Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ基盤統合への歩み - ハッカーズチャンプルー2025前夜祭
Search
Yuji Takaesu
August 01, 2025
Programming
40
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データ基盤統合への歩み - ハッカーズチャンプルー2025前夜祭
Yuji Takaesu
August 01, 2025
More Decks by Yuji Takaesu
See All by Yuji Takaesu
サーバーレスのテストを取り巻く環境
yusabana
0
950
IT筋トレを続けるための技術
yusabana
0
280
テスト導入支援
yusabana
0
110
社内向けgyazo
yusabana
0
190
社内開発環境/テスト環境
yusabana
0
130
hubotを使ったチャット環境
yusabana
0
82
Other Decks in Programming
See All in Programming
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
860
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
650
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
140
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
390
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
180
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
AIエージェントで 変わるAndroid開発環境
takahirom
2
680
関数型プログラミングのメリットって何だろう?
wanko_it
0
180
Honoでのサプライチェーン侵害対策 〜 3つのライブラリに学ぶ
yusukebe
7
1.9k
えっ!!コードを読まずに開発を!?
hananouchi
0
210
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.7k
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
770
Featured
See All Featured
Music & Morning Musume
bryan
47
7.3k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
530
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Being A Developer After 40
akosma
91
590k
A designer walks into a library…
pauljervisheath
211
24k
Become a Pro
speakerdeck
PRO
31
6k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Code Review Best Practice
trishagee
74
20k
Tell your own story through comics
letsgokoyo
1
1k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Transcript
Hackers Champloo 2025 前夜祭 データ基盤統合への歩み RedshiftからBigQueryへ
⾼江洲 祐治 (たかえす ゆうじ) X: https://x.com/takaesu_ug 沖縄在住 リモートワーク歴 8年 ランニング(NAHAマラソン)
クラフトビール 【経歴】 - 2020年に⼊社してからトクバイ(チラシ‧買物情報 プラットフォーム)の開発 - https://tokubai.co.jp/ - 主にRailsやReactを⽤いた開発 - 今年からプラットフォーム開発部 - データ基盤などの開発を主軸 - ID統合や開発標準化 - データエンジニアリングとしては初⼼者
なぜデータ基盤統合するのか?!
グループ統合 • 私が2020年に⼊社してから関連会社の統廃合により社名変更や転籍によって会社が 2回変わったりして、直近の2,3年が変⾰のタイミング • 関与するサービスが増えたことによって様々なサービスのデータを横断的に扱いた い https://kufu.co.jp/company/group/
データ基盤がサービス毎に最適化されて横展開が難しい • グループ内の各種サービス毎にデータ基盤を活⽤している ◦ 主にRedshift とBigQuery、またサービス内のDBが⼊り混じっている • データの取り込み、変換、活⽤などそれぞれが最適な⼿段を適⽤しているため、 サービス毎にバラバラな状態 ◦
独⾃実装のデータ取り込み⽤のツール ◦ Embulkによる定期的な取り込み ◦ Railsのアプリケーション側のバッチ処理
データ品質に関して⼀貫性や担保が難しい • 共通化可能な条件が集計クエリ毎に定義されている ◦ クエリごとに条件が統⼀されておらず結果の担保や⼀貫性が難しい ◦ (例) 不要なBotのログを除外する条件など • 集計処理の状況把握や追跡がやりづらい
◦ どこで、どの分析基盤のテーブルを利⽤しているの分かりづらい ◦ 集計処理などをコード管理して、⼀貫性のある状態で追跡可能にしたい
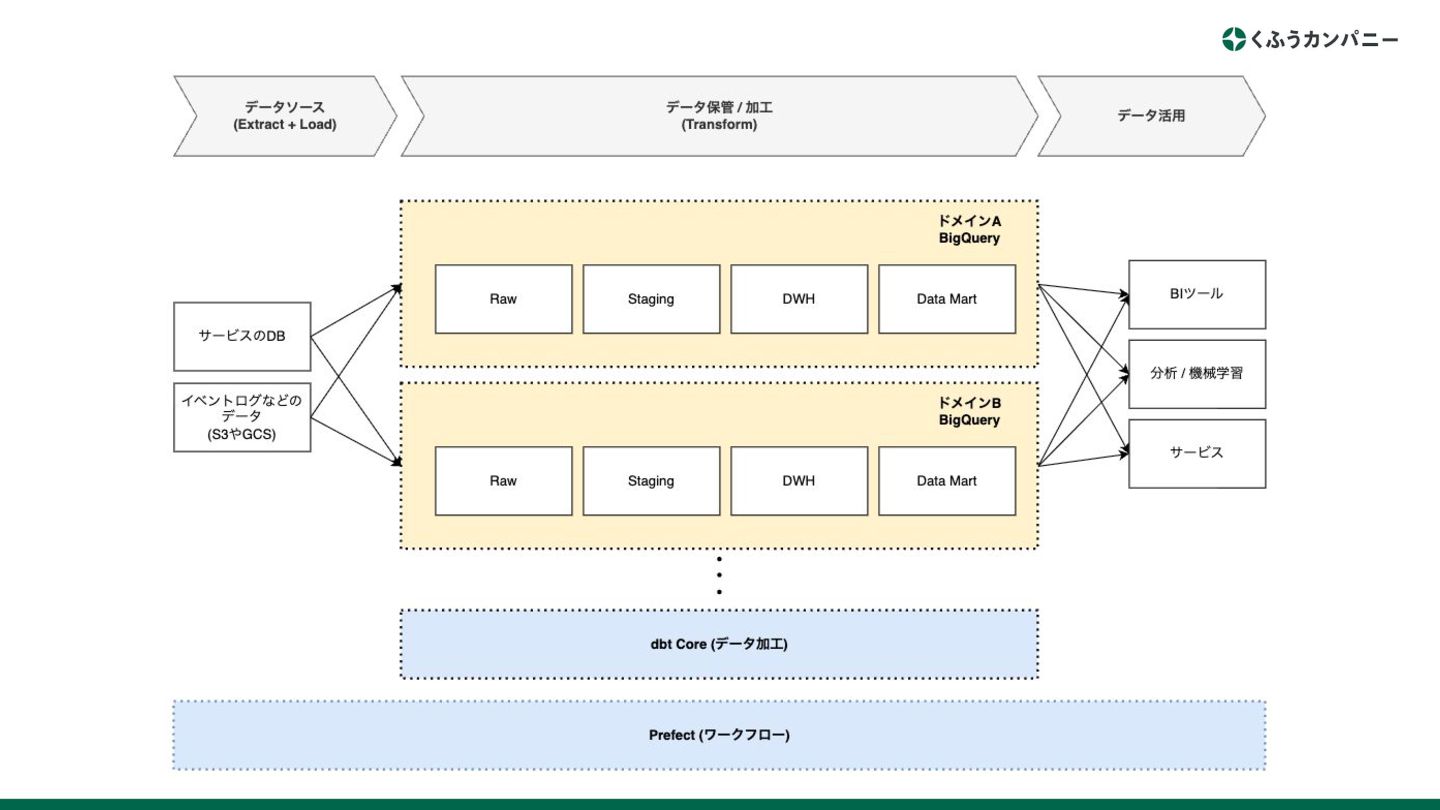
⽬指す理想像
None
理想像 1. データの格納先をBigQueryに集約する 2. ドメインごとのデータメッシュ構成を取る ◦ データメッシュ内のアーキテクチャと機能 | Cloud Architecture
Center | Google Cloud https://cloud.google.com/architecture/data-mesh?hl=ja 3. データの加⼯にはdbt Coreを利⽤する ◦ dbtのベストプラクティスの構成に習う 4. ワークフロー管理にPrefectを利⽤する ◦ dbtのデータ加⼯領域外も含めてワークフローとして管理
現状やっていることの ⼀部を紹介します
データの格納先をBigQueryに集約する (Redshift廃⽌)
Datastreamによるアプリケーションのデータの取り込み • Change Data Capture(CDC)の機能を提供 ◦ https://cloud.google.com/datastream?hl=ja ◦ 変更されたデータに対してアクションを⾏う事ができるGoogle Cloudのサー
バーレスなサービス ◦ 主にMySQL、PostgreSQL、SQL Server、Oracleなどのデータベースからの データレプリケーションに利⽤ • 特定の時点のデータを⼀括で同期するバックフィルも備えている • 設定さえすれば、新しいデータがどんどんストリームとしてBigQueryに⼊ってく る
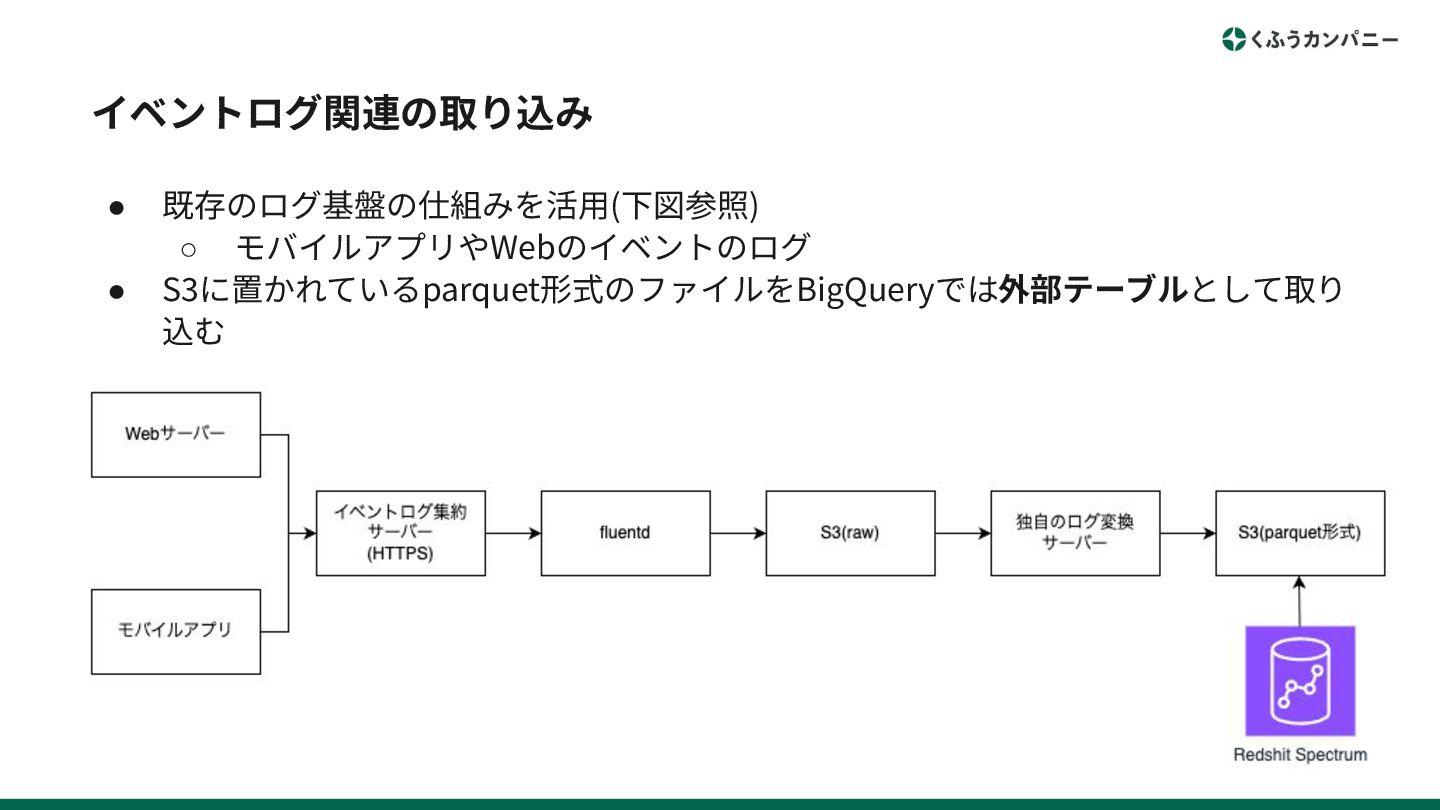
イベントログ関連の取り込み • 既存のログ基盤の仕組みを活⽤(下図参照) ◦ モバイルアプリやWebのイベントのログ • S3に置かれているparquet形式のファイルをBigQueryでは外部テーブルとして取り 込む
アプリケーション側に実装されたアドホックなバッチ処理 • ⽇次や週次の様々な集計バッチをRedshiftからBigQueryに向けるように変更 ◦ PV集計やUU集計など • ここにいくつかつらみがある ◦ TimeStamp型のTimeZone ◦
RailsのActiveRecordの依存を除く
バッチ処理のつらみ - TimeStamp型のTimeZone • RedshiftのTIMESTAMP型をそのままBigQueryにTIMESTAMP型でいれると9時間ズ レてしまう ◦ BigQuery側でTimestamp型はUTCとして保存されるため ◦ イベントログなど既存の仕組みを流⽤してBigQueryで外部テーブルとして取
り込んでいるところに要因がある • (対応)SELECT時にTIMESTAMP関数を適⽤している ◦ BigQueryにロードするときに変換するのが良いように思うが、現状は既存の 仕組みを流⽤している都合上、ロード時に⼿をいれるのは⼯数がかかる
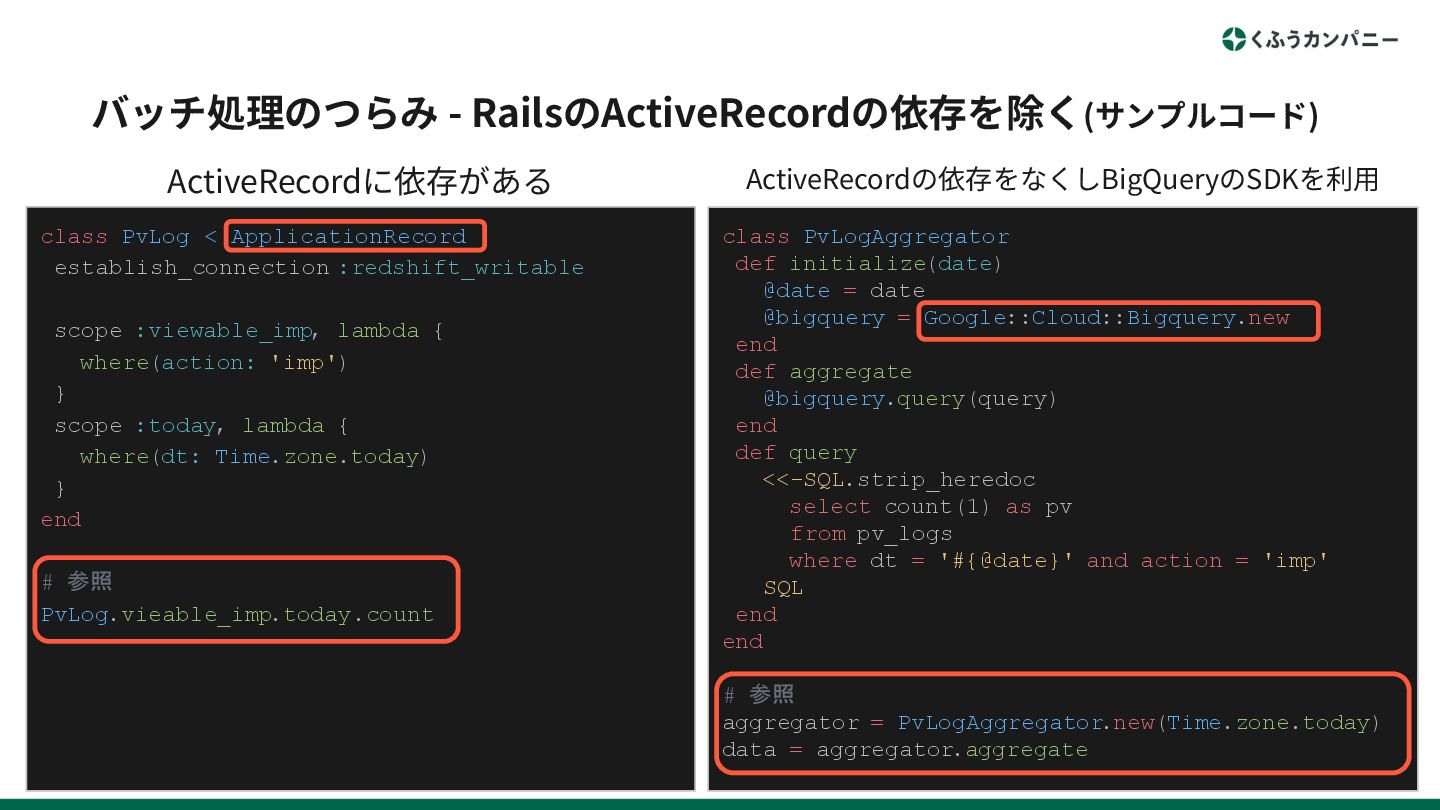
バッチ処理のつらみ - RailsのActiveRecordの依存を除く • Redshiftに対して、ActiveRecordのPostgreSQLアダプターを経由して利⽤してい る箇所がある ◦ RedshiftはPostgreSQL互換なので実装そのものは楽 ◦ 今ならRedshiftのRubySDKを使ってData
APIを利⽤するのがシンプルそう • 移⾏先として、ActiveRecordのBigQueryのアダプターもあるが使えなさそう 😇 ◦ https://github.com/michelson/BigBroda ◦ https://github.com/pedrocarmona/big_query_adapter ◦ … (他にもいくつかあるが全て古いしメンテされてなさそう)
バッチ処理のつらみ - RailsのActiveRecordの依存を除く(サンプルコード) class PvLog < ApplicationRecord establish_connection :redshift_writable scope
:viewable_imp, lambda { where(action: 'imp') } scope :today, lambda { where(dt: Time.zone.today) } end # 参照 PvLog.vieable_imp.today.count class PvLogAggregator def initialize(date) @date = date @bigquery = Google::Cloud::Bigquery.new end def aggregate @bigquery.query(query) end def query <<-SQL.strip_heredoc select count(1) as pv from pv_logs where dt = '#{@date}' and action = 'imp' SQL end end # 参照 aggregator = PvLogAggregator.new(Time.zone.today) data = aggregator.aggregate ActiveRecordに依存がある ActiveRecordの依存をなくしBigQueryのSDKを利⽤
まとめ • RedshiftからBigQueryへ基盤統合しているとい う話をしました • 理想を掲げ、少しずつ進めていってる • データ基盤の統合のようにグループ全社横断する プラットフォーム開発はサービス開発とはまた 違った⾯⽩さと難しさやつらみがある
◦ 新しい学びがあること(Prefectやdbtなど)
Fin. ありがとうございました!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}