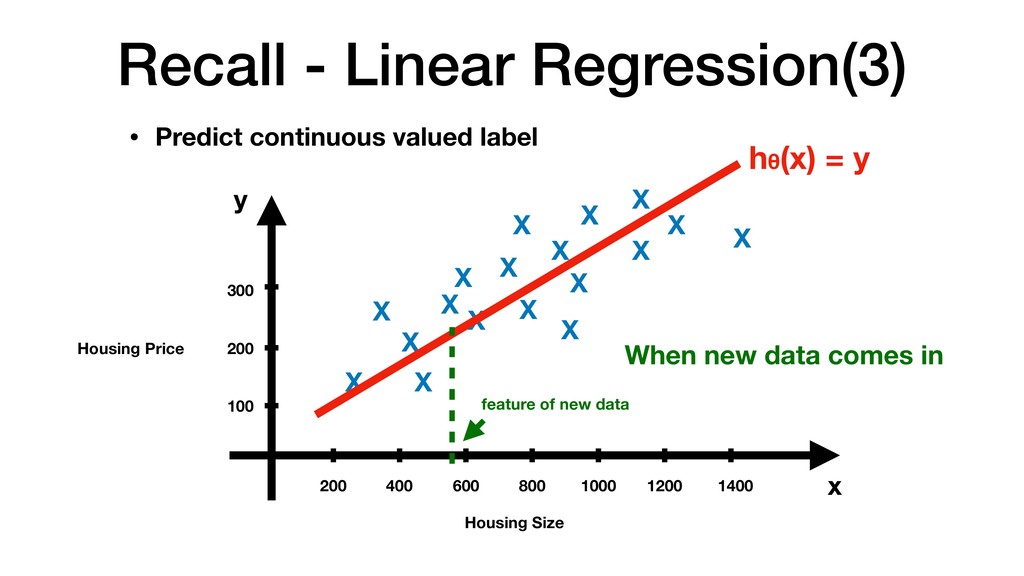
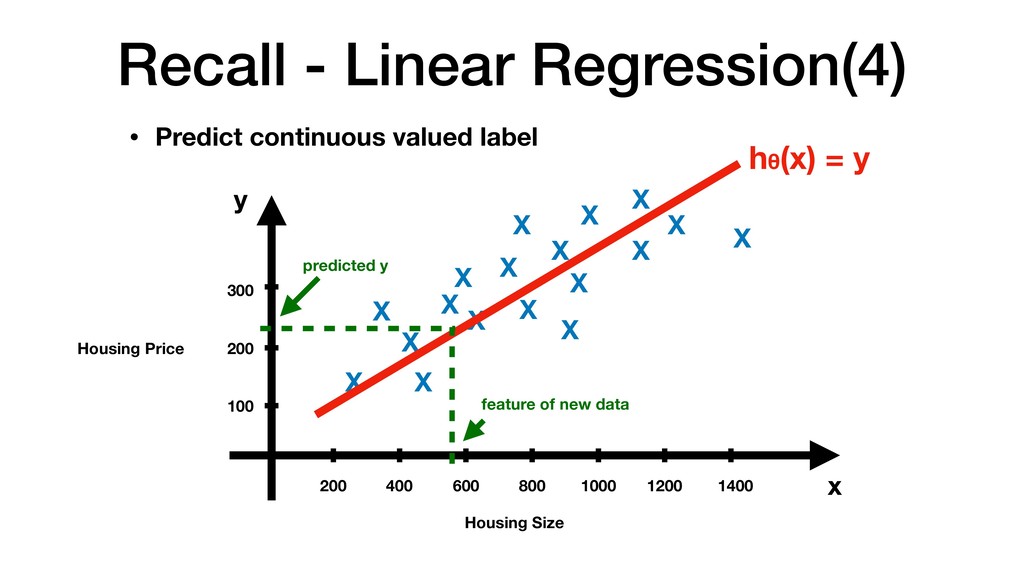
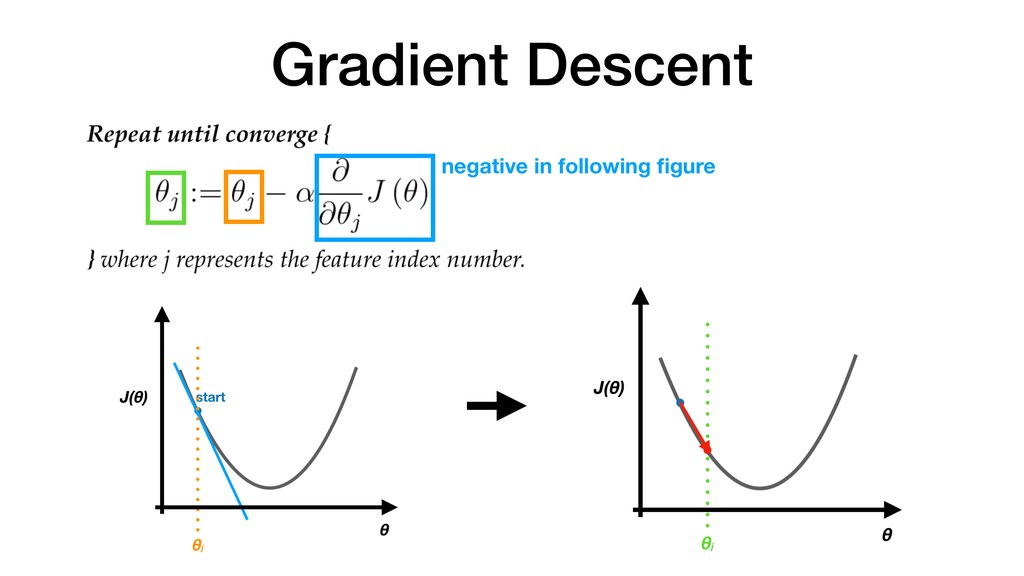
600 800 1000 1200 1400 100 200 300 X X X X X X X X X X X X X X X X X X x y • Predict continuous valued label hθ(x) = y When new data comes in feature of new data
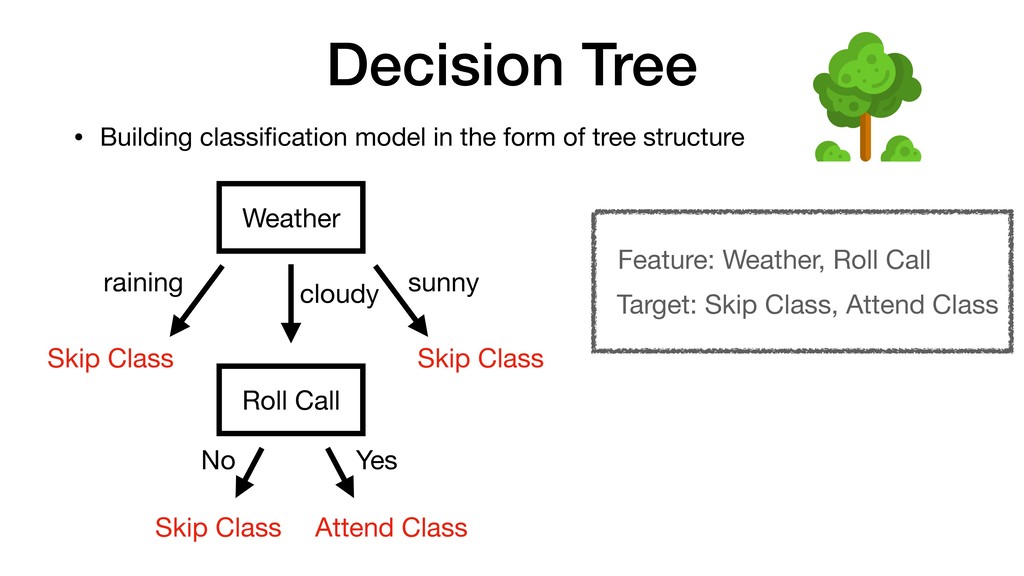
tree structure Weather Skip Class Skip Class raining sunny cloudy Roll Call No Yes Skip Class Attend Class Feature: Weather, Roll Call Target: Skip Class, Attend Class
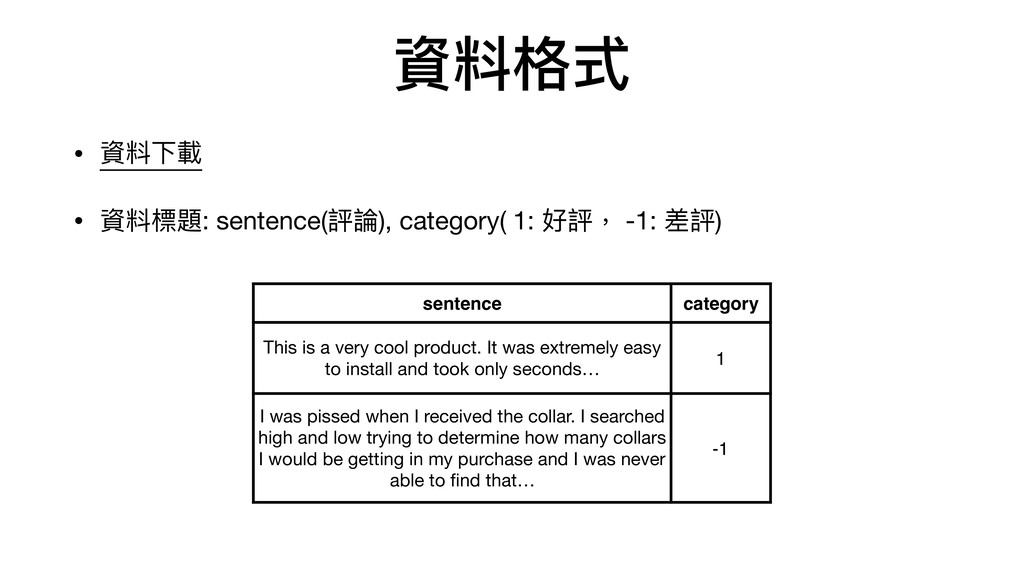
差評) sentence category This is a very cool product. It was extremely easy to install and took only seconds… 1 I was pissed when I received the collar. I searched high and low trying to determine how many collars I would be getting in my purchase and I was never able to find that… -1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}