Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層学習は奔流に身をまかせ / Get Drowned in the Flood for De...
Search
Henry Cui
February 17, 2023
Technology
310
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層学習は奔流に身をまかせ / Get Drowned in the Flood for Deep Learning
Henry Cui
February 17, 2023
More Decks by Henry Cui
See All by Henry Cui
プロダクション言語モデルの情報を盗む攻撃 / Stealing Part of a Production Language Model
zchenry
1
260
Direct Preference Optimization
zchenry
0
470
Diffusion Model with Perceptual Loss
zchenry
0
530
レンズの下のLLM / LLM under the Lens
zchenry
0
240
Go with the Prompt Flow
zchenry
0
230
Mojo Dojo
zchenry
0
270
ことのはの力で画像の異常検知 / Anomaly Detection by Language
zchenry
0
740
驚愕の事実!LangChainが抱える問題 / Problems of LangChain
zchenry
0
330
MLOps初心者がMLflowを触る / MLflow Brief Introduction
zchenry
0
220
Other Decks in Technology
See All in Technology
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
140
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
790
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
420
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
480
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
Featured
See All Featured
Un-Boring Meetings
codingconduct
0
350
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
280
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
370
GraphQLとの向き合い方2022年版
quramy
50
15k
RailsConf 2023
tenderlove
30
1.5k
WENDY [Excerpt]
tessaabrams
11
38k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Building the Perfect Custom Keyboard
takai
2
820
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Chasing Engaging Ingredients in Design
codingconduct
0
240
Transcript
深層学習は奔流に身をまかせ 機械学習の社会実装勉強会第20回 Henry 2023/2/18
モチベーション ▪ ペインポイント • 深層モデルの学習で望ましい効果を素早く得るのは難しい • 実データのラベルにノイズが多い • その問題点の一つに、過適合が挙げられる ▪
過適合を解消するための様々な正則化手法がある • weight decay や learning rate scheduler • Pytorchで簡単に使える ▪ 今日は最近の研究から、実用性が高い新しい正則化手法を 紹介する • 特に実装が楽 • まだあまり知られていない 2
紹介する論文 ▪ Do We Need Zero Training Loss After Achieving
Zero Training Error?, Ishida et al., ICML 2020 • Floodingという新しい正則化手法を導入 ▪ iFlood: A Stable and Effective Regularizer, Xie et al., ICLR 2022 • Floodingの計算式を少しだけ改良 3
Ishida et al., ICML 2020 ▪ モチベーション • 学習データでの損失を0まで学習を行ったほうが良いと言われる •
しかし、これは本当に必要なのか • 正則化手法は、学習データでの損失を過度に最小化しないための間 接的な手法と見なせる ▪ 直接学習損失の最小化を制限する手法:Flooding • 実装も簡単 • 学習損失は0じゃなくても、学習精度が100%の可能性もある 4
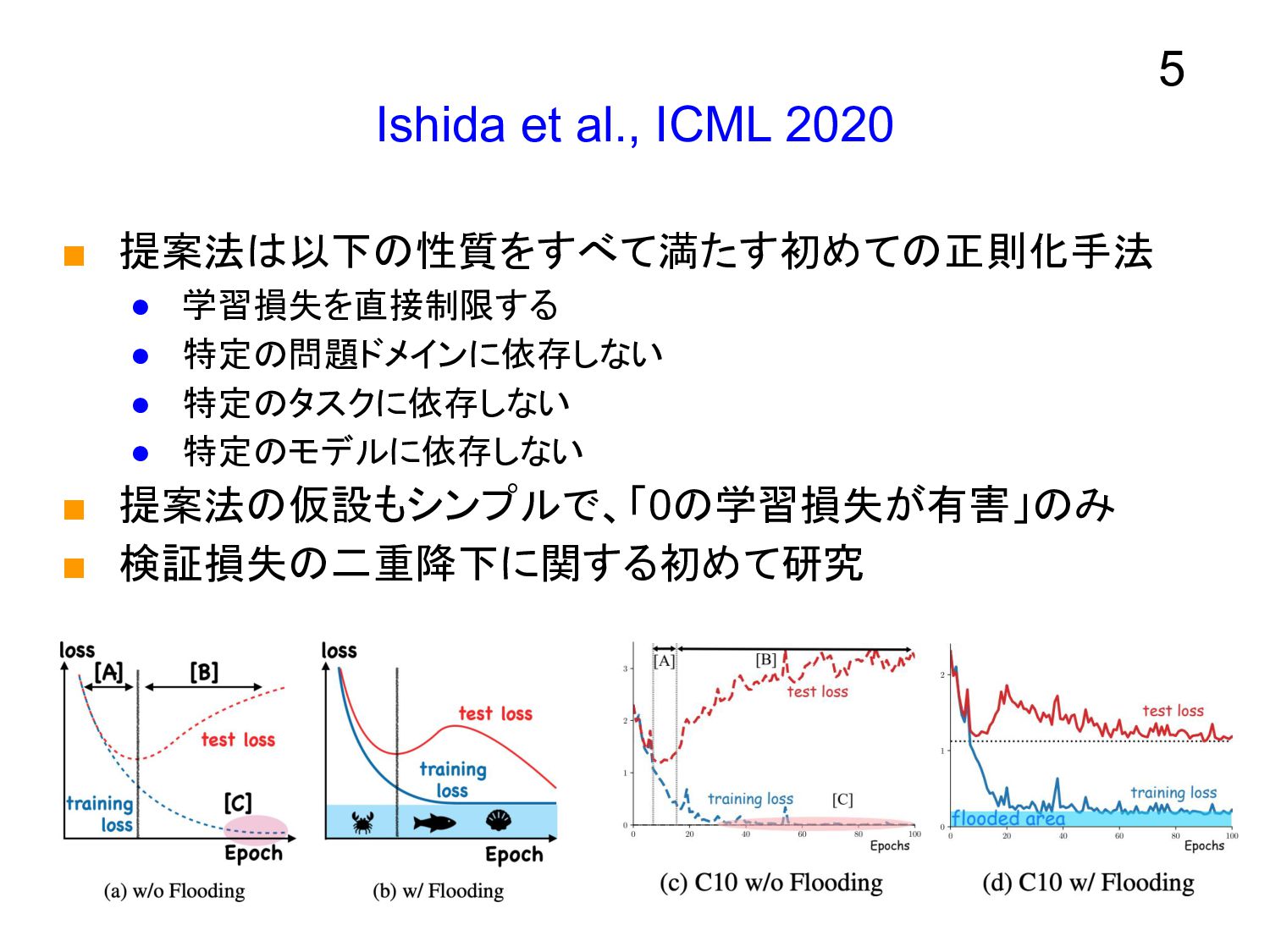
Ishida et al., ICML 2020 ▪ 提案法は以下の性質をすべて満たす初めての正則化手法 • 学習損失を直接制限する •
特定の問題ドメインに依存しない • 特定のタスクに依存しない • 特定のモデルに依存しない ▪ 提案法の仮設もシンプルで、「0の学習損失が有害」のみ ▪ 検証損失の二重降下に関する初めて研究 5
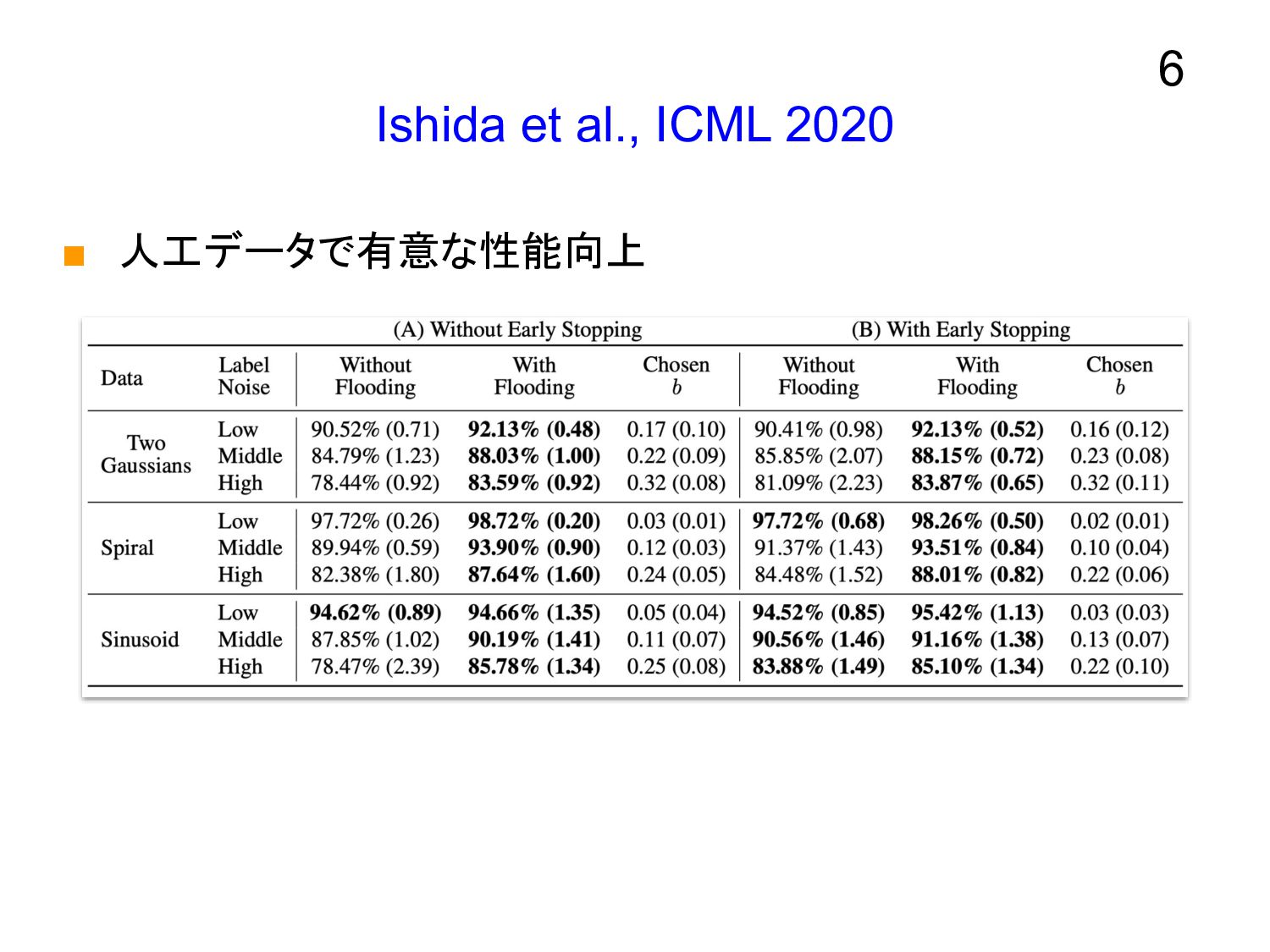
Ishida et al., ICML 2020 ▪ 人工データで有意な性能向上 6
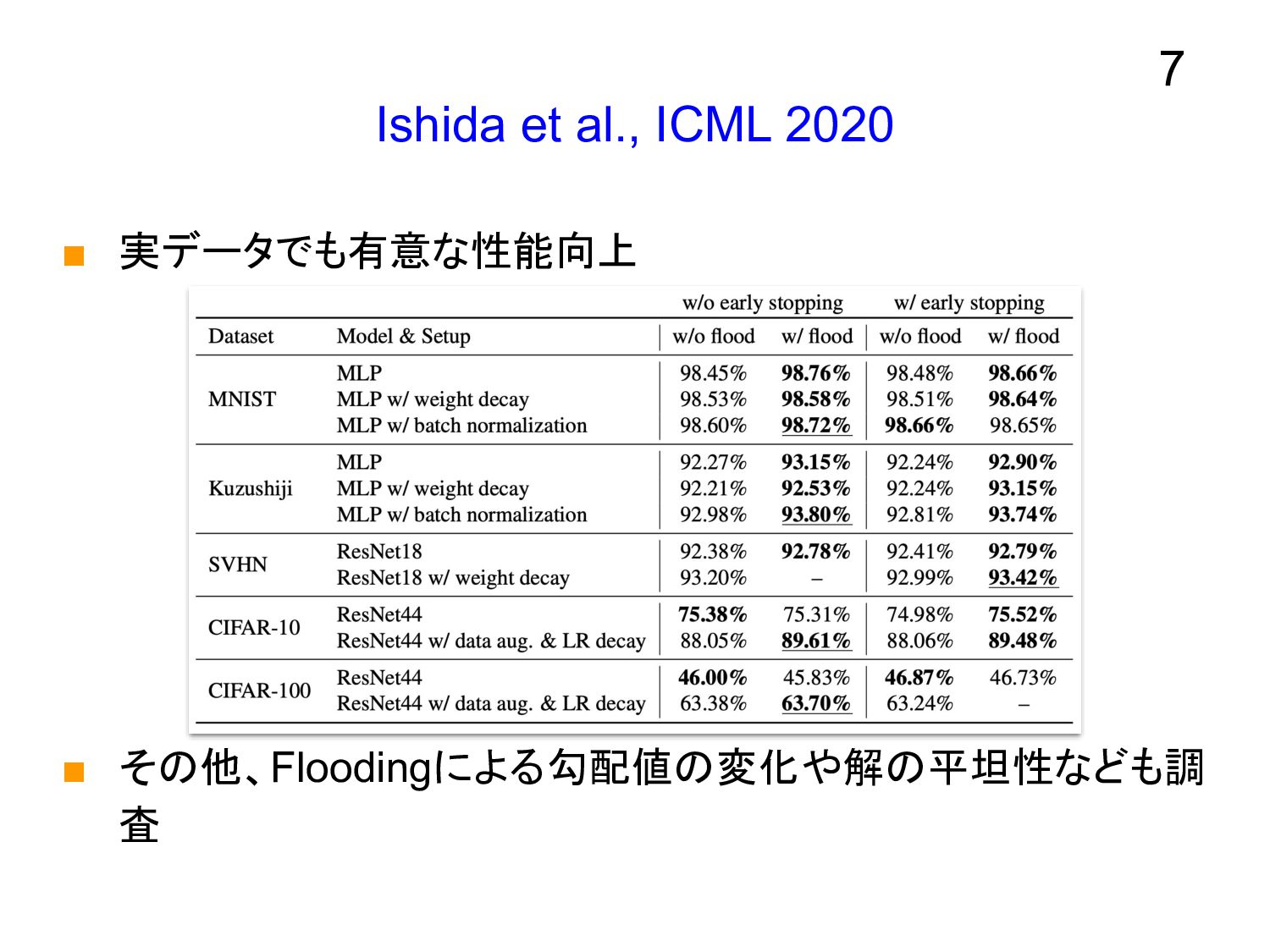
Ishida et al., ICML 2020 ▪ 実データでも有意な性能向上 ▪ その他、Floodingによる勾配値の変化や解の平坦性なども調 査
7
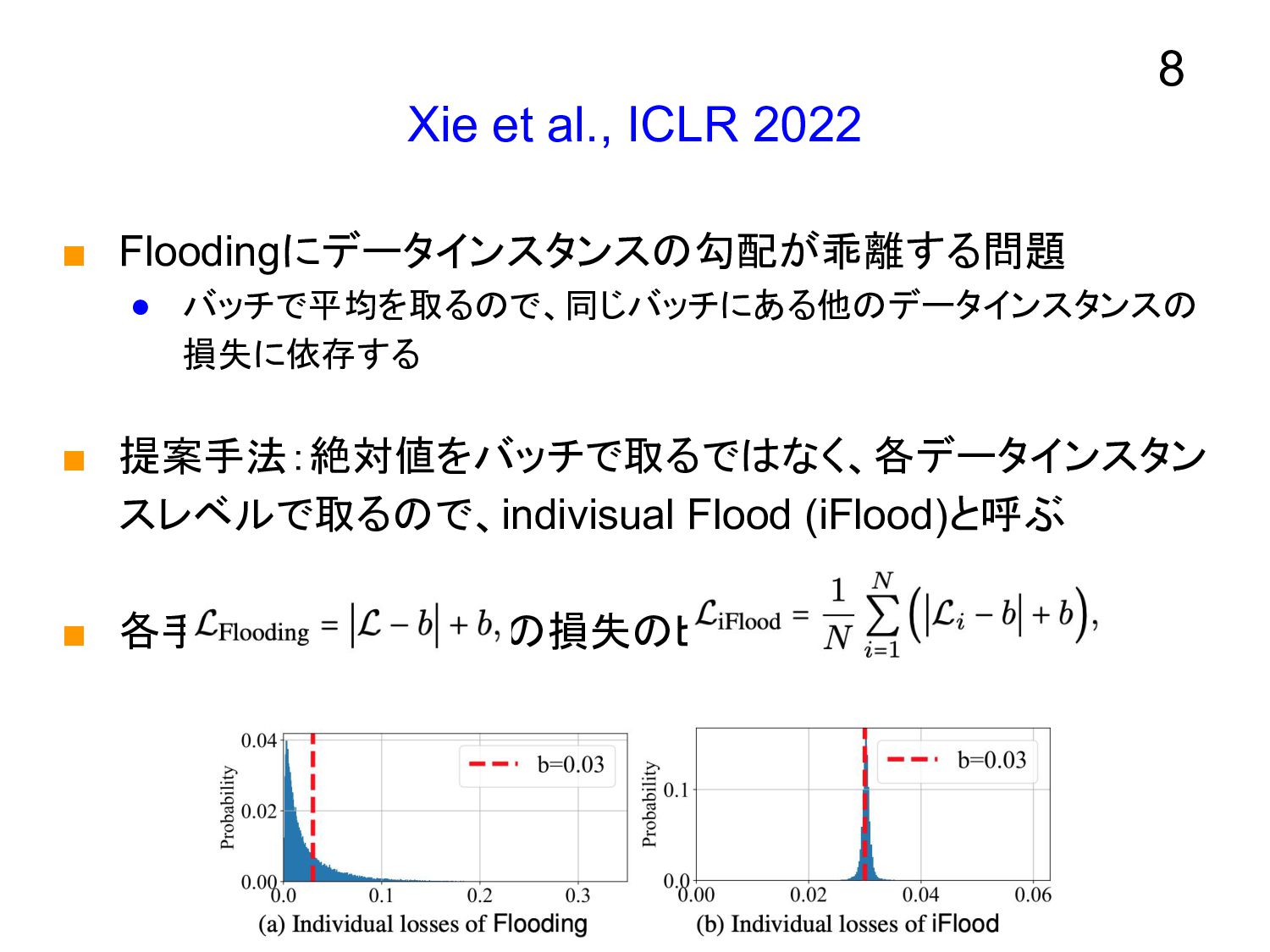
Xie et al., ICLR 2022 ▪ Floodingにデータインスタンスの勾配が乖離する問題 • バッチで平均を取るので、同じバッチにある他のデータインスタンスの 損失に依存する
▪ 提案手法:絶対値をバッチで取るではなく、各データインスタン スレベルで取るので、indivisual Flood (iFlood)と呼ぶ ▪ 各手法のインスタンスの損失のヒストグラム 8
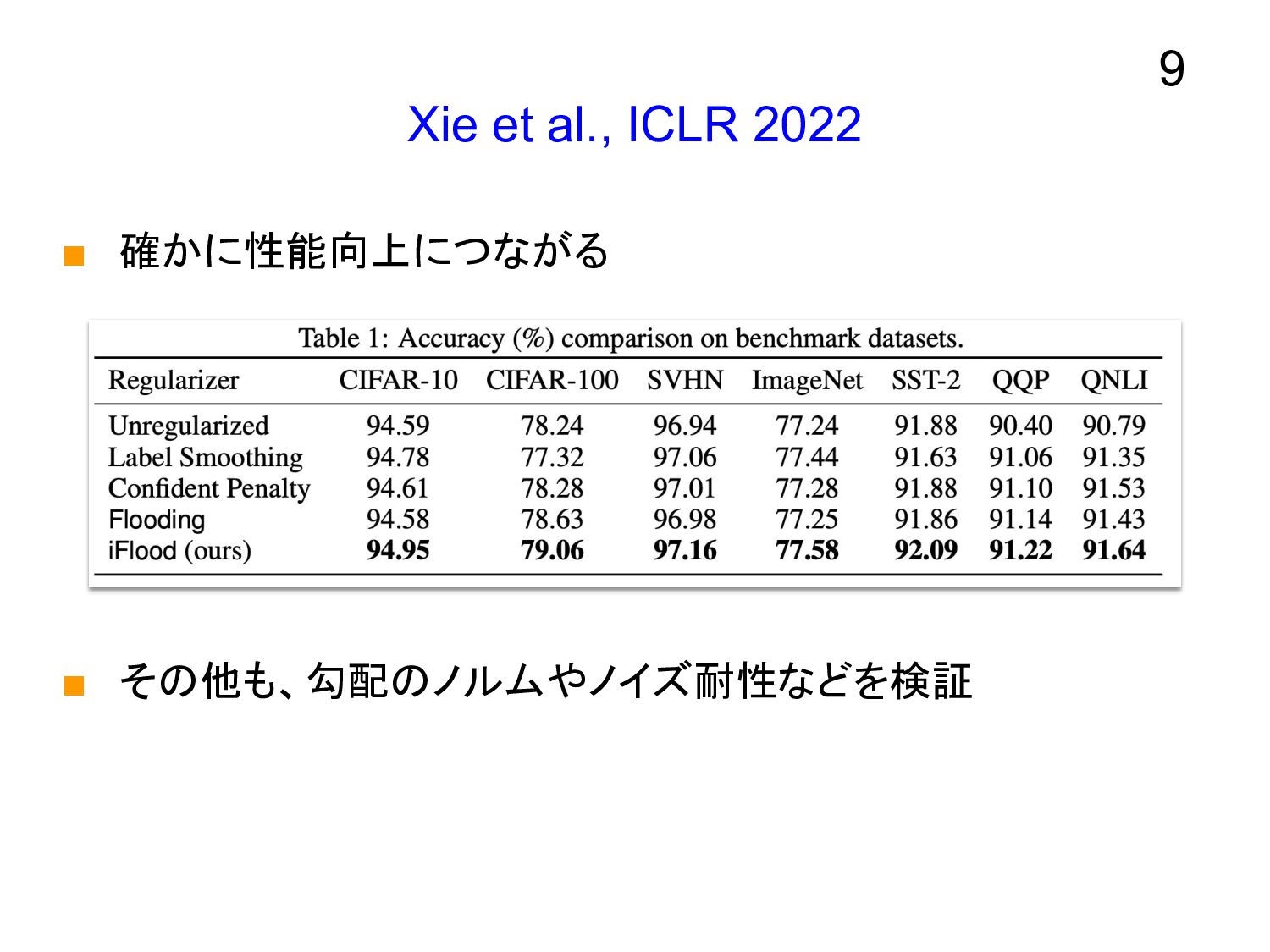
Xie et al., ICLR 2022 ▪ 確かに性能向上につながる ▪ その他も、勾配のノルムやノイズ耐性などを検証 9
まとめ ▪ 実用性高い正則化手法のFloodingとその改良版のiFlood ▪ 実装がシンプルで試しやすい 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}