Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Simply Distributed
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Nugroho Herucahyono
October 22, 2015
Technology
120
0
Share
Simply Distributed
Nugroho Herucahyono
October 22, 2015
More Decks by Nugroho Herucahyono
See All by Nugroho Herucahyono
Choosing the right technology
xinuc
0
180
This Talk is so Meta
xinuc
1
140
A Tale of a Happy Programmer
xinuc
0
160
Rails on Wiradipa - Jakarta.rb Februari 2012 - Hafiz Badrie Lubiz
xinuc
1
170
Why Ruby? - View from business aspect - Jakarta.rb Februari 2012 - Fajrin Rasyid
xinuc
1
360
Other Decks in Technology
See All in Technology
新規事業を牽引する技術選定 〜フルスタックTypeScript開発の実践事例〜
nullnull
2
310
Claude Codeを組織で使いこなす— サーバサイドAIエージェント運用の実践知
techtekt
PRO
0
200
AI Engineering Summit Tokyo 2026 AIの前に、やることがある 〜医療データ企業の4フェーズ〜
dtaniwaki
0
1.7k
個人最適 から 全体最適 へ AI情報共有会・AIギルド・AI-DLC で進める カンリーの組織展開
rfdnxbro
0
1.4k
新規ゲーム開発におけるAI駆動開発のリアル
202409e2
0
2.4k
Unlocking the Apps
pimterry
0
200
Claude code Orchestra
ozakiomumkj
3
940
チームで実践する AI-DLC 思考の軌跡を残すチェックポイント設計
belongadmin
0
2.5k
「速く作る」から「正しく作る」へ ─ 生成AI時代の開発フロー改革の ロードマップと実行 ─
starfish719
0
6.9k
新アーキテクチャ「TiDB X」解説とDedicated比較 TiDB Cloud Premiumのゲーム運用活用を検証
staffrecruiter
0
110
電子辞書Brainをネットに繋げてみた(自力編)
raspython3
0
430
Javaコミュニティをもっと楽しむための9箇条
takasyou
0
1.2k
Featured
See All Featured
Building the Perfect Custom Keyboard
takai
2
780
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
160
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Code Review Best Practice
trishagee
74
20k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
160
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.5k
Done Done
chrislema
186
16k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
940
Large-scale JavaScript Application Architecture
addyosmani
515
110k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Transcript
Simply Distributed KNIF 2015, Bandung
Who? Nugroho Herucahyono @xinuc Programmer @Bukalapak
Keandalan Sistem dalam Mendukung Penyediaan Layanan
“Andal" => reliable & scalable
reliable: fault tolerant scalable: able to grow
How a reliable & scalable system built?
Most systems start small
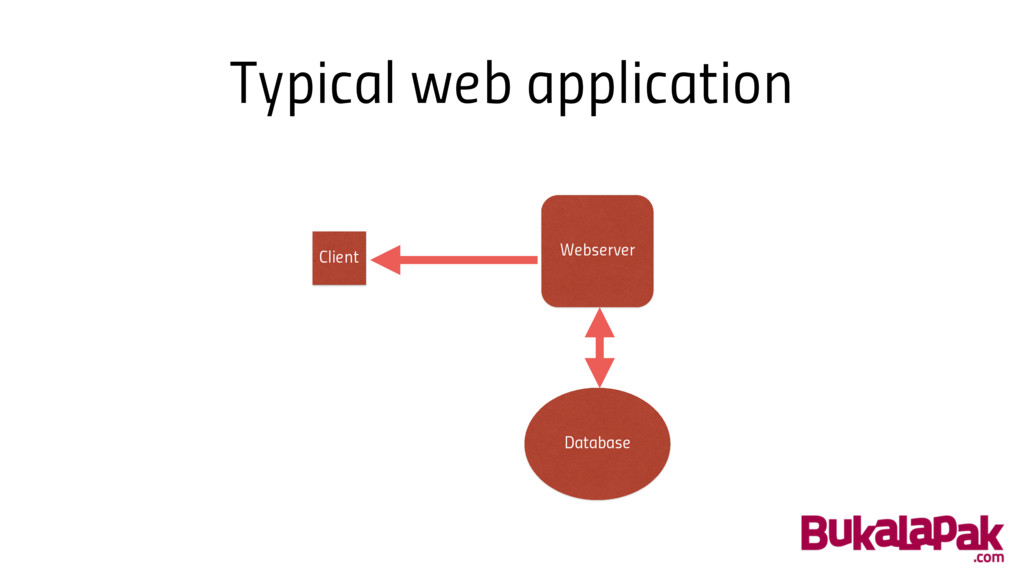
Typical web application Webserver Database Client
Typical web application • Need more features • Serve more
users • Need to be more reliable
More features Add more code Split the system
More users Need to scale machine limitation add more machines
More business value Need more reliable System should be fault
tolerant Self healing Backup, redundancy
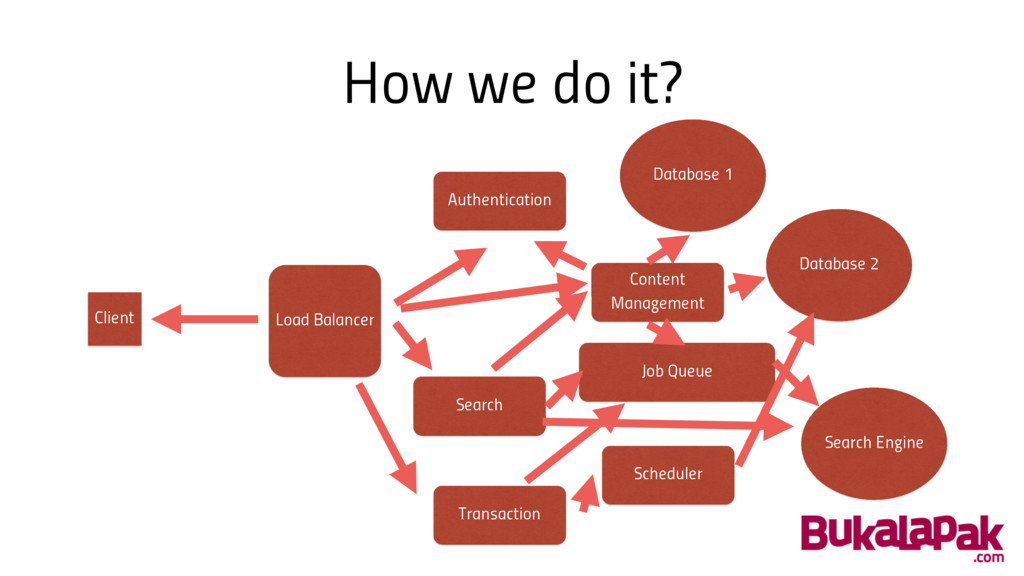
How we do it? Current “Best practice”: • Split system
into smaller services • Communicate with http • Scale independently • Gracefully handle failure
How we do it? Load Balancer Search Engine Client Authentication
Content Management Search Scheduler Transaction Database 2 Database 1 Job Queue
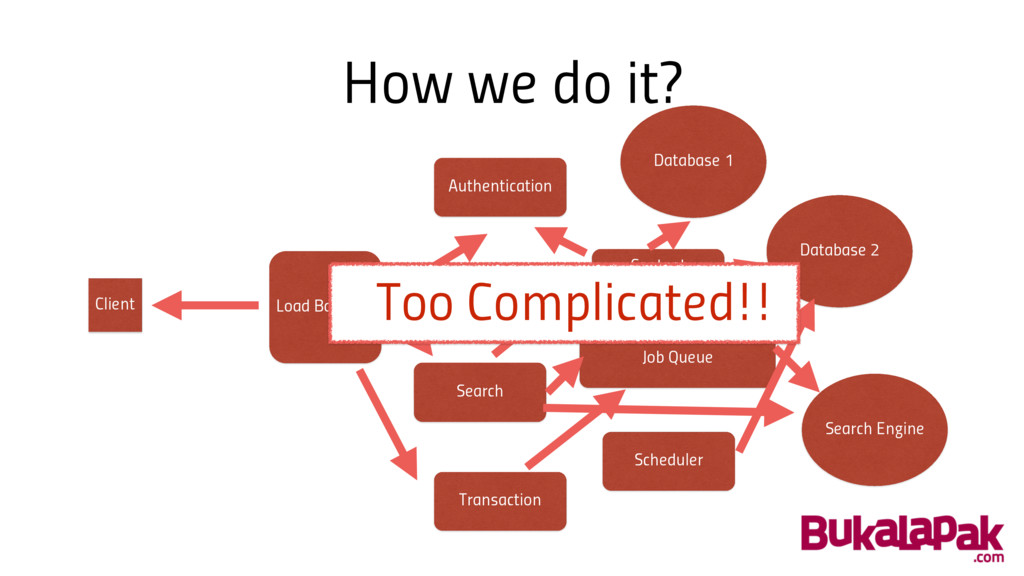
How we do it? Current “Best practice” apparently is not
the best: • Requires massive change to our system • Manual load balancing, replication • Manual resource management • Inefficient communication (http? really?)
How we do it? Load Balancer Search Engine Client Authentication
Content Management Search Scheduler Transaction Database 2 Database 1 Job Queue Too Complicated!!
What would a good computer scientist do?
Introduce a new layer of abstraction!
A new layer of abstraction • Handle resource management •
Handle load balancing • Handle service communication • Handle service failure • Handle replication
A new layer of abstraction We need “Operating System” of
a cluster
A new layer of abstraction Cluster Operating system Operating System
Pod Application Hardware Operating System Pod Application Hardware Operating System Pod Application Hardware
Cluster Operating System • Build in interprocess communication • Build
in monitoring & supervision • Automatic load balancing • Automatic resource management • Scale with little / no system modification
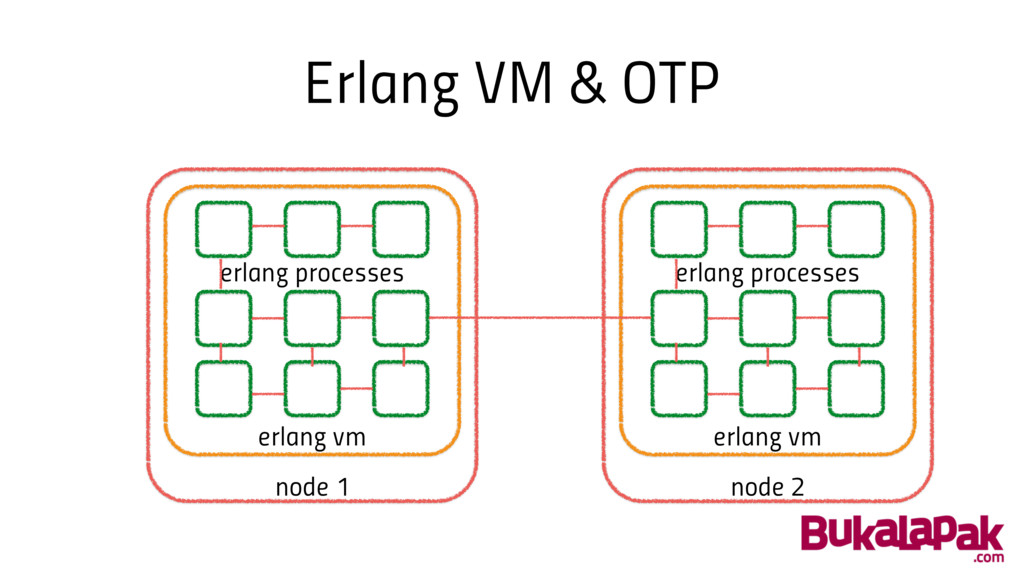
What do we have now? • Erlang VM & OTP
• Docker, Kubernetes
Erlang VM & OTP node 1 erlang vm erlang processes
node 2 erlang vm erlang processes
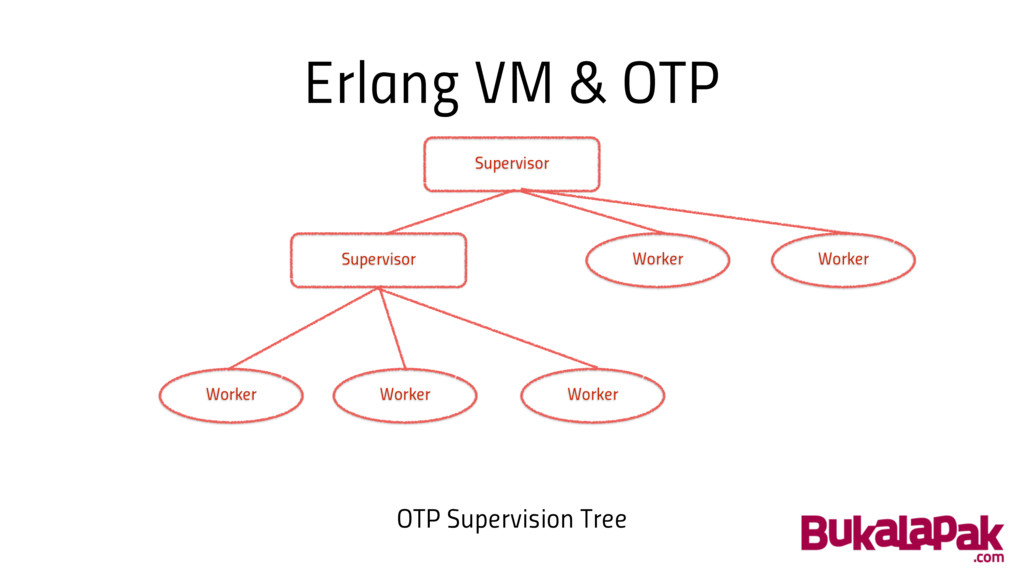
Erlang VM & OTP Supervisor Supervisor Worker Worker Worker Worker
Worker OTP Supervision Tree
Erlang VM & OTP • Build in interprocess communication √
• Build in monitoring & supervision √ • Automatic load balancing X • Automatic resource management X • Scale with little / no system modification √
Erlang VM & OTP • The building block is too
low level? (erlang processes) • Your application need to be written in erlang (or other erlang vm languages)
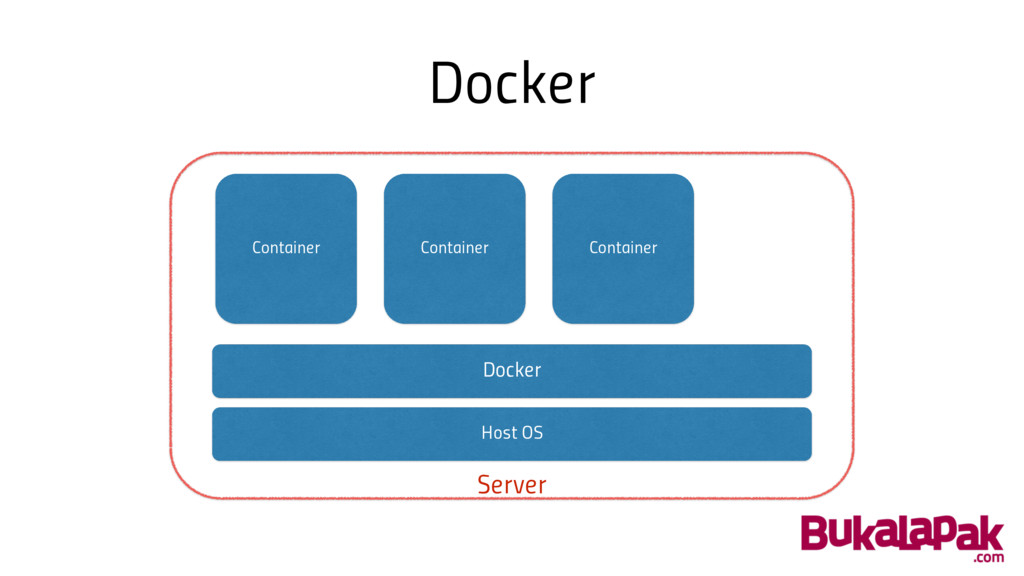
Docker • Like virtual machine, but much lighter • Encapsulate
our application into single “executable” • Remove dependencies, development vs production headache
Docker Host OS Docker Container Container Container Server
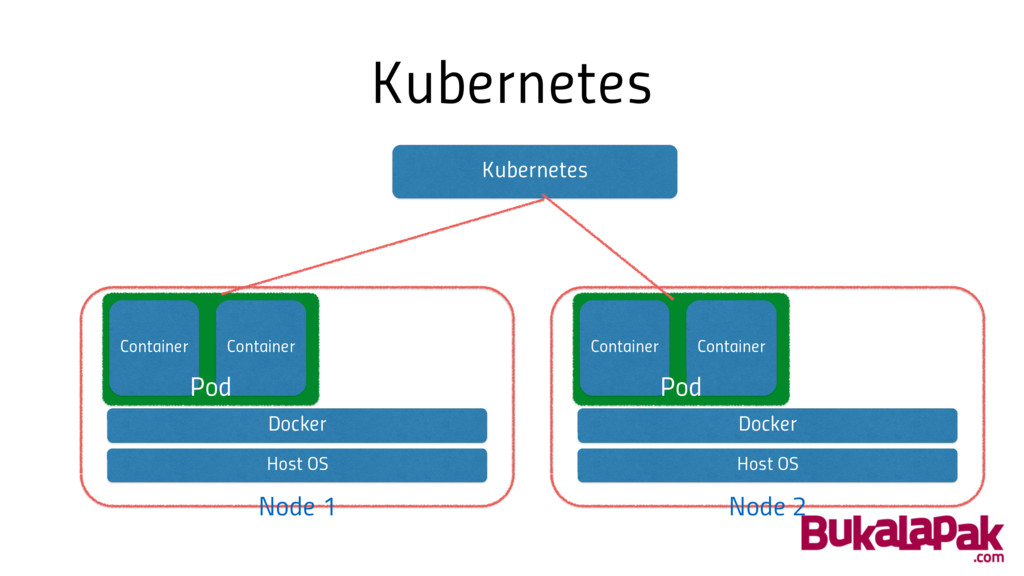
Kubernetes • Manages & monitors containers • Resource allocation between
containers
Kubernetes Host OS Docker Container Container Pod Host OS Docker
Container Container Pod Node 1 Node 2 Kubernetes
Docker & Kubernetes • Build in interprocess communication X •
Build in monitoring & supervision √ • Automatic load balancing √ • Automatic resource management √ • Scale with little / no system modification X
Docker & Kubernetes • No build in interprocess communication •
Still have to modify the system (split into smaller services) • Too complicated
Can we do better?
Let’s zoom out a bit • Service vs Process •
Node vs Core They’re conceptually the same
Maybe we can push down the abstraction layer?
What if, our “Cluster operating system” is a real Operating
System?
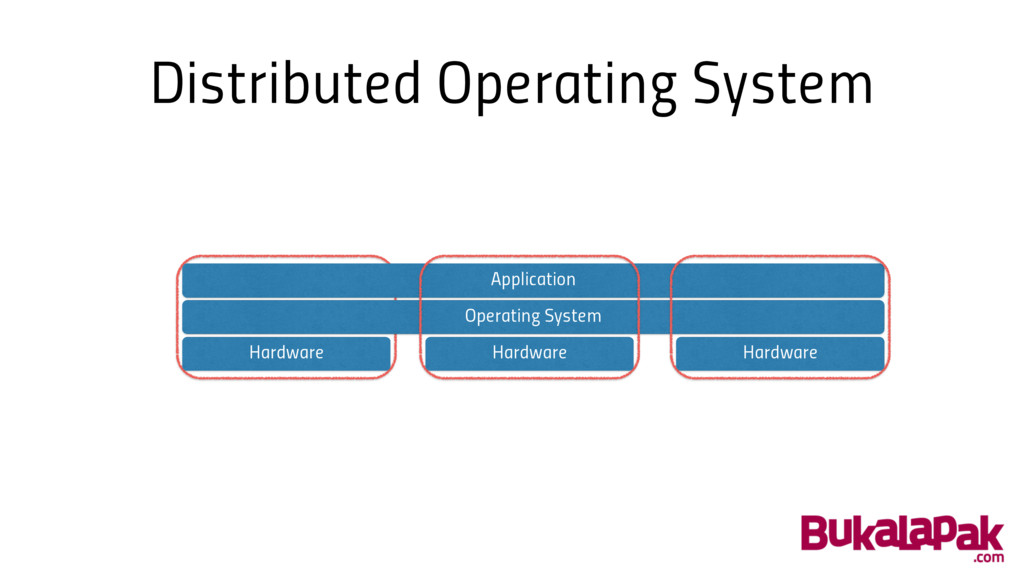
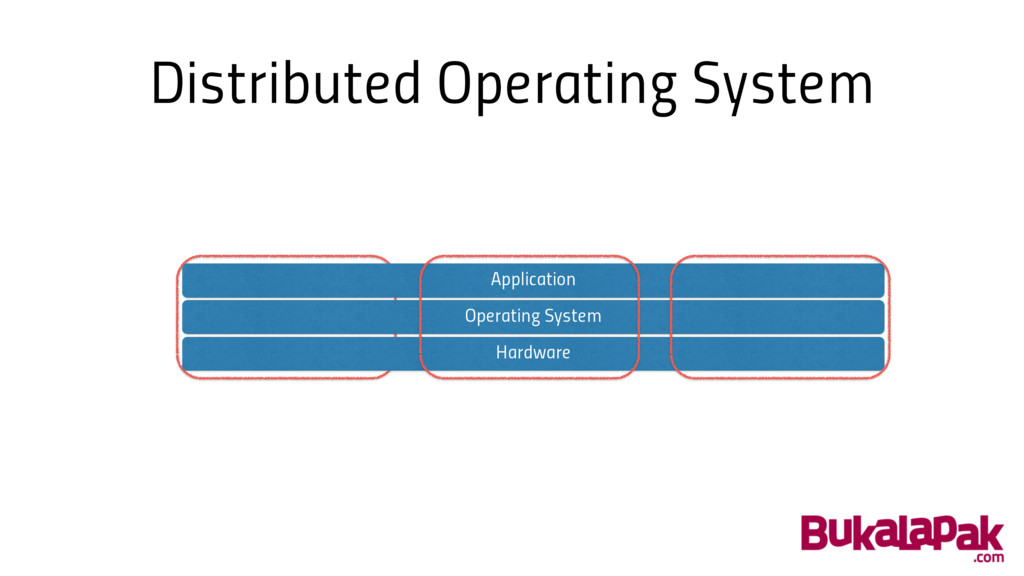
We need a real “Distributed Operating System”
Distributed Operating System Operating System Application Hardware Hardware Hardware
Distributed Operating System • Encapsulate multiple machines as a single
node • Transparent from user / application point of view • Handle load balancing, replication & distribution automatically • Better yet, if we can add more machine on the fly
Is it possible? I have no idea.
We’ve done something similar • Raid • Multiple disk, single
volume • Transparent from applications • Automatic failure handling & replication
We need Raid for CPU & Memory
Or maybe, we can push it down further, to the
hardware level?
We need a real “Distributed Motherboard” :D
Distributed Operating System Operating System Application Hardware
Distributed Motherboard • Node 1, 32 Cores, 32 GB RAM
• Node 2, 32 Cores, 32 GB RAM • Detected by operating system as 1 Node, 64 Cores, 64 GB RAM
Distributed Motherboard • We can add more node, on the
fly • Motherboard will communicate between each other • Abstract their resources as a SINGLE NODE
Again, is it possible? I have no idea.
We’ve done that too • Hardware Raid Controller • Multiple
Disk, detected as a single hardware • Transparent from operating system & application
Too much wishful thinking?
Why does it matter?
Why does it matter? Scalable & Reliable system is a
SOLVED problem We already have Google, Facebook, etc as a prove
Why does it matter? • Scalable & Reliable system is
not easy & cheap • Need a group of highly skilled experts to build
Case Study: WhatsApp
Case Study: WhatsApp • WhatsApp use Erlang VM & OTP
• They can scale it without adding too much complexity
Case Study: WhatsApp
Case Study: WhatsApp We need more companies like WhatsApp
Small Startups? Can 4-fresh-graduate startup create a product used by
a billion users?
Non profits? Can we create non profit system than serve
billons of users?
./bukalapak
more research on this, please :)
Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}