Microservices are the current "big thing" and most of the current technologies seems to be a fit for greenfield projects. Unfortunately the great majority of developers can't build something from scratch and have a big legacy database with multiple relationships. The code usually is the easy part. The question that every enterprise developer asks is: what about my database?
Come to this session to learn the required database refactorings, architecture and deployment strategies that will enable you to split your big monolithic database into Microservices. And downtime is not an option! We'll show how we need to encompass code, architecture, DevOps and infrastructure altogether to accomplish this awesome evolution of your application with your database.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
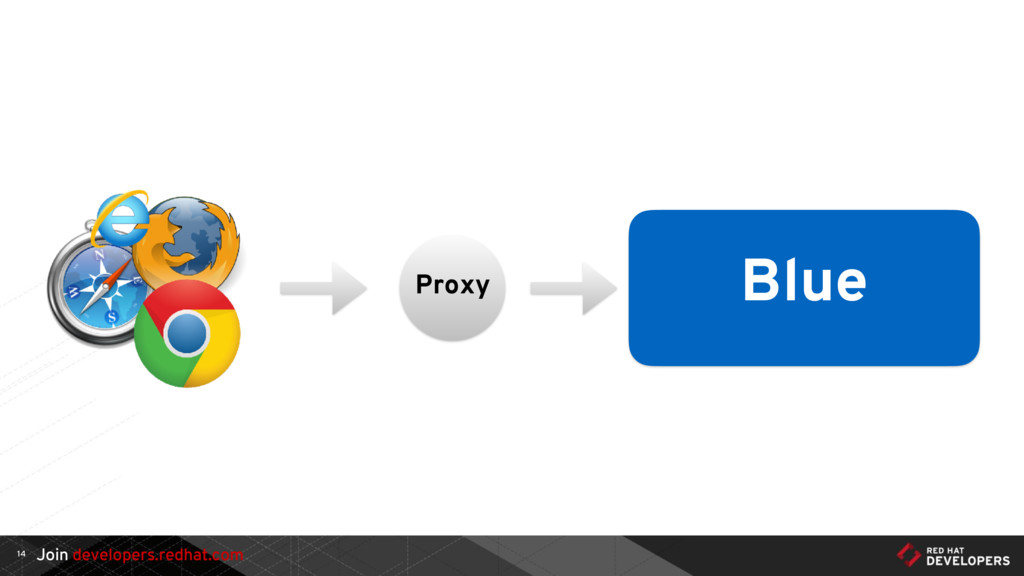{kind=link}
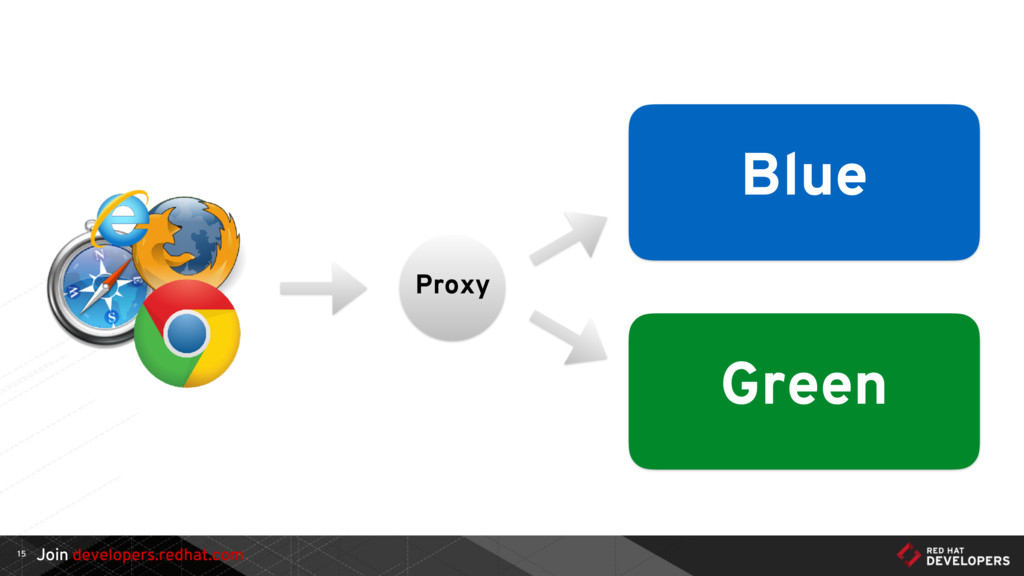{kind=link}
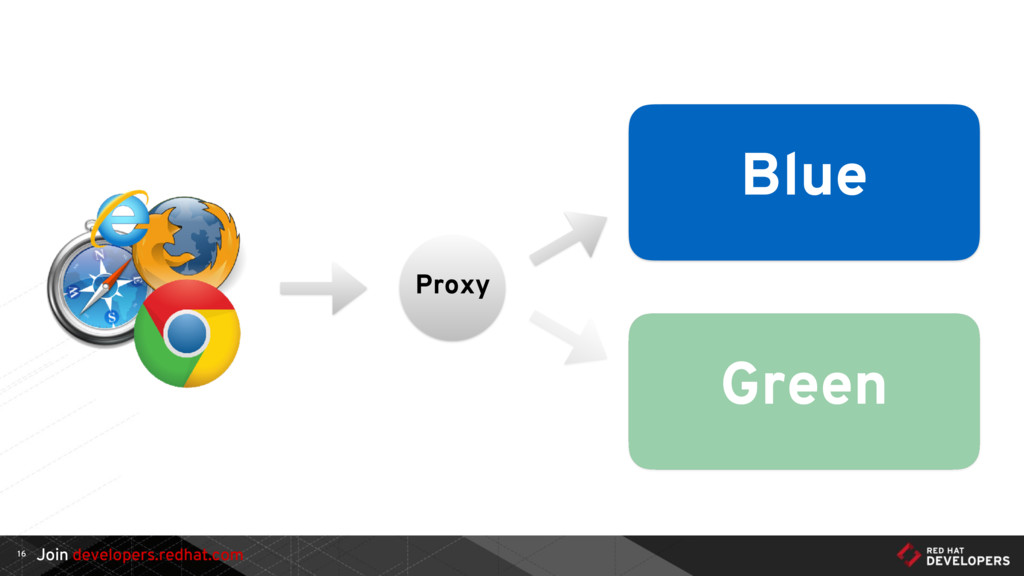{kind=link}
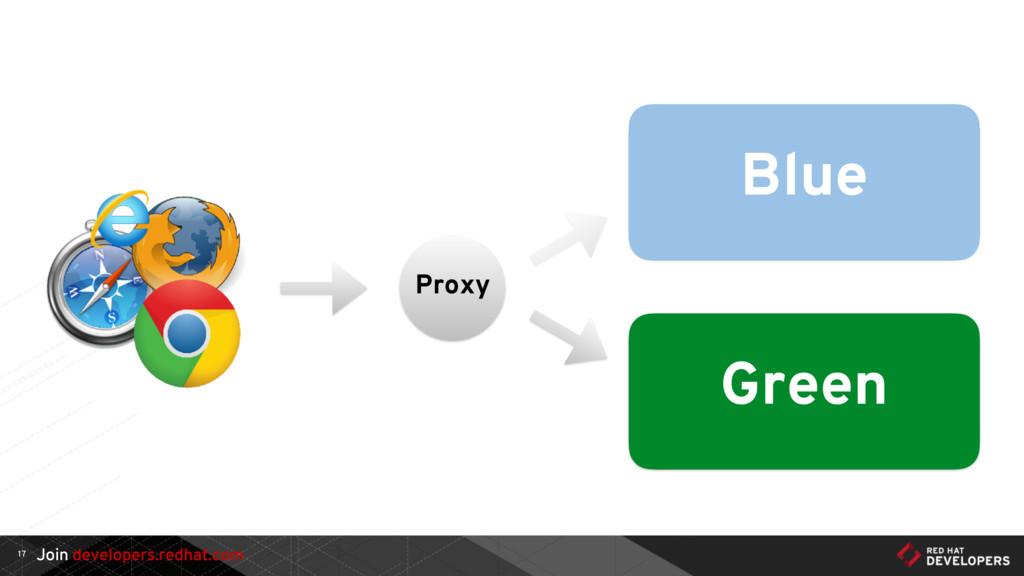{kind=link}
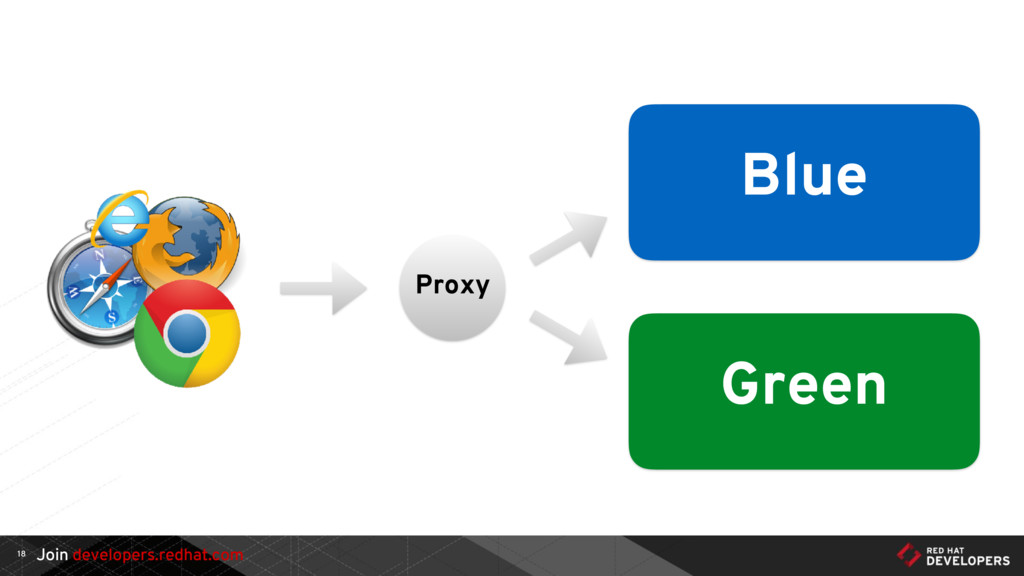{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
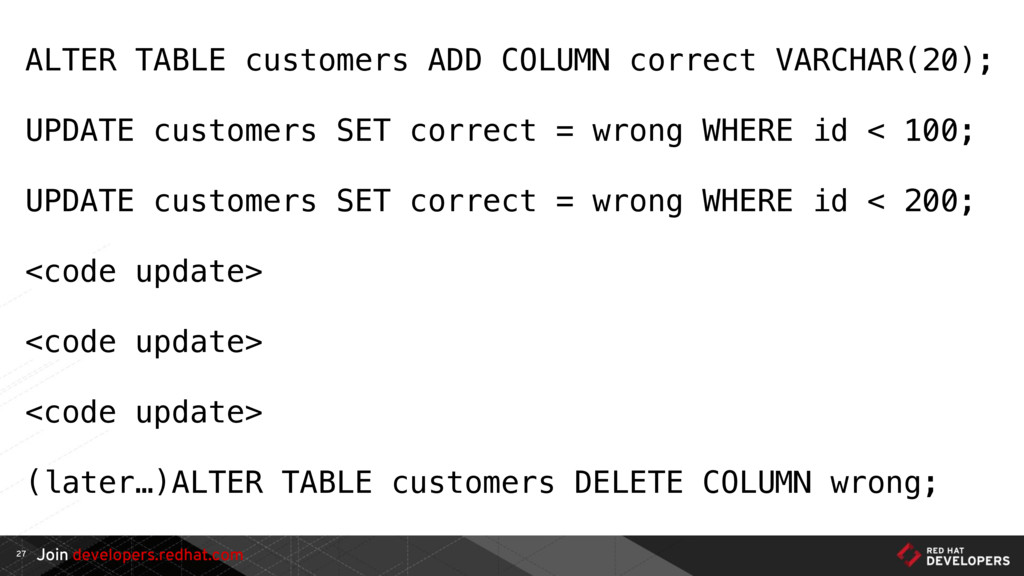{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
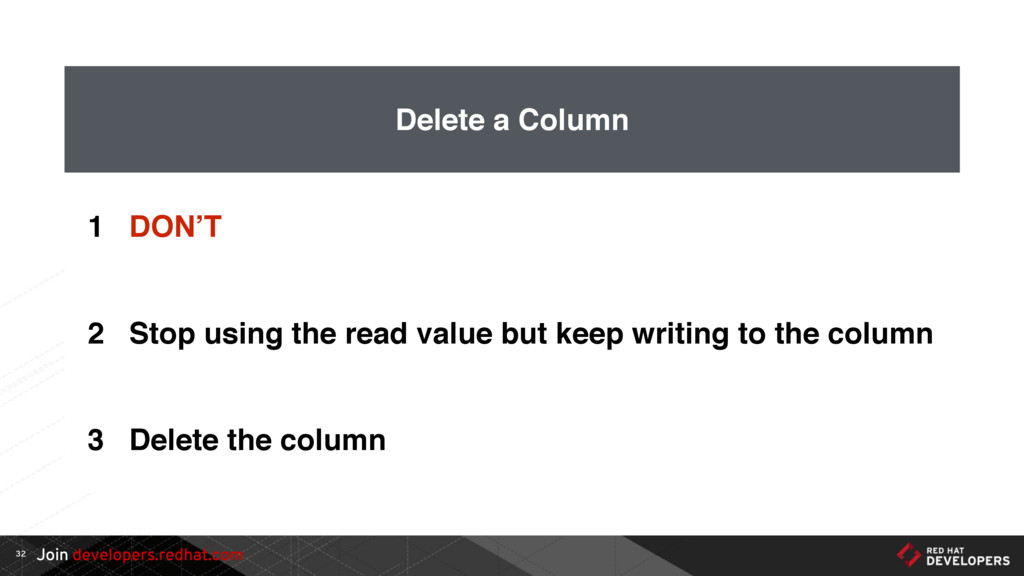{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}