Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Evolving ML Platform with OSS Upstream Community
Search
Yuki Iwai
June 08, 2023
Technology
1.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Evolving ML Platform with OSS Upstream Community
CIU Tech Meetup #1 (
https://cyberagent.connpass.com/event/283317/
) で発表した資料です。
Yuki Iwai
June 08, 2023
More Decks by Yuki Iwai
See All by Yuki Iwai
Standardizing Cloud Native ML Computing Platforms
y_iwai
0
310
ML環境でのRook/Ceph
y_iwai
1
3.7k
Other Decks in Technology
See All in Technology
AI工学特論: MLOps・継続的評価
asei
11
2.7k
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
880
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
16k
Power Automateアップデート情報
miyakemito
0
250
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
1.3k
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
110
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
書籍セキュアAPIについて
riiimparm
0
350
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
520
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
670
reFACToring
moznion
1
620
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
エンジニアに許された特別な時間の終わり
watany
108
250k
Leo the Paperboy
mayatellez
8
1.9k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Transcript
Evolving ML Platform with OSS Upstream Community 岩井 佑樹 (Iwai
Yuki) 2023/06/07
岩井 佑樹 (Iwai Yuki) 2022 年新卒入社 CyberAgent Group Infrastructure Unit
> Development Division @tenzen-y Software Engineer (Private Cloud) • ML Platform および AKE の開発 • Kubernetes WG Batch (SIG Scheduling / Apps) Maintainer / Member • Kubeflow WG AutoML / Training Maintainer / Reviewer / Member • Kserve WG Serving Member
None
1.What is ML Platform? 2.Driving OSS Upstream Community 3.Evolving OSS
Upstream 4.Conclusion 5.Next ML Platform
What is ML Platform? • CIU で提供している機械学習基盤 • GPUaaS /
AI Platform / Distributed を内包したサービス 機械学習タスクを実行 GPU 環境を提供 AFF A800 DGX A100 H100/A100/A2/T4 AI Platform Prediction Training Distributed GPUaaS(Kubernetes)
None
GPU as a Service (GPUaaS) • Kubernetes 上で GPU 環境を払い出すサービス
NVIDIA A100 / NVIDIA A2 / NVIDIA T4 を提供 NVIDIA H100 環境は構築中 コンソール (Web UI) から操作可能なマネージドな Jupyter Notebook 環境 オブジェクトストレージ連携機能 etc… NVIDIA DGX A100
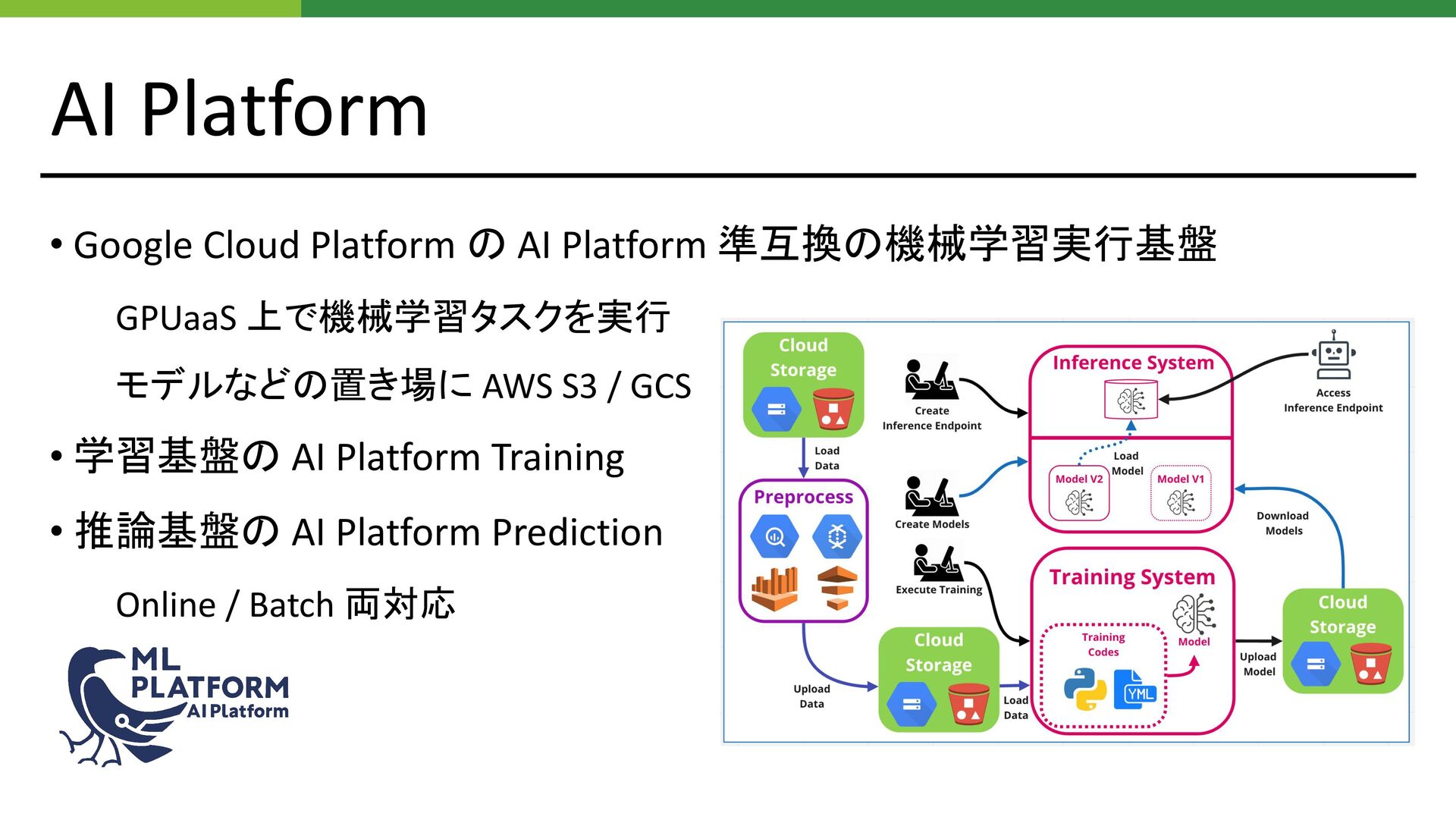
AI Platform • Google Cloud Platform の AI Platform 準互換の機械学習実行基盤
GPUaaS 上で機械学習タスクを実行 モデルなどの置き場に AWS S3 / GCS • 学習基盤の AI Platform Training • 推論基盤の AI Platform Prediction Online / Batch 両対応
Distributed • MPI を用いた分散学習をサポート AI Platform Training は単一 Node 前提
Distributed は Node 間分散学習をサポート ML Platform で最も高性能な基盤を提供 (LLM の学習などに最適) Distributed の詳細は別のイベントで!
KubernetesベースのGPU as a Serviceプラットフォーム :GPU活用の取り組み
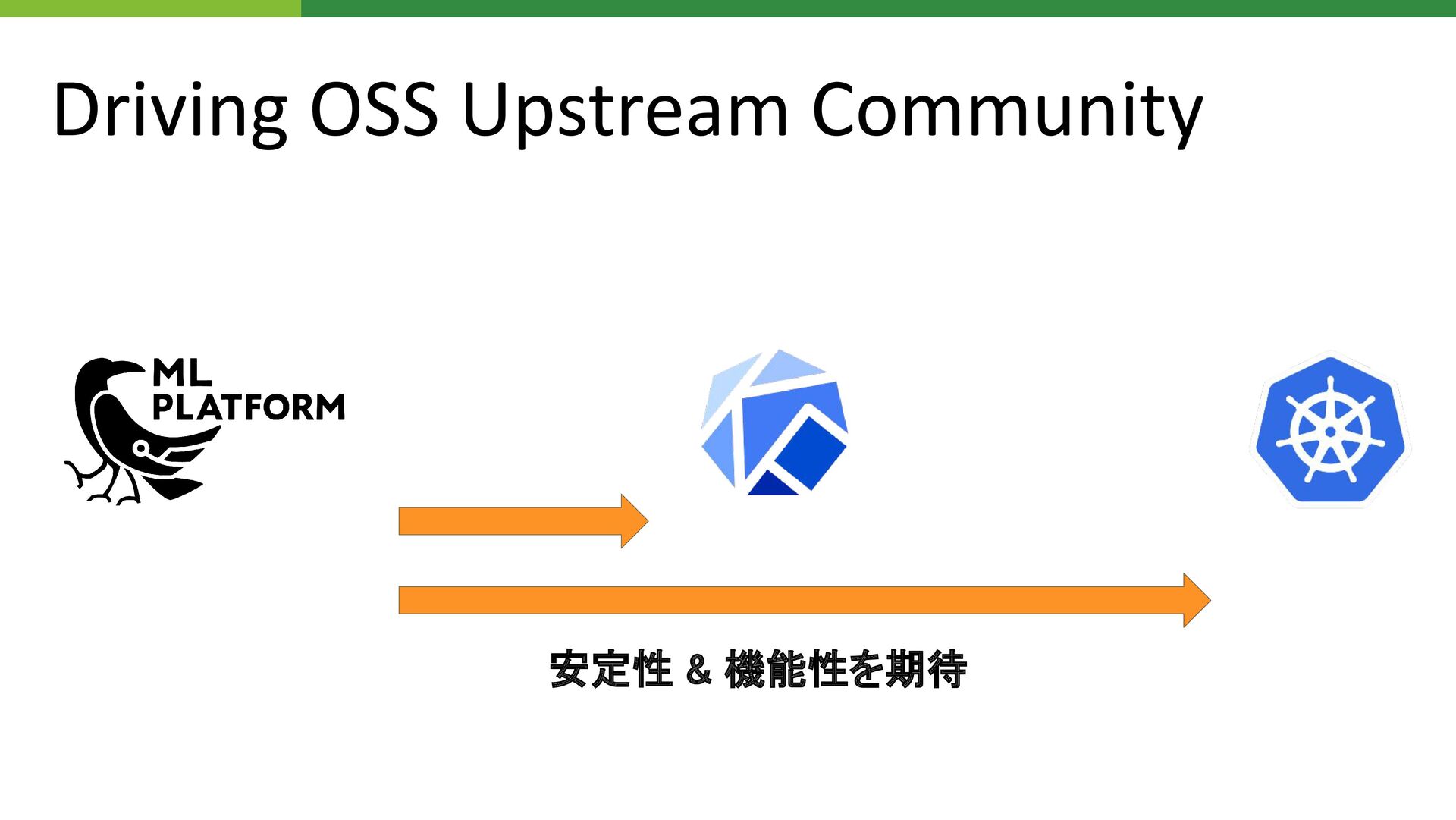
Driving OSS Upstream Community • ML Platform の OS から上のレイヤーがほとんど全て
OSS Containerd, Kubernetes, Kubeflow, Knative, Istio, Grafana Loki... • OSS コミュニティ (or ソフトウェア) の成熟が ML Platform の品質に直結 • Kubernetes 上での機械学習基盤 / バッチ実行システムの構築が チャレンジング 自らコミュニティを Lead コミュニティに社内の意見を反映させやすくする
Driving OSS Upstream Community • ML Platform の OS から上のレイヤーがほとんど全て
OSS Containerd, Kubernetes, Kubeflow, Knative, Istio, Grafana Loki... • OSS コミュニティ (or ソフトウェア) の成熟が ML Platform の品質に直結 • Kubernetes 上での機械学習基盤 / バッチ実行システムの構築が チャレンジング 自らコミュニティを Lead コミュニティに社内の意見を反映させやすくする 主に以下の WG (SIG) で活動している ▪ Kubeflow: WG AutoML / Training ▪ Kubernetes: WG Batch (SIG Apps / Scheduling)
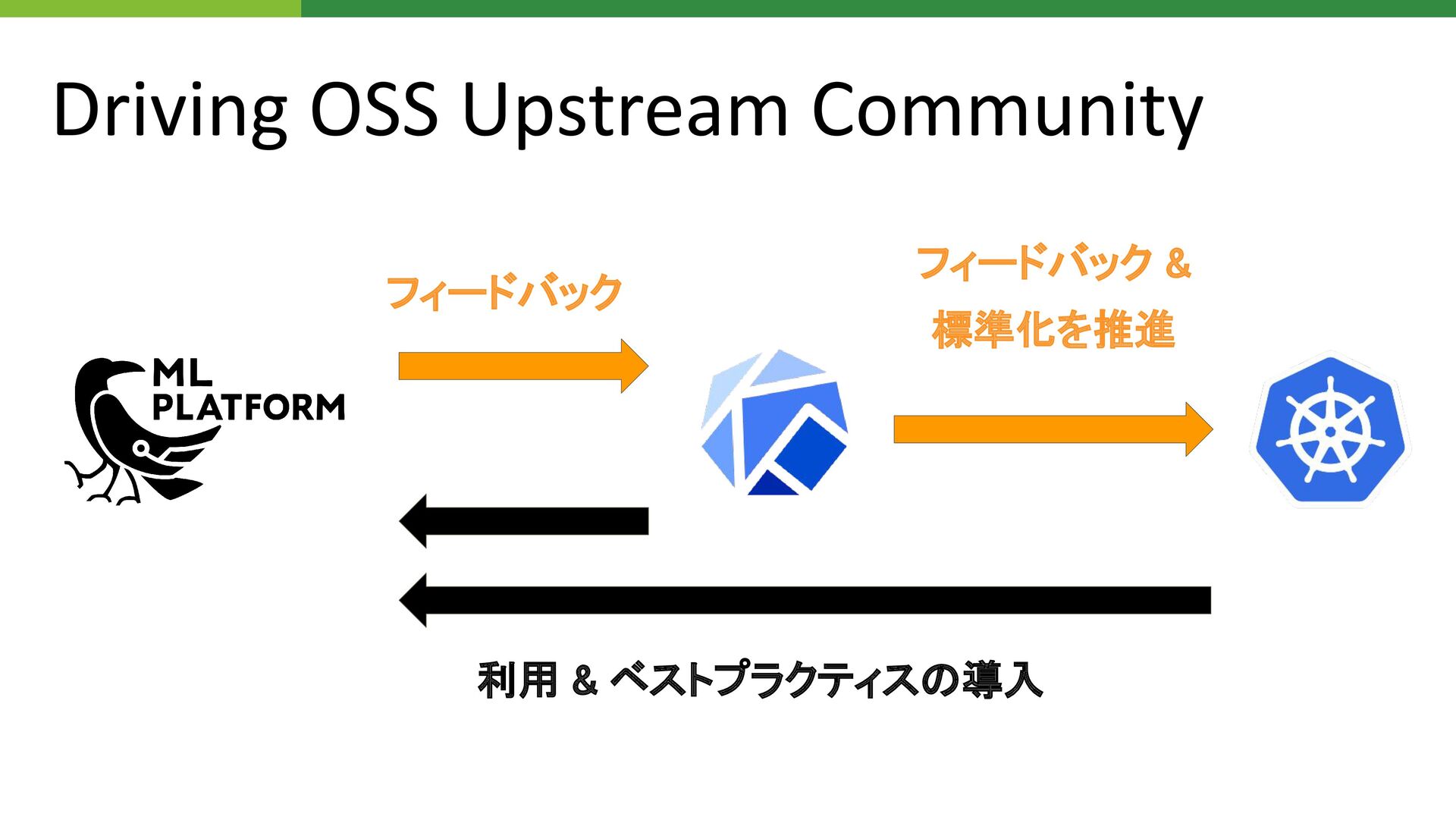
Driving OSS Upstream Community フィードバック & 標準化を推進 フィードバック 利用 &
ベストプラクティスの導入
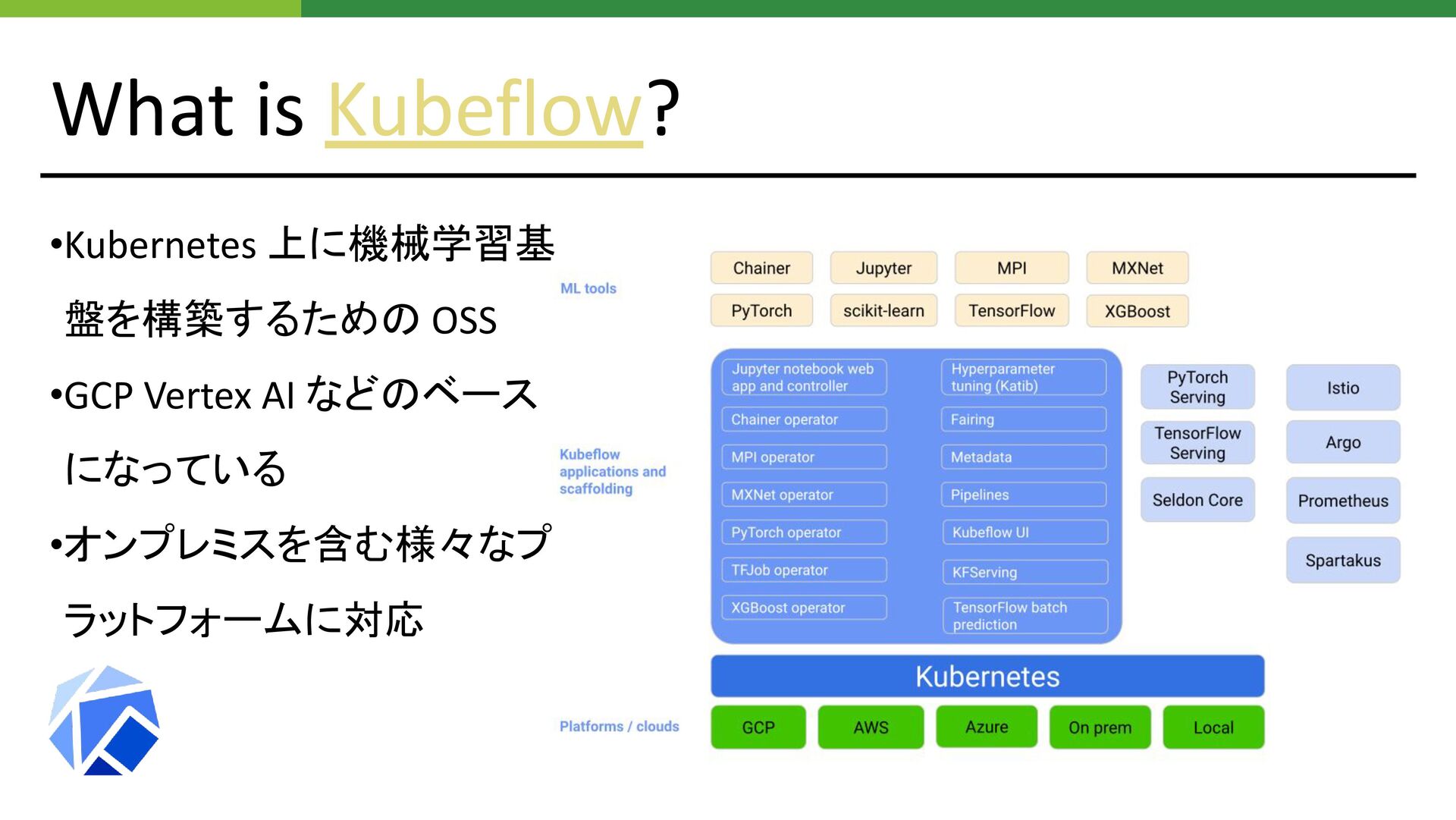
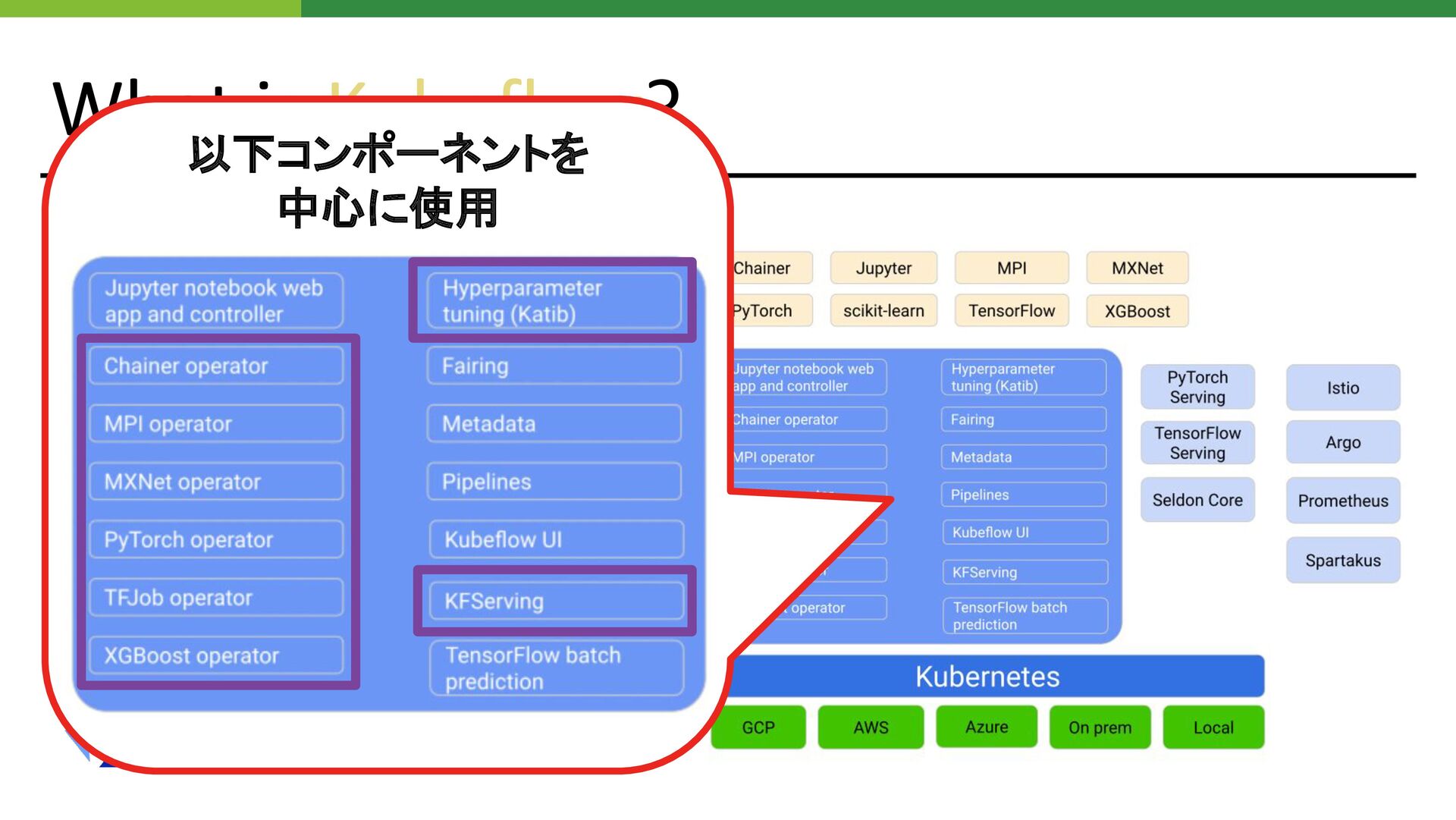
What is Kubeflow? •Kubernetes 上に機械学習基 盤を構築するための OSS •GCP Vertex AI
などのベース になっている •オンプレミスを含む様々なプ ラットフォームに対応
What is Kubeflow? •Kubernetes 上に機械学習基 盤を構築するための OSS •GCP Vertex AI
などのベース になっている •オンプレミスを含む様々なプ ラットフォームに対応 以下コンポーネントを 中心に使用
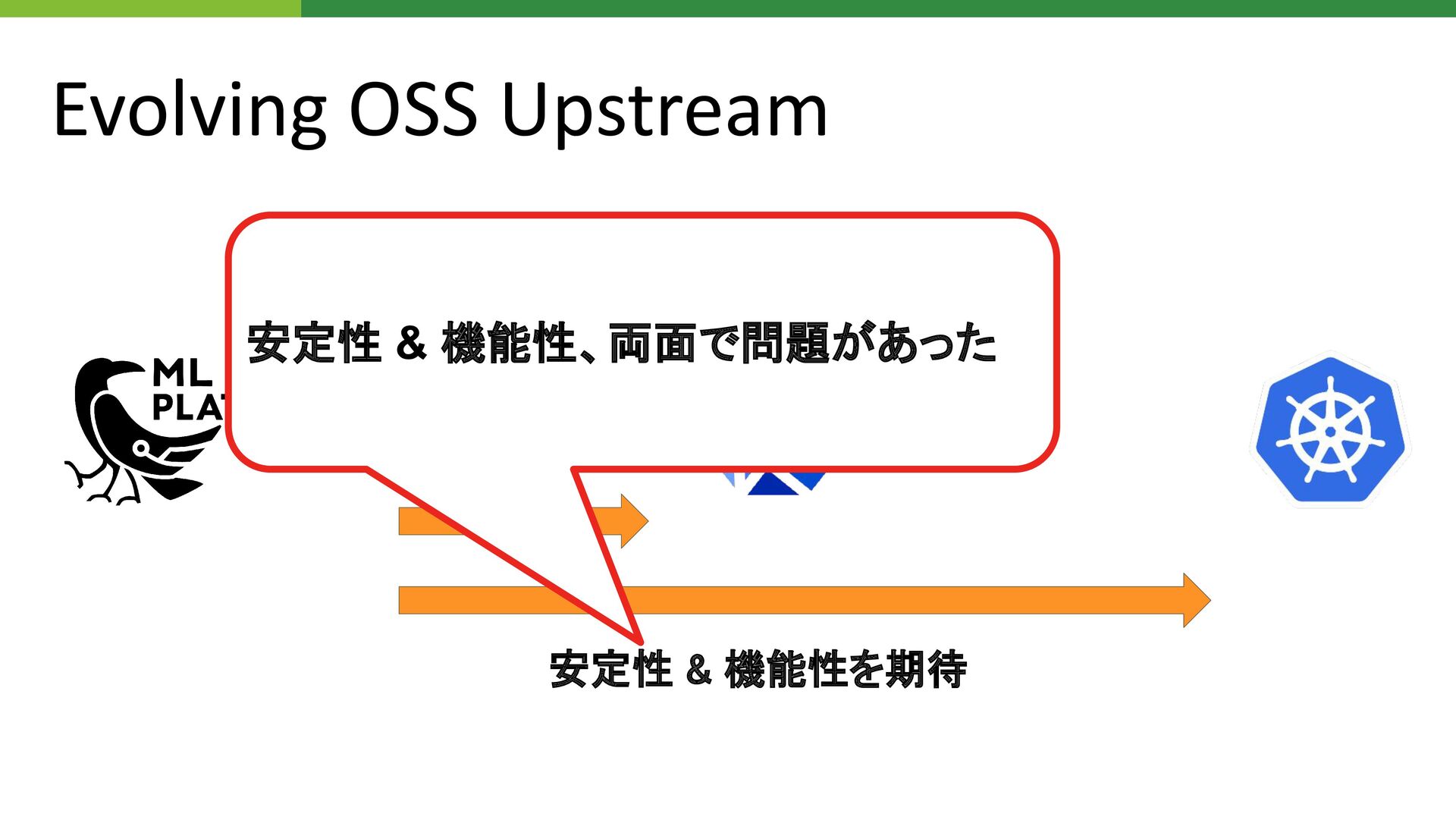
Driving OSS Upstream Community 安定性 & 機能性を期待
Evolving OSS Upstream 安定性 & 機能性を期待 安定性 & 機能性、両面で問題があった
Kubeflow Job • 機械学習における 分散学習のセットアップを自 動で行ってくれる • Job 内に複数の PodTemplate
をもつ • .spec.runPolicy に batch/v1 Job と似たような 機能を持っている • Kubeflow Job から batch/v1 Job にもち込まれた 機能もある。 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ...
Kubeflow Job • 機械学習における 分散学習のセットアップを自 動で行ってくれる • Job 内に複数の PodTemplate
をもつ • .spec.runPolicy に batch/v1 Job と似たような 機能を持っている • Kubeflow Job から batch/v1 Job にもち込まれた 機能もある。 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: …
Kubeflow Job • 機械学習における 分散学習のセットアップを自 動で行ってくれる • Job 内に複数の PodTemplate
をもつ • .spec.runPolicy に batch/v1 Job と似たような 機能を持っている • Kubeflow Job から batch/v1 Job にもち込まれた 機能もある。 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s BackoffLimit: 10 pytorchReplicaSpecs: ... apiVersion: batch/v1 kind: Job metadata: name: sample spec: backoffLimit: 5 ttlSecondsAfterFinished: 10s template: spec: ... spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 spec: backoffLimit: 10 ttlSecondsAfterFinished: 10s
• 機械学習における 分散学習のセットアップを自 動で行ってくれる •Job 内に複数の PodTemplate をもつ •.spec.runPolicy に
batch/v1 Job と似たような 機能を持っている •Kubeflow Job から batch/v1 Job にもつ込まれた機 能もある。 Kubeflow Job apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s BackoffLimit: 10 pytorchReplicaSpecs: ... batch/v1 Job の機能を複数 PodTemplate 向けに Kubeflow で kube-controller-manager 実装の拡張 を行っている spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 apiVersion: batch/v1 kind: Job metadata: name: sample spec: backoffLimit: 5 ttlSecondsAfterFinished: 10s template: spec: ... spec: backoffLimit: 10 ttlSecondsAfterFinished: 10s
Kubernetes Job API • 2021 ~ 2022 で追加された Kubernetes Job
API (batch Job) の新機能 JobTrackingWithFinalizers JobPodFailurePolicy ElasticIndexedJob ... • 2023 ~ も多くの機能が追加される予定 BackoffLimitPerIndex JobRecreatePodsWhenFailed JobSuccessPolicy ...
Kubeflow Job • 機械学習における 分散学習のセットアップを自 動で行ってくれる •Job 内に複数の PodTemplate をもつ
•.spec.runPolicy に batch/v1 Job と似たような 機能を持っている apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s BackoffLimit: 10 pytorchReplicaSpecs: ... batch/v1 Job の機能を複数 PodTemplate 向けに Kubeflow で kube-controller-manager 実装の拡張を 行っている spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 メンテナンスコスト & 不安定さ 増加 apiVersion: batch/v1 kind: Job metadata: name: sample spec: backoffLimit: 5 ttlSecondsAfterFinished: 10s template: spec: ... spec: backoffLimit: 10 ttlSecondsAfterFinished: 10s
Kubeflow Job • 機械学習における 分散学習のセットアップを自 動で行ってくれる • Job 内に複数の PodTemplate
をもつ • .spec.runPolicy に batch/v1 Job と似たような 機能を持っている • Kubeflow Job から batch/v1 Job にもち込まれ た機能もある。 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: pytorchReplicaSpecs: Chief: restartPolicy: ExitCode … apiVersion: batch/v1 kind: Job metadata: name: sample spec: ... podFailurePolicy: rules: - action: FailJob onExitCodes: containerName: main operator: In values: [42] Chief: restartPolicy: ExitCode podFailurePolicy: rules: - action: FailJob onExitCodes: containerName: main operator: In values: [42]
apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished:
10s BackoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Kubeflow Job • Kubernetes のダウンストリーム (Kubeflow) で 再実装し続けるのは現実的ではない • 機能を Kubernetes の API として標準化 標準化されたものを Kubeflow で使用する spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 Worker: replicas: 1 restartPolicy: ExitCode
Kubernetes Job API • 2021 ~ 2022 で追加された Kubernetes Job
API (batch Job) の新機能 JobTrackingWithFinalizers JobPodFailurePolicy ElasticIndexedJob ... • 2023 ~ も多くの機能が追加される予定 BackoffLimitPerIndex JobRecreatePodsWhenFailed JobSuccessPolicy ... ダウンストリームからの バブルアップで実現した機能 ダウンストリームからの バブルアップで実現予定の機能
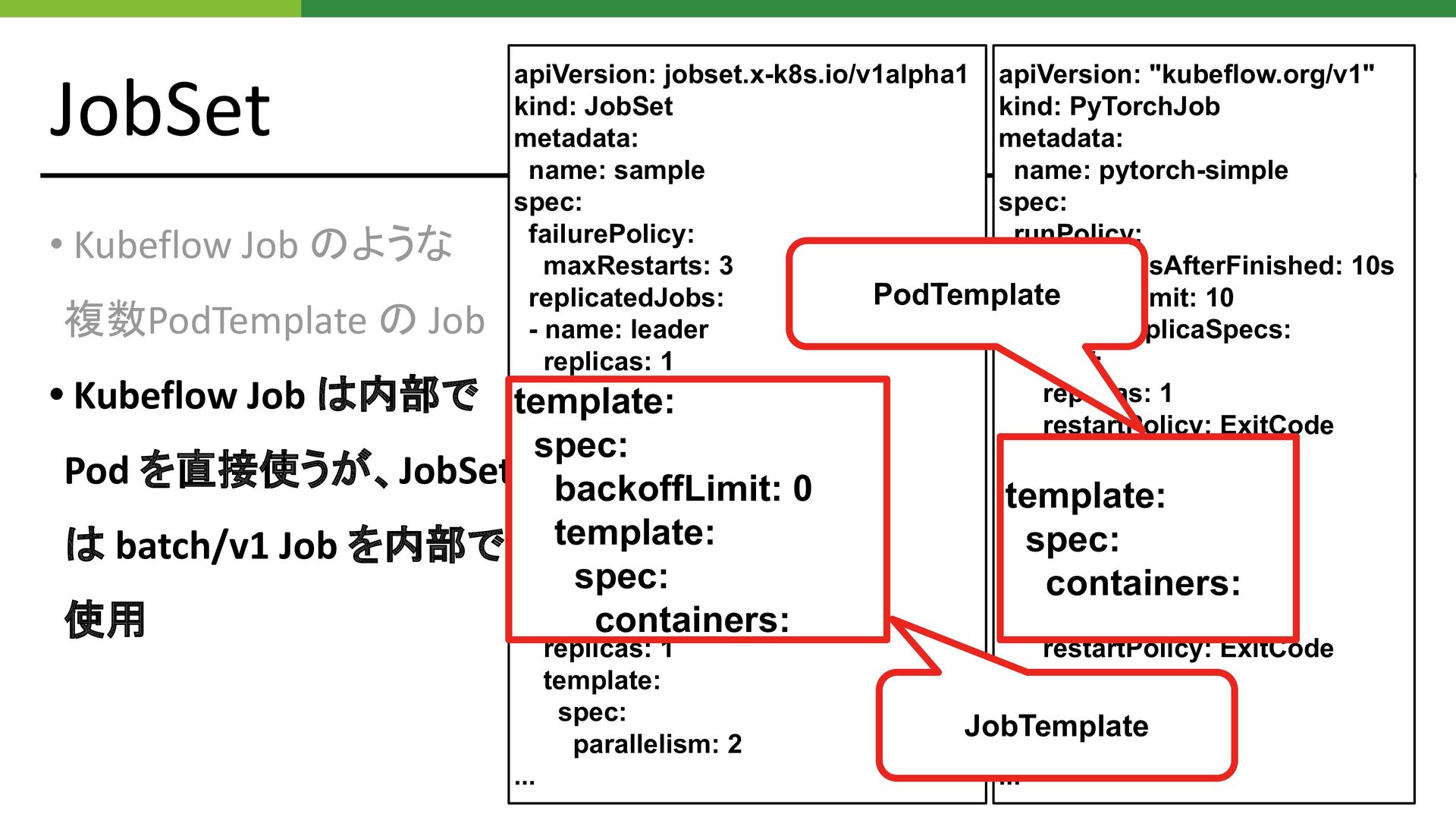
JobSet •Kubeflow Job のような 複数PodTemplate の Job • Kubeflow Job
は内部で Pod を直接使うが、JobSet は batch/v1 Job を内部で 使用 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... apiVersion: jobset.x-k8s.io/v1alpha1 kind: JobSet metadata: name: sample spec: failurePolicy: maxRestarts: 3 replicatedJobs: - name: leader replicas: 1 template: spec: backoffLimit: 0 template: spec: containers: ... - name: workers replicas: 1 template: spec: parallelism: 2 ...
JobSet • Kubeflow Job のような 複数 JobTemplate の Job •
Kubeflow Job は内部で Pod を直接使うが、JobSet は batch/v1 Job を内部で 使用 apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished: 10s backoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... apiVersion: jobset.x-k8s.io/v1alpha1 kind: JobSet metadata: name: sample spec: failurePolicy: maxRestarts: 3 replicatedJobs: - name: leader replicas: 1 template: spec: backoffLimit: 0 template: spec: containers: ... - name: workers replicas: 1 template: spec: parallelism: 2 ... replicatedJobs: - name: leader replicas: 1 template: spec: backoffLimit: 0 ... - name: workers replicas: 1 template: spec: parallelism: 2 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: ... Worker: replicas: 1 restartPolicy: ExitCode template:
apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorch-simple spec: runPolicy: ttlSecondsAfterFinished:
10s BackoffLimit: 10 pytorchReplicaSpecs: Chief: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... Worker: replicas: 1 restartPolicy: ExitCode template: spec: containers: ... apiVersion: jobset.x-k8s.io/v1alpha1 kind: JobSet metadata: name: sample spec: failurePolicy: maxRestarts: 3 replicatedJobs: - name: leader replicas: 1 template: spec: backoffLimit: 0 template: spec: containers: ... - name: workers replicas: 1 template: spec: parallelism: 2 ... JobSet • Kubeflow Job のような 複数PodTemplate の Job • Kubeflow Job は内部で Pod を直接使うが、JobSet は batch/v1 Job を内部で 使用 JobTemplate PodTemplate template: spec: backoffLimit: 0 template: spec: containers: template: spec: containers:
Job Queueing • Job をキューイングせず、Pending 状態で作り続けると Kubernetes Cluster (kube-apiserver &
etcd) のパフォーマンスが悪化する • kube-apiserver & etcd のパフォーマンスが悪化し続けると、 kube-controller-manager などの controller 類の動作が遅延して不整合が起き る Job Queueing がクラスタの安定性に直結
Job Queueing • Job をキューイングせず、Pending 状態で作り続けると Kubernetes Cluster (kube-apiserver &
etcd) のパフォーマンスが悪化する •kube-apiserver や etcd のパフォーマンスが悪化し続けると、 kube-controller-manager などの controller 類の動作が遅延して不整合が起き る Job Queueing がクラスタの安定性に直結 Job Level Queueing & Dynamic Quota Management が可能な Kueue を採用
Job Queueing • Kueue は Kubernetes SIG Scheduling と SIG
Apps (Job Controller) コアメンバに よる強力な開発体制がしかれていた SIG Scheduling テクニカルリード 2人 / メンテナ 1 人 / レビュワー 1 人 SIG Apps (Job Controller) レビュワー 1 人 • Kueue は Job レベル Queueing が可能で、Job が Dequeue されるまで Pod が 作成されない • kube-scheduler で培われたパフォーマンス向上テクニックが随所で使用され ていた • 一部の kubeflow Job に対応 MPIJob
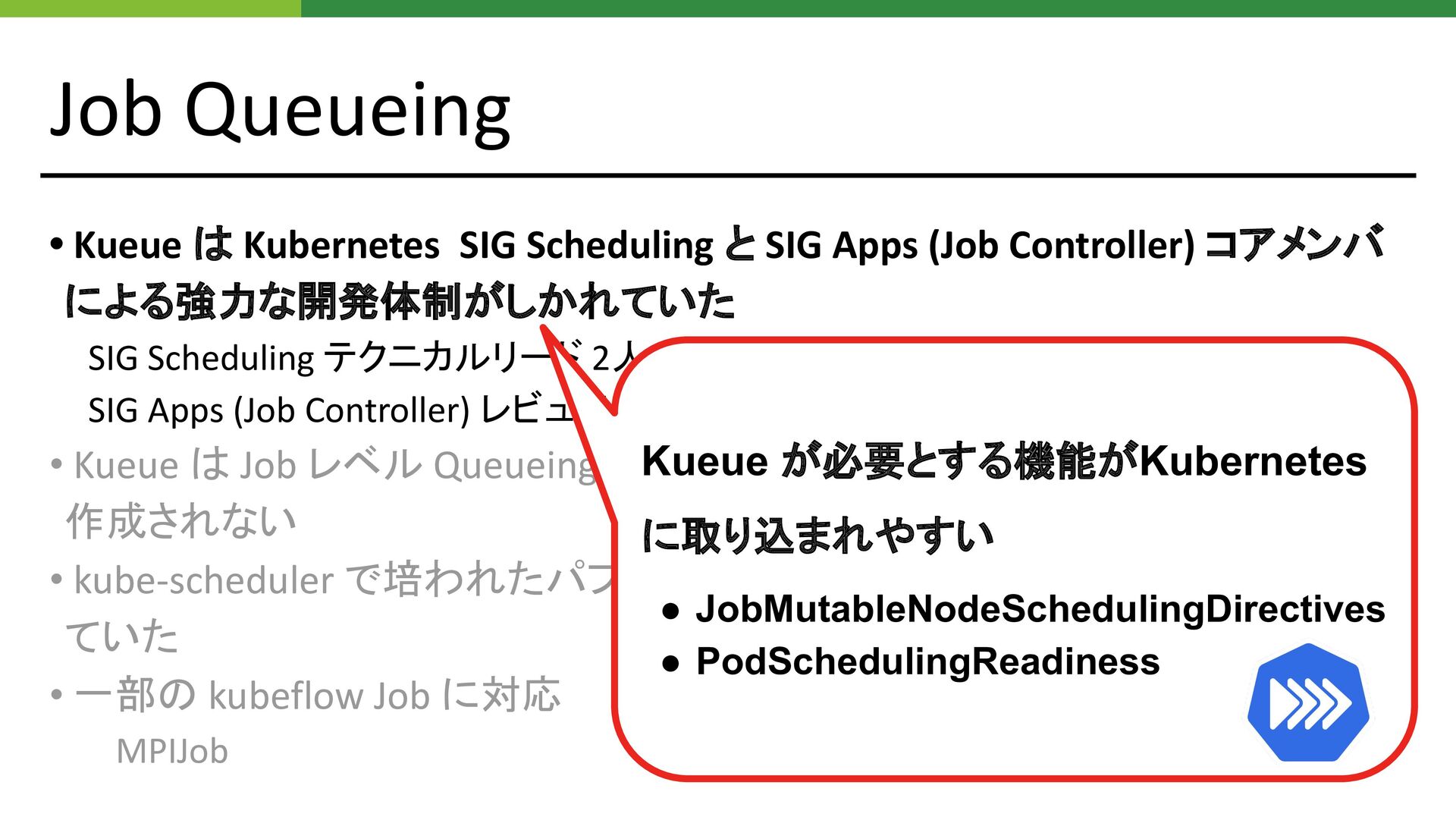
Job Queueing • Kueue は Kubernetes SIG Scheduling と SIG
Apps (Job Controller) コアメンバ による強力な開発体制がしかれていた SIG Scheduling テクニカルリード 2人 / メンテナ 1 人 / レビュワー 1 人 SIG Apps (Job Controller) レビュワー 1 人 • Kueue は Job レベル Queueing が可能で、Job が Dequeue されるまで Pod が 作成されない • kube-scheduler で培われたパフォーマンス向上テクニックが随所で使用され ていた • 一部の kubeflow Job に対応 MPIJob Kueue が必要とする機能がKubernetes に取り込まれやすい • JobMutableNodeSchedulingDirectives • PodSchedulingReadiness
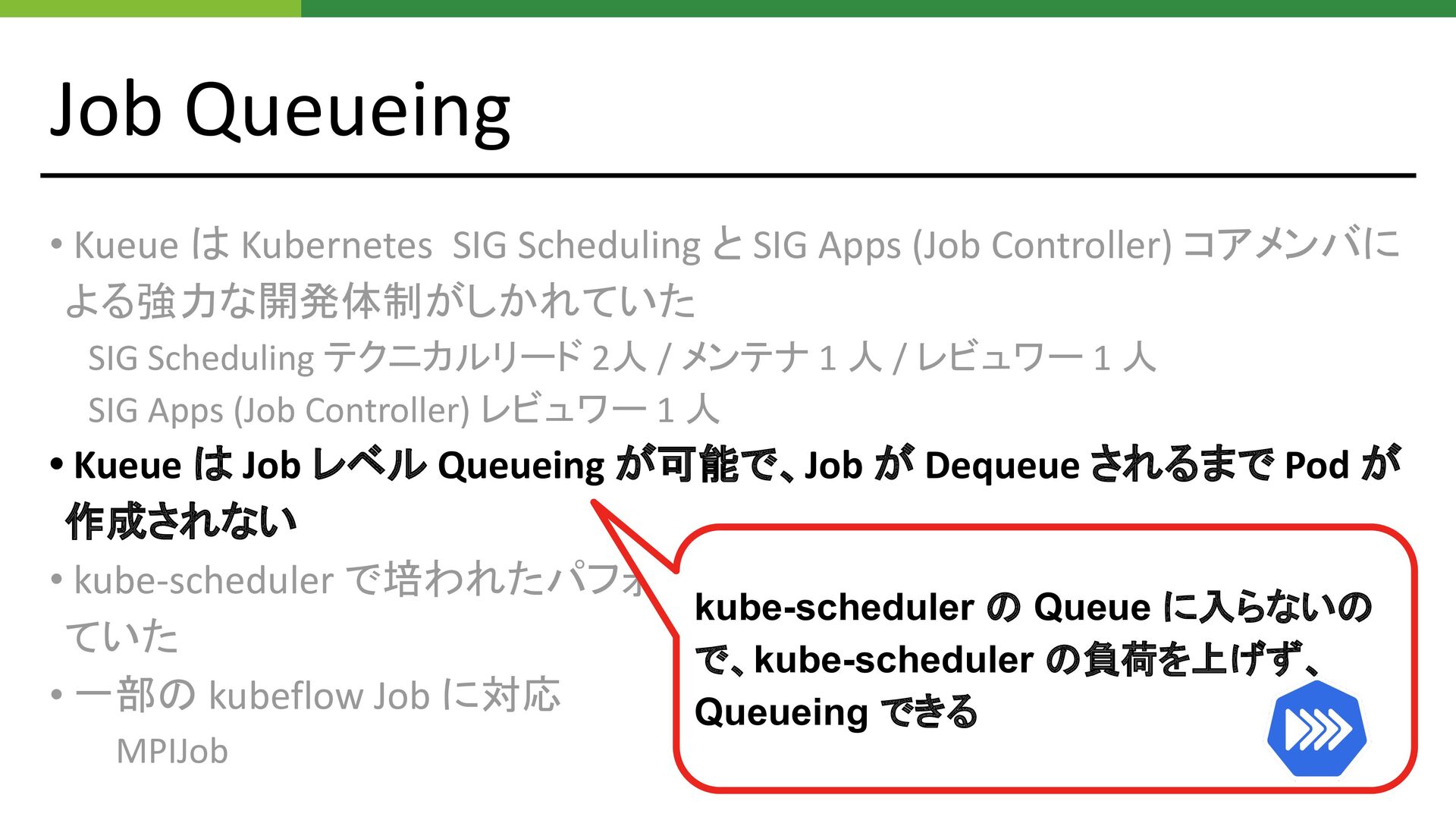
Job Queueing • Kueue は Kubernetes SIG Scheduling と SIG
Apps (Job Controller) コアメンバに よる強力な開発体制がしかれていた SIG Scheduling テクニカルリード 2人 / メンテナ 1 人 / レビュワー 1 人 SIG Apps (Job Controller) レビュワー 1 人 • Kueue は Job レベル Queueing が可能で、Job が Dequeue されるまで Pod が 作成されない • kube-scheduler で培われたパフォーマンス向上テクニックが随所で使用され ていた • 一部の kubeflow Job に対応 MPIJob kube-scheduler の Queue に入らないの で、kube-scheduler の負荷を上げず、 Queueing できる
Scheduling Pods for ML Workloads • ML ワークロードでは、複数の異なる役割 の Pod
を同時に動かす必要がある Chief - Worker パターン Parameter Server パターン • Gang Scheduling は複数の異なる役割の Podをまとめて Scheduling する • Scheduler Plugins / Coscheduling Kubernetes SIG Scheduling で開発 Kubeflow Native 対応 apiVersion: scheduling.x-k8s.io/v1alpha1 kind: PodGroup metadata: name: sample-pg spec: scheduleTimeoutSeconds: 10 minMember: 3 minResources: cpu: 10 memory: 16Gi
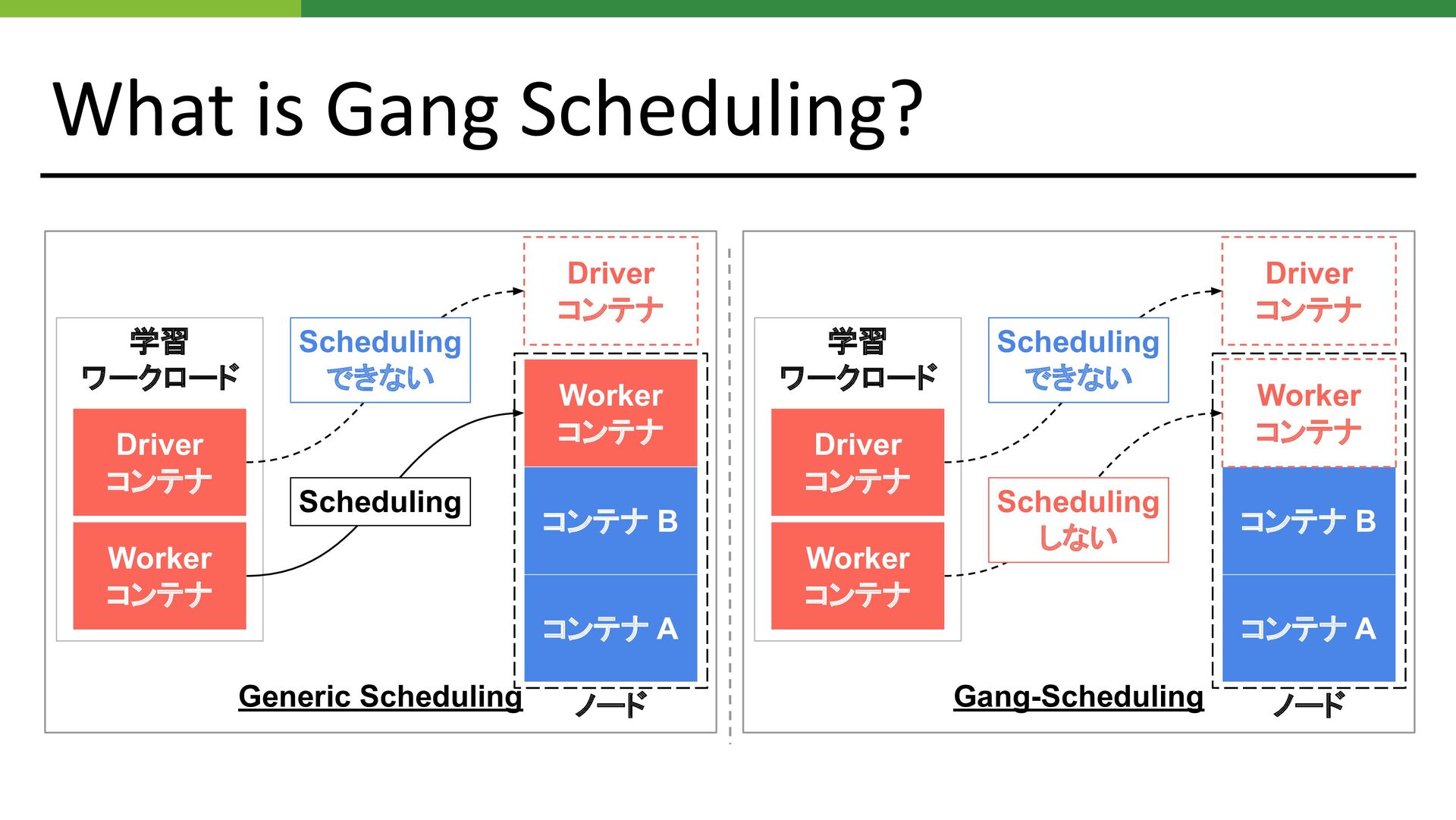
What is Gang Scheduling? • ML ワークロードでは、複数の異なる役割 の Pod を同時に動かす必要がある
Chief - Worker パターン Parameter Server パターン • Gang Scheduling は複数の異なる役割の Podをまとめて Scheduling する • Scheduler Plugins / Coscheduling Kubernetes SIG Scheduling で開発 Kubeflow Native 対応 apiVersion: scheduling.x-k8s.io/v1alpha1 kind: PodGroup metadata: name: sample-pg spec: scheduleTimeoutSeconds: 10 minMember: 3 minResources: cpu: 10 memory: 16Gi
What is Gang Scheduling? 学習 ワークロード ノード Driver コンテナ コンテナ
A Worker コンテナ コンテナ B Worker コンテナ Driver コンテナ Scheduling できない Scheduling Generic Scheduling Gang-Scheduling 学習 ワークロード ノード Driver コンテナ コンテナ A Worker コンテナ コンテナ B Worker コンテナ Driver コンテナ Scheduling できない Scheduling しない
Scheduler Plugins • ML ワークロードでは、複数の異なる役割 の Pod を同時に動かす必要がある Chief -
Worker パターン Parameter Server パターン •Gang Scheduling は複数の異なる役割の Podをまとめて Scheduling する • Scheduler Plugins / Coscheduling Kubernetes SIG Scheduling で開発 Kubeflow Native 対応 apiVersion: scheduling.x-k8s.io/v1alpha1 kind: PodGroup metadata: name: sample-pg spec: scheduleTimeoutSeconds: 10 minMember: 3 minResources: cpu: 10 memory: 16Gi Node上で minResource が確保 できたら Pod を Scheduling minResources: cpu: 10 memory: 16Gi minMember: 3 Node上に minMember の数の Pod が作成されたら Scheduling
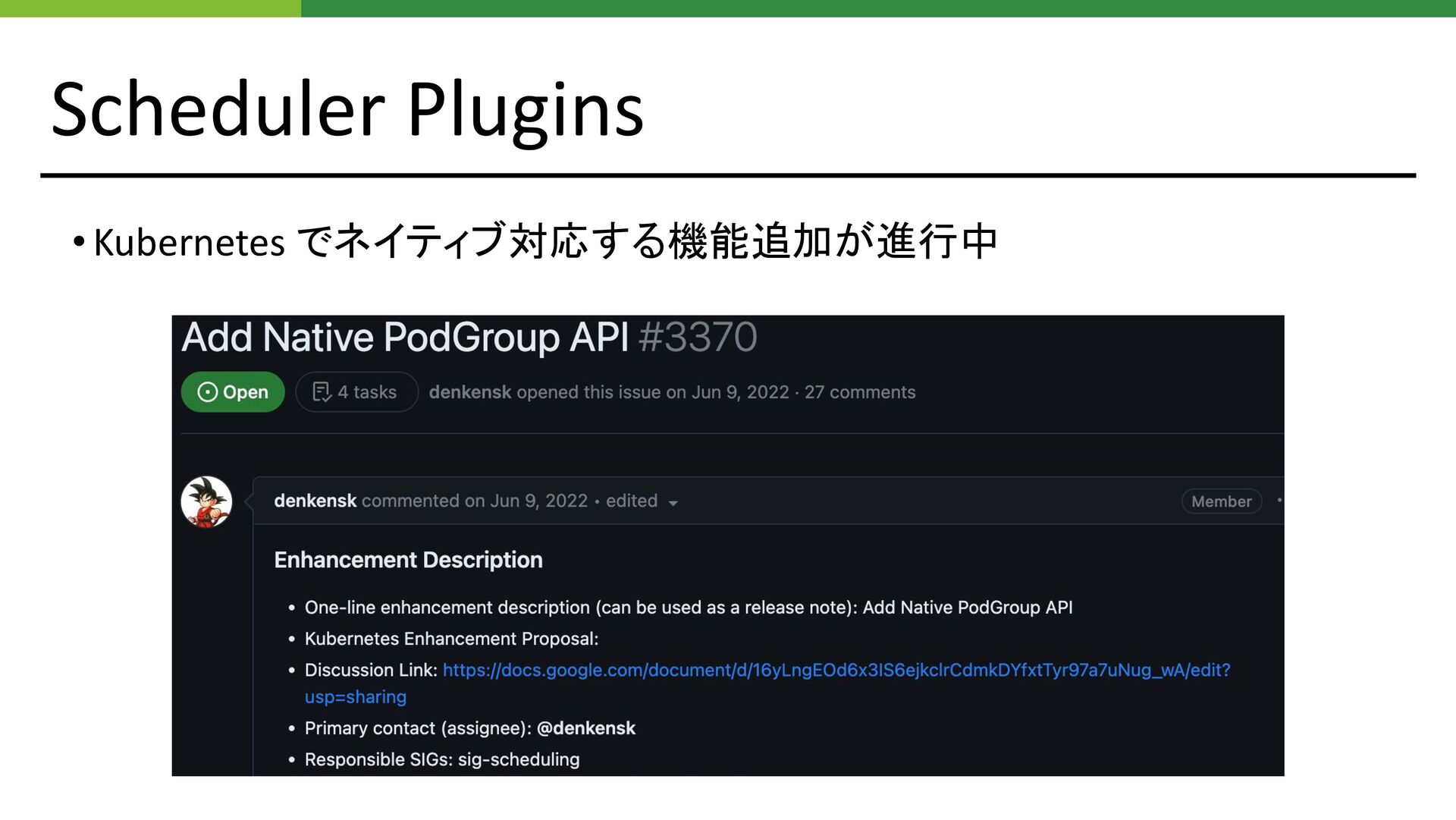
Scheduler Plugins • Kubernetes でネイティブ対応する機能追加が進行中
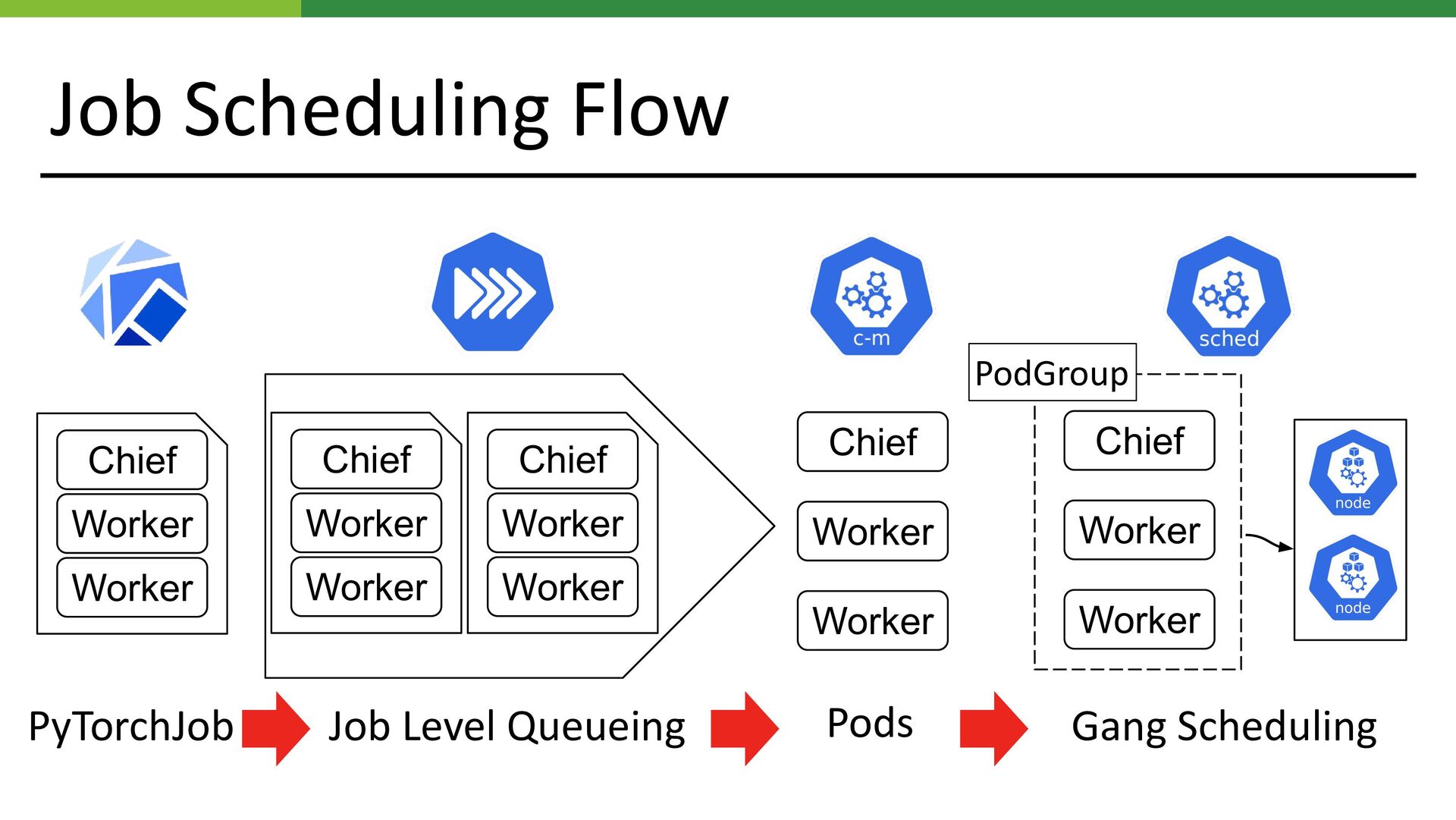
Job Scheduling Flow Job Level Queueing Chief Worker Worker PyTorchJob
Chief Worker Worker Chief Worker Worker Gang Scheduling Chief Worker Worker Pods Chief Worker Worker PodGroup
Conclusion • 社内基盤の要件を反映させた上で OSS ベースの基盤を構築可能 • OSS コミュニティ牽引によるメリット OSS だけどプロダクト
(ML Platform) の要望をダイレクトに反映できる 社外から多くのフィードバックを受けることができる OSS を使用しているの QoS が向上される 非標準化仕様によるメンテナンスコスト上昇の危険性を回避しやすい • OSS コミュニティ牽引の苦労 各社要望のせめぎあい 時差
Next ML Platform (We are hiring!) • 現状の ML Platform
は計算基盤色がつよい AI 技術の研究開発組織 (AI Lab) がメインターゲットだった • MLOps を実現するための基盤を提供 Pipeline / Workflow / Feature Store • 計算基盤としての機能もより強化 対応フレームワークの拡充やストレージ IO の改善 計算基盤としての ML Platform & MLOps 基盤としての ML Platform
参考文献 • Kubernetes: https://kubernetes.io/ • Kubeflow: https://www.kubeflow.org/ • Google Cloud
Platform: https://cloud.google.com/ • Amazon Web Service: https://aws.amazon.com/ • NVIDIA: https://www.nvidia.com • NetApp: https://www.netapp.com
FIN
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}