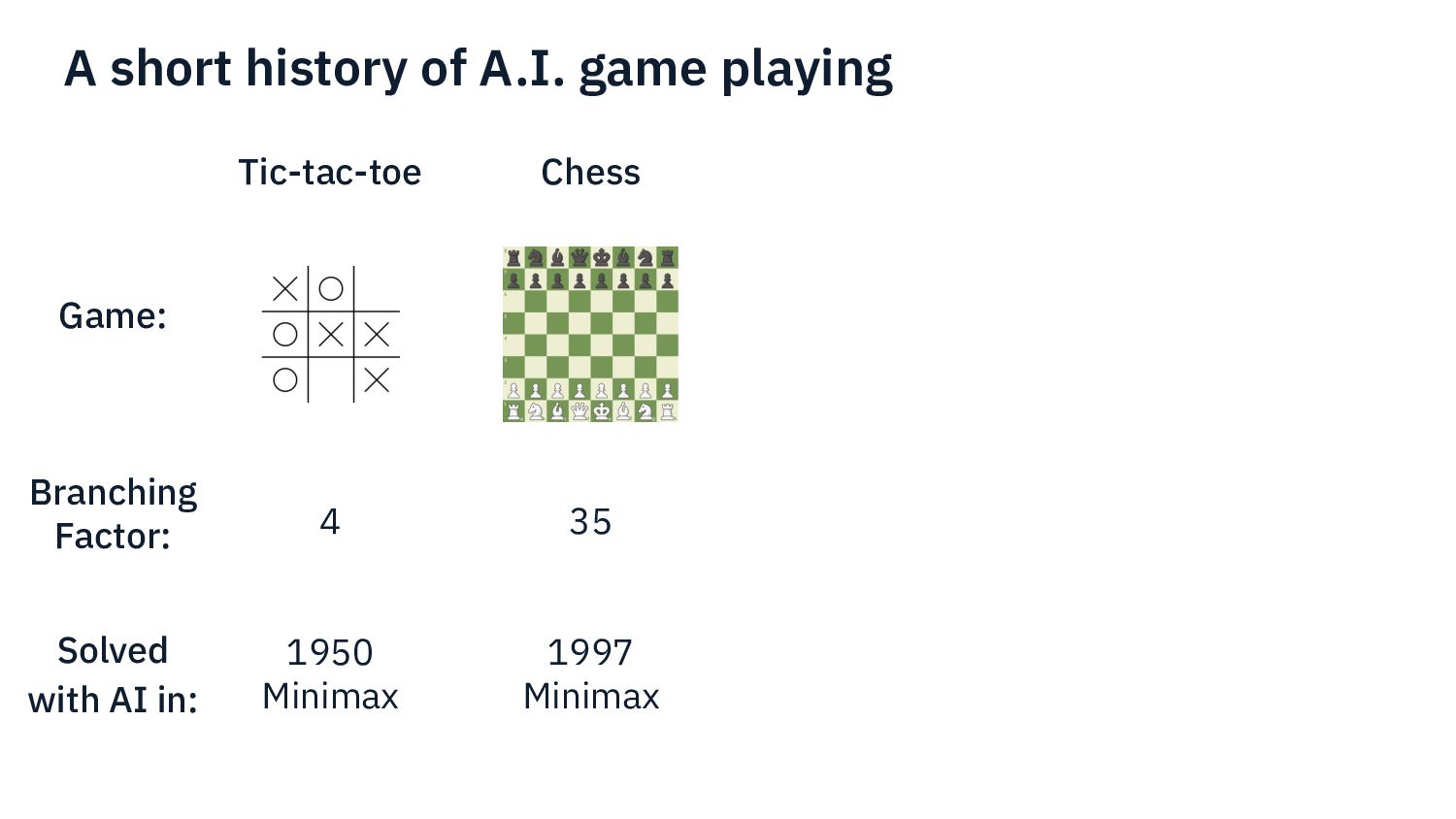
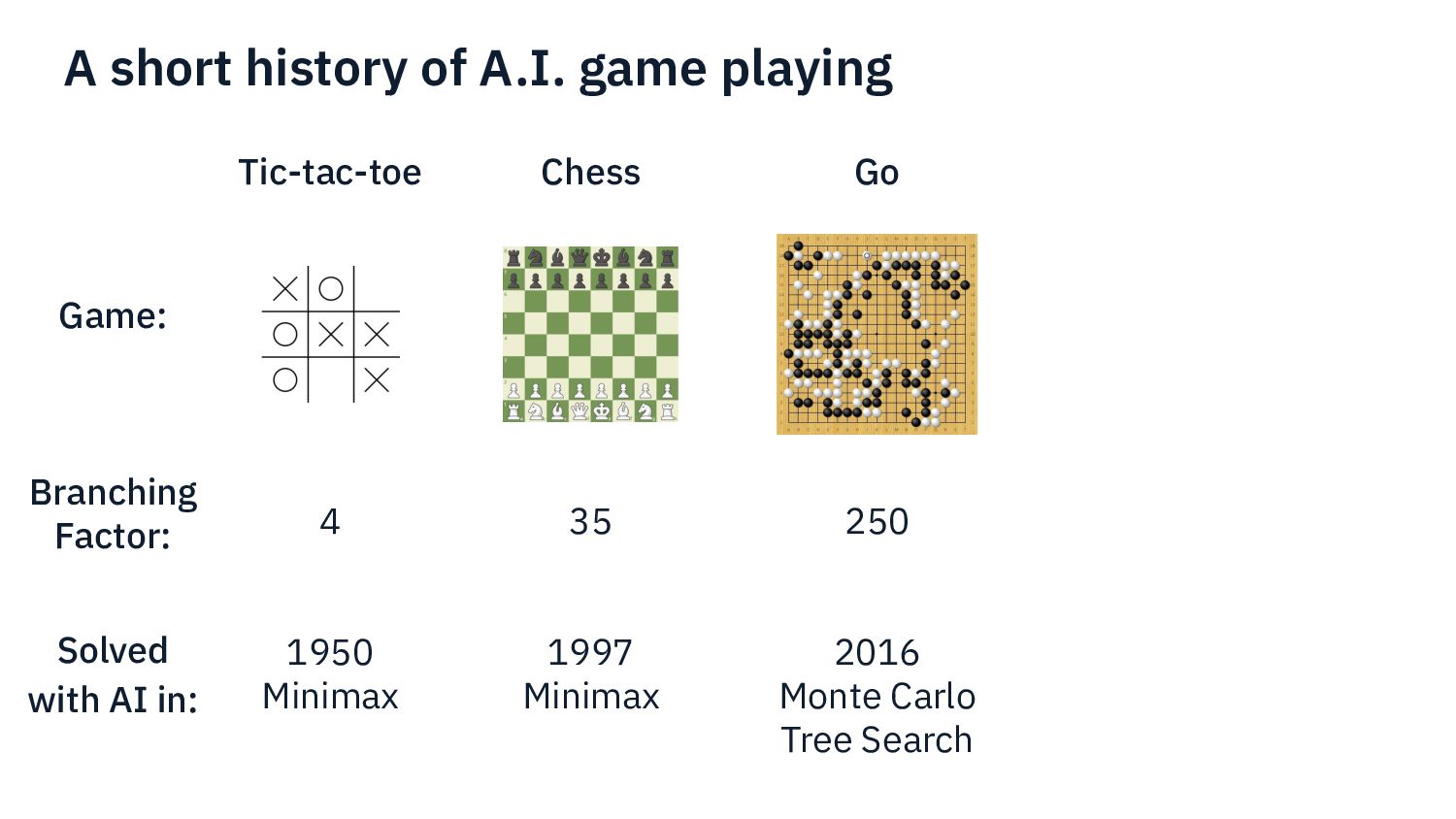
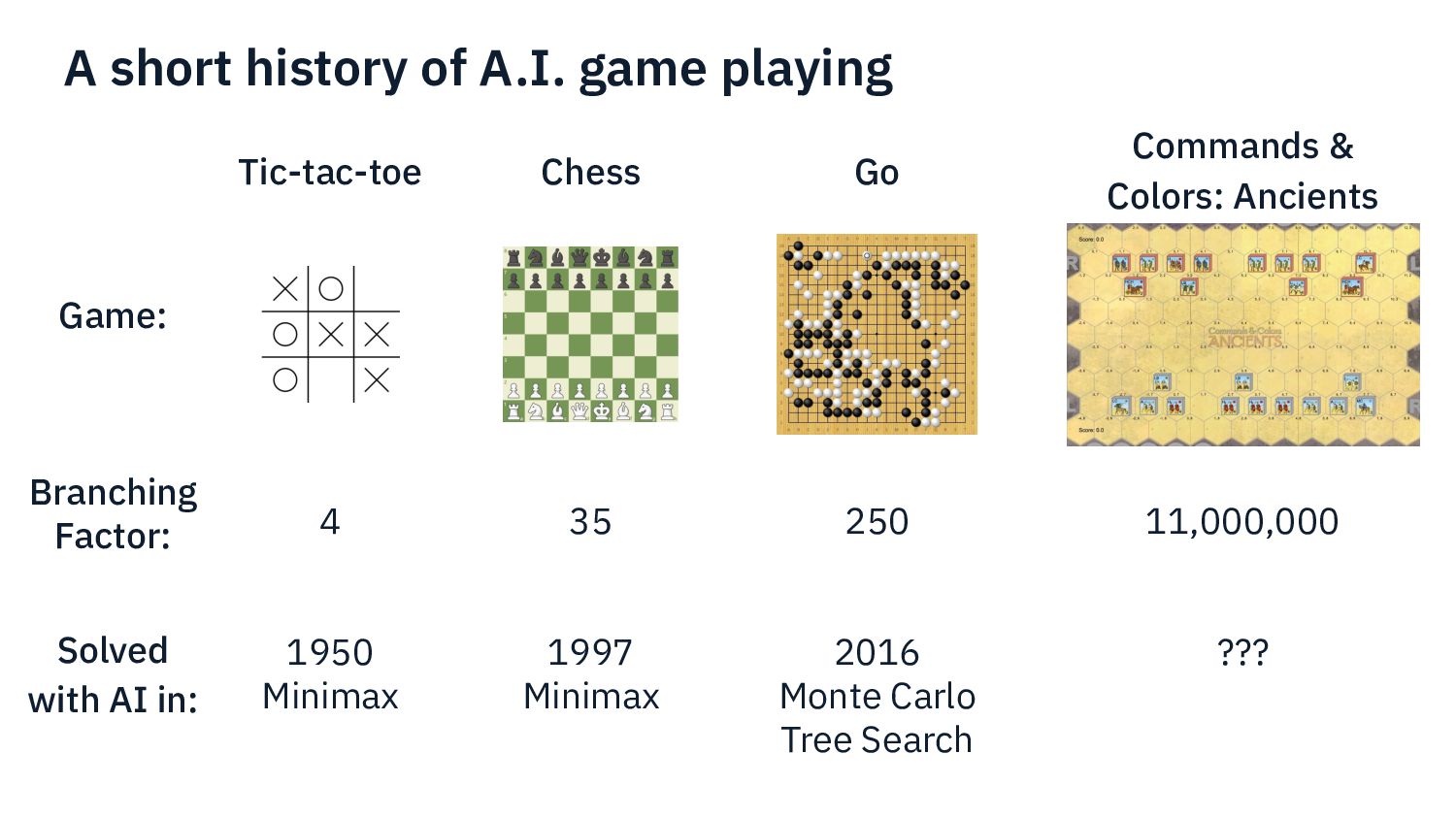
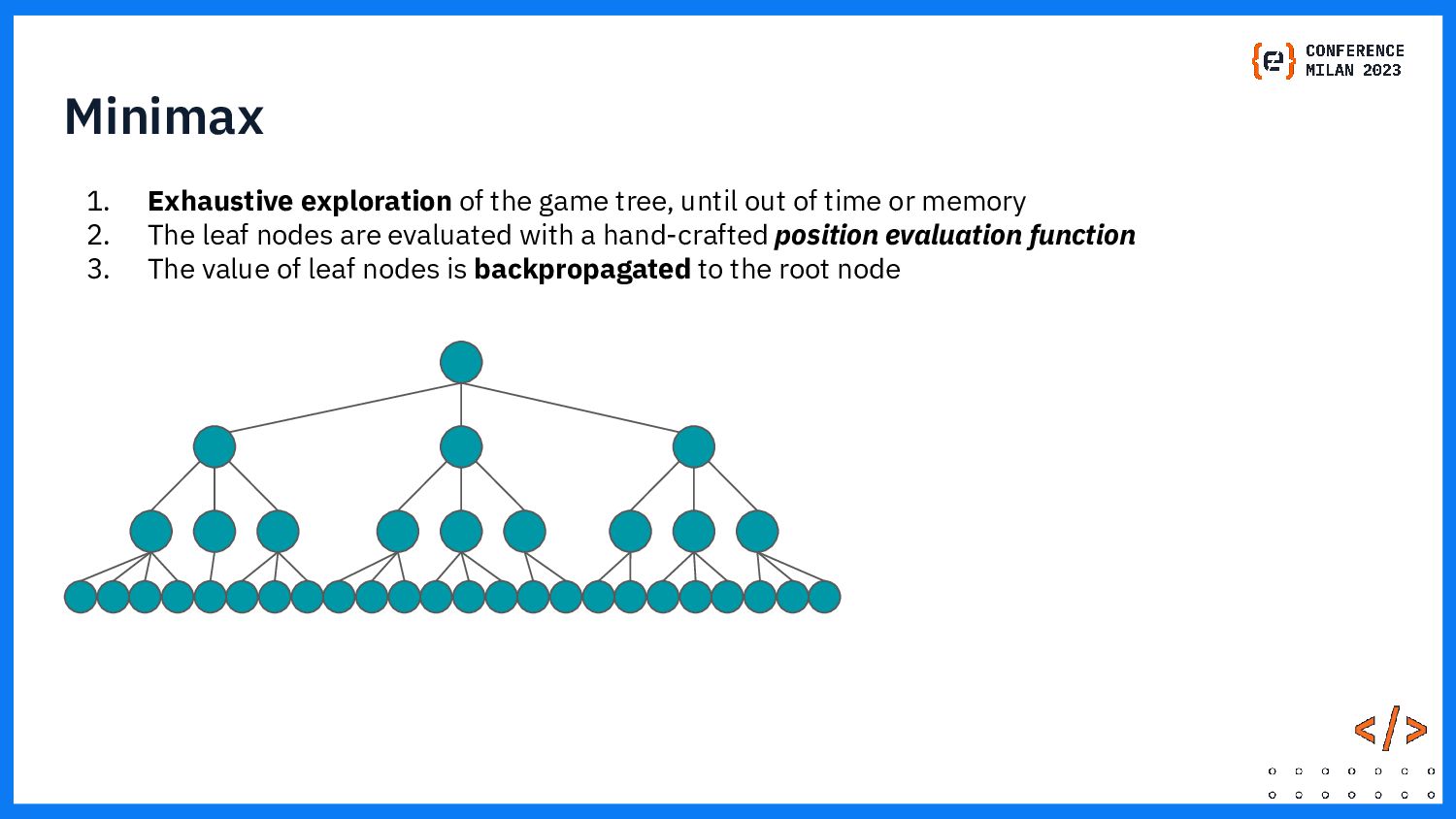
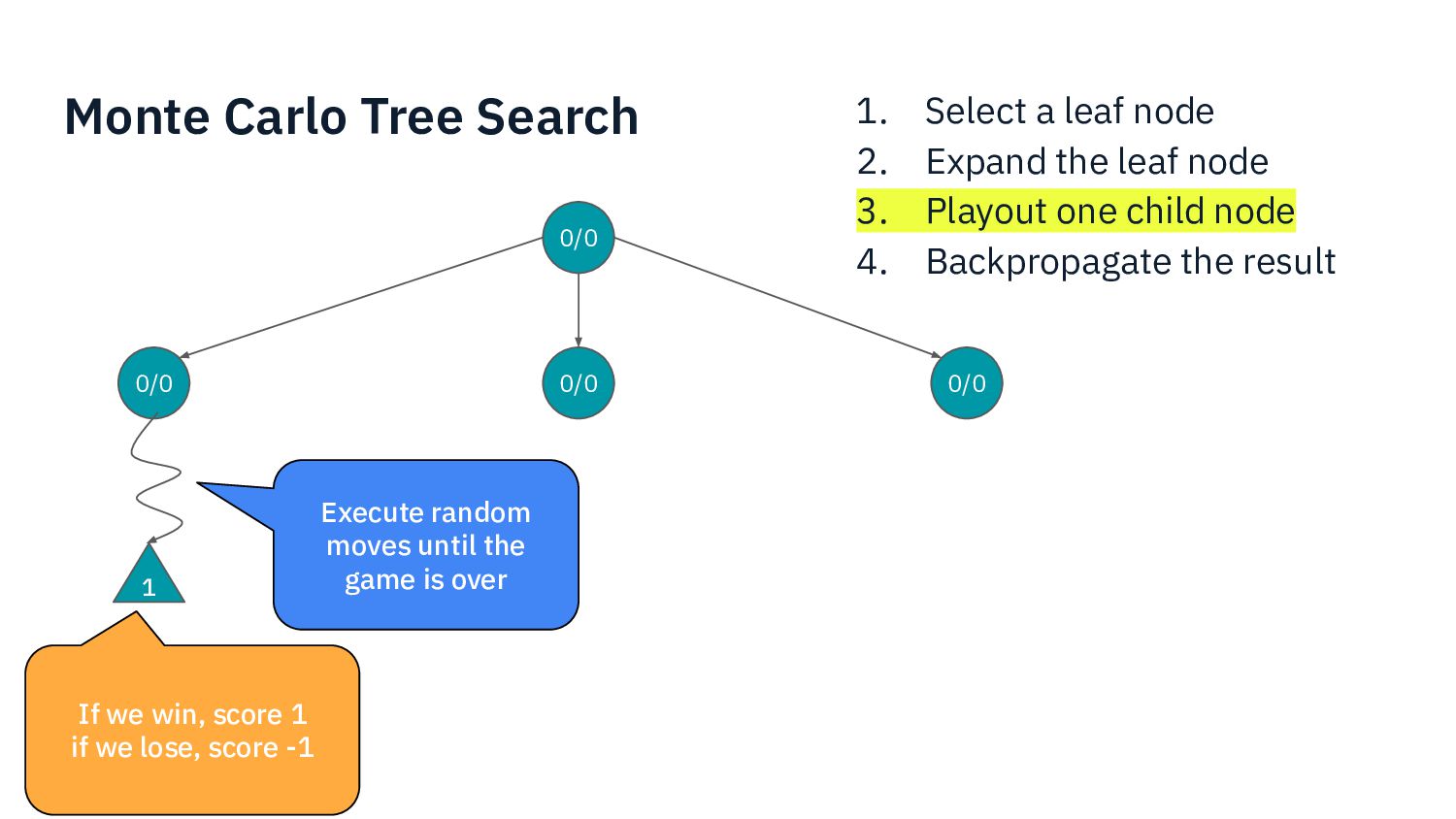
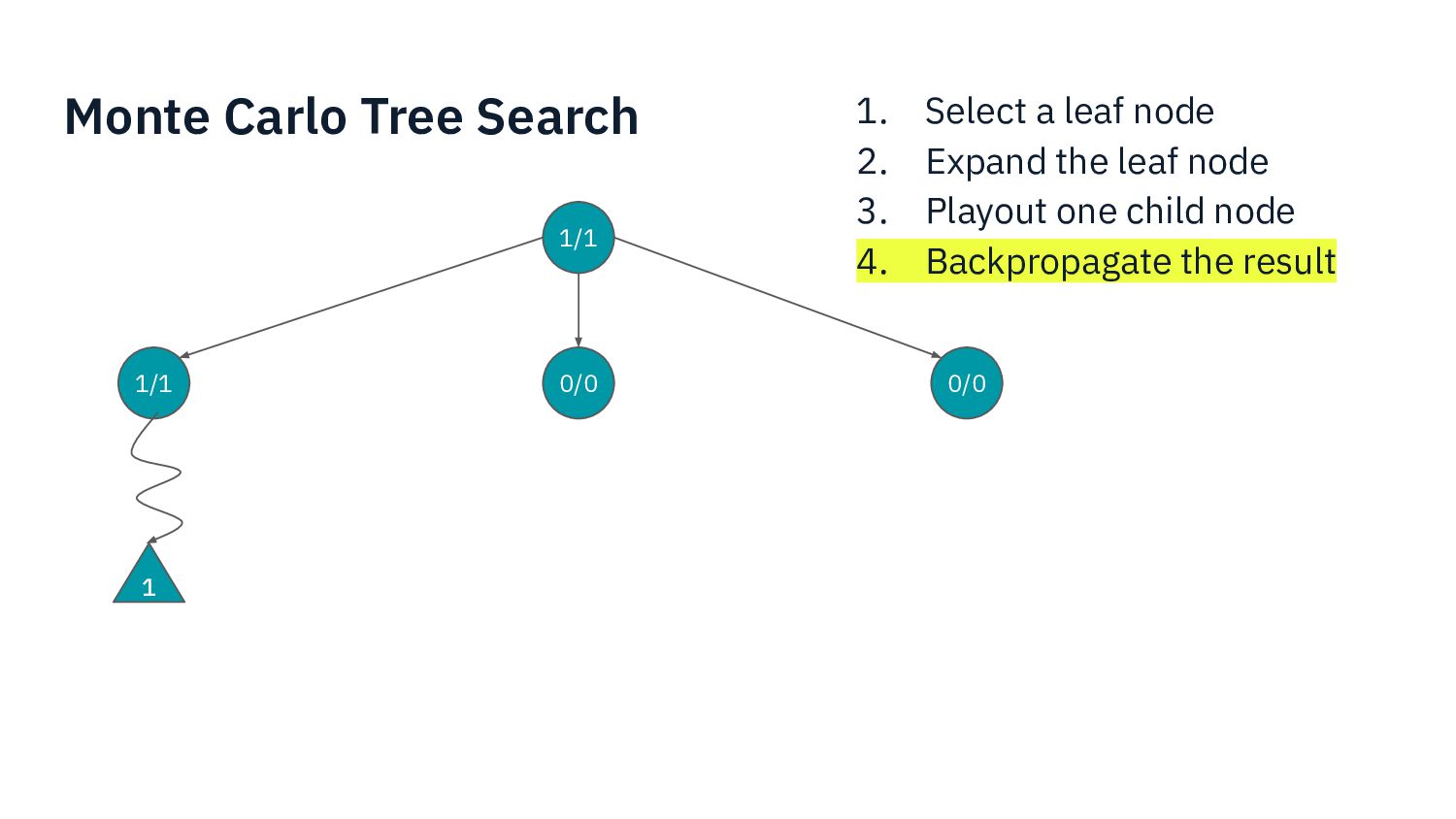
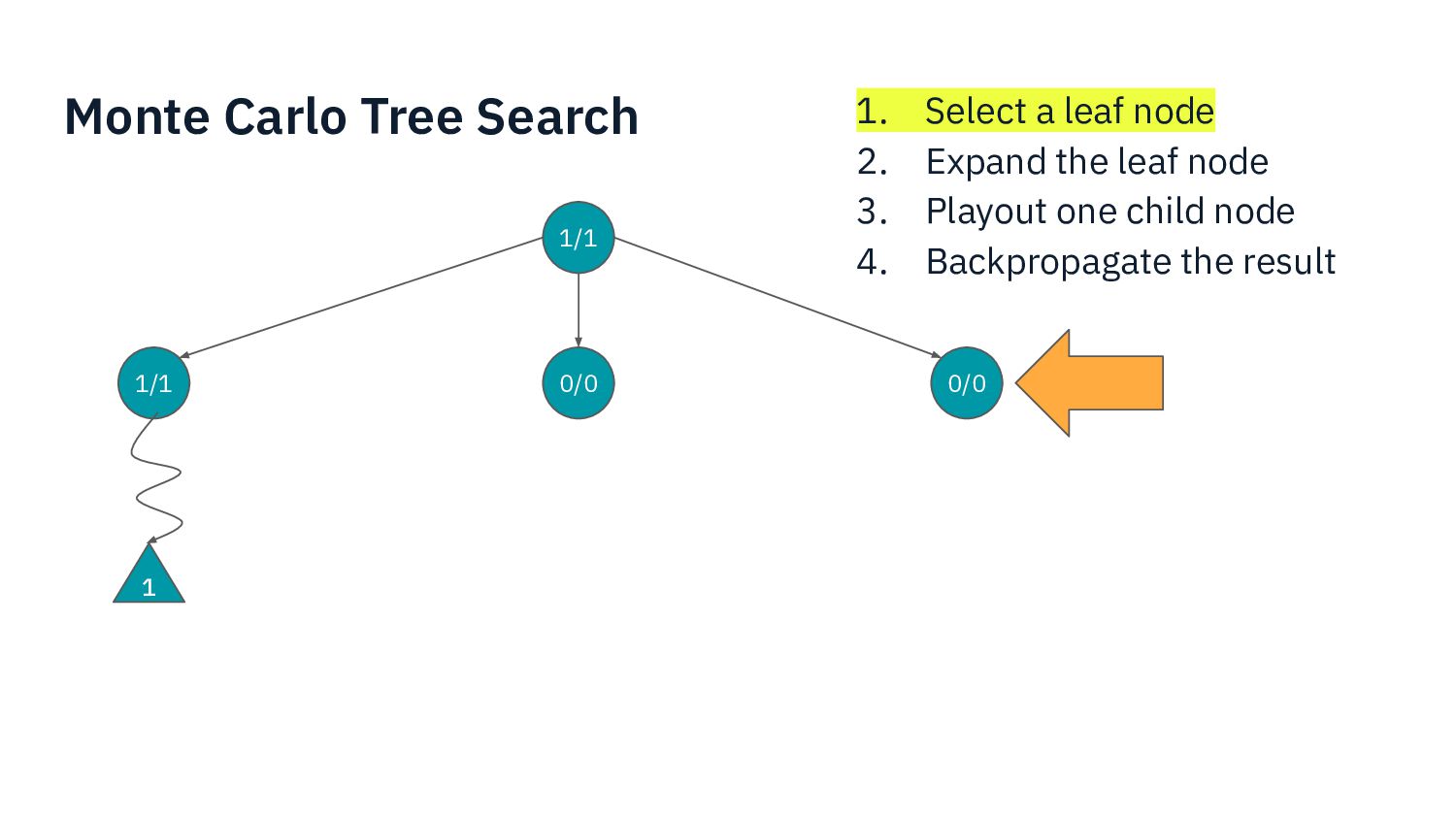
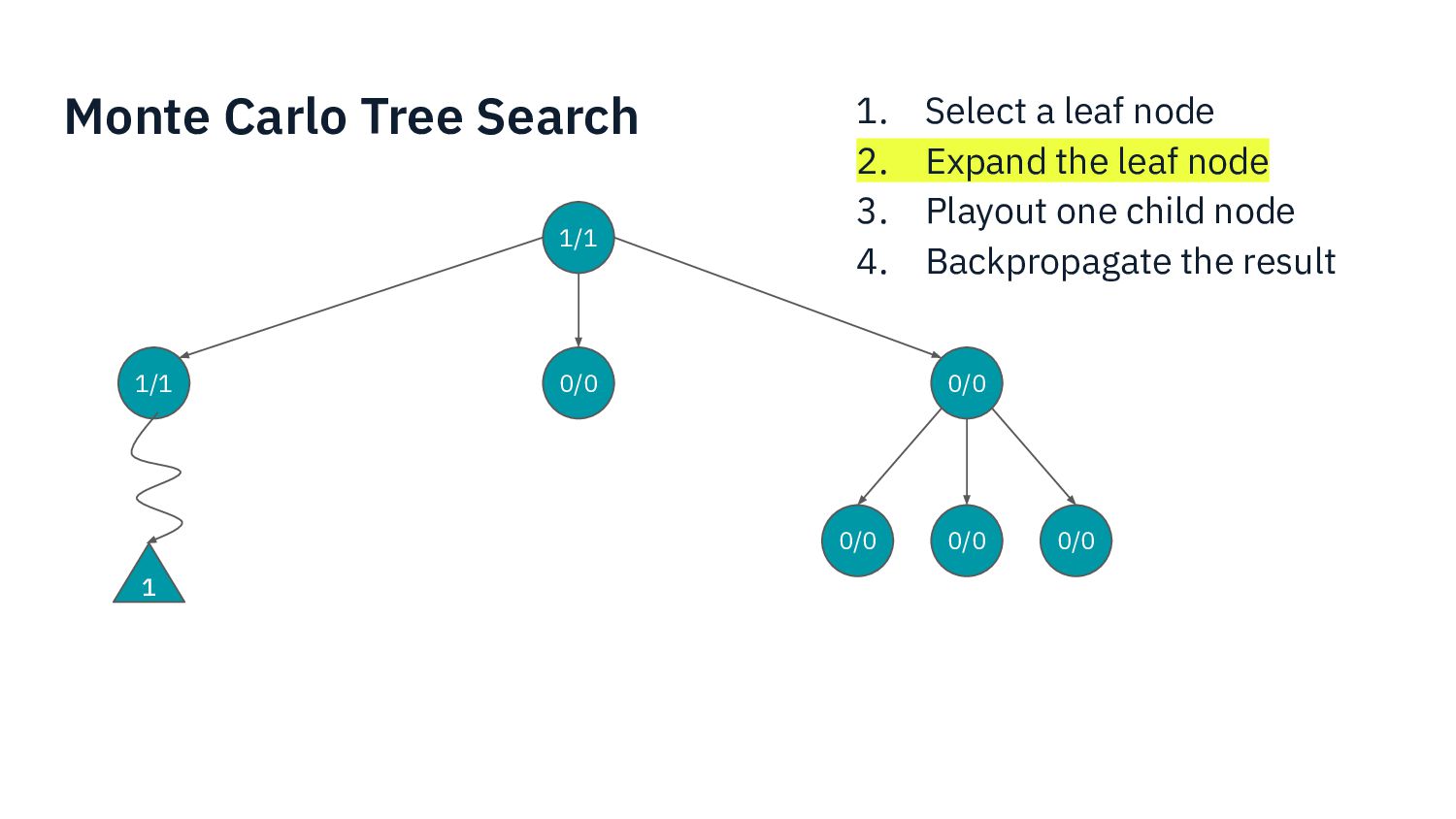
I present my experience developing an AI for a complex modern boardgame such as Commands & Colors: Ancients. The techniques that can be applied to perfect information games such as chess do not apply directly here, because the game has: incomplete information (cards), chance (dice) and a player performs a variable number of moves before passing the turn to the other player. Monte Carlo Tree Search is one of the fundamental techniques used in modern game AI. In this presentation we show what modifications are needed in order to make MCTS work for our chosen game.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
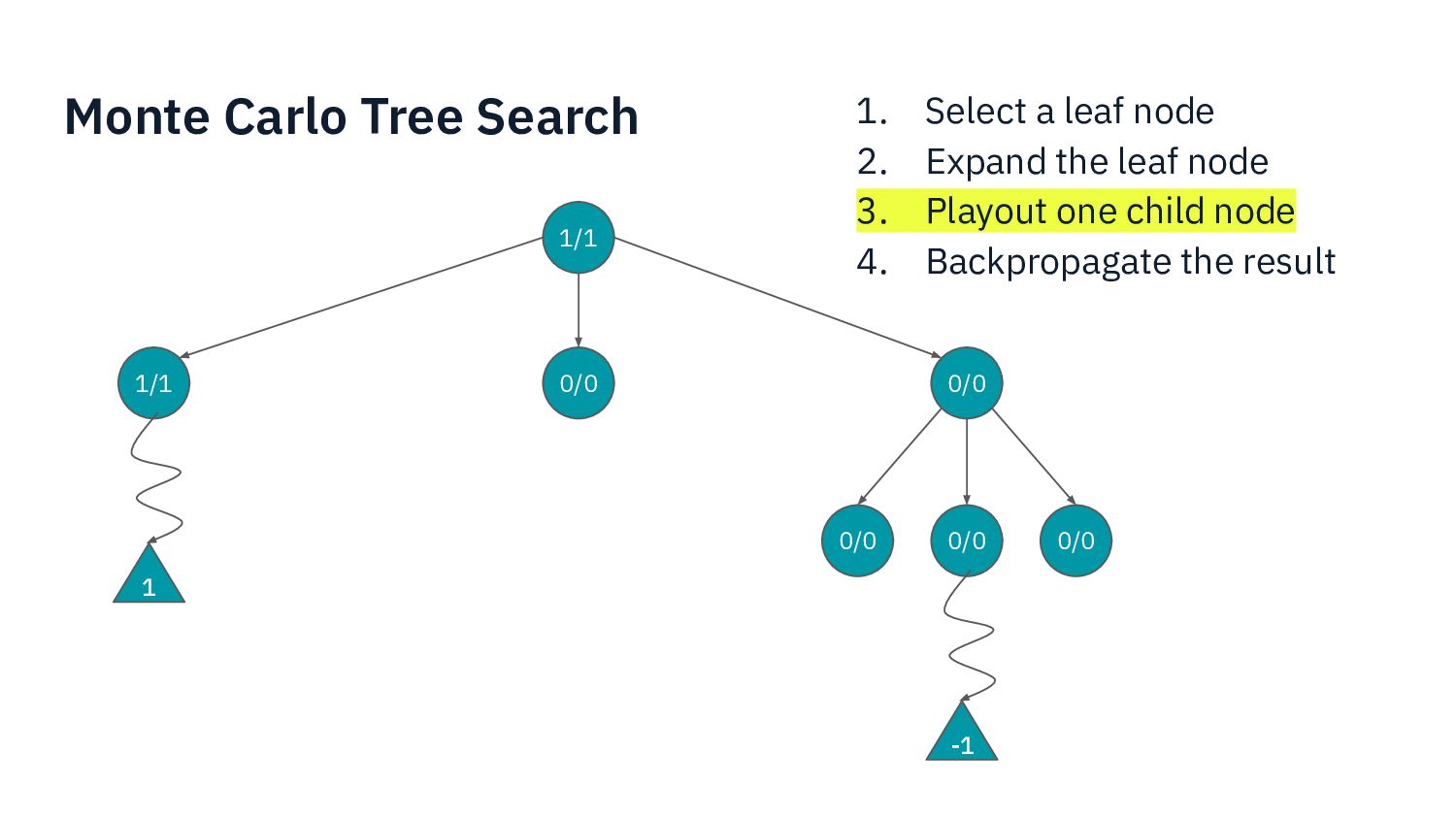{kind=link}
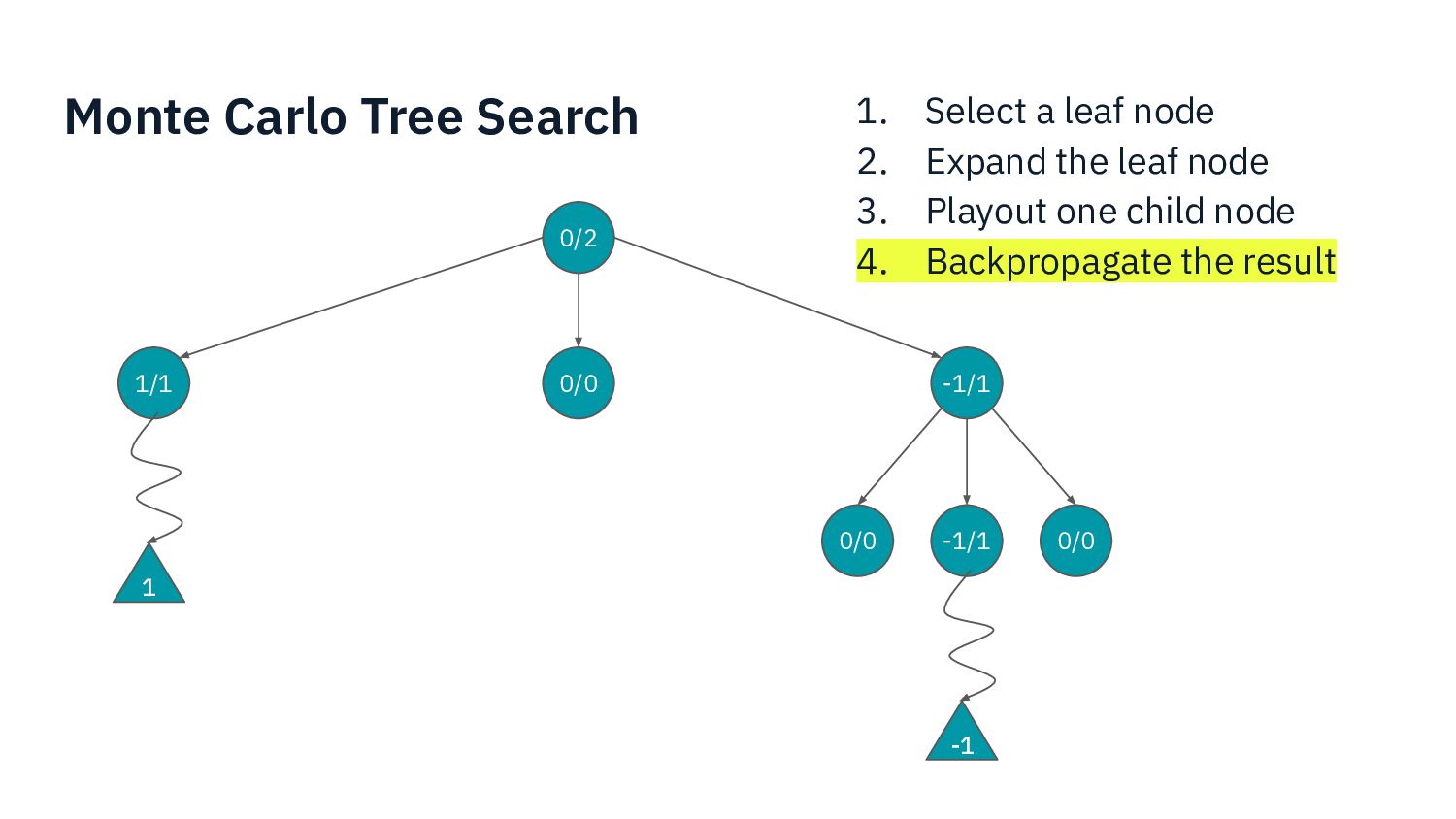{kind=link}
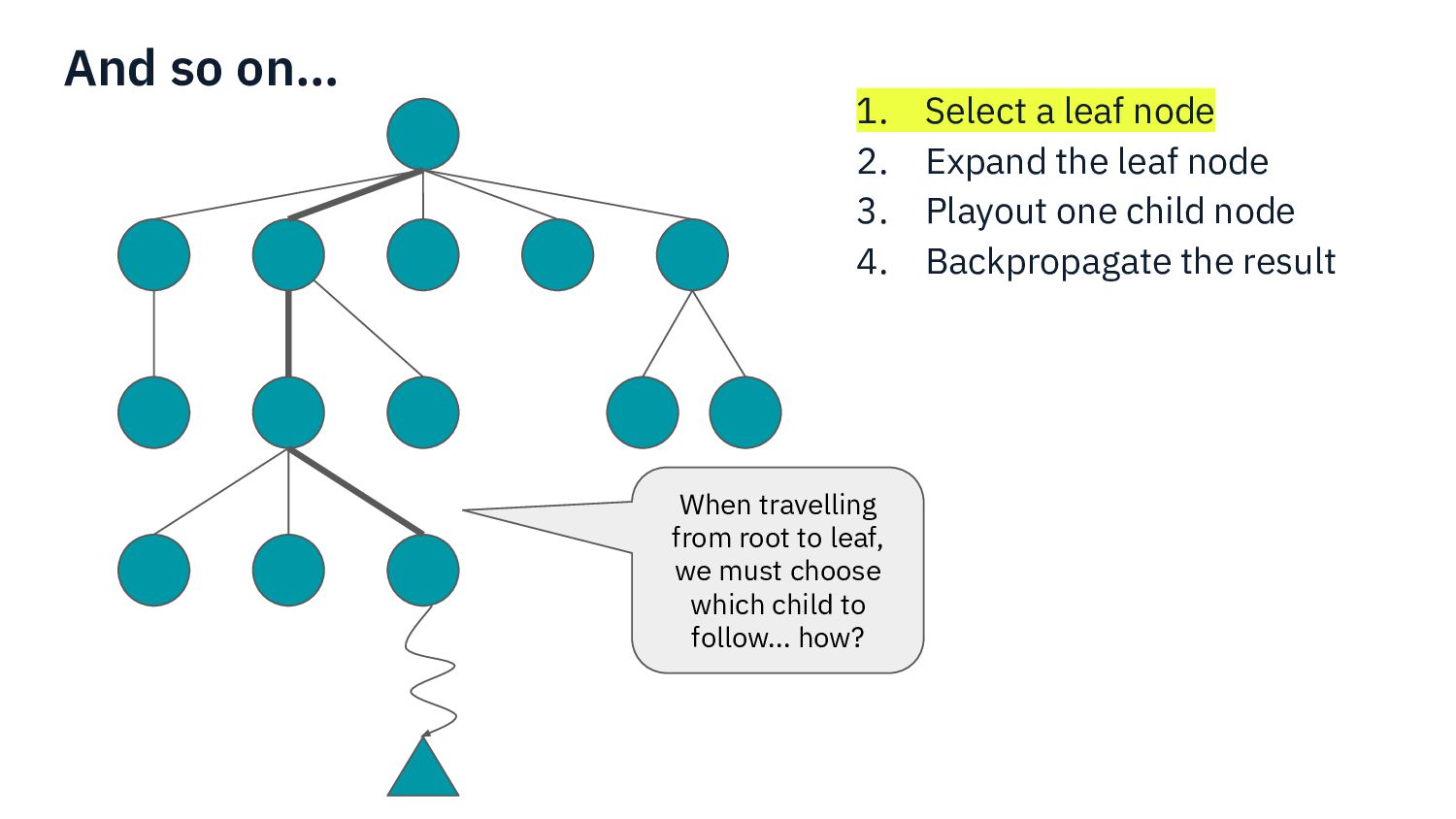{kind=link}
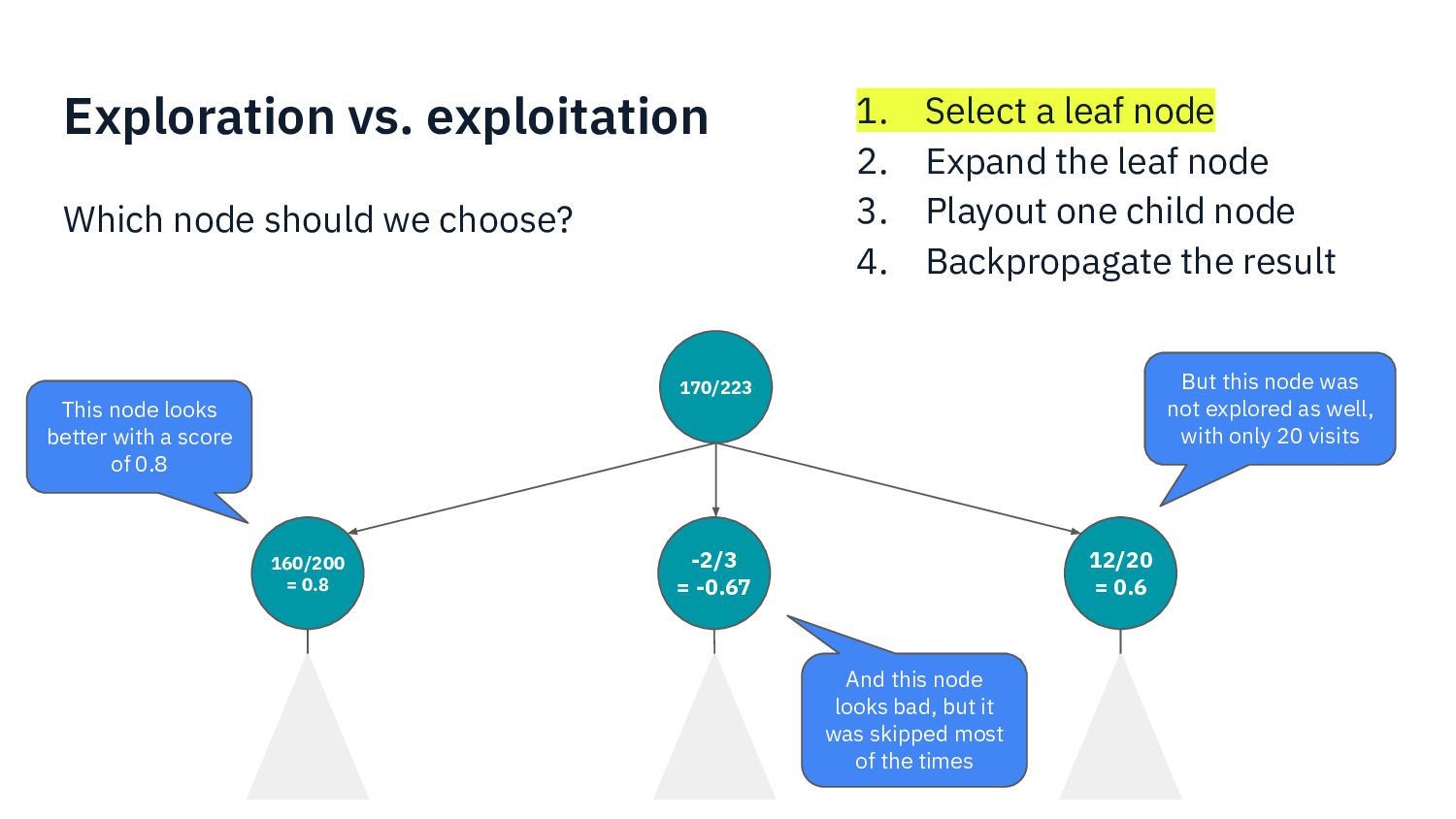{kind=link}
{kind=link}
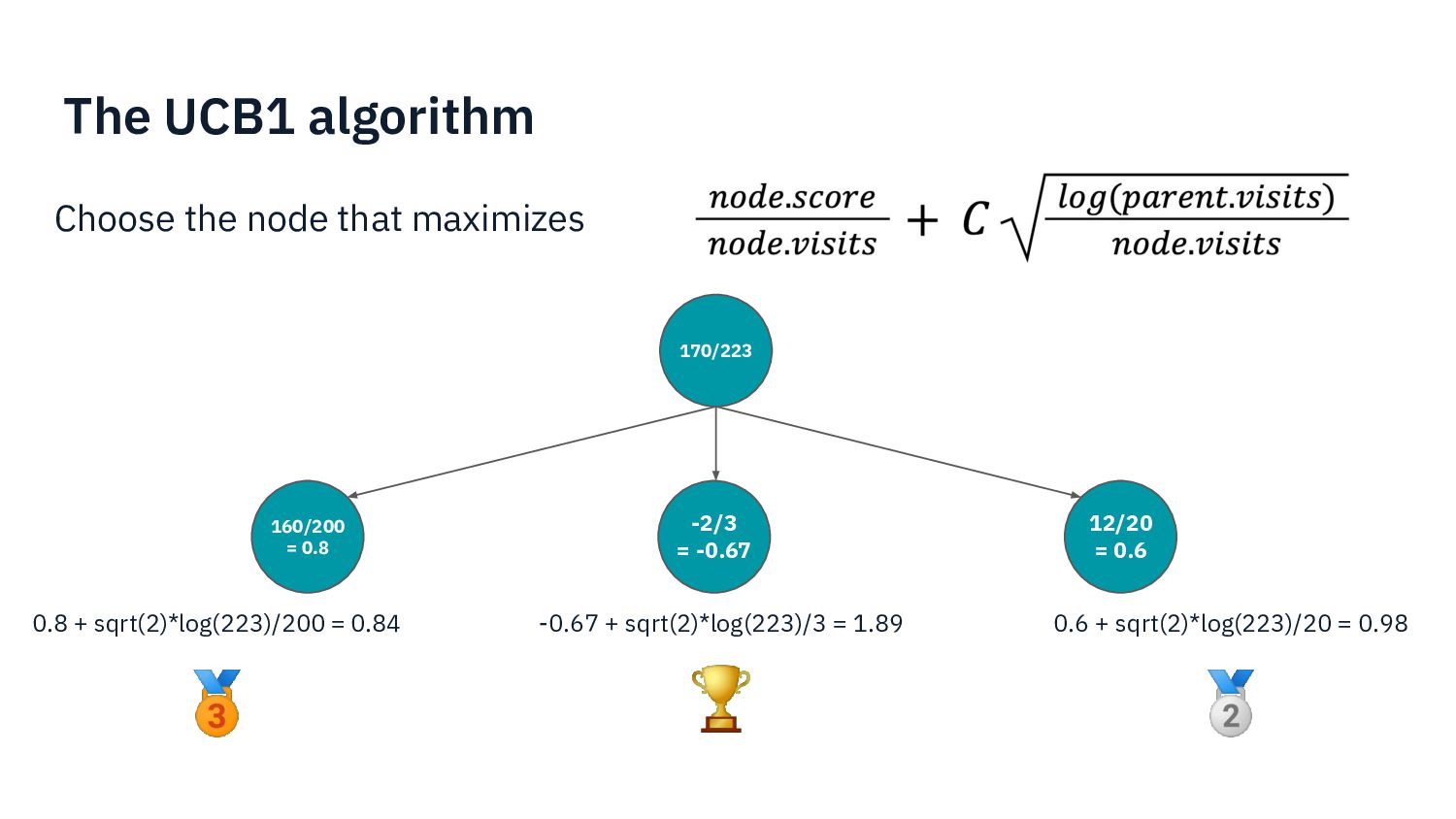{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
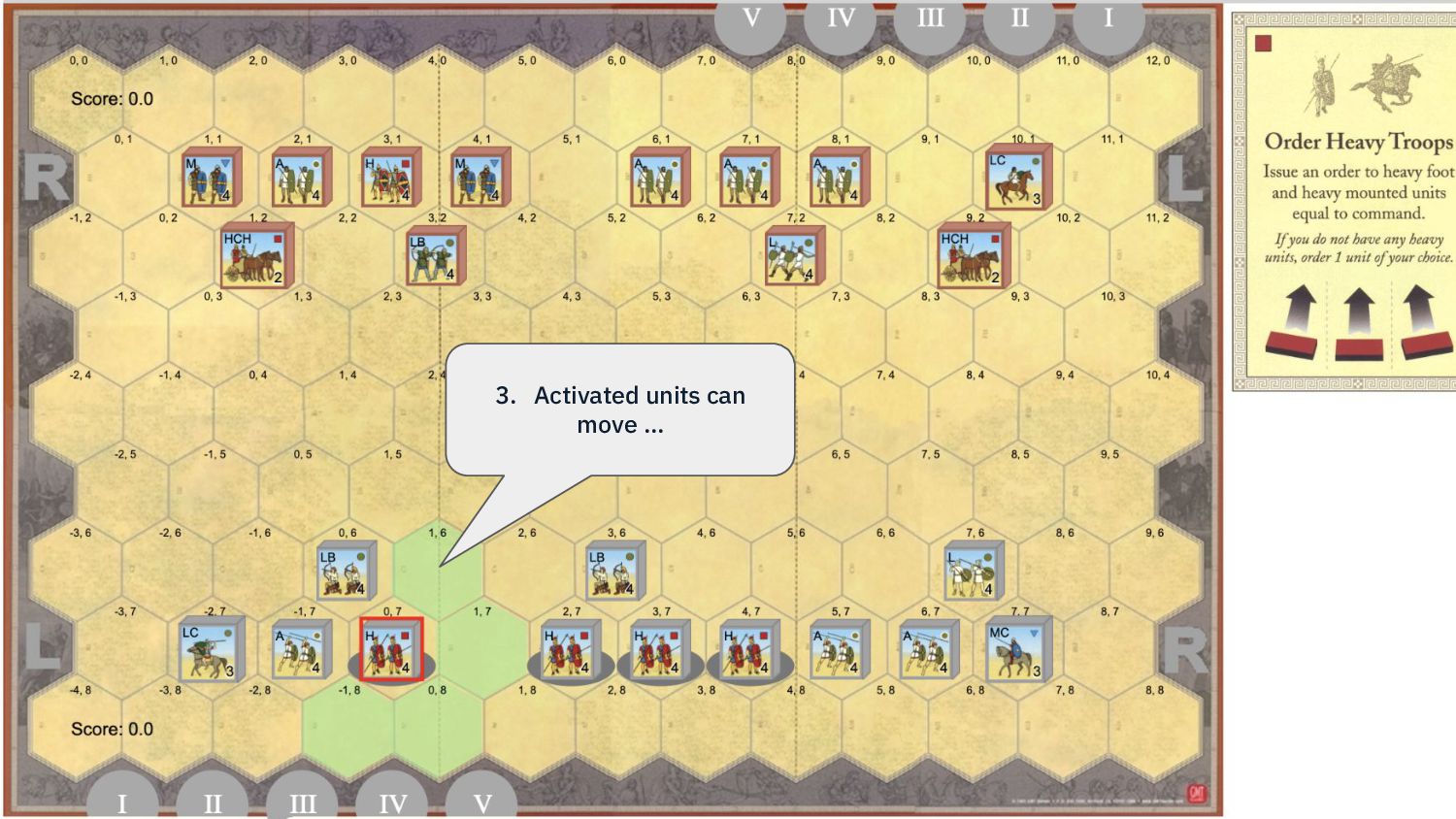{kind=link}
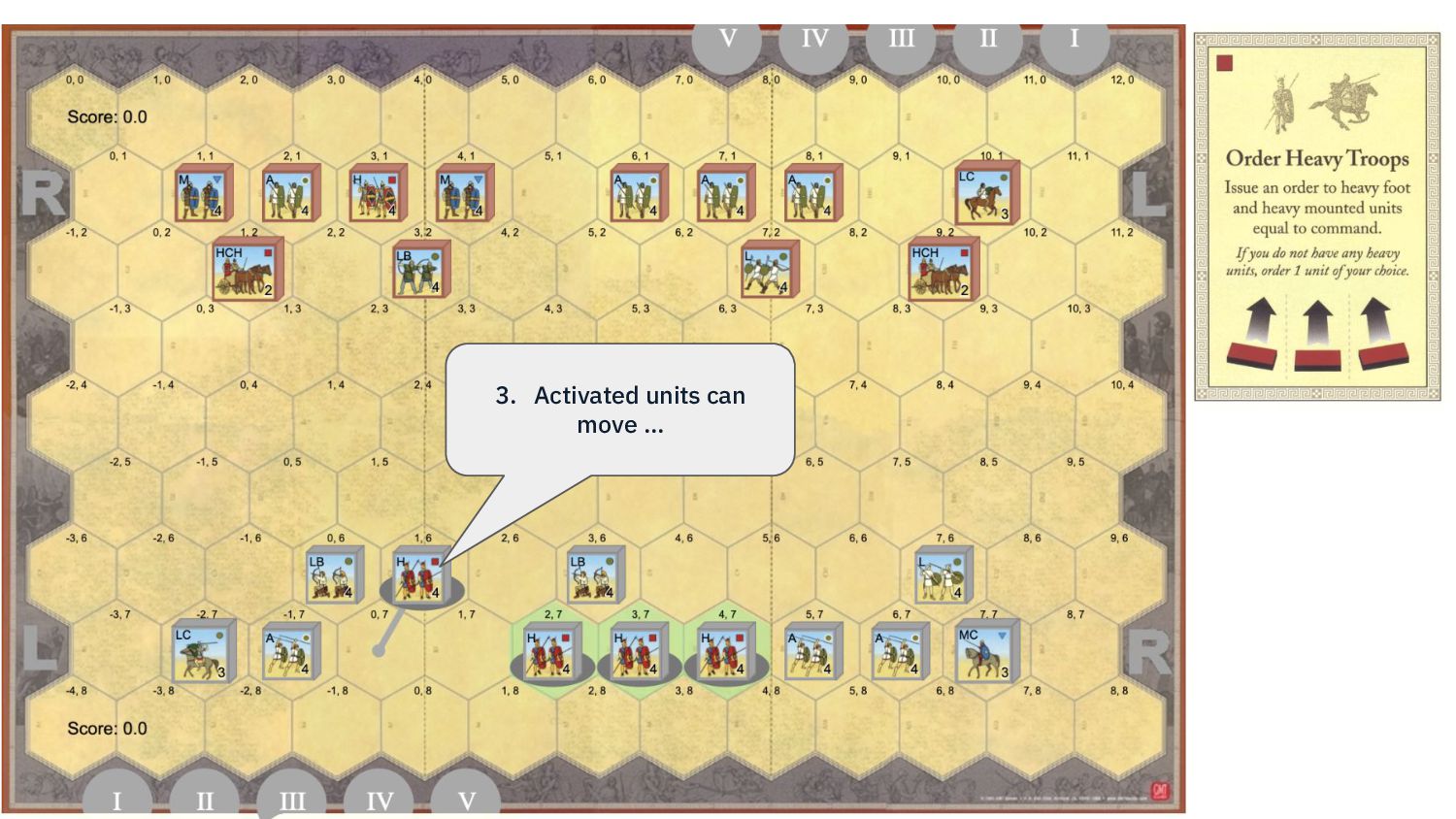{kind=link}
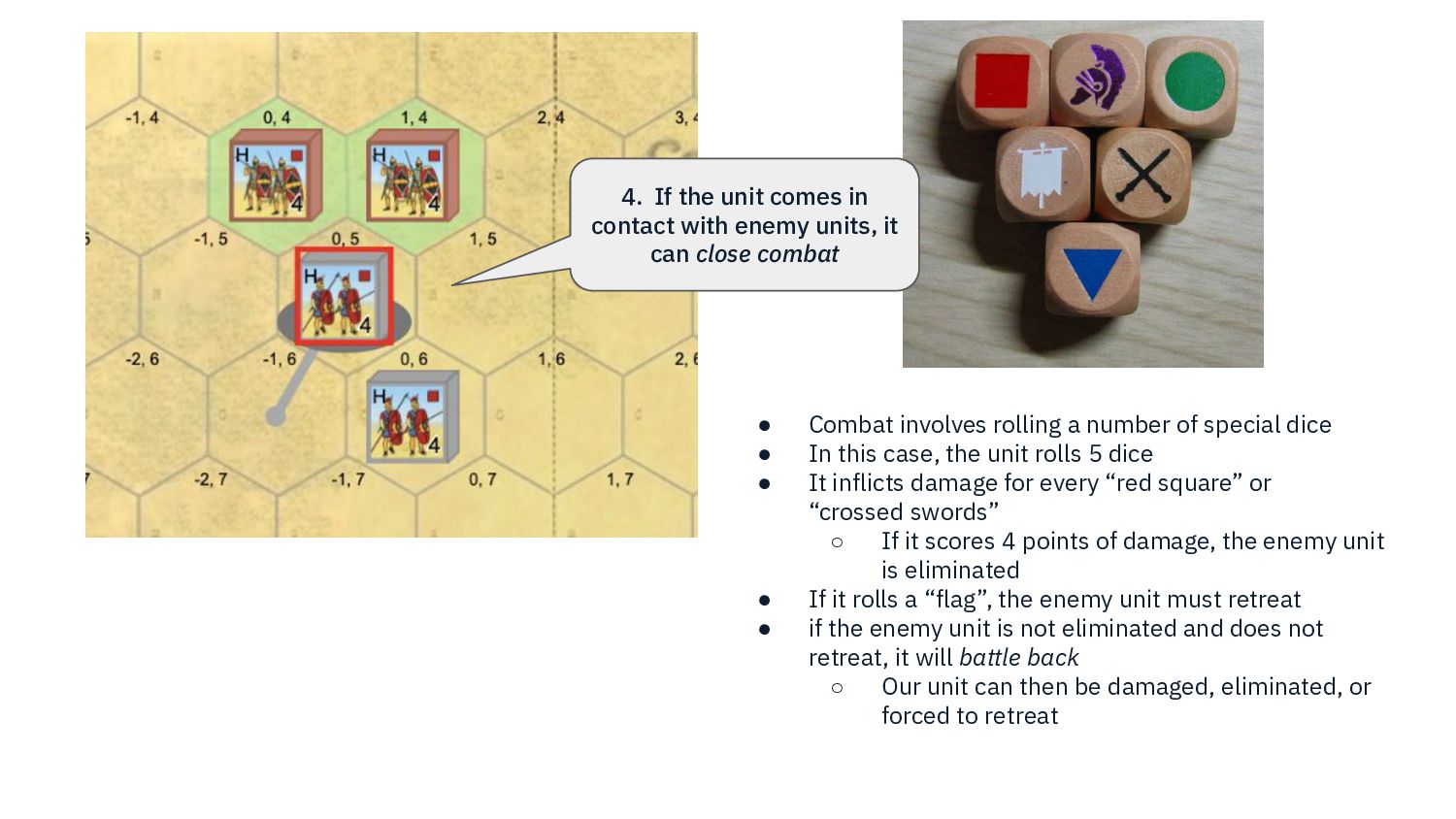{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
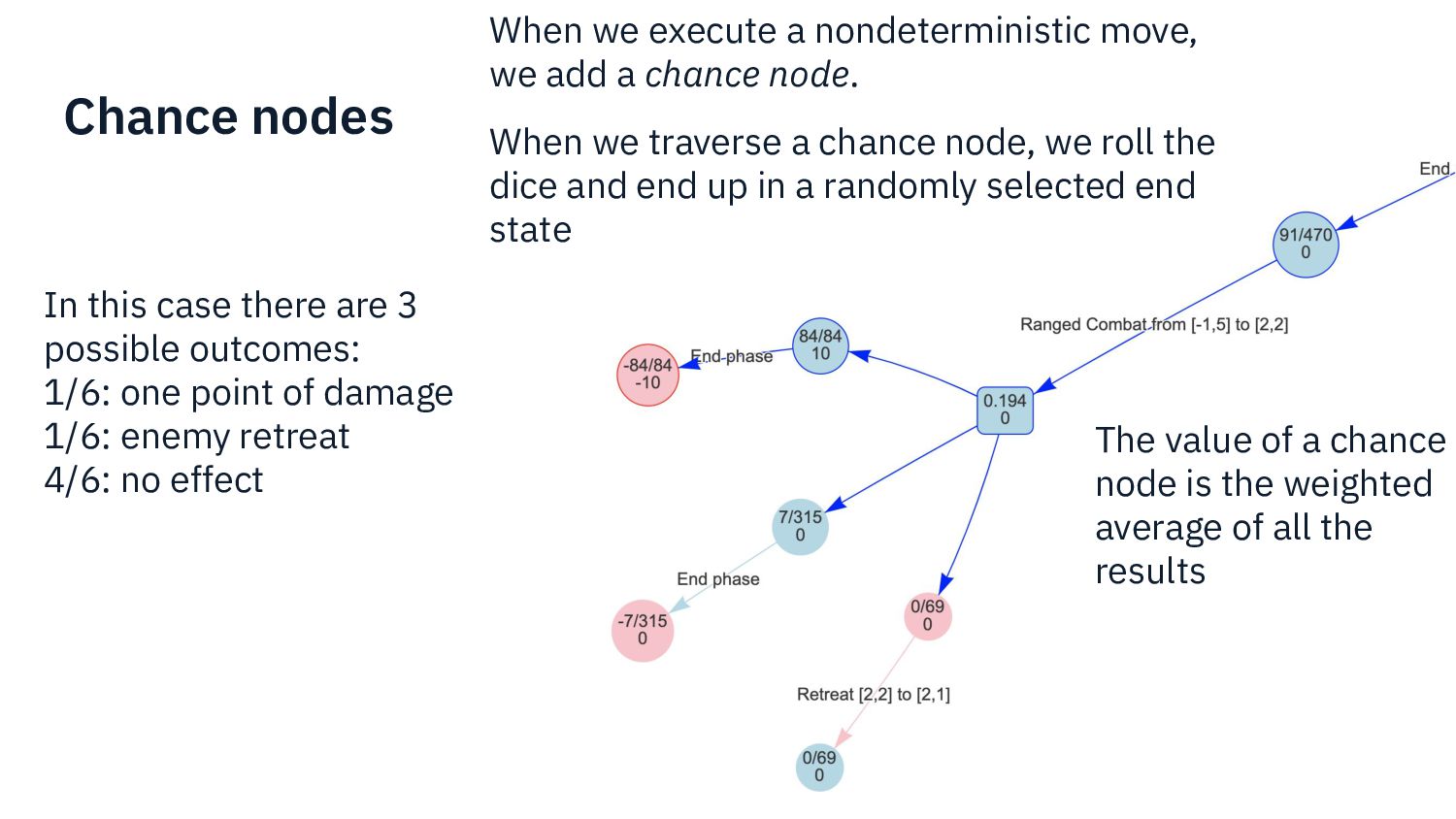{kind=link}
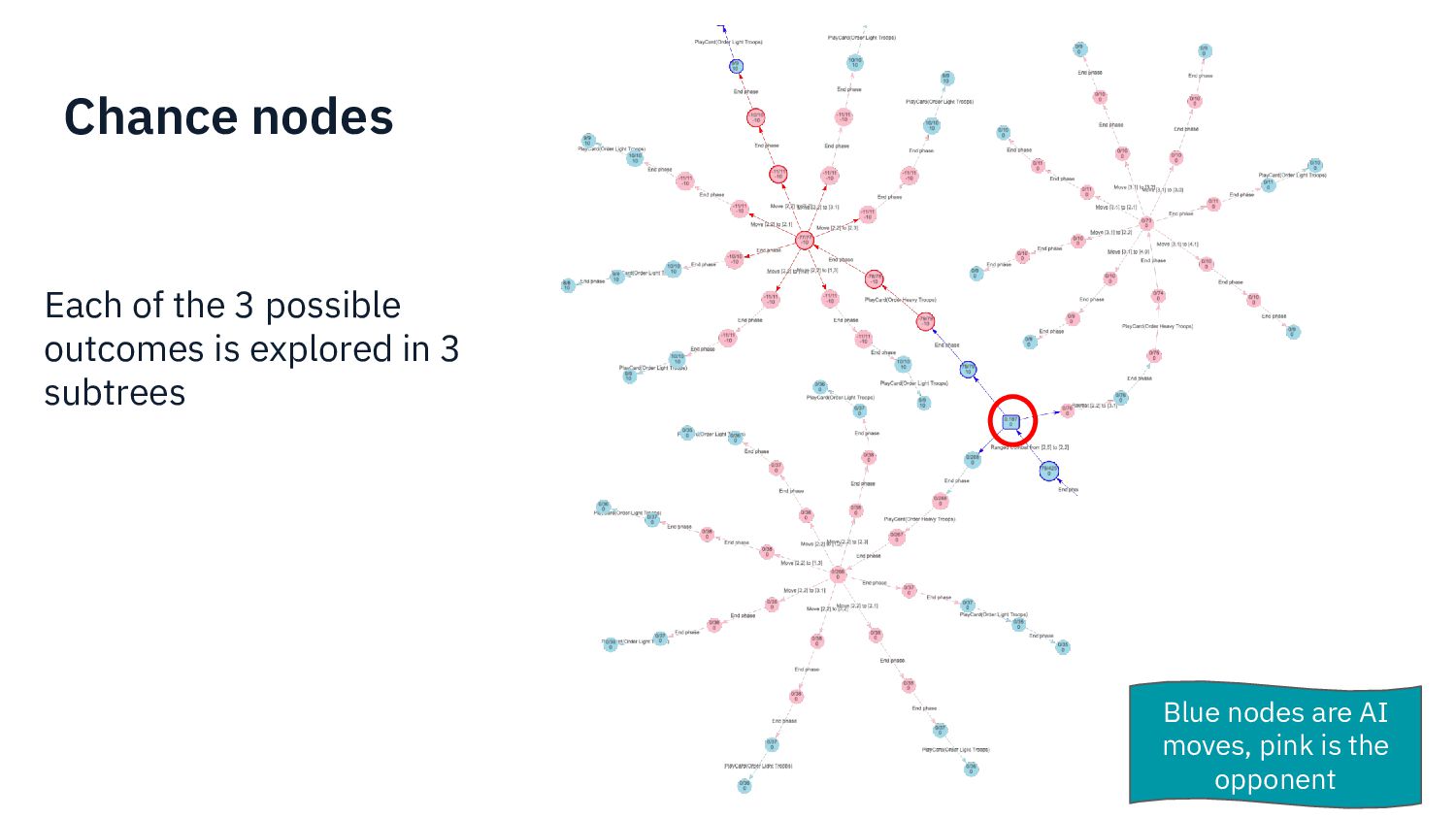{kind=link}
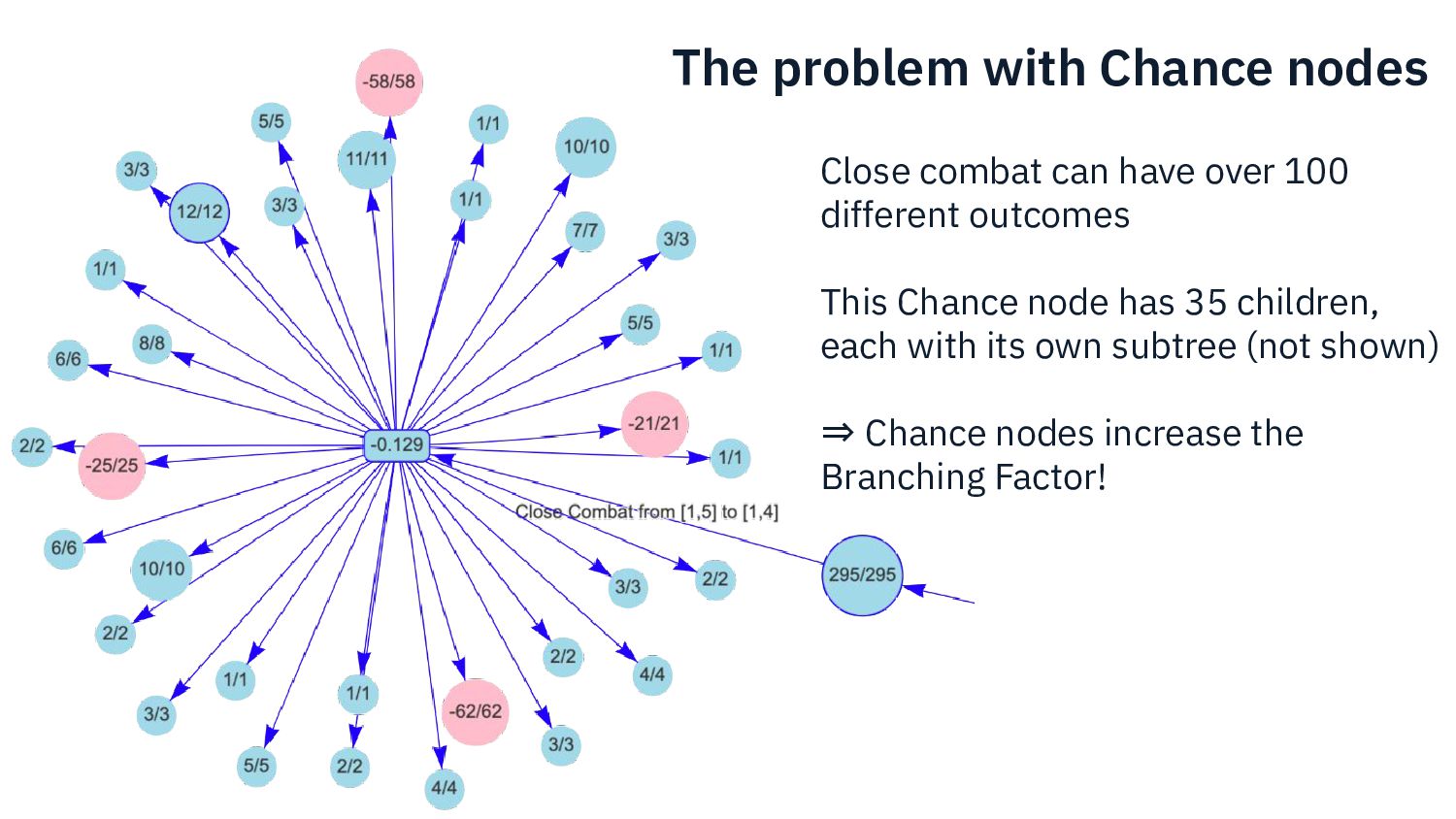{kind=link}
{kind=link}
![An alternative to chance nodes: Open Loop Close combat [1,2]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_39.jpg){kind=link}
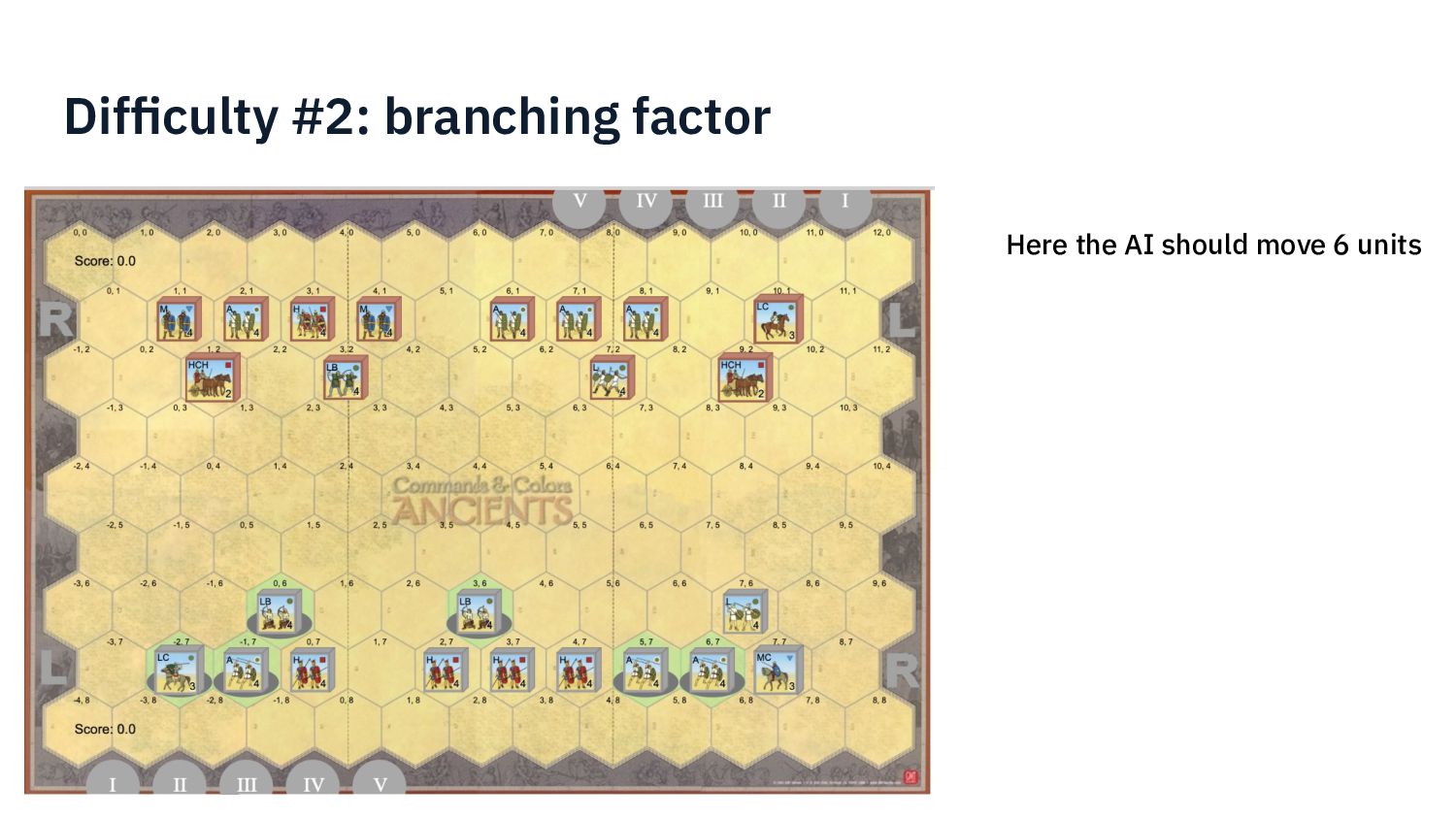{kind=link}
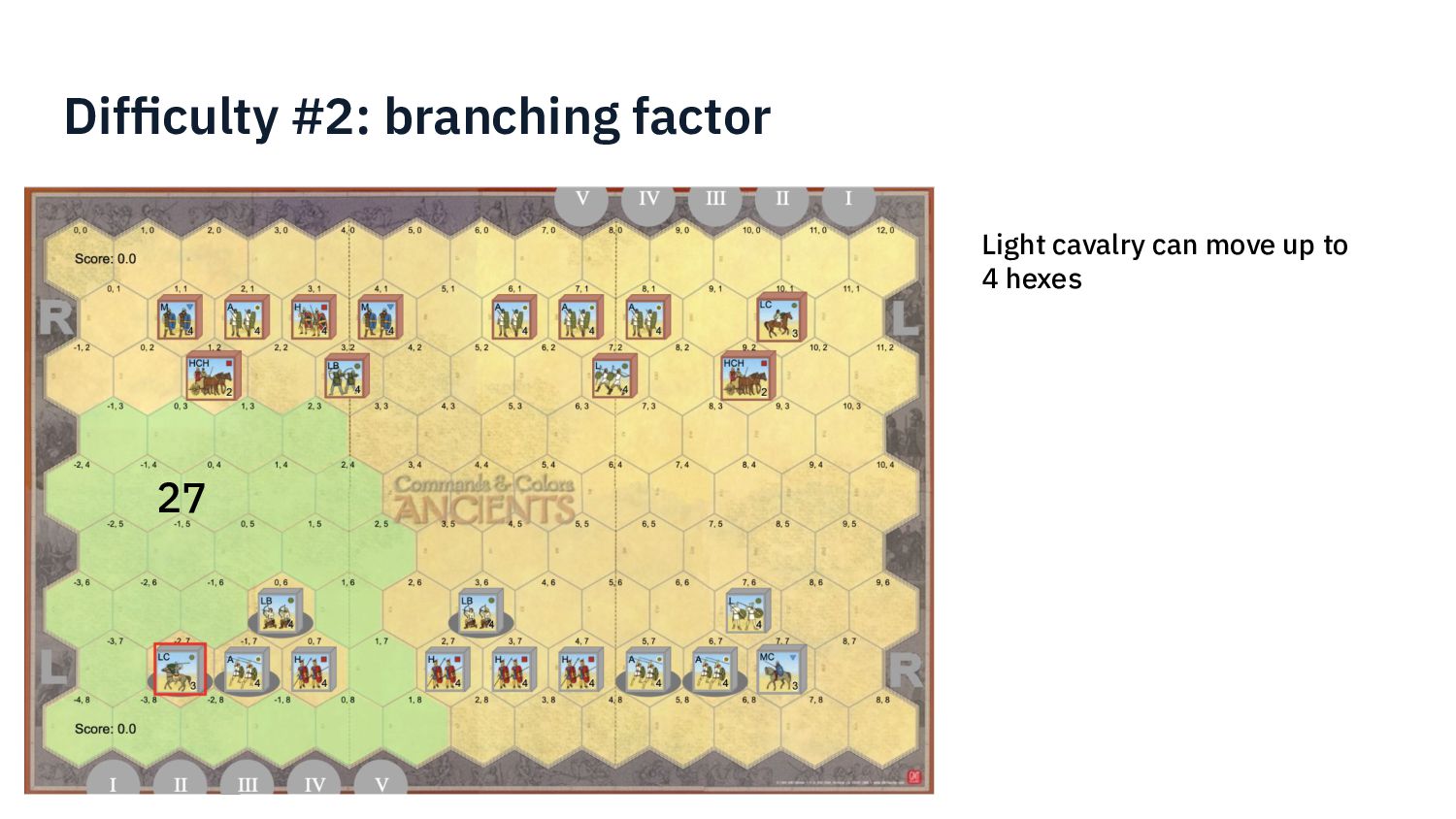{kind=link}
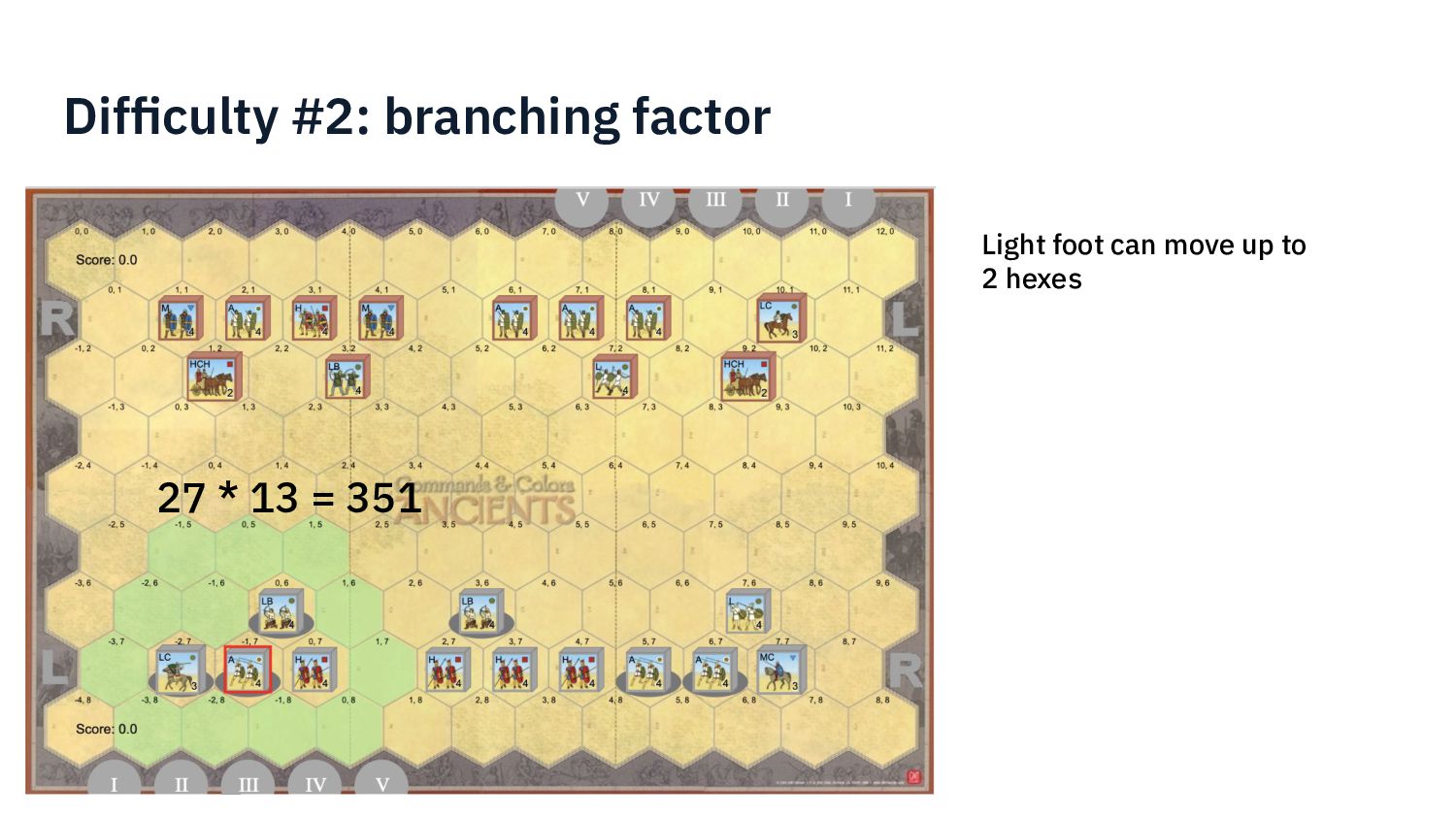{kind=link}
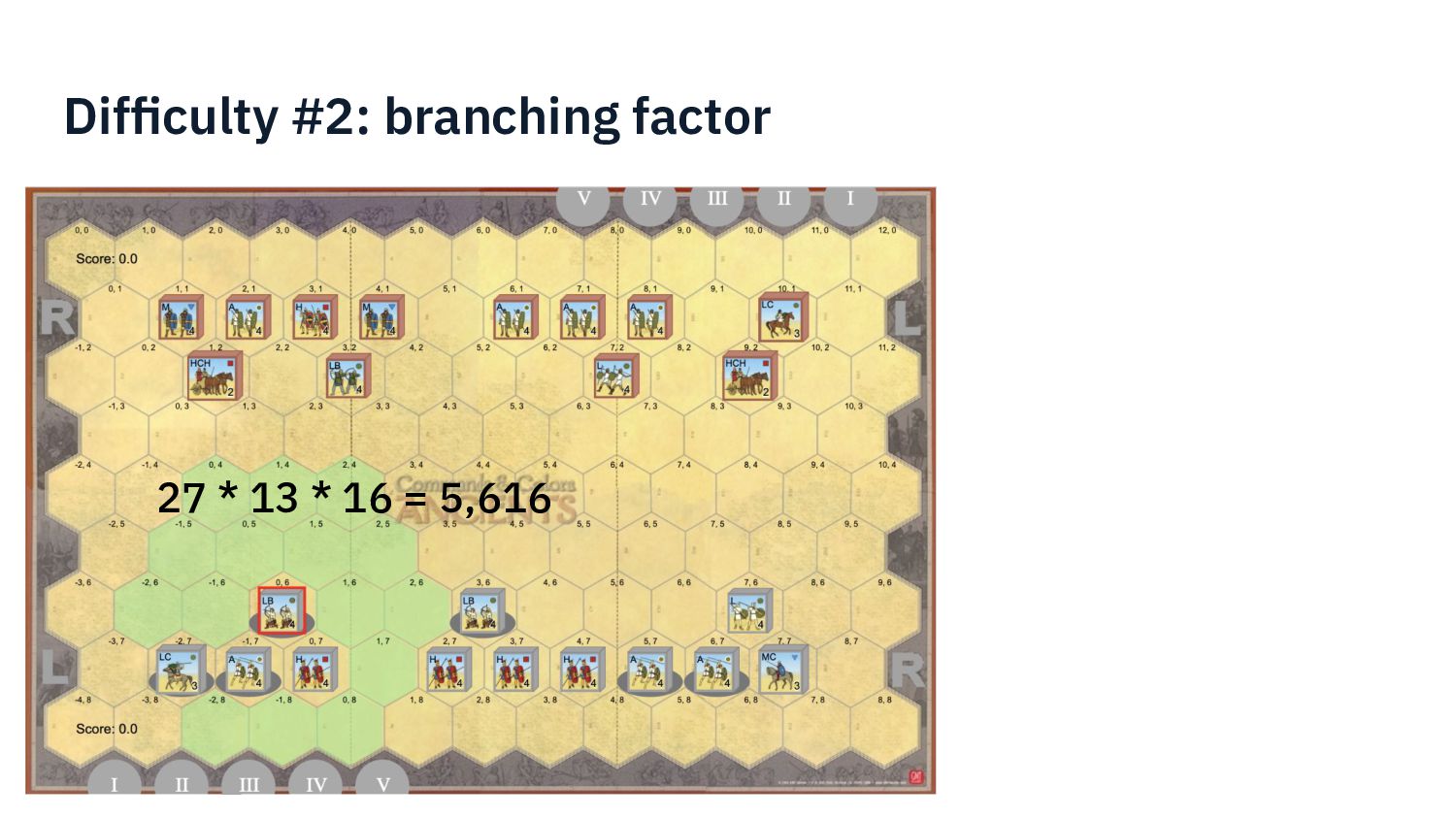{kind=link}
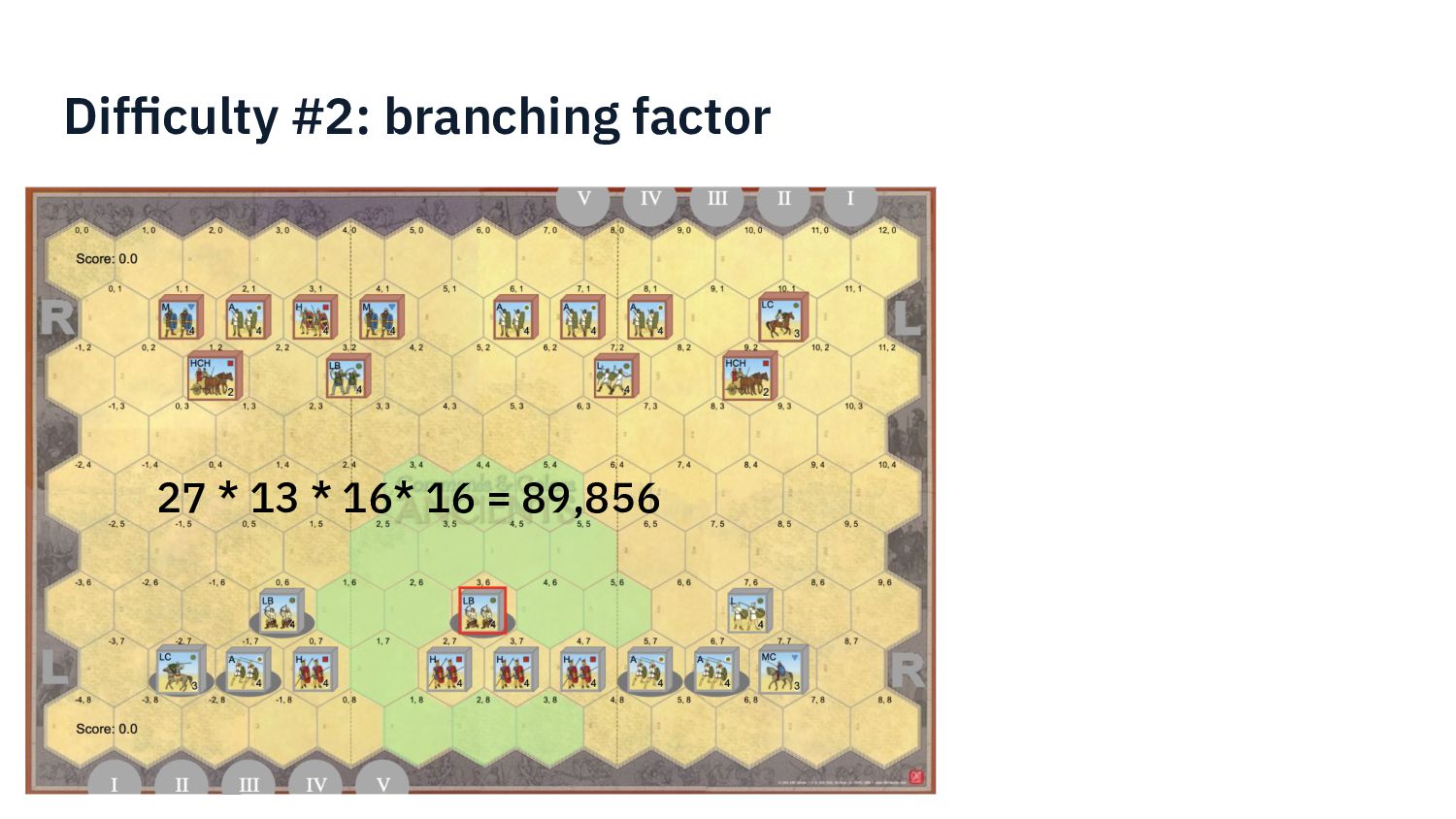{kind=link}
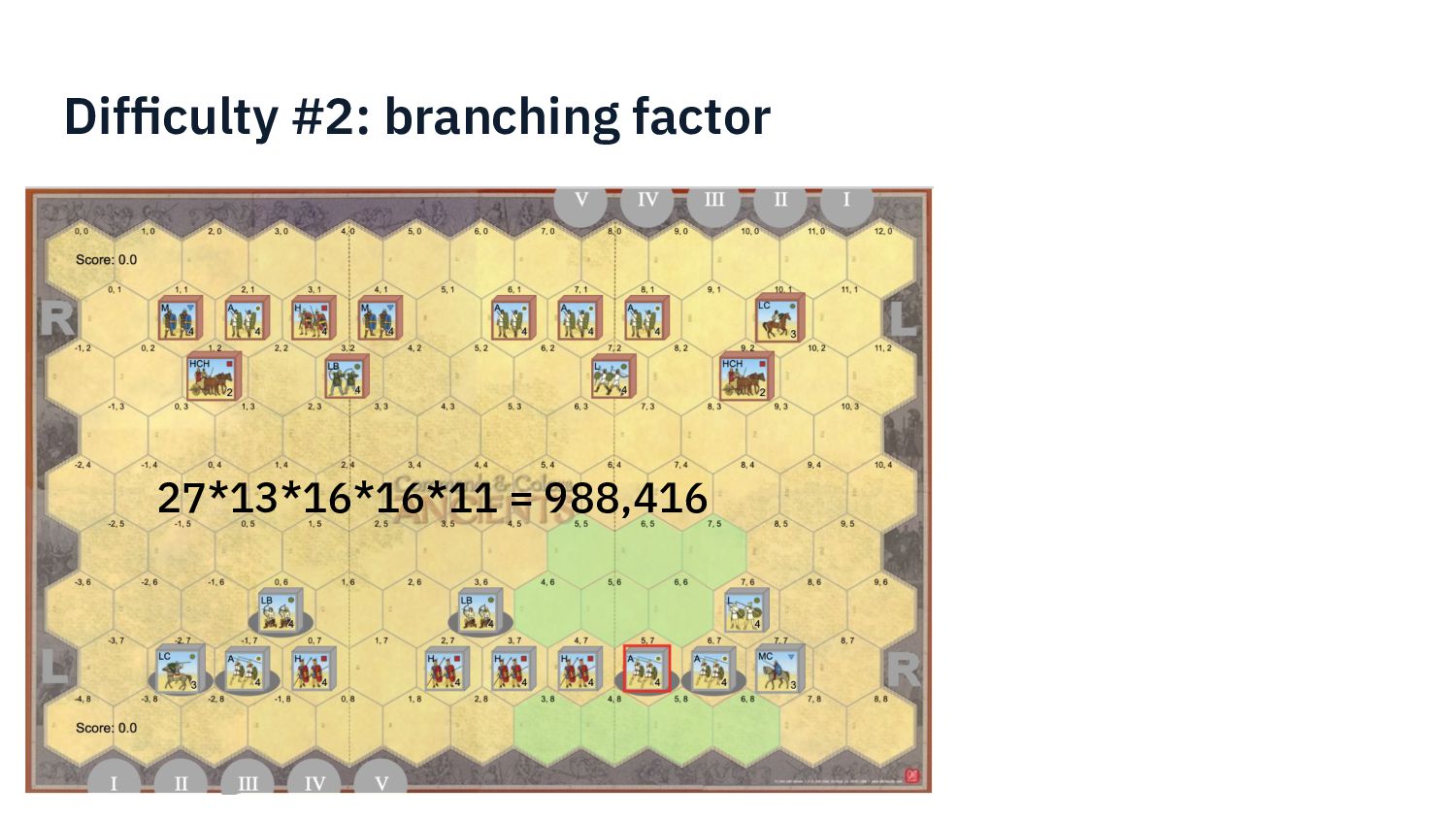{kind=link}
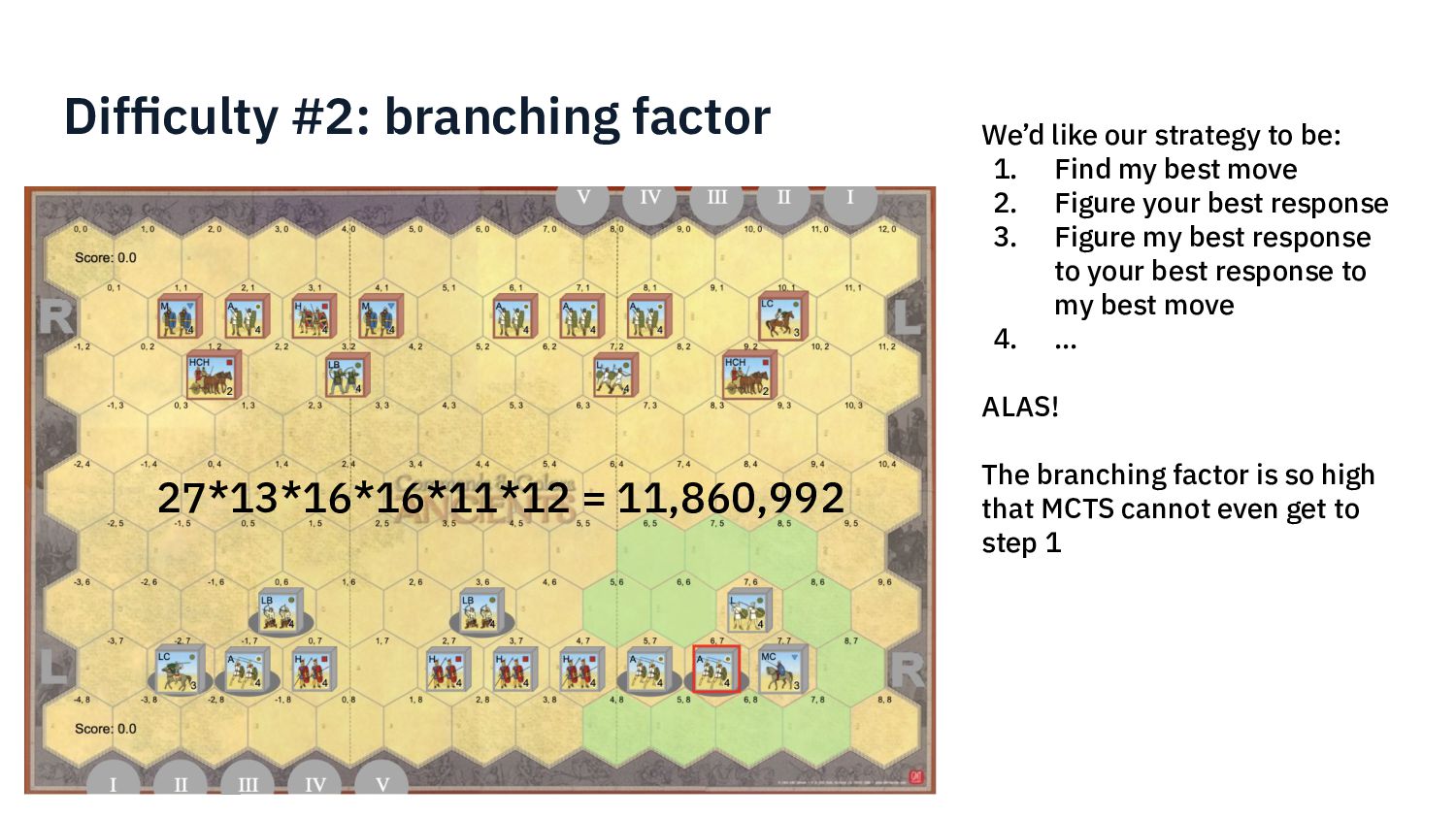{kind=link}
{kind=link}
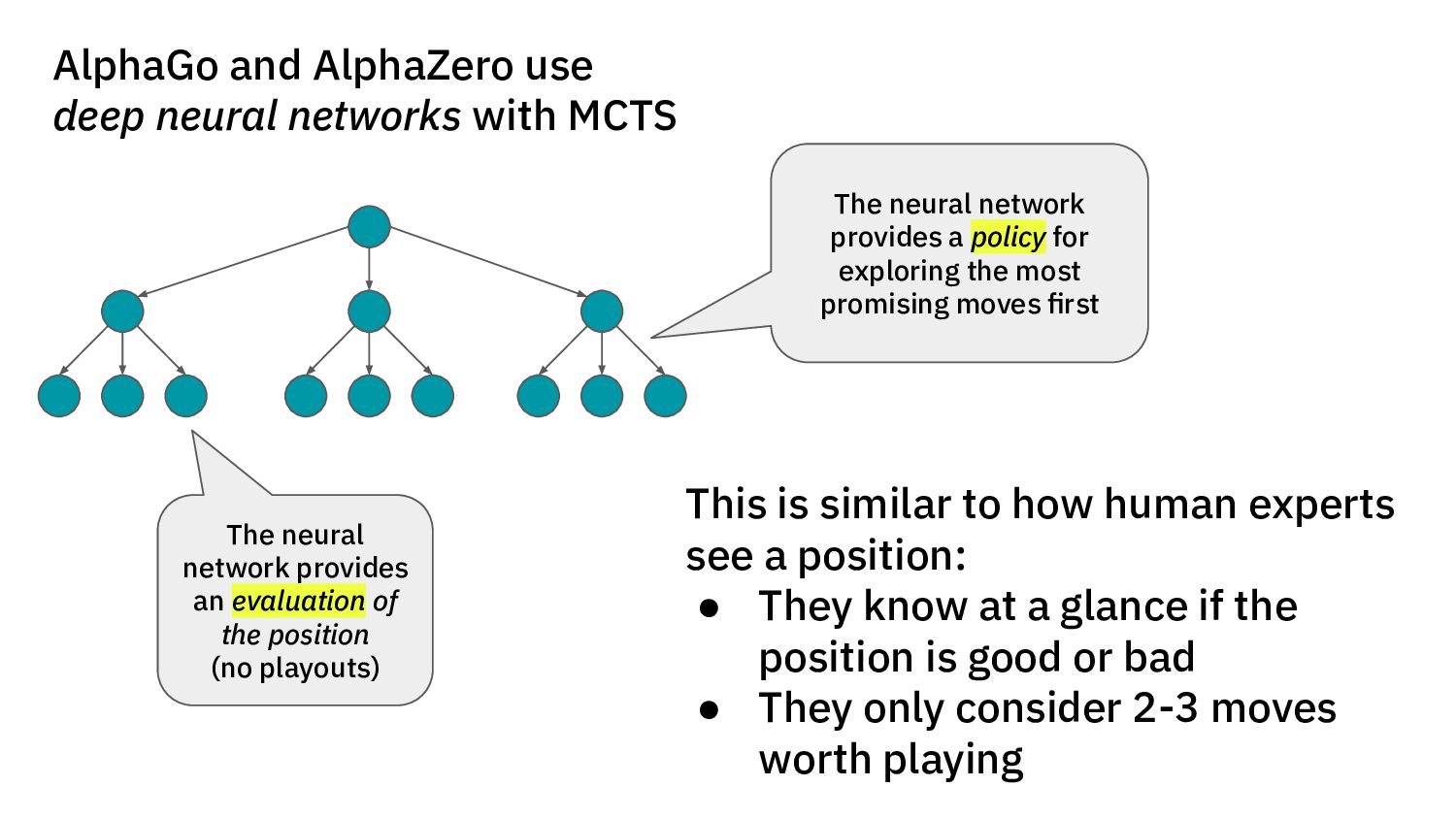{kind=link}
{kind=link}
{kind=link}
{kind=link}
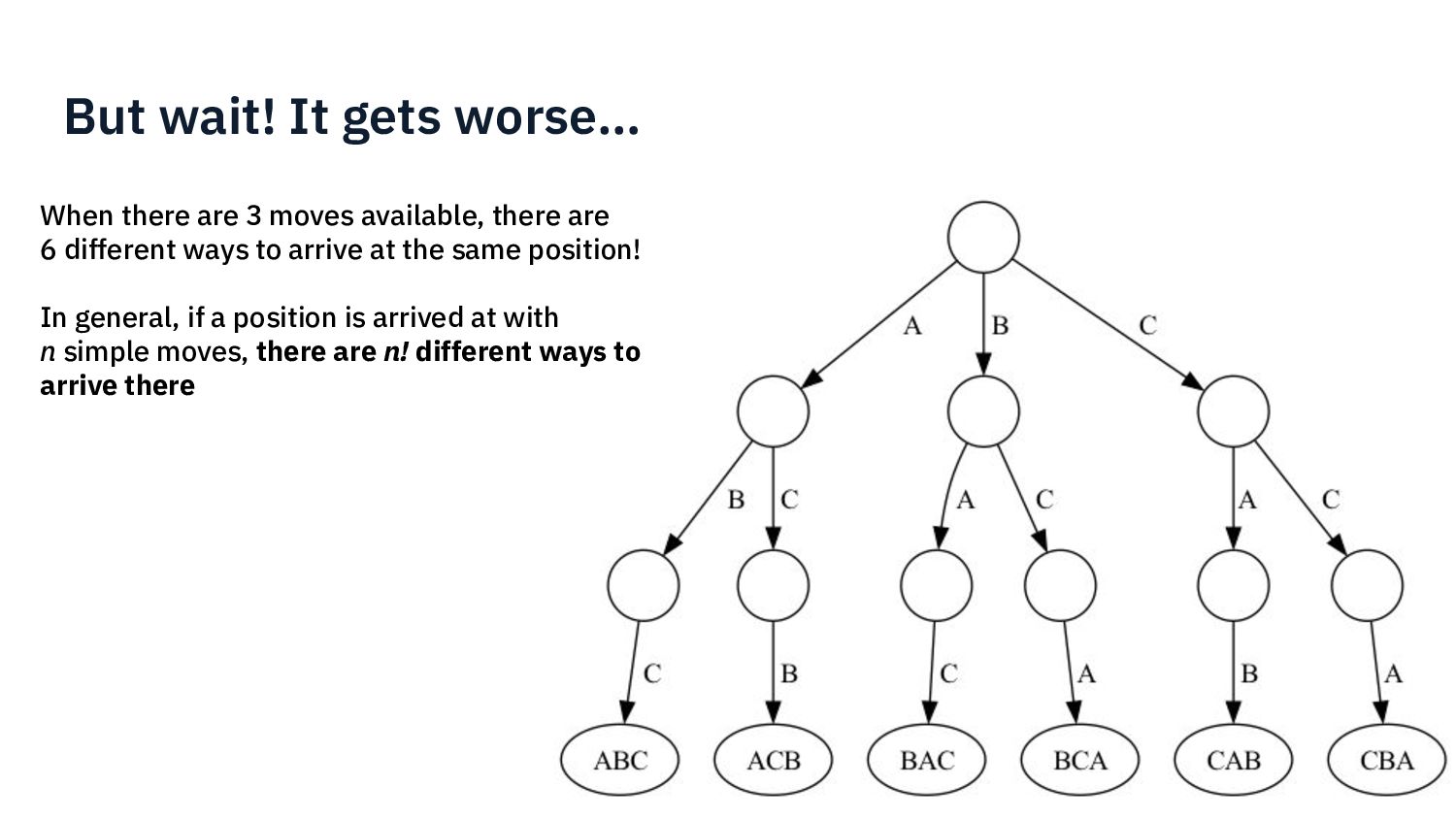{kind=link}
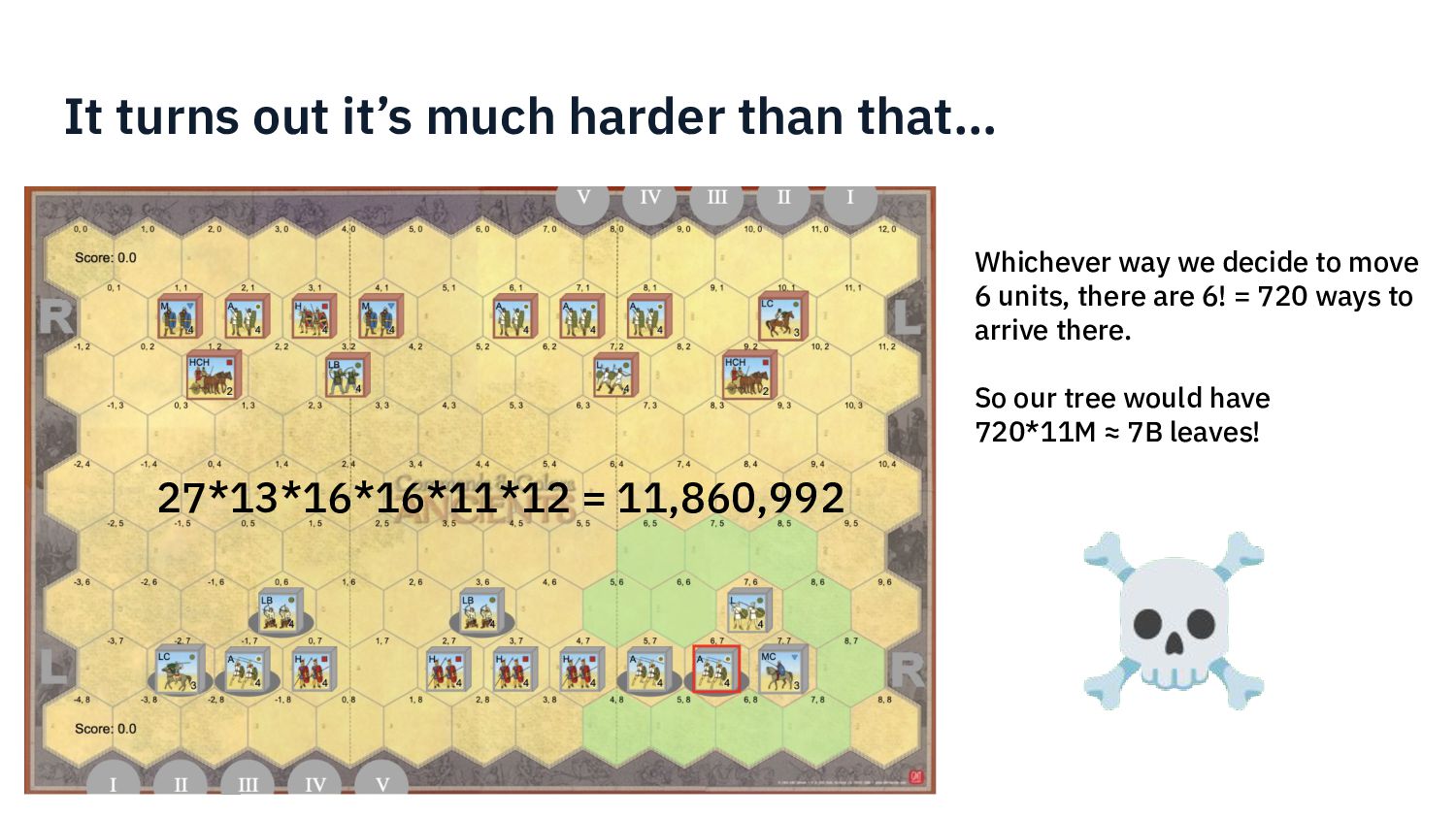{kind=link}
![From simple moves to Macro-moves Move [0,1] to [0,2] Move](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_54.jpg){kind=link}
![Sampling Macro-moves Move [ [0,1] to [0,2] [1,1] to [1,2]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
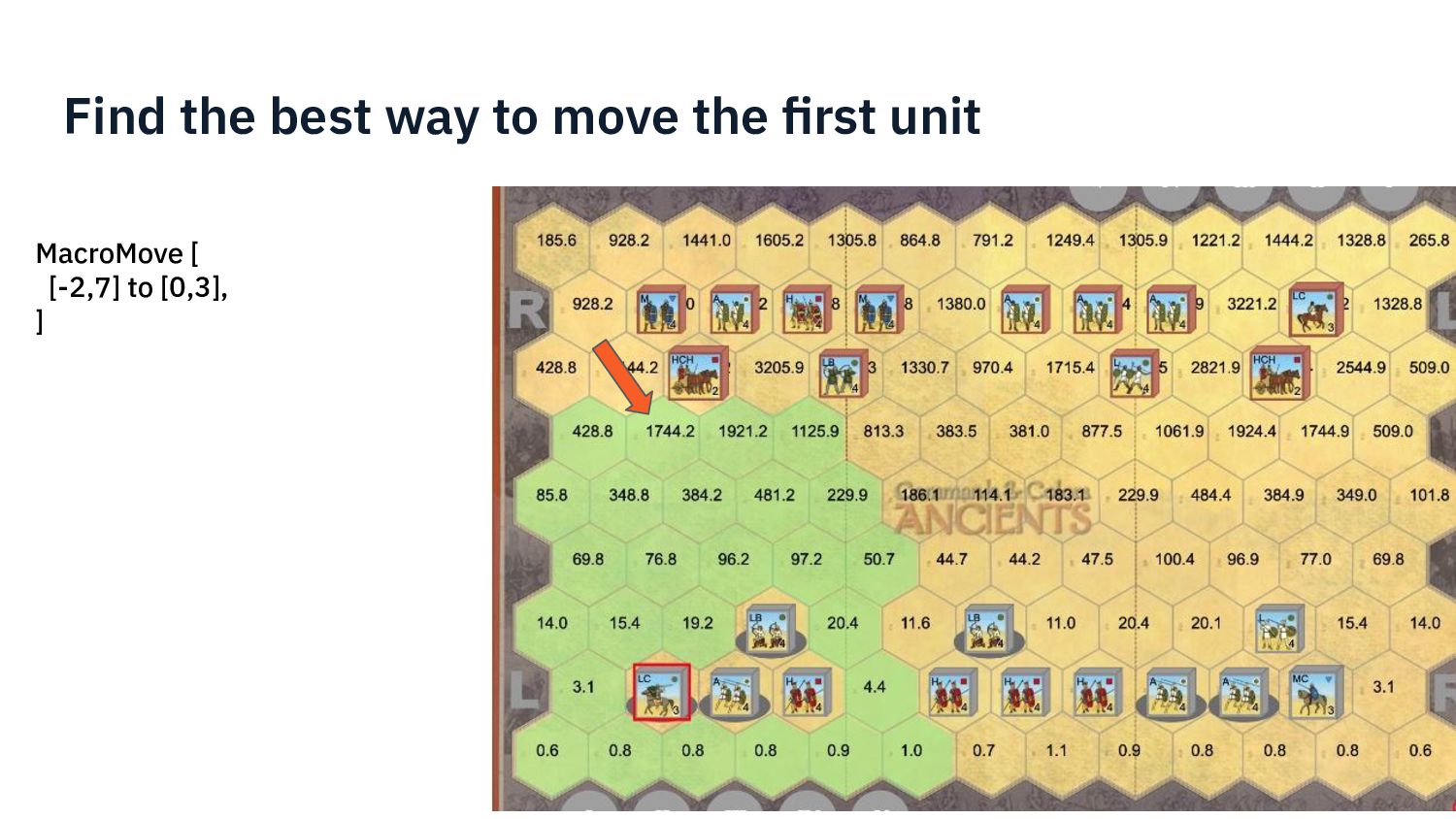{kind=link}
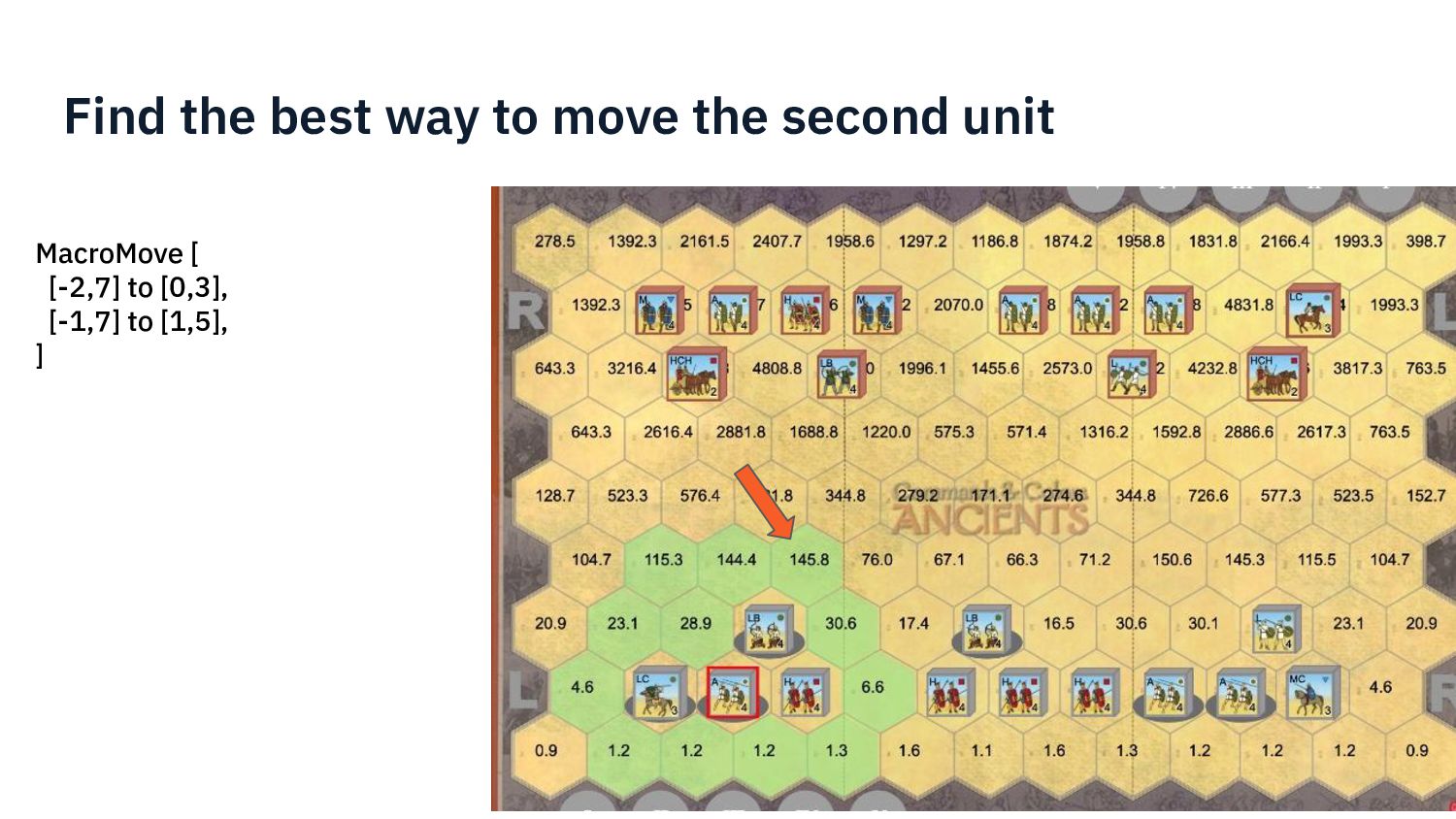{kind=link}
![Etc. MacroMove [ [-2,7] to [0,3], [-1,7] to [1,5], [0,6]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_60.jpg){kind=link}
![Etc. MacroMove [ [-2,7] to [0,3], [-1,7] to [1,5], [0,6]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_61.jpg){kind=link}
![Etc. MacroMove [ [-2,7] to [0,3], [-1,7] to [1,5], [0,6]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_62.jpg){kind=link}
![Etc. MacroMove [ [-2,7] to [0,3], [-1,7] to [1,5], [0,6]](https://files.speakerdeck.com/presentations/562908d03e804ebf96c7f73f5855d573/slide_63.jpg){kind=link}
{kind=link}
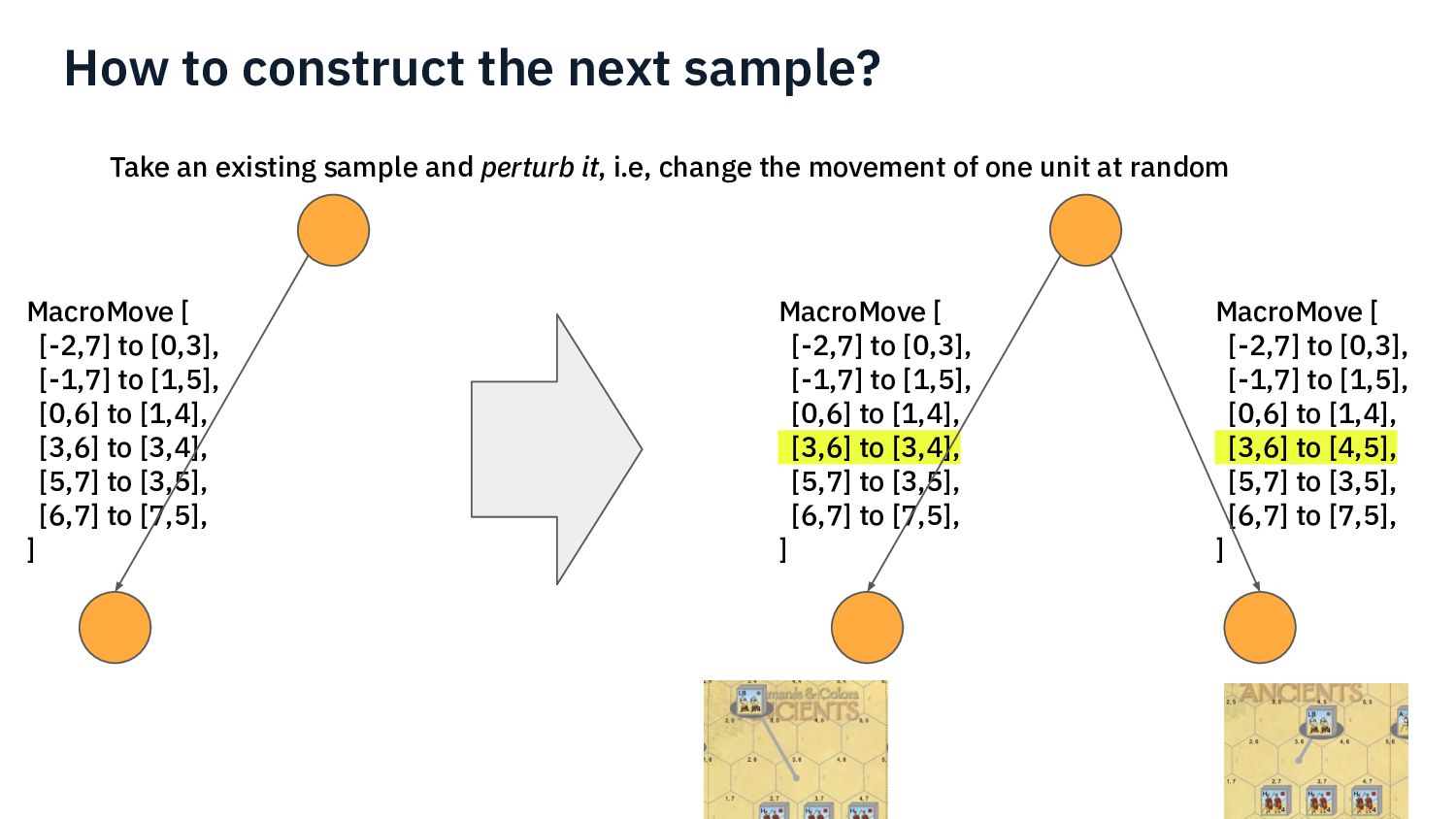{kind=link}
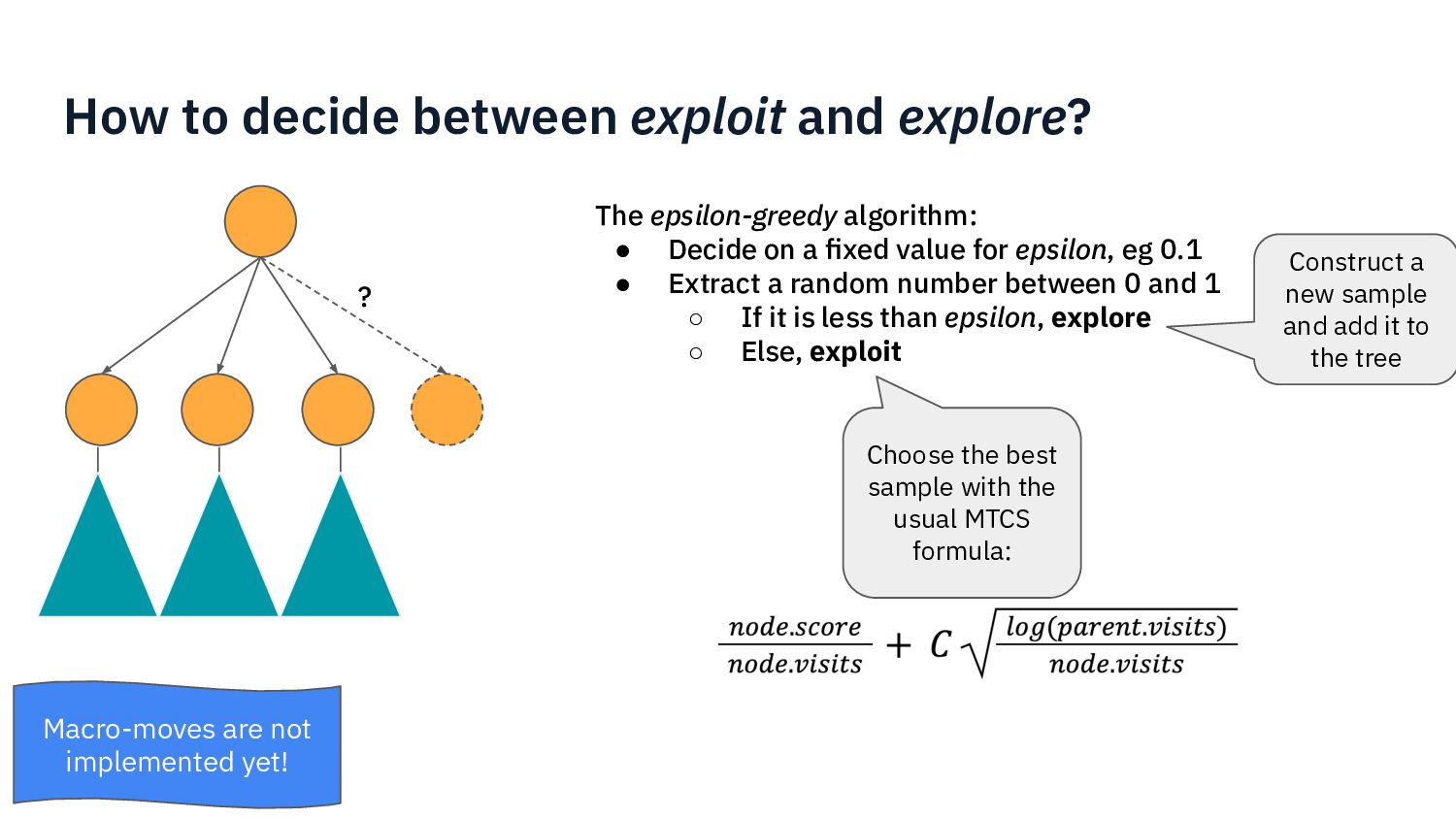{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}