interests: ◦ Artificial General Intelligence ◦ Reinforcement Learning ◦ Neural Network Architecture Design • Currently, An Master Student in CSIE, National Cheng Kung University, Taiwan. • LinkedIn: link 2
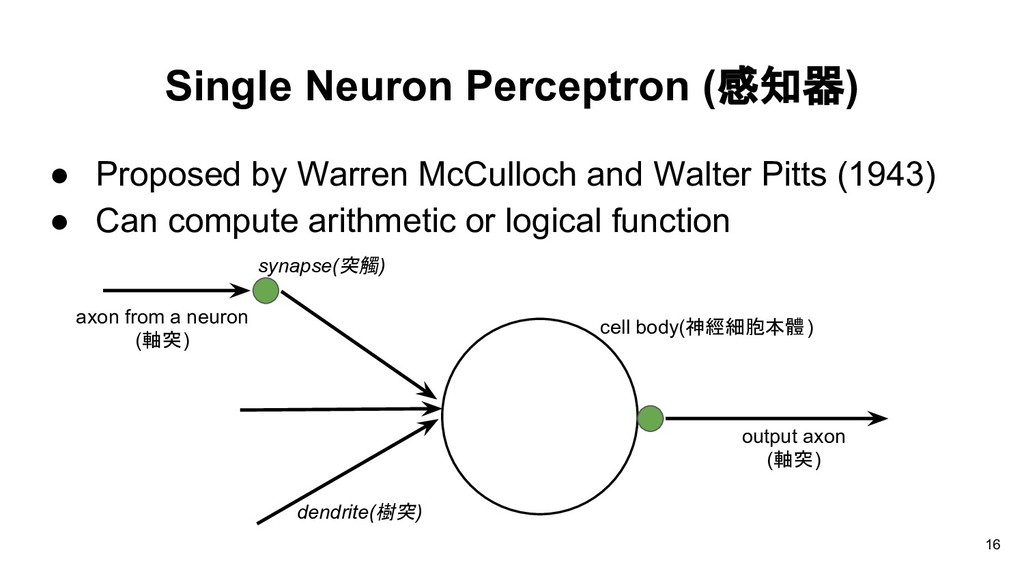
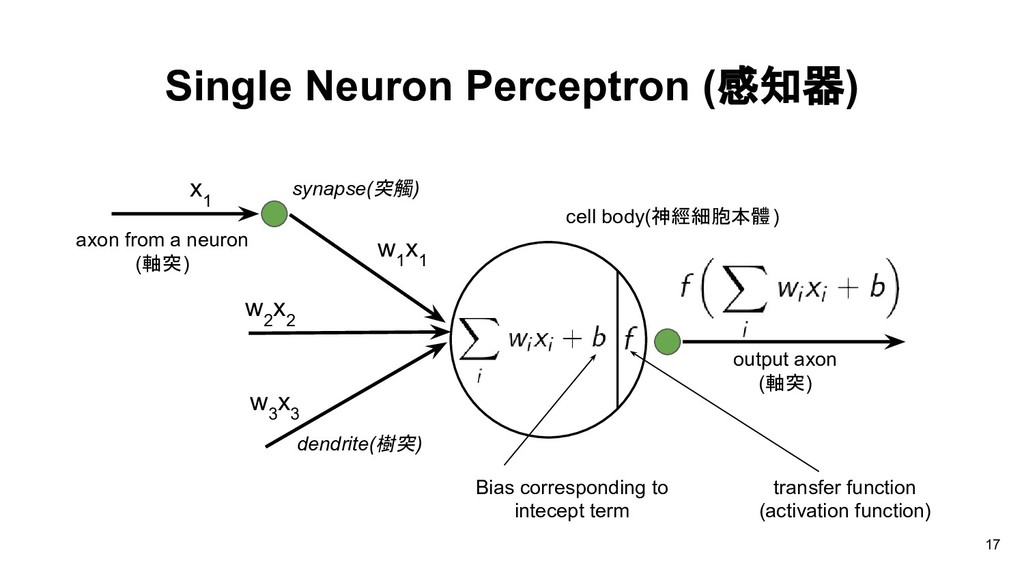
Walter Pitts (1943) • Can compute arithmetic or logical function axon from a neuron (軸突) synapse(突觸) dendrite(樹突) output axon (軸突) cell body(神經細胞本體) 16
x 3 x 1 axon from a neuron (軸突) synapse(突觸) w 1 x 1 dendrite(樹突) cell body(神經細胞本體) output axon (軸突) Bias corresponding to intecept term transfer function (activation function) 17
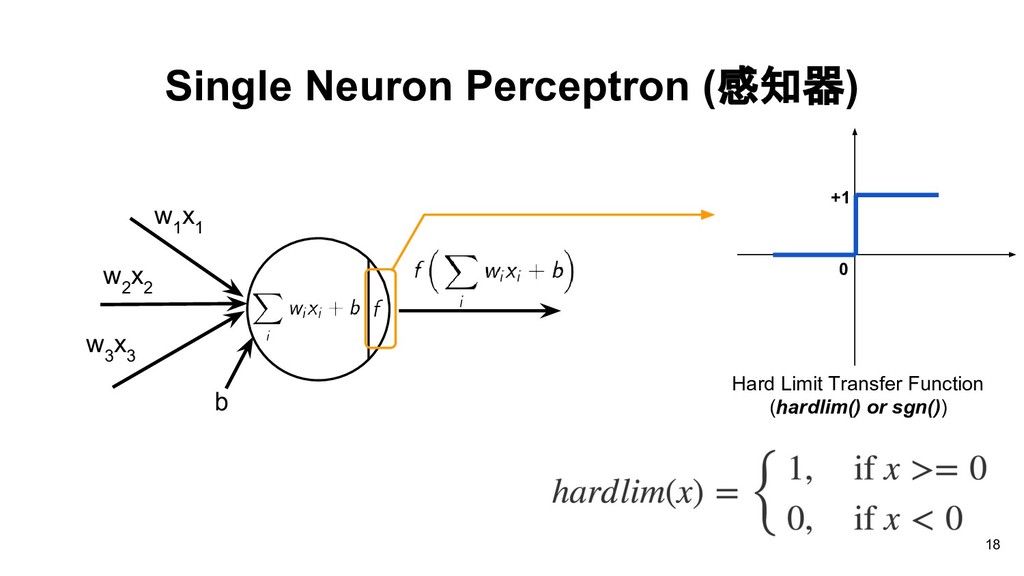
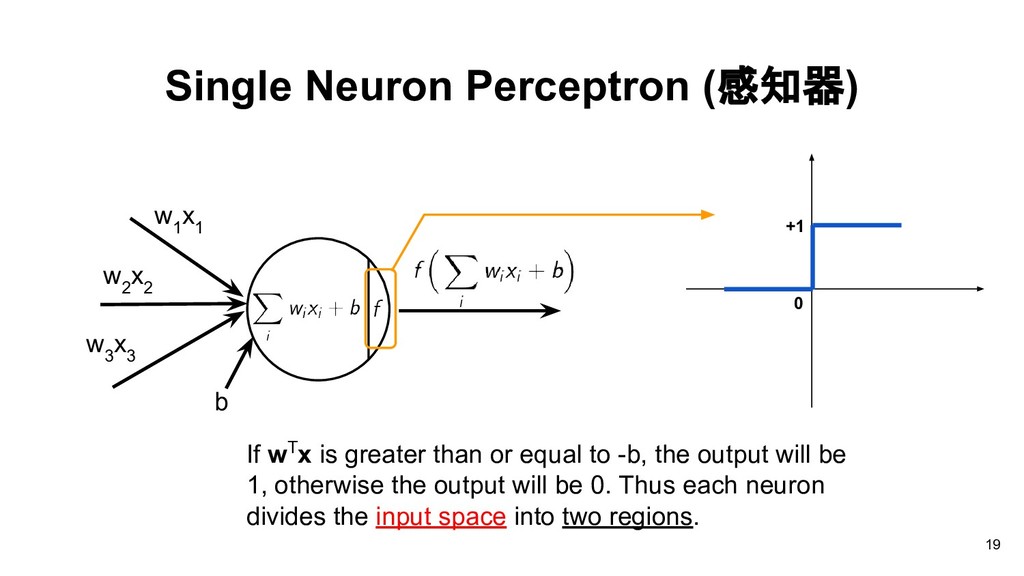
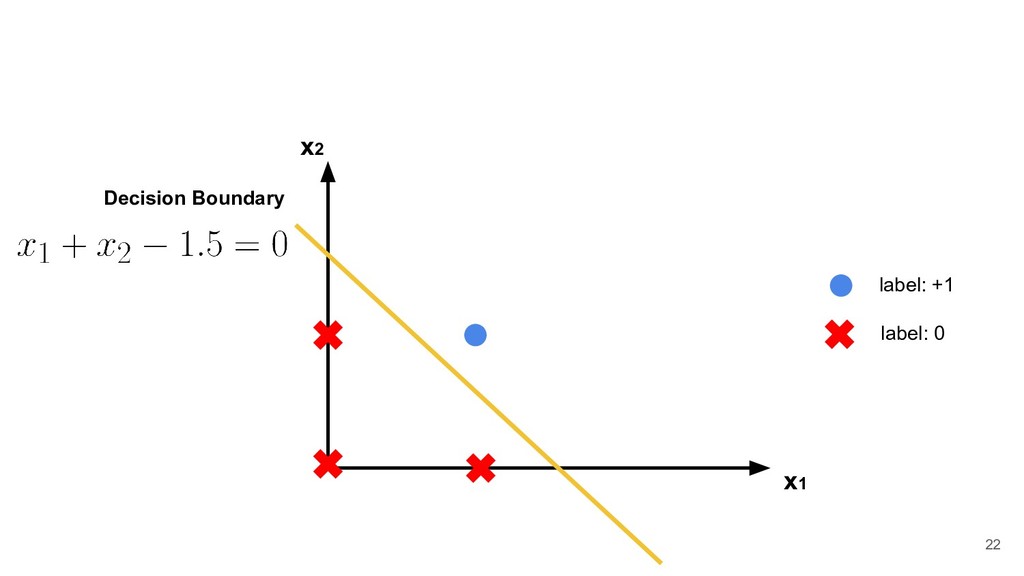
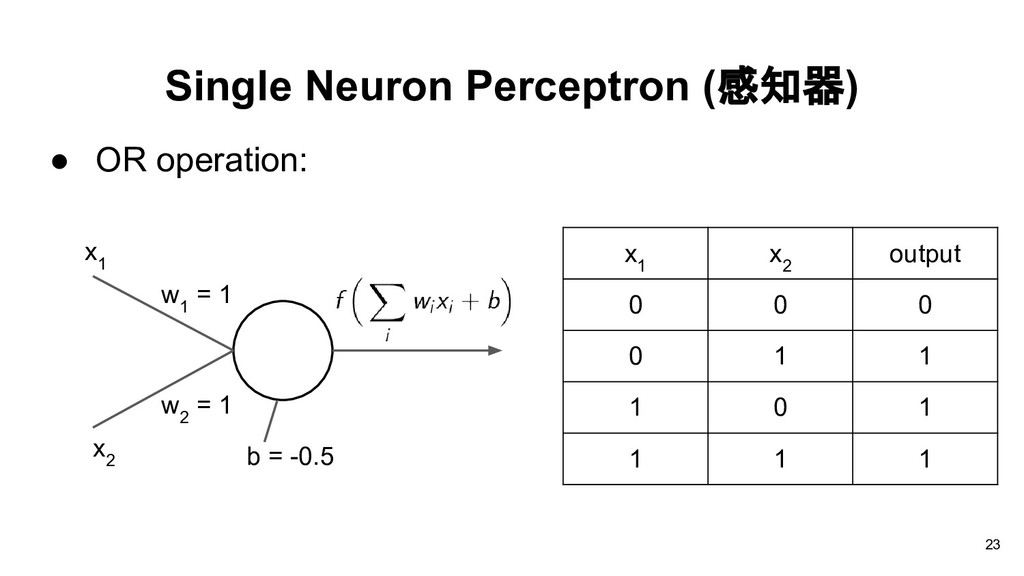
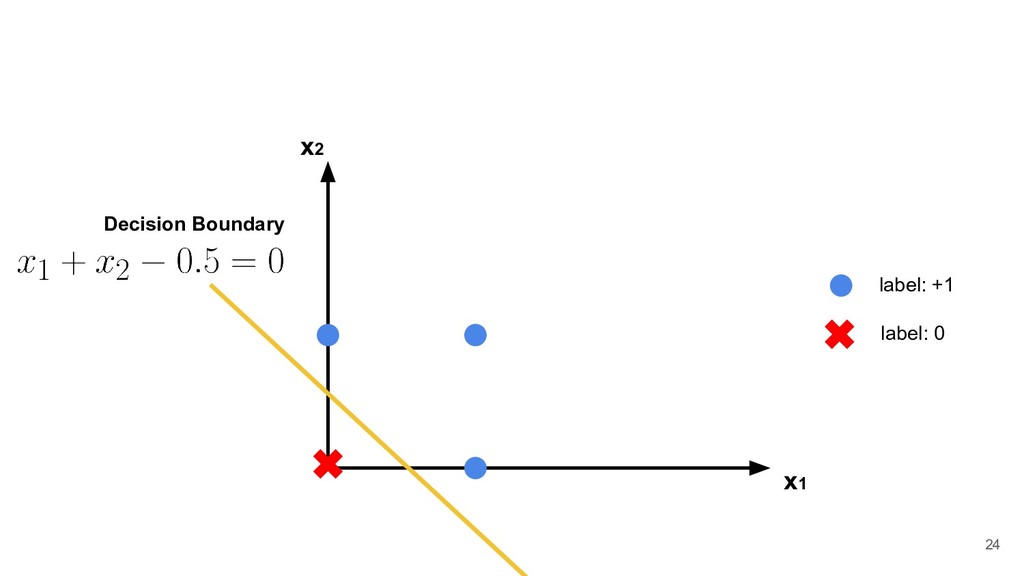
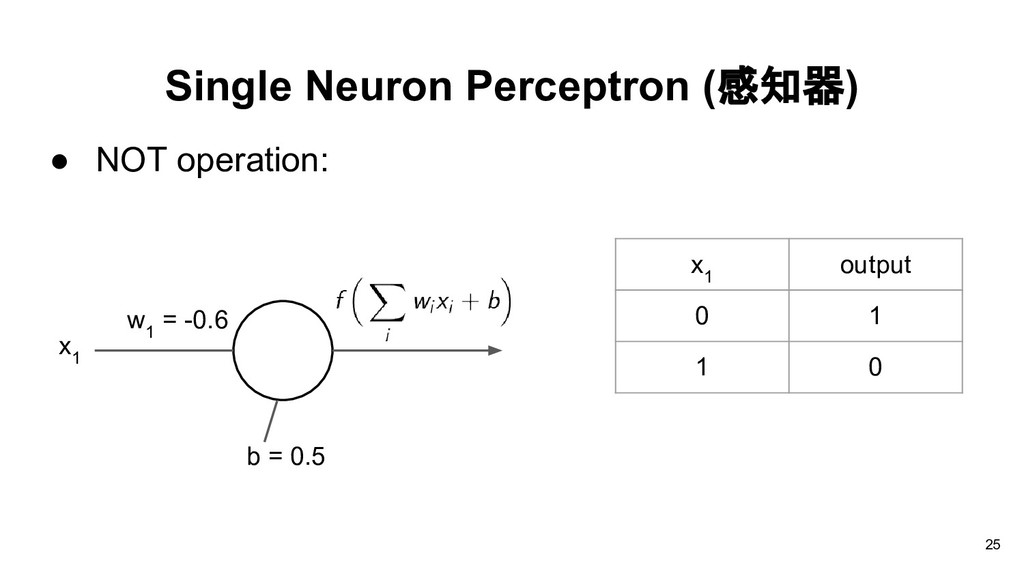
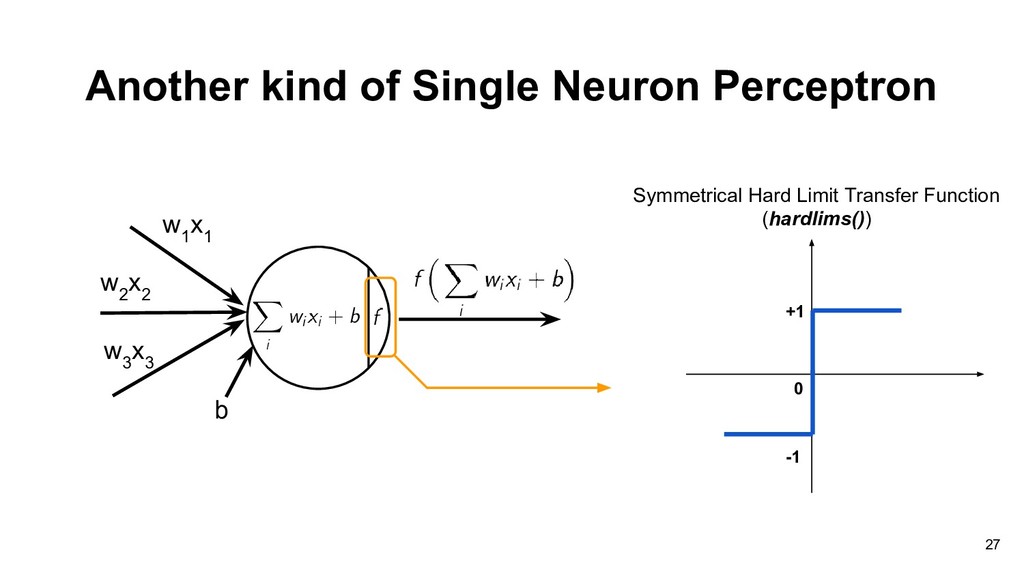
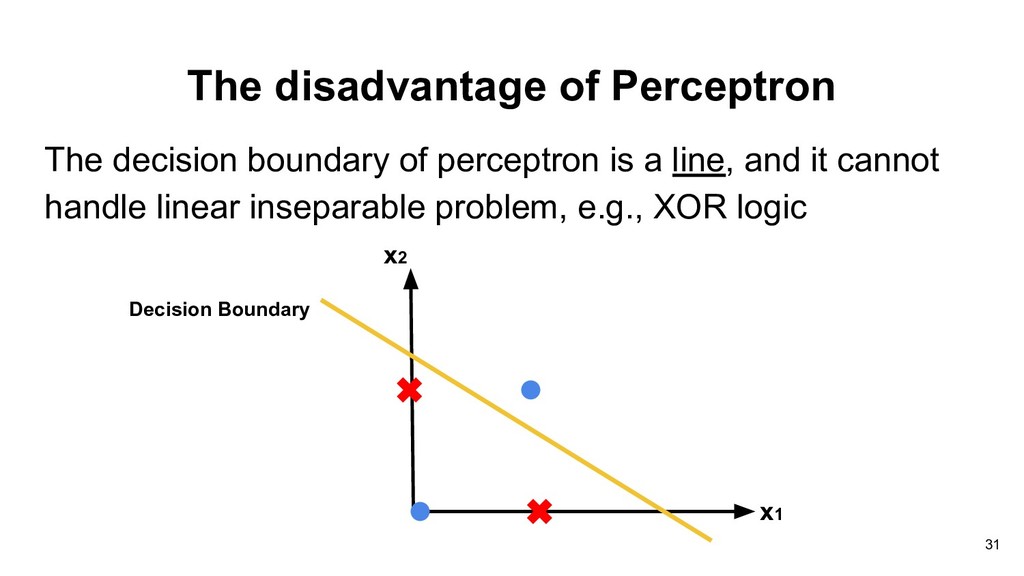
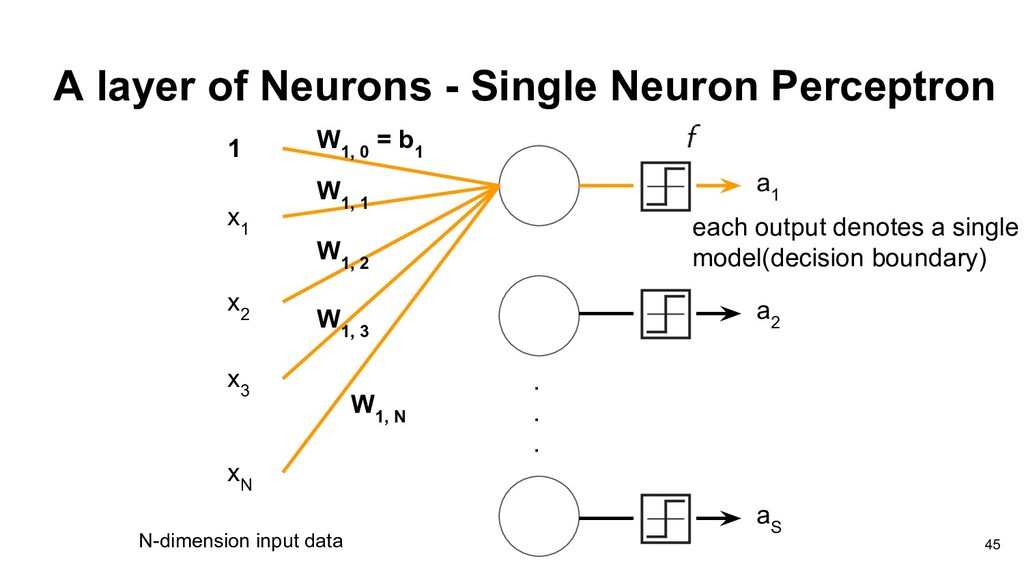
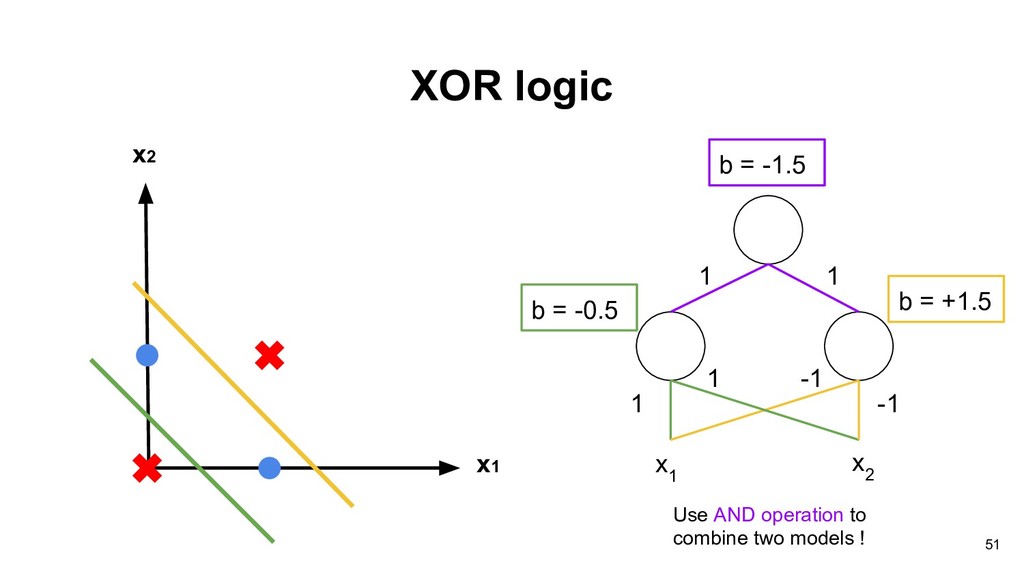
than or equal to -b, the output will be 1, otherwise the output will be 0. Thus each neuron divides the input space into two regions. w 1 x 1 w 2 x 2 w 3 x 3 b 19
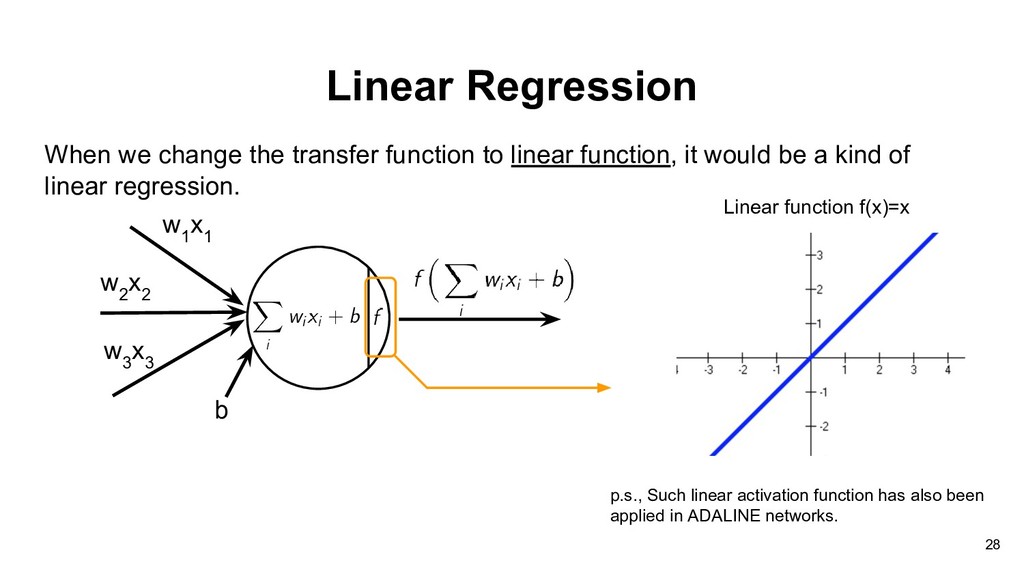
would be a kind of linear regression. Linear Regression Linear function f(x)=x p.s., Such linear activation function has also been applied in ADALINE networks. w 2 x 2 w 3 x 3 w 1 x 1 b 28
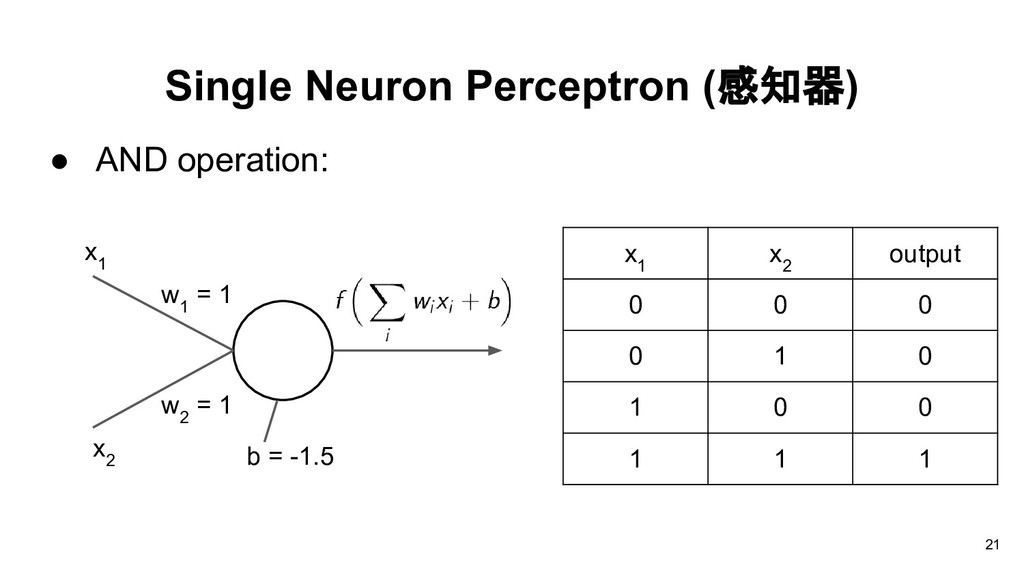
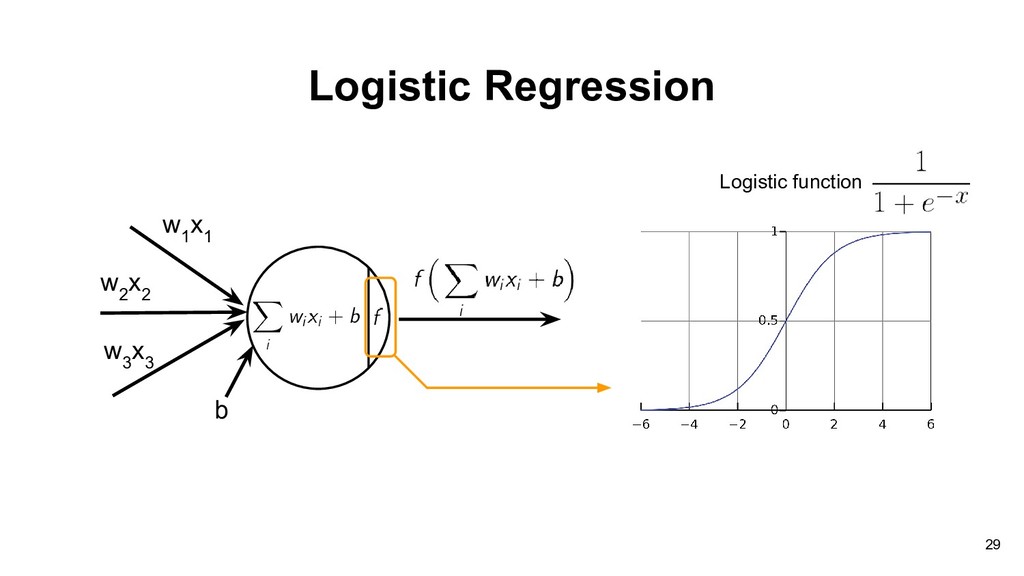
Algorithm(PLA) here. if you have strong interest about the learning algorithm, just notice that the learning algorithm would be different with different transfer functions, hardlim and hardlims. • hardlim: see the details in “Neural network design” in Chapter4 (formula 4.34, 4.35) • hardlims: see the details in “Learning from data” in Chapter1 (formula 1.3) • You also can write down the loss function and use derivative to derive the learning algorithm. 30
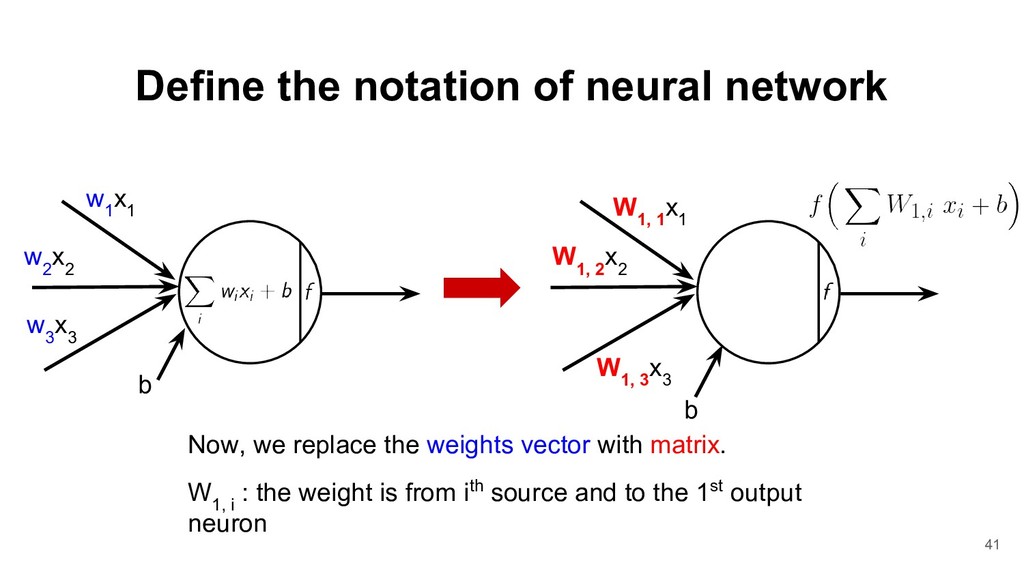
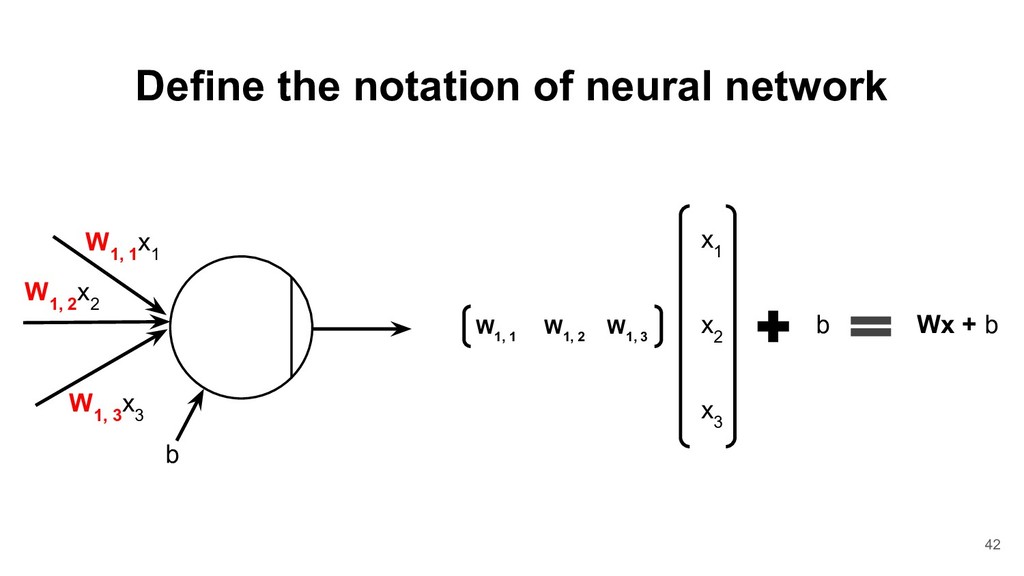
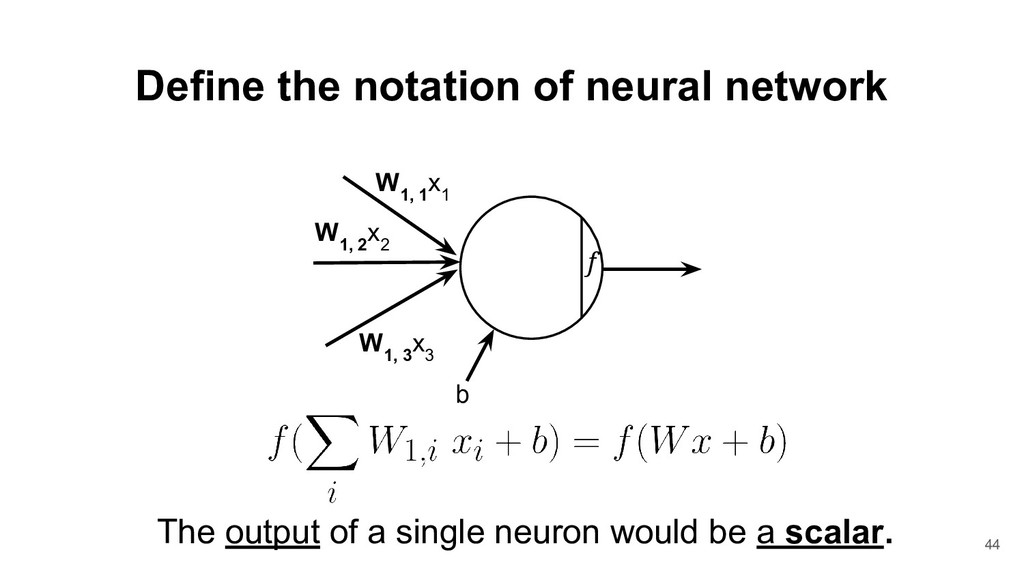
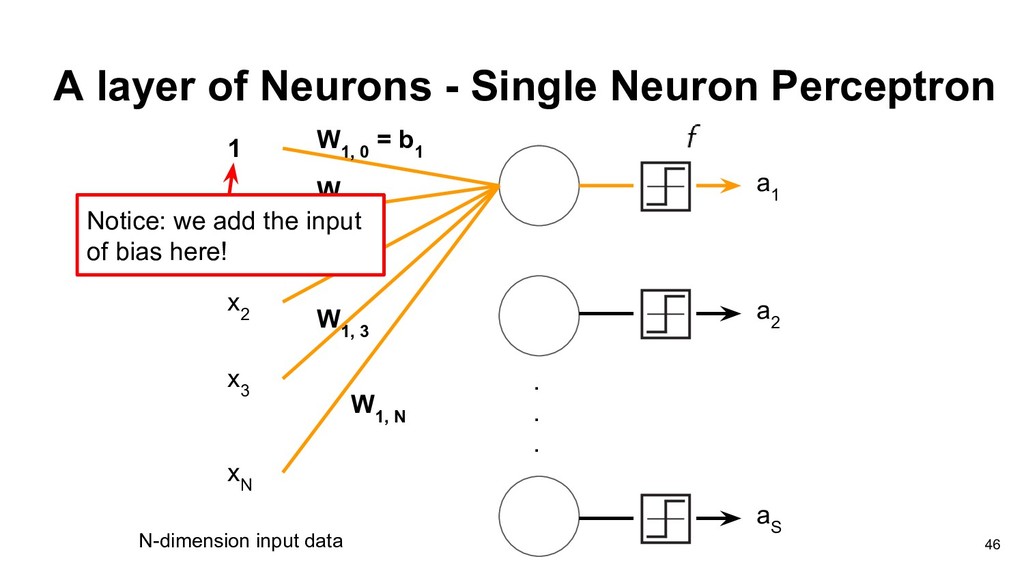
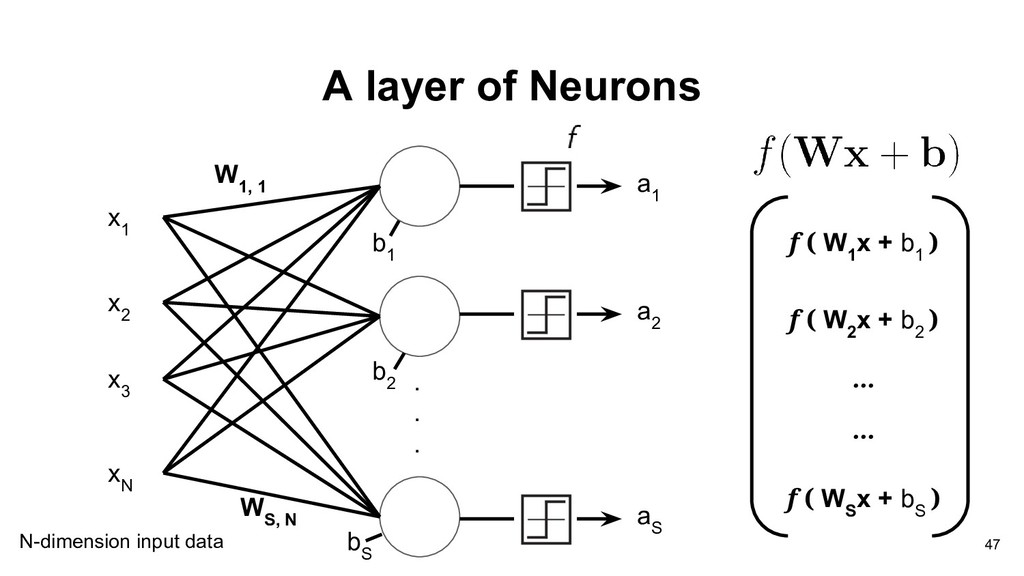
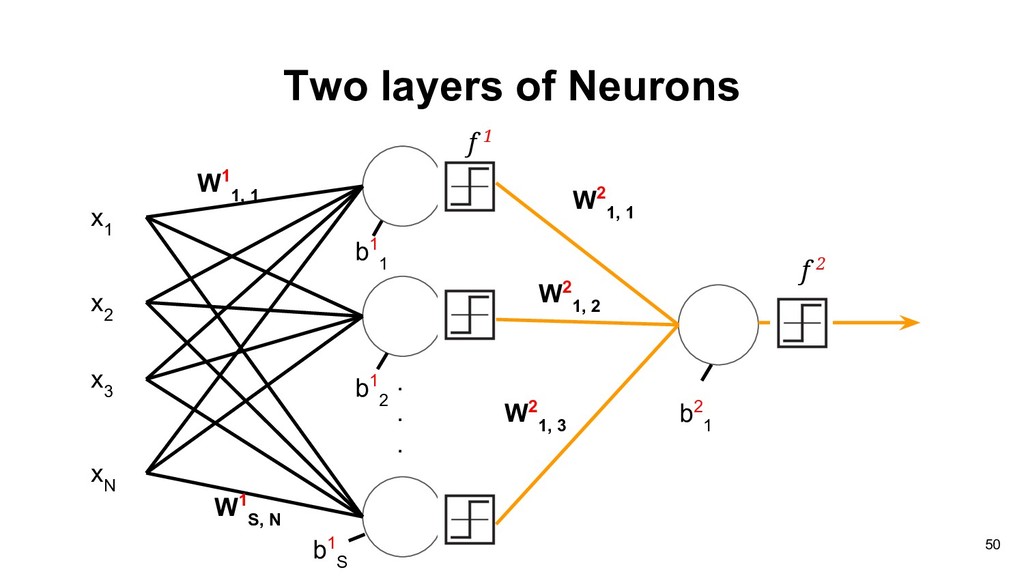
2 W 1, 3 x 3 W 1, 1 x 1 Now, we replace the weights vector with matrix. W 1, i : the weight is from ith source and to the 1st output neuron b w 2 x 2 w 3 x 3 w 1 x 1 b 41
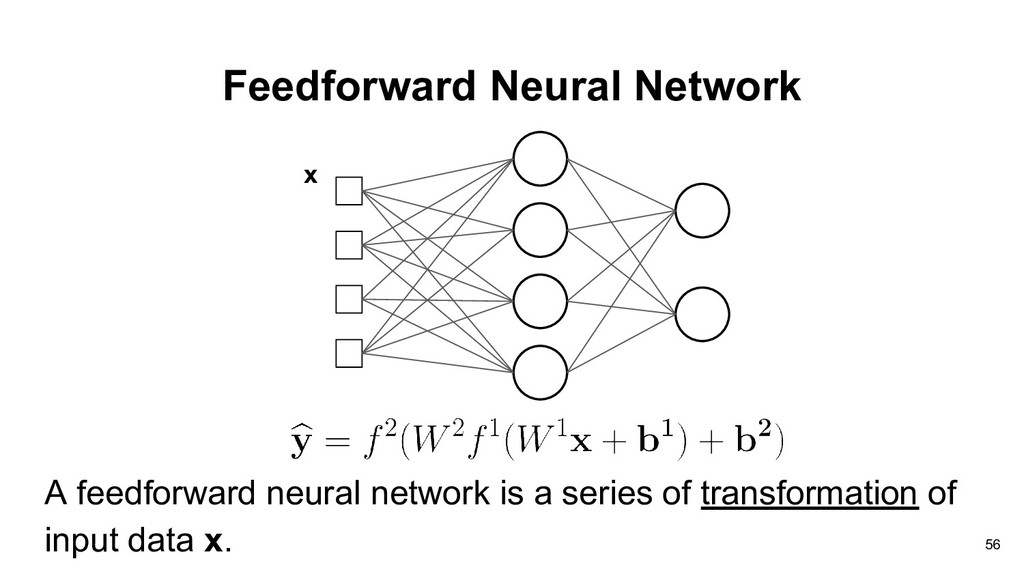
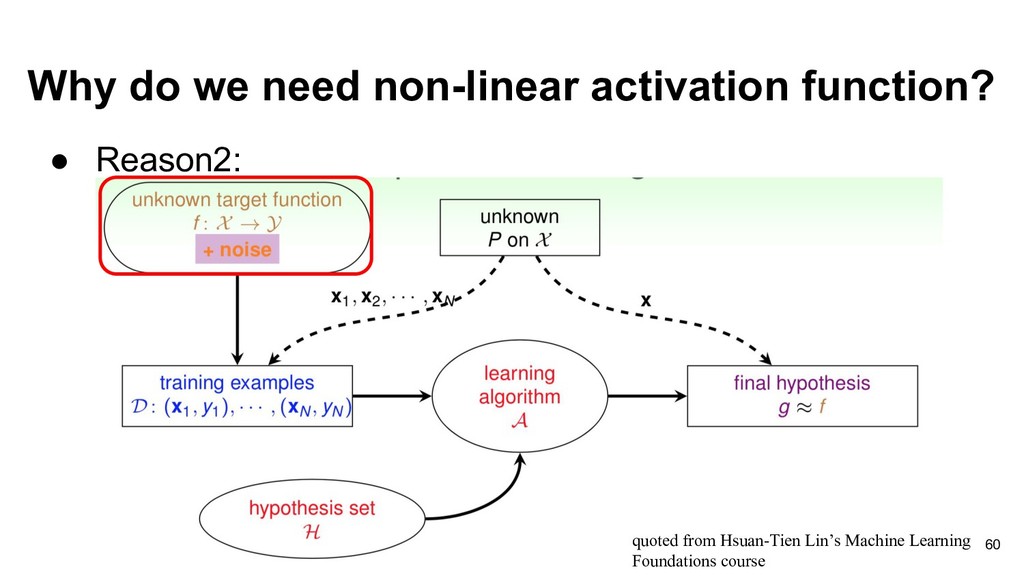
neural network is a function approximator to approximate the ideal target function f target in machine learning. The target function f target may be complicated (non-linear). 59
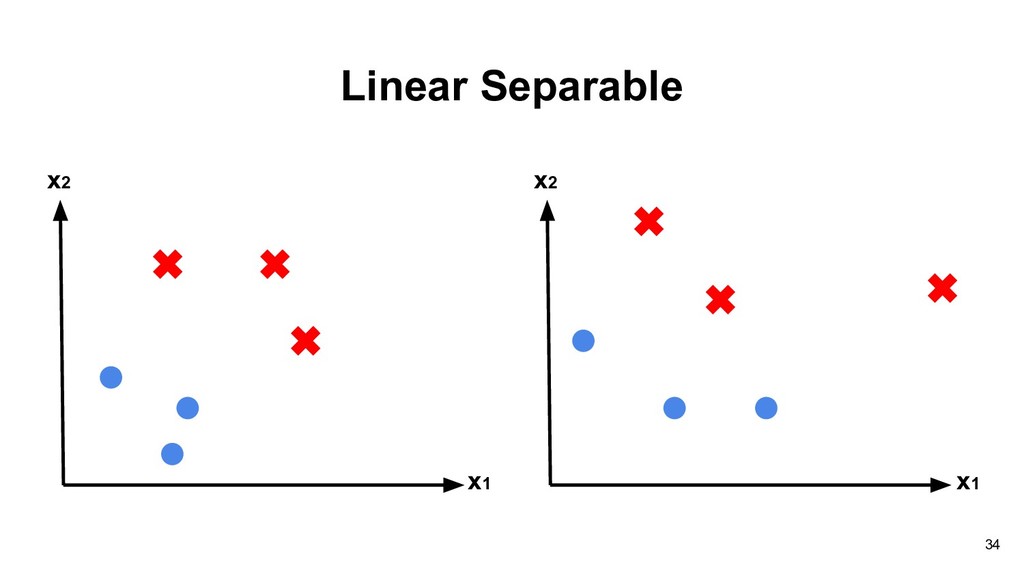
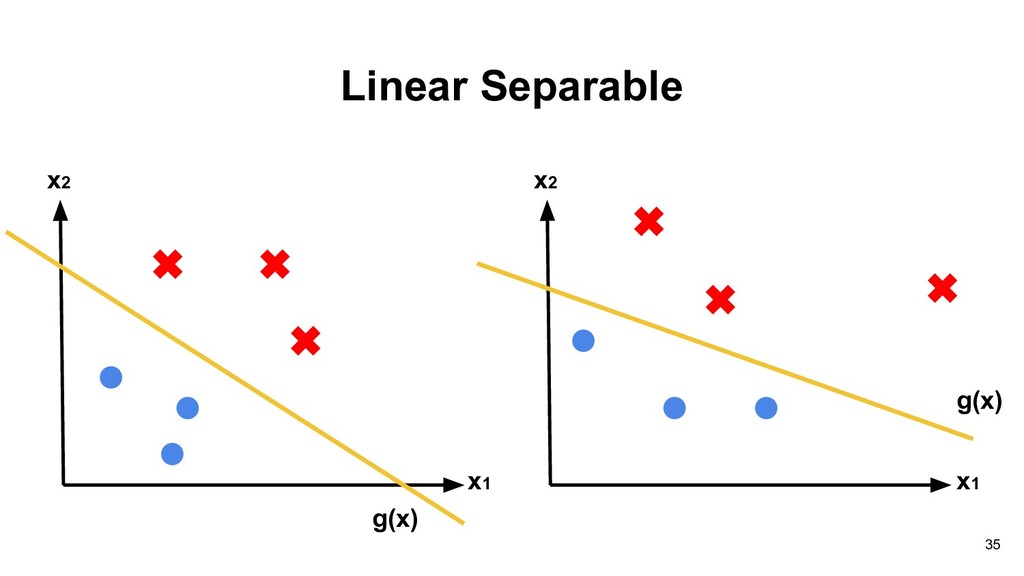
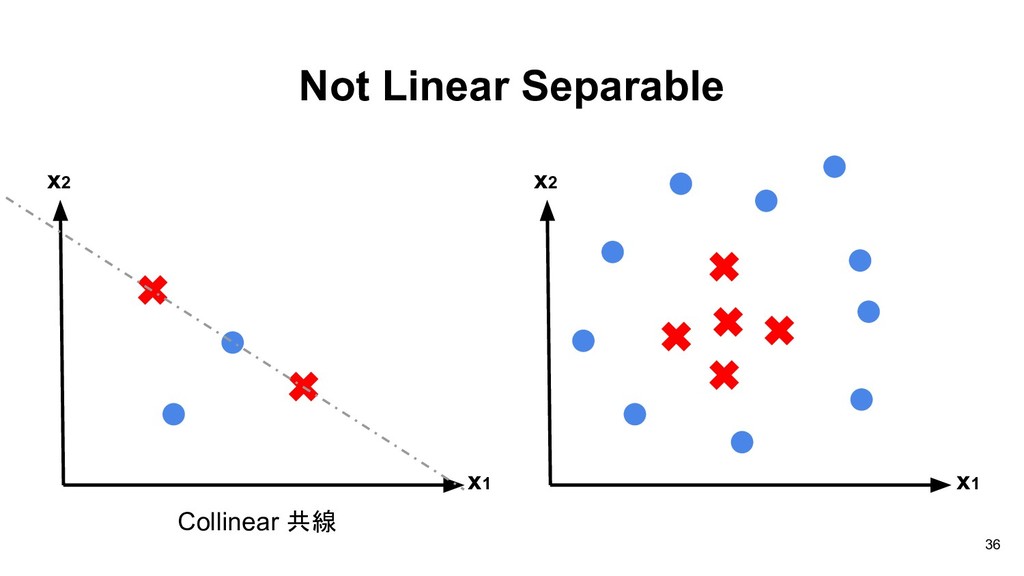
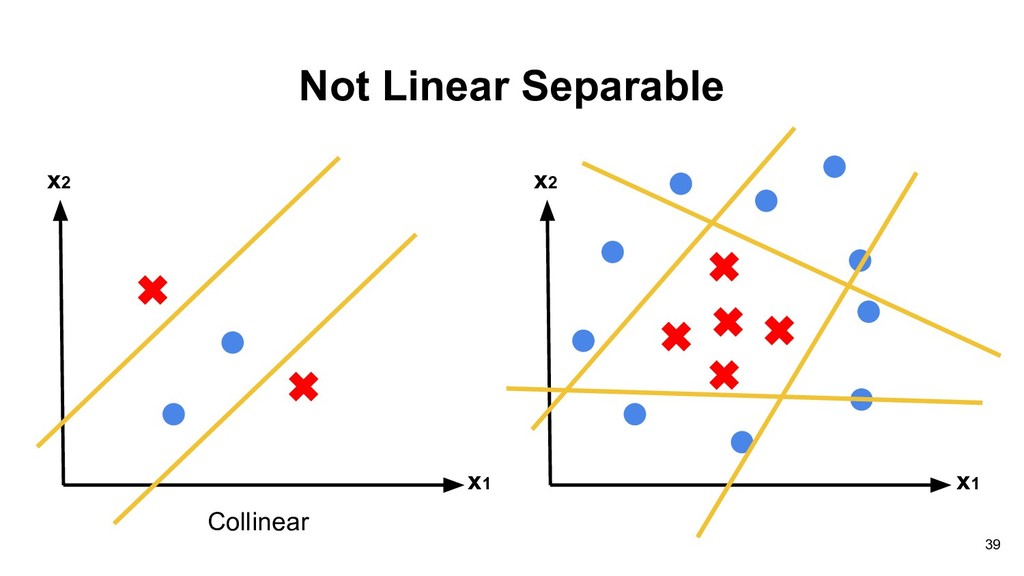
Lecture The Deep Learning Revolution” in JSM 2018 and you can play with ConvnetJS: https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html 63
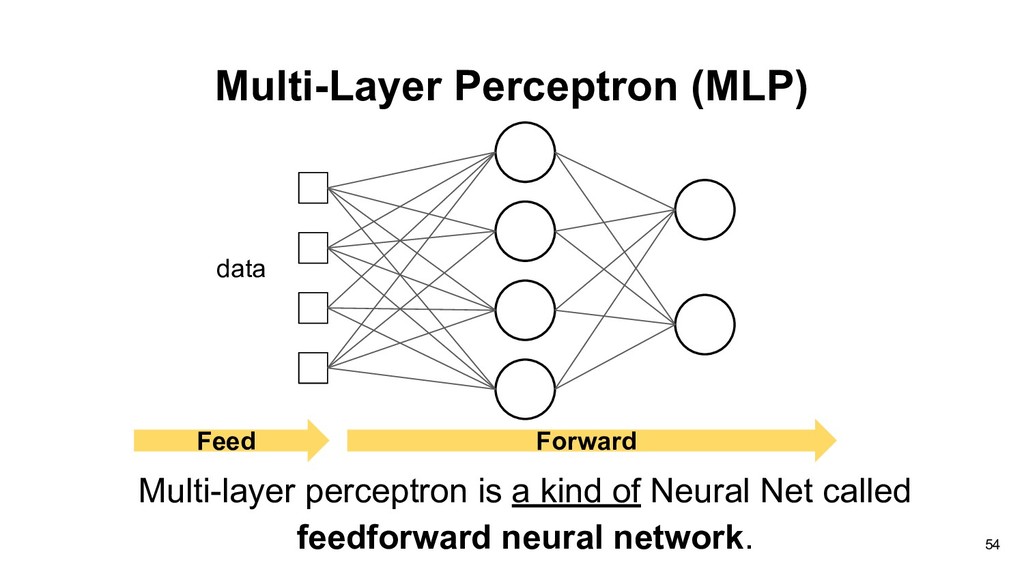
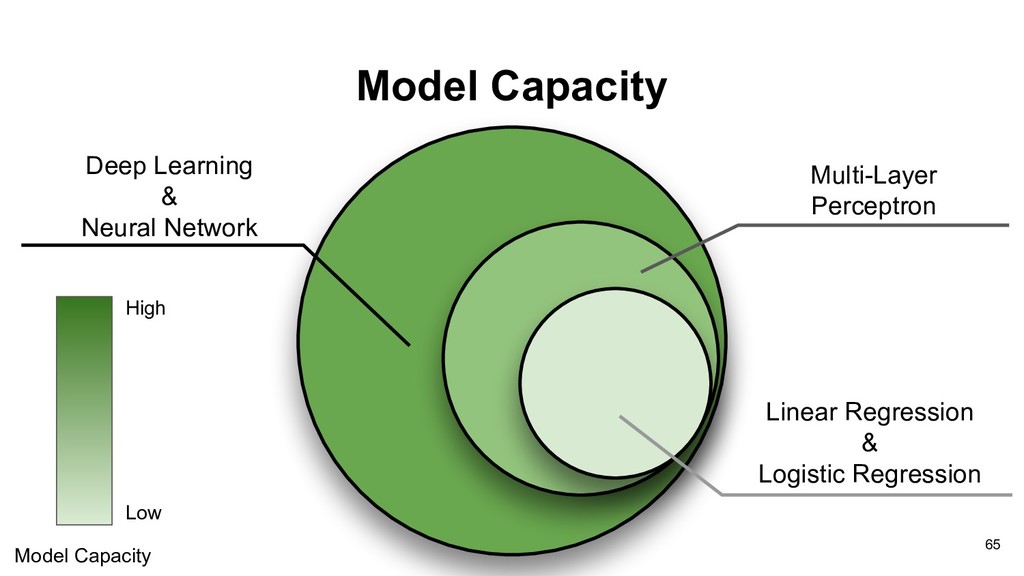
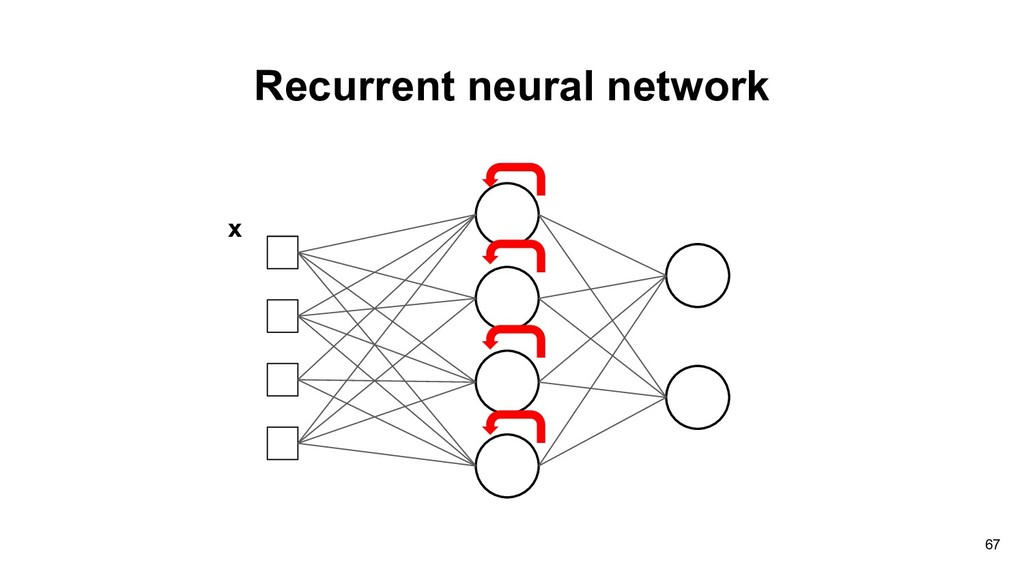
network • Recurrent neural network • Radial basis function network • Memory neural network • ... There are all called Deep Learning in this era, because of using deep hidden layers. 66
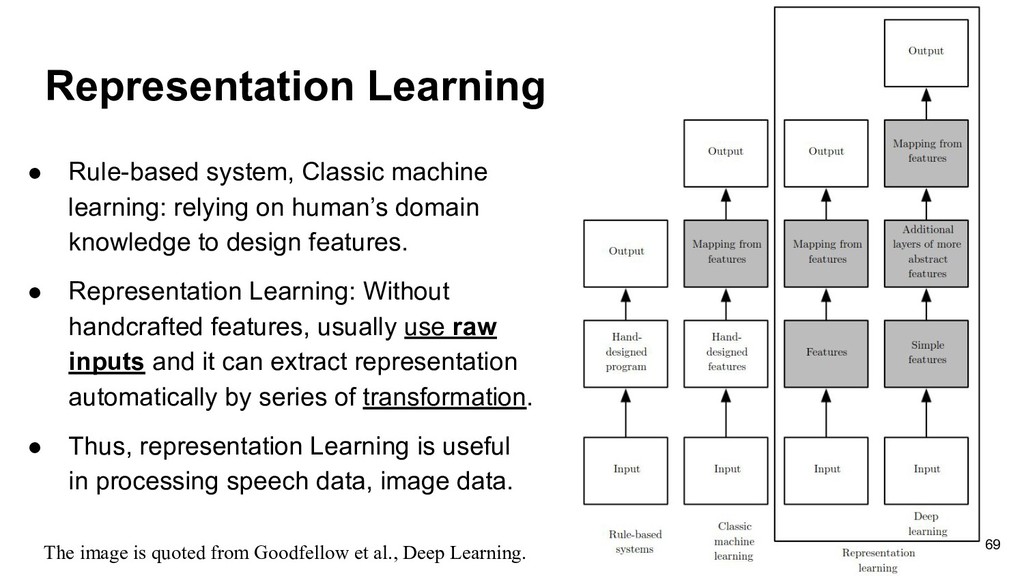
human’s domain knowledge to design features. • Representation Learning: Without handcrafted features, usually use raw inputs and it can extract representation automatically by series of transformation. • Thus, representation Learning is useful in processing speech data, image data. The image is quoted from Goodfellow et al., Deep Learning. 69
machine learning, and we can learn the weights by optimization algorithm. Learning algorithms: • Gradient based method • Evolutionary method • ... We focus on this! 72
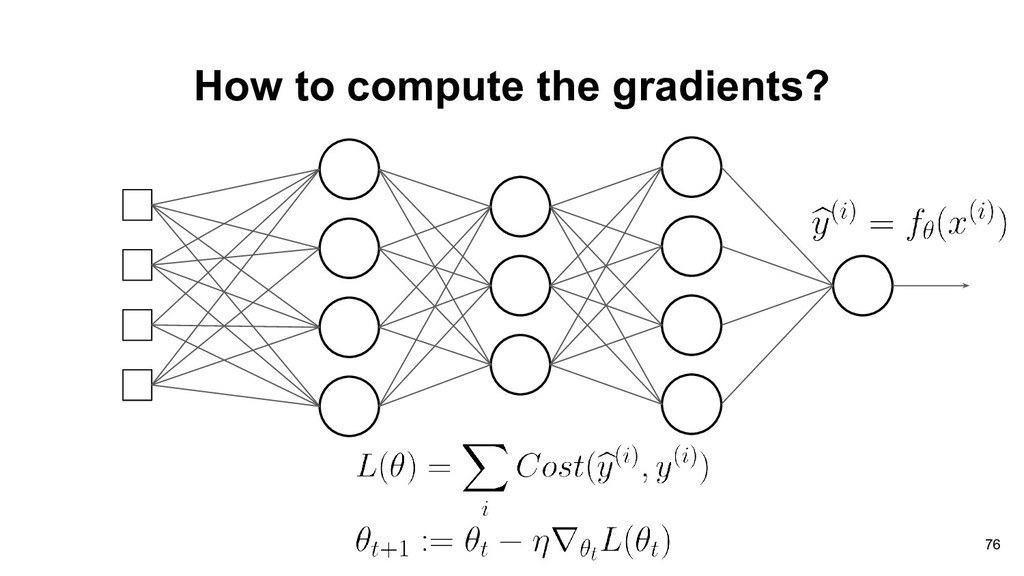
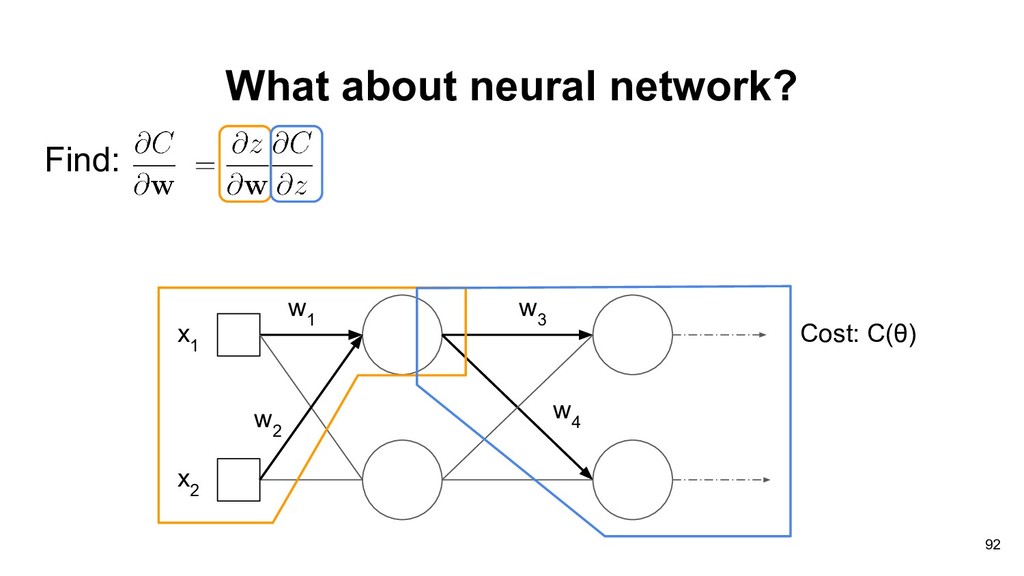
have learned that gradient descent can be used to optimize the learning model. Where J( ) is the objective function and denotes the parameters (weights) in the neural network. 73
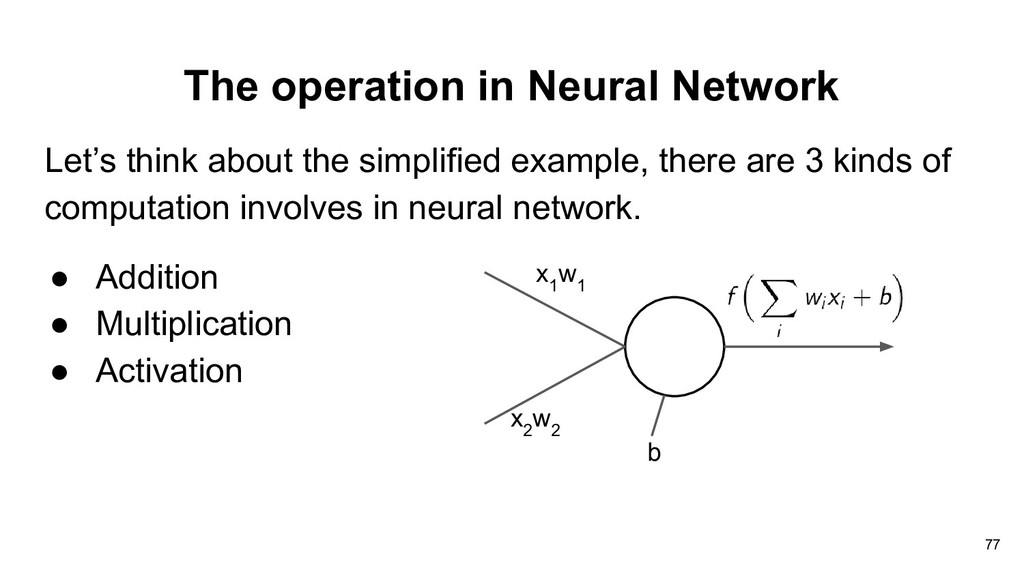
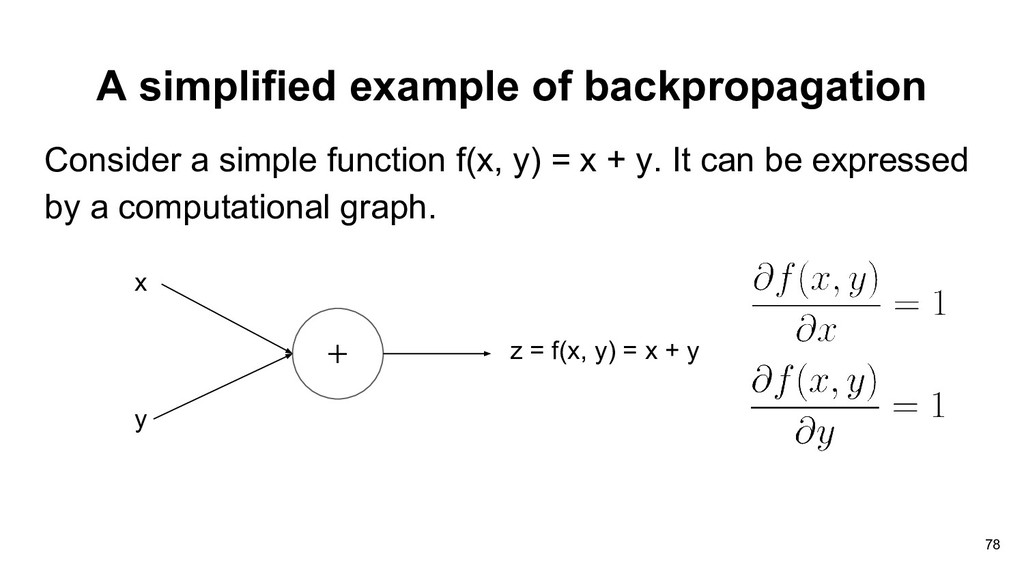
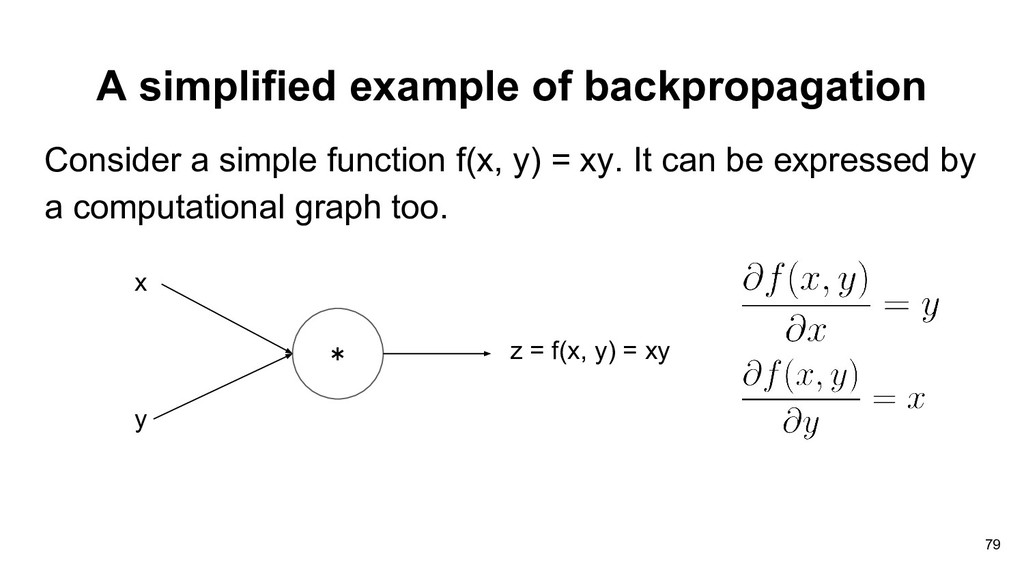
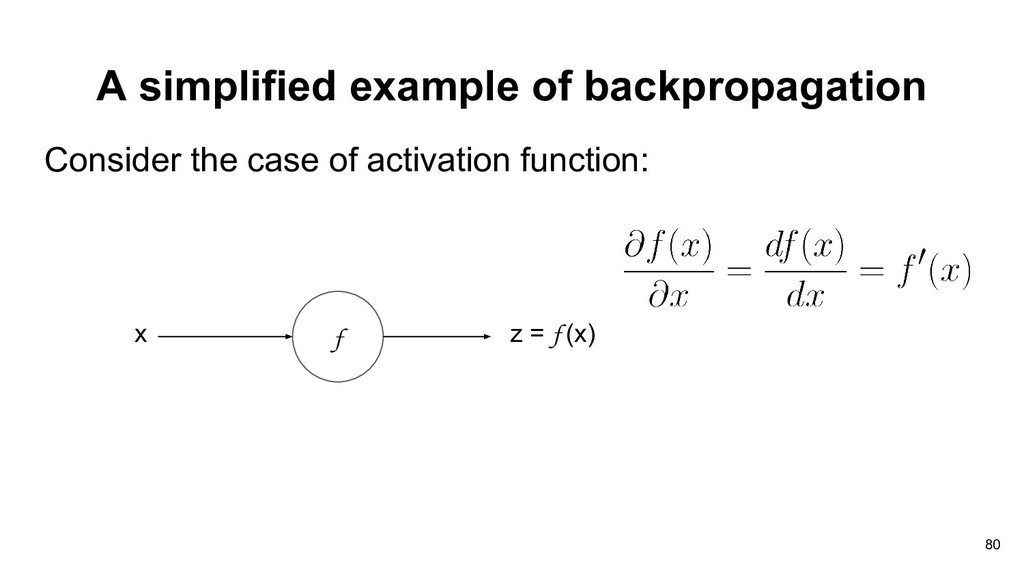
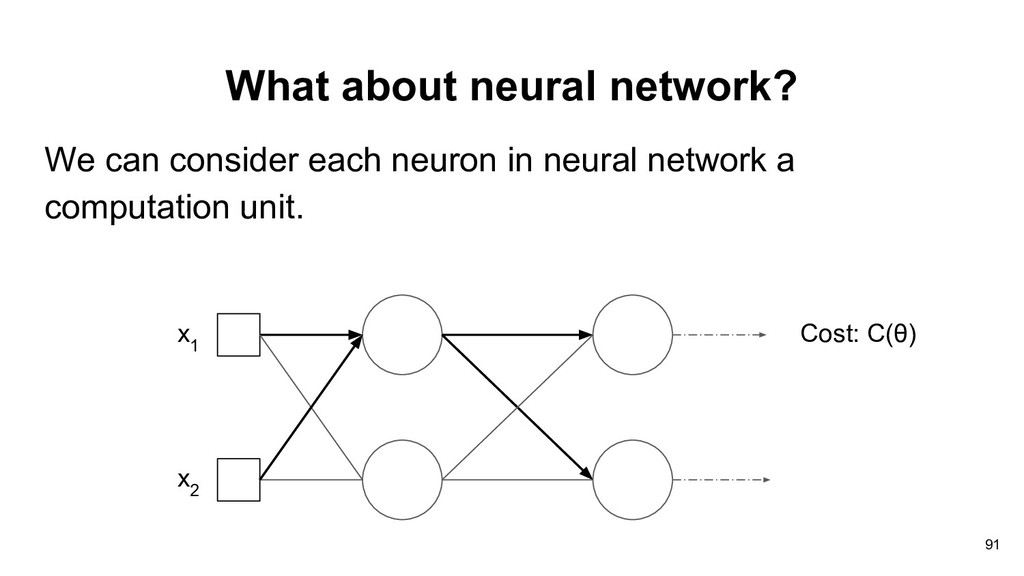
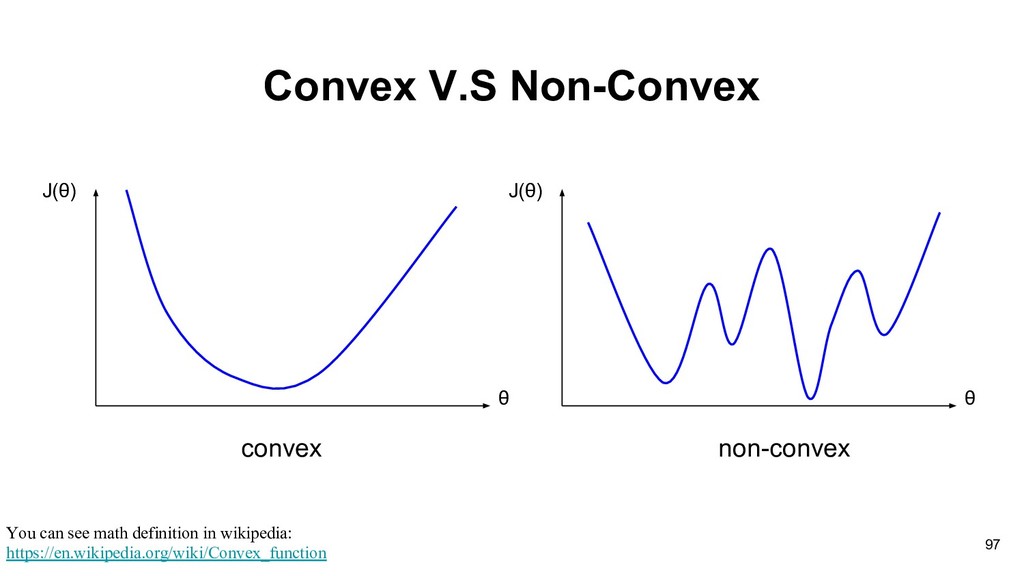
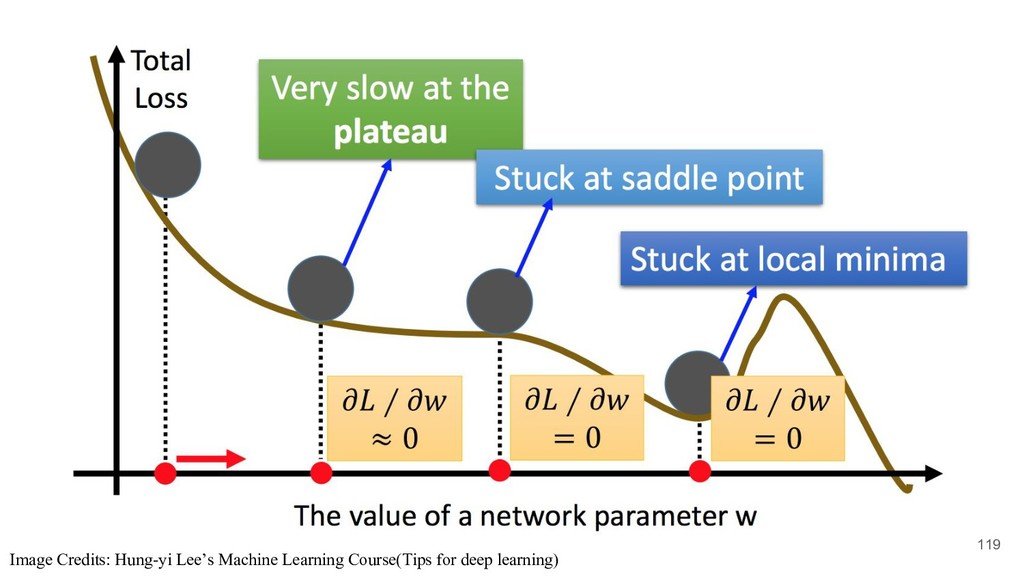
doing gradient descent in neural network. • How do we compute the gradients for the weights of each layer? • The landscape of loss function is probably not convex. 74
doing gradient descent in neural network. • How do we compute the gradients for the weights of each layer? • The landscape of loss function is probably not convex. 75
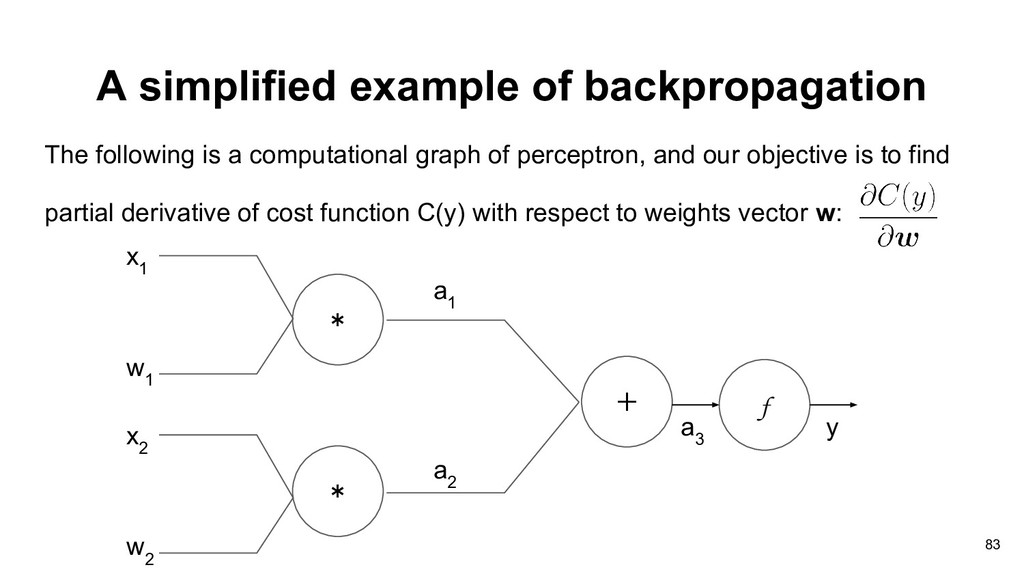
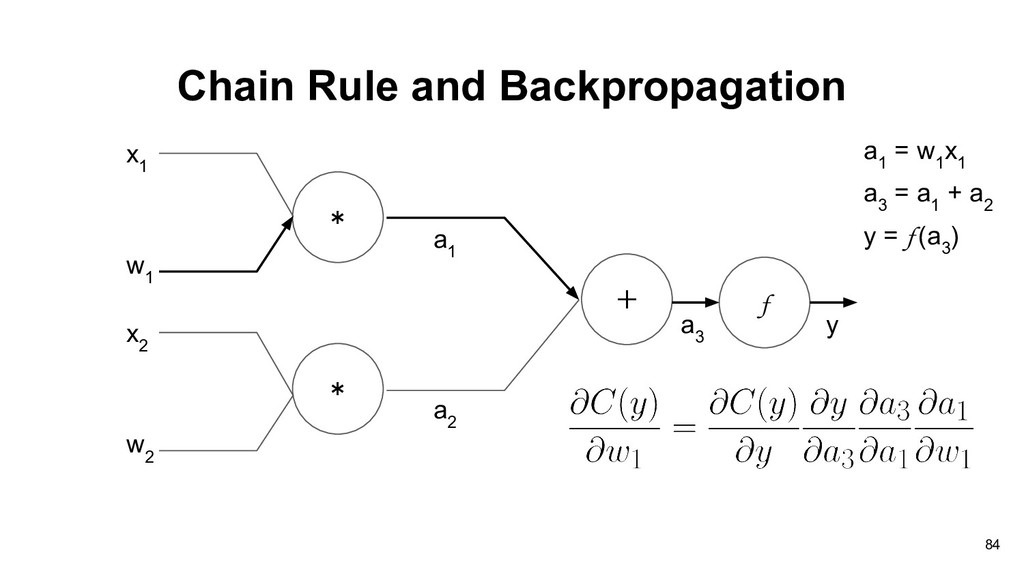
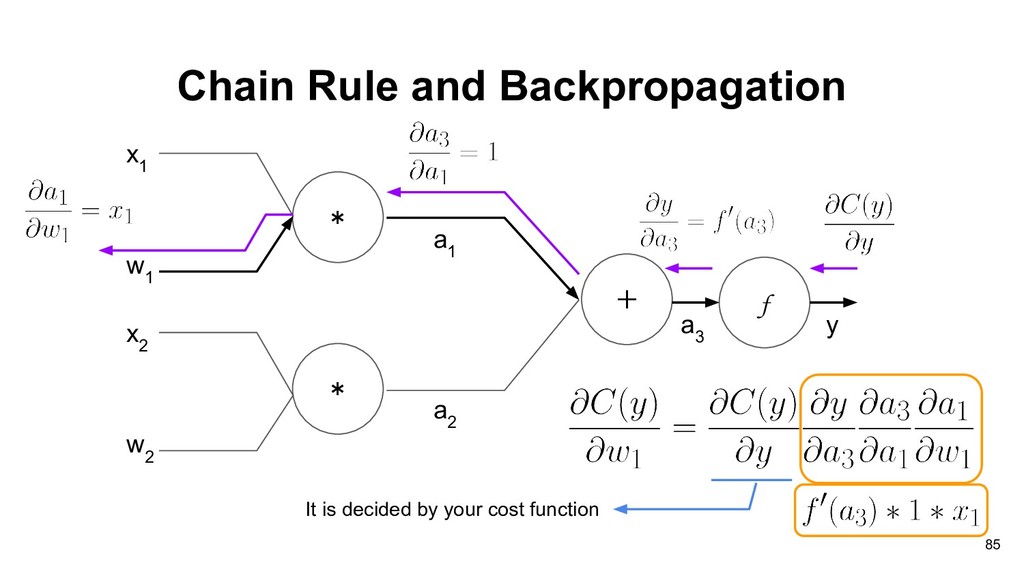
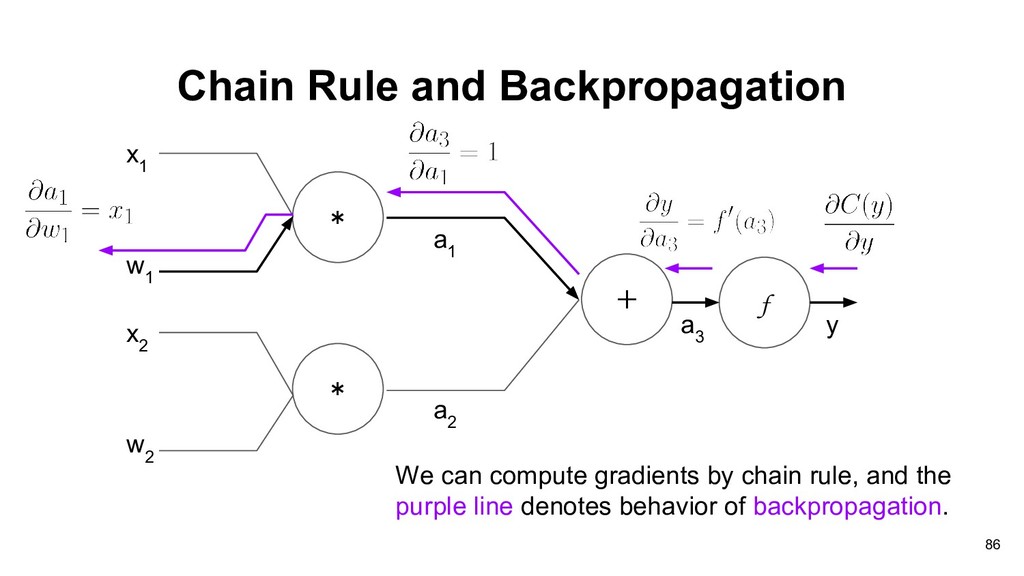
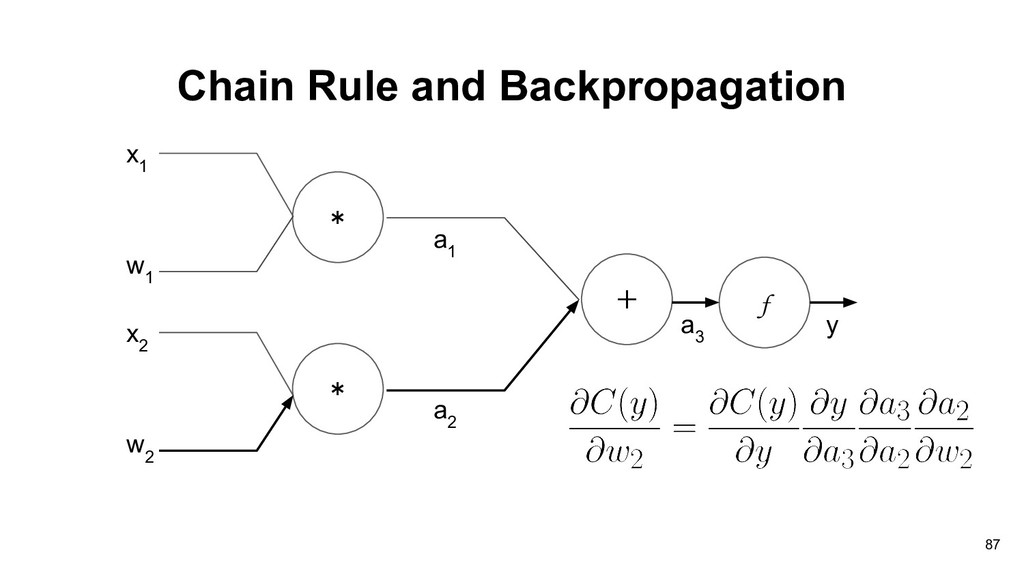
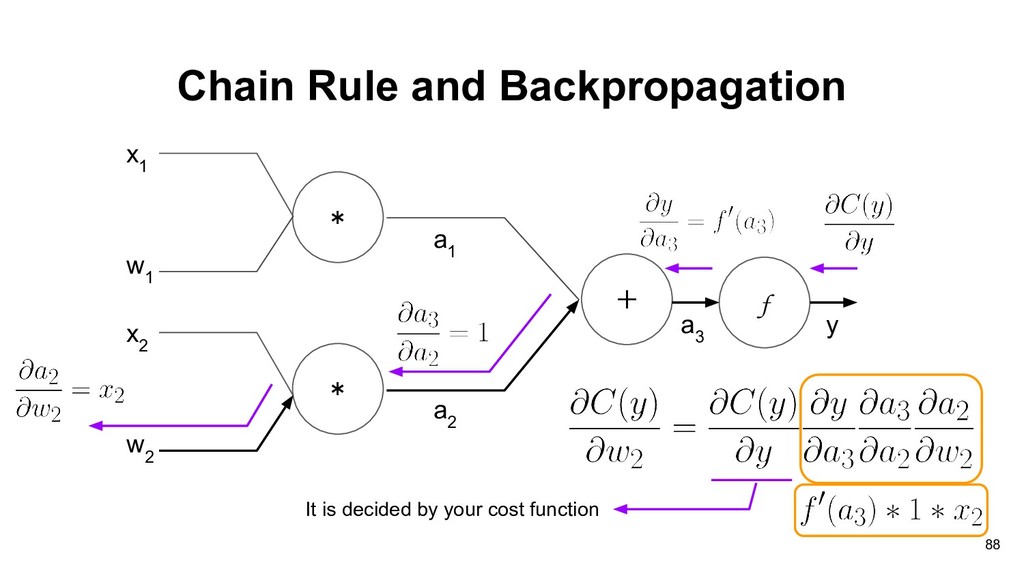
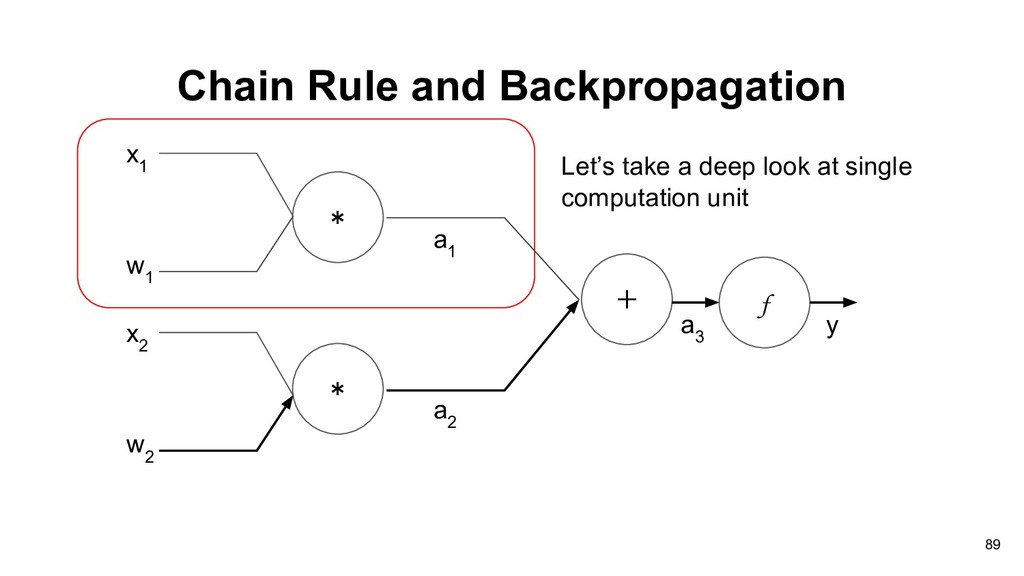
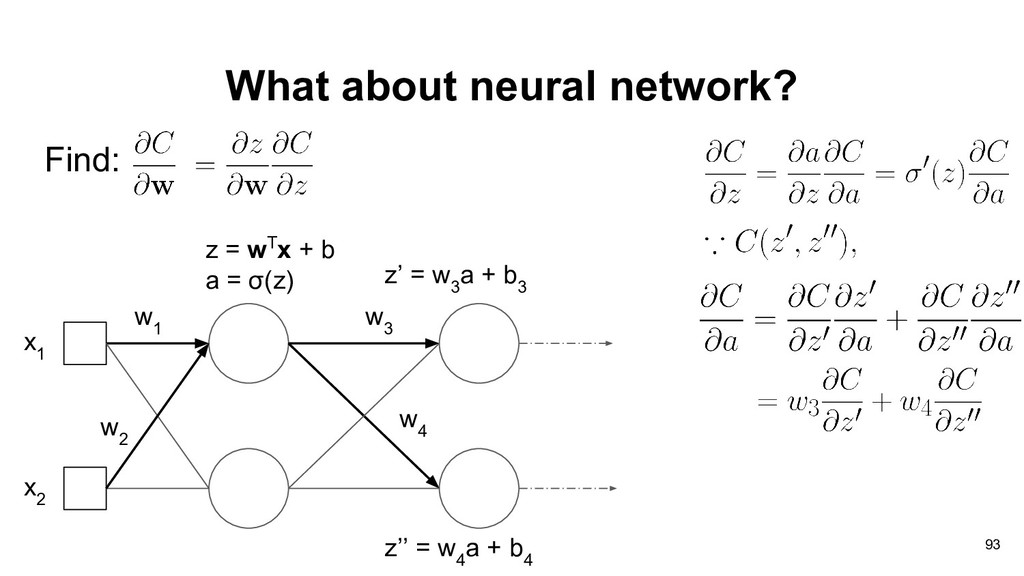
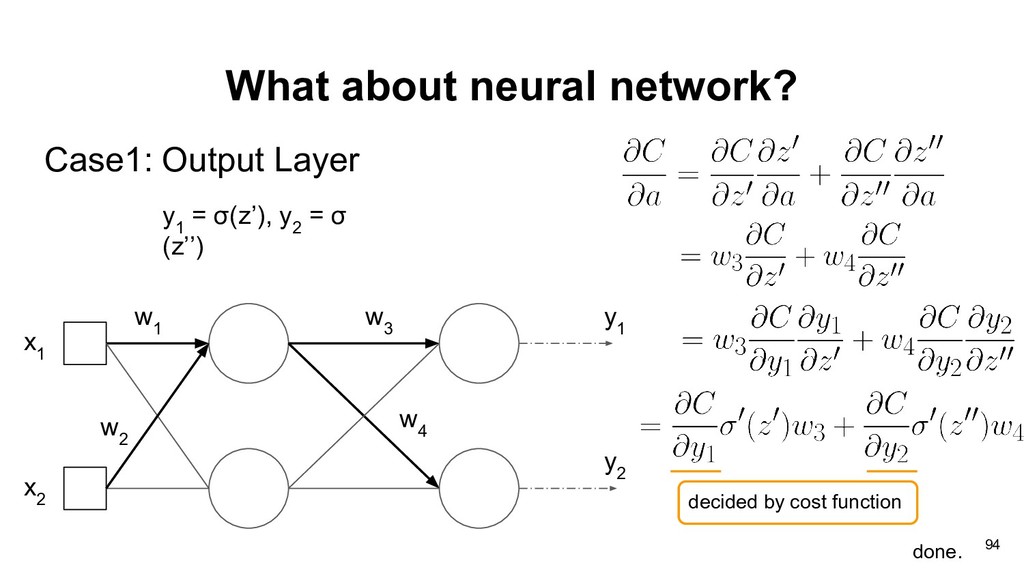
graph of perceptron, and our objective is to find partial derivative of cost function C(y) with respect to weights vector w: * * x 1 + w 1 x 2 w 2 a 1 a 2 f a 3 y 83
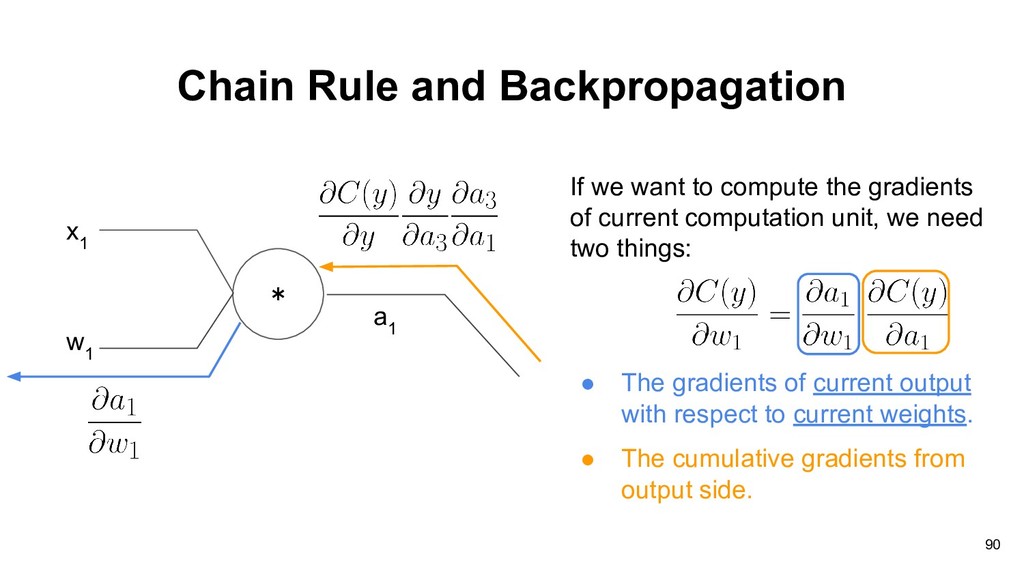
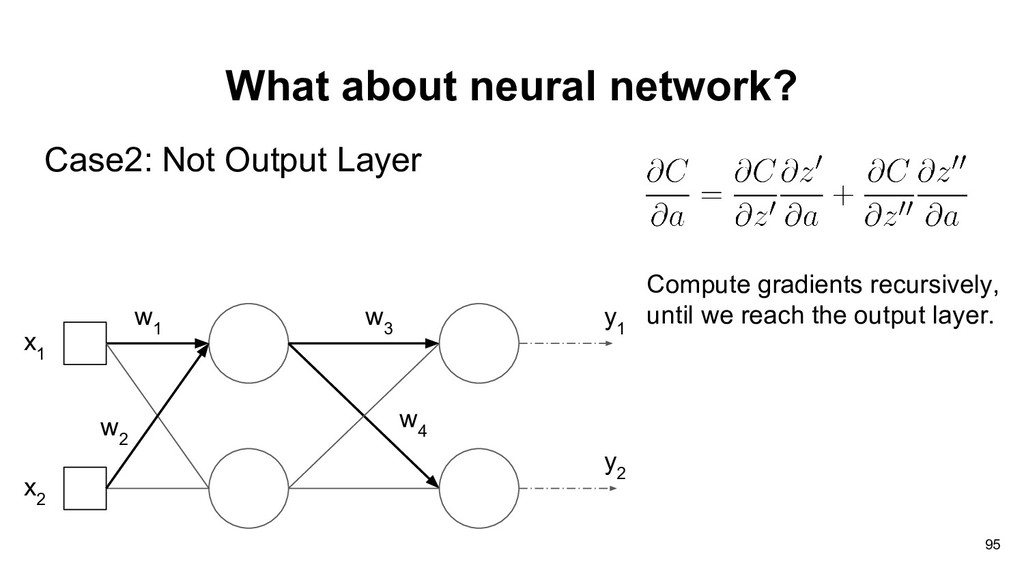
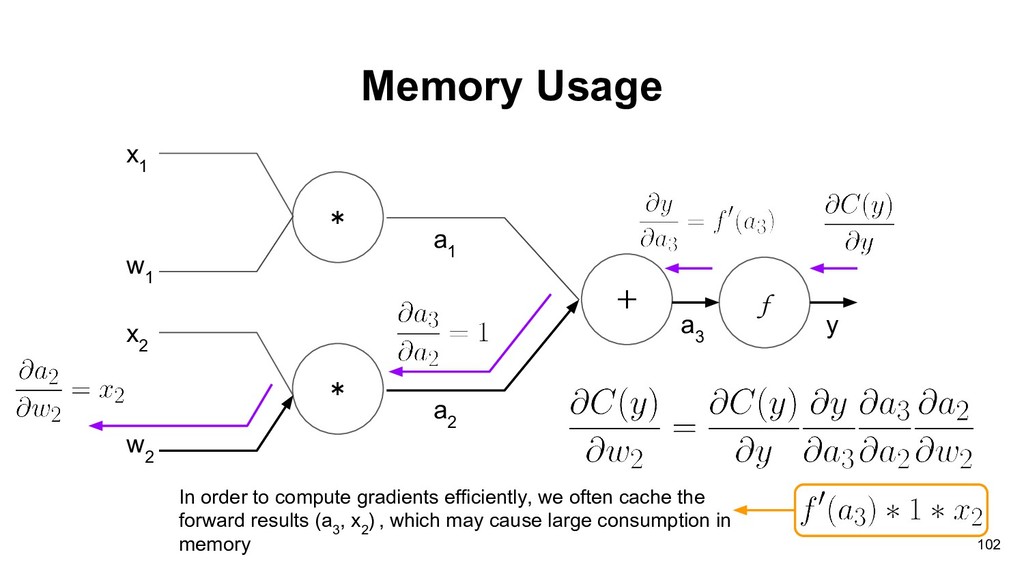
1 If we want to compute the gradients of current computation unit, we need two things: • The gradients of current output with respect to current weights. • The cumulative gradients from output side. 90
doing gradient descent in neural network. • How do we compute the gradients for the weights of each layer? • The landscape of loss function is probably not convex. 96
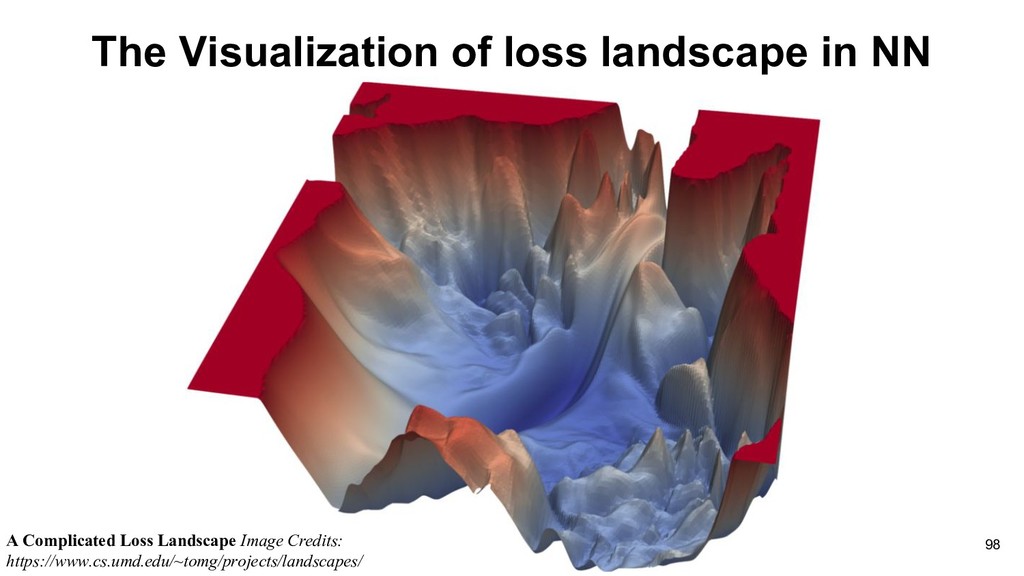
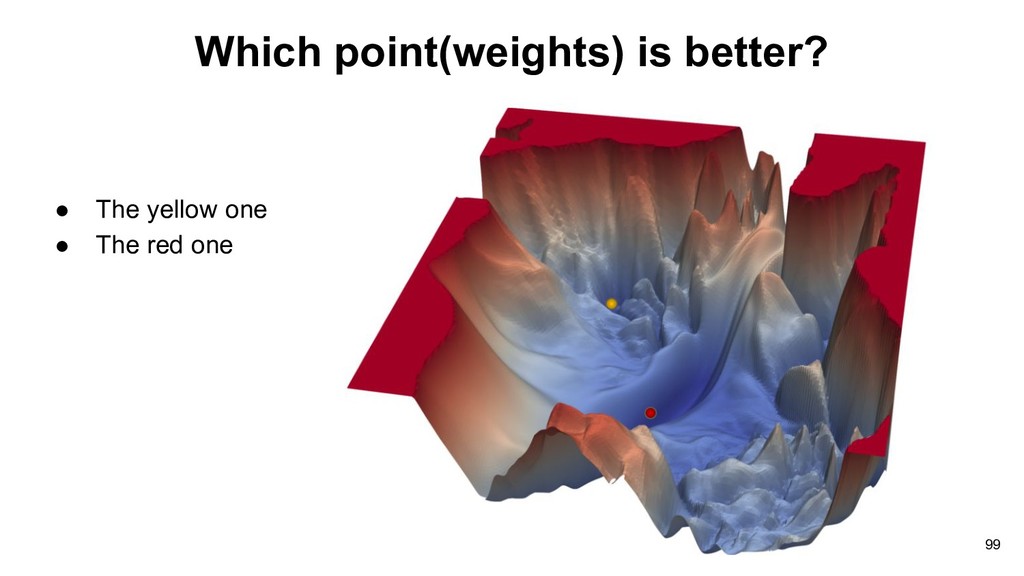
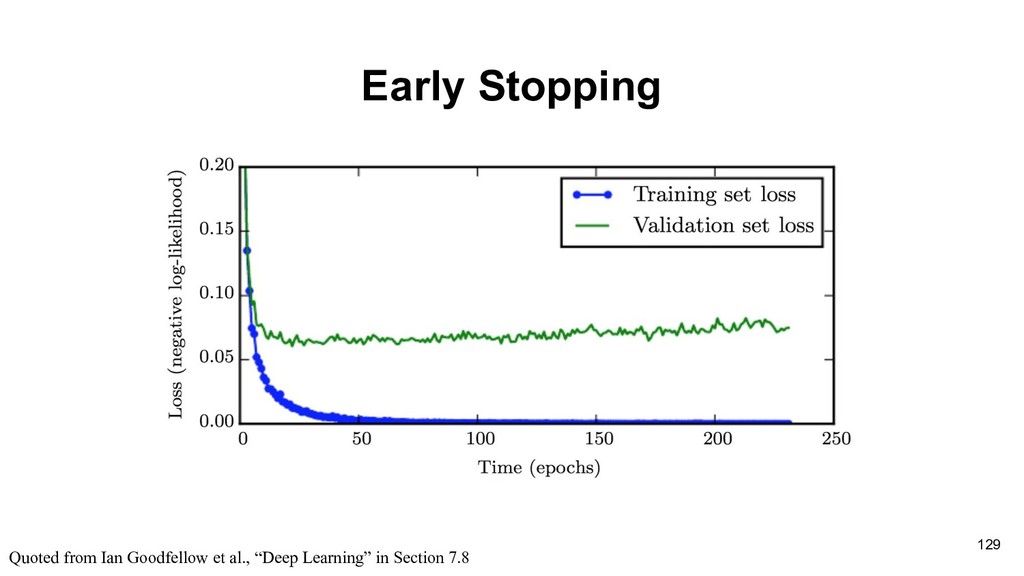
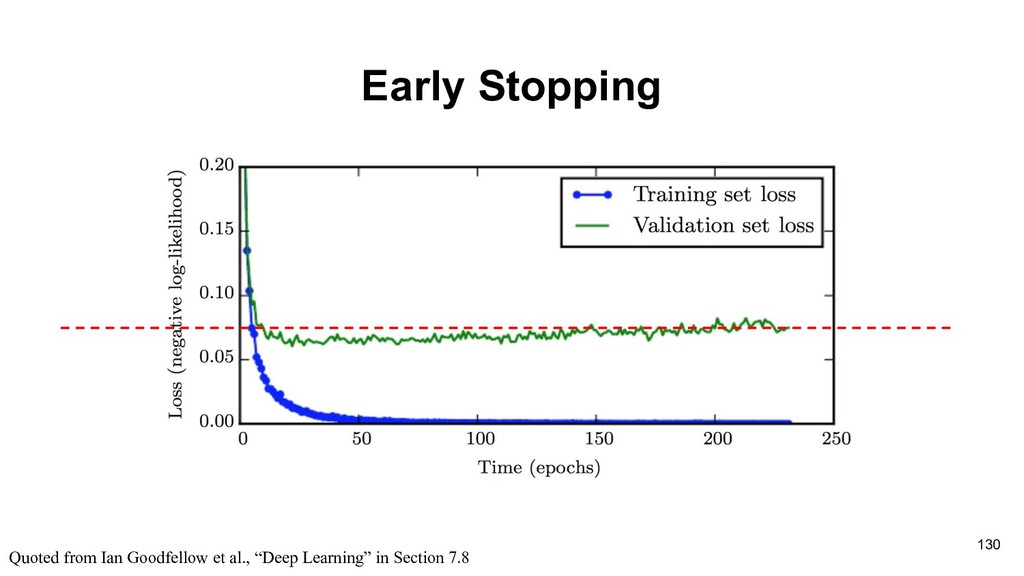
training data, which may not be closed to actual loss with just few samples. (Learning theory) • Fortunately, local optimal would be great enough to solve most problems. 100
x 2 w 2 a 1 a 2 f a 3 y In order to compute gradients efficiently, we often cache the forward results (a 3 , x 2 ) , which may cause large consumption in memory
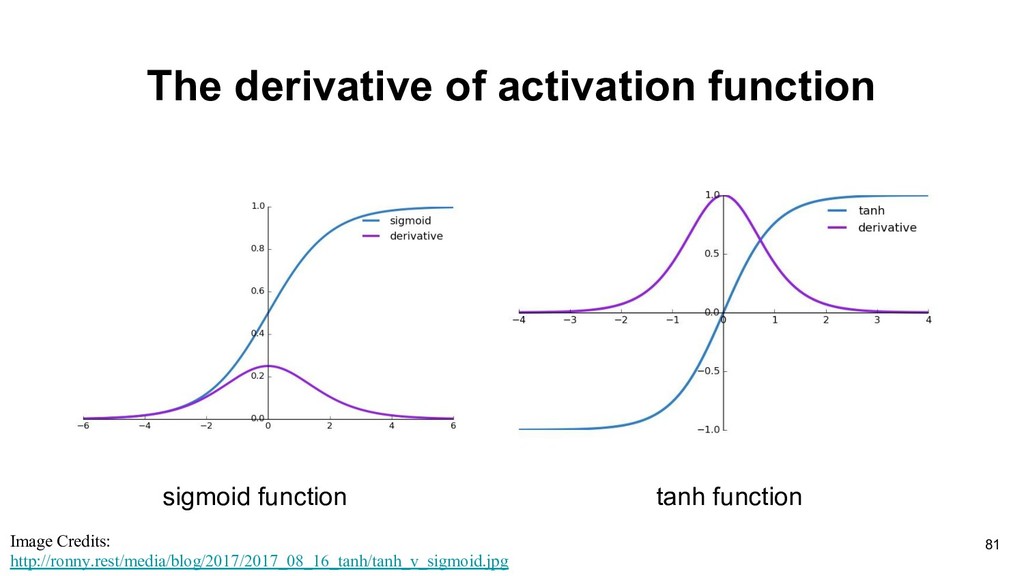
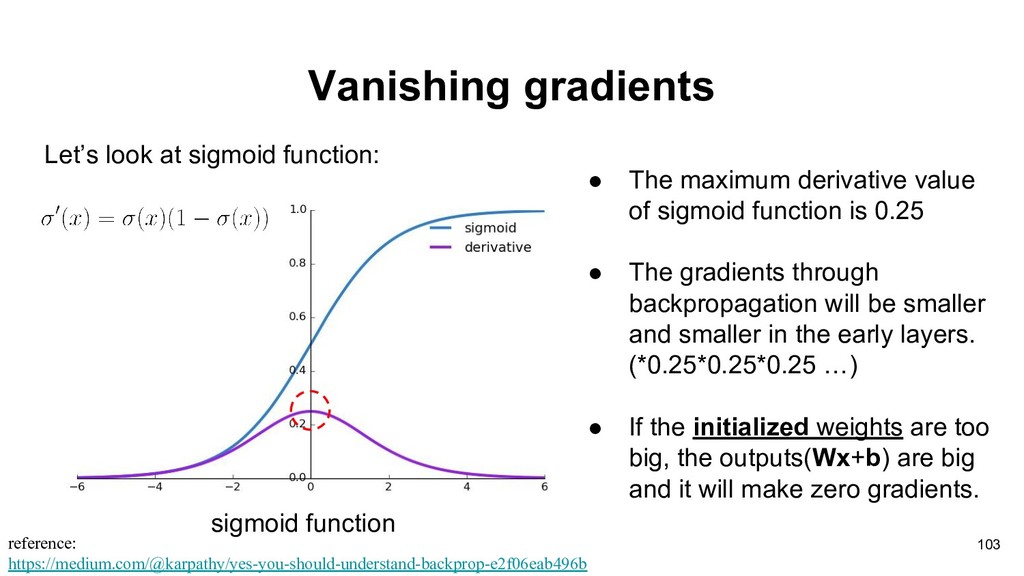
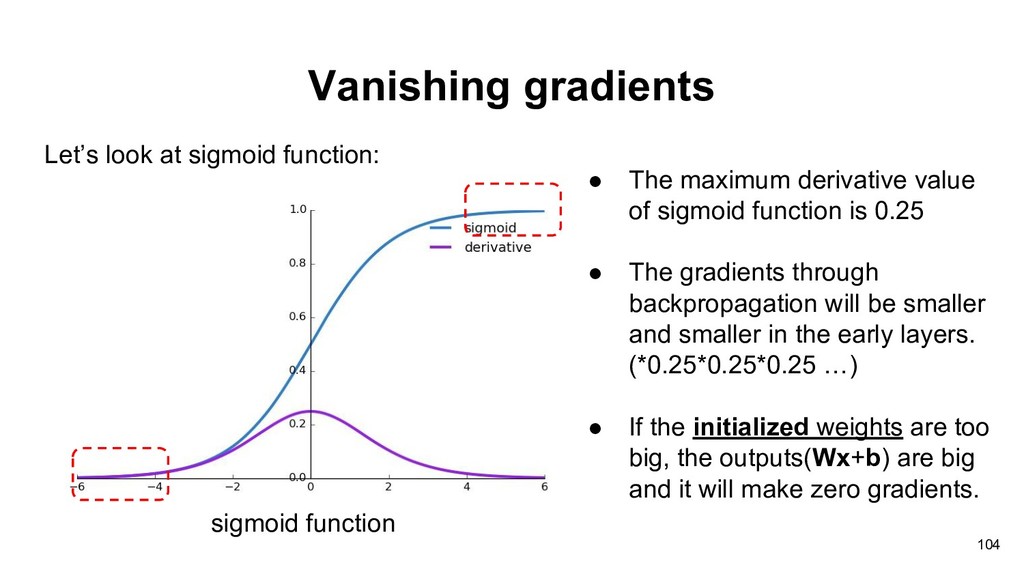
reference: https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b • The maximum derivative value of sigmoid function is 0.25 • The gradients through backpropagation will be smaller and smaller in the early layers. (*0.25*0.25*0.25 …) • If the initialized weights are too big, the outputs(Wx+b) are big and it will make zero gradients.
• The maximum derivative value of sigmoid function is 0.25 • The gradients through backpropagation will be smaller and smaller in the early layers. (*0.25*0.25*0.25 …) • If the initialized weights are too big, the outputs(Wx+b) are big and it will make zero gradients.
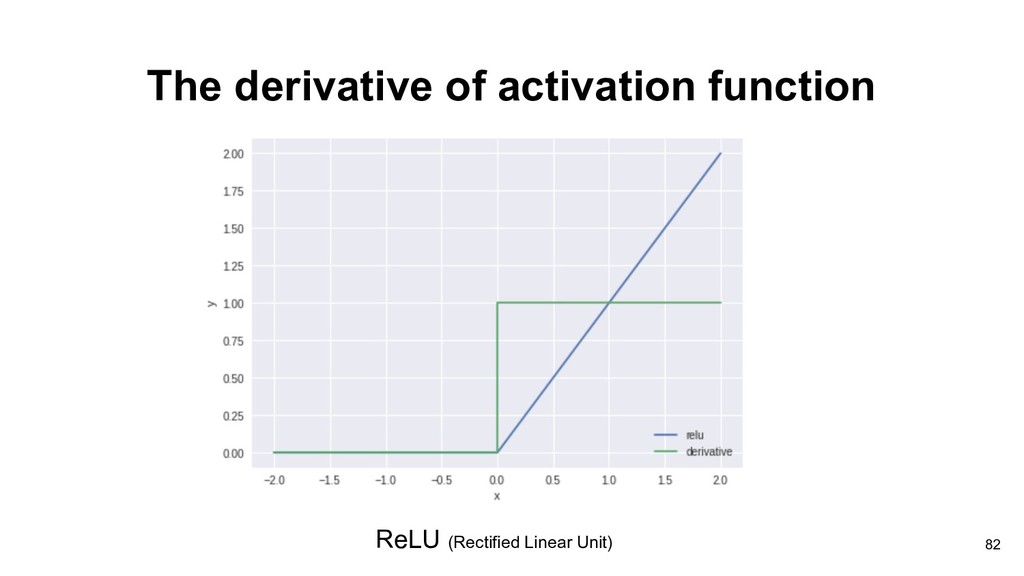
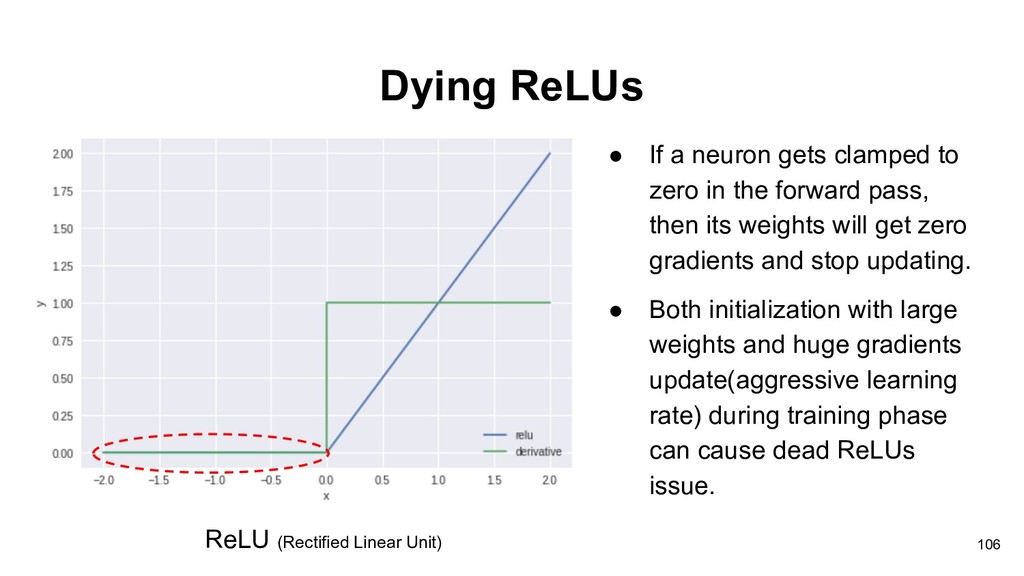
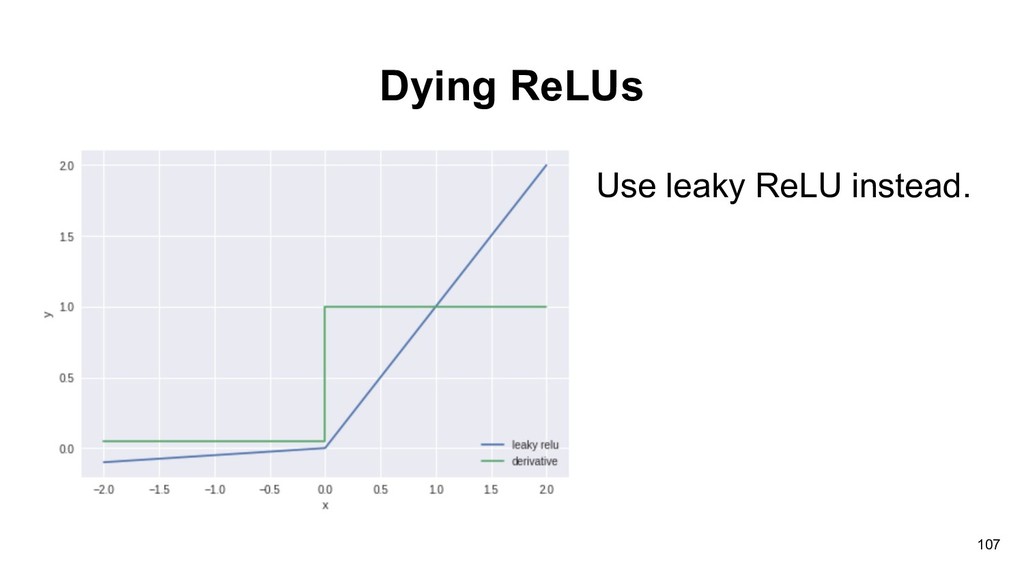
in the forward pass, then its weights will get zero gradients and stop updating. • Both initialization with large weights and huge gradients update(aggressive learning rate) during training phase can cause dead ReLUs issue. 106 ReLU (Rectified Linear Unit)
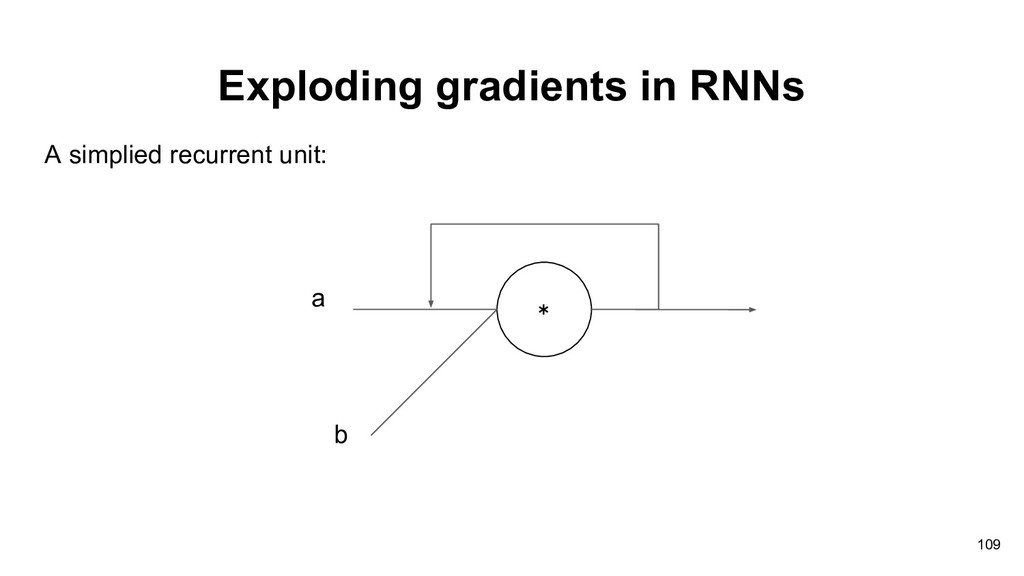
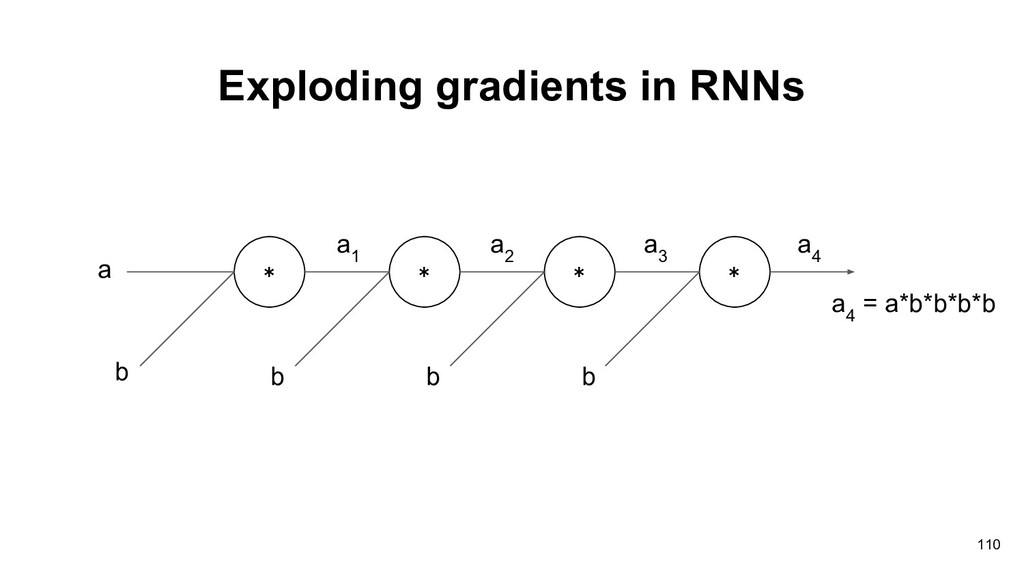
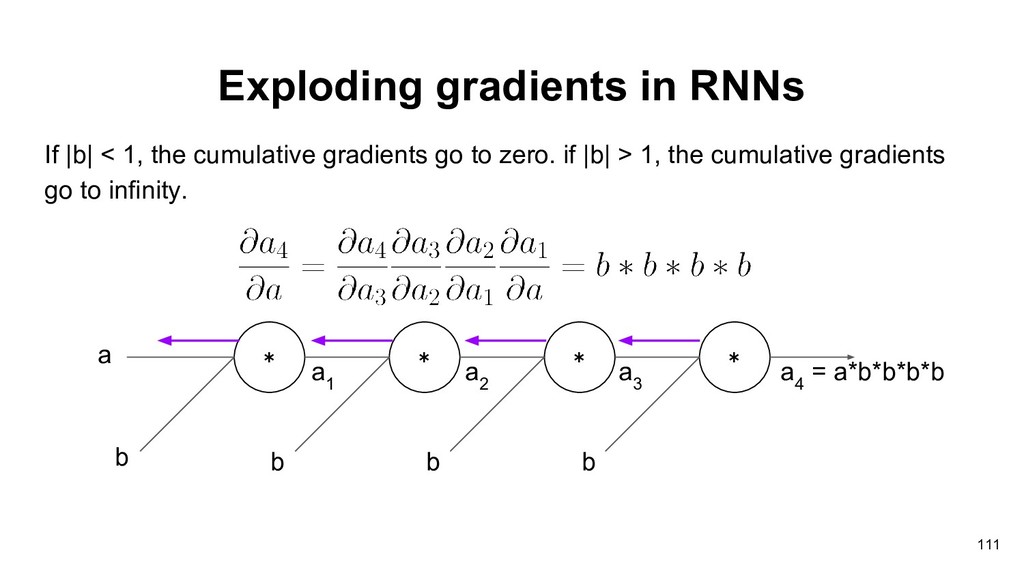
in vanilla recurrent neural network(原始的RNN). Pascanu et al. addressed this problem and proposed a solution called gradients clipping to relieve exploding gradients. A special recurrent unit LSTM can relieve this issue! 108 Pascanu et al., “On the difficulty of training Recurrent Neural Networks”
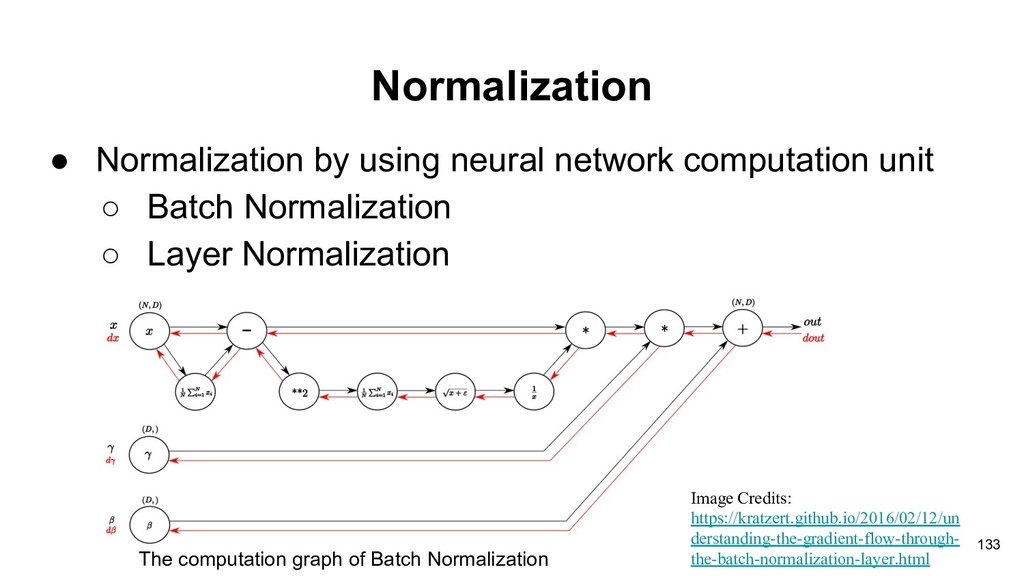
relieve vanishing gradients • Kaiming initialization - relieve dead ReLUs • Use normalization layers ◦ Batch Normalization ◦ Layer Normalization ◦ … • Use LSTM, Gradients Clipping - relieve exploding gradients 112 The articles about initialization and batch normalization(Chinese): https://zhuanlan.zhihu.com/p/25110150 You also can found similar content in the Chapter 6 of “Deep learning from scratch”, O’reilly https://github.com/oreilly-japan/deep-learning-from-scratch
◦ http://cs231n.github.io/optimization-1/ • Hung-Yi Lee’s course video in NTU, Taiwan ◦ https://www.youtube.com/watch?v=ibJpTrp5mcE&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89 yu49&index=12 • An article from Andrej Karpathy ◦ Yes you should understand backprop: https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b 113
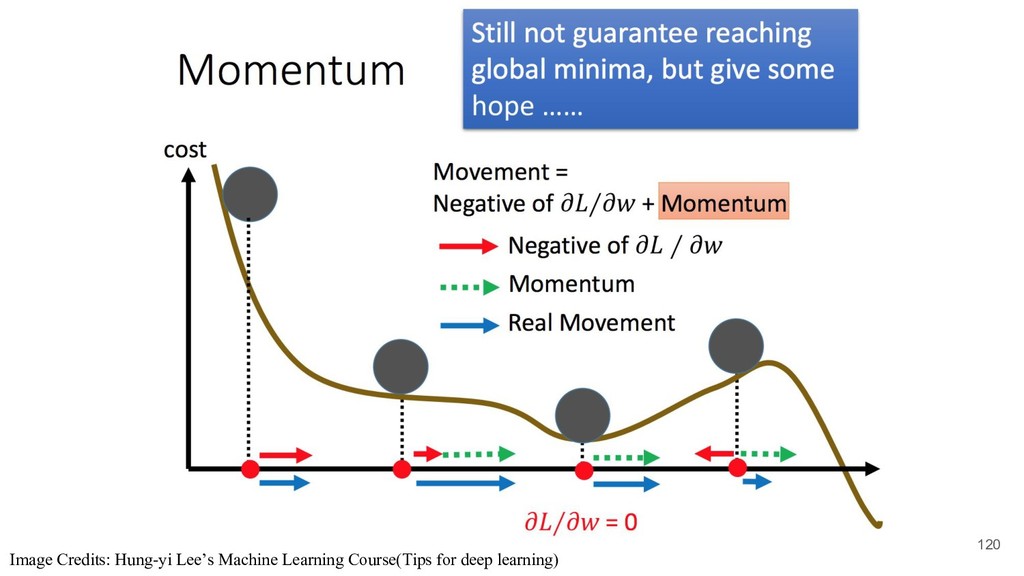
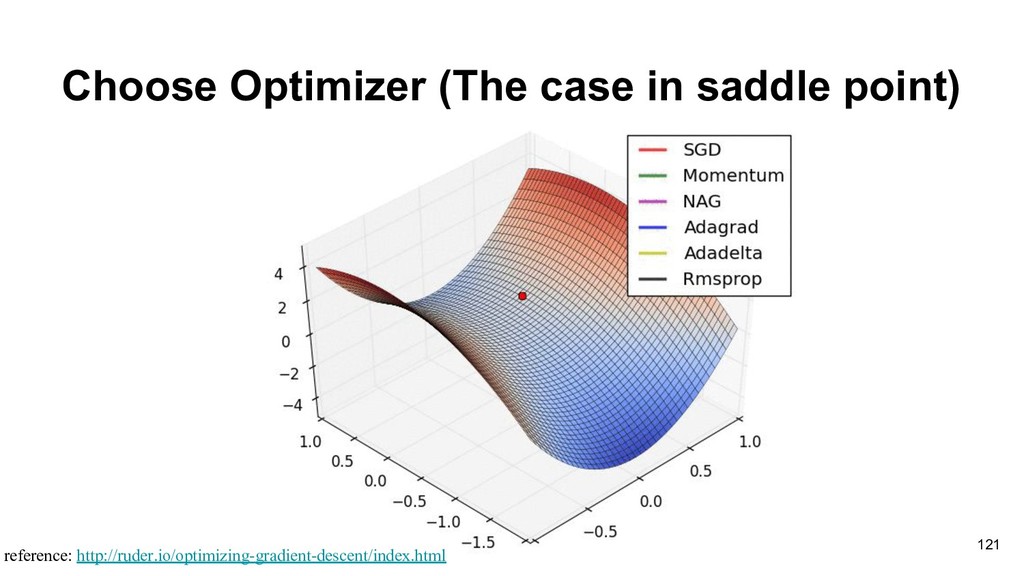
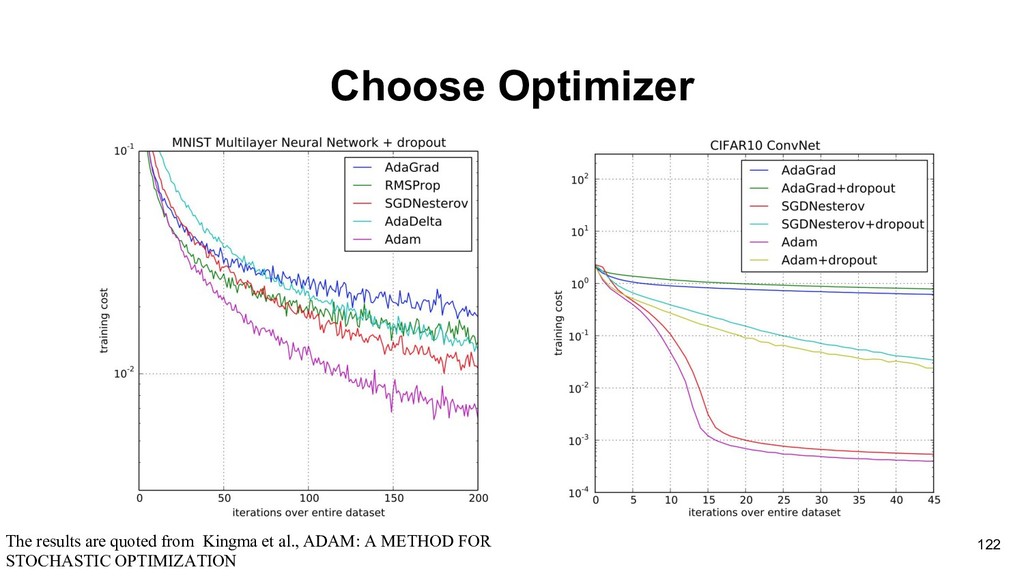
the most basic one is SGD(Stochastic Gradient Descent Optimizer) However, in order to well optimize the objective function, researchers design many useful optimizers that help deep learning.Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization 116 • Stochastic Gradient Descent(SGD) • Adagrad • Adadelta • RMSProp • Adam recommended article: http://ruder.io/optimizing-gradient-descent/index.html
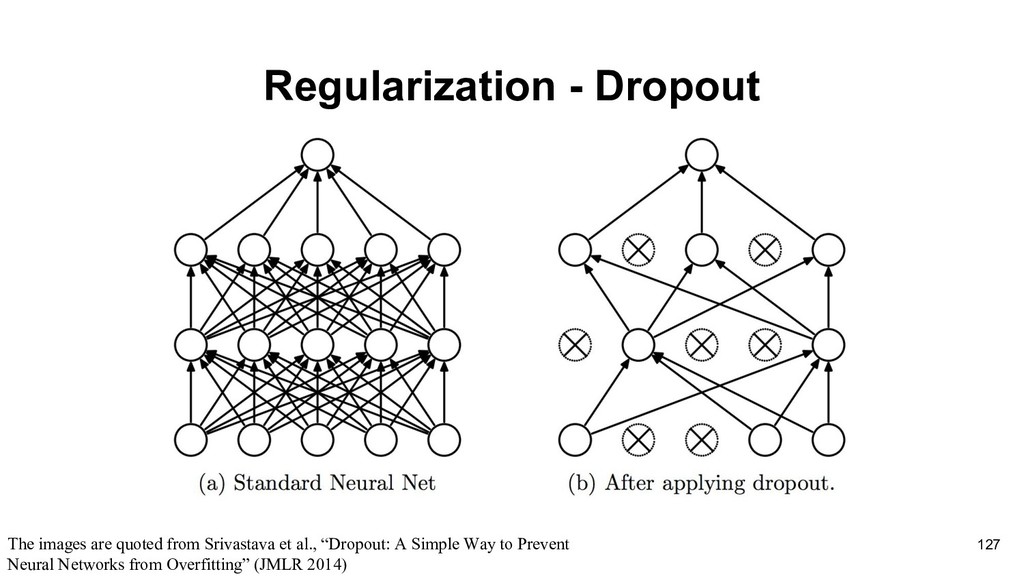
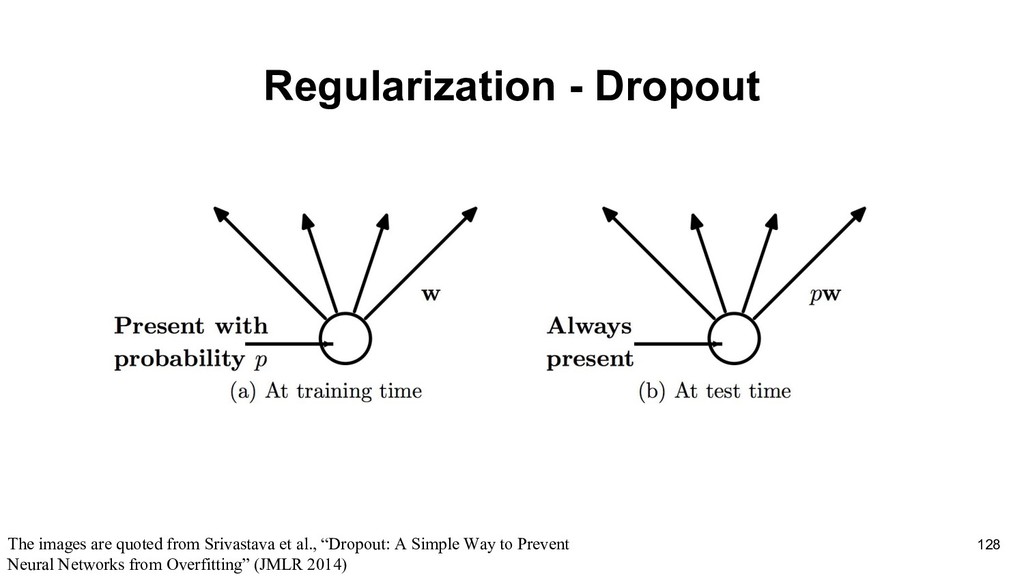
to reduce the testing error, possibly at the expense of increased training error. These strategies are known collectively as regularization.(e.g., L1-regularization, L2-regularization) The most popular one in deep learning is Dropout 126
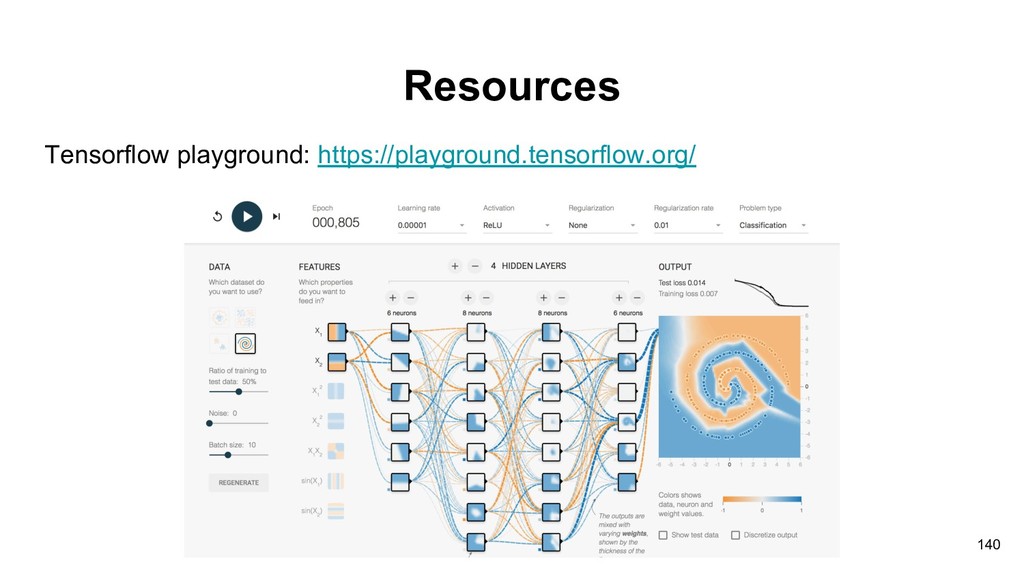
neural network architecture in deep learning, especially in computer vision tasks. Here are some nice resources: • CS231n, Stanford: http://cs231n.stanford.edu/ • ConvNetJS: https://cs.stanford.edu/people/karpathy/convnetjs/index.html • Article: An Intuitive Explanation of Convolutional Neural Networks: https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ • Intuitively Understanding Convolutions for Deep Learning: https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee 1 • Intuitively Understanding Convolutions for Deep Learning (Chinese) http://bangqu.com/nNMB58.html#utm_source=Facebook_PicSee&utm_medium=Social 135
Learning from Data Course • CS229, Stanford • CS231n, Stanford • Hsuan-Tien Lin’s Machine Learning Foundations, National Taiwan University • Hung-yi Lee’s Machine Learning, National Taiwan University And some papers and articles 138
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}