and OpenStreetMap • Collaborative database, shared across all France services (IGN, La Poste, firemen, emergency services…) • Data published in open licence • V0 currently running (read only), v1 to be released first quarter of 2017 (with CRUD API) Part of “Base adresse nationale” (BAN) project
base (and a bit of Lua) • 1324 LoC • Open source (WTFPL licenced) • Stable version: 0.5 • 1.0.0 release coming • ~ 30ms as average search time on our server • ~ 2000 searchs/s on our server (6 cores) • ~ 16Go of RAM for full France data • ~ 2 millions requests/day
address – Hard to debug, “black blox” – Very good for the 80%, very hard for the next 20% – A lot of features cannot be mixed (fuzzy + edge-ngrams for autocompletion + location bias…) – Quite slow with advanced configuration mixing features
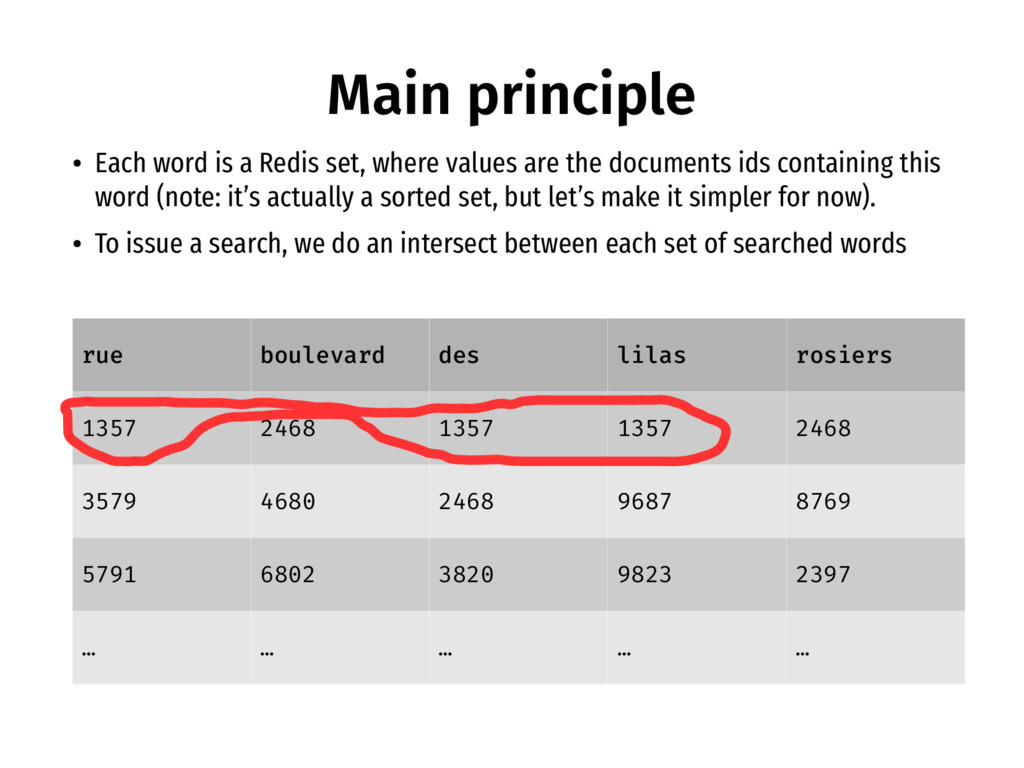
1357 2468 3579 4680 2468 9687 8769 5791 6802 3820 9823 2397 … … … … … • Each word is a Redis set, where values are the documents ids containing this word (note: it’s actually a sorted set, but let’s make it simpler for now). • To issue a search, we do an intersect between each set of searched words
replace synonyms…) • Split search string in tokens (“ru”, “de”, “lila”) • First retain only “rare” tokens • Get all candidates (by intersecting matching sets: the one for “ru”, the one for “de”, the one for “lila”) • If needed, adapt number of candidates by adding/removing tokens, autocompleting, trying fuzzy words… • Sort all candidates, by comparing search string and candidates labels (“rue rose” with “rue des roses 59240 Dunkerque”, “rue des rosiers 59220 Henain”…), plus document importance (“boulevard de la République” in Paris VS “boulevard de la République” in a small village), plus optional location bias.
one can filter by citycode, postcode, type, etc. • The available filters are configurable per Addok instance • they are just other sets, which will be added to the set intersection in order to find the candidates • for example if we have a filter by citycode, each citycode value is a set where values are documents ids with this citycode
(and only if we don’t find any good candidates without) • Dedicated “edge-ngrams” like index: the set key is the first letters of a word, and values are words starting by those letters • For example, we may have a “fri” set that would have “frigo”, “friche”, “frioul”…; but also “frig”, that would only contain “frigo”, “frigau”…
possibilities are computed in python (“frigo” would give “firgo”, “rfigo”, “friko”, “brigo”…), then only retain the ones existing in the index (in this case “friko” and “brigo”) and that have been seen with the other searched words
lon) to priorise results • Not yet using the new Redis GEO commands • Computing the geohash in python, which is then another set used to intersect documents ids • Always make sure results in the center geohash and neighbours are selected • Then apply a score boost for closer results in the sort step
(roughly) dependent of the smaller set we are trying to intersect • There are cases where we only have big sets, i.e. very common words. For example for the search “rue de la saint…” • First thing is to try to avoid such situation: if there is a filter, a center, those will usually allow to reduce a lot the intersect time • In the worst case, we do a manual scan by selecting the first “500” documents of the “less common” searched term, and we manually check if those documents are in the set of the others words
documents are more linked to some words than others • For example, in France, there is a city called “Rue” • This is why we use a sorted set, where the score is the “weight” of the relation document<=>word • First, we add a “boost” to some fields: “name” is more boosted than “city” • Then we divide this boost by the number of words in the field. For example, “name” has a boost of 4, so “Rue” in the case of the city will have a final score of “4”, while in the “rue des Lilas” the final score of “rue” is 4/3=1.333 (field boost / number of words) • When we select documents candidates, the documents with the most weighted relations come first
post search…) • Trigram experiment (split in trigrams instead of words: “rue”, “ue “, “e d”, “ de”…) via plugin • Document storage in third party DB (Sqlite, Postgres…) via plugin • Use new Redis GEO pseudo-types • Various optimizations • Lua scripts • 1.0.0 freeze
on storing the documents themselves elsewhere) • No OR in filters (postcode is 12345 OR 23456) • Only one configuration file (not possible to mix English and French in the same instance, for example)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}