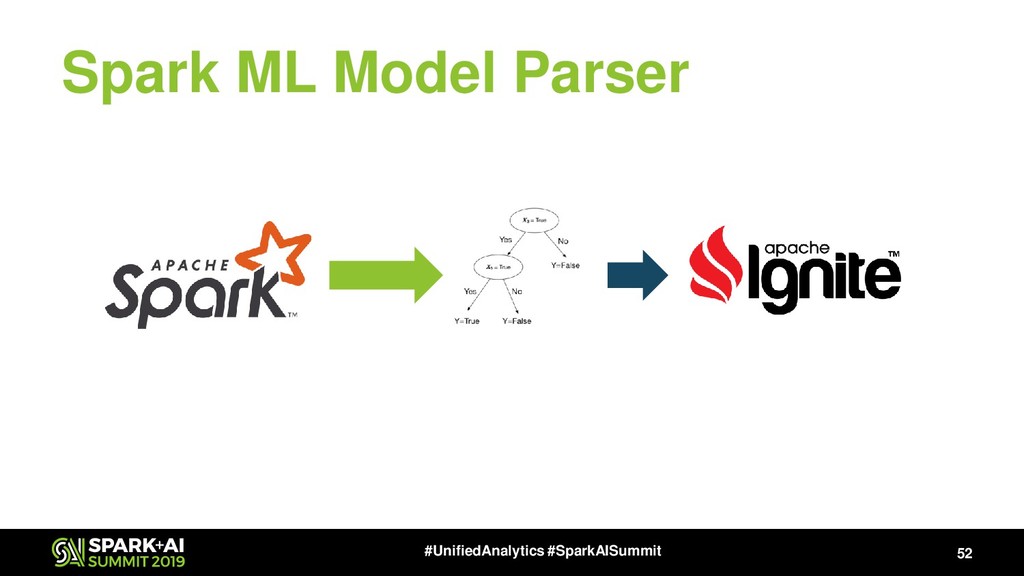
The current implementation of ML algorithms in Spark has several disadvantages associated with the transition from standard Spark SQL types to ML-specific types, a low level of algorithms' adaptation to distributed computing, a relatively slow speed of adding new algorithms to the current library.
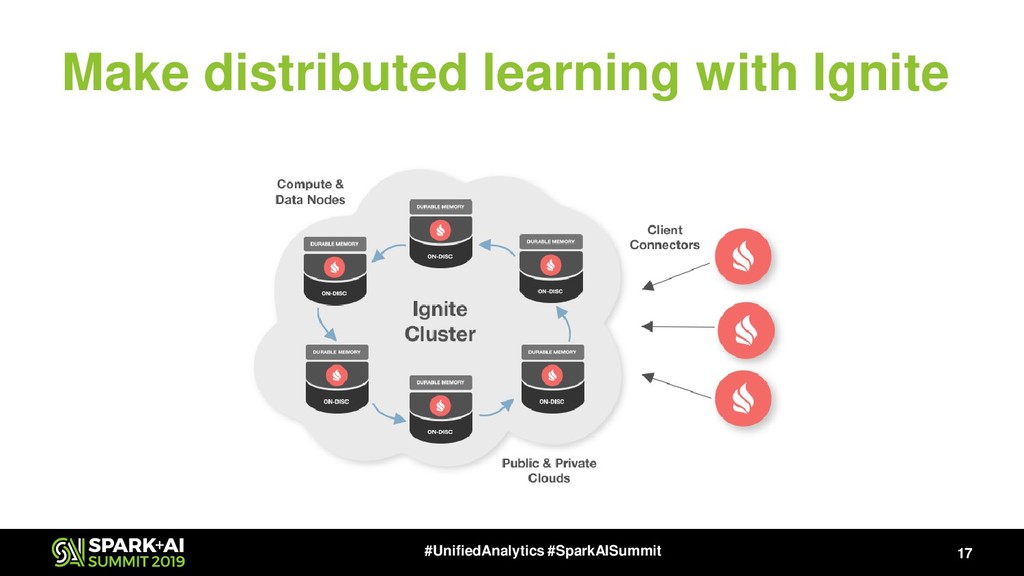
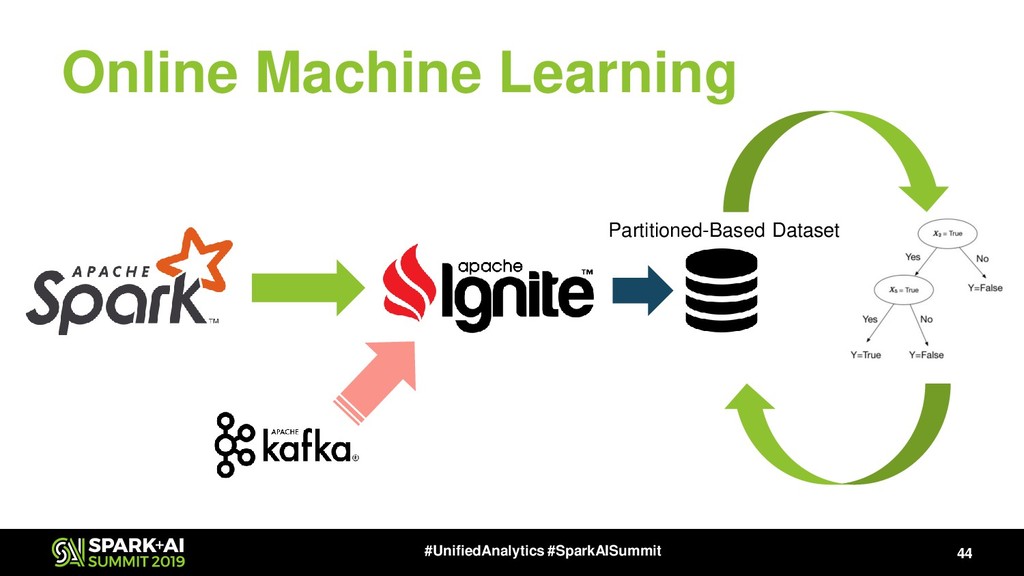
Also, Spark ML doesn't support online-learning by nature for all algorithms, stacking, boosting and a bunch of approximate ML algorithms that gives a significant speedup in many cases. The Apache Ignite could work closely with Apache Spark due to exellent Ignite RDD/Ignite DataFrame implementation (see
https://ignite.apache.org/use-cases/spark/shared-memory-layer.html).
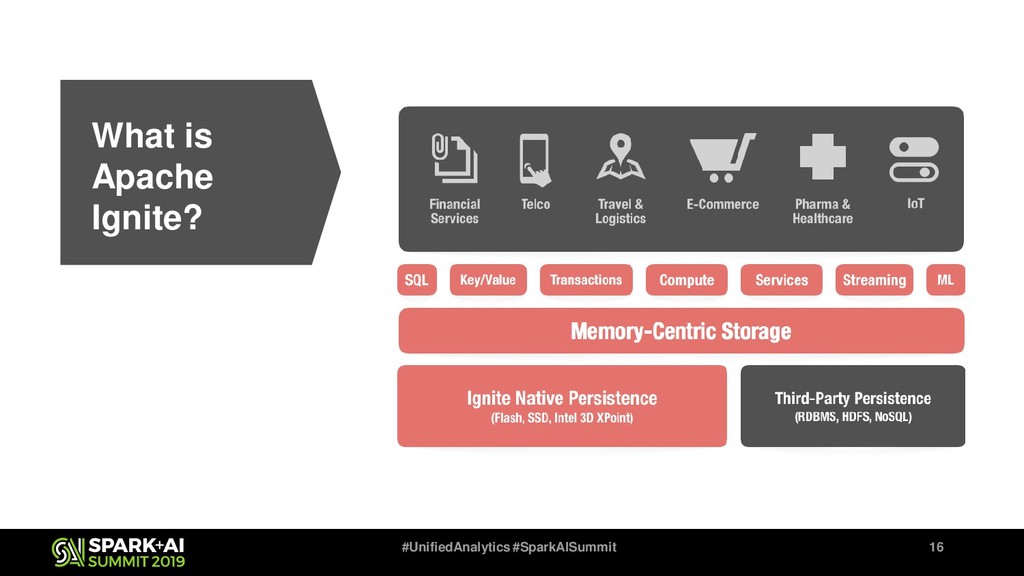
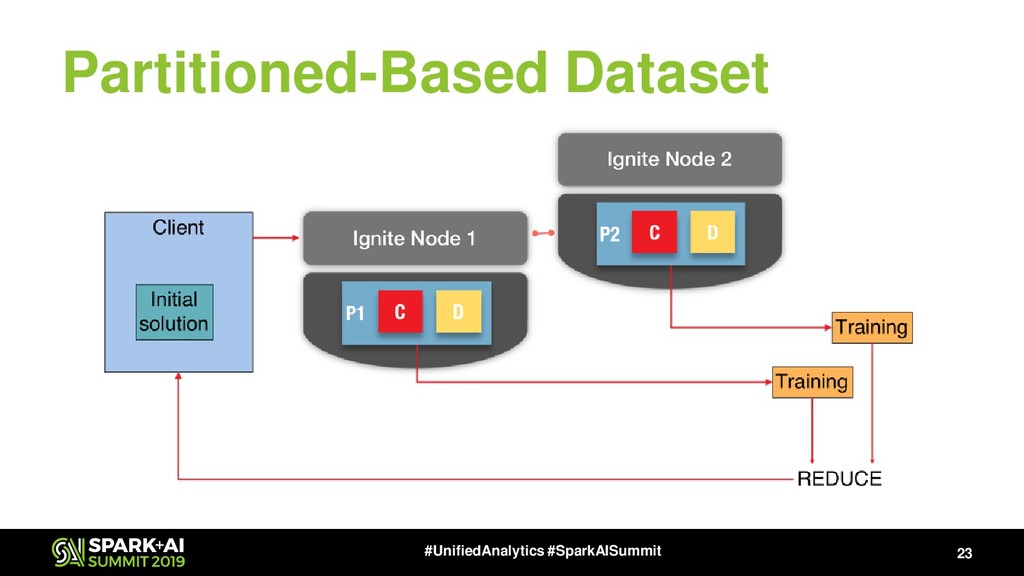
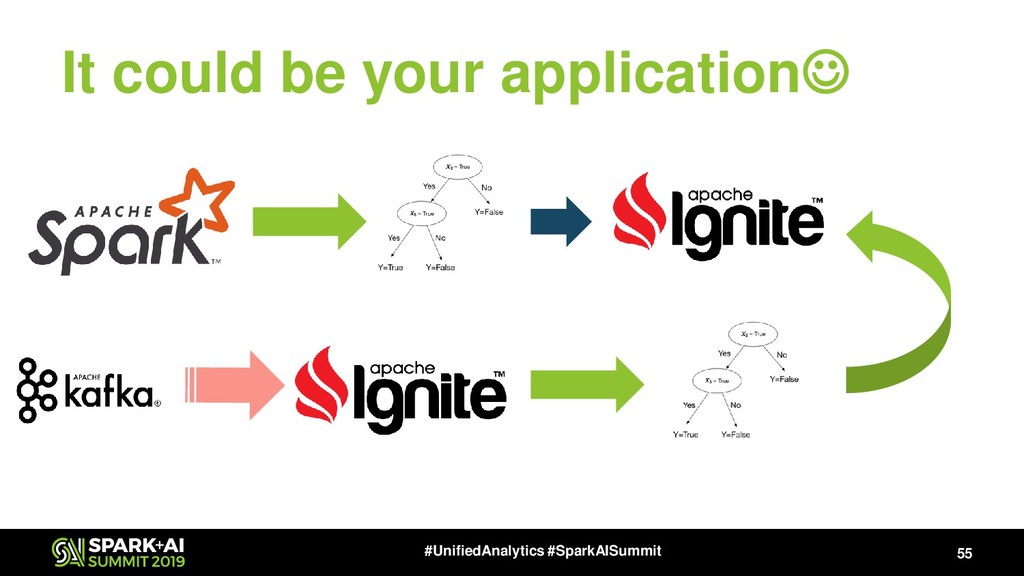
Also Apache Ignite has Ignite ML module that includes a lot of distributed ML algorithms, NLP package (will be available in next release, 2.8), the bunch of approximate ML algorithms, simple integration with TensorFlow via TensorFlow Ignite Dataset (currently, this is a part of TF.contrib package) and also each algorithm supports the model updating that gives us ability to make online-learning not only for KMeans and LinReg.
We suggest to use Apache Ignite ML module to speedup your ML training and use Spark + Ignite as backend for distributed TensorFlow calculations. You will see live demos of ML pipeline building with Apache Ignite ML module, Apache Spark, Apache Kafka, TensorFlow and more.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22 #UnifiedAnalytics #SparkAISummit public class SparkCacheStore implements CacheStore<Integer, Object[]>, Serializable](https://files.speakerdeck.com/presentations/6971bafd48bb4df8ab8e7ffcd3007906/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
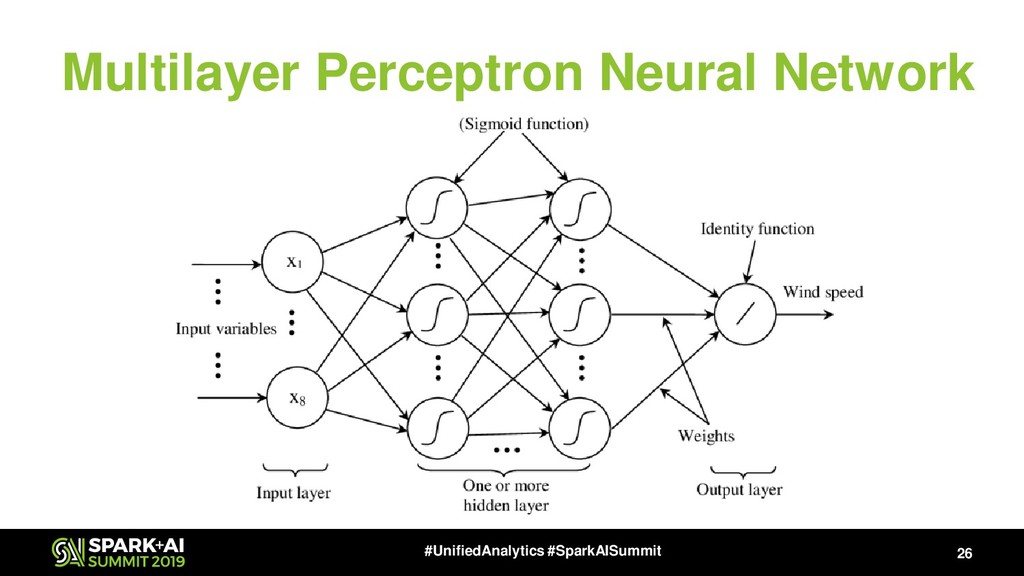{kind=link}
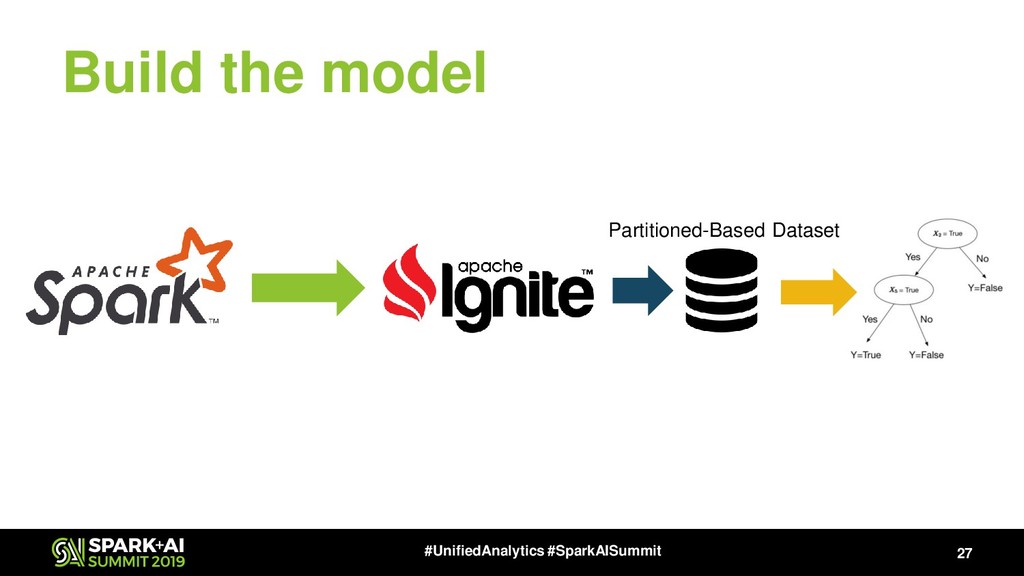{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
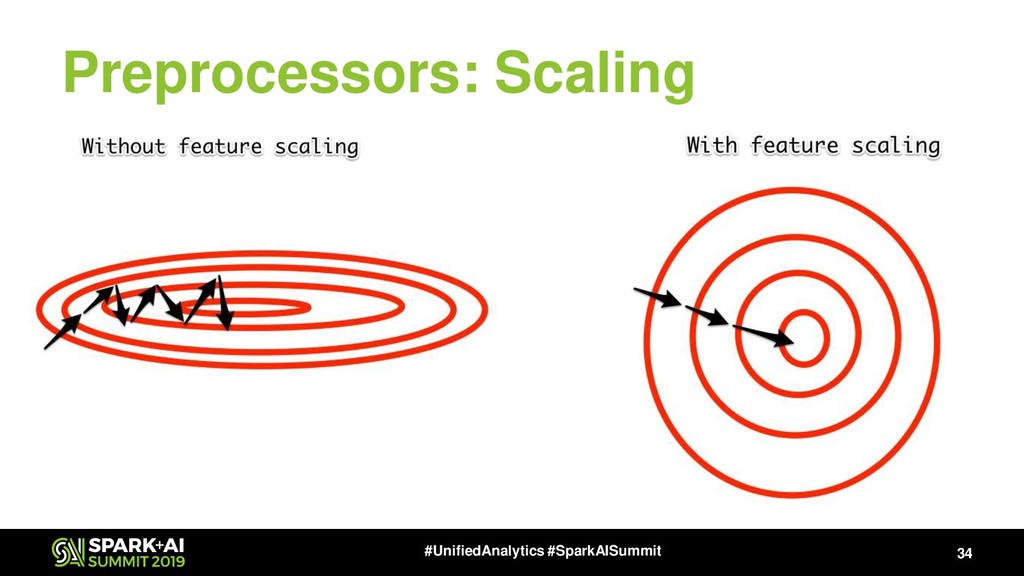{kind=link}
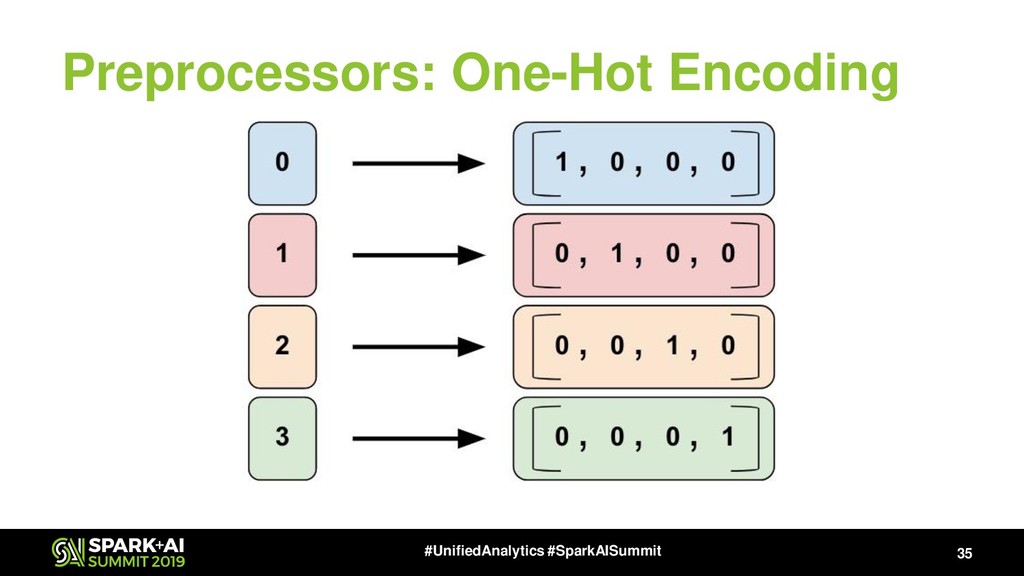{kind=link}
{kind=link}
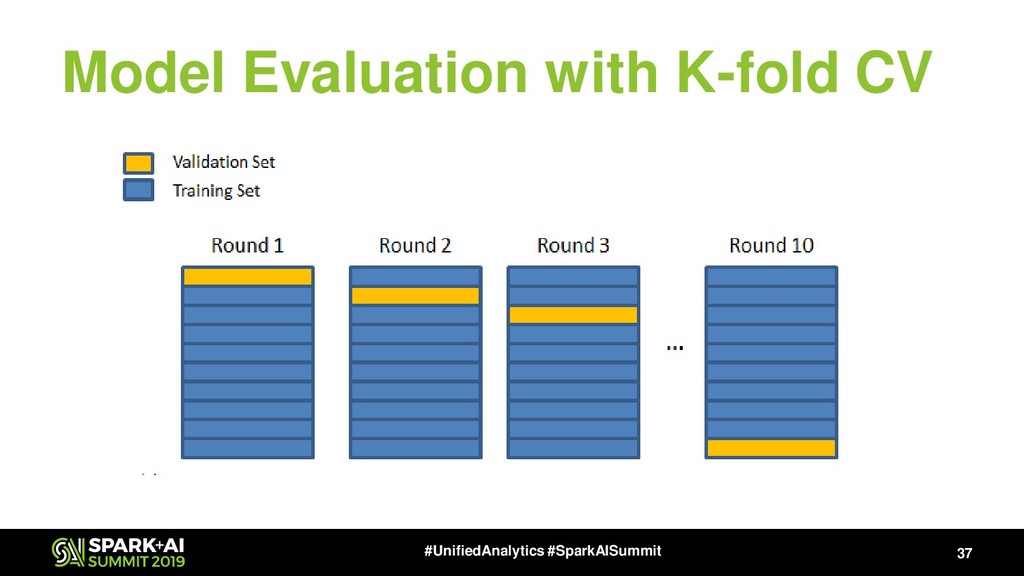{kind=link}
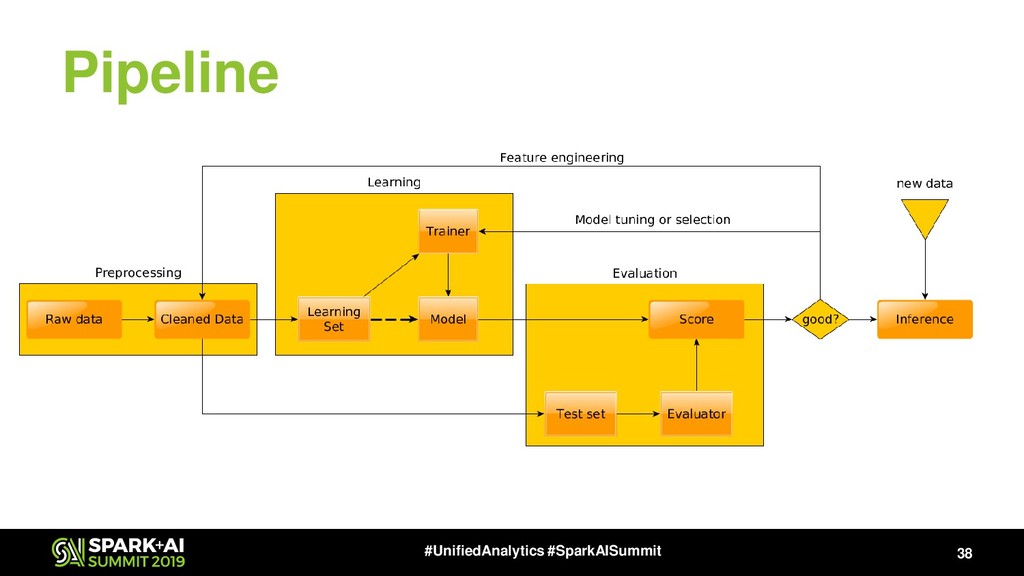{kind=link}
{kind=link}
{kind=link}
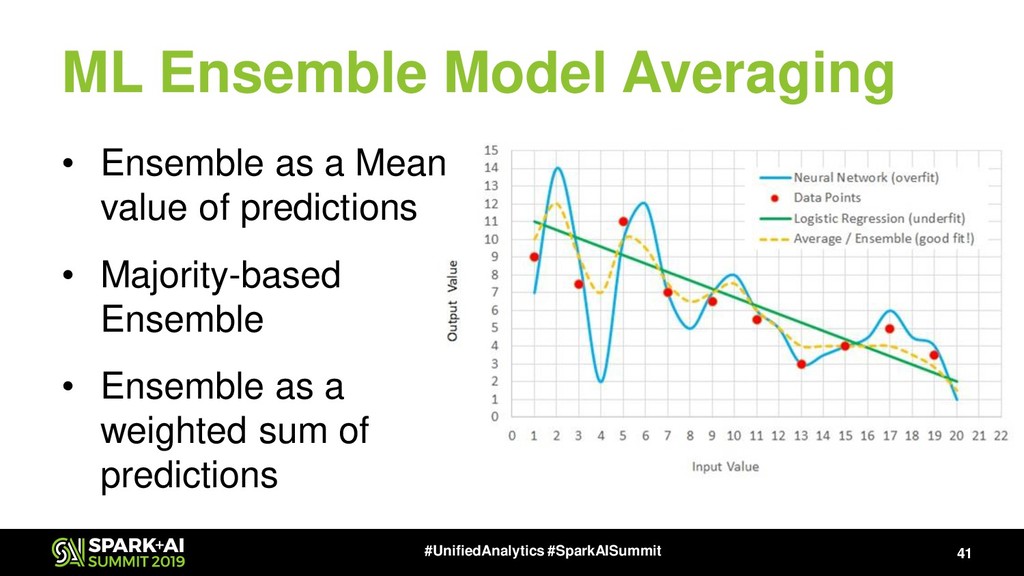{kind=link}
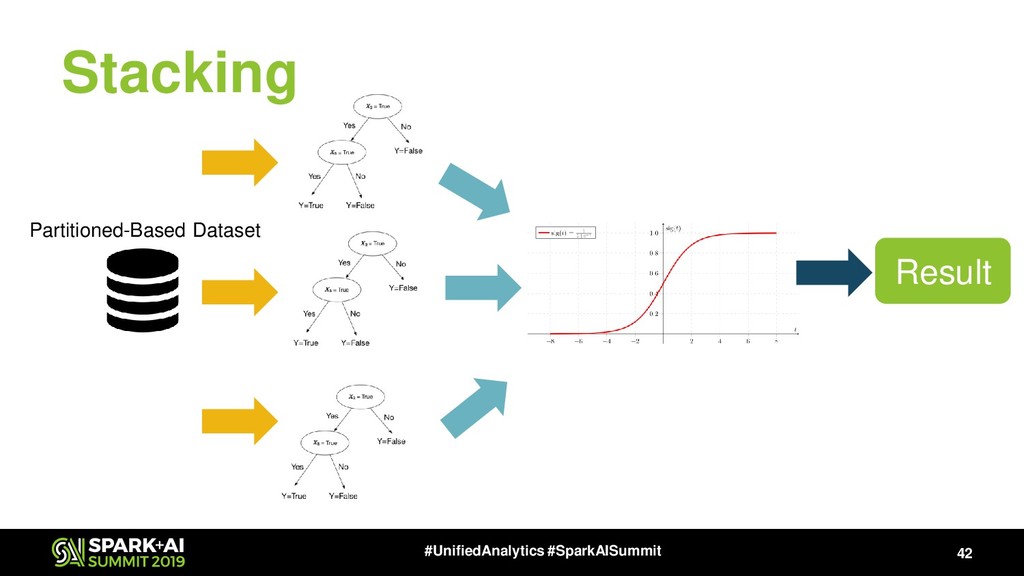{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}