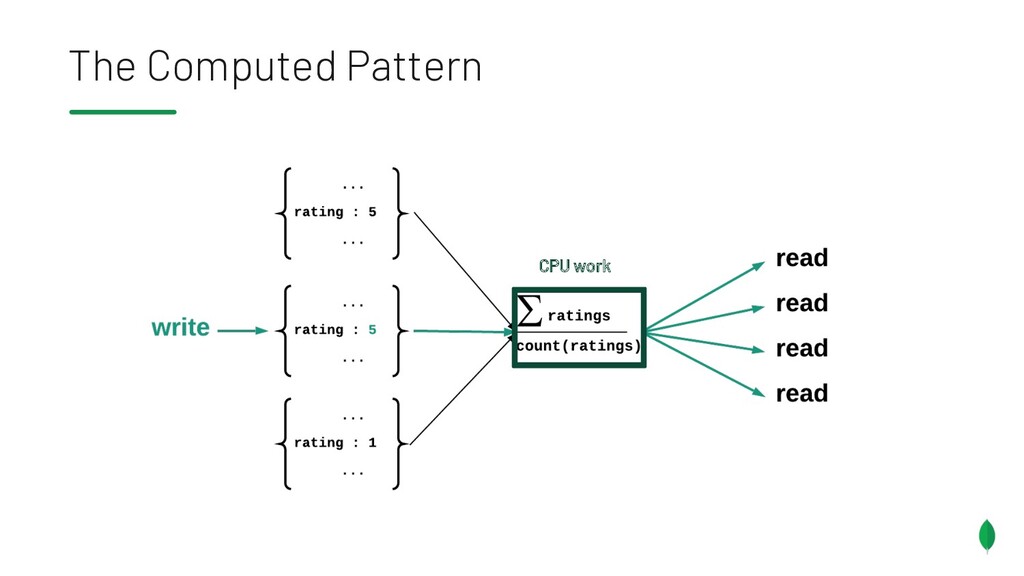
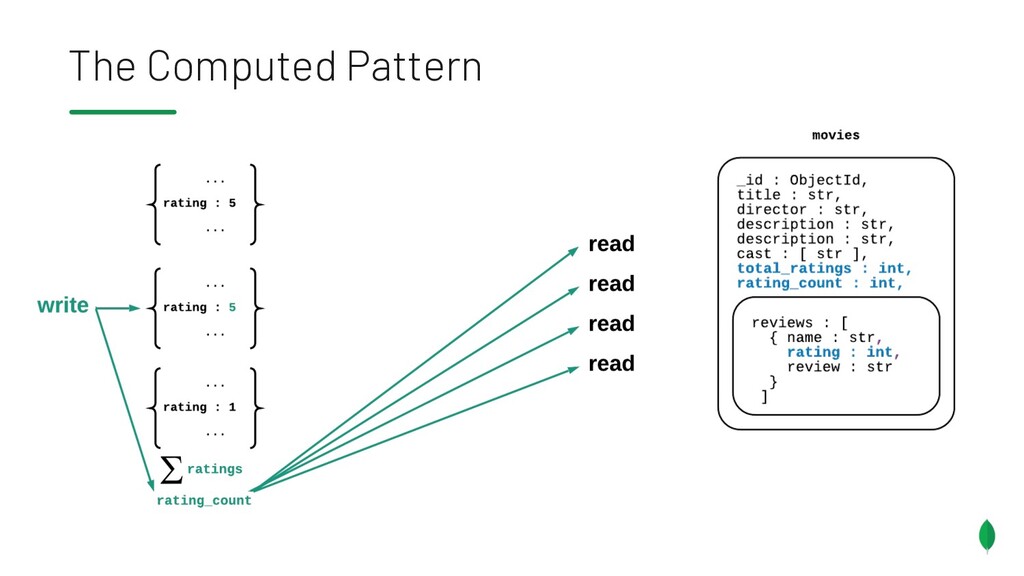
= 22, time = Date('2020-05-11') db.iot.updateOne({ "sensor": reading.sensor, "valcount": { $lt:200 } }, { "$push": { "readings": { "v": value, "t": time } }, "$inc": { "valcount": 1, "tot": value } }, { upsert: true }) { "_id": ObjectId("abcd12340101"), "sensor": 5, "valcount": 3, "tot": 114, "readings": [ { "v": 11, "t": Date("2020-05-09” )}, { "v": 81, "t": Date("2020-05-10” )}, { "v": 22, "t": Date("2020-05-11” )} ] }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
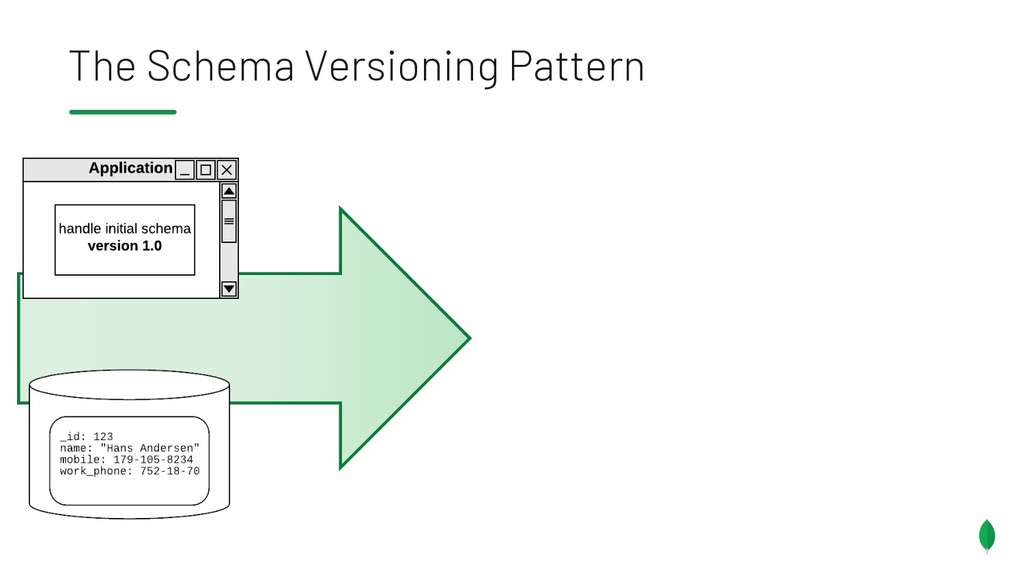{kind=link}
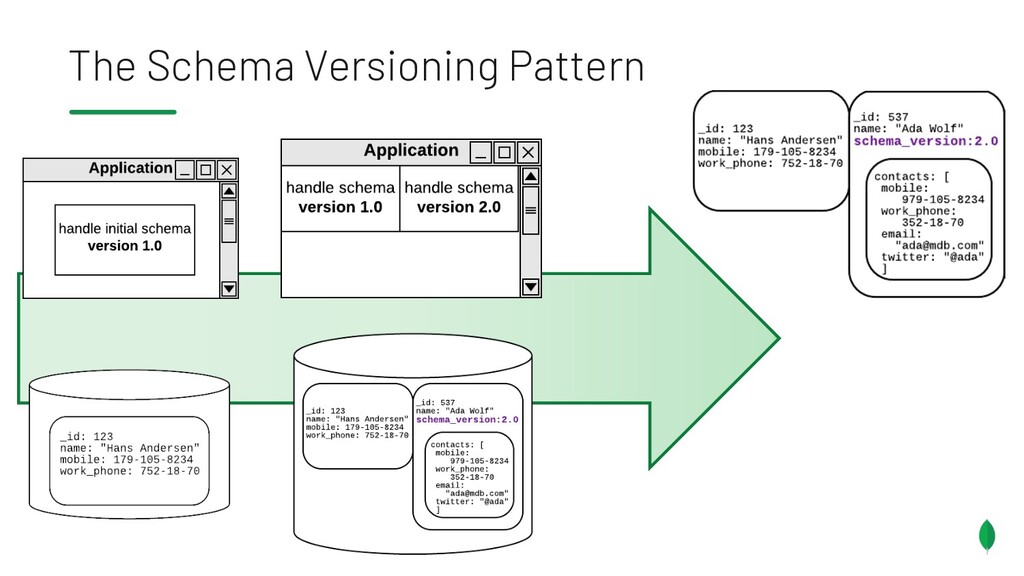{kind=link}
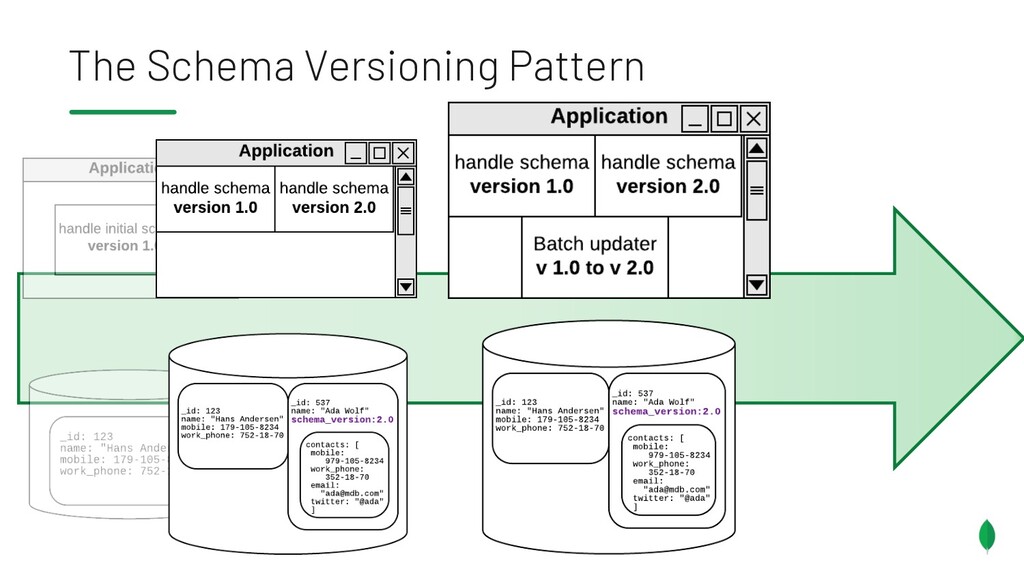{kind=link}
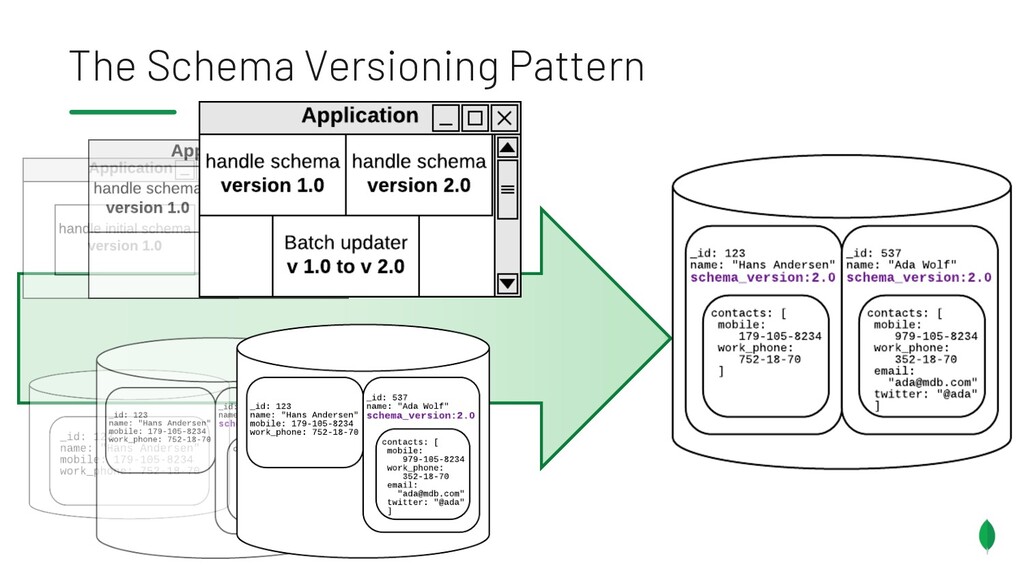{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
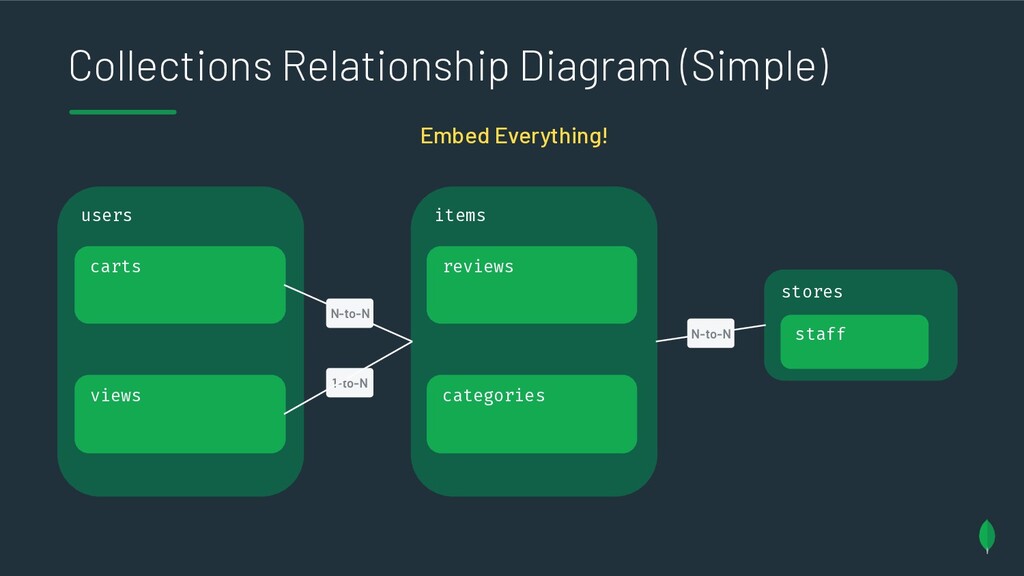{kind=link}
{kind=link}
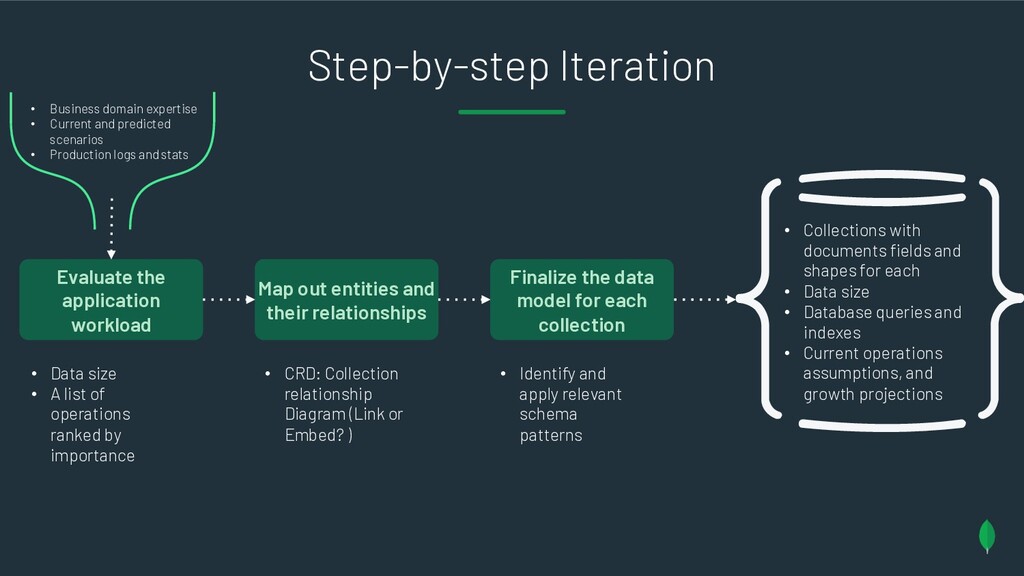{kind=link}
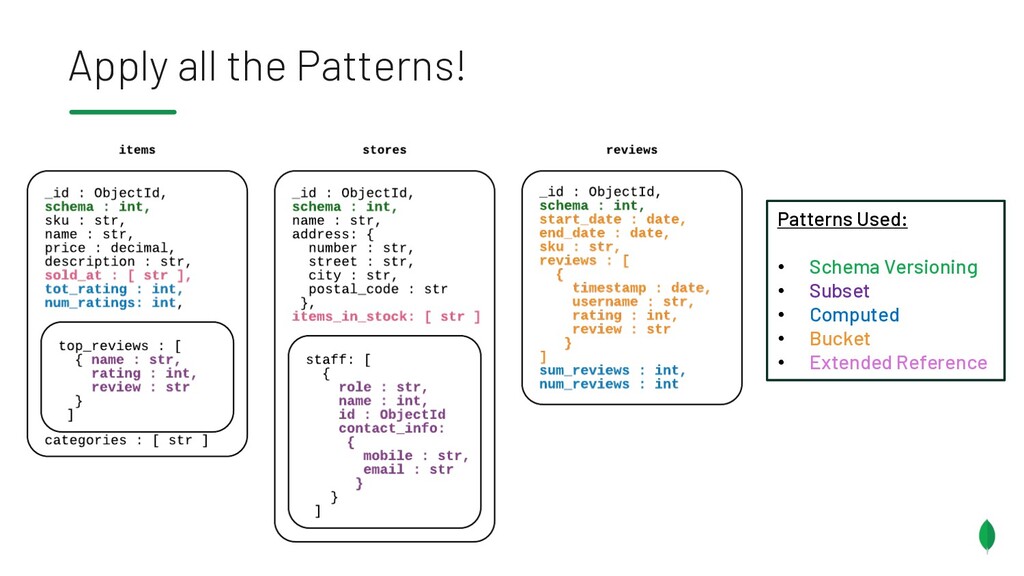{kind=link}
{kind=link}
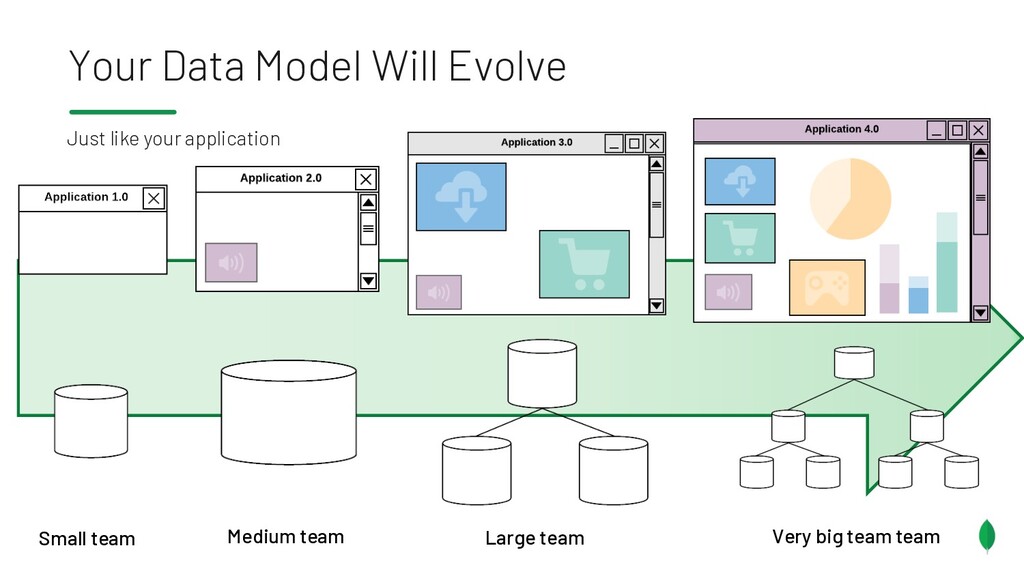{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}