Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang et al. "Imagenet large scale visual recognition challenge." International Journal of Computer Vision 115, no. 3 (2015): 211-252.
International Journal of Computer Vision 115.3 (2015): 211-252 CSci 8980: Special Topics in Vision based Approaches to Learning Presenters: Yeong Hoon Park and Rankyung Hong
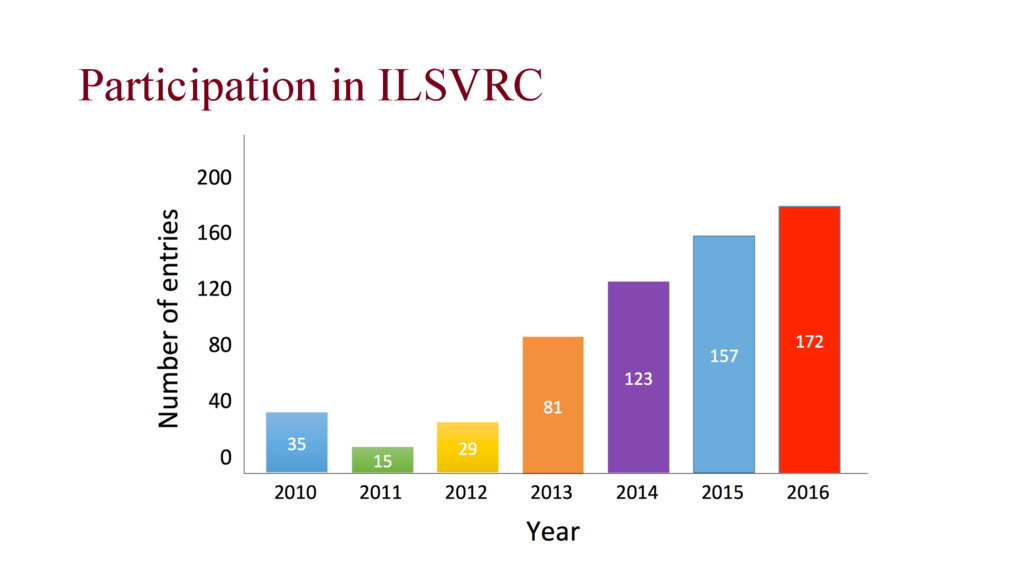
Running annually (2010 – present) • Following in the footsteps of PASCAL VOC challenge (2005 – 2012) • Publicly available dataset (training, validation and test images) • Development and comparison of categorical object recognition algorithms • Annual competition and corresponding workshop (ICCV / ECCV) • A way to track the progress and discuss lessons learned from the most successful and innovative entries PASCAL VOC 2010 ILSVRC 2010 ImageNet as of now # Objects 20 1,000 21,841 # Images 19,737 1,461,406 14,197,122
objects • 673,966 images (Train: 523,966 + Val: 50,000 + Test: 100,000) • Ground-truth: bboxes for all instances of 1 object present in the image • Predictions: 5 candidate pairs of an object and a bbox in the image
objects • 518,956 images (Train: 458,683 + Val: 20,121 + Test: 40,152) • Ground-truth: bboxes for all instances of all objects present in the image • Predictions: a set of [object class, confidence score, bounding box] for all instances of all objects present in the image
• 30 objects (subset of object detection) • 3,862 Snippets (Train: 2,370 + Val: 555 + Test: 937) • Ground-truth: All instances of all objects for each clip • Predictions: a set of [frame number, object class, confidence score, bounding box] for each video clip
with MIT Places team • 365 scene objects • Place2 dataset : 10M images (Train: 8M + Val: 36K + Test: 328K) • Ground-truth: 1 scene object per image • Predictions: 5 candidate scene objects per image
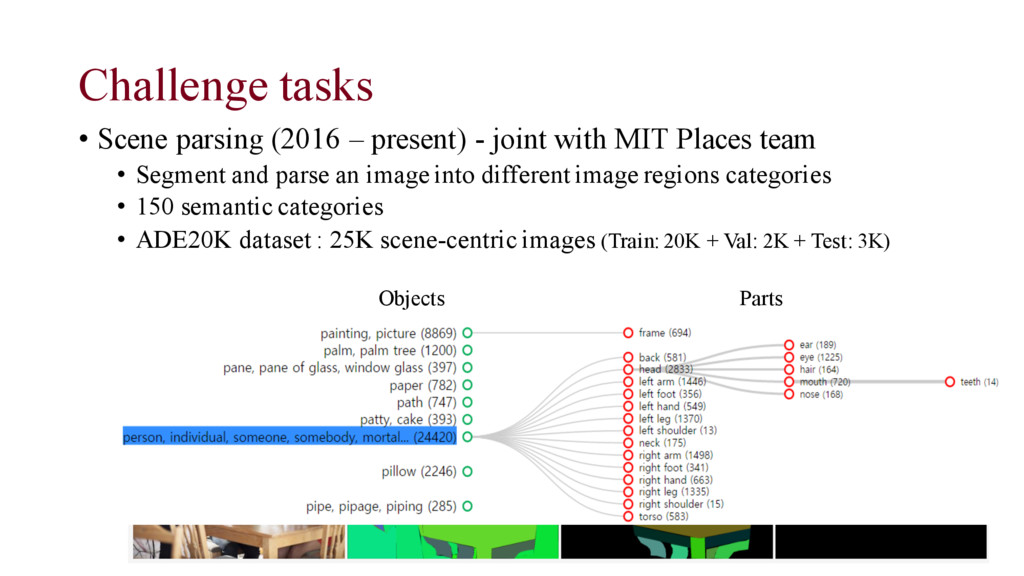
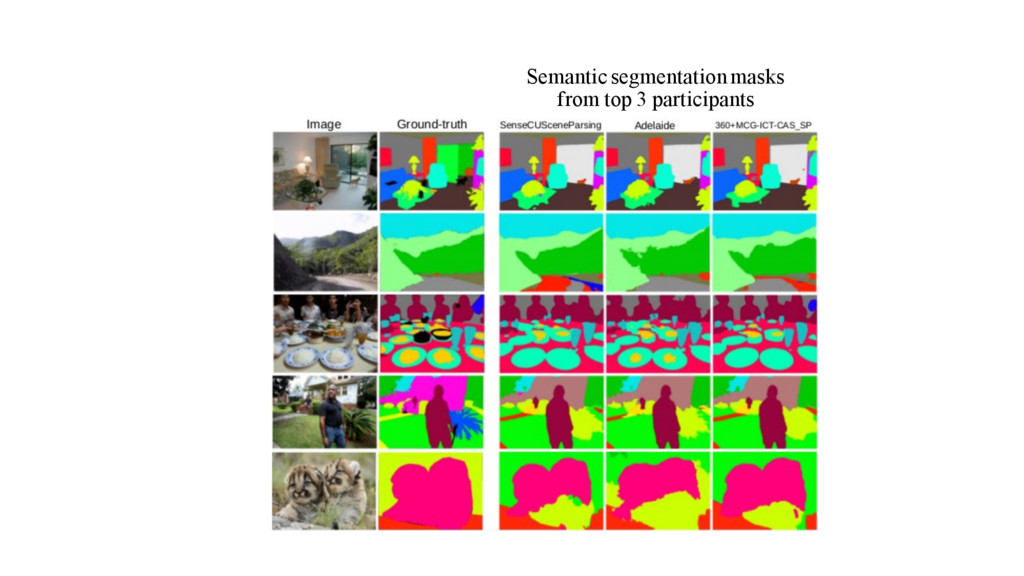
with MIT Places team • Segment and parse an image into different image regions categories • 150 semantic categories • ADE20K dataset : 25K scene-centric images (Train: 20K + Val: 2K + Test: 3K) • Ground-truth: All object and part instances are annotated for each image • RGB image (jpg), Object segmentation mask (png) • Part segmentation masks (png) with different levels in hierarchy • Predictions: a semantic segmentation mask, predicting the semantic category for each pixel in the image. Objects Parts
Localization Object Detection 1,000 Object Categories Easy to Localize No Overlap Fine- grained ImageNet 21,841 Synsets from WordNet any category I and J, I is not an ancestor of J e.g. removed “New Zealand Beach” e.g. dog breeds : dalmatian, schnauzer, … cat breeds : persian cat, egyptian cat, … • 20 PASCAL VOC • Basic-level objects (e.g. bird, dog, …) • Small size objects (< 50%) • Well-suited for detection (e.g. No hay, barbershop, ...) 1,000 Object Categories 200 Object Categories
Verify whether each image contains a certain object or not • Consensus score threshold per object from 10 users with initial subset images • AMT user labeling until the predetermined consensus score Quality Control 1500 images from 80 synsets 99.7% precision Label all instance of one object per image (Draw a bounding box for an instance) 1st users : draw one bbox 2nd users : check if the bbox is correctly drawn 3rd users : check if all instances have bboxes Quality Control 200 images from each synset • Coverage (all instances of the object) 97.9% : covered with bboxes 2.1% : missed bboxes • Quality (tight bbox) 99.2% : accurate 0.8% : somewhat off
- Naïve: 200N queries (N images, 200 labels) - Smart way: hierarchy of queries • 2.8 annotated instances per image • Avg object take up 17% of image area 3. Annotate millions of collected images
# of test images dij = 0 if correctly classified = 1 if incorrectly classified # images with wrong classification Total # of test images = dij 1 1 0 1 1 Min(dij) = 0 dij 1 1 1 1 1 Min(dij) = 1 Wrong classification Correct classification Evaluation : Image Classification
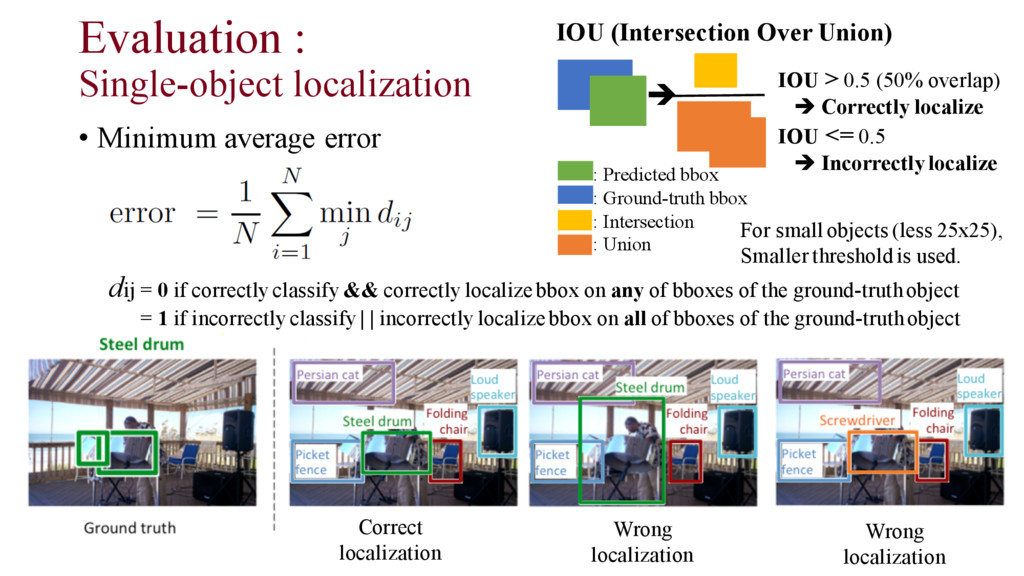
• Minimum average error dij = 0 if correctly classify && correctly localize bbox on any of bboxes of the ground-truth object = 1 if incorrectly classify | | incorrectly localize bbox on all of bboxes of the ground-truth object : Predicted bbox : Ground-truth bbox : Intersection : Union è IOU > 0.5 (50% overlap) è Correctly localize IOU <= 0.5 è Incorrectly localize IOU (Intersection Over Union) For small objects (less 25x25), Smaller threshold is used.
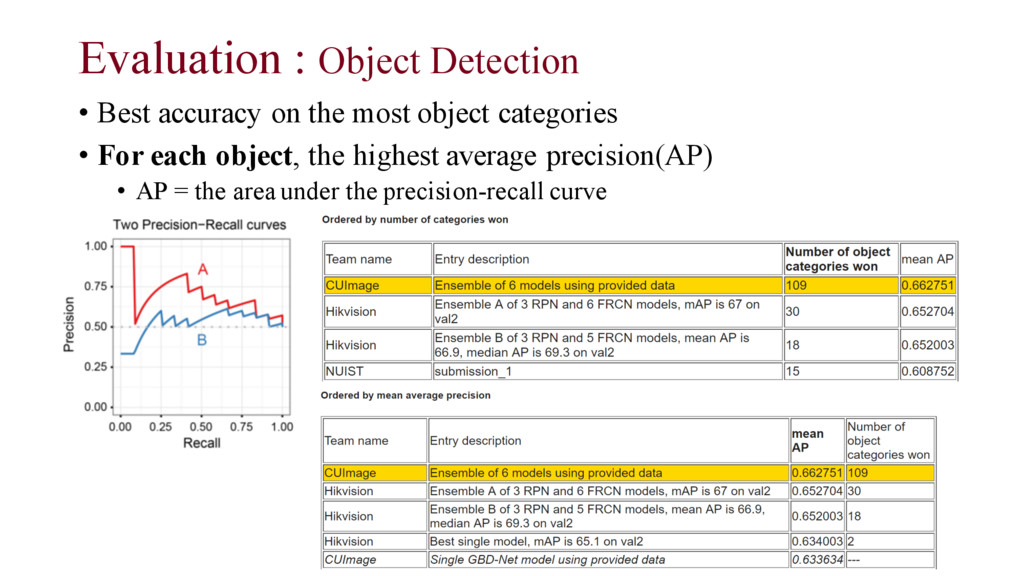
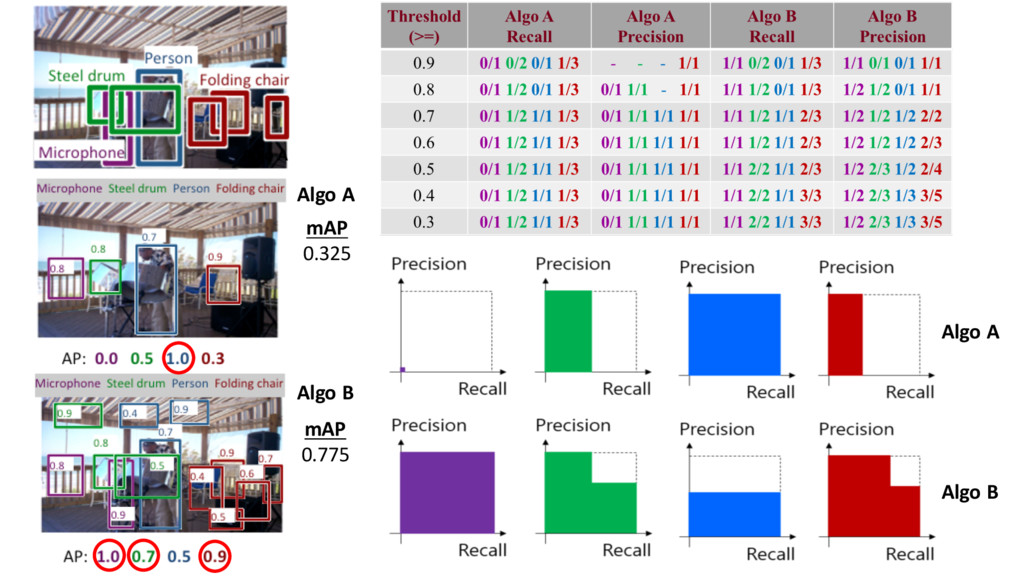
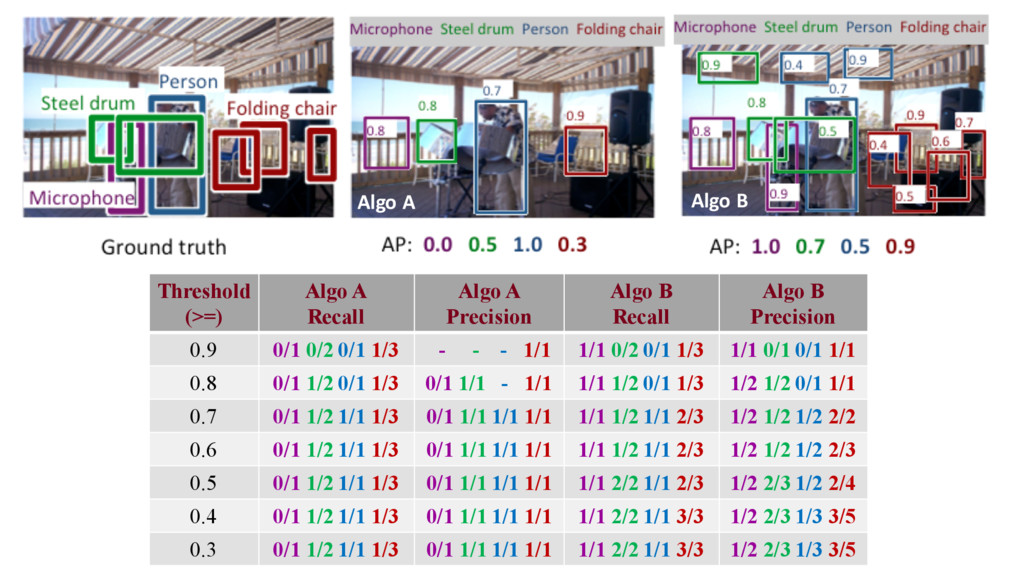
a object across all test images s = confidence score t = Threshold for S = # my correct bboxes for object J = # of all (correct + wrong) my bboxes for object J • 4 different objects è 4 AP scores • N for steel drum = 2 • N for Microphone = 1 • N for Person = 1 • N for Folding chair = 3 • All predicted bboxes of an algorithm • Numbers = confidence score • Average precision(AP) over the different levels of recall achieved by varying the threshold t
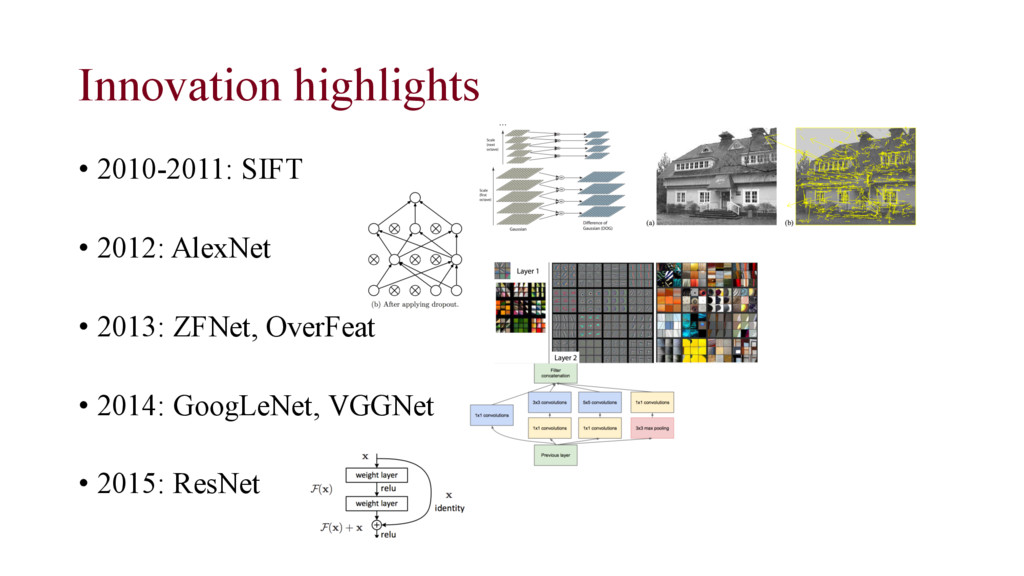
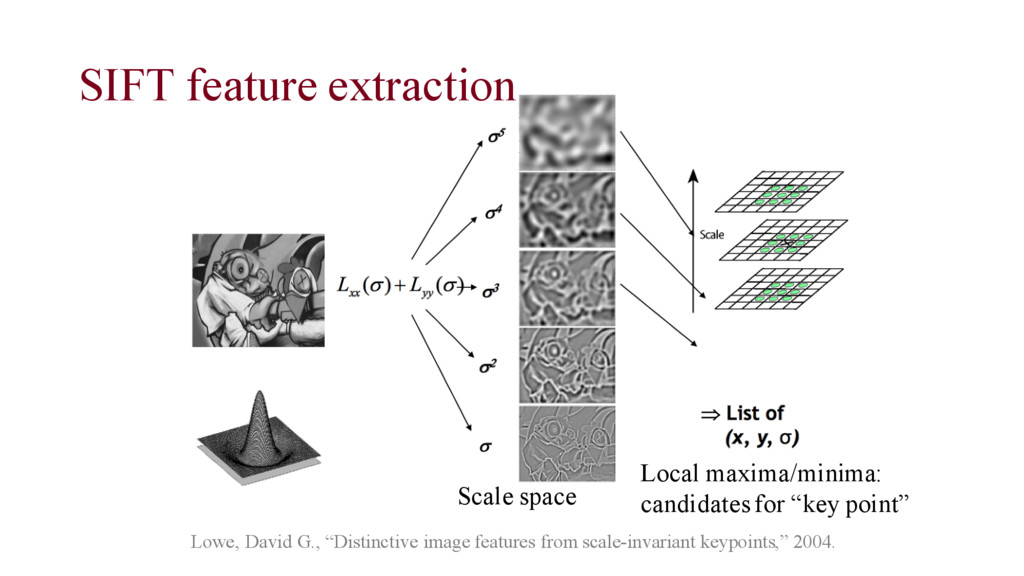
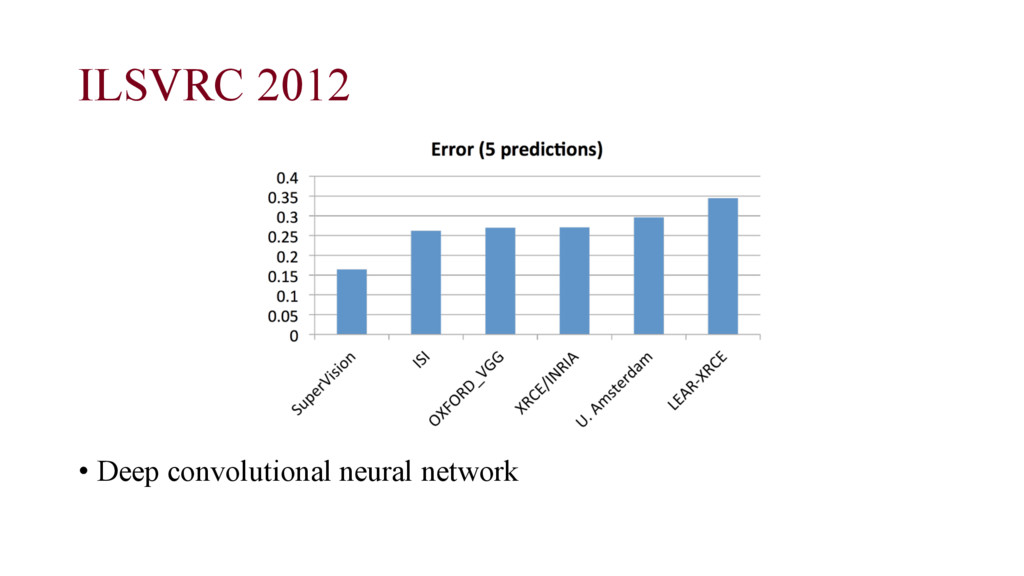
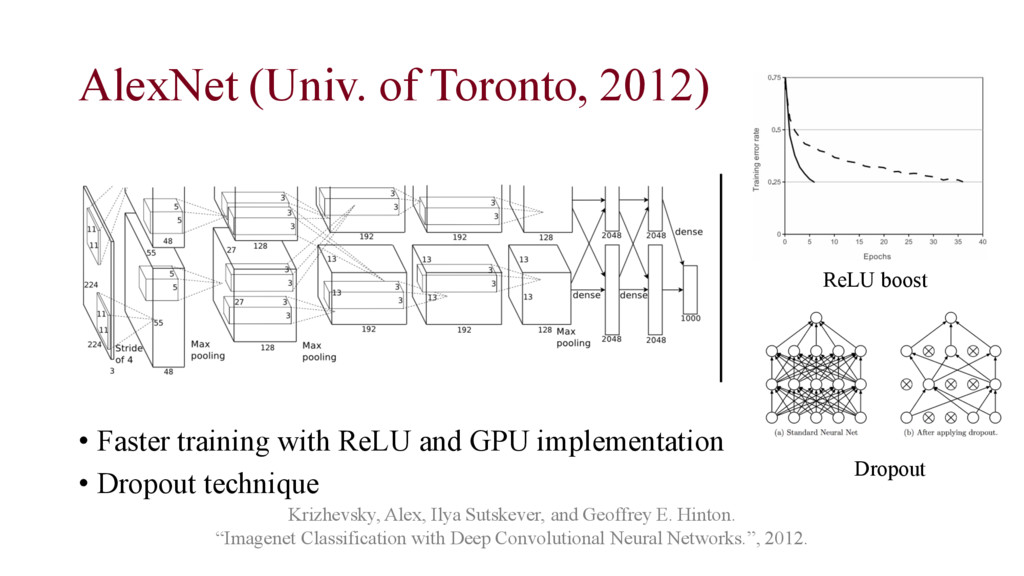
Geoffrey E. Hinton. “Imagenet Classification with Deep Convolutional Neural Networks.”, 2012. • Faster training with ReLU and GPU implementation • Dropout technique ReLU boost Dropout
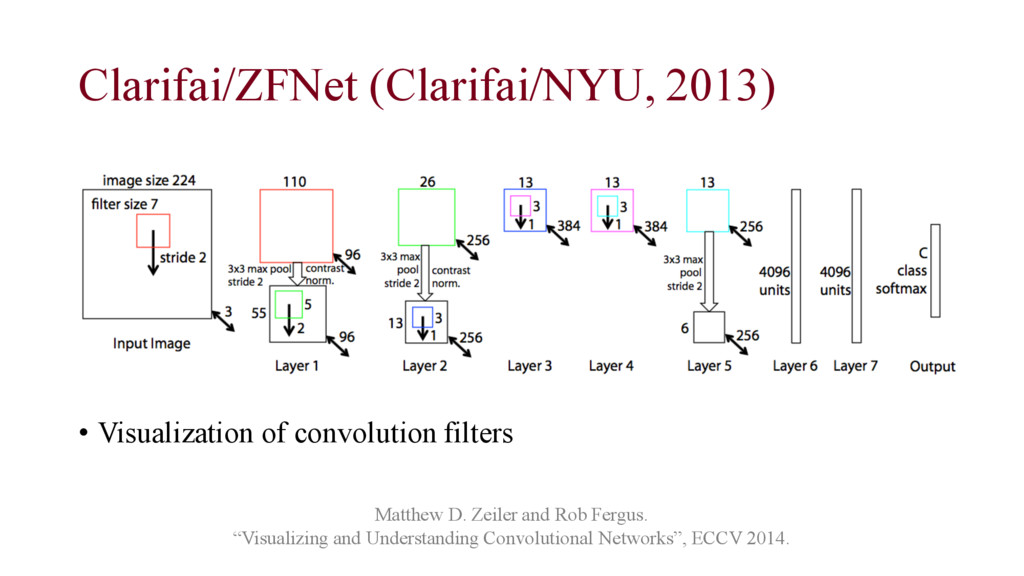
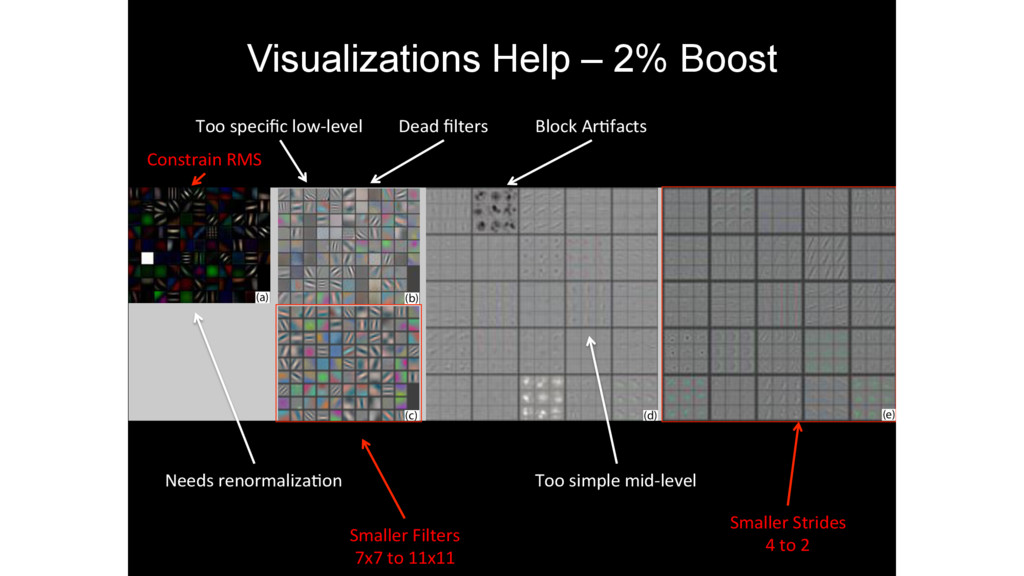
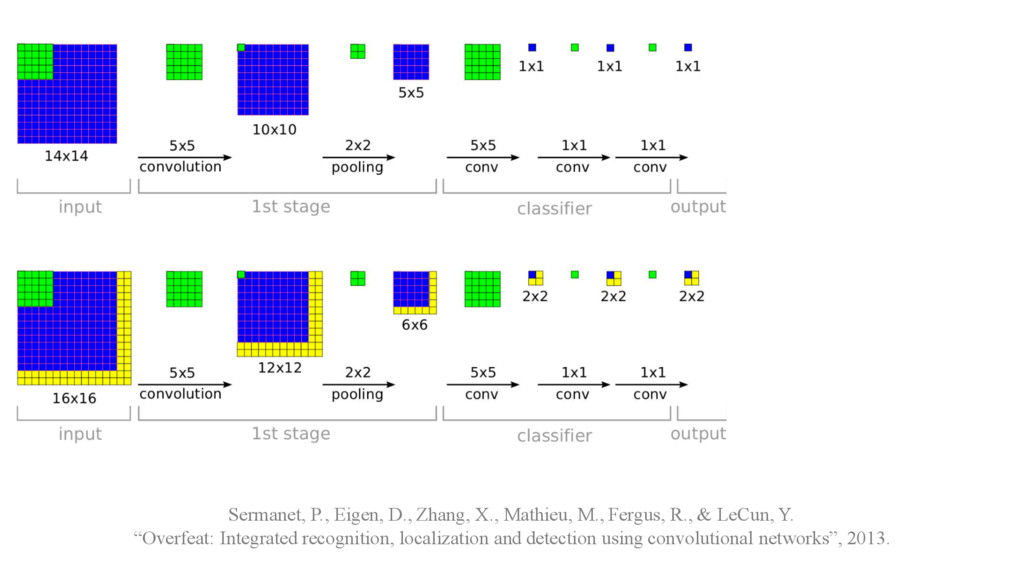
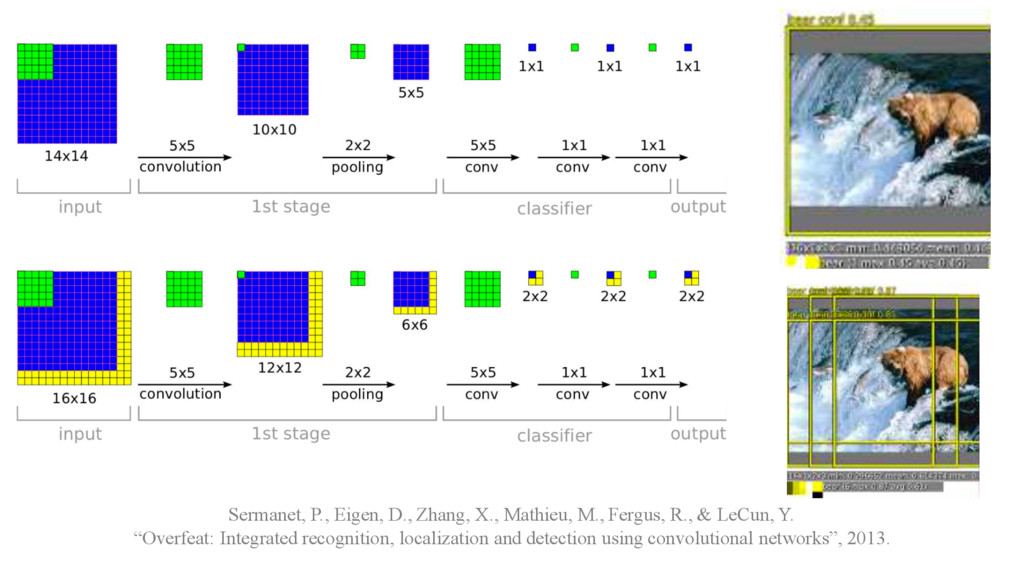
detection • Multiscale sliding window (feature pooling with 1x1 convolutional filter) Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., & LeCun, Y. “Overfeat: Integrated recognition, localization and detection using convolutional networks”, 2013.
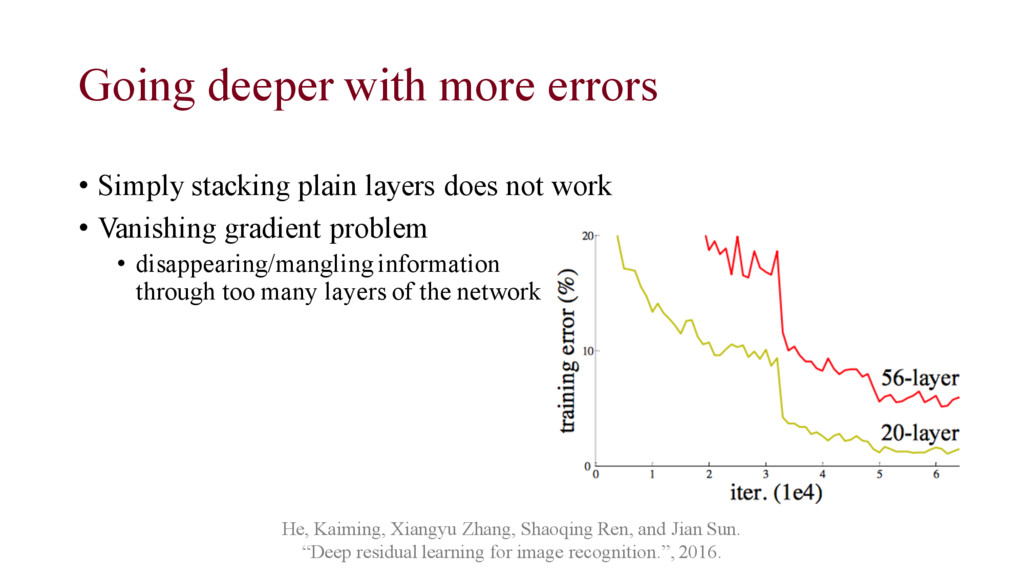
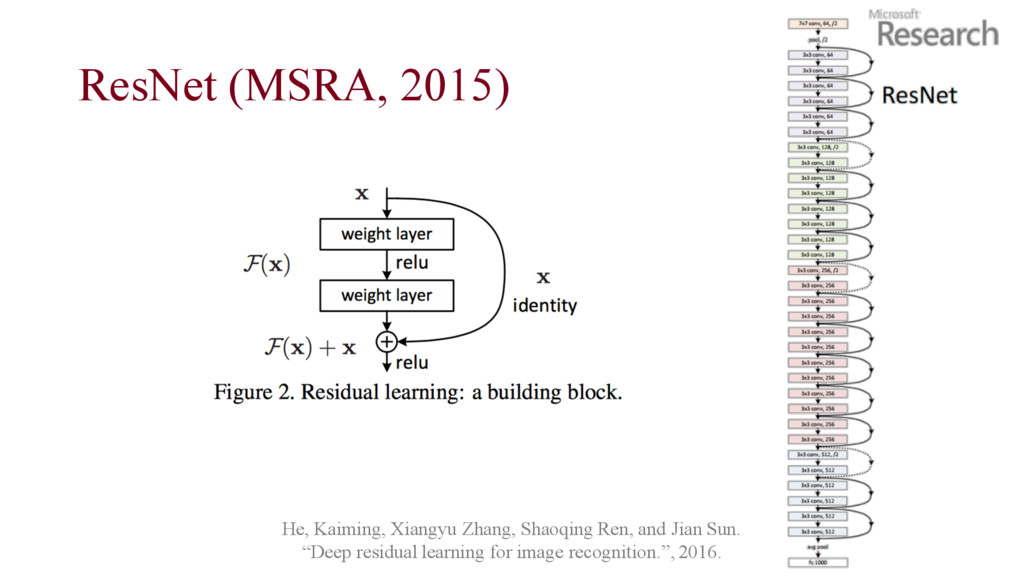
does not work • Vanishing gradient problem • disappearing/mangling information through too many layers of the network He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep residual learning for image recognition.”, 2016.
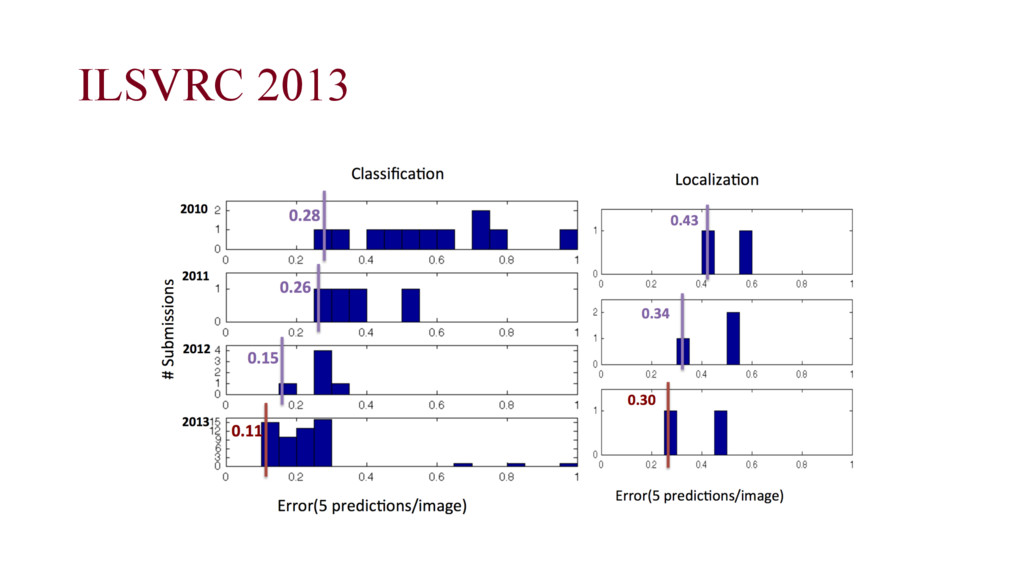
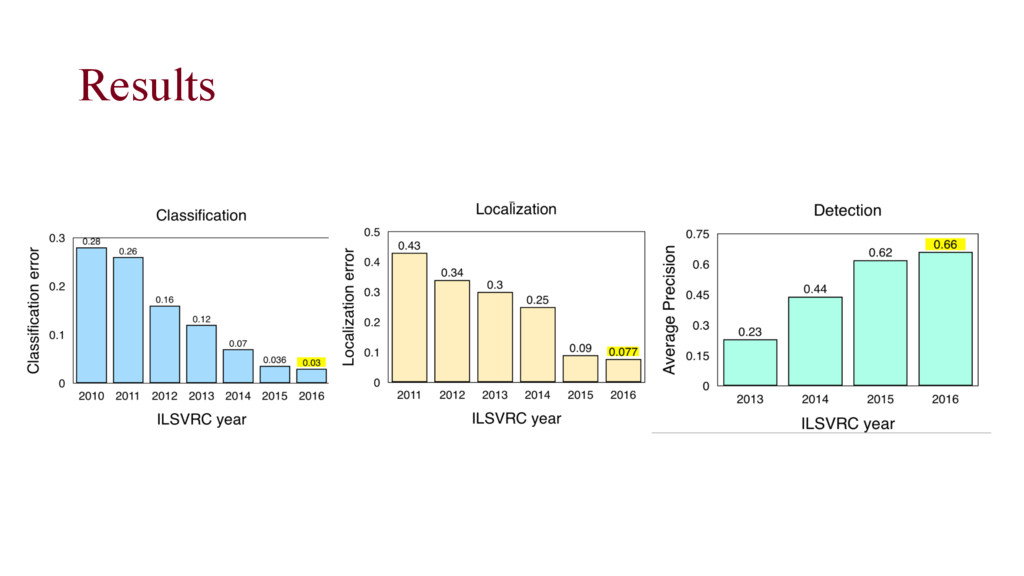
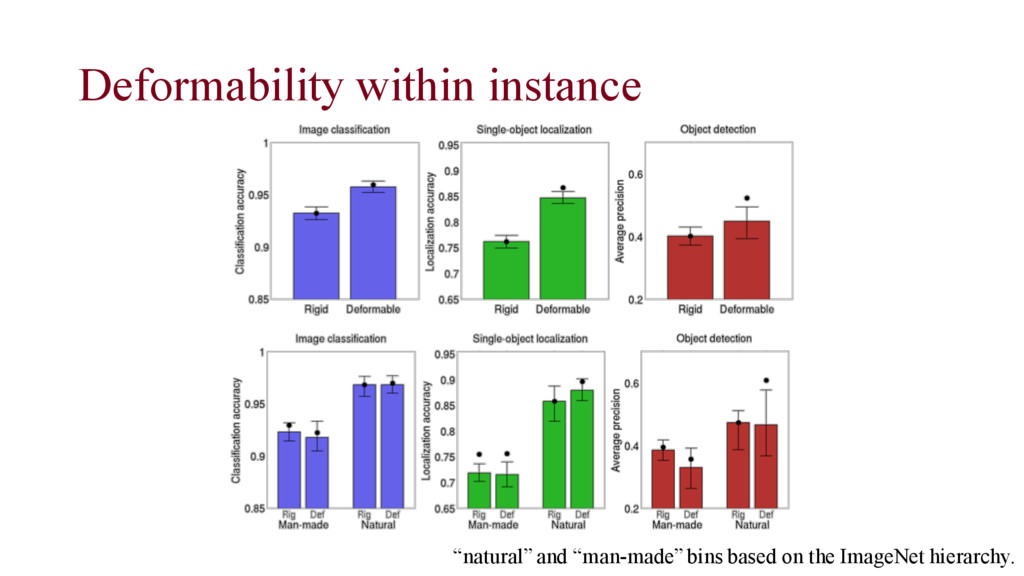
living organisms for image classification, single object loc and object detection task. • Performances are based on the best entry submitted to ILSVRC2012- 2014 (“optimistic” results)
see-through man-made objects, material “velvet”, and highly varied scene class as “restaurant” • Thin objects like “spacebar” and “pole” for localization and object detection task
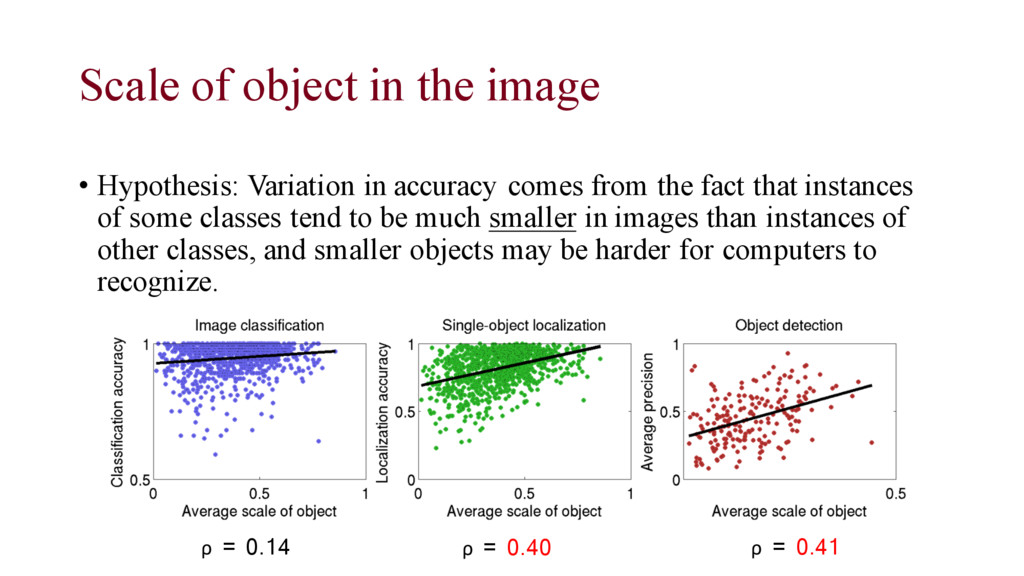
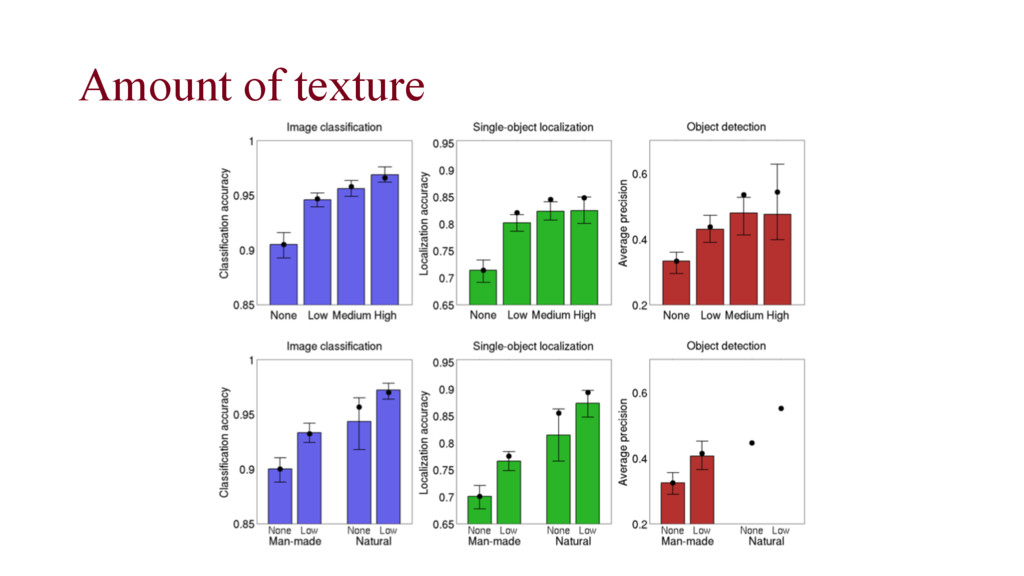
accuracy comes from the fact that instances of some classes tend to be much smaller in images than instances of other classes, and smaller objects may be harder for computers to recognize. ρ = 0.14 ρ = 0.40 ρ = 0.41
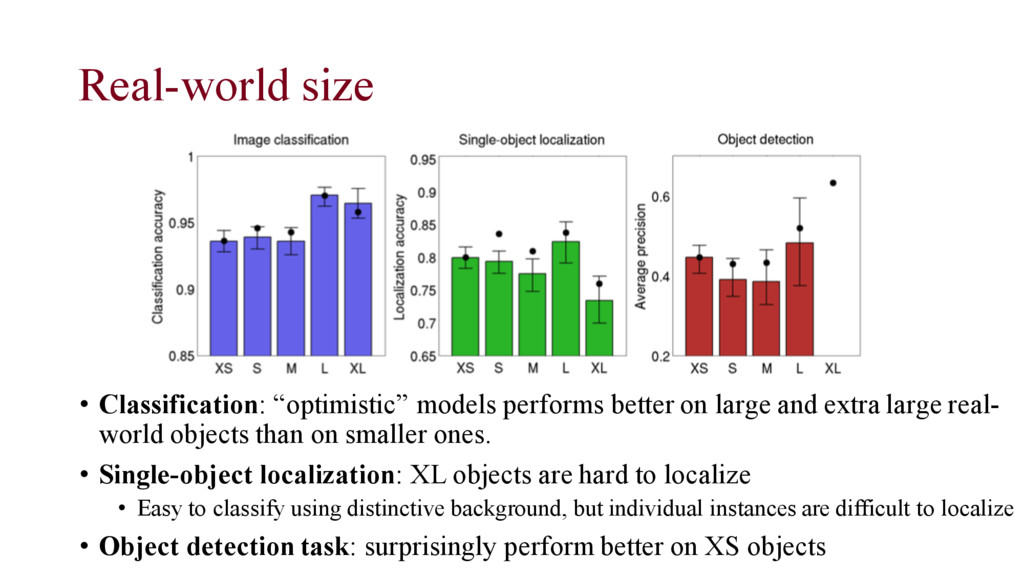
and extra large real- world objects than on smaller ones. • Single-object localization: XL objects are hard to localize • Easy to classify using distinctive background, but individual instances are difficult to localize • Object detection task: surprisingly perform better on XS objects
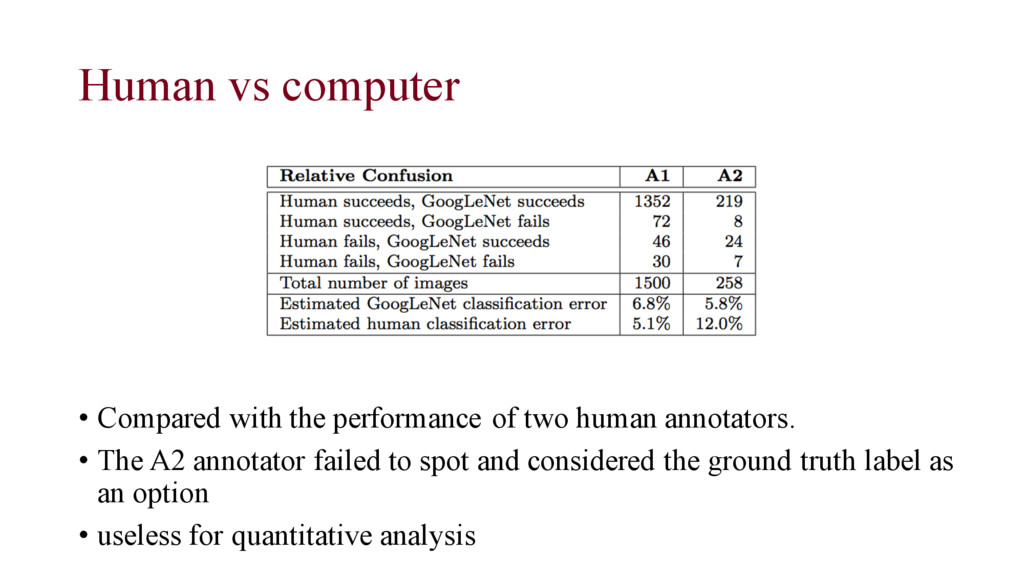
both human and computer annotations • Multiple objects • Types of errors computer is more susceptible to make Multiple obj Unconventional viewpoint Image filter Text dependent Very small obj abstract
• All human intelligence tasks need to be exceptionally well-designed. • Crowdsourcing – task design, user interface, etc. • Scaling up the dataset always reveals unexpected challenges.
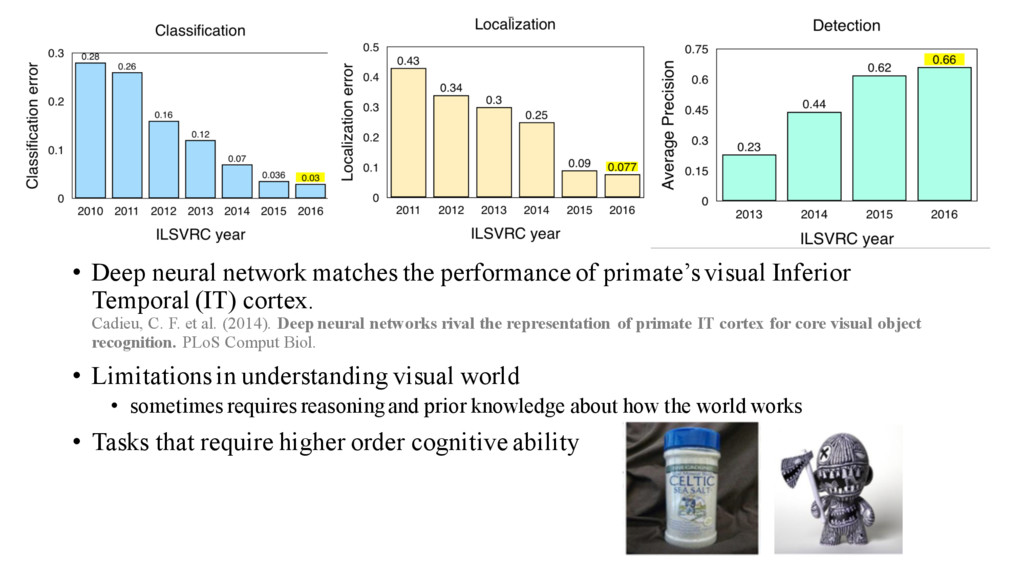
Inferior Temporal (IT) cortex. Cadieu, C. F. et al. (2014). Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Comput Biol. • Limitations in understanding visual world • sometimes requires reasoning and prior knowledge about how the world works • Tasks that require higher order cognitive ability
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}