language for data science 2. No modern data science without Neural Networks 3. All deep learning frameworks are good enough at image recognition 4. Convolutional neural networks (CNNs) are the gold standard for image recognition 5. Training, Transfer Learning, and Inference are now available for different CNN architectures on Kotlin with KotlinDL library
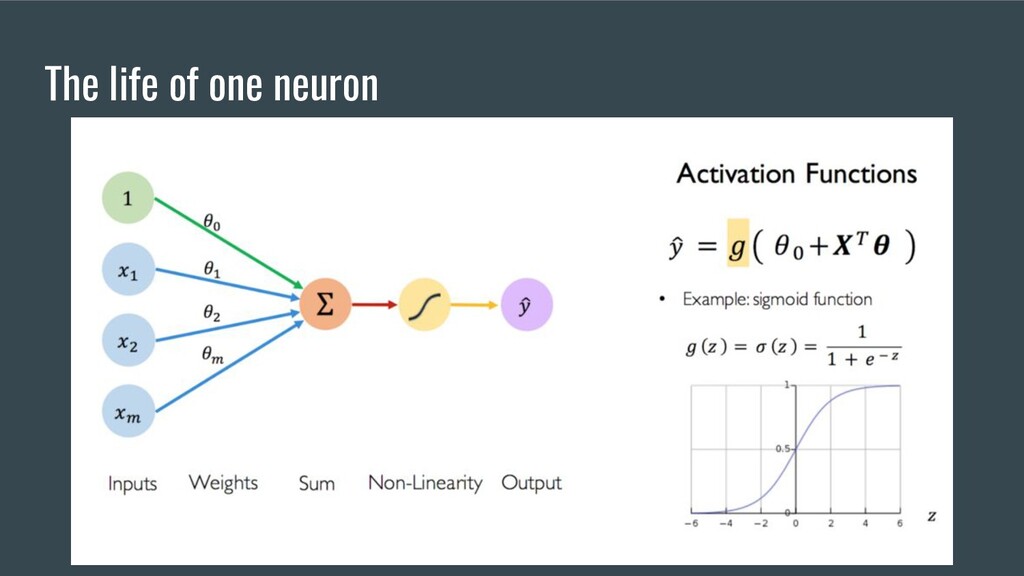
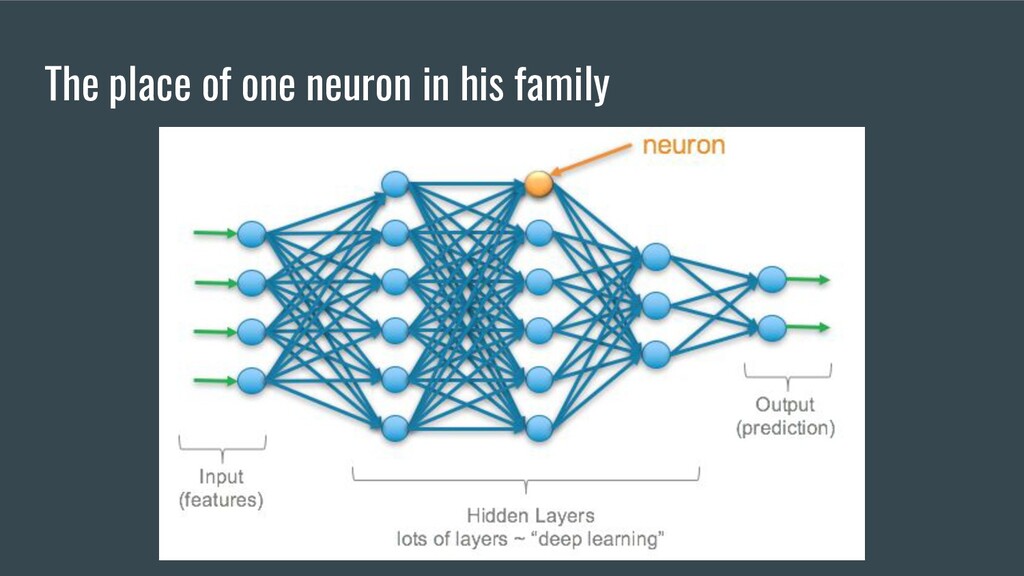
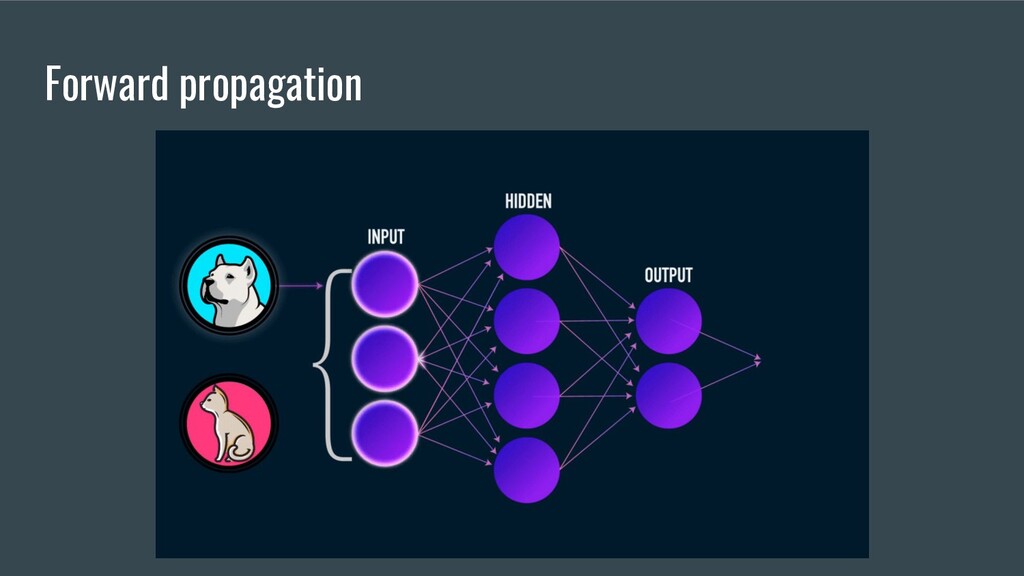
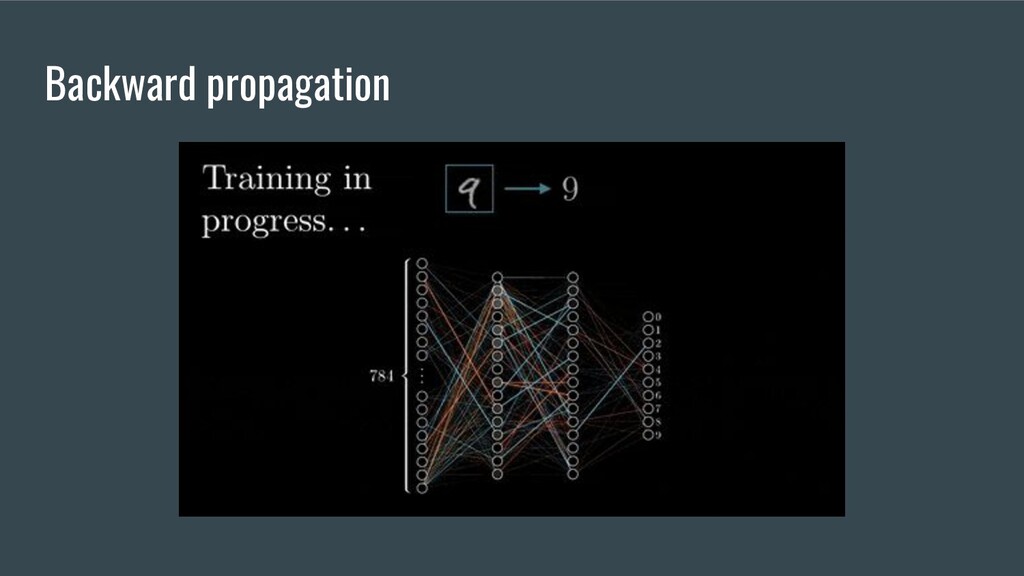
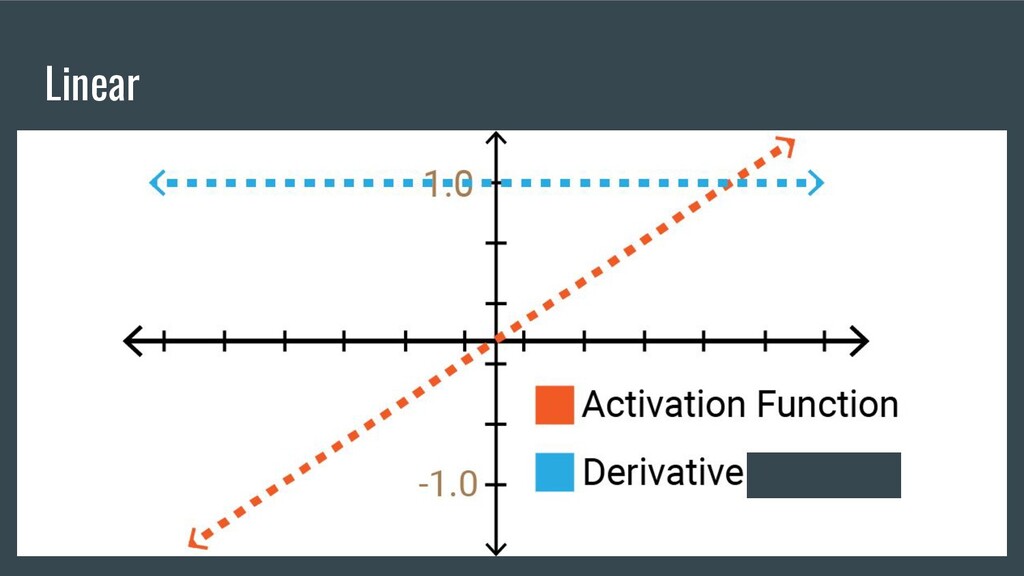
and optional math knowledge 4. Primitives or building blocks a. Activation Functions b. Loss Functions c. Initializers d. Optimizers e. Layers 5. 5 Major Scientific breakthroughs in DL 6. Kotlin DL Demo
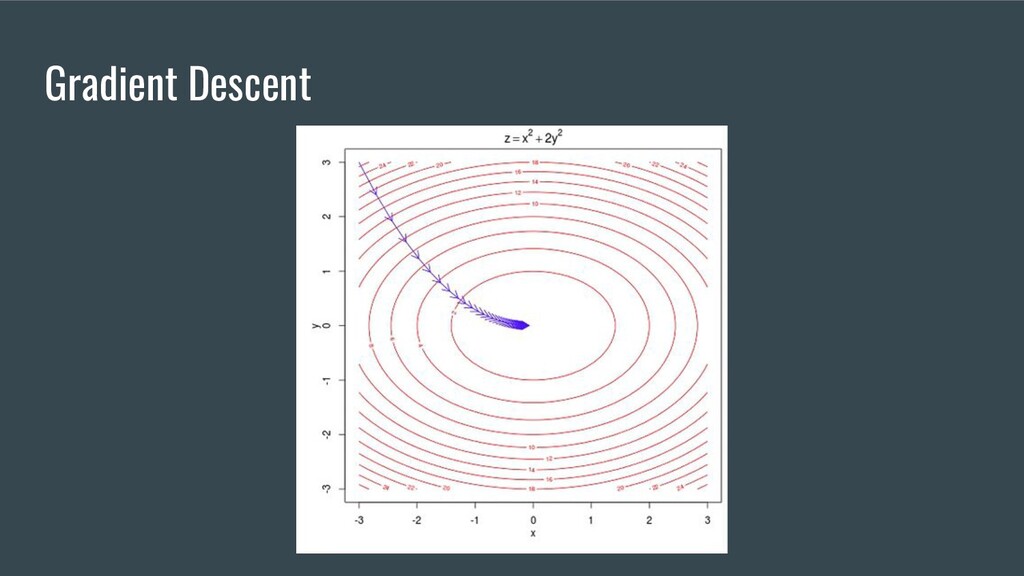
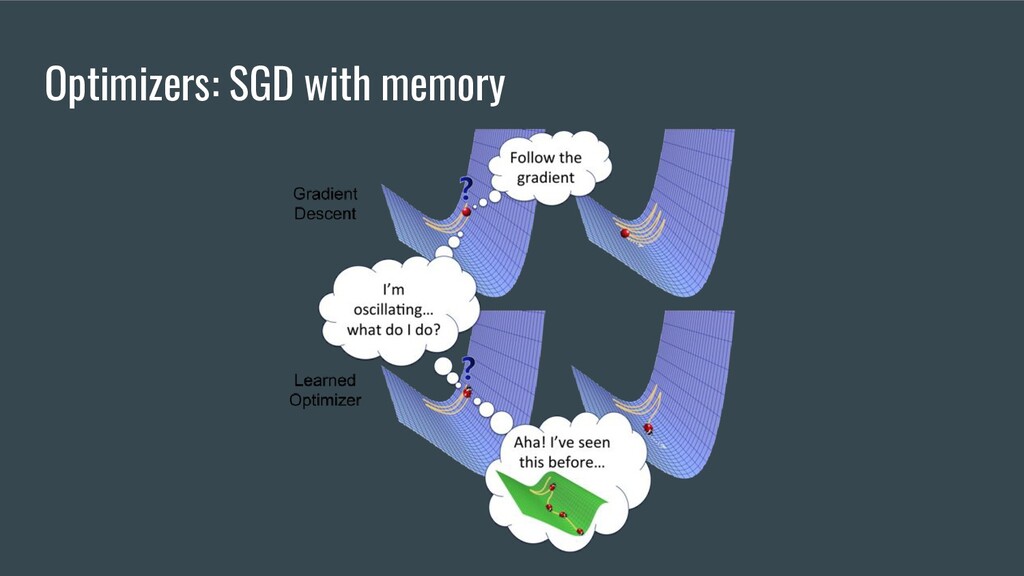
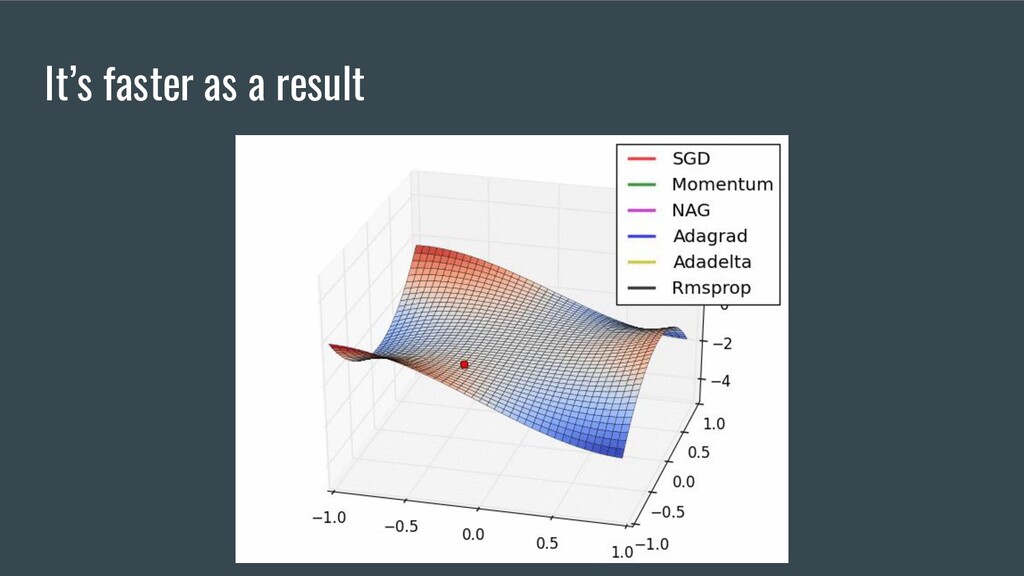
logarithms; • Linear Algebra: vectors, vector space; • Linear Algebra: inverse and transpose matrices, matrix decomposition, eigenvectors, Kronecker-Capelli’s theorem; • Mathematical Analysis: continuous, monotonous, differentiable functions; • Mathematical Analysis: derivative, partial derivative, Jacobian; • Methods of one-dimensional and multidimensional optimization; • Gradient Descent and all its variations; • Optimization methods and convex analysis will not be superfluous in your luggage
metric • Should be differentiable • Not every metric could be a loss function ( metrics could have not the derivative ) • Loss function could be very complex • Are different for regression and classification tasks
Regression ML 2. Limited number of layers is supported 3. Tiny number of preprocessing methods 4. Only VGG-like architectures are supported 5. No Android support
Dataset API 3. GPU settings 4. Maven Central Availability 5. Functional API 6. New layers: BatchNorm, Add, Concatenate, DepthwiseConv2d 7. Regularization for layers will be added 8. New metrics framework 9. Conversion to TFLite (for mobile devices) 10. ONNX support 11. ML algorithms
solve new problems) 2. ReLU and simplest and cheap non-linearity (could converge on new tasks) 3. Batch Normalization (could help convergence and give more acceleration) 4. Xe Initialization (solves vanishing/exploding gradient problem) 5. Adam optimizer (give more performance)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![An optimization problem [Loss Optimization Problem]](https://files.speakerdeck.com/presentations/0706e6077baf44c2ba104d295c174592/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
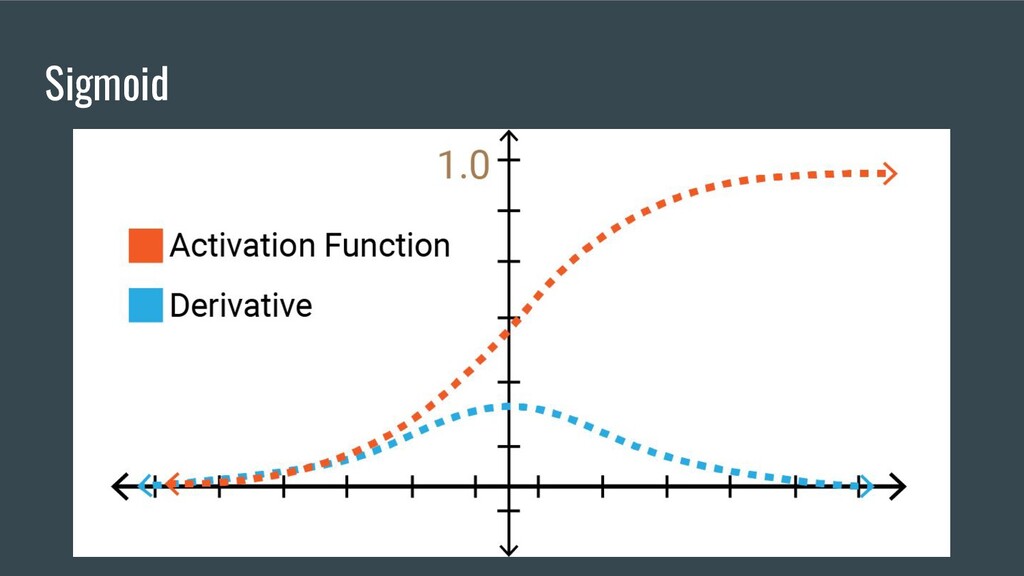{kind=link}
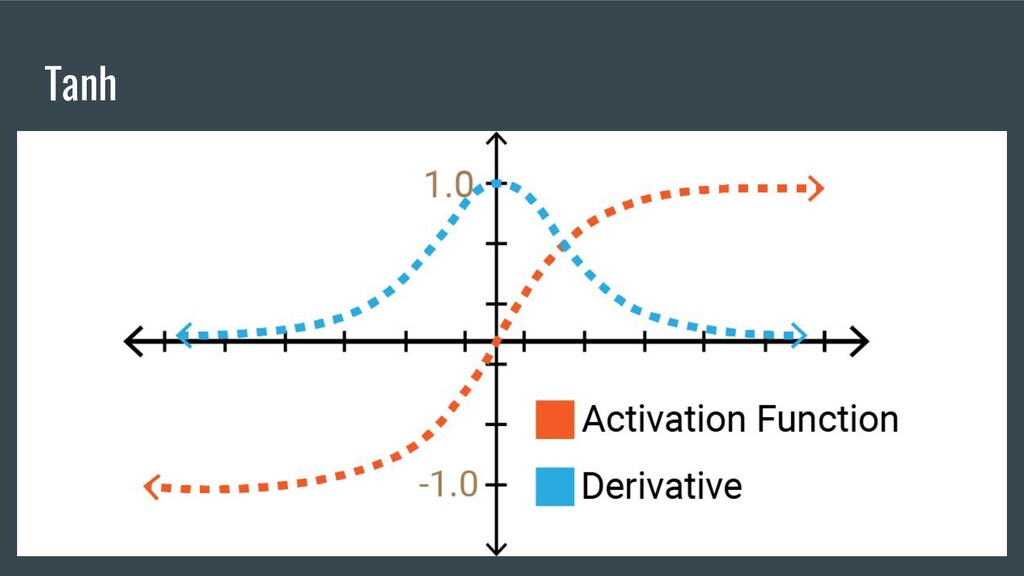{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
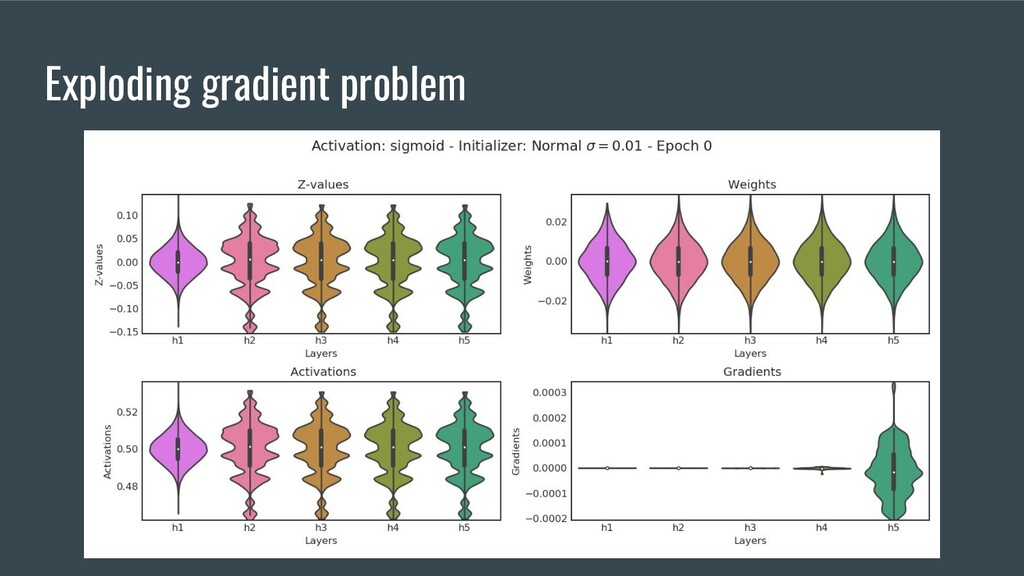{kind=link}
![Initializers • Zeros • Ones • Random [Uniform or Normal]](https://files.speakerdeck.com/presentations/0706e6077baf44c2ba104d295c174592/slide_46.jpg){kind=link}
{kind=link}
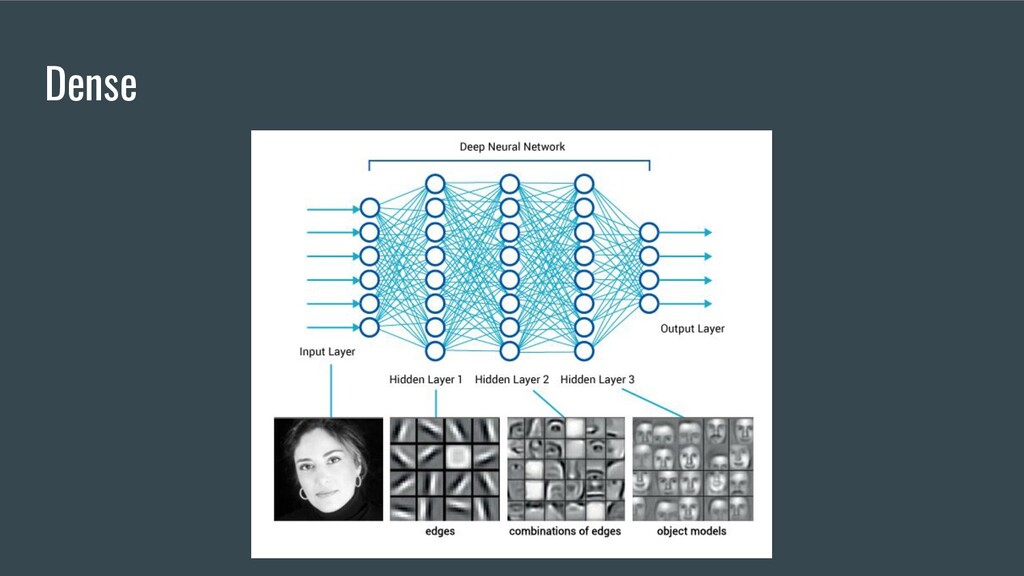{kind=link}
{kind=link}
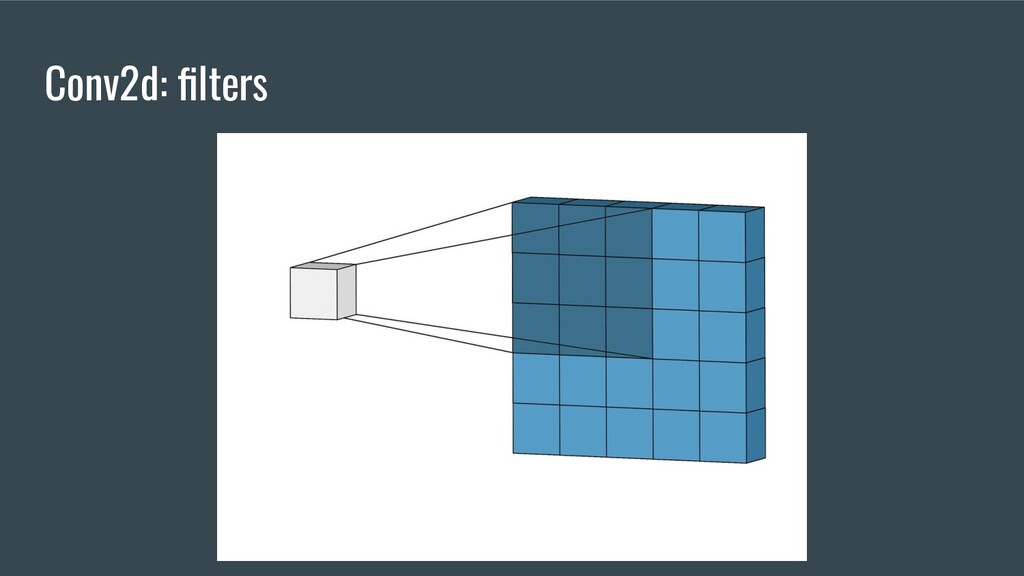{kind=link}
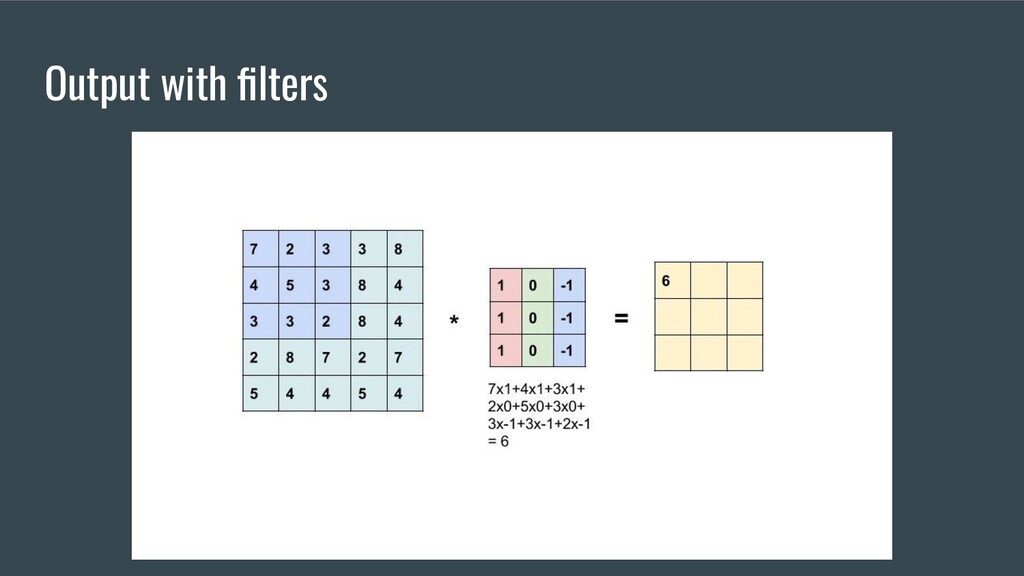{kind=link}
{kind=link}
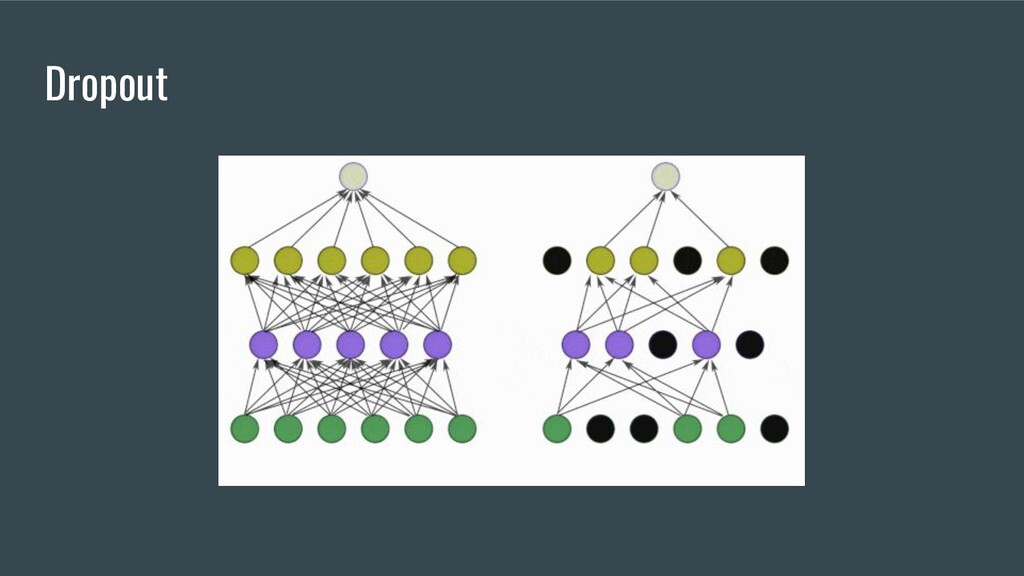{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}