Often based on a common backend (e.g. NumPy) • Poor integration to other systems • CSV is your only resort • „We need to talk!“ • Memory copy is about 10GiB/s • (De-)serialisation comes on top
in fall 2012 by Cloudera & Twitter 3. July 2013: 1.0 release 4. top-level Apache project 5. Fall 2016: Python & C++ support 6. State of the art format in the Hadoop ecosystem • often used as the default I/O option
2. Efficient encodings and compressions —> small size without the need for a fat CPU 3. Predicate push-down —> bring computation to the I/O layer 4. Language independent format —> libs in Java / Scala / C++ / Python /…
More CPU intensive than encoding 3. encoding+compression performs better than compression alone with less CPU cost 4. LZO, Snappy, GZIP, Brotli —> If in doubt: use Snappy 5. GZIP: 174 MiB (11%) Snappy: 216 MiB (14 %)
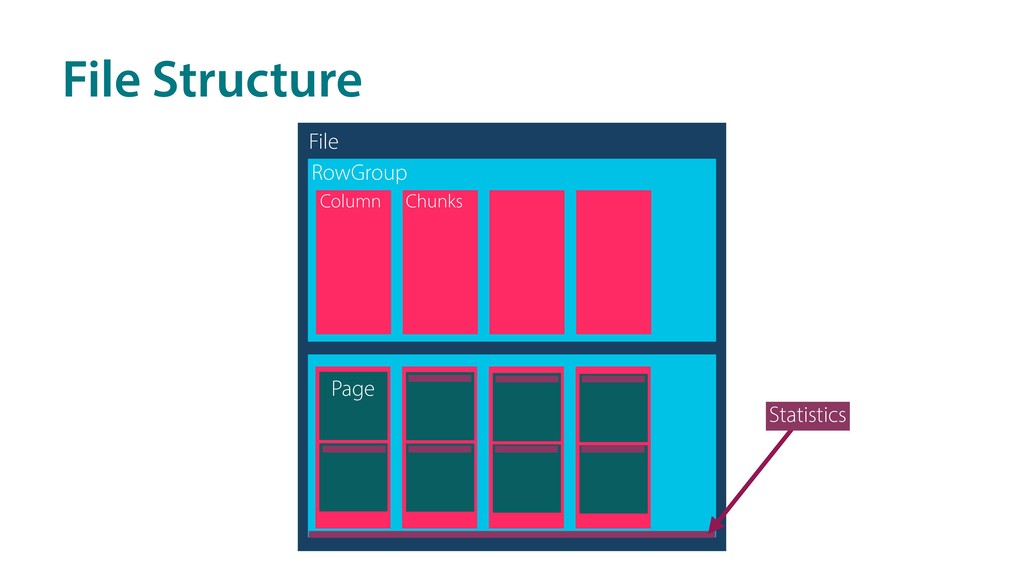
that are not needed • skip (chunks of) rows that not relevant 2. saves I/O load as the data is not transferred 3. saves CPU as the data is not decoded Which products are sold in $?
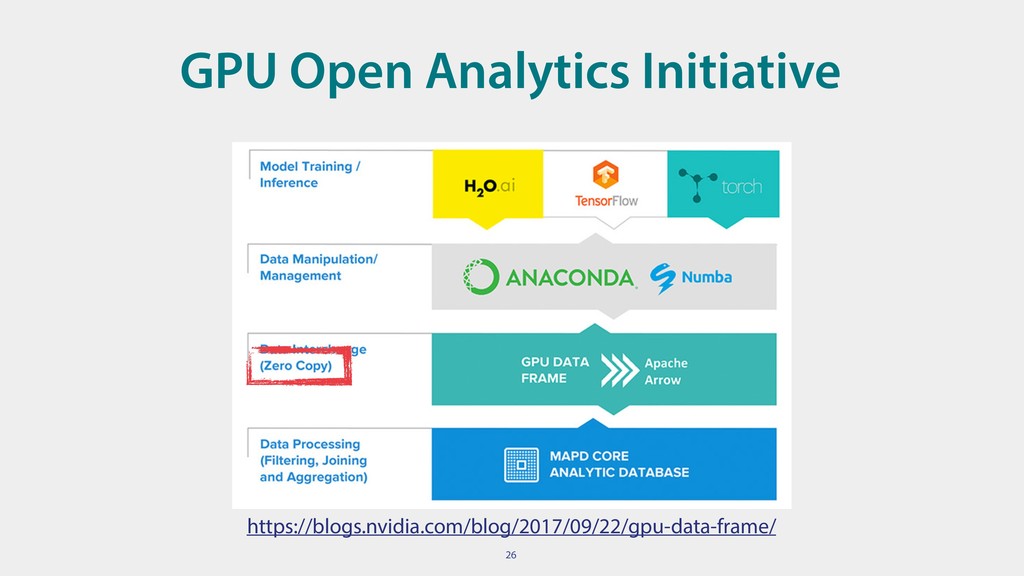
• No overhead for cross-system communication • Designed for efficiency (exploit SIMD, cache locality, ..) • Exchange data without conversion between Python, C++, C(glib), Ruby, Lua, R, JavaScript and the JVM • This brought Parquet to Pandas without any Python code in parquet-cpp
• used in Spark for JVM<->Python • future extensions include: GRPC backend, shared memory communication, … • Columnar in-memory analytics • be the backbone of Pandas 2.0
Retrieve a dataset from an MPP database and analyze it in Pandas 1. Run a query in the DB 2. Pass it in columnar form to the DB driver 3. The OBDC layer transform it into row-wise form 4. Pandas makes it columnar again Ugly real-life solution: export as CSV, bypass ODBC
results 2. Pass them in a columnar fashion to Pandas More systems in the future (without the ODBC overhead) See also Michael’s talk tomorrow: Turbodbc: Turbocharged database access for data scientists Apache Arrow – Real life improvement
383117 0 Blue Yonder Software Limited 19 Eastbourne Terrace London, W2 6LG United Kingdom +44 20 3626 0360 Blue Yonder Best decisions, delivered daily Blue Yonder Analytics, Inc. 5048 Tennyson Parkway Suite 250 Plano, Texas 75024 USA 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cross language DataFrame library • Website: https://arrow.apache.org/ • ML: [email protected]](https://files.speakerdeck.com/presentations/8f191111ae7049449947964e8516d24e/slide_26.jpg){kind=link}
{kind=link}