JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
Presented at IS&T's international symposium on Electronic Imaging, Media Watermarking, Security, and Forensics track 2020, San Francisco, CA, January 26–30, 2020.
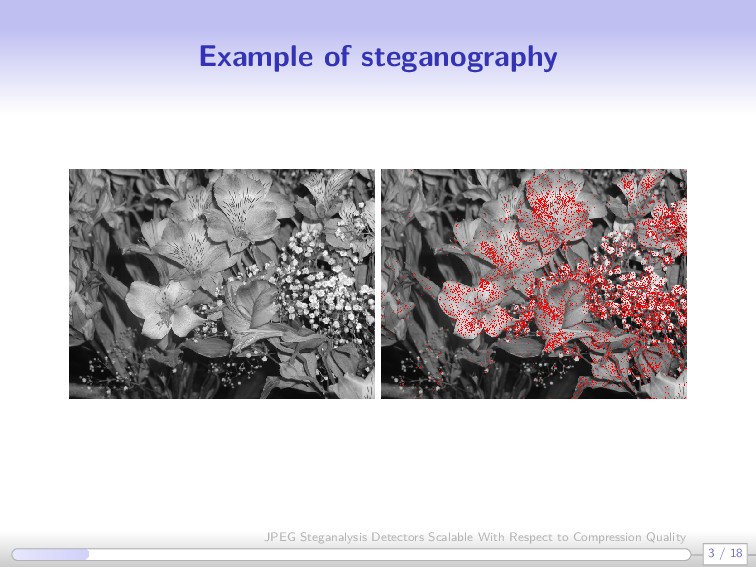
ordinary looking cover objects Focus on image objects because they contain many indeterministic components: acquisition conditions, development, post-processing, editing, and even sharing Images can have multiple formats: JPEG, GIF, PNG, etc. Secret messages are embedded by introducing noise looking signal to the image Can be content adaptive, e.g. taking advantage of textured regions, edges, etc. 2 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
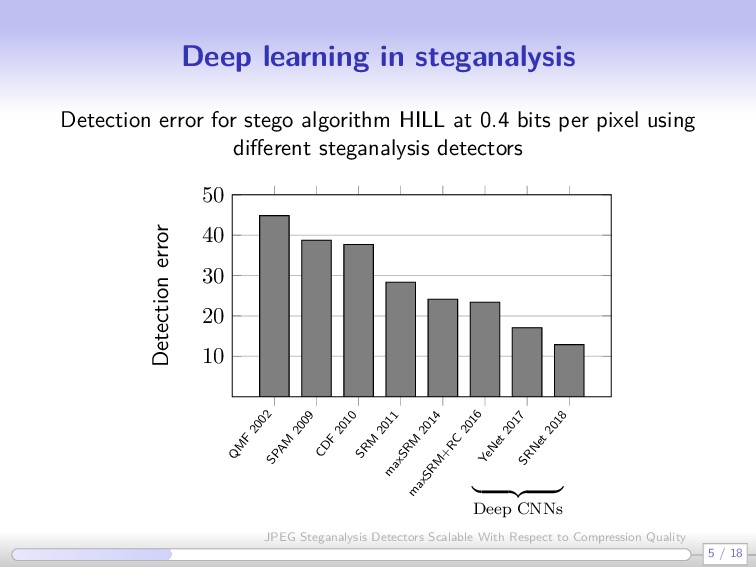
messages Usually built as binary detectors, trained in sand-boxed environments: a known steganographic scheme, known payload, and a known cover source 2 approaches: Feature based detectors End-to-end deep learning based detectors 4 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
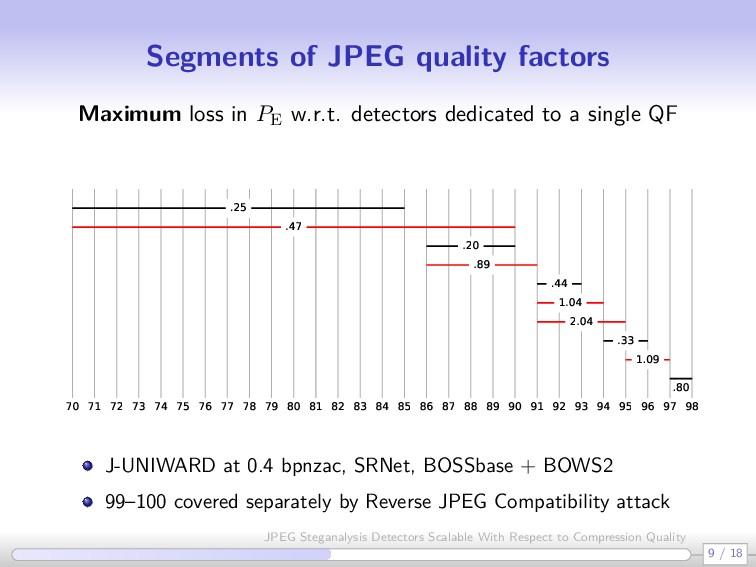
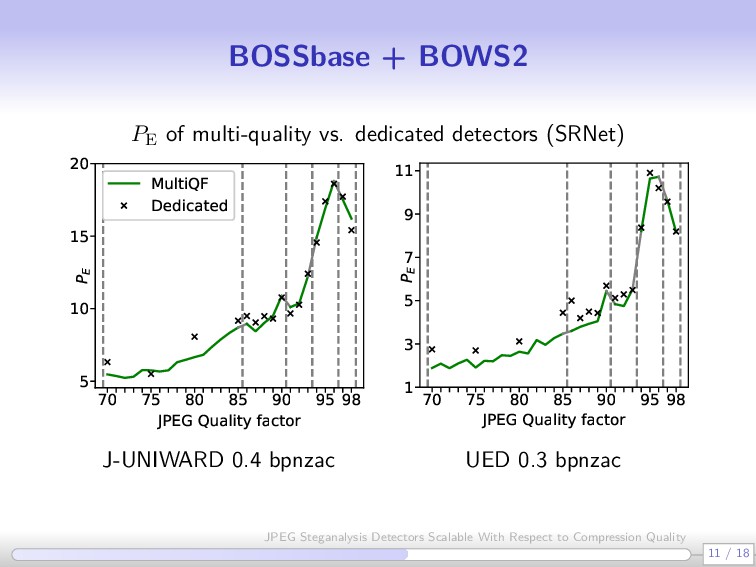
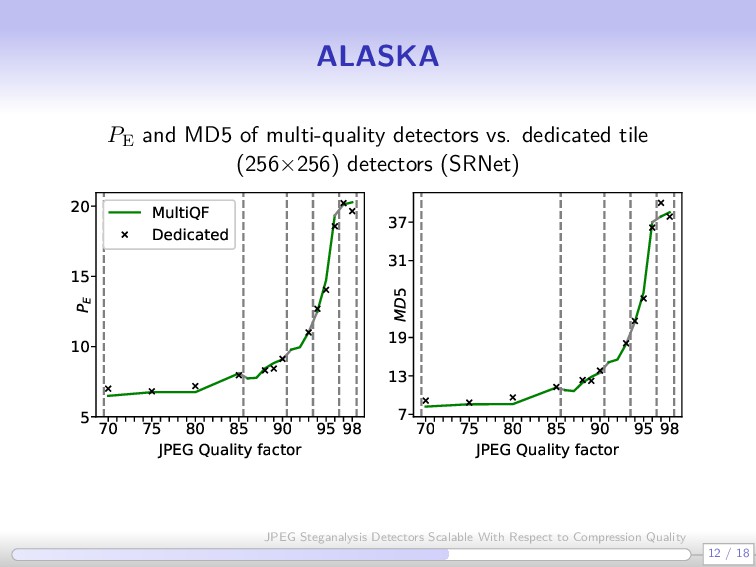
grouping multiple quality factors in one detector is a bad idea” because it (unnecessarily) increases cover source diversity “CNNs are more sensitive to cover source mismatch (CSM) than rich models” ALASKA challenge (Sep 2018 – March 2019) Winners [Yousfi et al. 2019] trained a detector for each quality factor [60–100 QFs] Cumbersome, extremely time and resource consuming 6 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
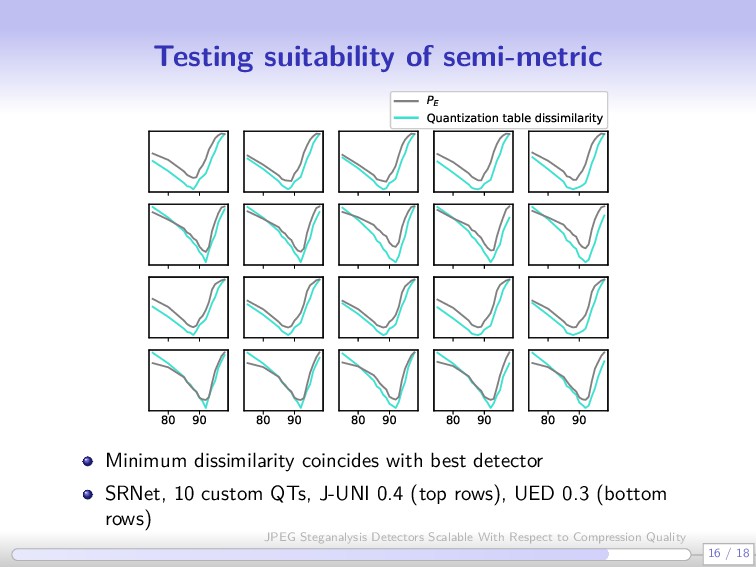
thumb Let q(Q) be the standard JPEG quantization table indexed by quality factor Q. The segment [Qmin, Qmax] can be grouped in one detector without loss of performance if qkl(Qmin)/qkl(Qmax) 2, ∀ 0 ≤ k, l ≤ 7 7 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
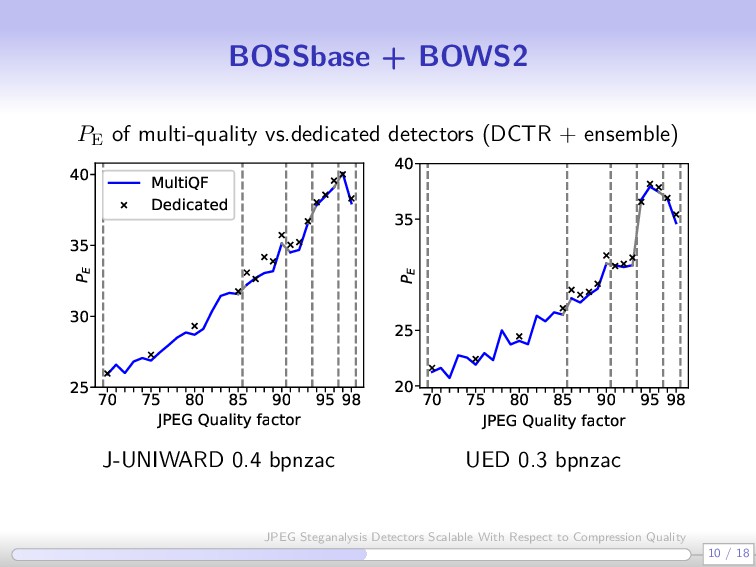
answer Which generalizes better, CNNs vs. rich models? What is better, multi-quality detector vs. detector trained on closest QF? 14 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
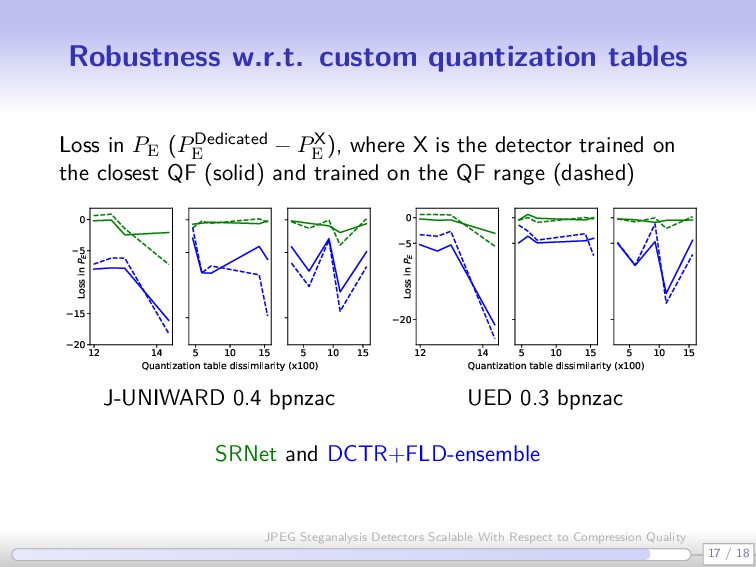
− PX E ), where X is the detector trained on the closest QF (solid) and trained on the QF range (dashed) 12 14 −20 −15 −5 0 Loss in PE 5 10 15 Quantization table dissimilarity (x100) 5 10 15 12 14 −20 −5 0 Loss in PE 5 10 15 Quantization table dissimilarity (x100) 5 10 15 J-UNIWARD 0.4 bpnzac UED 0.3 bpnzac SRNet and DCTR+FLD-ensemble 17 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
JPEG quality factors Both CNNs and rich models can span a range of JPEG quality factors CNNs better generalize to custom quantization tables Use larger batch size when training CNN detectors on a range Very dissimilar non-standard quantization matrices still a challenge 18 / 18 JPEG Steganalysis Detectors Scalable With Respect to Compression Quality
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}