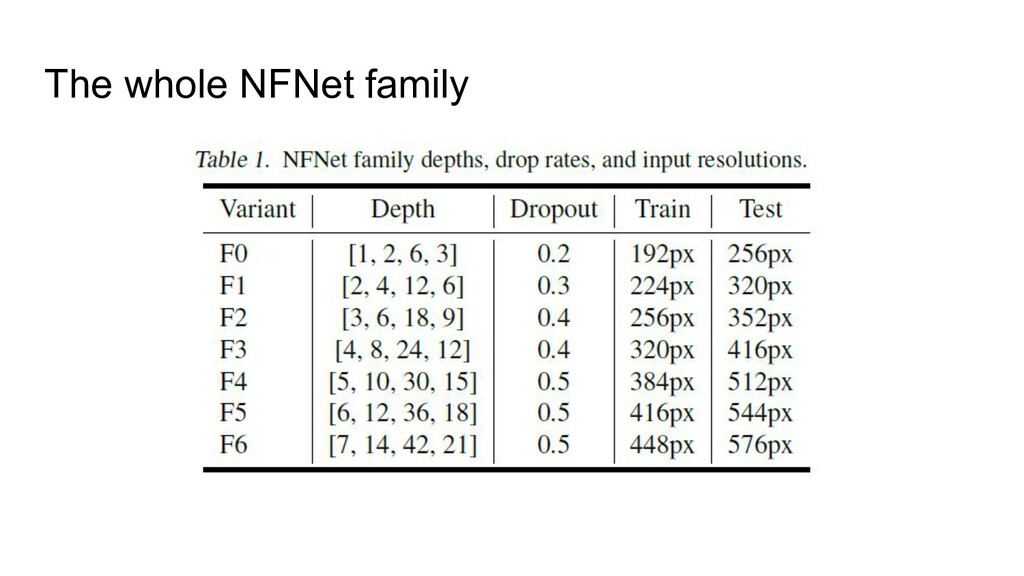
NFNet: High-Performance Large-Scale Image Recognition Without Normalization
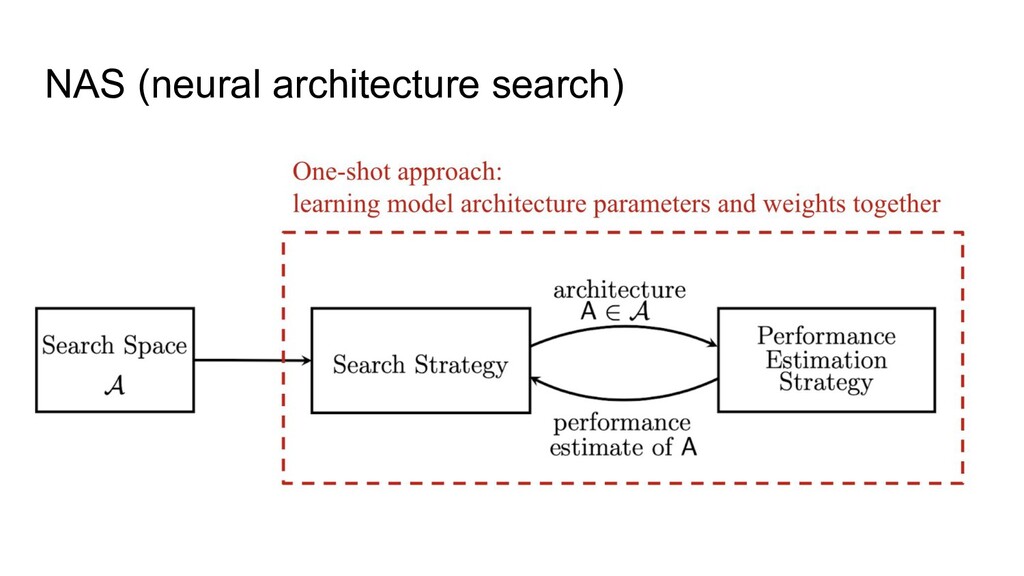
This is a talk about SAM, image augmentation, ResNet-like architectures evolution (from ResNet to NFNet), NAS (neural architecture search), and other techniques which could help to build modern SOTA in Computer Vision and Object Detection.
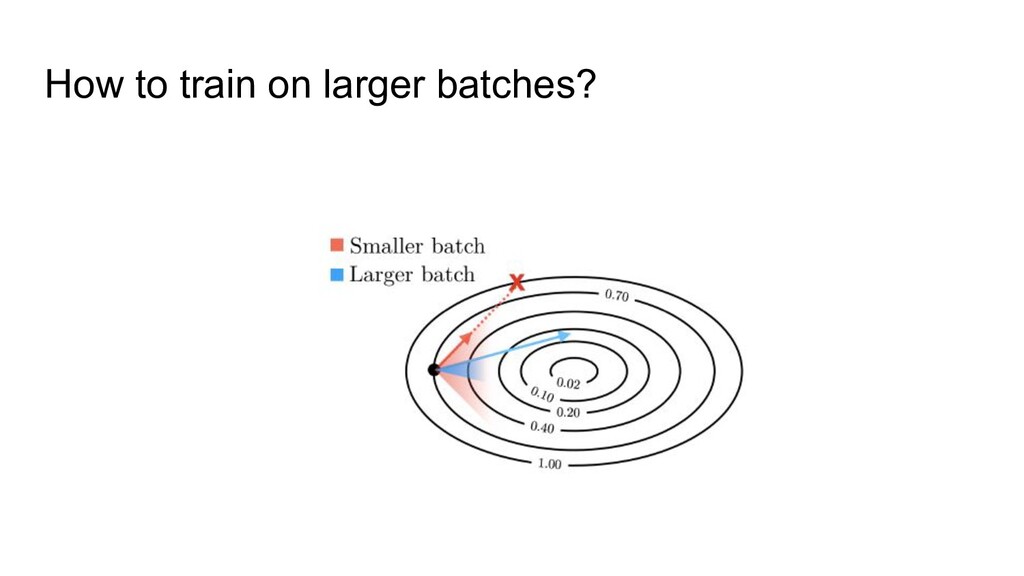
breaks the assumption of data independence • Introduces a lot of extra hyper-parameters that need further fine-tuning • Causes a lot of implementation errors in distributed training • Requires a specific “training” and “inference” mode in frameworks
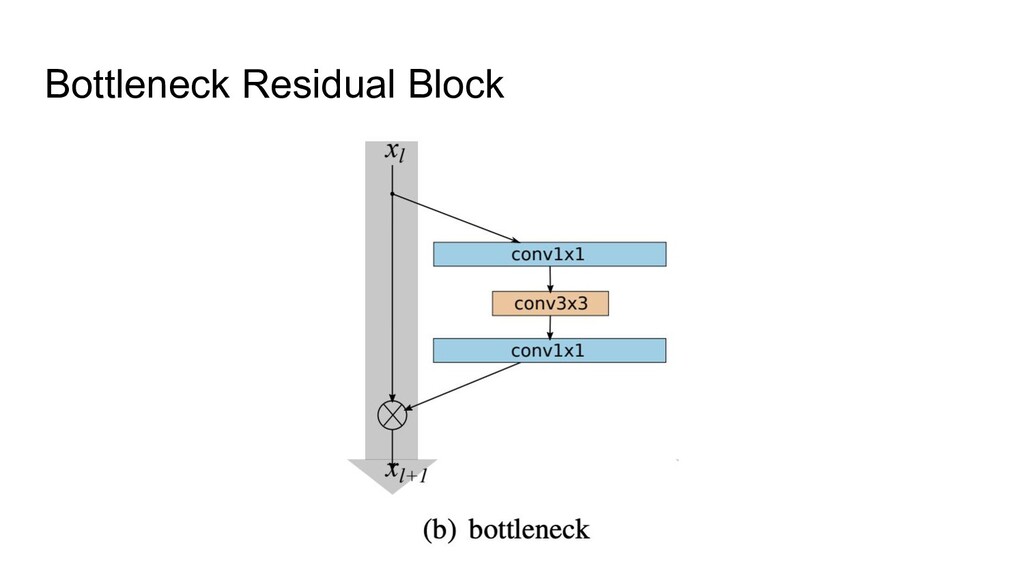
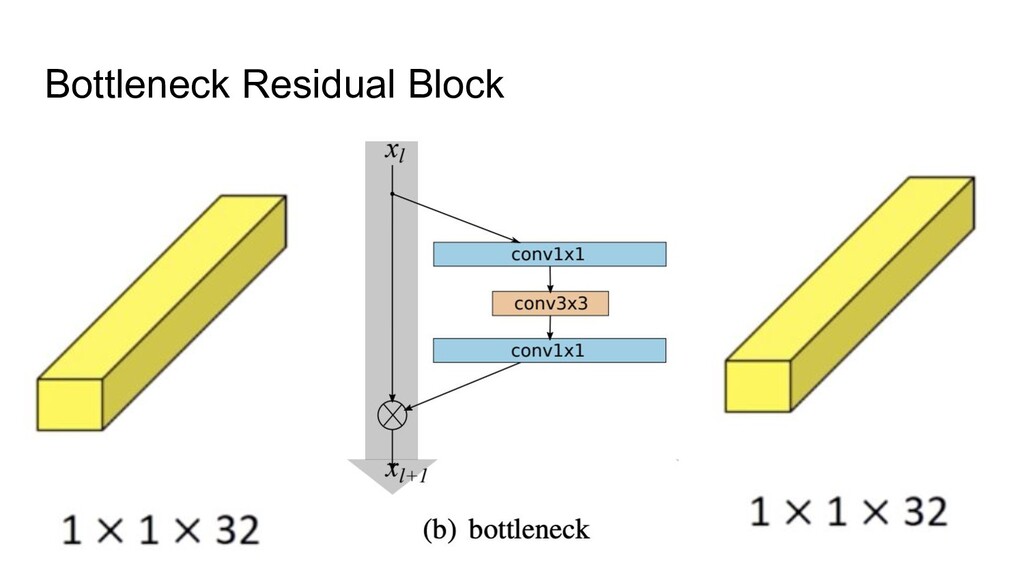
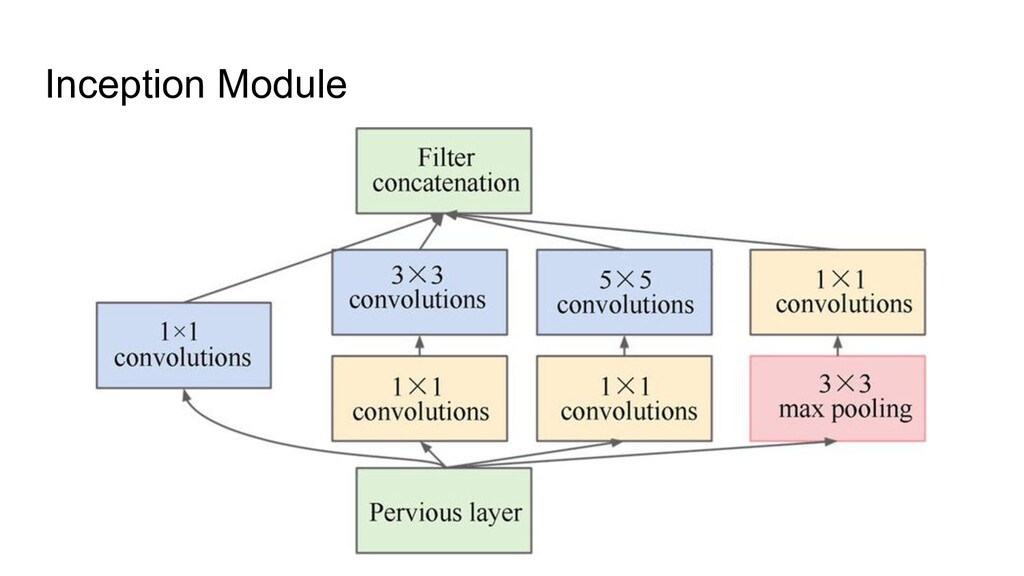
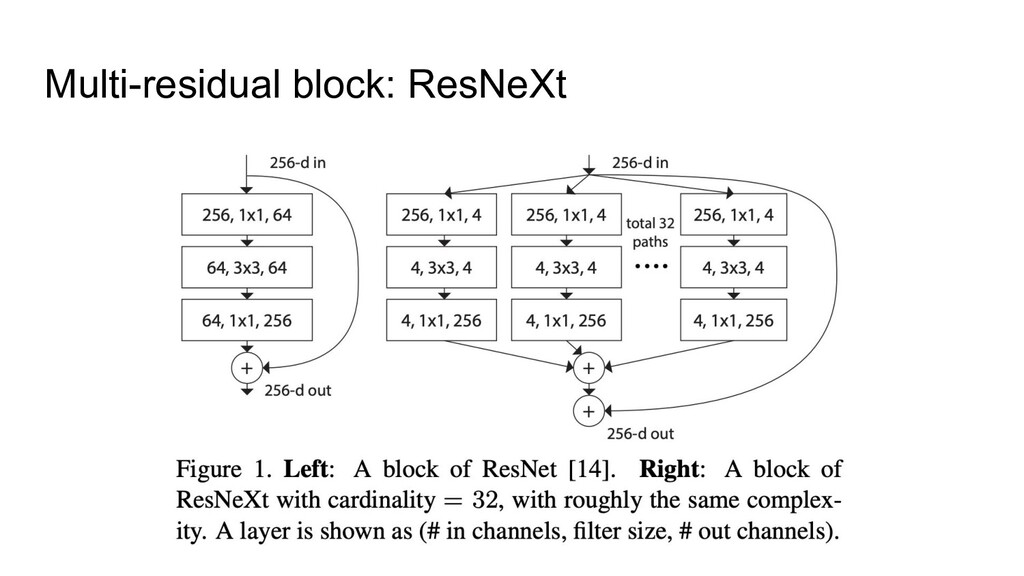
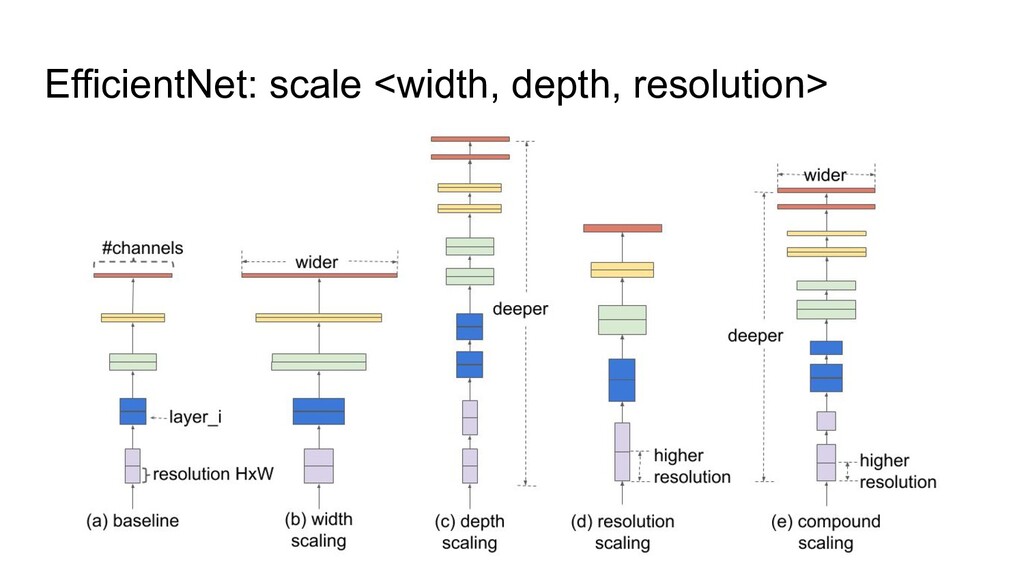
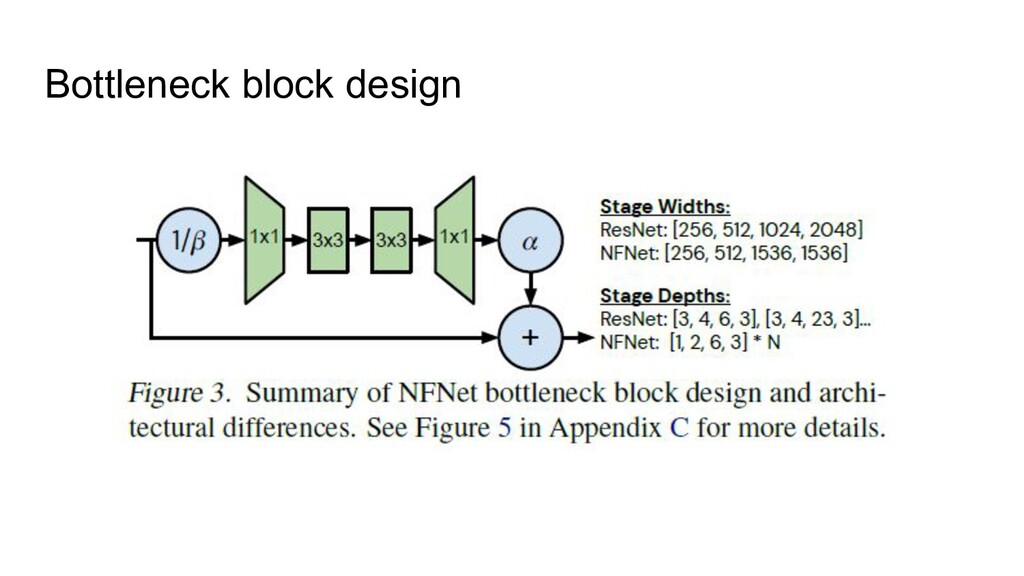
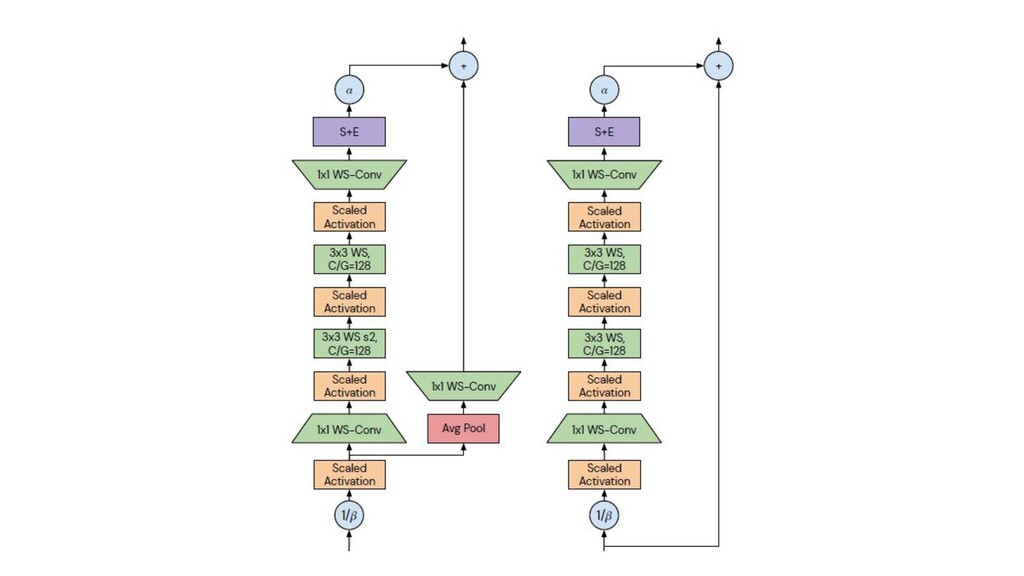
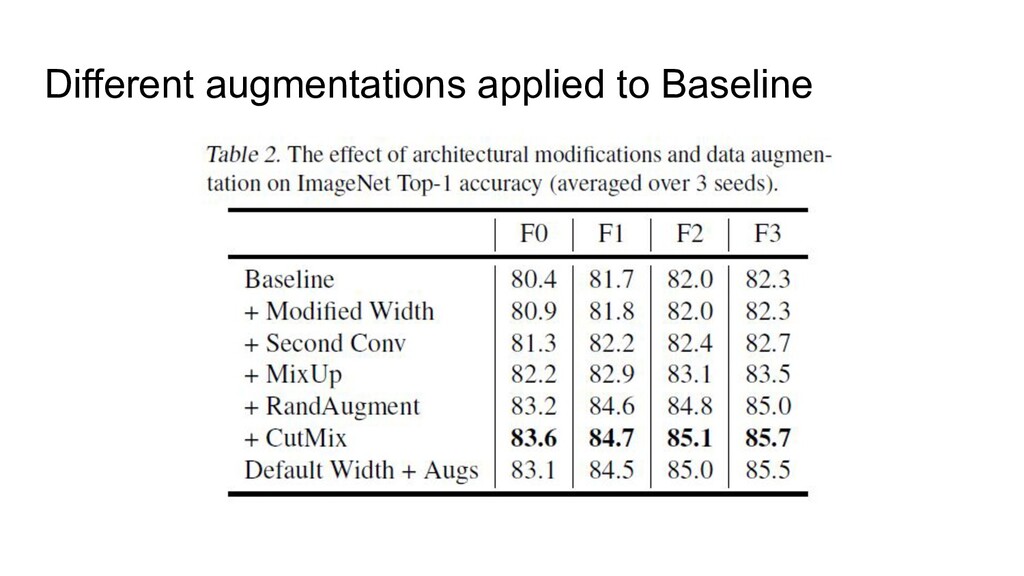
as a baseline • Fixed group width (specific for the ResNeXt architecture) • Depth Scaling pattern was changed (from very specific to very simple) • Width pattern was changed too
with • PyTorch with weights • Yet another PyTorch • Very good PyTorch (clear code) • Adaptive Gradient Clipping example • Broken Keras example (could be a good entry point) • Raw TF implementation
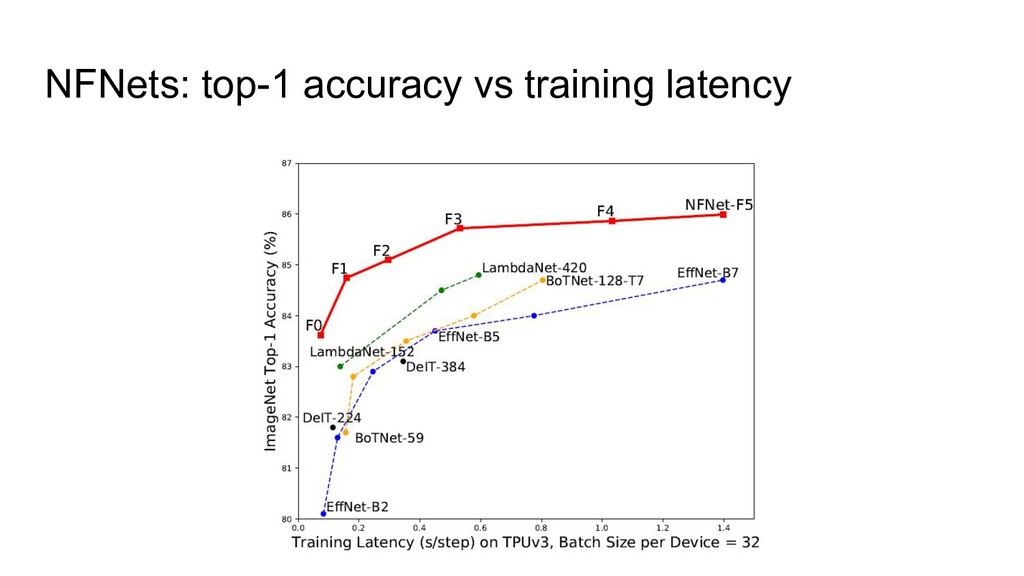
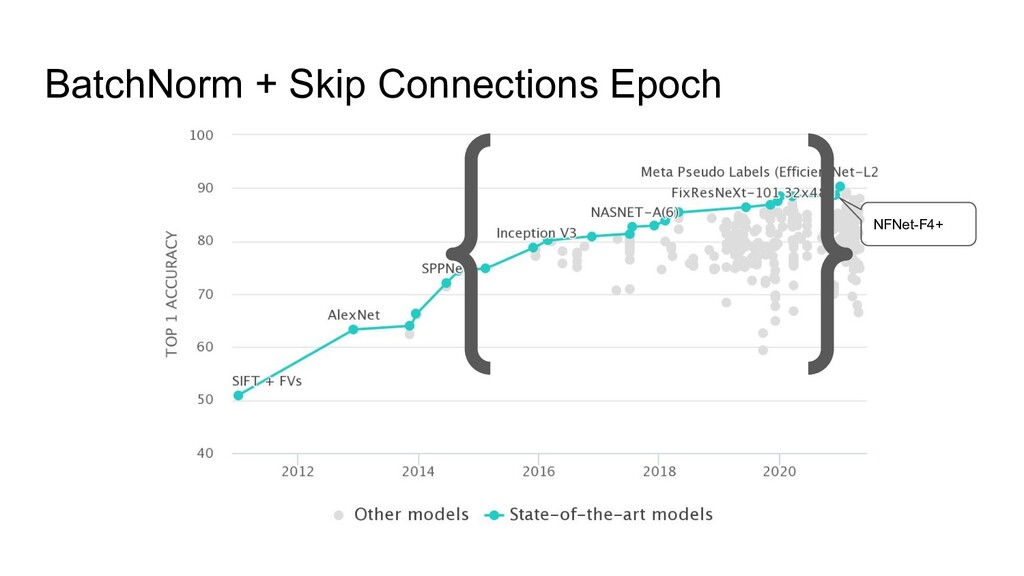
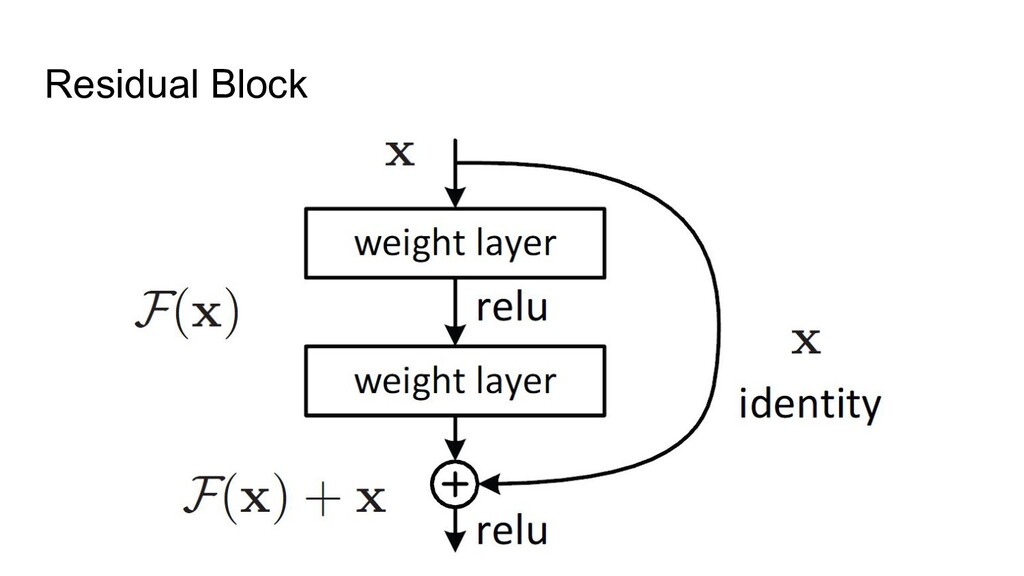
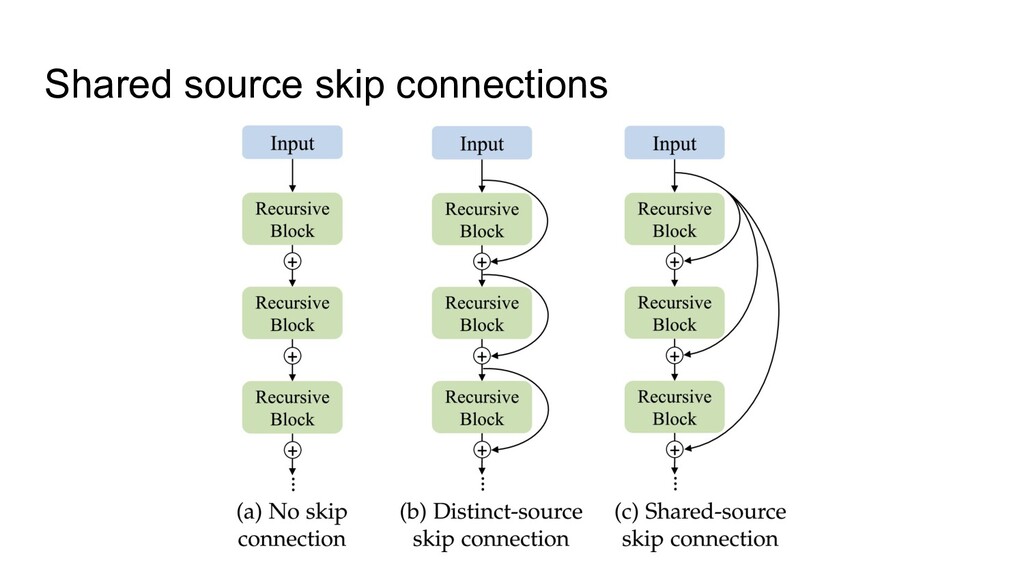
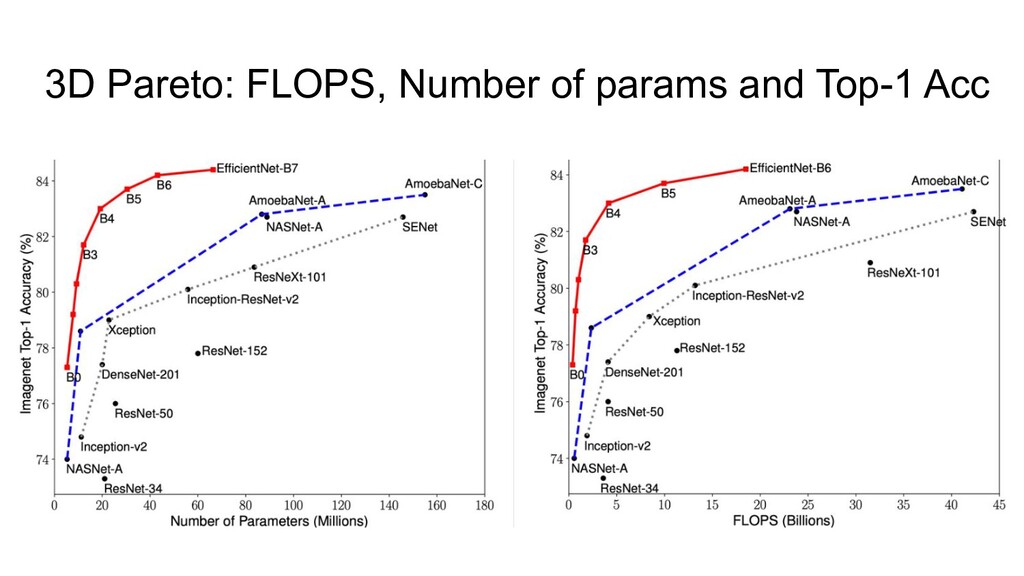
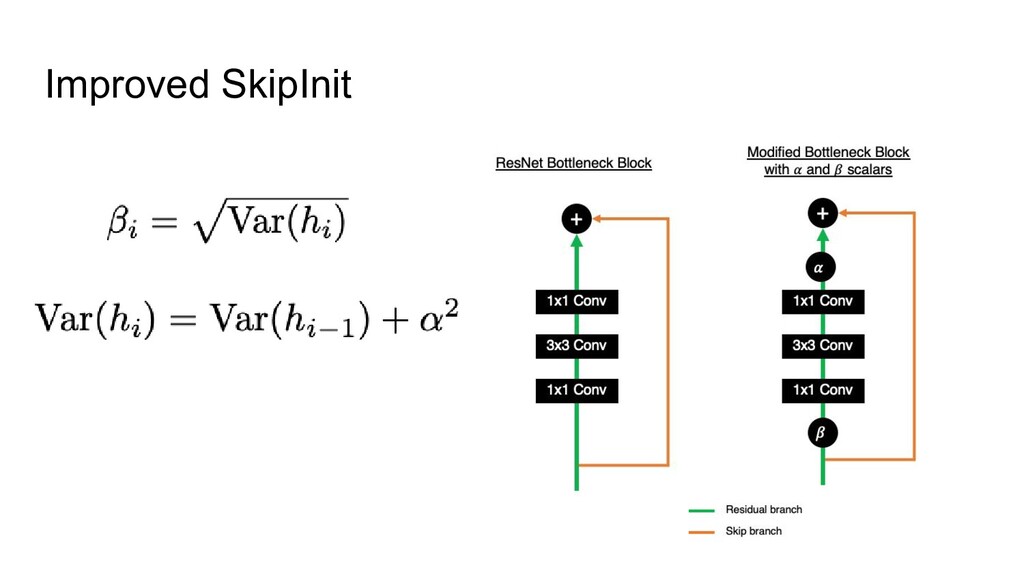
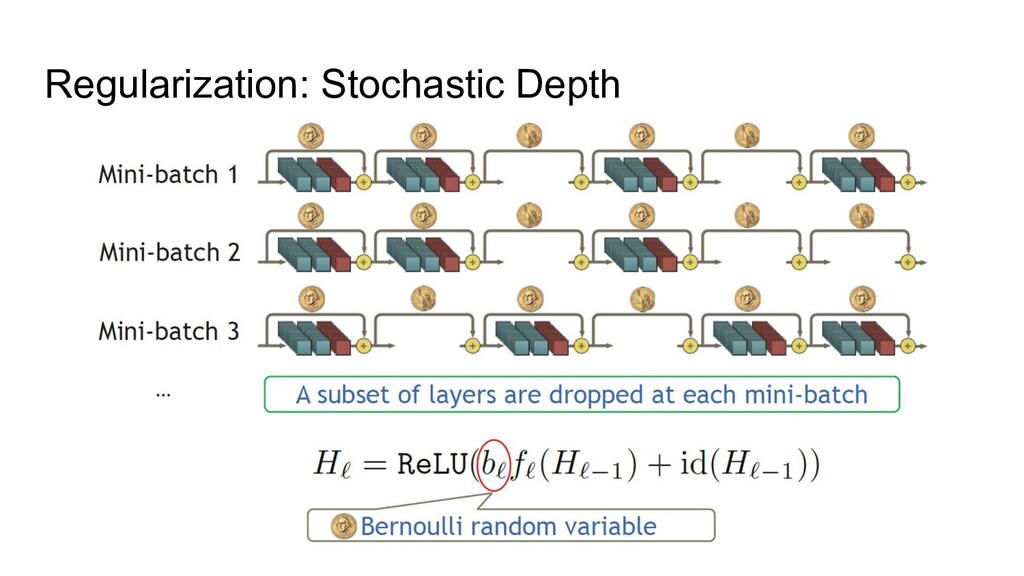
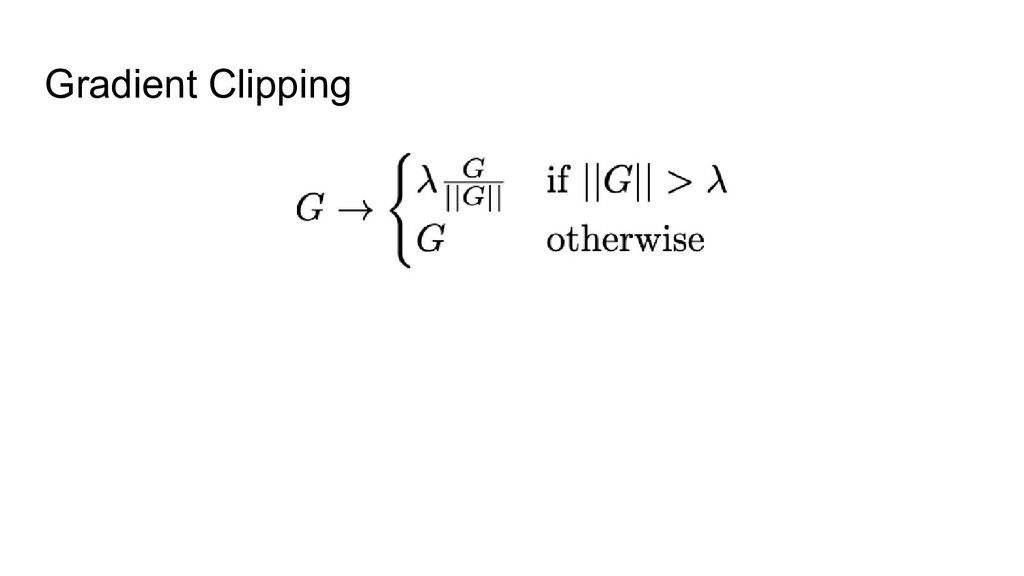
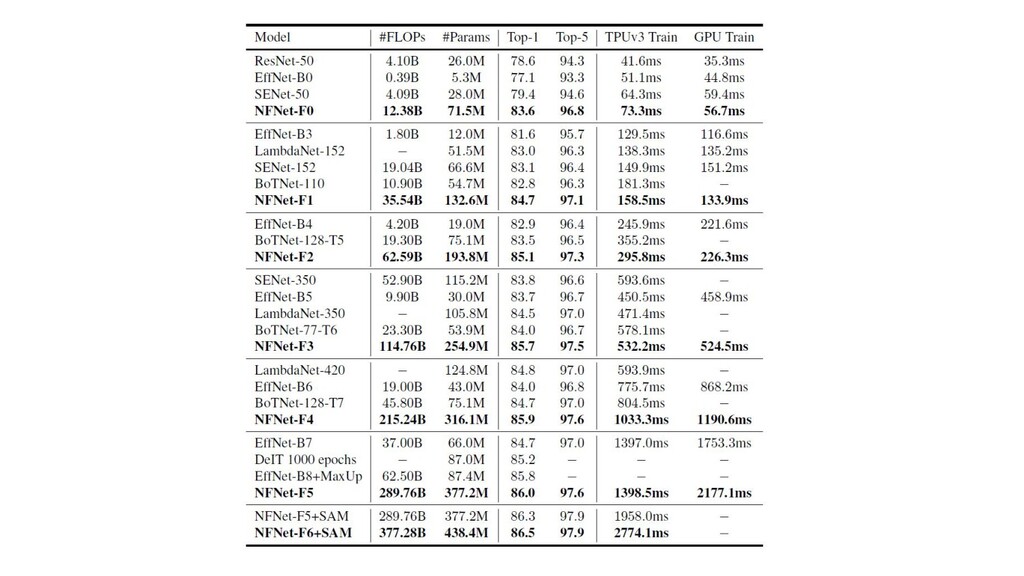
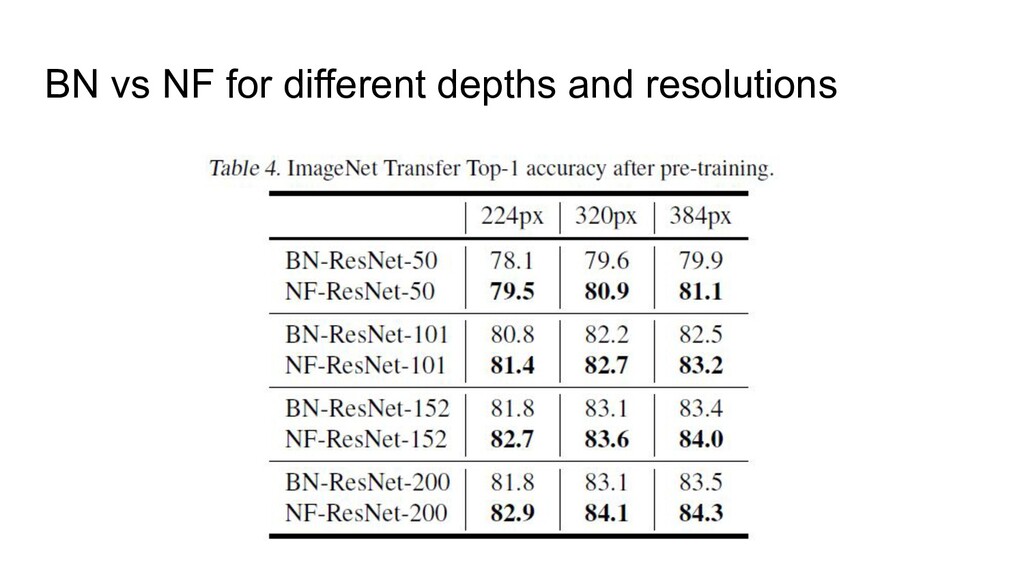
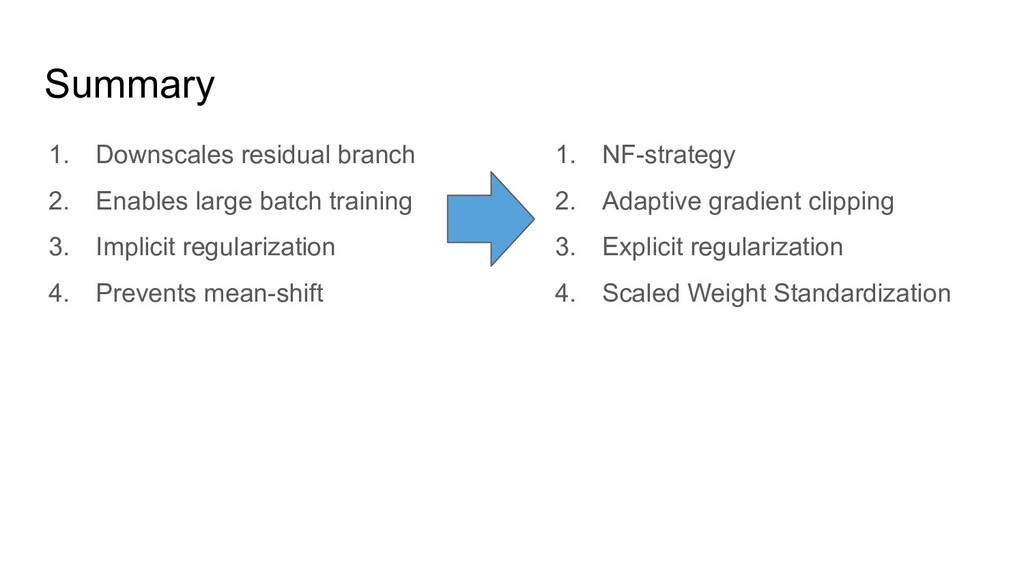
3. Implicit regularization 4. Prevents mean-shift 1. NF-strategy 2. Adaptive gradient clipping 3. Explicit regularization 4. Scaled Weight Standardization • NFNets were new SOTA during a few months • NFResNet >= BNResNet • NFNet training >>> EfficientNet training
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}