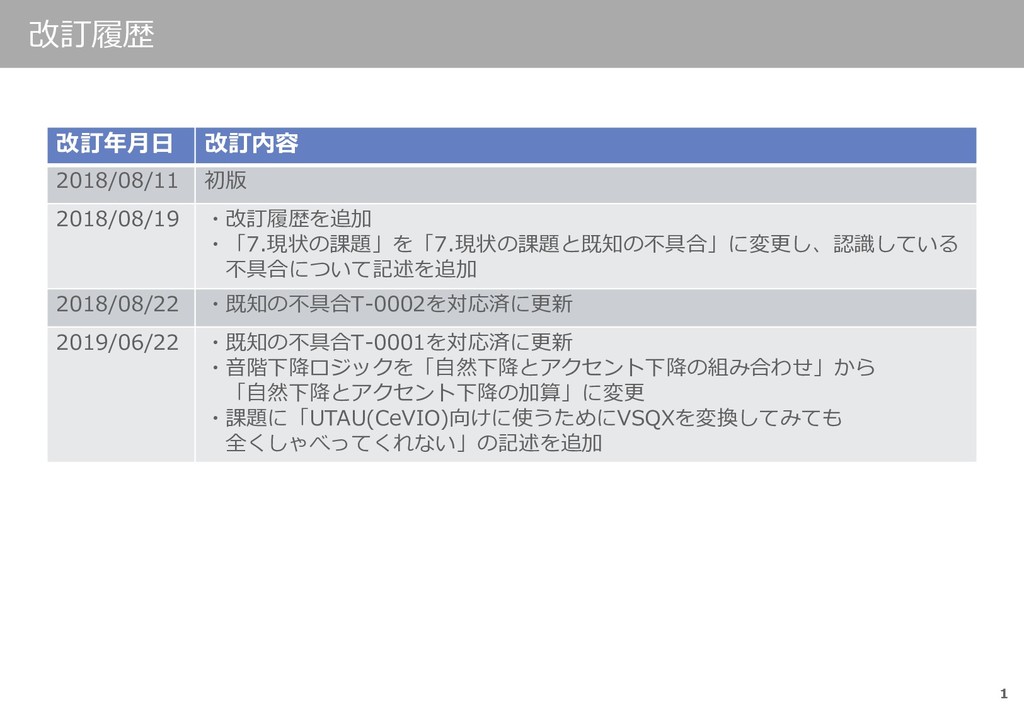
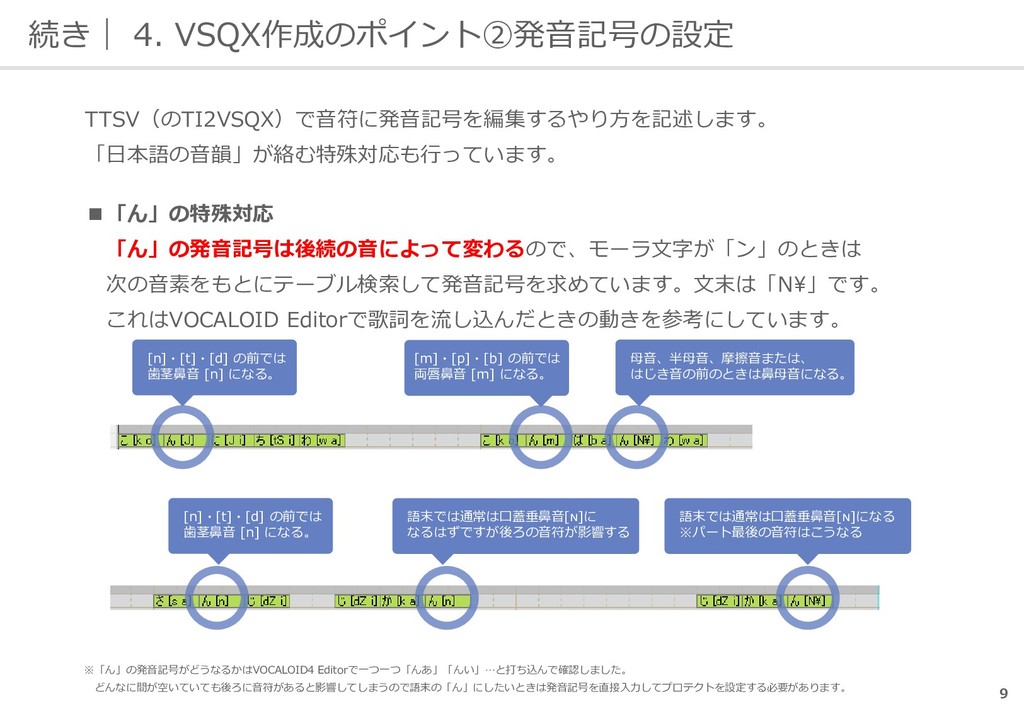
(A I U E O)そのまま適用すると「テキスト」が「テクスト」と聞こえるといった 違和感が出るので「文末で無声化した時のみ無声化する」としています。 「文末で」は、次の音素が空白(「sil」または「pau」)かで判断し、 発音記号に「Asp」を編集することで無声化しています。 ▪基本的な発音記号取得方法 トレース情報の「モーラ文字」と「音素」に対応する発音記号のテーブルを用意して、 テーブル検索して見つかったものを編集しています。 テーブルを作るにあたってはVOCALOID4 Editor同梱のユーザーマニュアルにある VOCALOID4発音記号一覧表(日本語) を参照しました。
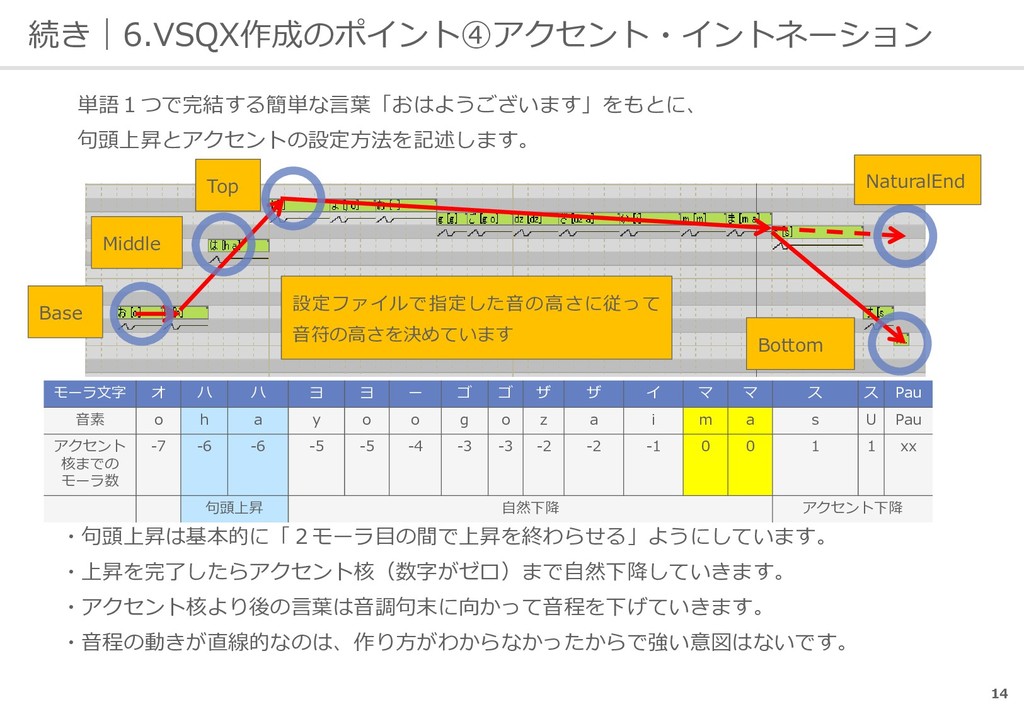
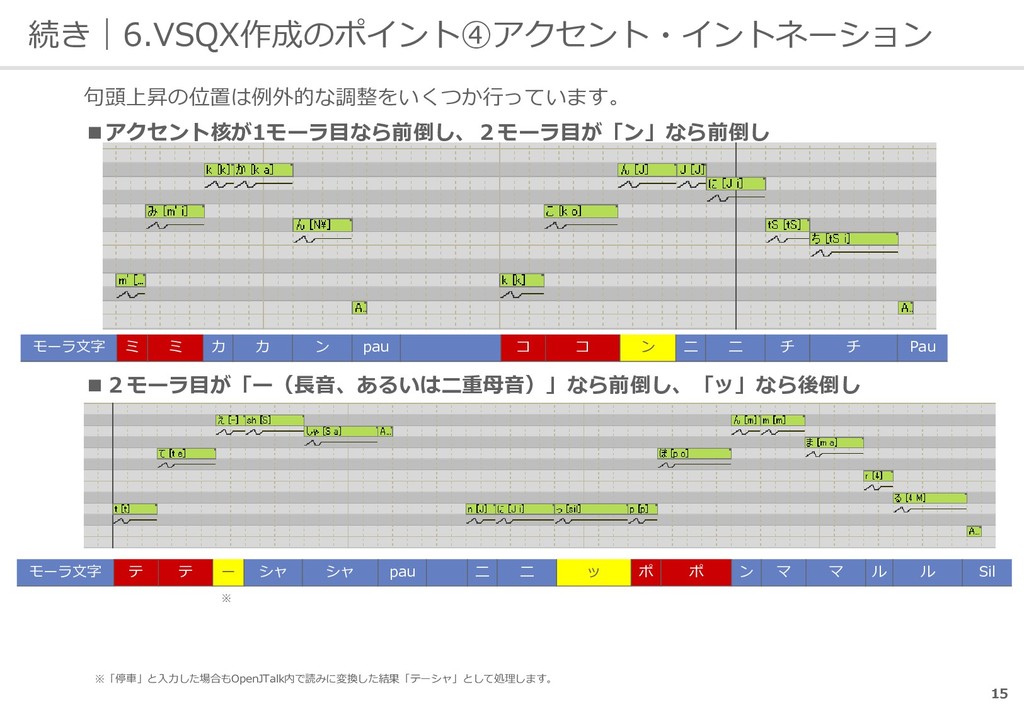
ー ゴ ゴ ザ ザ イ マ マ ス ス Pau 音素 o h a y o o g o z a i m a s U Pau アクセント 核までの モーラ数 -7 -6 -6 -5 -5 -4 -3 -3 -2 -2 -1 0 0 1 1 xx 句頭上昇 自然下降 アクセント下降 ・句頭上昇は基本的に「2モーラ目の間で上昇を終わらせる」ようにしています。 ・上昇を完了したらアクセント核(数字がゼロ)まで自然下降していきます。 ・アクセント核より後の言葉は音調句末に向かって音程を下げていきます。 ・音程の動きが直線的なのは、作り方がわからなかったからで強い意図はないです。 Base Middle Top NaturalEnd Bottom 設定ファイルで指定した音の高さに従って 音符の高さを決めています
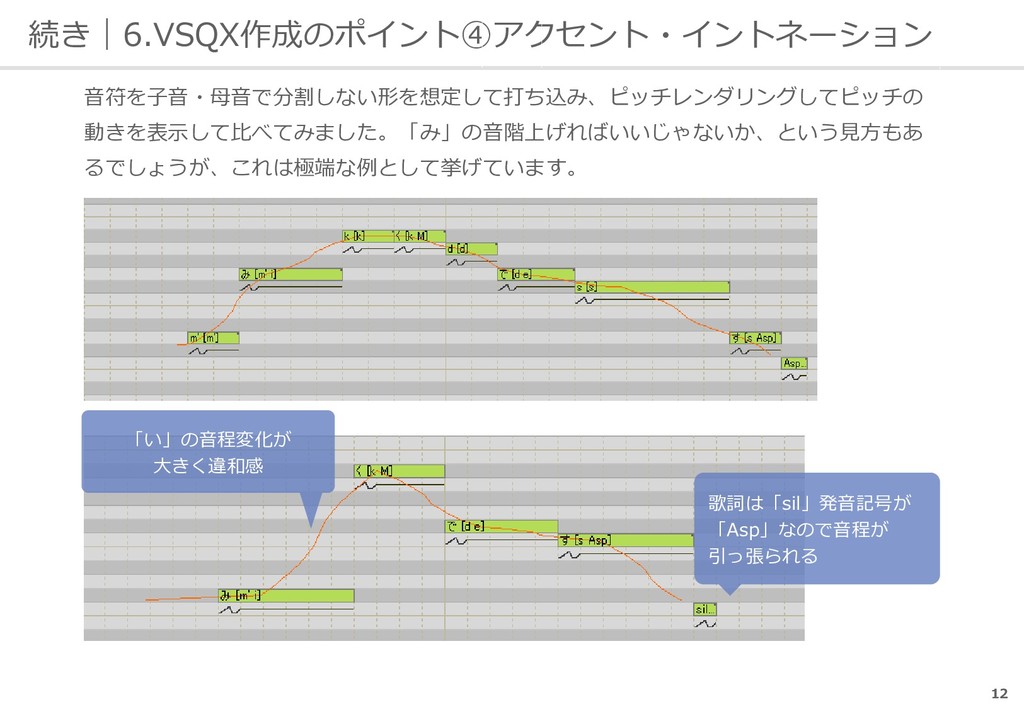
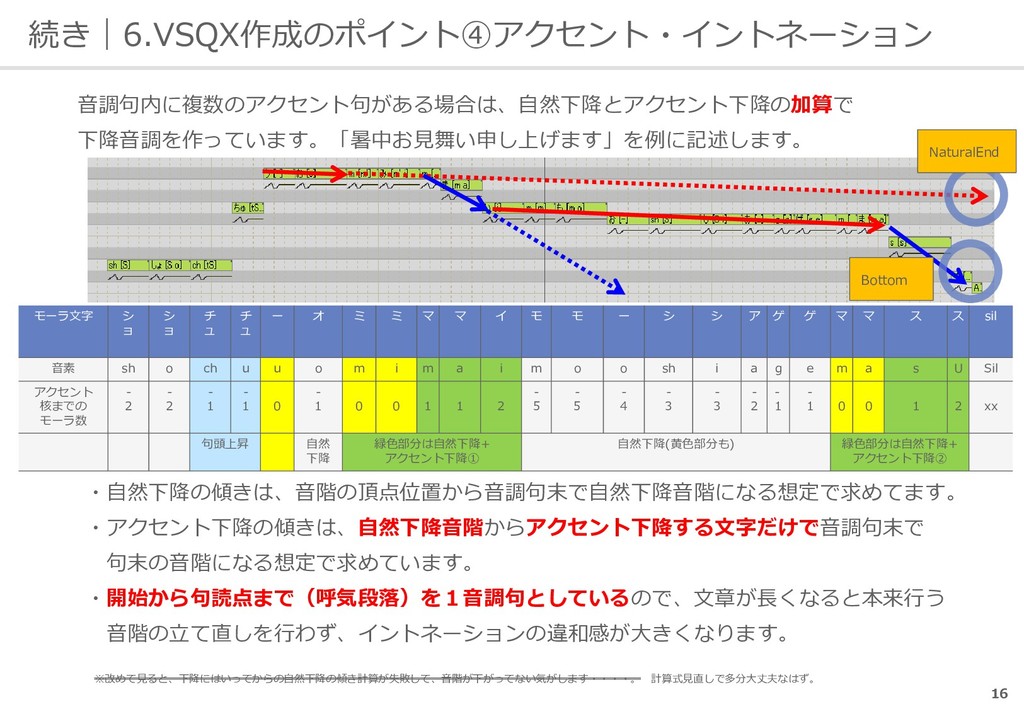
ュ チ ュ ー オ ミ ミ マ マ イ モ モ ー シ シ ア ゲ ゲ マ マ ス ス sil 音素 sh o ch u u o m i m a i m o o sh i a g e m a s U Sil アクセント 核までの モーラ数 - 2 - 2 - 1 - 1 0 - 1 0 0 1 1 2 - 5 - 5 - 4 - 3 - 3 - 2 - 1 - 1 0 0 1 2 xx 句頭上昇 自然 下降 緑色部分は自然下降+ アクセント下降① 自然下降(黄色部分も) 緑色部分は自然下降+ アクセント下降② ・自然下降の傾きは、音階の頂点位置から音調句末で自然下降音階になる想定で求めてます。 ・アクセント下降の傾きは、自然下降音階からアクセント下降する文字だけで音調句末で 句末の音階になる想定で求めています。 ・開始から句読点まで(呼気段落)を1音調句としているので、文章が長くなると本来行う 音階の立て直しを行わず、イントネーションの違和感が大きくなります。 NaturalEnd Bottom ※改めて見ると、下降にはいってからの自然下降の傾き計算が失敗して、音階が下がってない気がします・・・・。 計算式見直しで多分大丈夫なはず。
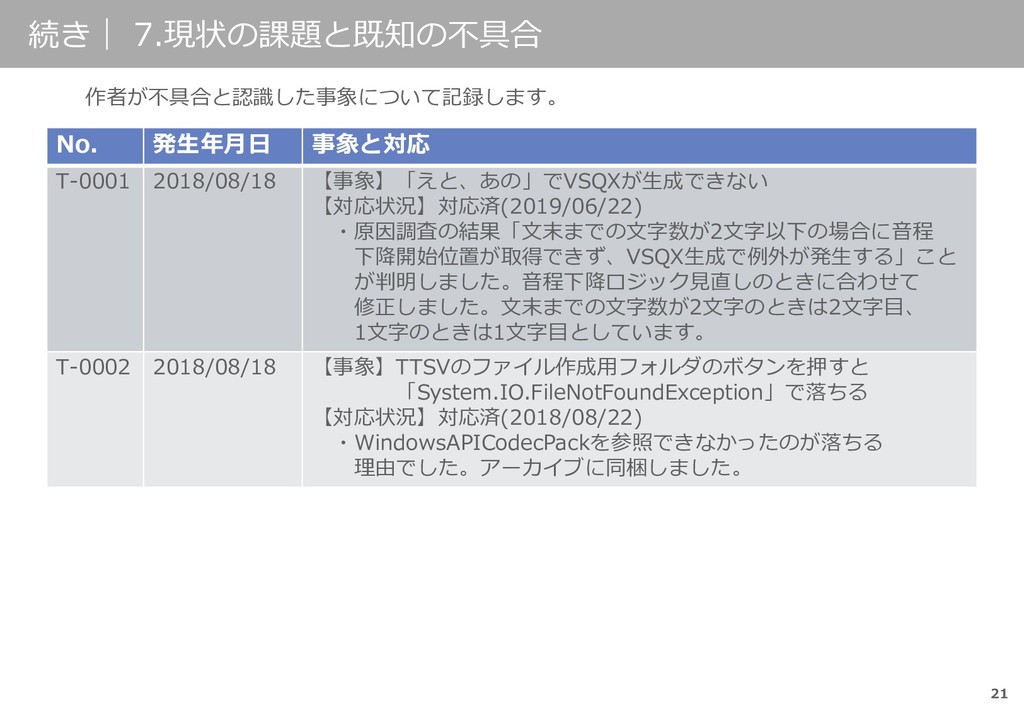
▪妙に音符が長いことがある 音響モデルによって特定の文字が長くなることがあるようです。 Open JTalkに依存する部分は手を付ける予定はありません。 ▪アクセントがおかしいことがある Open JTalkの辞書に依存する部分は手を付ける予定はありません。 TASETを使えばアクセント推定の精度が上がる、という話があるようですがWindowsで TASETをふまえたOpen JTalkが作れるのかわかっていません。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}