□ https://osdn.jp/projects/jposug/ ▪ Piwikjapan — I make patches to solve the problems under multibyte character set./ I give the lecture at OSC (Open Source Conference) Tokyo twice a year. □ https://osdn.jp/projects/piwik-fluentd/ 2 of 47
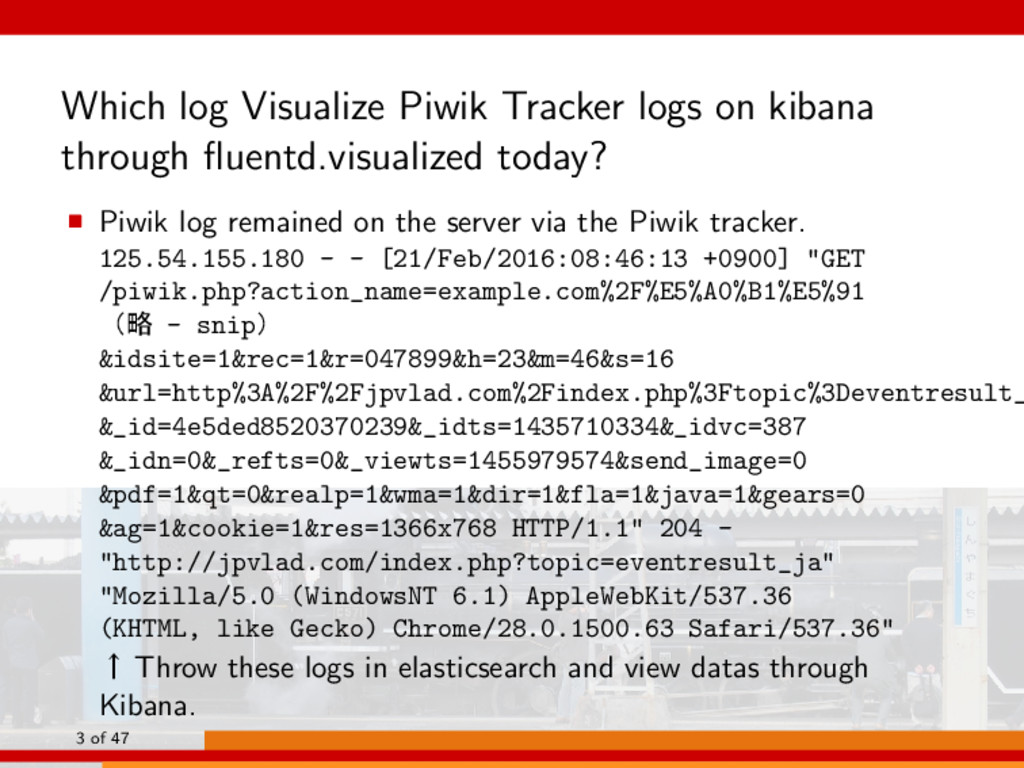
today? ▪ Piwik log remained on the server via the Piwik tracker. 125.54.155.180 - - [21/Feb/2016:08:46:13 +0900] "GET /piwik.php?action_name=example.com%2F%E5%A0%B1%E5%91 ʢུ - snipʣ &idsite=1&rec=1&r=047899&h=23&m=46&s=16 &url=http%3A%2F%2Fjpvlad.com%2Findex.php%3Ftopic%3Deventresult_ &_id=4e5ded8520370239&_idts=1435710334&_idvc=387 &_idn=0&_refts=0&_viewts=1455979574&send_image=0 &pdf=1&qt=0&realp=1&wma=1&dir=1&fla=1&java=1&gears=0 &ag=1&cookie=1&res=1366x768 HTTP/1.1" 204 - "http://jpvlad.com/index.php?topic=eventresult_ja" "Mozilla/5.0 (WindowsNT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.63 Safari/537.36" ˢ Throw these logs in elasticsearch and view datas through Kibana. 3 of 47
▪ These data are recorded even without tracker □ client ip addresses, user agent, referer ▪ Using piwik tracker sends additional data □ idsite: The ID of the website we’re tracking a visit/action for. □ action name: Page title which looked at by client. □ id: The unique visitor ID □ res: Client’s screen resolution □ pdf: Does client browser include pdf addon ? □ java: java ? □ fla: flash ? □ cookie: Client browser allowed to accept cookies. □ viewts: The timestamp of this visitor’s previous visit. ▪ Others look at the link: “Supported Query Parameters1” 1http://developer.piwik.org/api-reference/tracking-api 5 of 47
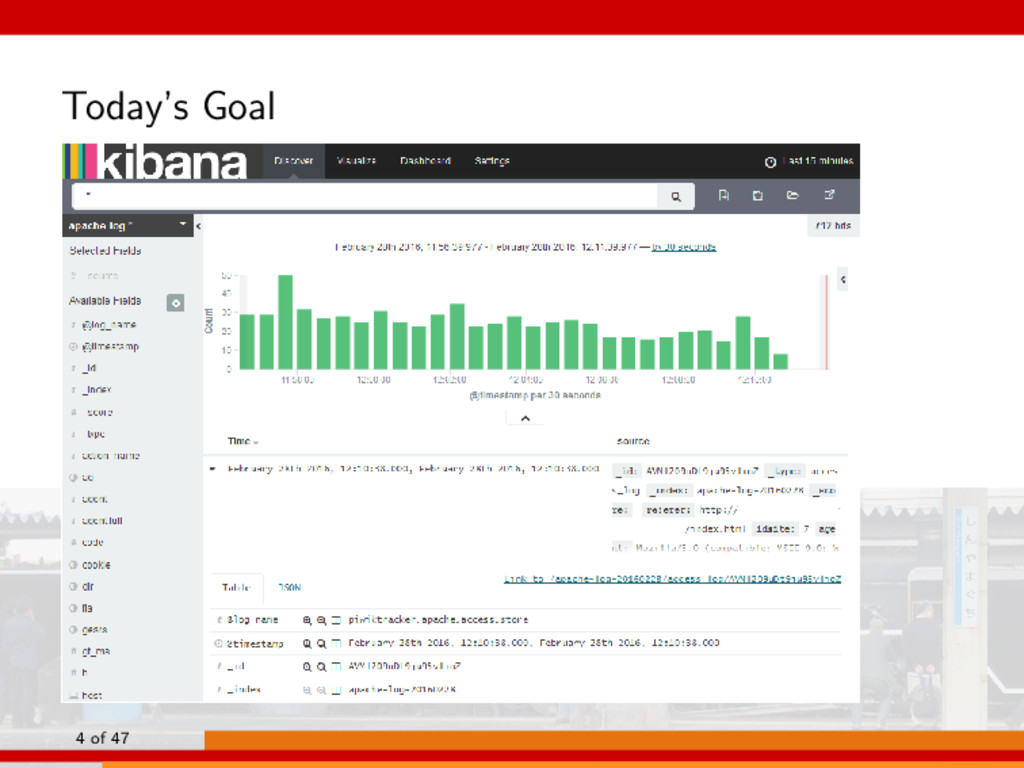
2. Records about visits on each site are collected on a server using the Piwik tracker. □ Piwik tracker directly calls PHP programs and this behavior is also recorded in the Piwik server log □ Always Piwik tracker uses GET method. 3. Server logs are stored on elasticsearch through fluentd. □ Elasticsearch is a full-text, distributed NoSQL database. □ Fluentd performs URL decode process for some data. 4. Kibana used for visualization. Kibana has the ability for visualization of data that was stored in elasticsearch. 6 of 47
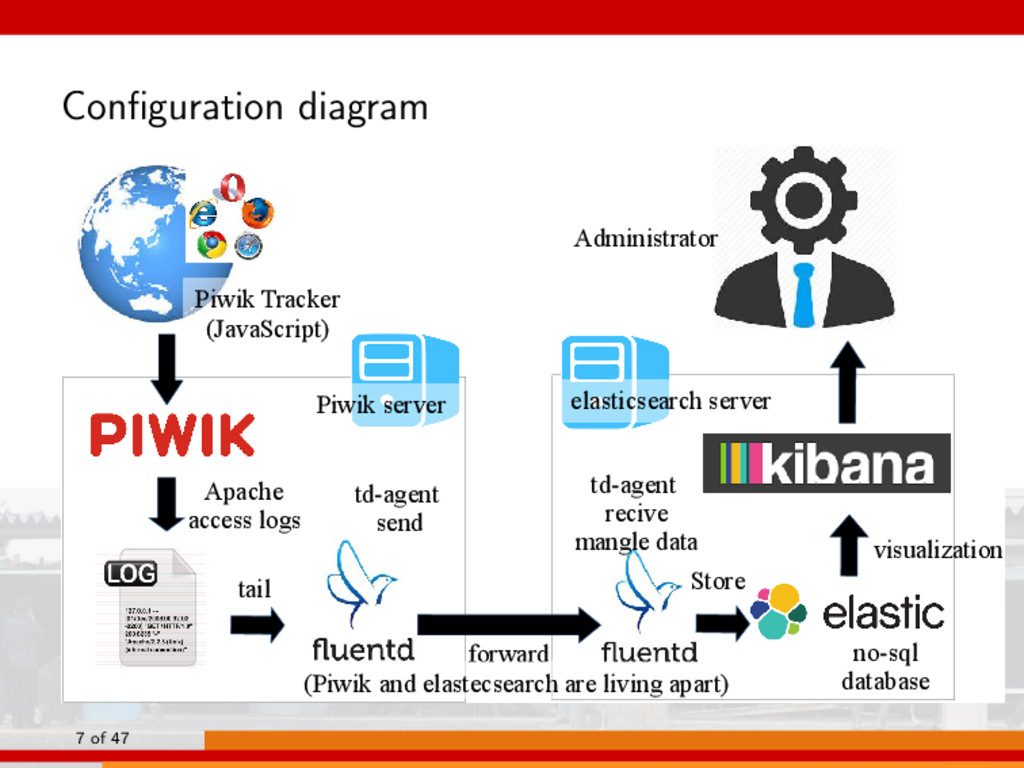
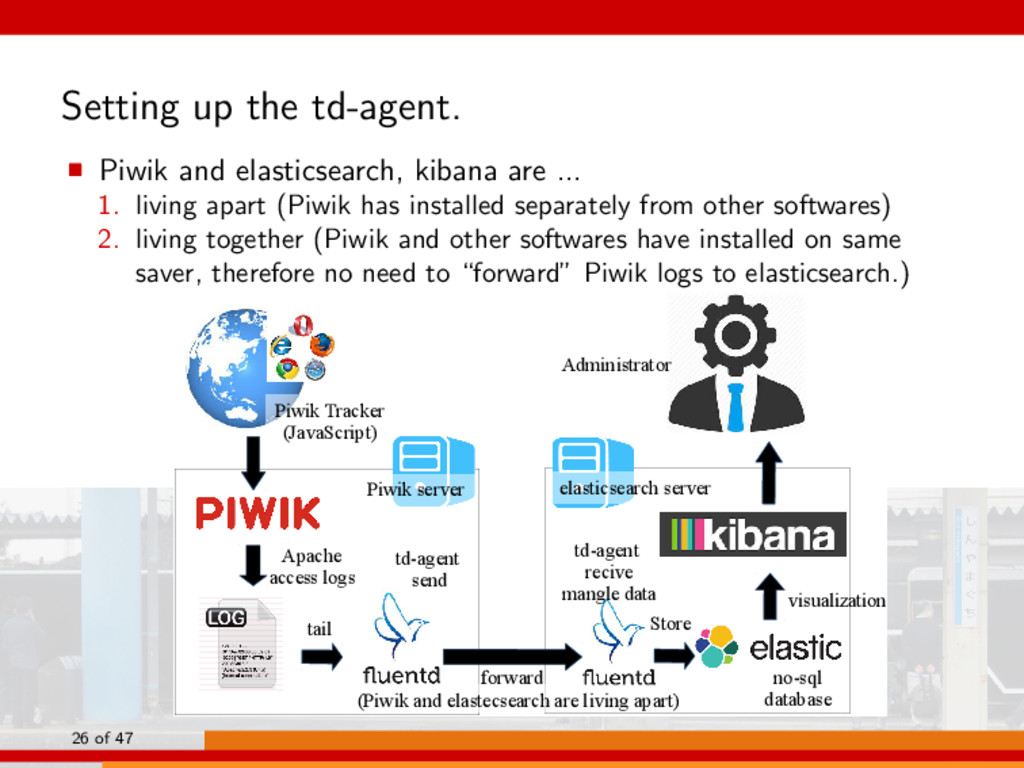
Apache access logs tail no-sql database Piwik Tracker (JavaScript) Administrator Piwik server elasticsearch server forward (Piwik and elastecsearch are living apart) 7 of 47
default. □ When I confirmed the other way under the RedHat 6, I wrote (RedHat6). □ (RedHat6)· · · CentOS6, Scientific Linux 6 ▪ Assume that the Piwik already working on your server. □ Please see the link to install the Piwik2. ▪ We will install fluentd, elasticsearch and kibana have installed on the same server. □ I’ll explain that Piwik and other softwares have installed on same server (living together), and Piwik has installed separately from other softwares (living apart). 2http://piwik.org/docs/installation 8 of 47
the td-agent that is wrapper for the fluentd. ▪ Refer to the version 2.x of td-agent (1.9.x has stopped updating). ▪ We use the RPM package to protect interfere with genuine Ruby. □ The fluentd consisting of Ruby. □ Genuine RedHat6 – Ruby 1.9.3 □ Genuine RedHat7 – Ruby 2.0 □ But td-agent 2.x requires Ruby 2.2. ▪ Put additional plugins into fluentd in advance. □ You can find the td-agent RPM from binary, but. . . e.g. elasticsearch gem not included in genuine td-agent RPM. □ I don’t know how to install additional gem(s) after installation td-agent RPM, so I want to install prepared. □ ˢ This is why in advance to make special RPM. 9 of 47
Ruby 2.2.4. 1. Prepare the development environment of RedHat, in which Ruby is not installed yet. ▪ Of course, you can use CentOS or Scientific linux. ▪ Version 6 or 7 2. Remove the td-agent RPM, if you have already installed it. 3. Install the development tools in order to make RPM from SRPM. $ sudo yum groupinstall "Development tools" 4. Download “ruby223.spec” from this link “how to make Ruby RPM for CentOS 6 (in Japanese)3”. 5. Hit Ctrl+C and quit in the middle to make directories to make RPM. $ rpmbuild -bp ruby223.spec (Hit Ctrl+C) (Maybe directory ~/rpmbuild appeared.) $ mv ruby223.spec rpmbuild/SPECS/ruby224.spec 3http://www.torutk.com/projects/swe/wiki/CentOS 6 Ͱ ruby ͷ RPM ύο έʔδΛ࡞Δ 10 of 47
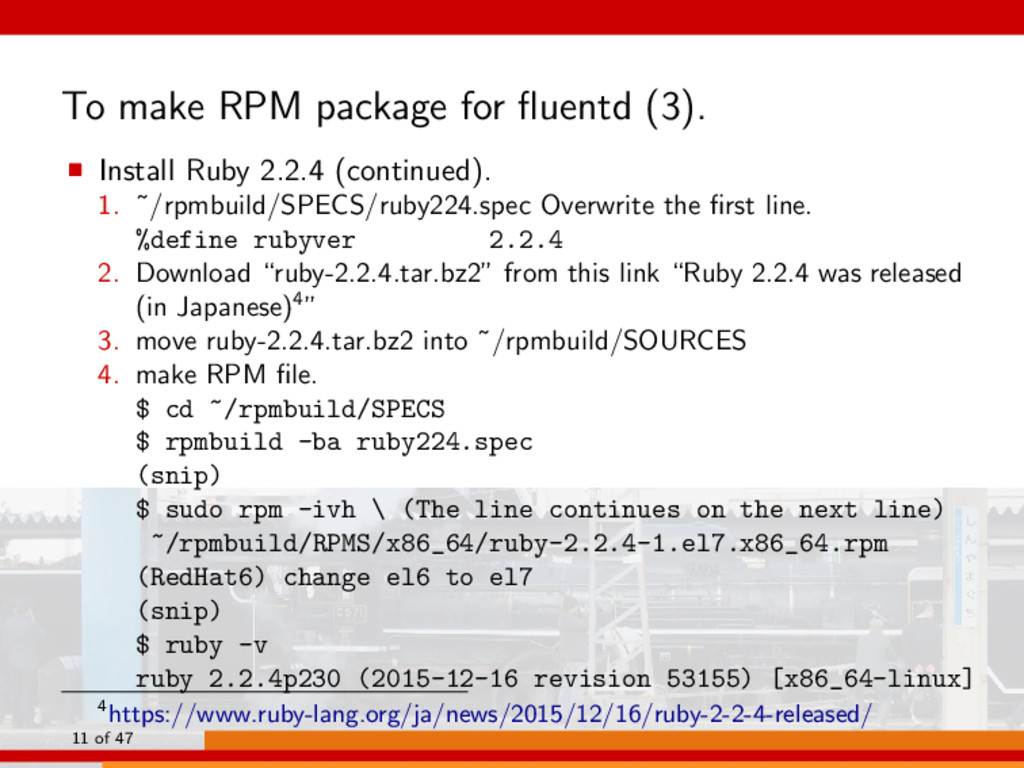
2.2.4 (continued). 1. ˜/rpmbuild/SPECS/ruby224.spec Overwrite the first line. %define rubyver 2.2.4 2. Download “ruby-2.2.4.tar.bz2” from this link “Ruby 2.2.4 was released (in Japanese)4” 3. move ruby-2.2.4.tar.bz2 into ˜/rpmbuild/SOURCES 4. make RPM file. $ cd ~/rpmbuild/SPECS $ rpmbuild -ba ruby224.spec (snip) $ sudo rpm -ivh \ (The line continues on the next line) ~/rpmbuild/RPMS/x86_64/ruby-2.2.4-1.el7.x86_64.rpm (RedHat6) change el6 to el7 (snip) $ ruby -v ruby 2.2.4p230 (2015-12-16 revision 53155) [x86_64-linux] 4https://www.ruby-lang.org/ja/news/2015/12/16/ruby-2-2-4-released/ 11 of 47
need to be updated for more than 1.8. $ wget http://dl.marmotte.net/rpms/redhat/el6/x86 64/\ git-1.8.3.1-3.el6/git-1.8.3.1-3.el6.src.rpm $ cp ~/rpmbuild/SRPMS/git-1.8.3.1-3.el6.src.rpm $ rpmbuild --rebuild \ ~/rpmbuild/SRPMS/git-1.8.3.1-3.el6.src.rpm $ sudo yum install perl-TermReadKey $ sudo rpm -ivh \ ~/rpmbuild/RPMS/x86 64/git-1.8.3.1-3.el6.x86_64.rpm □ Need the option “-c” on git to build, but less than 1.8 is not supported this option. ▪ git version 1.8 or more is not included in genuine packages. ▪ You can find a few roving git SRPM, but we choose SRPM which requires RPMS consisting only of epel. 13 of 47
environment and download td-agent sources. 1. Install bundle $ sudo gem install bundler 2. Clone the td-agent repository to local. $ cd ~ $ git clone \ (The line continues on the next line) [email protected]:treasure-data/omnibus-td-agent.git $ cd ~/omnibus-td-agent 3. Then we go according to treasure-data/omnibus-td-agent5 plan, but on the way make RPM will fail to resolve dependencies, so insert a row in the middle of Gemfile is shown on the following page. 5https://github.com/treasure-data/omnibus-td-agent 14 of 47
elasticsearch, record-reformer, norikra plugins into RPM package. □ Today, I don’t make mention of the Norikra. ▪ Add 3 lines to bottom of ˜/omnibus-td-agent/plugin gems.rb. download "fluent-plugin-norikra", "0.2.2" download "fluent-plugin-elasticsearch", "1.3.0" download "fluent-plugin-record-reformer", "0.8.0" 16 of 47
plugins to resolve dependencies of Norikra. □ But today I don’t make mention of the Norikra. □ norikra-client requires msgpack-rpc-over-http, msgpack-rpc-over-http requires rack. But, rack 2.x will make errors, so enforce version 1.6.4. ▪ Add 2 lines to bottom of ˜/omnibus-td-agent/core gems.rb. download "rack", "1.6.4" download "norikra-client", "1.3.1" 17 of 47
instructions8. $ cd ~/omnibus-td-agent $ bundle install --binstubs (snip, Sudo asks you on the way for the password.) $ bin/gem_downloader core_gems.rb (snip) $ bin/gem_downloader plugin_gems.rb (snip) $ bin/omnibus build td-agent2 (snip) 8https://github.com/treasure-data/omnibus-td-agent 19 of 47
the following lines into one line. $ sudo yum install \ https://download.elasticsearch.org/elasticsearch/\ release/org/elasticsearch/distribution/\ rpm/elasticsearch/2.2.0/elasticsearch-2.2.0.rpm 2. Install Kuromoji plugin. Kuromoji is an open source Japanese morphological analyzer written in Java. Write the following lines into one line. $ sudo /usr/share/elasticsearch/bin/plugin \ install analysis-kuromoji 21 of 47
of installation method of Kibana on RedHat6. Please see the link: “Setup kibana49”. ▪ There is startup script on site too. ▪ I will try to make SPEC file, if I feel like it. 9http://qiita.com/nagomu1985/items/82e699dde4f99b2ce417 23 of 47
mention of the Norikra (26578/tcp). 2. Add a line to text after “-A INPUT -m state –state ESTABLISHED,RELATED -j ACCEPT” of /etc/sysconfig/iptables. -A INPUT -m multiport -p tcp -m tcp \ Continues on next line --dports 26578,5651,24224 -j ACCEPT -A INPUT -m multiport -p udp -m udp --dports 24224 -j ACCEPT 3. Reload the firewall for changes to take effect. $ sudo service iptables reload 25 of 47
... 1. living apart (Piwik has installed separately from other softwares) 2. living together (Piwik and other softwares have installed on same saver, therefore no need to “forward” Piwik logs to elasticsearch.) td-agent send td-agent recive mangle data Store visualization Apache access logs tail no-sql database Piwik Tracker (JavaScript) Administrator Piwik server elasticsearch server forward (Piwik and elastecsearch are living apart) 26 of 47
and elasticsearch has installed on different servers. □ Install td-agent on both servers. □ Configuration file: /etc/td-agent/td-agent.conf ▪ It is shown on the following pages as an example, you should gather together to one file. ▪ If example protrudes outside screen, snip off. □ For that reason, look for the link “Collect Piwik tracking datas using the elasticsearch10”, I have written fully configuration there. 10https://osdn.jp/projects/piwik-fluentd/wiki/FrontPage 27 of 47
Piwik server. □ Siphon Piwik access logs from Piwik server by fluentd. □ The following data processing continues by “tag piwiktracker.apache.access”. <source> type tail format apache time_format %d/%b/%Y:%H:%M:%S %z pos_file /var/log/td-agent/access_log.pos path /var/log/httpd/access_log tag piwiktracker.apache.access </source> 28 of 47
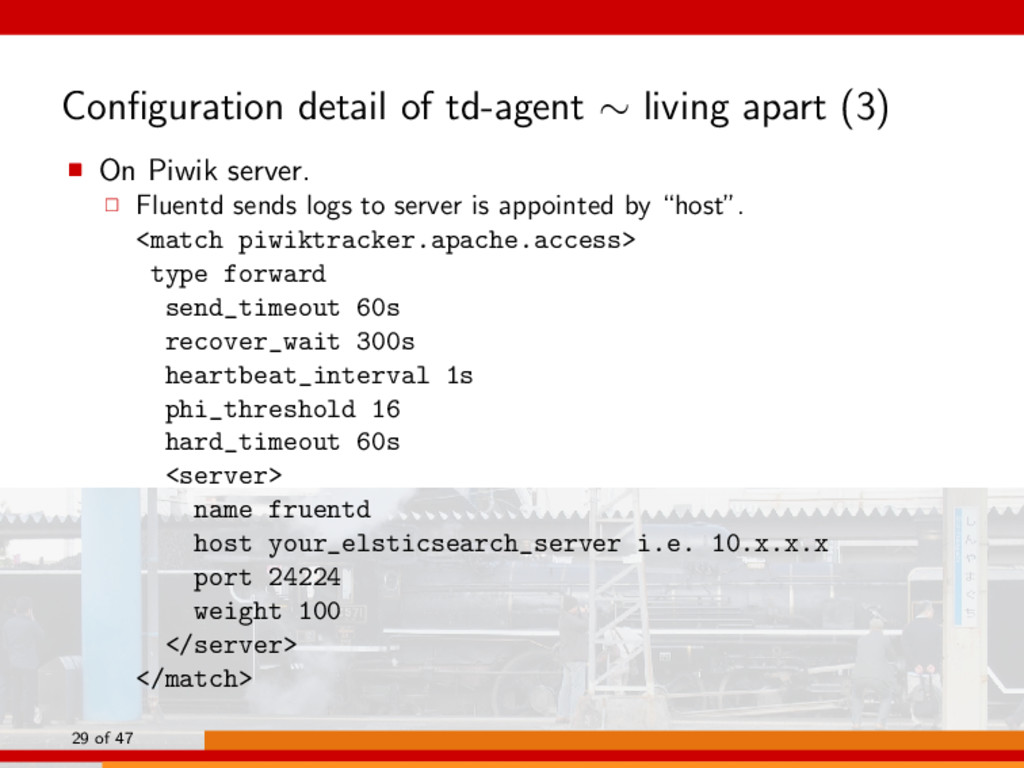
Piwik server. □ Fluentd sends logs to server is appointed by “host”. <match piwiktracker.apache.access> type forward send_timeout 60s recover_wait 300s heartbeat_interval 1s phi_threshold 16 hard_timeout 60s <server> name fruentd host your_elsticsearch_server i.e. 10.x.x.x port 24224 weight 100 </server> </match> 29 of 47
elasticsearch server. □ Tracker logs are extracted from Piwik access logs. 1. Throw away logs when someone looked control panels of Piwik. 2. Throw away logs when someone used APIs of Piwik. 3. After the “filter”, go to “match piwiktracker.apache.access”. <filter piwiktracker.apache.access> type grep regexp1 path /piwik\.php\?action name=.*\&idsite=\d+ </filter> <match piwiktracker.apache.access> type record_reformer tag piwiktracker.apache.access.urldecode (snip, continued on next page) 30 of 47
elasticsearch server. □ Parses the query string passed via a URL and sets variables of fluentd. See “Supported Query Parameters11” for reference. □ Don’t begin with underscore: “ ”. And “id” is unusable. □ After set variables, go to “piwiktracker.apache.access.urldecode”. <match piwiktracker.apache.access> type record_reformer tag piwiktracker.apache.access.urldecode (3 variables out of 29 as shown here.) idsite ${path[/piwik\.php\? action name=.*\&idsite=(\d+)/,1]} ˡ site ID piwikid ${path[/piwik\.php\?action name= .*\& id=([a-z\d]+)/,1]} ˡ unique ID fla ${path[/piwik\.php\?action name= ˡ have flash addon? .*\&fla=(\d+)/,1] == "1" ? "true" : "false" } </match> 11http://developer.piwik.org/api-reference/tracking-api 31 of 47
elasticsearch server. □ Decodes URL-encoded variables on fluentd. □ After decode, go to “piwiktracker.apache.access.store”. <match piwiktracker.apache.access.urldecode> type uri_decode tag piwiktracker.apache.access.store key_names action_name,ref,url,urlref </match> 32 of 47
elasticsearch server. □ You can send to other than elasticsearch by use of multiple <store>. <match piwiktracker.apache.access.store> type copy <store> type elasticsearch type_name access_log host 127.0.0.1 port 9200 logstash_format true logstash_prefix apache-log logstash_dateformat %Y%m%d include_tag_key true tag_key @log_name flush_interval 10s </store> </match> 33 of 47
and elasticsearch have installed on the same server. □ And install td-agent together and open the port. □ Configuration file: /etc/td-agent/td-agent.conf ▪ Basically, combine the two servers configurations that I explained on “living apart”. ▪ Today I will show tags only. □ Look for the link: “Collect Piwik tracking datas using the elasticsearch12”, where I have written fully configuration. 12https://osdn.jp/projects/piwik-fluentd/wiki/FrontPage 34 of 47
and elasticsearch have installed on the same server. □ Today I show tags only. I haven’t made any changes in the contents compared with “living apart”. ▪ But there is no “type forward”, existed on the condition of “living apart” on the part of Piwik server. <source> tag piwiktracker.apache.access </source> <match piwiktracker.apache.access> tag piwiktracker.apache.access.urldecode </match> <match piwiktracker.apache.access.urldecode> tag piwiktracker.apache.access.store </match> <match piwiktracker.apache.access.store> </match> 35 of 47
fluentd and elasticsearch, then when the data is thrown in elasticsearch, it will make the type (it looks like DDL on relational database) automatically. ▪ But all fields (it looks like columns on relational database) will make with string. ▪ Therefore, we set the datatypes. 36 of 47
in JSON include both settings and mappings, and a simple pattern template that controls whether the template should be applied to the new index14. ▪ I show the important elements of the template, in order to understand main point, because it is too long. You can download the perfect template on this site: “Configuration mapping of elasticsearch15”. 14https://www.elastic.co/guide/en/elasticsearch/reference/current/indices- templates.html 15https://osdn.jp/projects/piwik-fluentd/wiki/ elasticsearch#h2-elasticsearch.20.E3.81.AE.20mapping.20.E8.A8.AD.E5.AE.9A 38 of 47
This mapping applies to the “apache-log-*” index16. “apache-log” must fit in with logstash prefix apache-log in td-agent.conf. The elasticsearch makes daily indexes “apache-log-YYYYMMDD” because we have written logstash dateformat %Y%m%d in td-agent.conf, therefore, you must add “-*” suffix. ▪ ”settings”: { It’s possible that Piwik tracker logs include Japanese articulation. So I set Kuromoji datatype. Please refer to “A note to make good full-text search in Japanese17”. 16It looks like “table” on relational database. 17http://tech.gmo-media.jp/post/70245090007/elasticsearch-kuromoji- japanese-fulltext-search 39 of 47
”access log”: { ”access log” is name of type. “access log” must fit in with type name access log in td-agent.conf18. 18“ default ” will be applied on all types. 40 of 47
of the automatically generated fields1920. □ Disable source and all to reduce increase in capacity of indexes. "mappings": { "access log": { ˡ name of type " source": { ˡ the actual JSON as data. "enabled": "false" ˡ not need. default: true }, " all": { ˡ special catch-all field. "enabled": "false" ˡ not need. default: true }, 19https://www.elastic.co/guide/en/elasticsearch/reference/1.4/mapping-all- field.html 20https://www.elastic.co/guide/en/elasticsearch/reference/1.4/mapping-source- field.html 41 of 47
of the specified fields in td-agent.conf. "mappings": { "access log": { (snip, described on the previous page) "properties": { "@log name": { ˠ field name (see td-agent.conf) "type": "string", ˠ datatype "store": "true", ˠ to retrieve the value "index": "not analyzed" ˠ don’t parse text }, ▪ See “Mapping parameters21”. 21https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping- params.html 42 of 47
of the specified fields in td-agent.conf. □ Continued from the previous page. "ref": { ˡ field name (see td-agent.conf) "type": "multi field", "fields": { ˡ set 2 datasets on one field "ref": { "type": "string", "index": "analyzed", ˡ English analysis "store": "true" }, "full": { "type": "string", "index": "not analyzed", ˡ don’t parse text "store": "true" } } 43 of 47
of the specified fields in td-agent.conf. □ Continued from the previous page. "action_name": { "type": "string", "analyzer": "kuromoji analyzer", ˡ Japanese analysis "store": "true" }, 44 of 47
paste from “Configuration mapping of elasticsearch22” to ˜/piwik-template.json 2. Start the elasticsearch. $ sudo service elasticsearch start 3. Define a template named piwik-tracker. Write on the same line. $ curl -XPUT localhost:9200/_template/piwik-tracker \ -d "‘cat ~/piwik-template.json‘" 22https://osdn.jp/projects/piwik-fluentd/wiki/elasticsearch#h2- elasticsearch.20.E3.81.AE.20mapping.20.E8.A8.AD.E5.AE.9A 45 of 47
you have set “living apart”. $ sudo service td-agent start $ sudo service kibana start ▪ Management of kibana: http://your elasticserach server:5601/ 46 of 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}