SRE NEXT 2022 での発表資料です。 https://sre-next.dev/2022/schedule#jp38 https://www.youtube.com/watch?v=KOEQ7mqSuW8
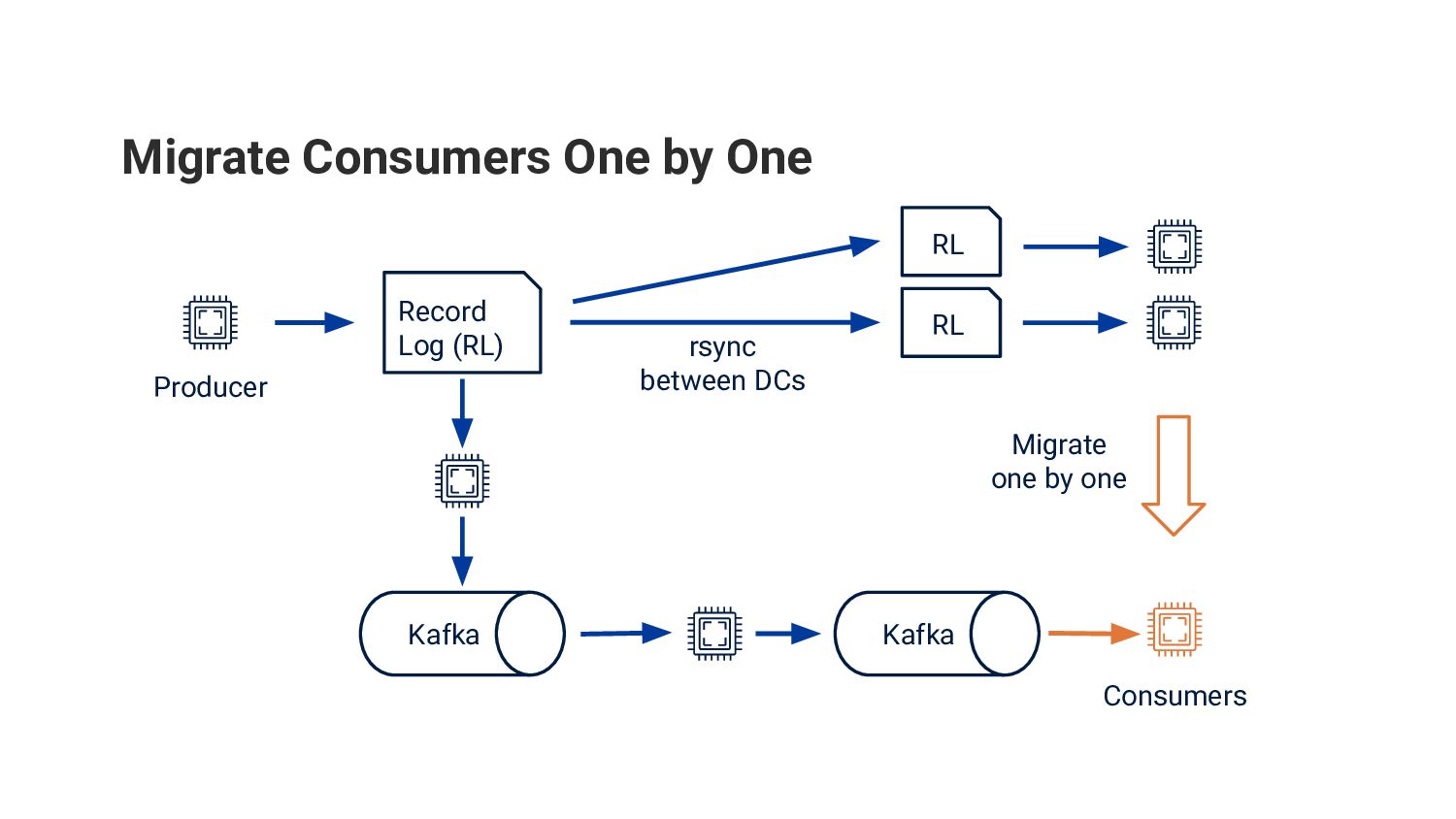
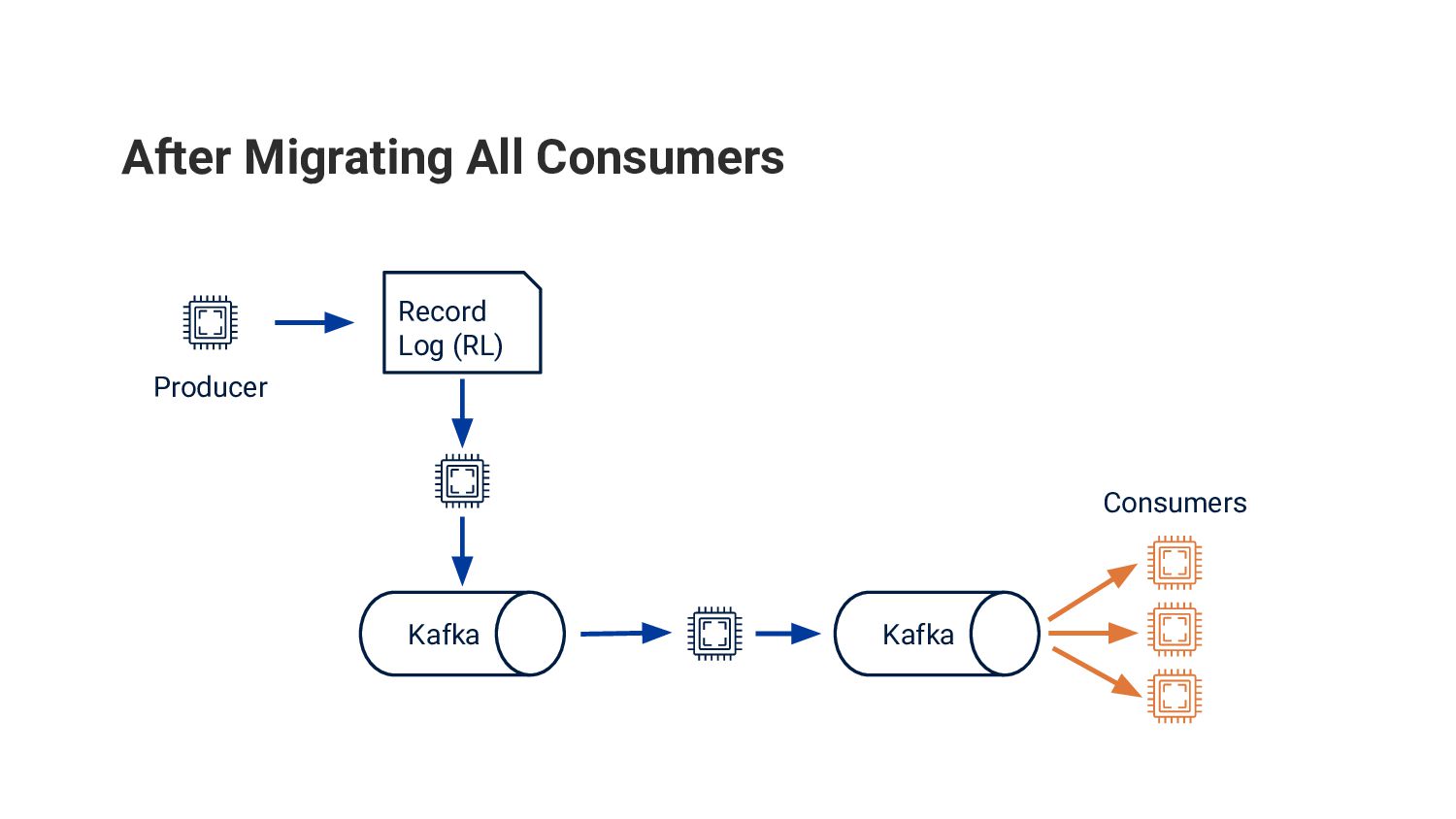
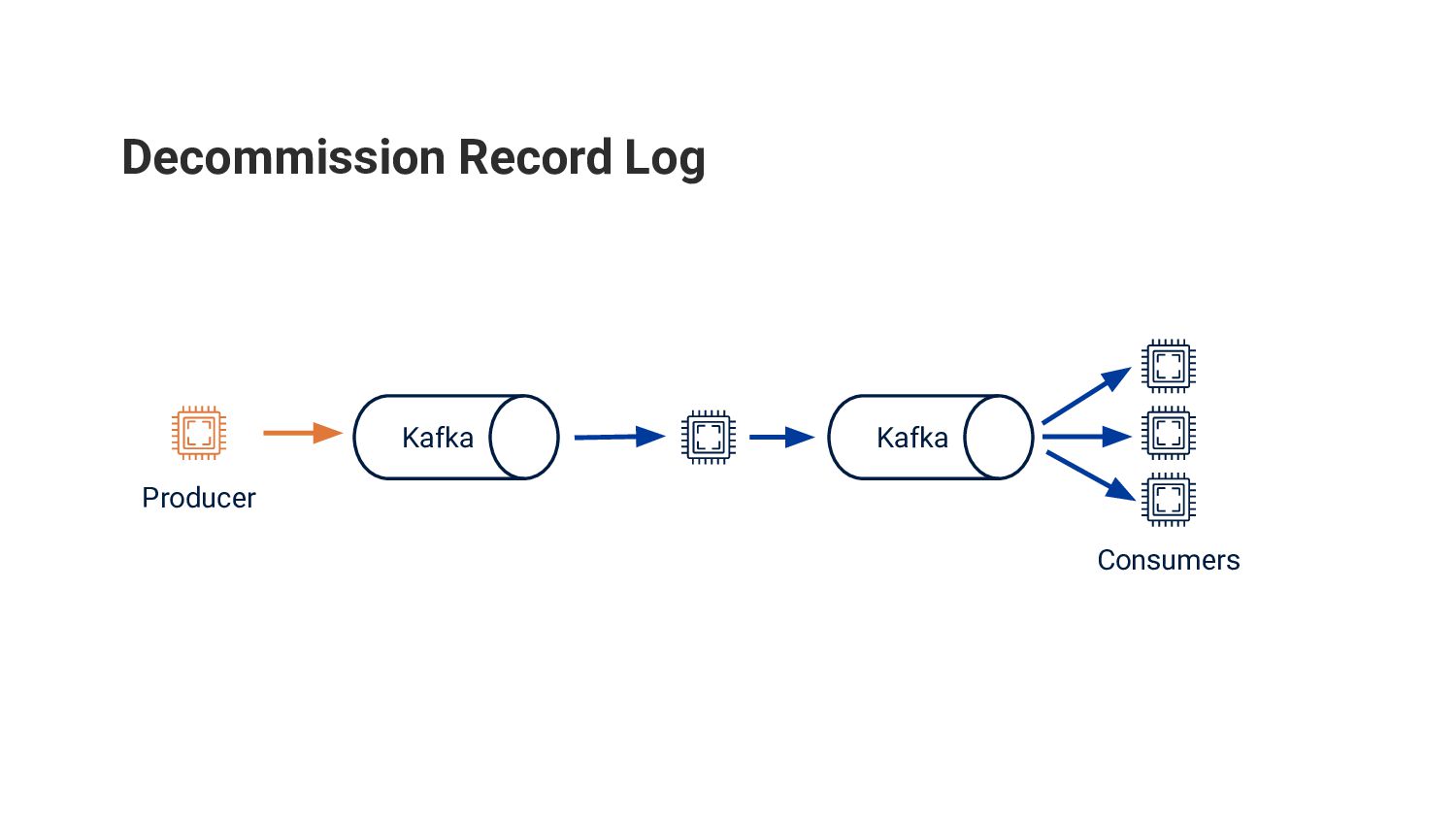
世界 No. 1 の求人検索エンジンである Indeed の求人検索のバックエンドにおいて Apache Kafka を採用した事例を紹介します。Kafka はオープンソースの分散イベントストリーミングのためのプラットフォームで、世界中の多くの企業によって採用されています。Indeed でも様々な用途で Kafka が活躍していますが、本発表では求人情報のストリーム処理とデータセンター間のレプリケーションのために利用していたレガシーなシステムを、段階的に Kafka ベースの新しいシステムに移行した事例について紹介します。
レガシーなシステムが抱えていた信頼性・プロダクト上の課題といった背景、どのように Kafka を適用しシステムの移行・検証を行ったのかという技術的な内容、ソフトウェアエンジニアやプロダクトマネージャーを含む職能横断的 (cross-functional) プロダクトチームに埋め込まれた SRE がどのようにプロジェクトを始動し、チームと共にプロジェクトを実行したのかなどをお話しする予定です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
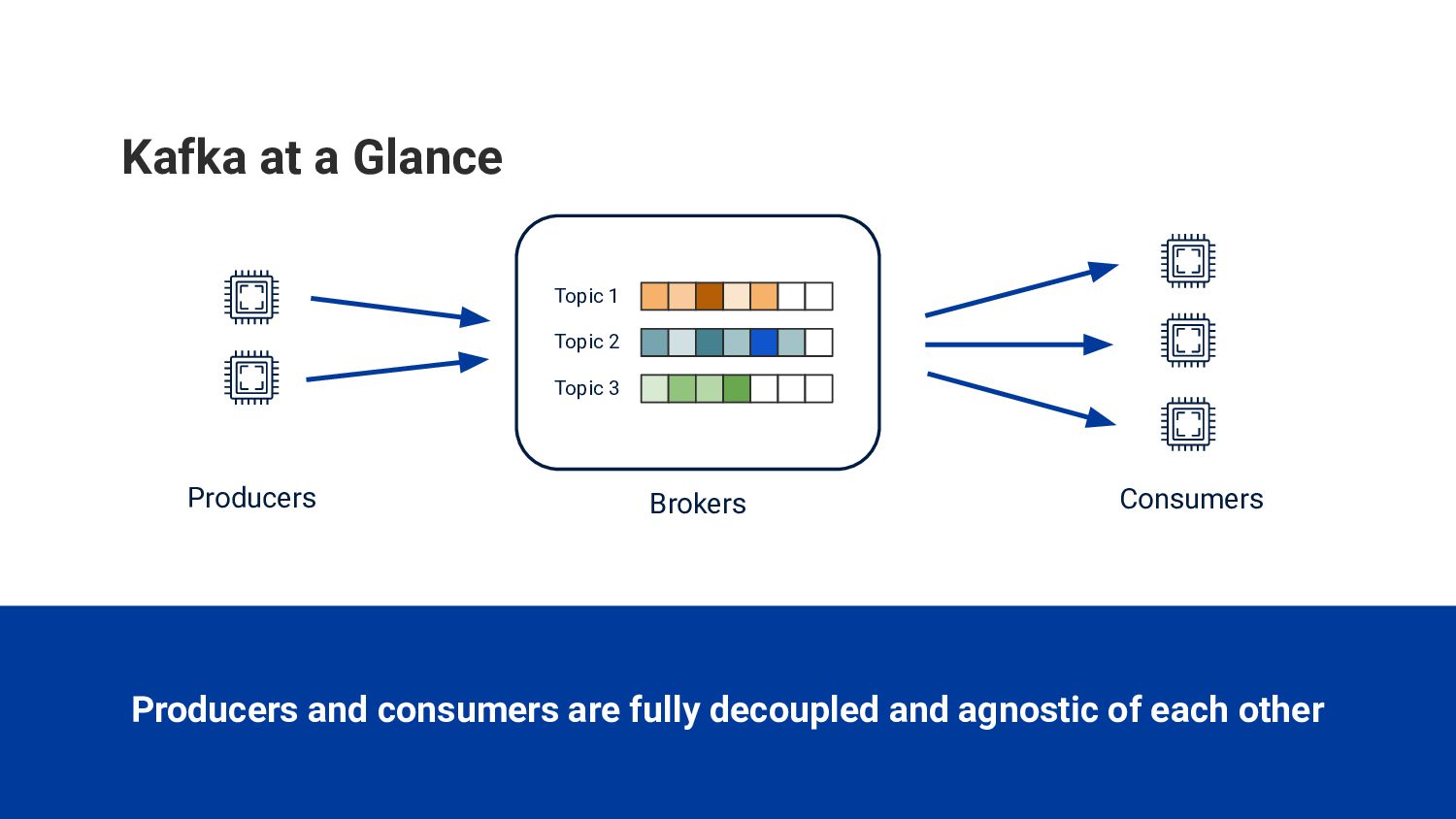{kind=link}
{kind=link}
{kind=link}
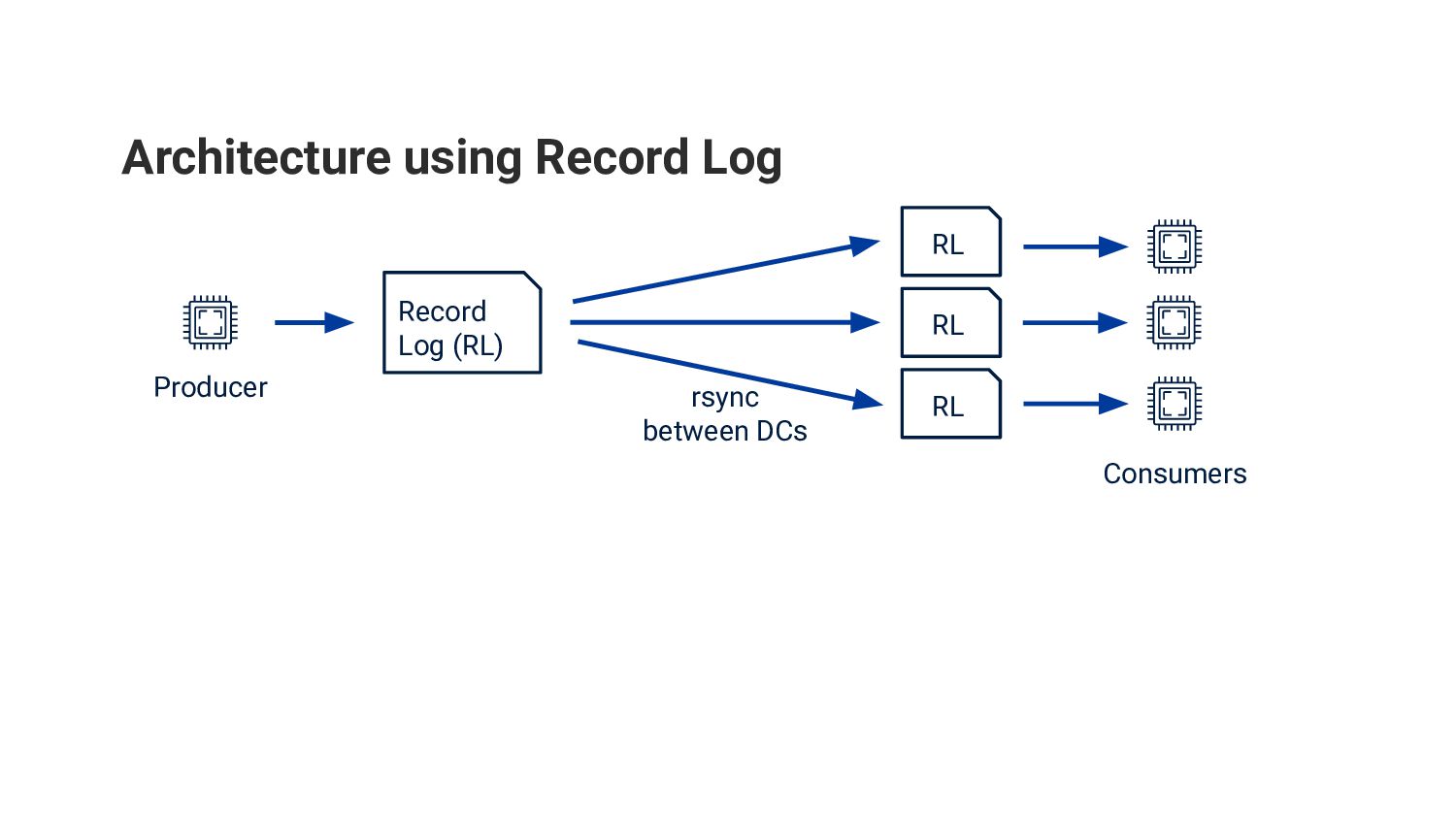{kind=link}
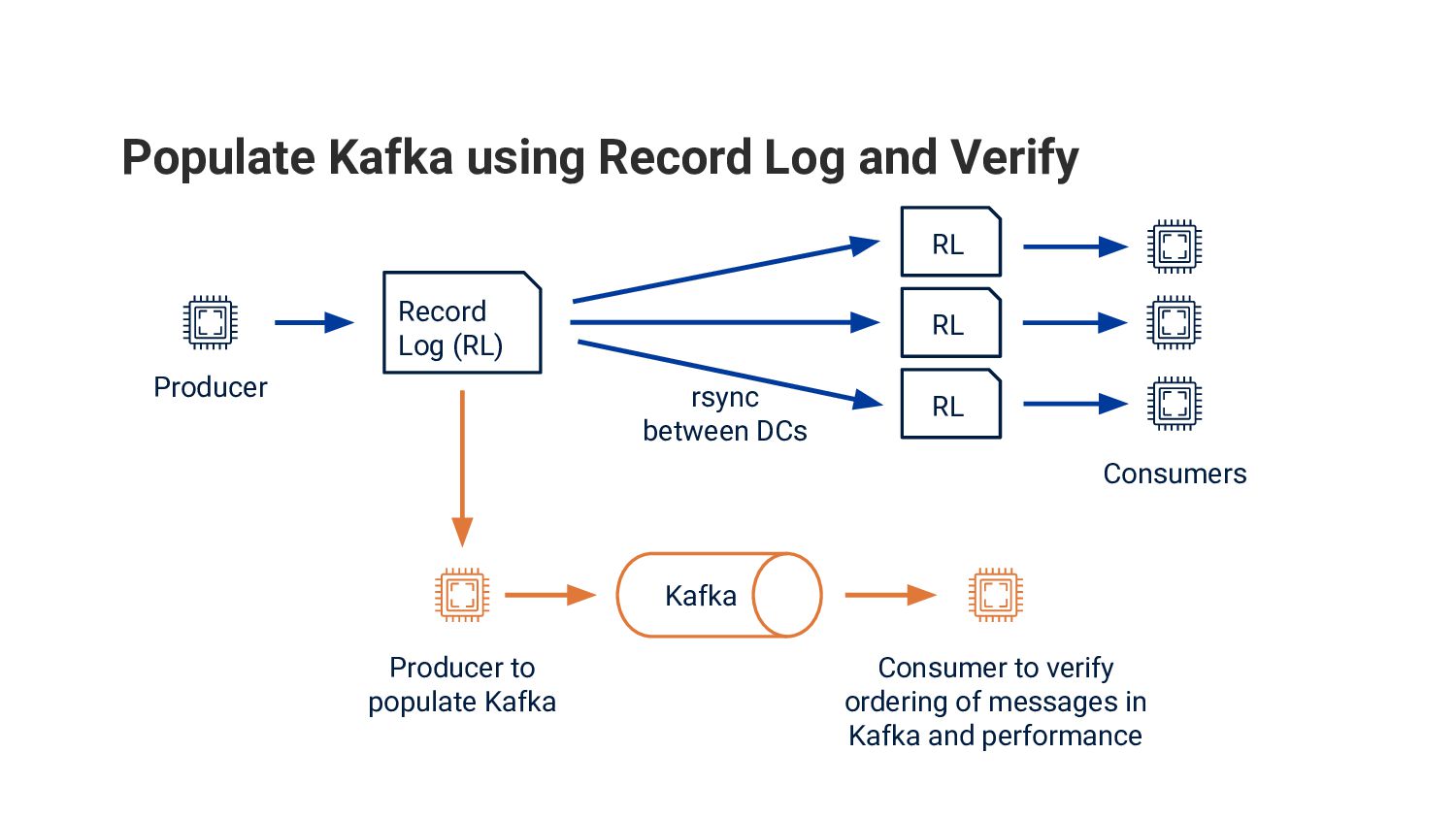{kind=link}
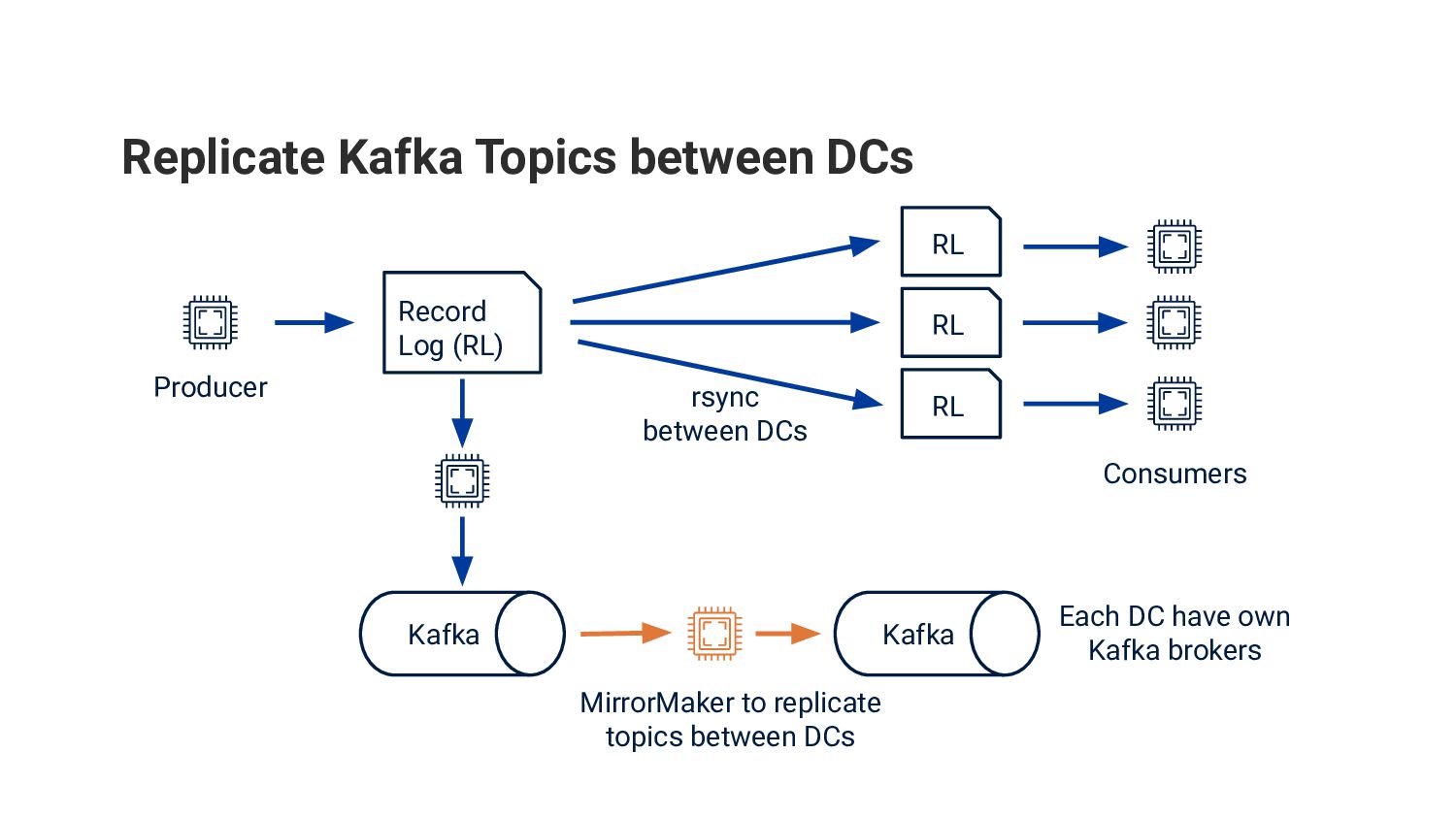{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}