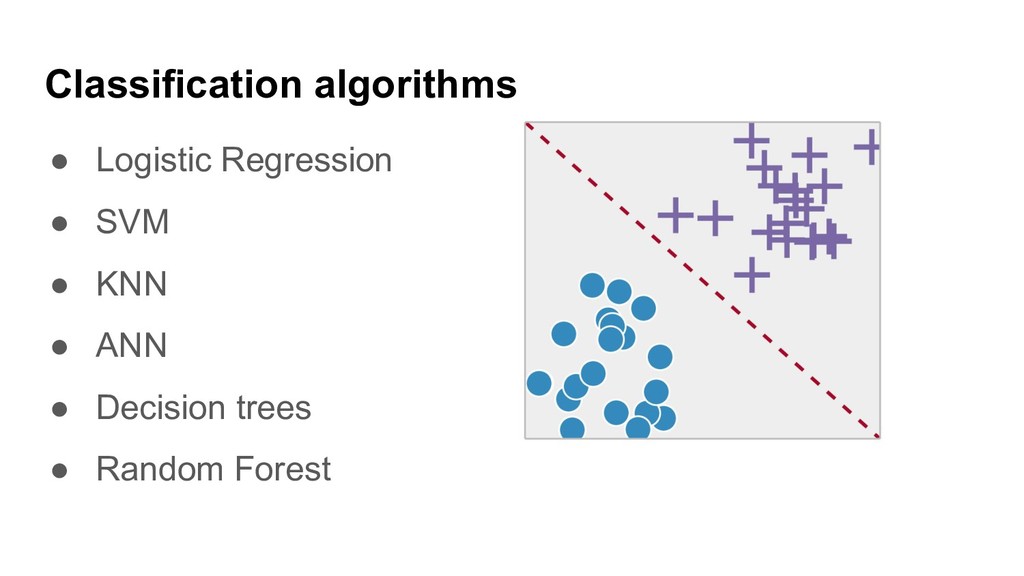
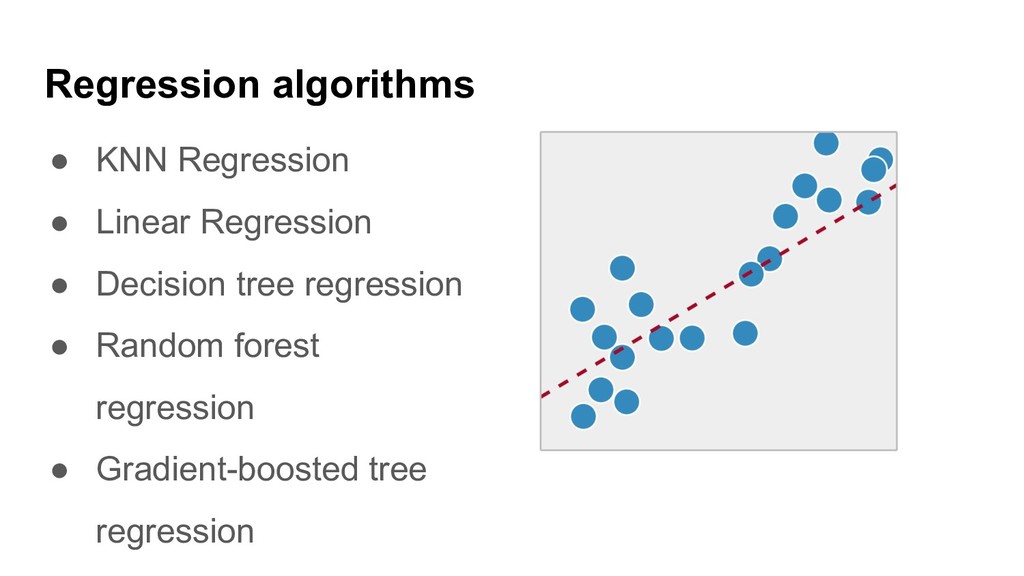
Ensembles of ML algorithms and Distributed Online Machine Learning with Apache Ignite
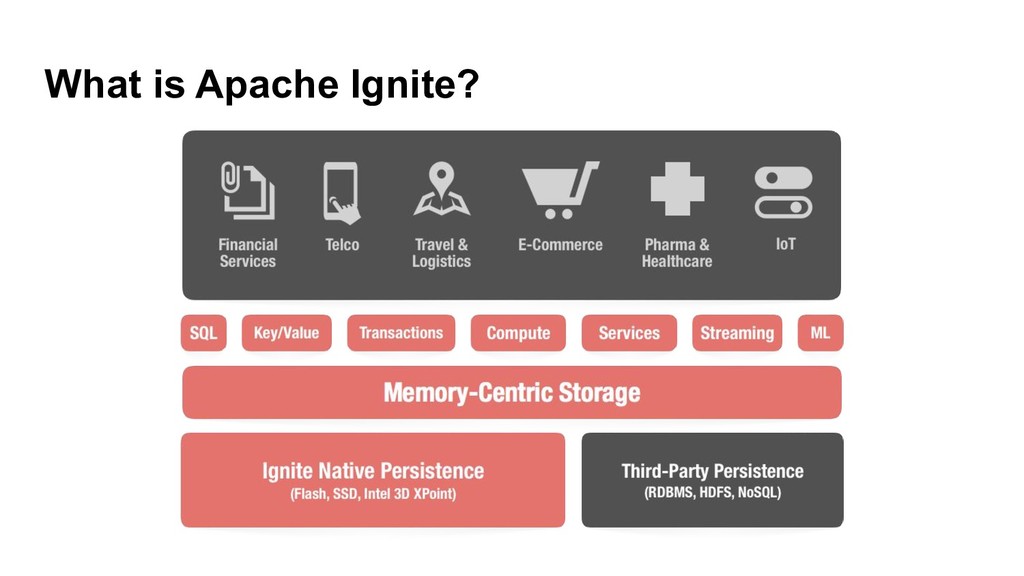
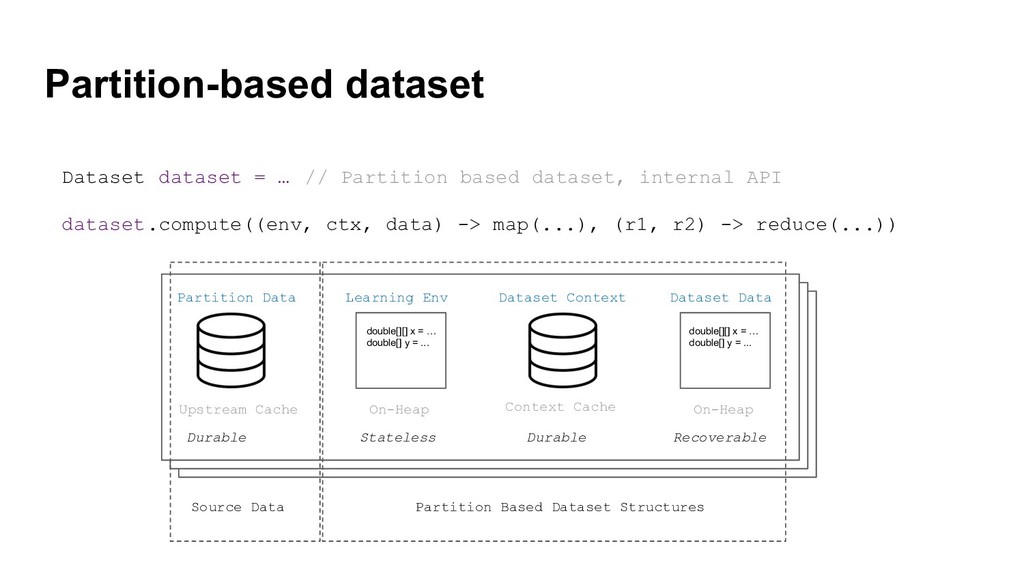
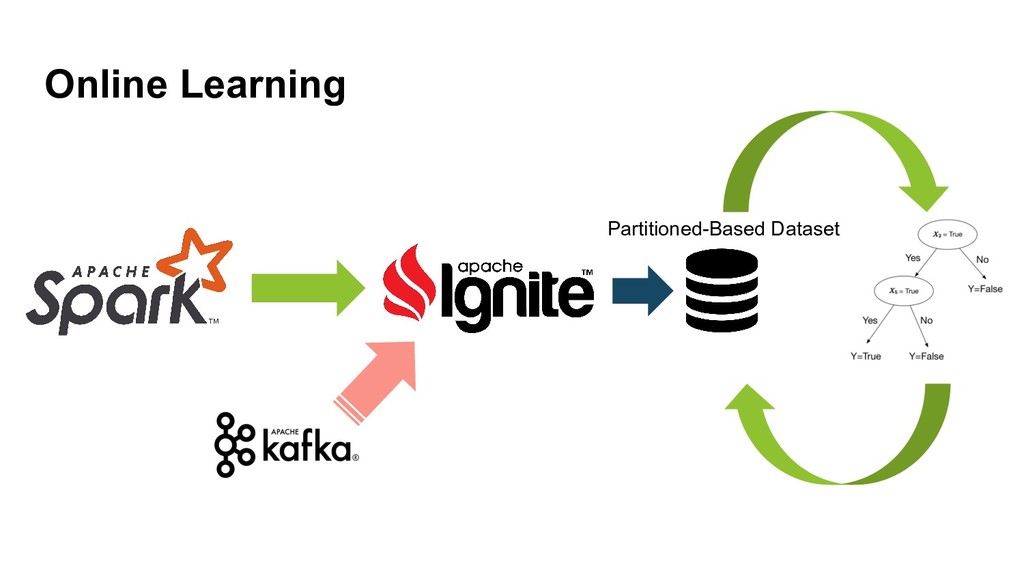
Currently, Apache Ignite has ML module that includes a lot of distributed ML algorithms, the bunch of approximate ML algorithms, easy integration with TensorFlow via TensorFlow Ignite Dataset (currently, this is a part of TF.contrib package) and also each algorithm supports the model updating that gives us ability to make online-learning not only for KMeans and LinReg unlike Apache Spark.
We suggest to use Apache Ignite ML module to speedup your ML training and use Ignite as backend for distributed TensorFlow calculations.
Also this talk lights issues of distributed machine learning algorithm implementations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Model example [Linear Regression]](https://files.speakerdeck.com/presentations/e39387513ee14132ac7594f8f4c4b42d/slide_7.jpg){kind=link}
![Model example [Linear Regression] Loss Function](https://files.speakerdeck.com/presentations/e39387513ee14132ac7594f8f4c4b42d/slide_8.jpg){kind=link}
![Model example [Decision Tree]](https://files.speakerdeck.com/presentations/e39387513ee14132ac7594f8f4c4b42d/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
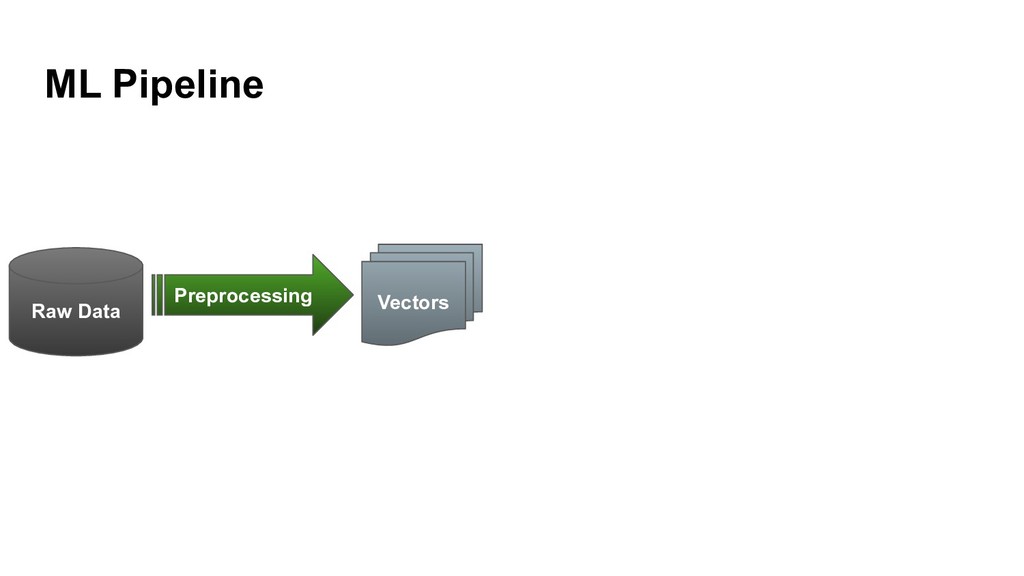{kind=link}
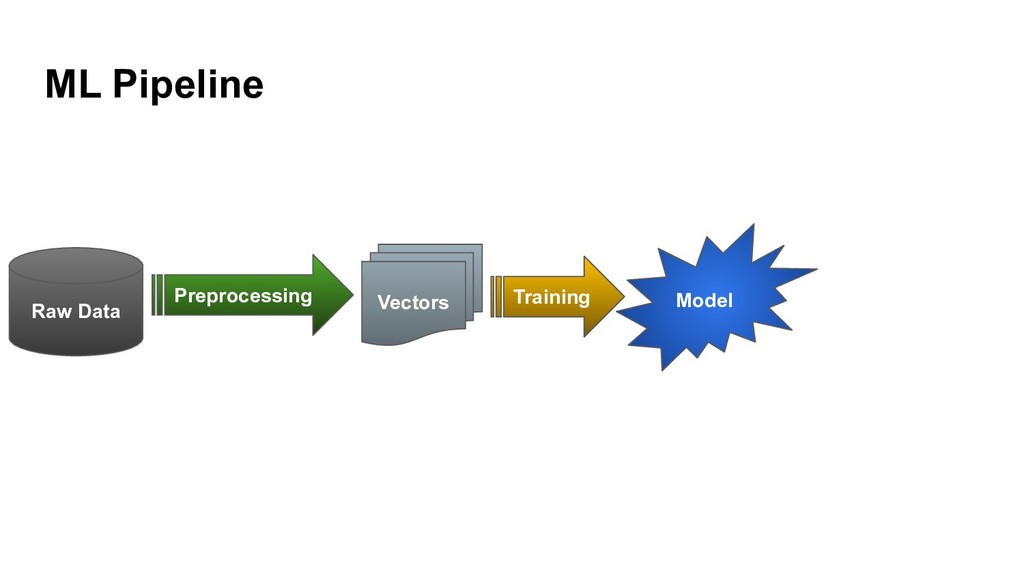{kind=link}
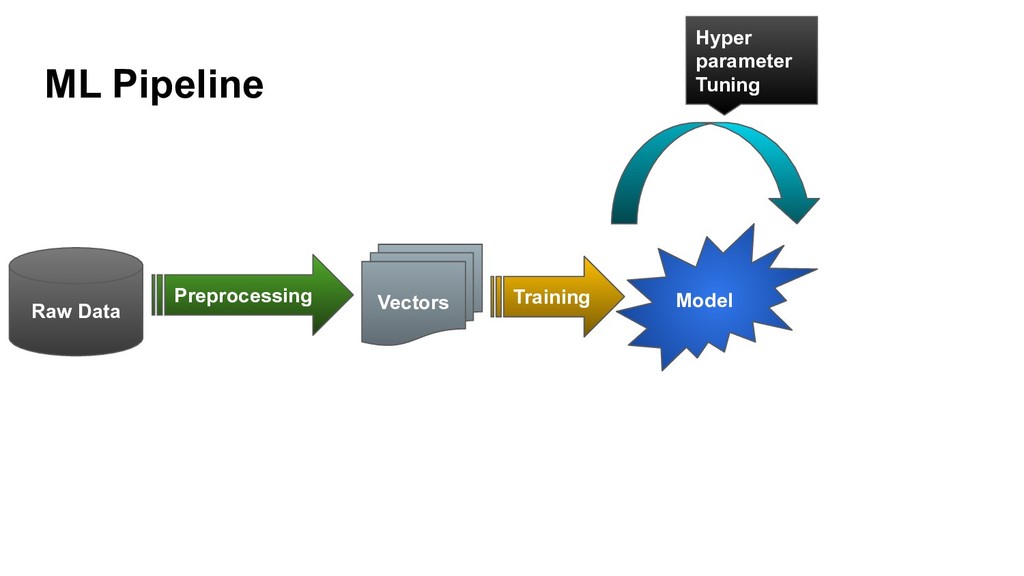{kind=link}
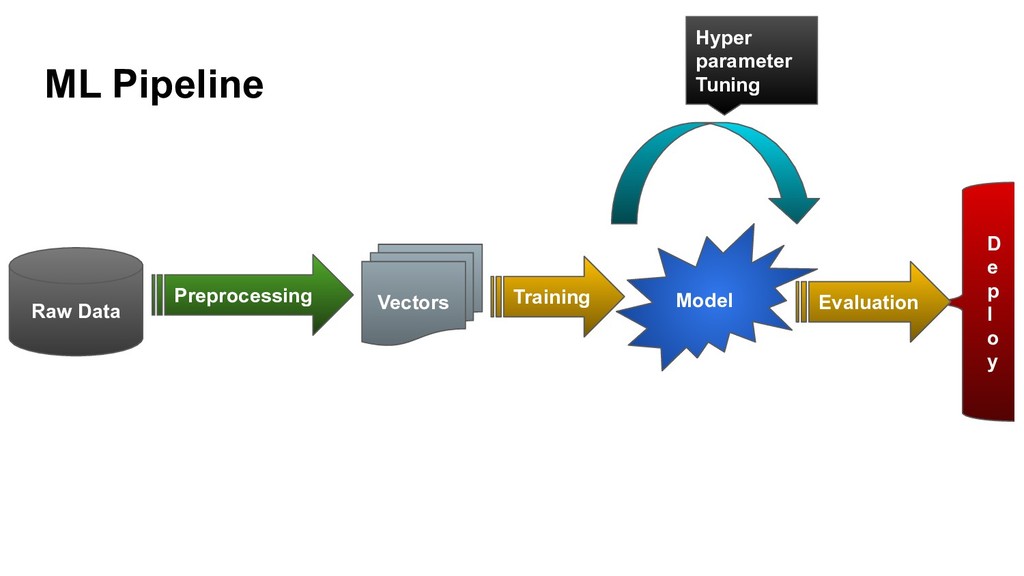{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
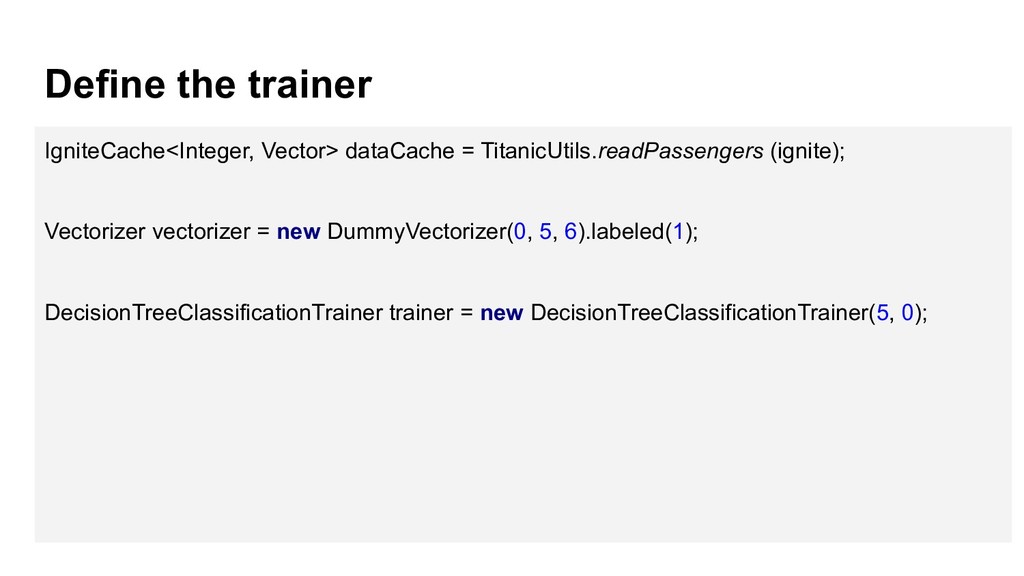{kind=link}
{kind=link}
{kind=link}
{kind=link}
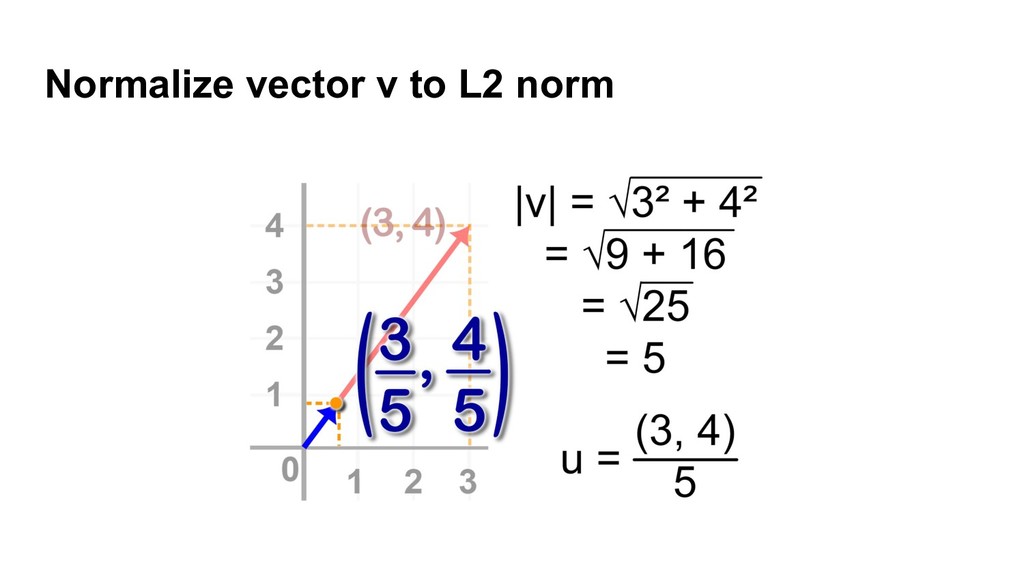{kind=link}
{kind=link}
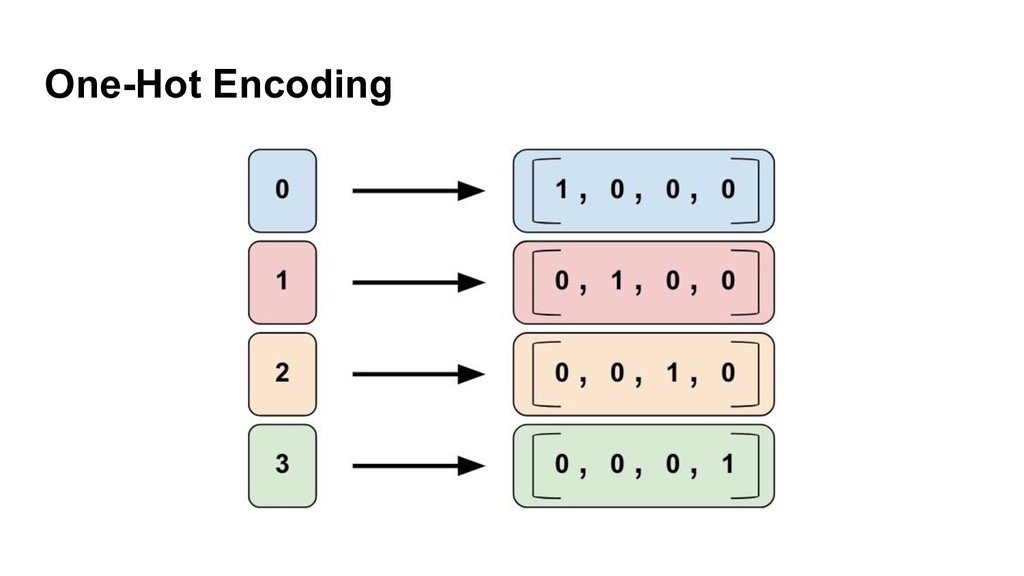{kind=link}
{kind=link}
{kind=link}
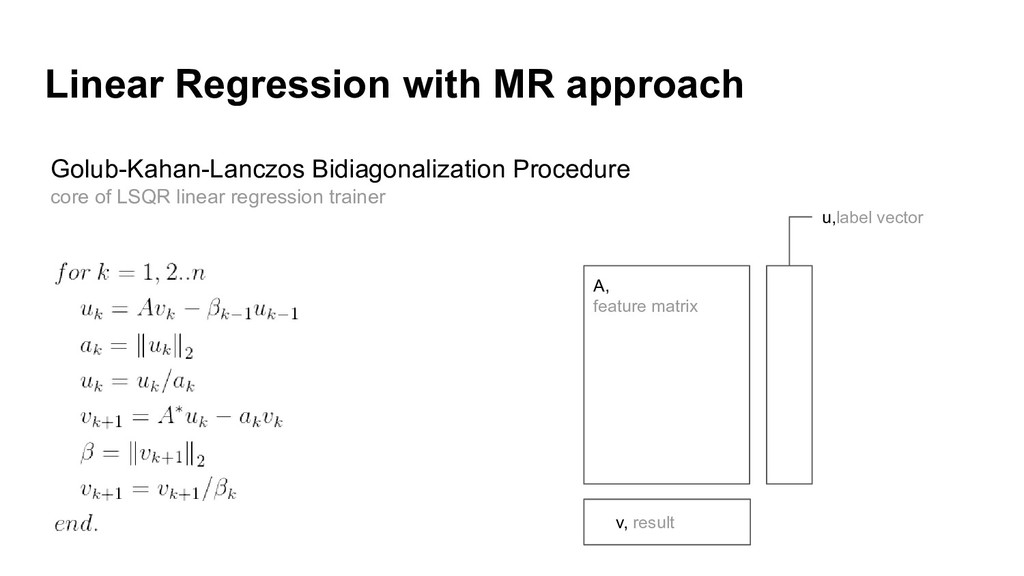{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
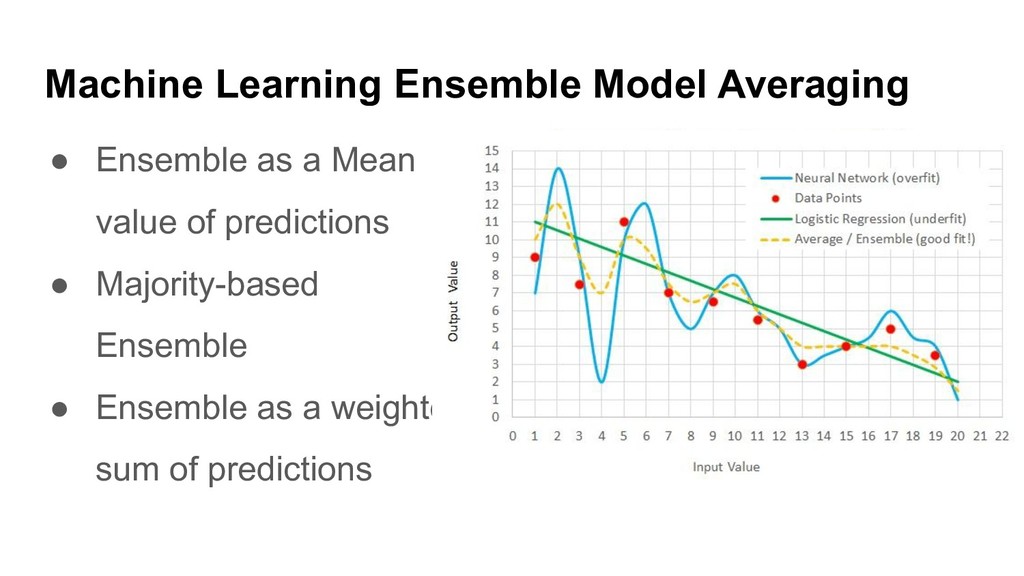{kind=link}
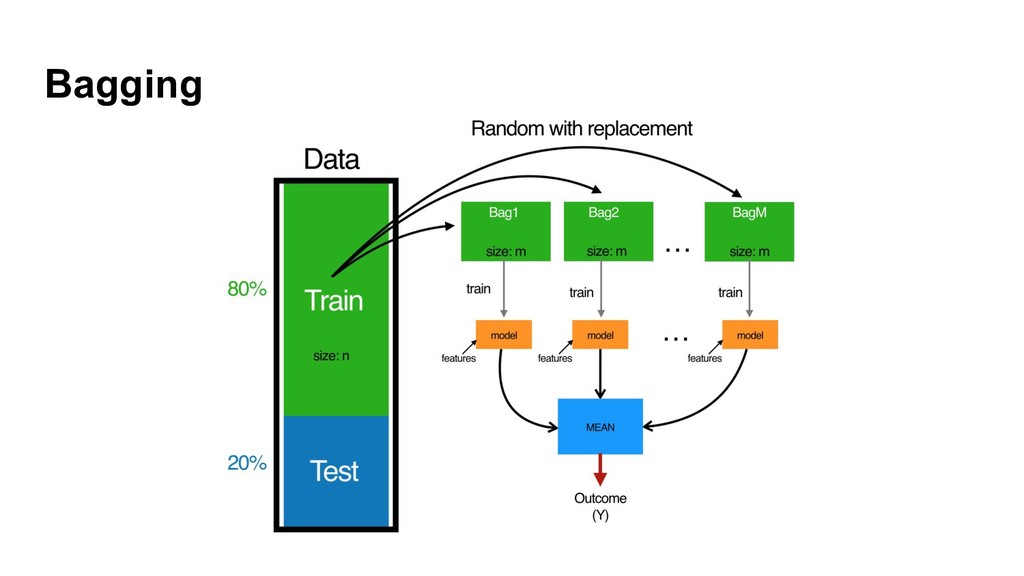{kind=link}
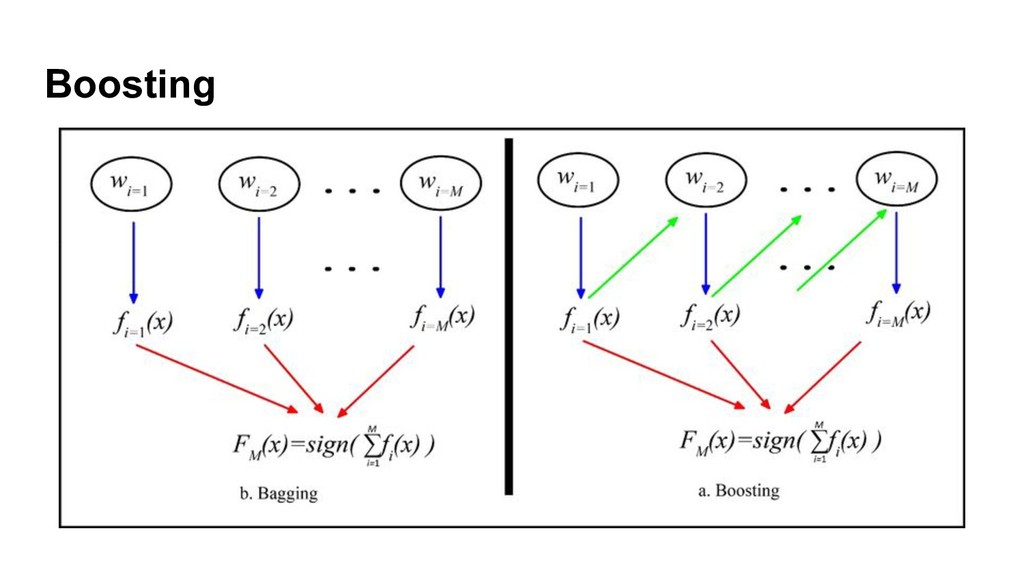{kind=link}
{kind=link}
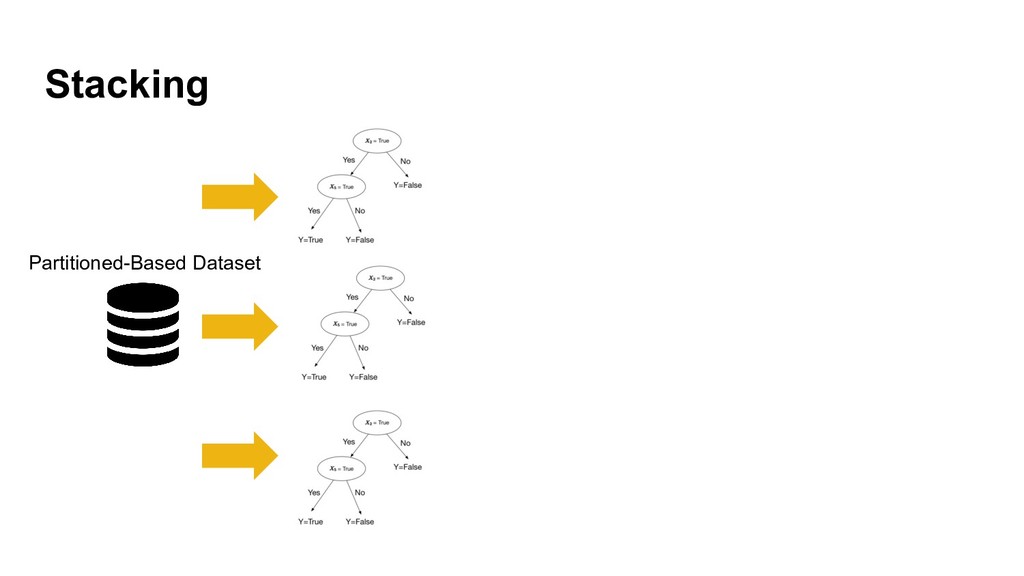{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Distributed Training dataset = IgniteDataset("IMAGES") gradients = [] # Compute](https://files.speakerdeck.com/presentations/e39387513ee14132ac7594f8f4c4b42d/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
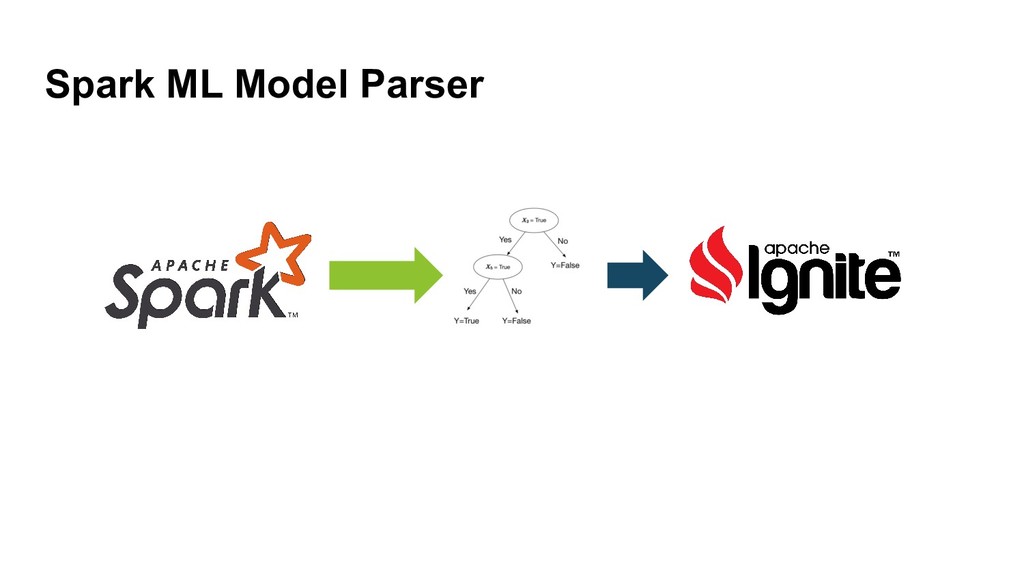{kind=link}
{kind=link}
{kind=link}
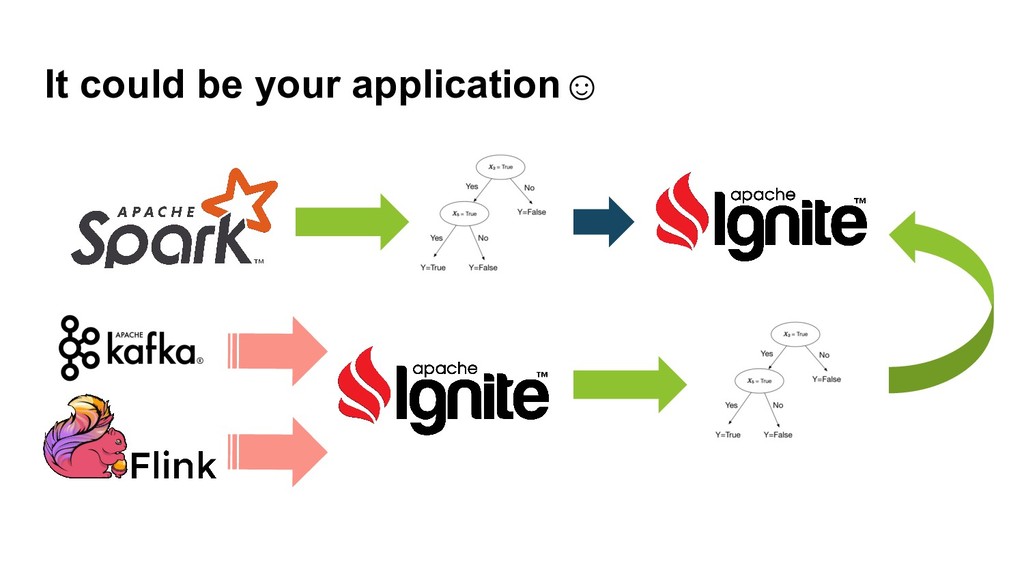{kind=link}
{kind=link}
{kind=link}
{kind=link}
![E-mail : [email protected] Twitter : @zaleslaw Github: zaleslaw Follow me](https://files.speakerdeck.com/presentations/e39387513ee14132ac7594f8f4c4b42d/slide_79.jpg){kind=link}
{kind=link}