This is my presentation when talking about Apache Kafka in Qiscus Tech Talk #113 at Block71 Yogyakarta. You can expect a working sample code in this presentation and also read the blog version here https://medium.com/@yusufs/getting-started-with-kafka-in-golang-14ccab5fa26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
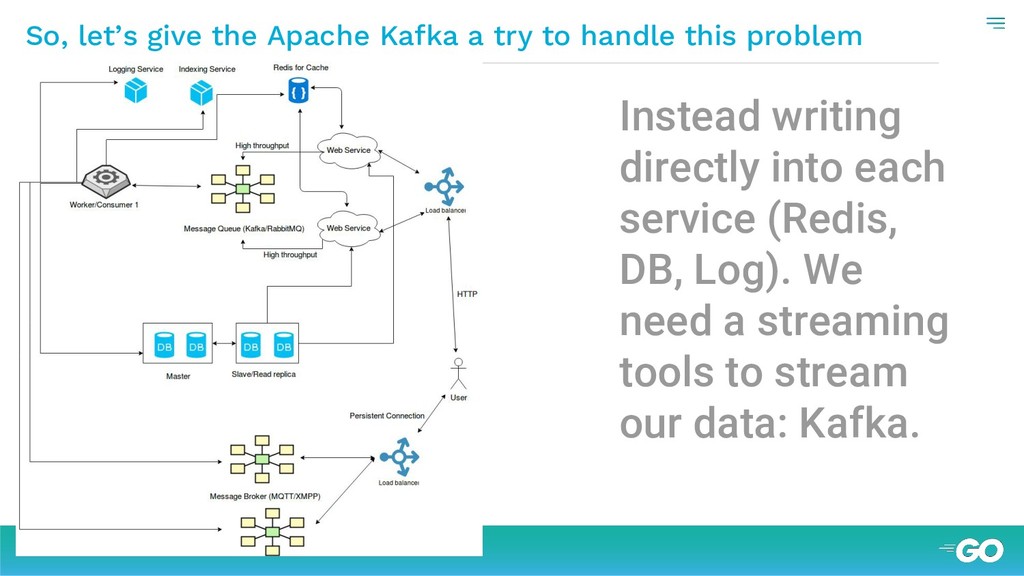{kind=link}
{kind=link}
{kind=link}
{kind=link}
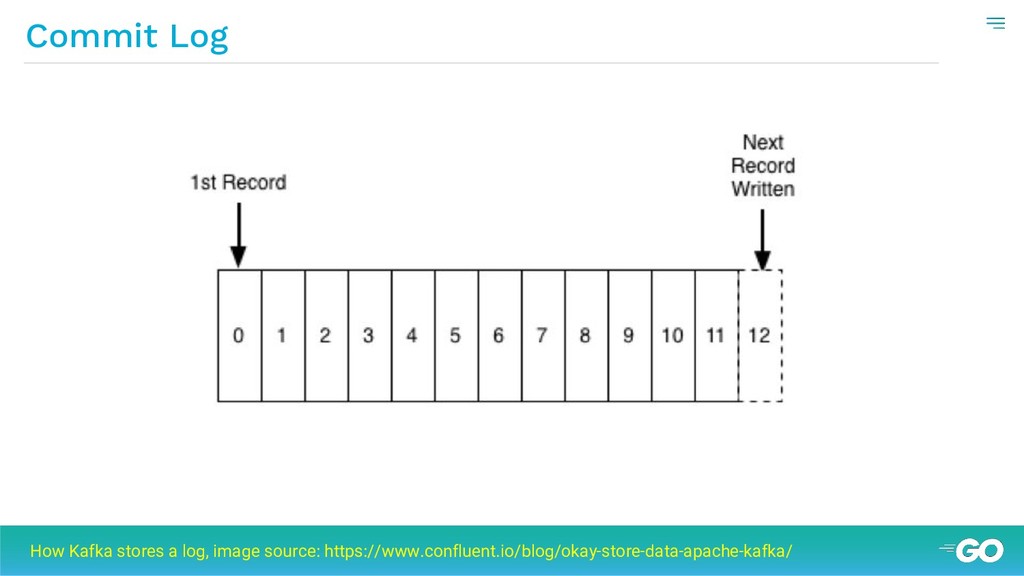{kind=link}
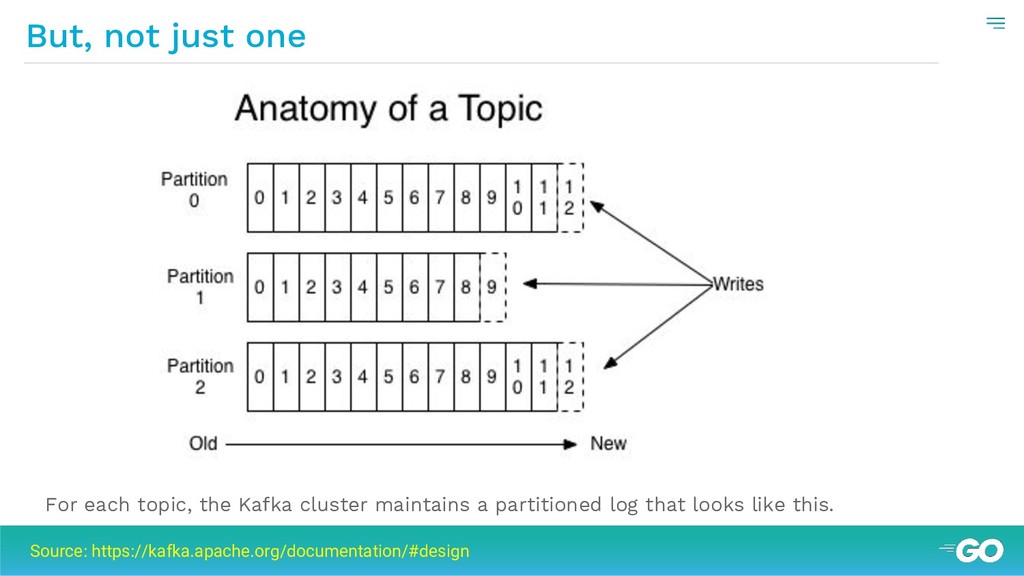{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}