Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
はじめての文字認識_改
Search
yasu
June 18, 2019
Technology
510
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
はじめての文字認識_改
scikit-learnを使って手書き文字認識をやってみました。
yasu
June 18, 2019
More Decks by yasu
See All by yasu
Docker 危険のキ!/Docker the beginning of danger
yasu8899
1
270
Dockerとは
yasu8899
1
900
ML基本のキの一筆目
yasu8899
0
82
rancheros-in-raspberrypi
yasu8899
2
480
5分で説明する RancherOS+Rancher2インストール / rancherosinstall
yasu8899
0
710
Other Decks in Technology
See All in Technology
打造你的 AI 工作流:Agent Skill + MCP 實戰工作坊
appleboy
0
160
秘密度ラベル初心者が第1歩でつまづかないための「設計・運用」ポイント
seafay
PRO
1
510
10年間のブログ発信を振り返って見えたWebアプリケーションエンジニアとしての軌跡
stefafafan
0
190
クラウドファンディング版StackChan 3体(4体)をインタラクティブな体験型作品にして展示もした話 / スタックチャンお誕生日会2026
you
PRO
0
220
千葉での単身赴任からAWSをやり続け、千葉に戻ってきた話
yama3133
1
120
初めてのDatabricks勉強会
taka_aki
2
190
AI時代のコスト管理を考えよう〜明日から使える実践AWSノウハウ~
yoshimi0227
0
960
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
140
5分でわかるDuckDB Quack
chanyou0311
4
260
Agile and AI Redmine Japan 2026
hiranabe
4
500
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
7.7k
“詰む”前に仕組みを作れ 〜技術の波に溺れないためのキャッチアップ術〜
takasyou
7
4.3k
Featured
See All Featured
YesSQL, Process and Tooling at Scale
rocio
174
15k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
420
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Ruling the World: When Life Gets Gamed
codingconduct
0
260
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
240
Google's AI Overviews - The New Search
badams
0
1k
Transcript
はじめての文字認識 改 oda@sendai 令和元年 6月18日
環境 Python 3.7.3 JupyterLab 0.35.4 scikit-learn 0.20.3 matplotlib 3.0.3 opencv-python
4.1.0.25
JupyterLab ・ブラウザ上でPythonのプログラミングができるツール ・プラグインを入れれば、JavaやRも使用できる https://github.com/jupyterlab/jupyterlab
JupyterLab
scikit-learn ・Pythonのオープンソース機械学習ライブラリ ・サポートベクターマシン(SVM)のサポート ・1797個の8x8サイズ 手書き数字イメージサンプル有り http://scikit-learn.org/ https://ja.wikipedia.org/wiki/Scikit-learn
matplotlib ・グラフ描画ライブラリ http://matplotlib.org/ https://ja.wikipedia.org/wiki/Matplotlib
opencv-python ・画像処理ライブラリ https://opencv.org https://ja.wikipedia.org/wiki/OpenCV
データ読み込み 1つ目のセル # cell 1 # モジュールのインポート from sklearn import
datasets # 数字データセット読み込み digits = datasets.load_digits() # 学習データ data = digits.data # ラベル(教師あり学習用) target = digits.target
学習データの表示 2つ目のセル(1/2) # cell 2 # モジュールのインポート import matplotlib.pyplot as
plt # 表示する学習データの指定(0 ~ 1797) n=100 # n番目のラベルの表示 print(target[n])
学習データの表示 2つ目のセル(2/2) # n番目の学習データの表示 i=0 for j in data[n]: if
i<7: print(j, end='') print(", ", end='') i+=1 else: print(j) i=0 # n番目の学習データを画像表示 plt.imshow(digits.images[n], cmap='Greys')
学習データの表示 2つ目のセルの実行結果
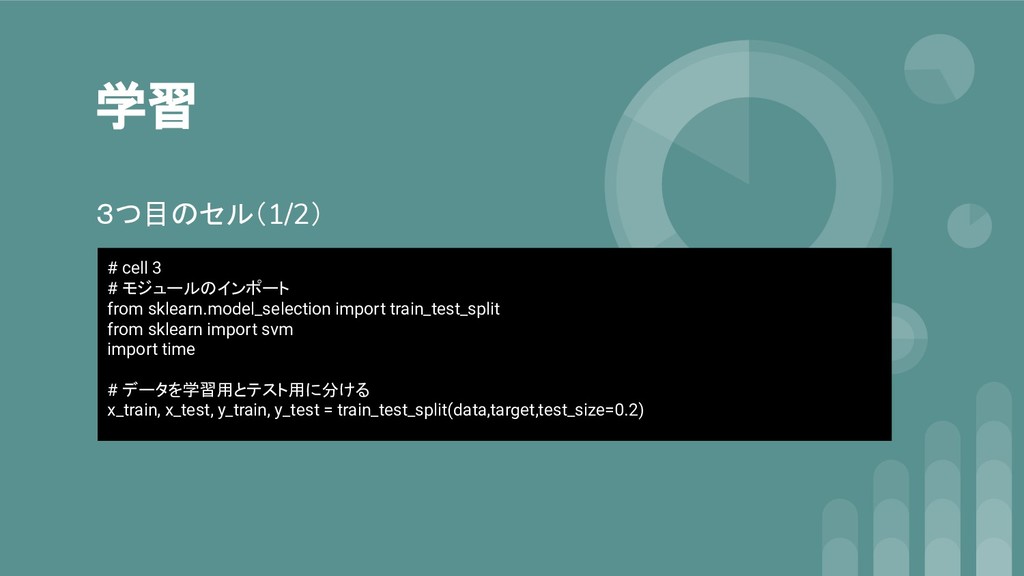
学習 3つ目のセル(1/2) # cell 3 # モジュールのインポート from sklearn.model_selection import
train_test_split from sklearn import svm import time # データを学習用とテスト用に分ける x_train, x_test, y_train, y_test = train_test_split(data,target,test_size=0.2)
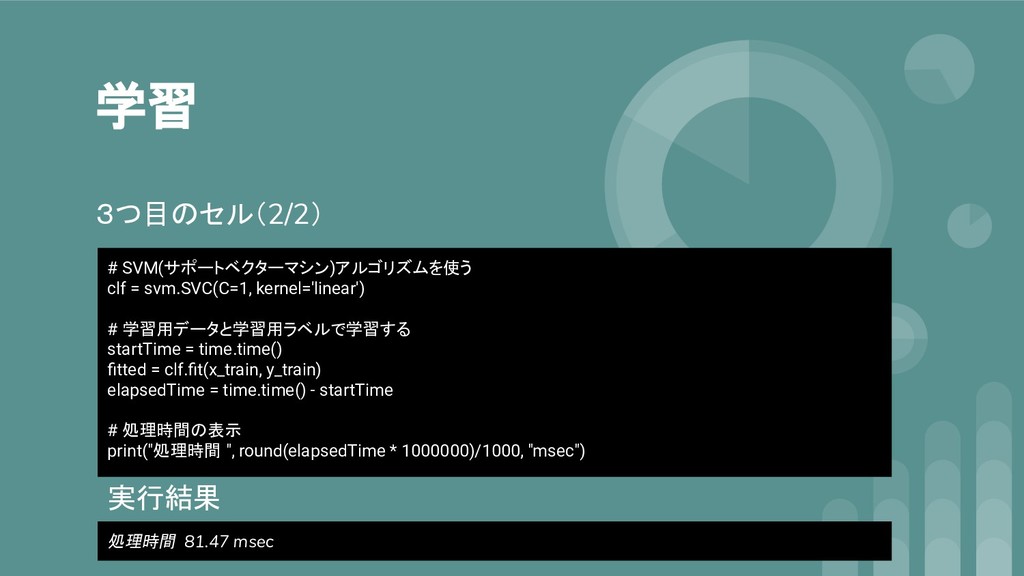
学習 3つ目のセル(2/2) # SVM(サポートベクターマシン)アルゴリズムを使う clf = svm.SVC(C=1, kernel='linear') # 学習用データと学習用ラベルで学習する
startTime = time.time() fitted = clf.fit(x_train, y_train) elapsedTime = time.time() - startTime # 処理時間の表示 print("処理時間 ", round(elapsedTime * 1000000)/1000, "msec") 実行結果 処理時間 81.47 msec
データを学習用とテスト用に分ける ・学習用データとテスト用データが同じなら、 正解率が100%に近くなるため分ける。 ・ここでは、学習用データを8割・テスト用データを2割 にしている。 train_test_splitが良しなにしてくれる。
SVM(サポートベクターマシン) ・教師あり学習を用いるパターン認識モデル。 ・線形分類が得意。
検証 4つ目のセル # cell 4 # モジュールのインポート from sklearn import
metrics # テスト用データで予測する predict = fitted.predict(x_test) # 検証する print(metrics.confusion_matrix(predict, y_test)) # スコア計算 print("テストデータの正解率:", str(metrics.accuracy_score(predict, y_test) * 100) + "%")
検証結果 横軸が検証結果 縦軸がテスト用ラベル [[33 0 0 0 0 0 0
0 0 0] [ 0 35 0 0 0 0 0 0 0 0] [ 0 0 44 0 0 0 0 0 0 0] [ 0 0 0 35 0 0 0 0 0 0] [ 1 0 0 0 39 0 0 0 0 0] [ 0 0 0 1 0 24 0 0 0 0] [ 0 0 0 0 0 1 38 0 0 0] [ 0 0 0 0 0 0 0 47 0 0] [ 0 0 0 1 0 0 0 0 30 0] [ 0 0 0 1 0 0 0 0 0 30]] テストデータの正解率: 98.61111111111111%
学習済みモデルの保存 5つ目のセル # cell 5 # モジュールのインポート import joblib #
学習済みモデルの保存 joblib.dump(fitted, 'model.pkl')
手書き数字の判定 6つ目のセル(1/3) # cell 6 # モジュールのインポート import cv2 from
sklearn.externals import joblib from IPython.display import display, Image # 読み込む画像ファイル名 filename="7.png" # 画像の表示 def display_cv_image(image, format='.png'): decoded_bytes = cv2.imencode(format, image)[1].tobytes() display(Image(data=decoded_bytes))
手書き数字の判定 6つ目のセル(2/3) # 画像読み込み pngData = cv2.imread(filename) print("読み込んだ画像") display_cv_image(pngData, '.png')
# モデル読み込み clf = joblib.load("model.pkl") # グレースケール変換 pngDataGray = cv2.cvtColor(pngData, cv2.COLOR_BGR2GRAY) print("グレースケール変換した画像") display_cv_image(pngDataGray, '.png') # 8x8サイズ変換 pngDataGray88 = cv2.resize(pngDataGray,(8,8)) print("8x8サイズ変換した画像") display_cv_image(pngDataGray88, '.png')
手書き数字の判定 6つ目のセル(3/3) # 白黒反転 pngDataGray88Rev = 15 - pngDataGray88 //
16 print("白黒反転した画像") display_cv_image(pngDataGray88Rev, '.png') # 一次元変換 pngDataGray88RevDim = pngDataGray88Rev.reshape((-1,64)) print("一次元変換した画像") display_cv_image(pngDataGray88RevDim, '.png') res = clf.predict(pngDataGray88RevDim) # 結果表示 print("判定結果は「", str(res[0]), "」です。\n")
手書き数字の判定 6つ目のセルの実行結果(1/2)
手書き数字の判定 6つ目のセルの実行結果(2/2)
8x8サイズ変換データをデカく表示 7つ目のセル # cell 7 # 8x8サイズ変換データをデカく表示 print("8x8サイズ変換データをmatplotlibで表示") plt.imshow(pngDataGray88, cmap=plt.cm.gray)
8x8サイズ変換データをデカく表示
手書き数字の判定(間違い) 6つ目のセルの実行結果(1/2)
手書き数字の判定(間違い) 6つ目のセルの実行結果(2/2)
8x8サイズ変換データをデカく表示
考察 ・5を判定させる数字は難しい。 4か6に誤認されることが多かった。 ・数字を8x8にしたときに失われるデータが多い。 誤認の原因と考えられる。 ・実用するためには、学習データはもっと大きいサイズに する必要がある。 ・8x8に変換する際に、余白を削除すれば良くなる・・・かな?
参考ページ ・scikit-learn Tutorials https://scikit-learn.org/stable/tutorial/index.html ・【Python】scikit-learnで手書き数字を判定してみた https://ymgsapo.com/2018/12/03/hand-digits-test/ ・sklearnで手書き文字認識 http://akiniwa.hatenablog.jp/entry/2013/12/20/120734
はじめての文字認識 END
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![学習データの表示 2つ目のセル(2/2) # n番目の学習データの表示 i=0 for j in data[n]: if](https://files.speakerdeck.com/presentations/fdae44e6a2fd4b7ab337a6ec6be9bf73/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}