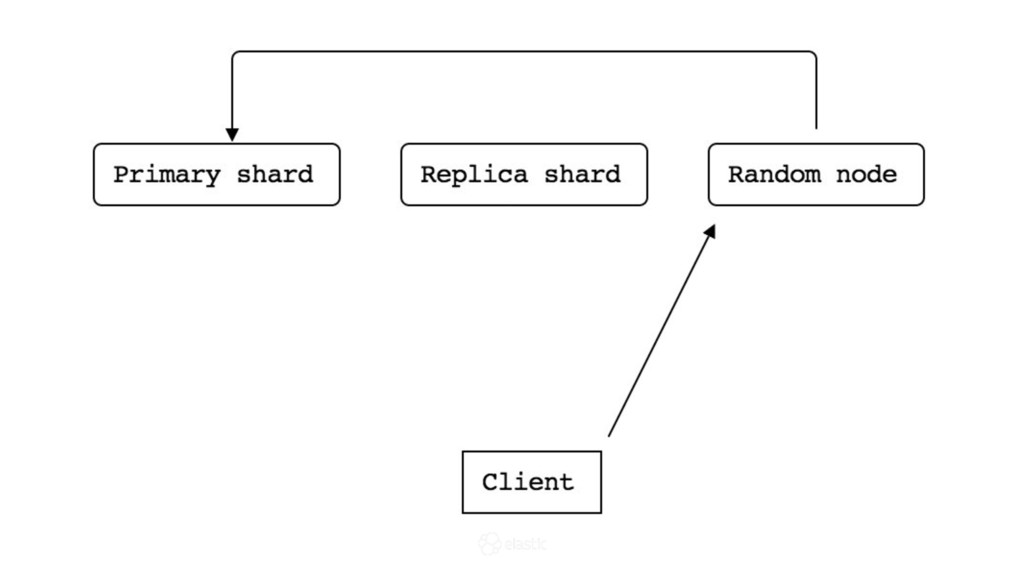
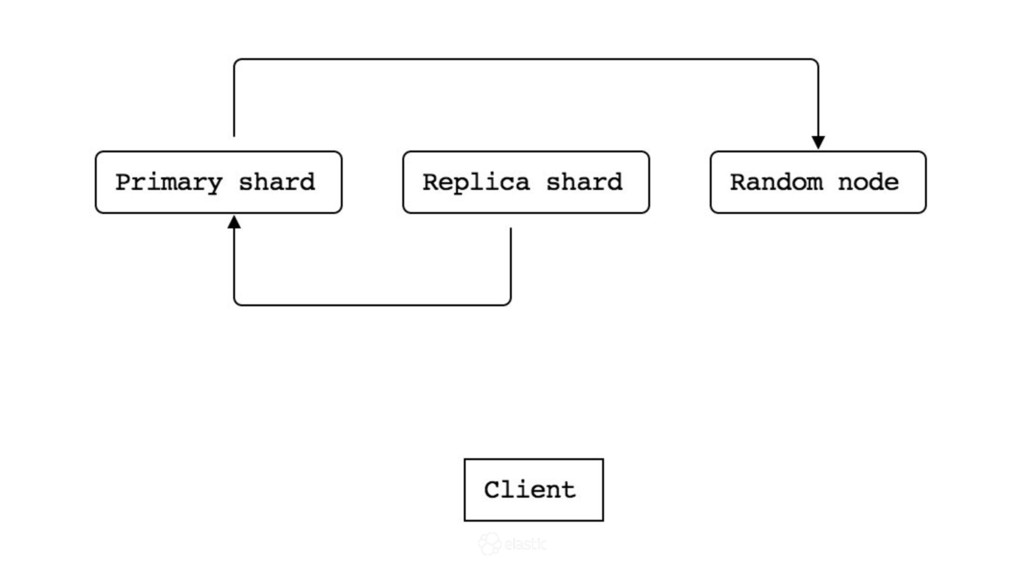
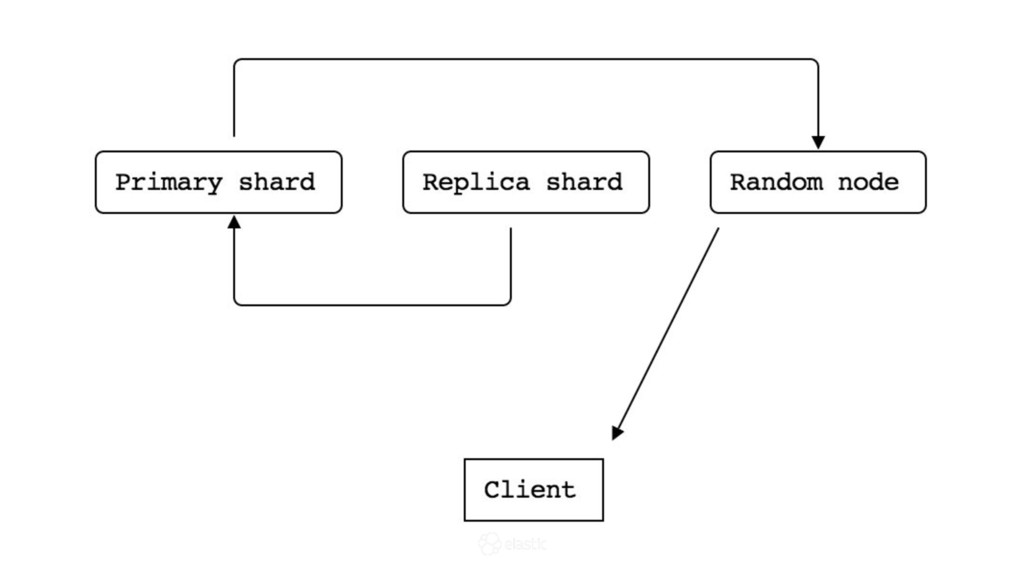
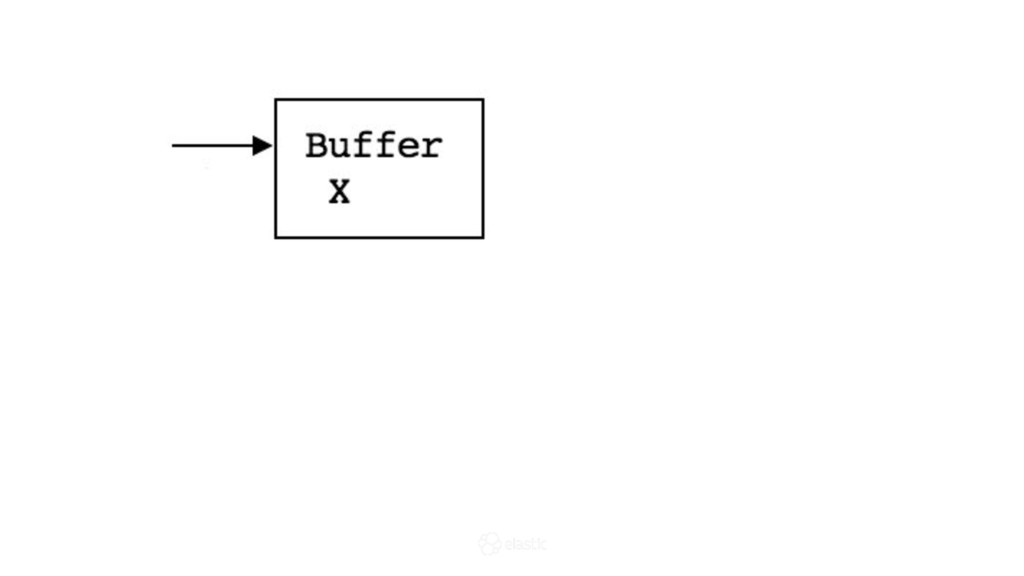
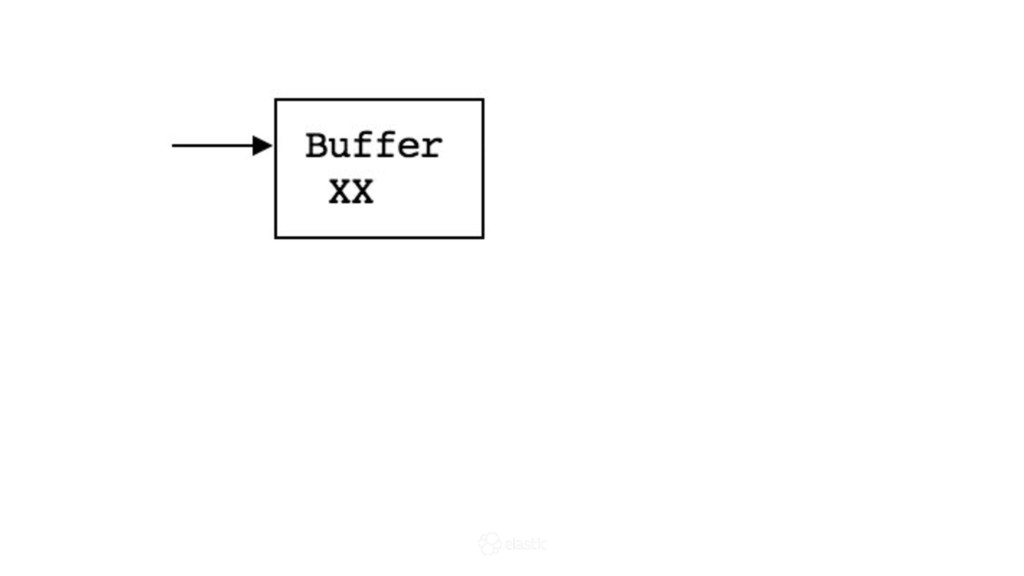
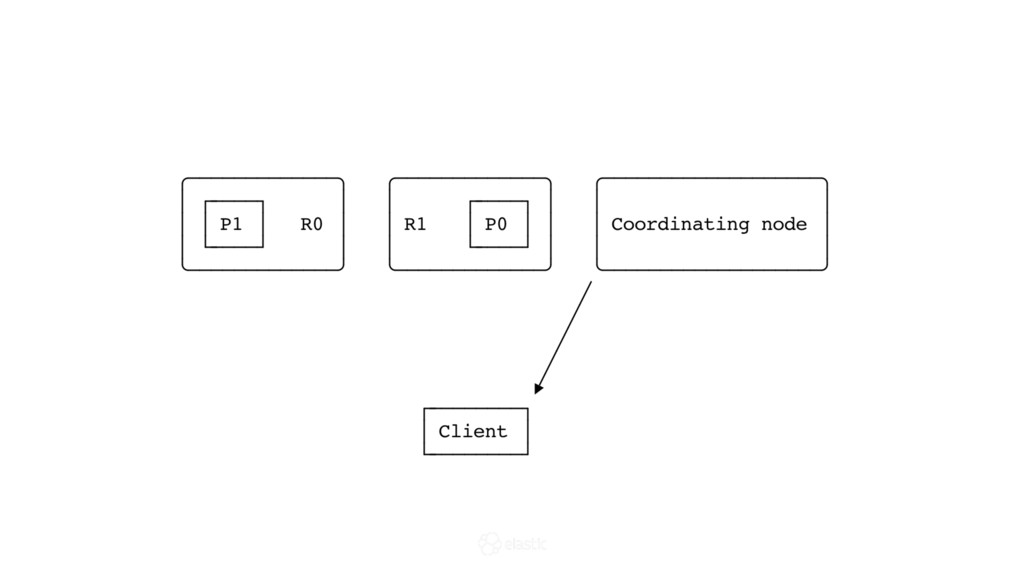
* How is data actually written and queried?
* How are node failures and added nodes handled?
While we will focus on the current implementation, we will also dedicate some time to past and future developments. What has gone wrong and how did we fix it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Consistent hashing 3 shards murmur3 [33185, 33347, 33468] djb2 [30100,](https://files.speakerdeck.com/presentations/e3c59c43201d4ff49bdb10db3263f251/slide_51.jpg){kind=link}
![Consistent hashing 5 shards murmur3 [19933, 19964, 19940, 20030, 20133]](https://files.speakerdeck.com/presentations/e3c59c43201d4ff49bdb10db3263f251/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
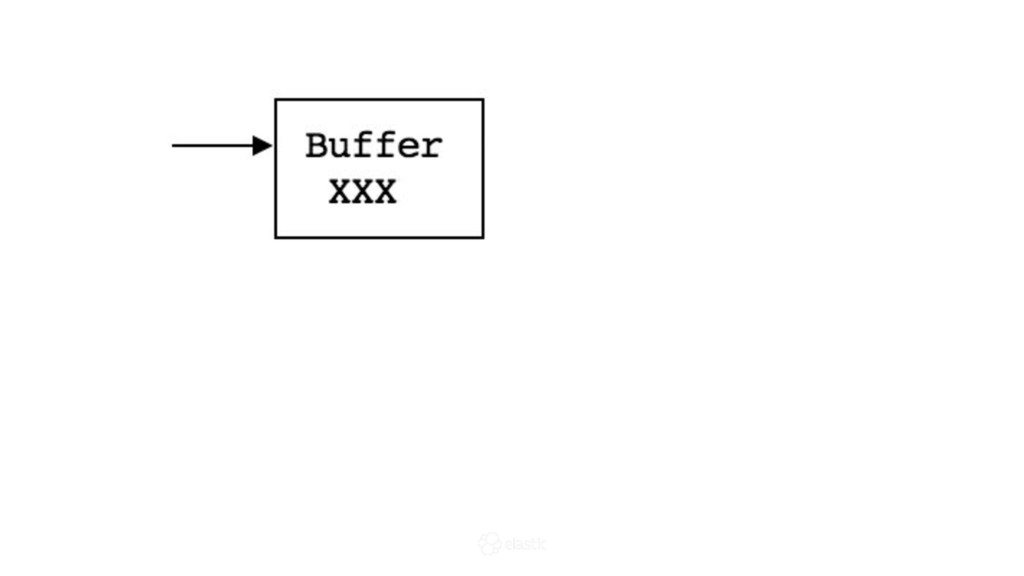{kind=link}
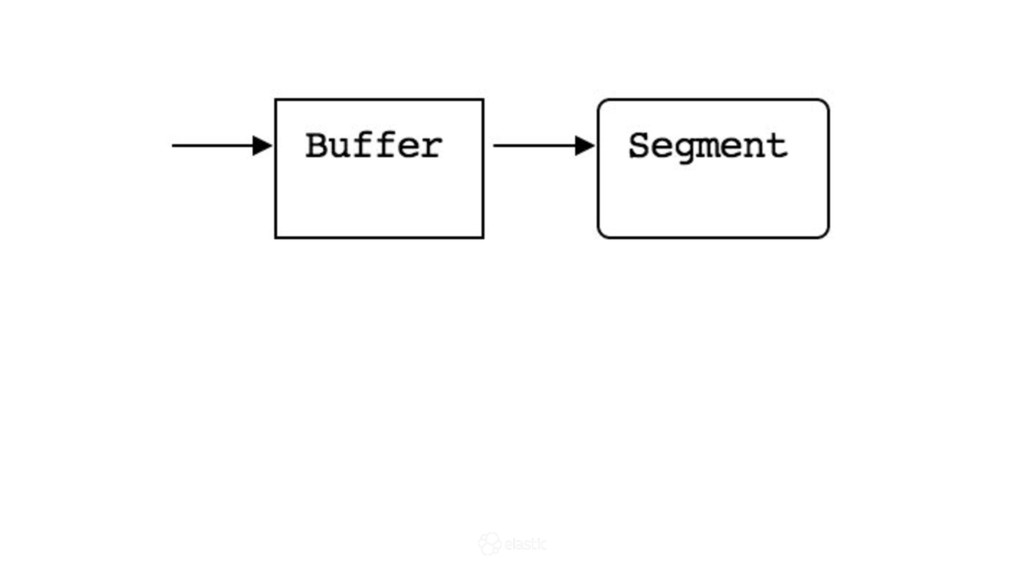{kind=link}
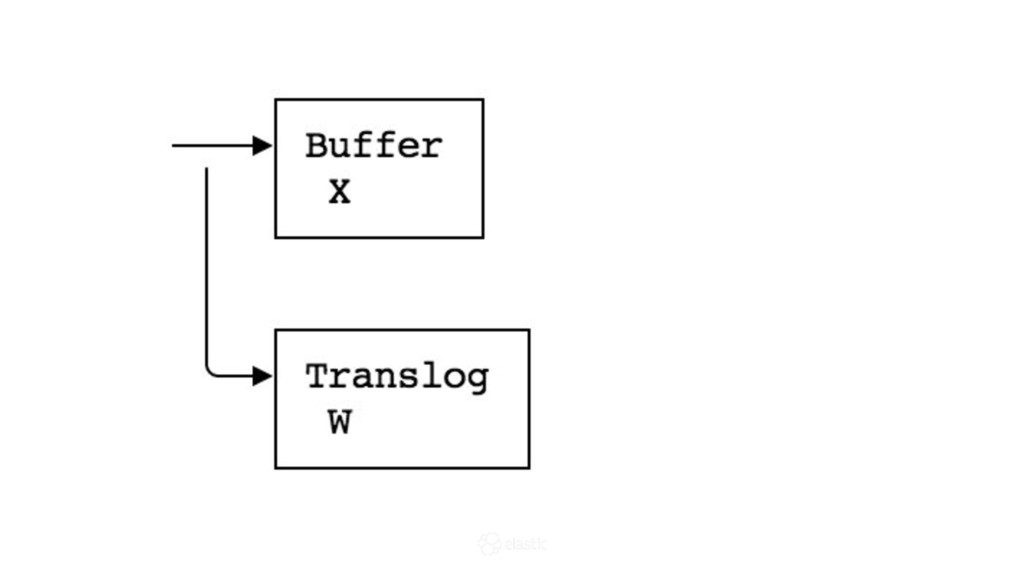{kind=link}
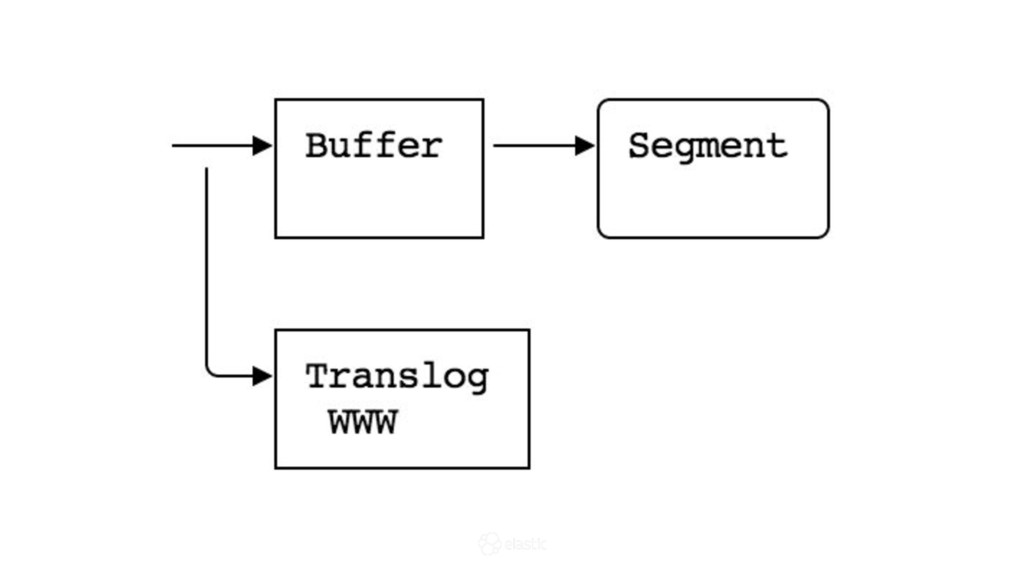{kind=link}
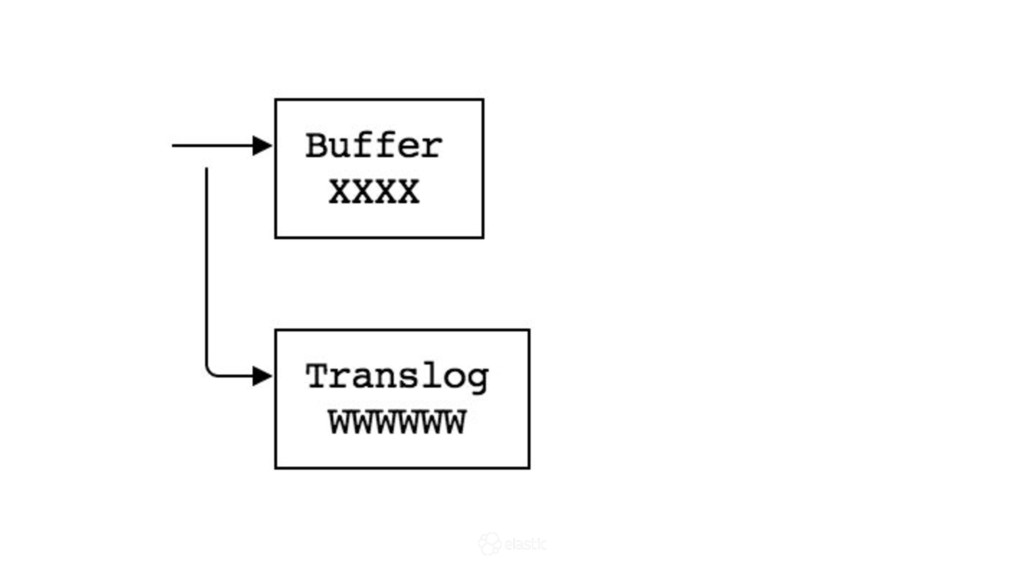{kind=link}
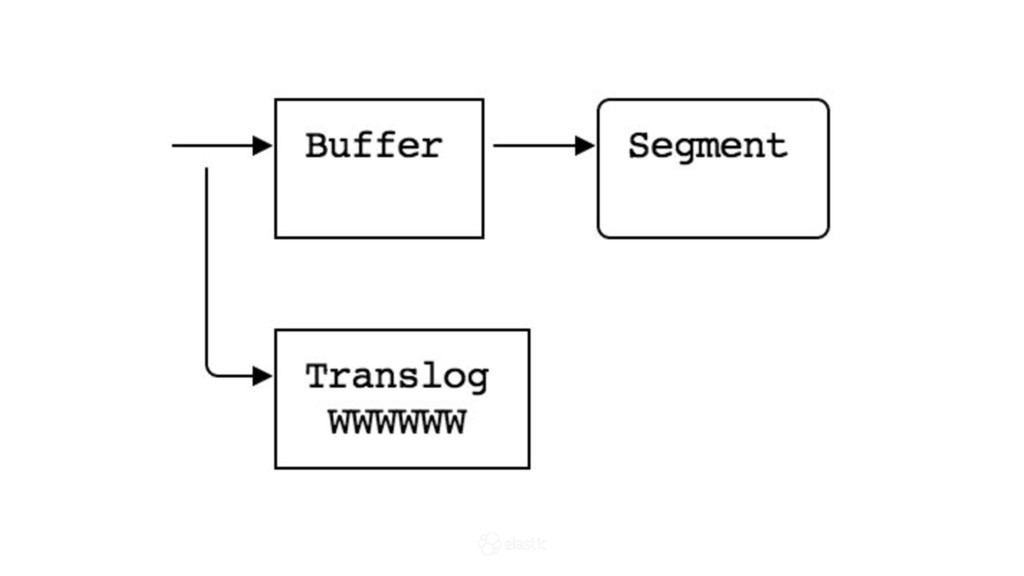{kind=link}
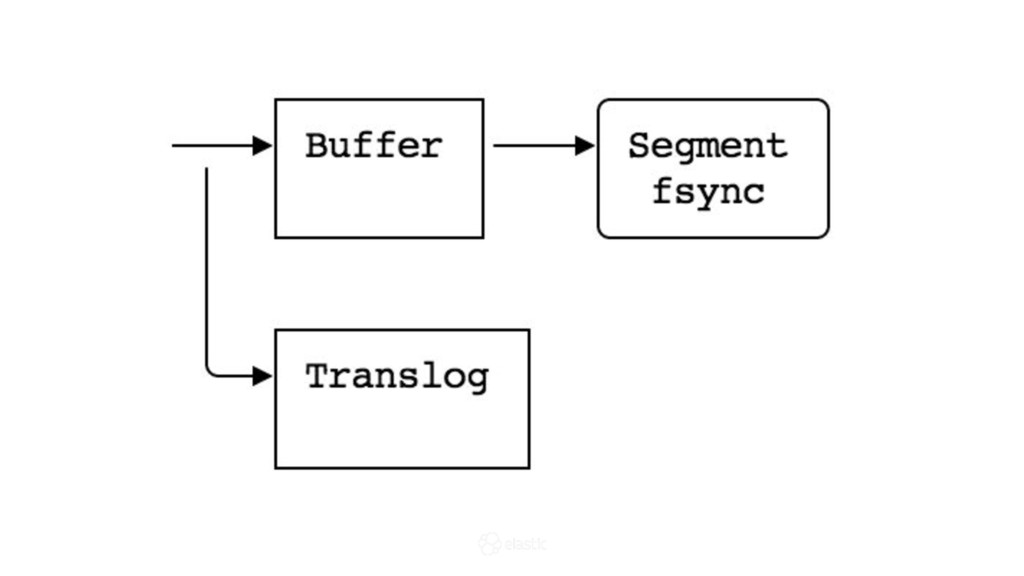{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
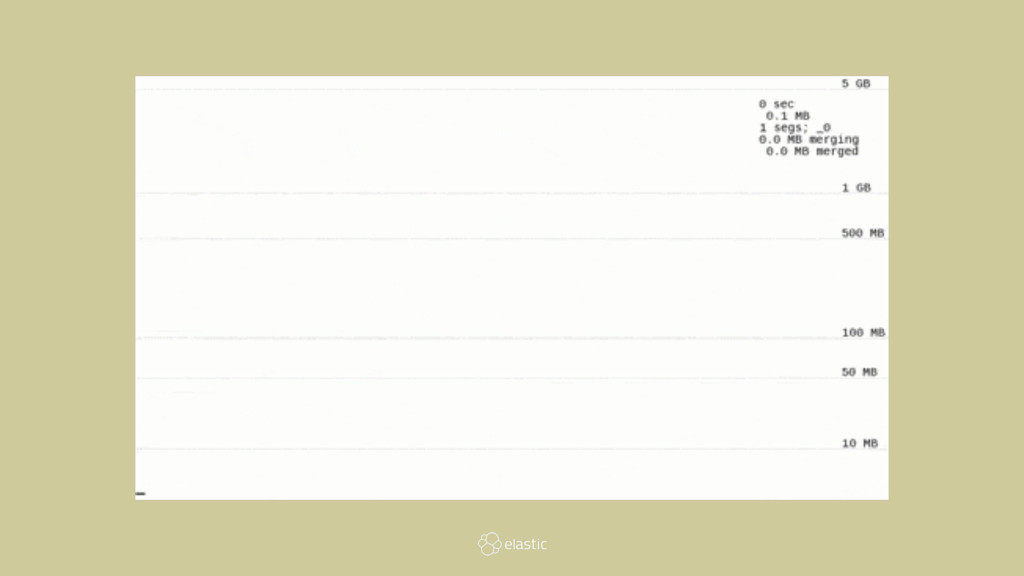{kind=link}
{kind=link}
{kind=link}
{kind=link}
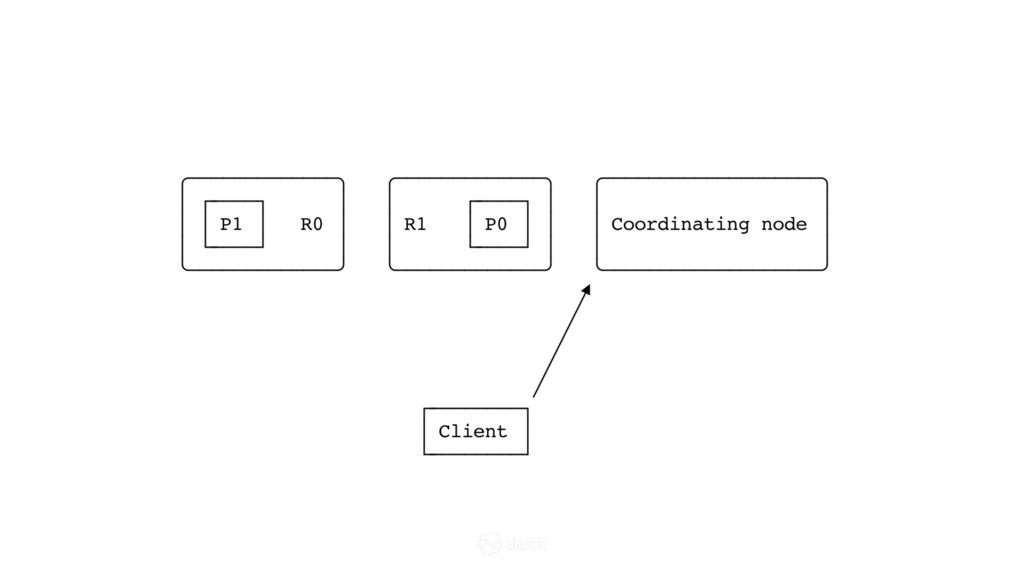{kind=link}
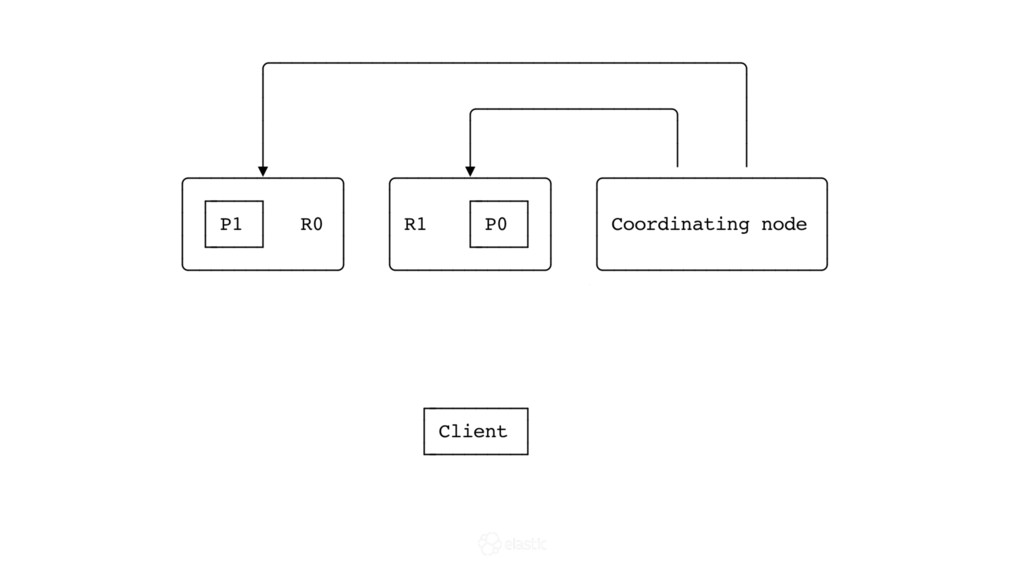{kind=link}
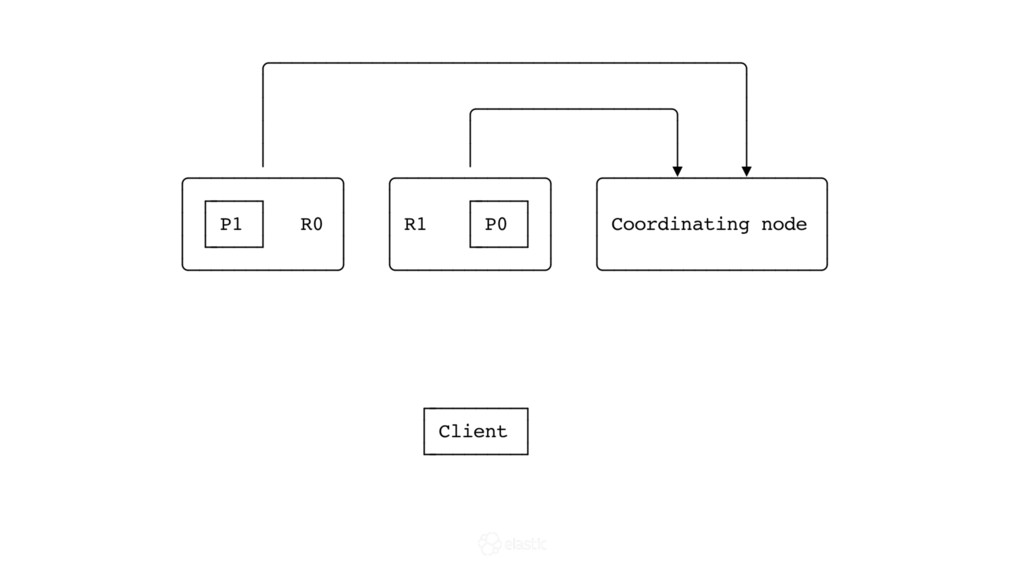{kind=link}
{kind=link}
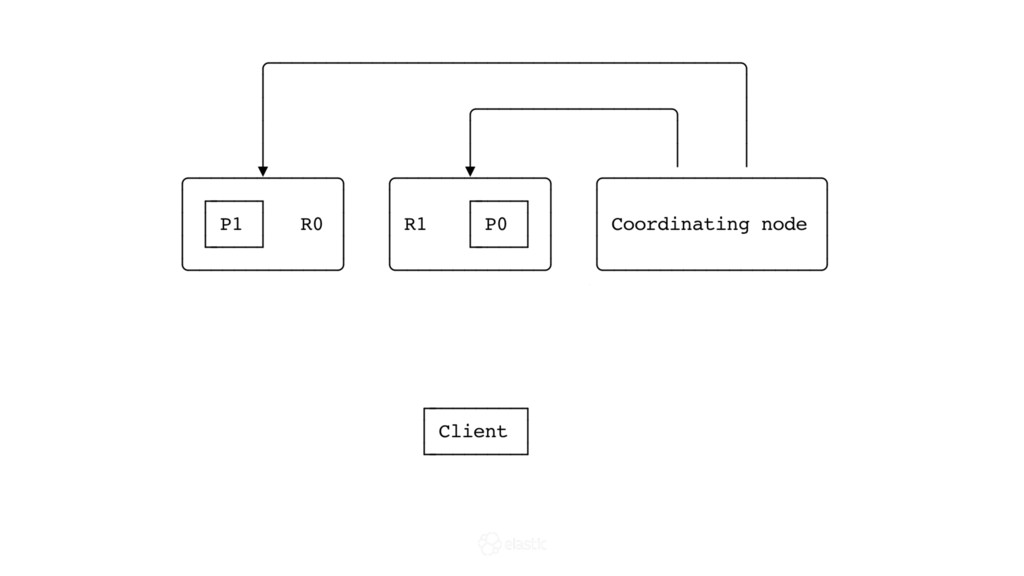{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}