for t in issues: result = re.compile('-+').sub('', t) result = re.compile('[0-9]+').sub('0', result) result = re.compile('\s+').sub('', result) # ... ͜ͷΑ͏ͳஔॲཧ͕ෳܨ͕͍ͬͯ·͢ # ࣭ςΩετ͕ۭจࣈʹͳΔ͜ͱ͕͋ΔͷͰͦͷߦؚΊͳ͍Α͏ʹ͠·͢ if len(result) > 0: sub_texts.append(result) filtered_text.append(result) print("text:%s" % result) # text:͓࣌ؒΛଷ͓ͯ͠Γ·͢ɻ
wakati") wakati.parse("") words = wakati.parse(text) # Make word list if words[-1] == u"\n": words = words[:-1] return words texts = [tokenize(a) for a in samples] Β͓࣌ؒ͘Λଷ͓ͯ͠Γ·͢ Β͘ ͓ ࣌ؒ Λ ଷ ͠ ͯ ͓Γ ·͢
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![࣭ςΩετͷલॲཧ ه߸ϝʔϧΞυϨεɺࣈͳͲͷจࣈΛআ͢Δ filtered_text = [] text = ["͓࣌ؒΛଷ͓ͯ͠Γ·͢ɻversion 1.2.3 ----------------------------------------"]](https://files.speakerdeck.com/presentations/05f81fb736534ce7b66252a820d2594e/slide_6.jpg){kind=link}
![αϯϓϧͱϥϕϧΛ࡞ labels = [] samples = [] threshold = 700](https://files.speakerdeck.com/presentations/05f81fb736534ce7b66252a820d2594e/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
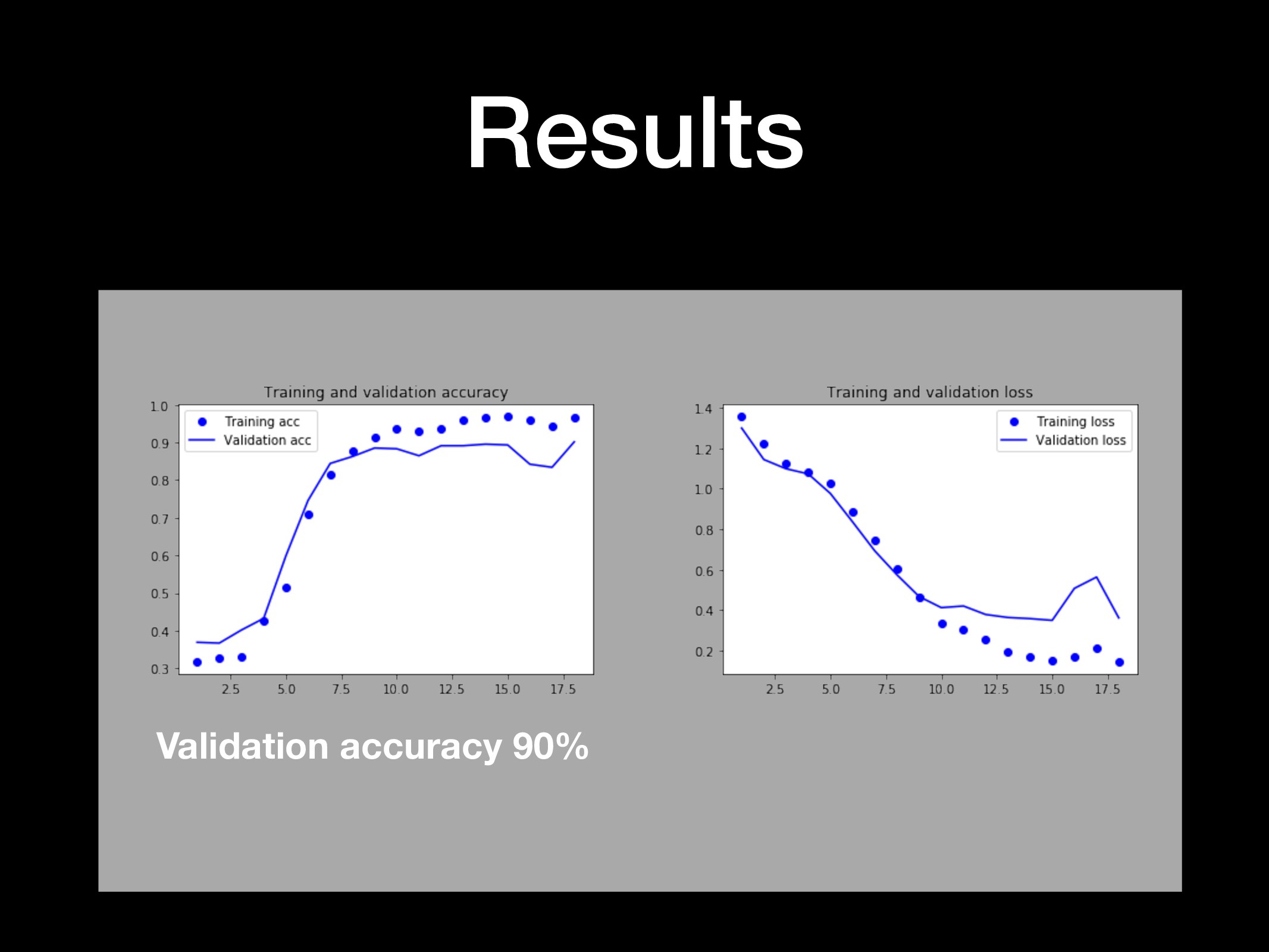{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}