In this session, Alexey will tell about problems of adapting classic machine learning algorithms for distributed execution from his experience of working with Apache Spark ML, Apache Mahout, Apache Flink ML and creating Apache Ignite ML.
Disclaimer: in this session, there won't be any code, demo, sales pitch, etc. But Alexey will touch upon approaches to implementing ML algorithms in the aforementioned frameworks and share his own opinion on these approaches.
{kind=link}
![E-mail : [email protected] Twitter : @zaleslaw @BigDataRussia vk.com/big_data_russia Big Data](https://files.speakerdeck.com/presentations/b8d6988f15c64d03b0de5b01902bcf83/slide_1.jpg){kind=link}
{kind=link}
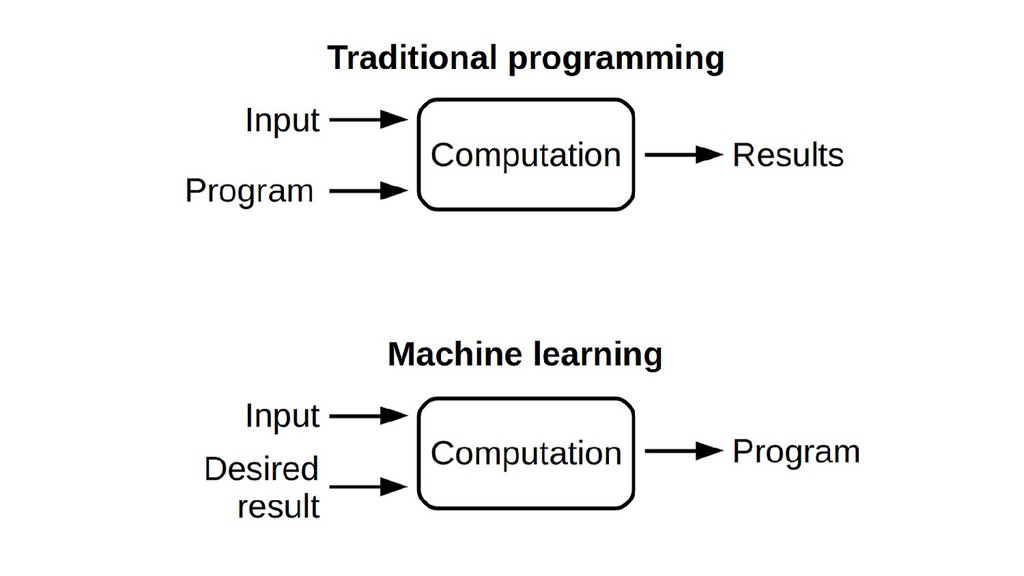{kind=link}
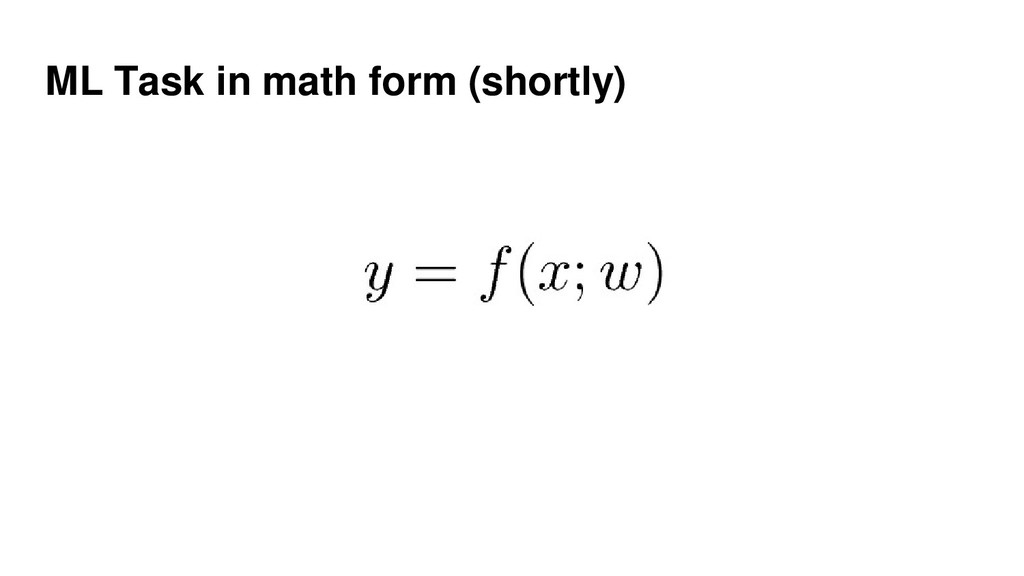{kind=link}
{kind=link}
![Model example [Linear Regression]](https://files.speakerdeck.com/presentations/b8d6988f15c64d03b0de5b01902bcf83/slide_6.jpg){kind=link}
![Model example [Linear Regression] Loss Function](https://files.speakerdeck.com/presentations/b8d6988f15c64d03b0de5b01902bcf83/slide_7.jpg){kind=link}
![Model example [Decision Tree]](https://files.speakerdeck.com/presentations/b8d6988f15c64d03b0de5b01902bcf83/slide_8.jpg){kind=link}
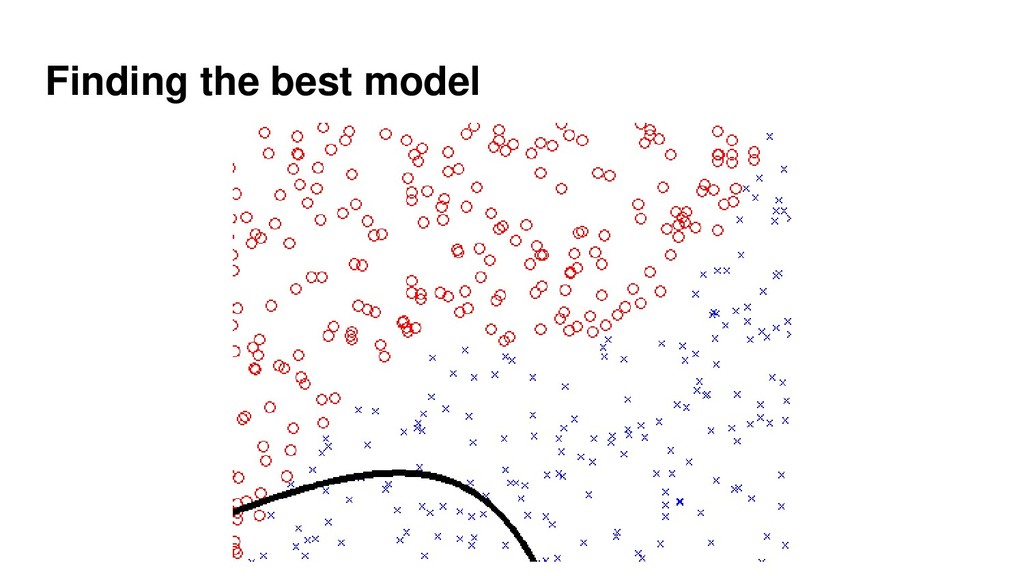{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
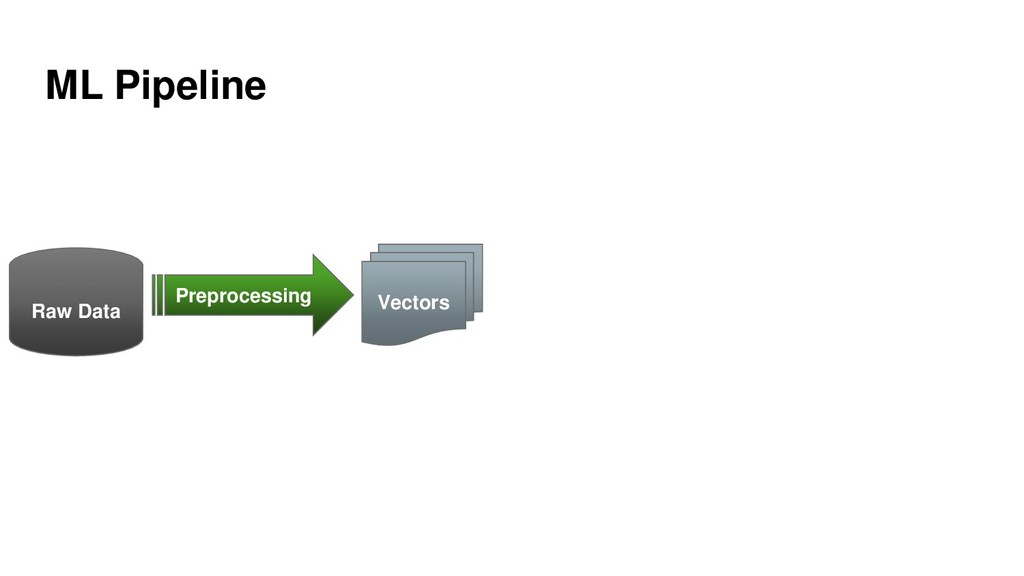{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
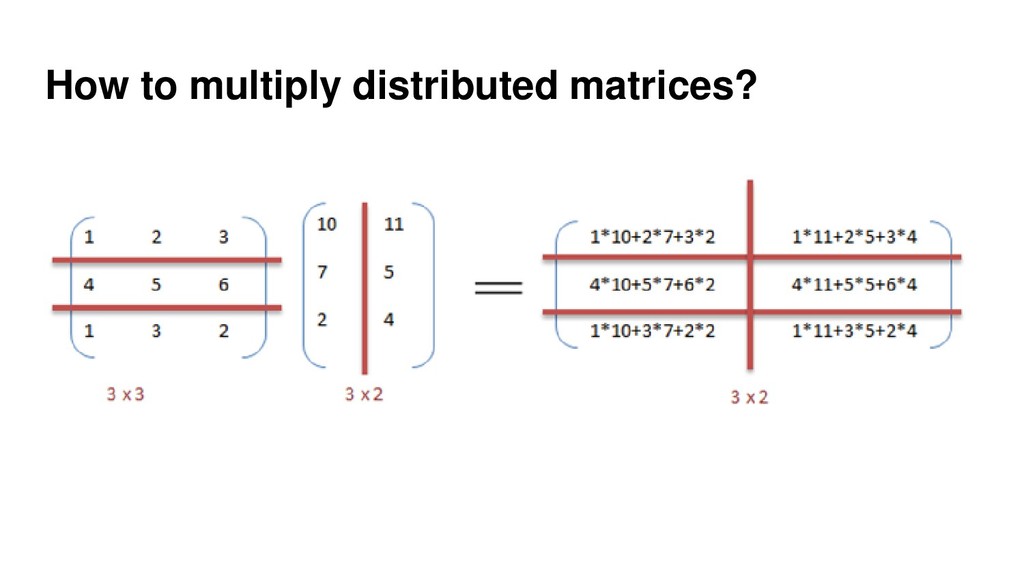{kind=link}
{kind=link}
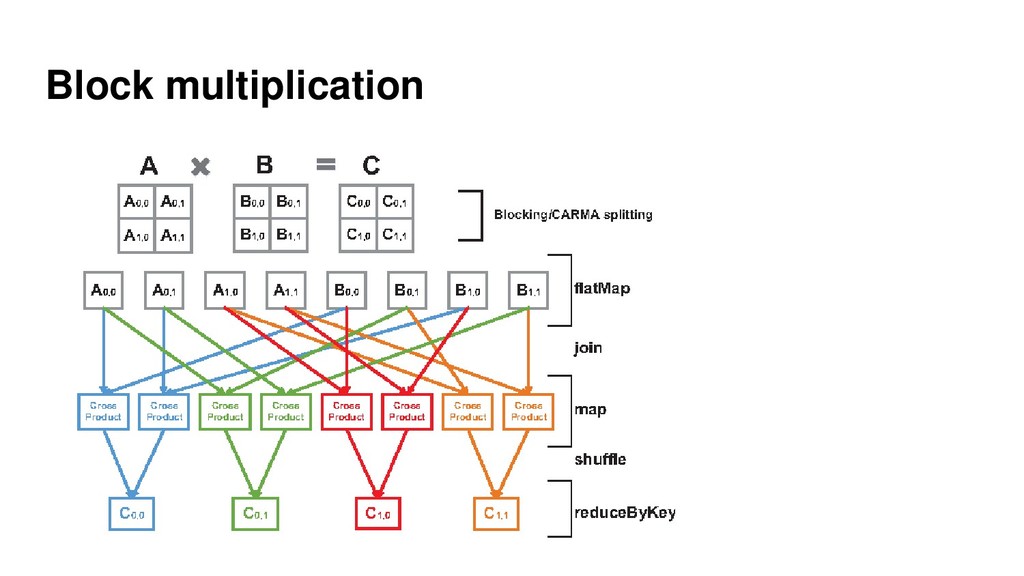{kind=link}
{kind=link}
{kind=link}
{kind=link}
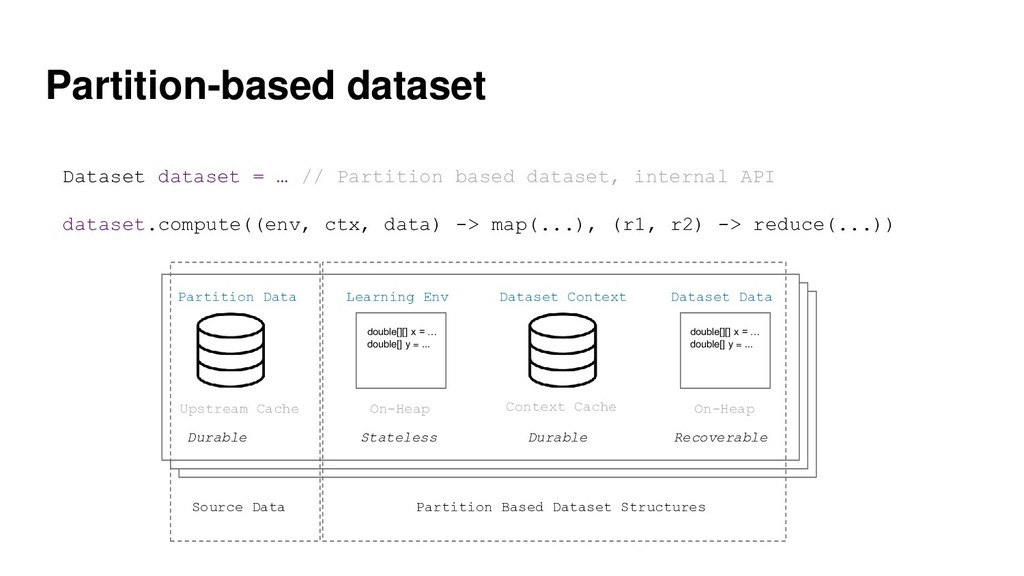{kind=link}
{kind=link}
{kind=link}
{kind=link}
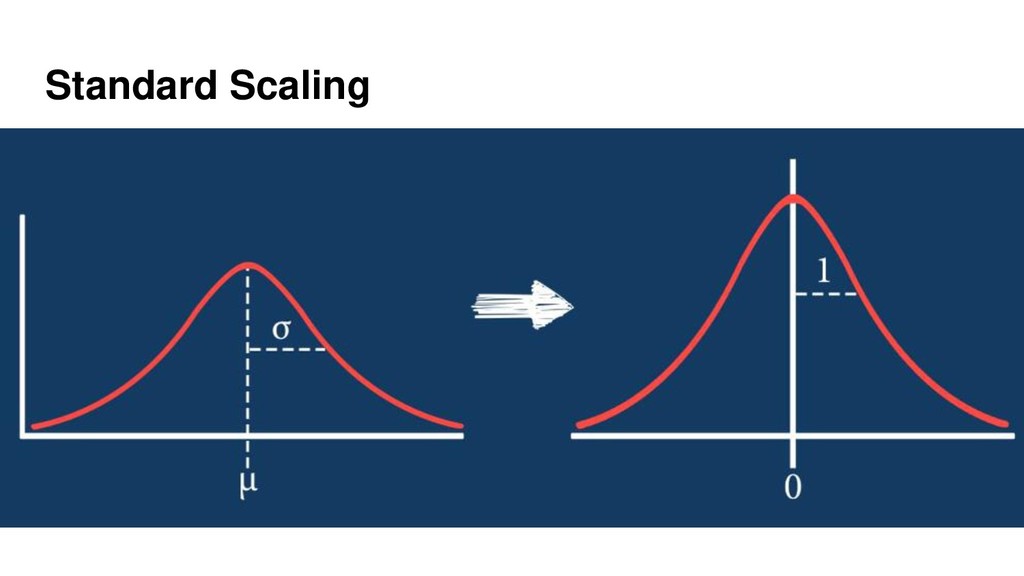{kind=link}
{kind=link}
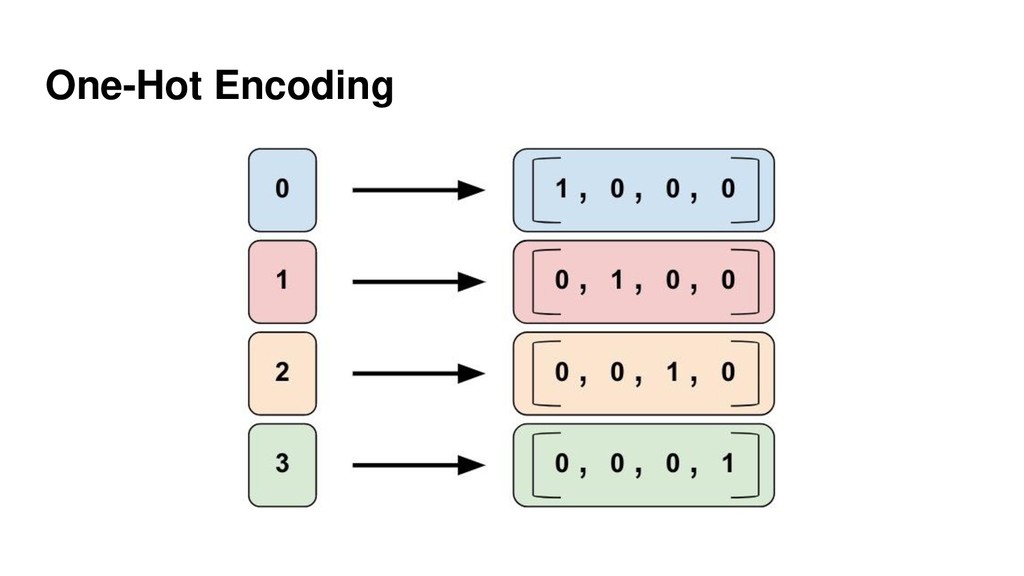{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
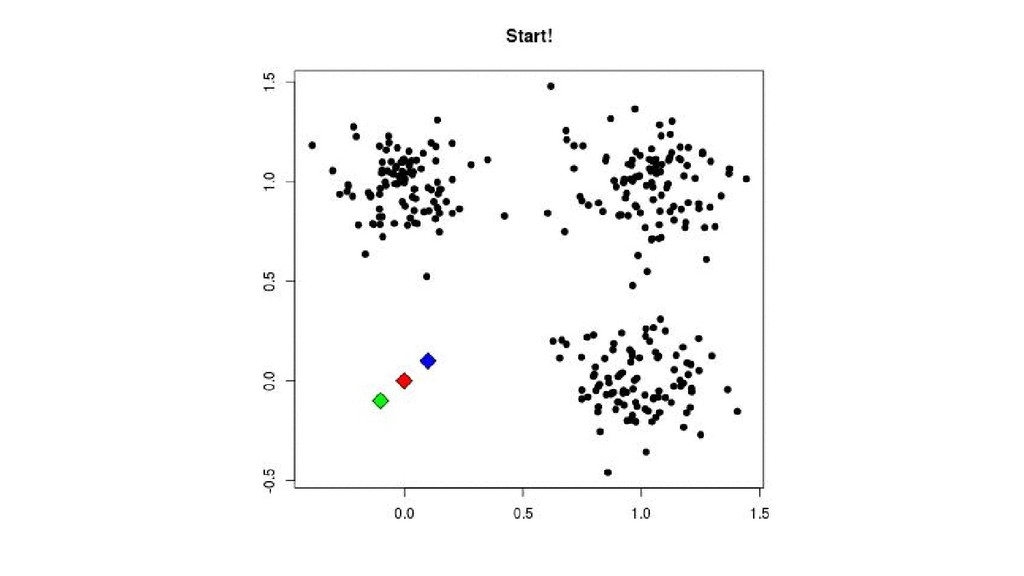{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
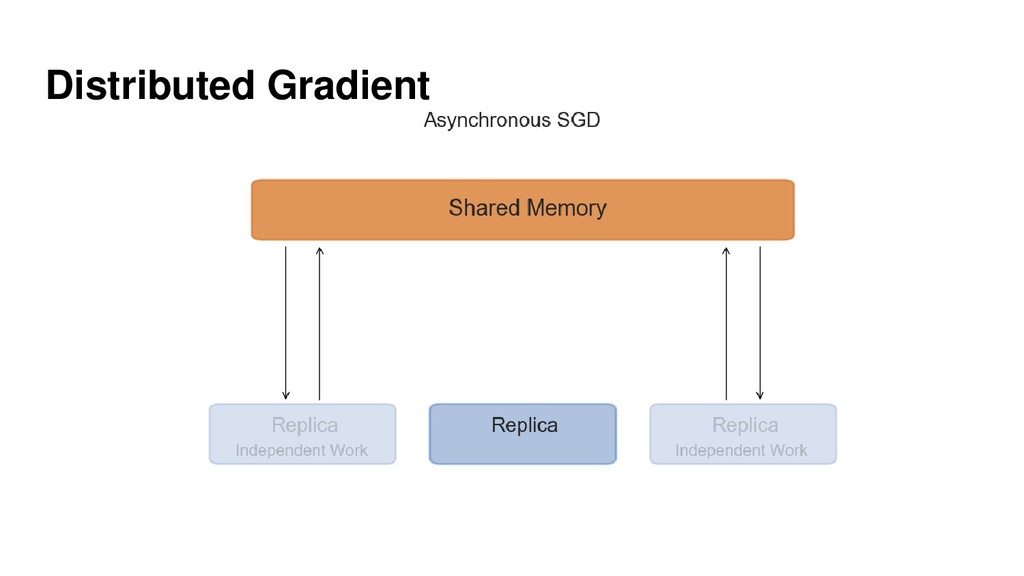{kind=link}
{kind=link}
{kind=link}
{kind=link}
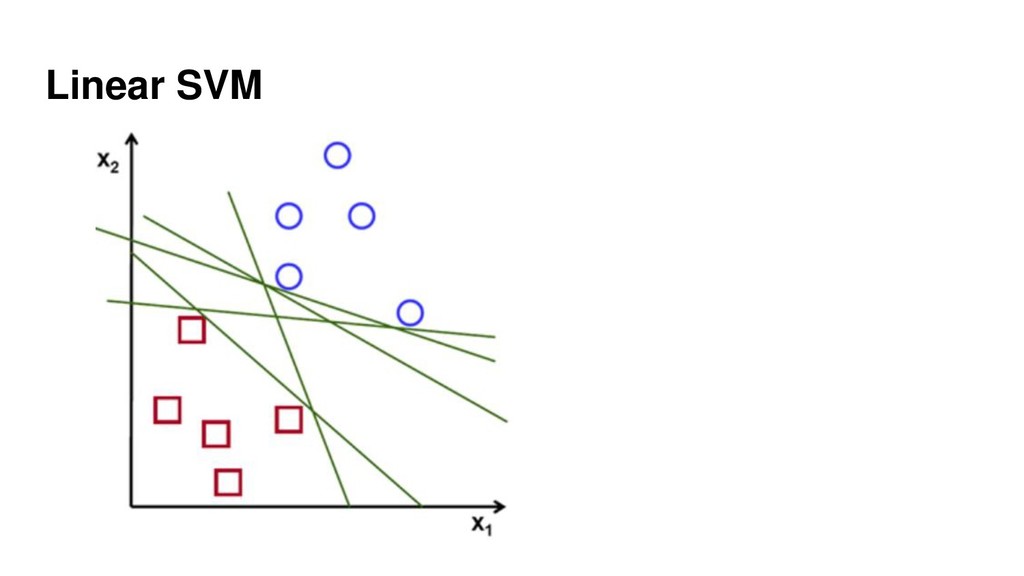{kind=link}
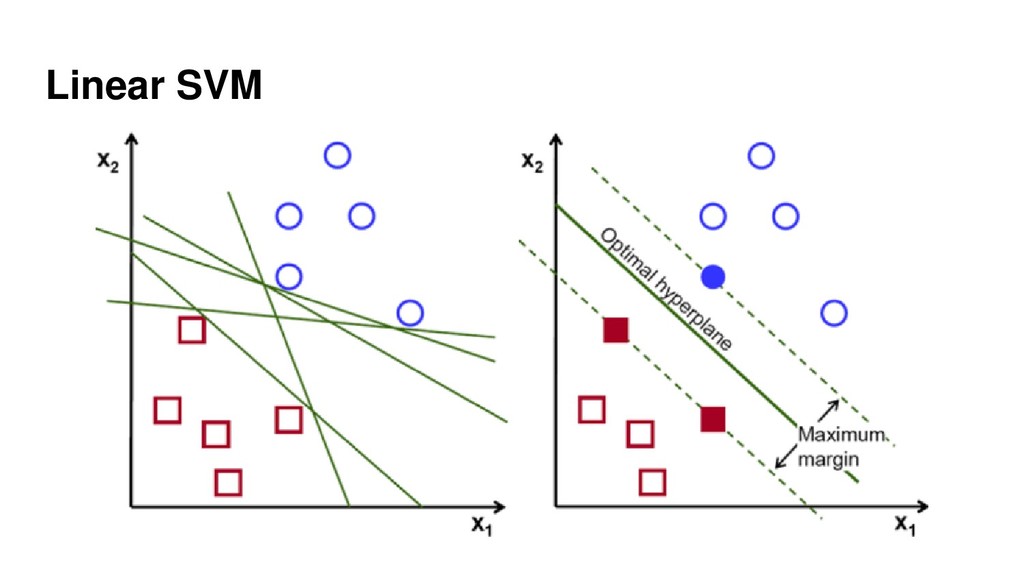{kind=link}
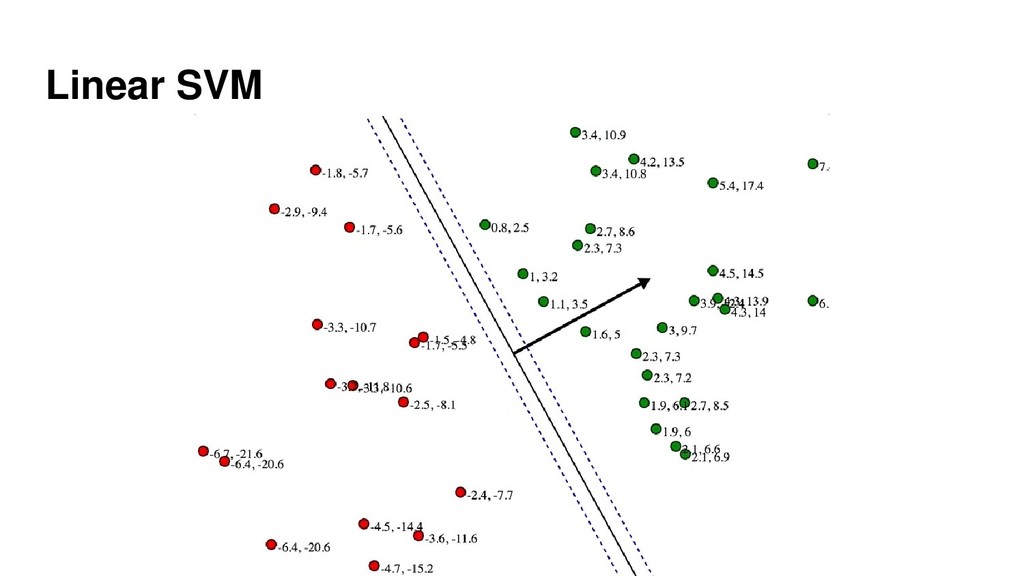{kind=link}
{kind=link}
{kind=link}
{kind=link}
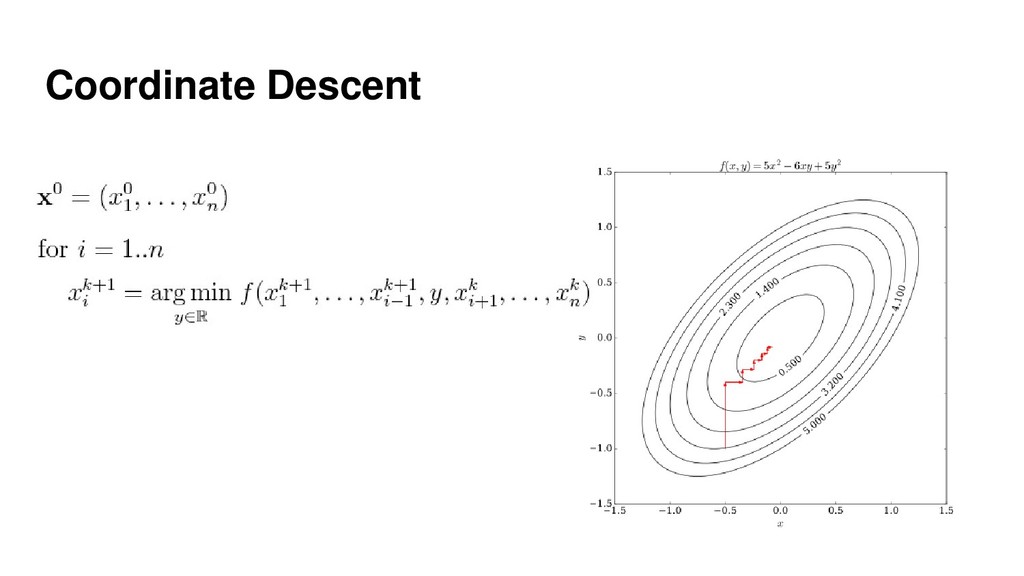{kind=link}
{kind=link}
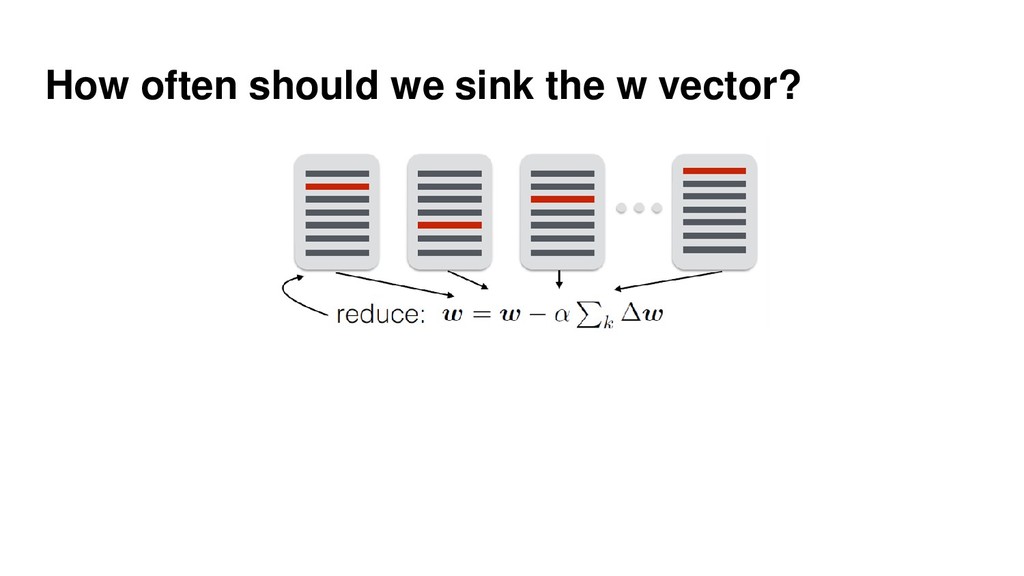{kind=link}
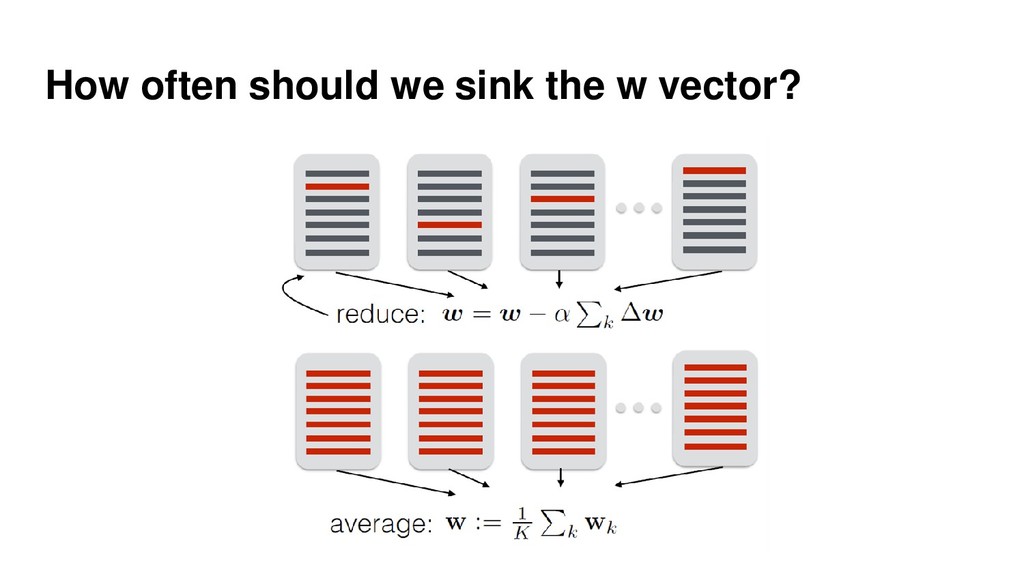{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
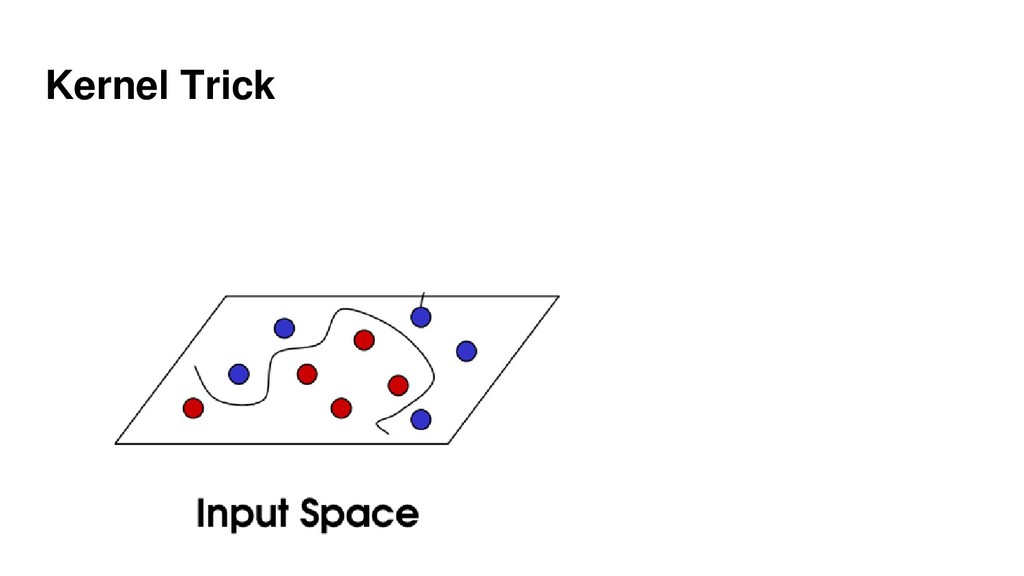{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
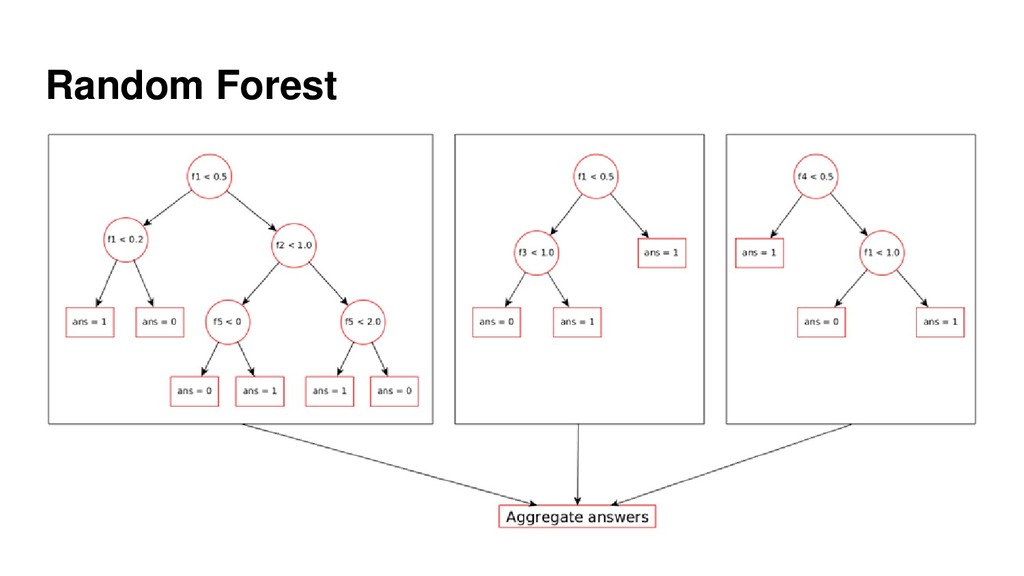{kind=link}
{kind=link}
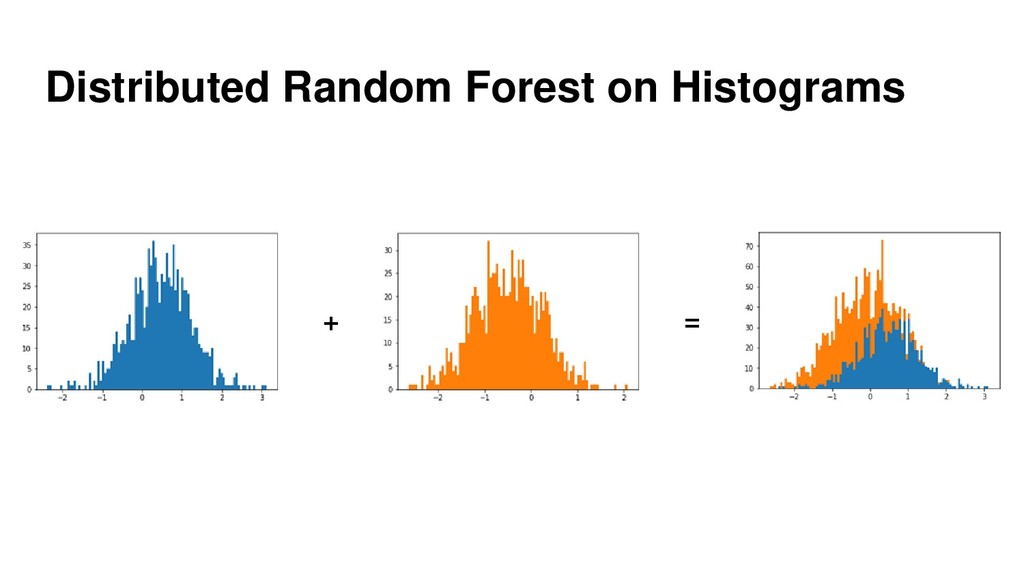{kind=link}
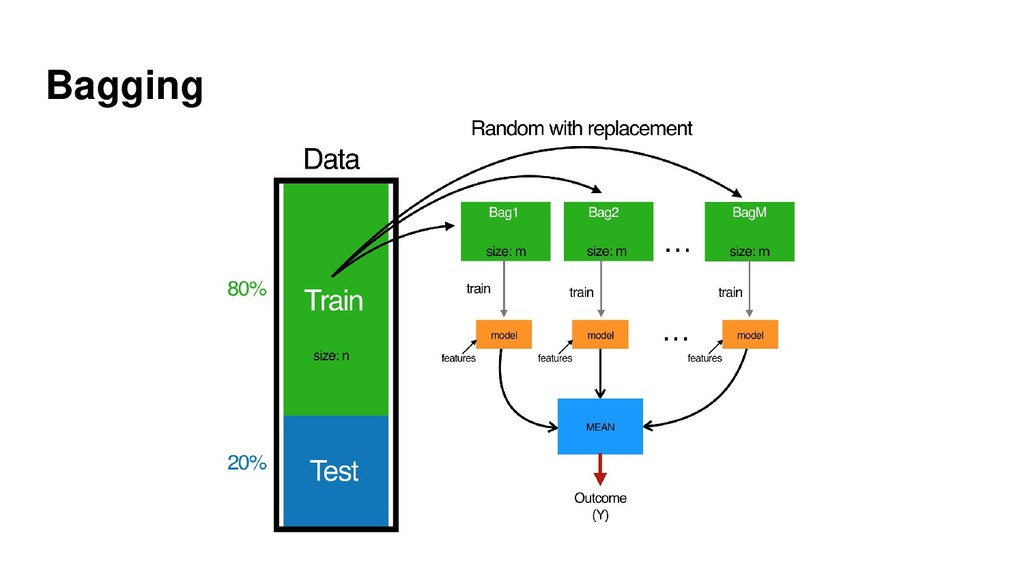{kind=link}
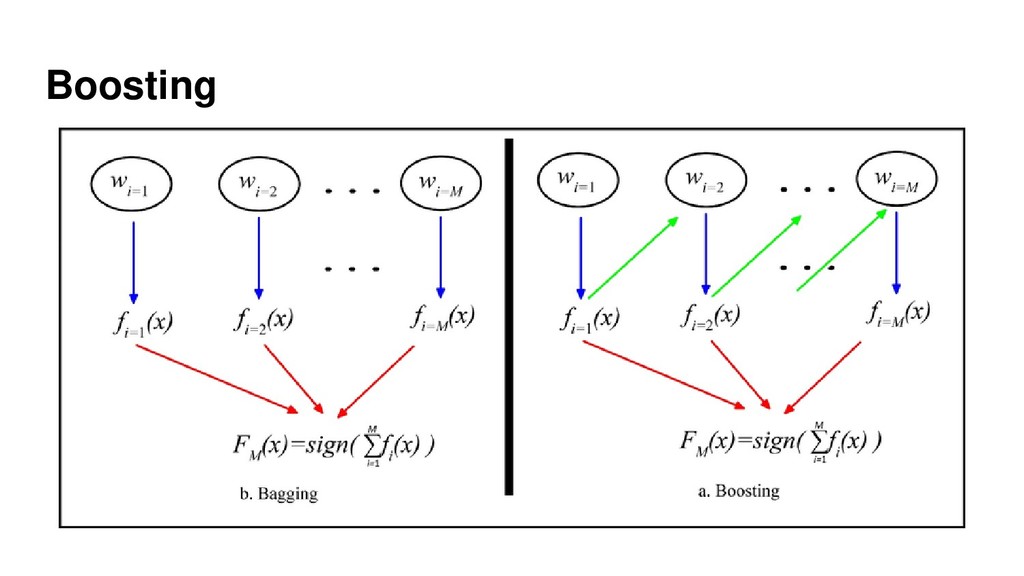{kind=link}
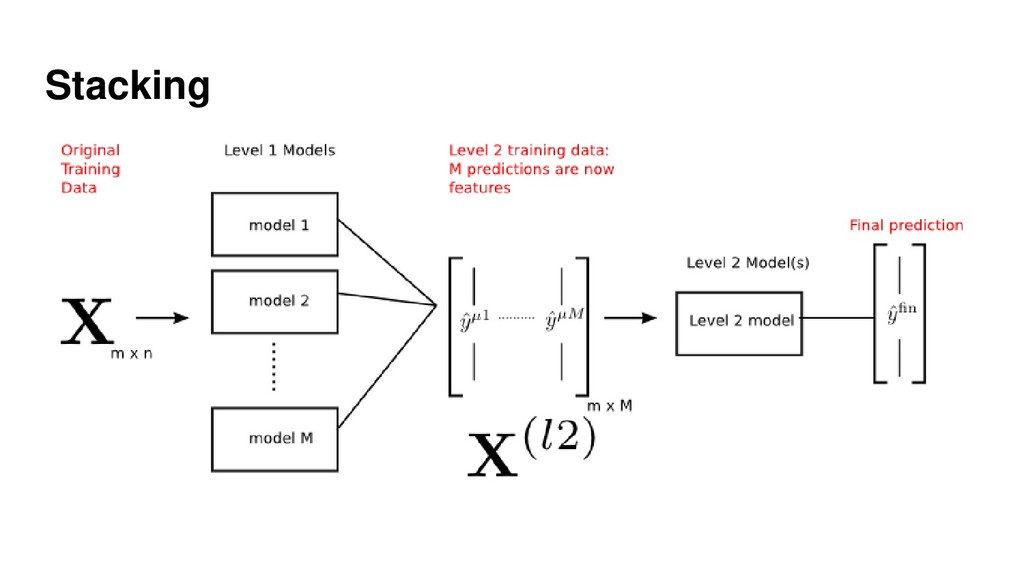{kind=link}
{kind=link}
{kind=link}
{kind=link}
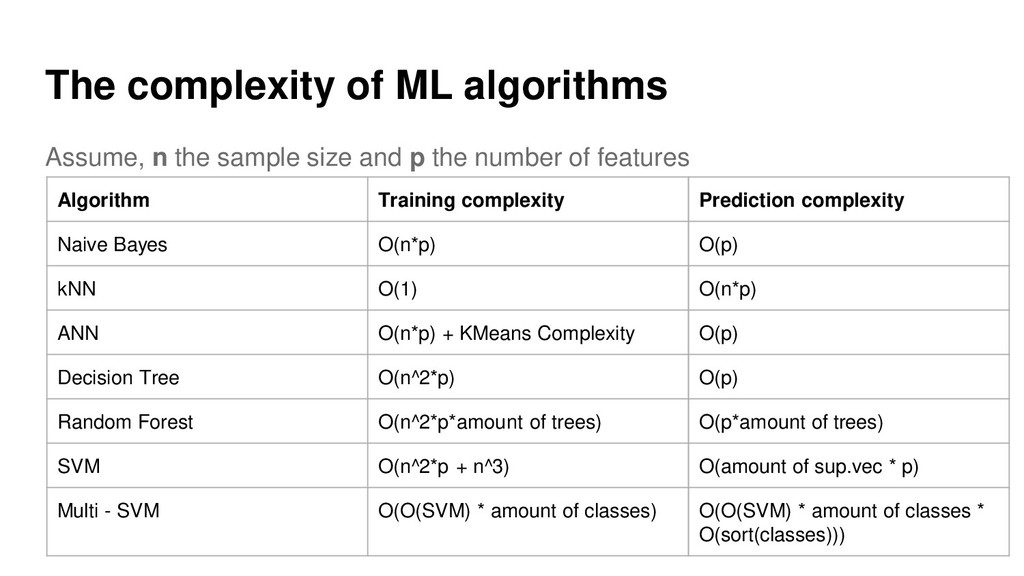{kind=link}
{kind=link}
![E-mail : [email protected] Twitter : @zaleslaw @BigDataRussia vk.com/big_data_russia Big Data](https://files.speakerdeck.com/presentations/b8d6988f15c64d03b0de5b01902bcf83/slide_112.jpg){kind=link}