VLDB 2020
Talk video: https://youtu.be/u2glA-S1AEs
Paper: https://zongheng.me/pubs/naru-vldb20.pdf
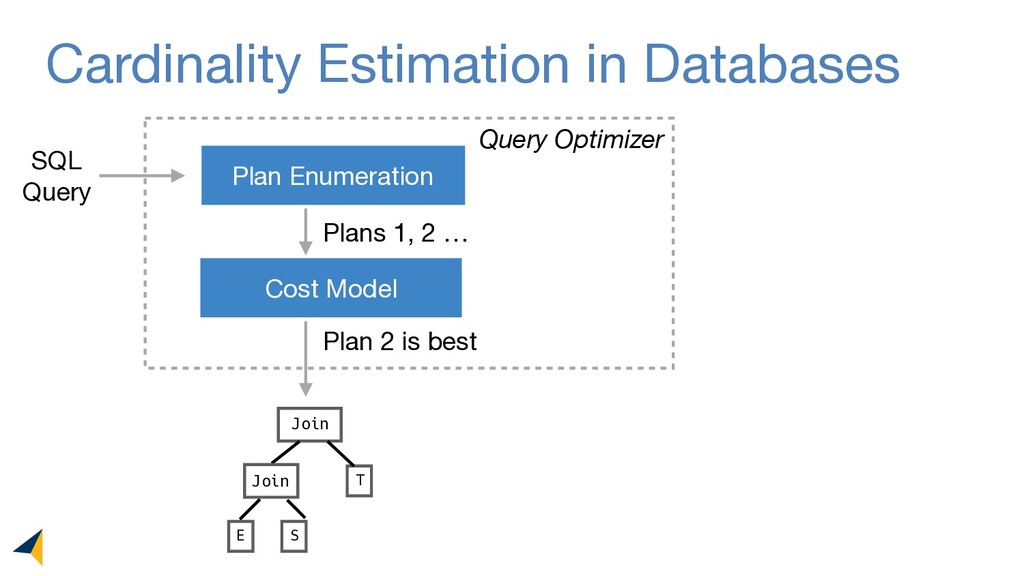
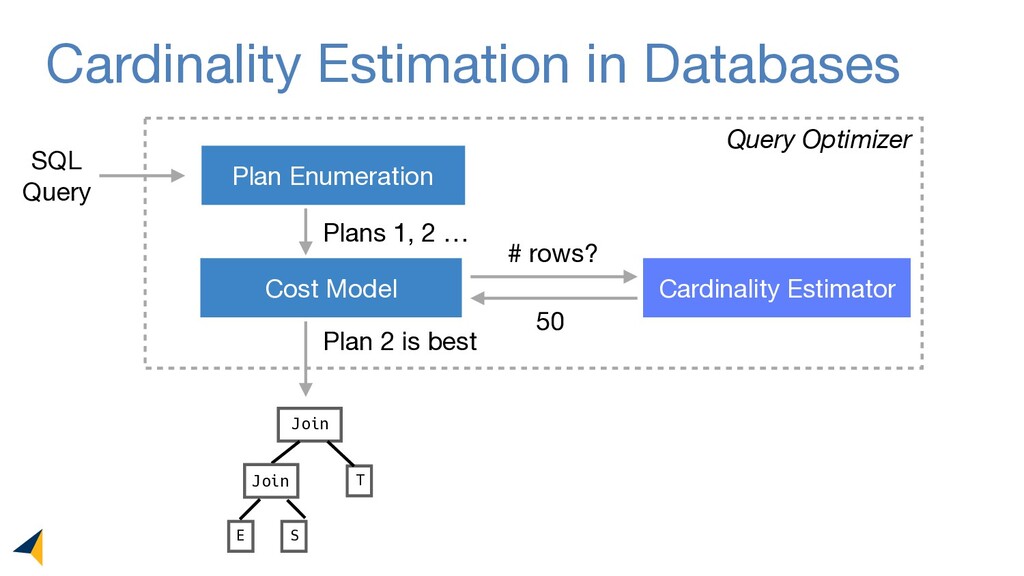
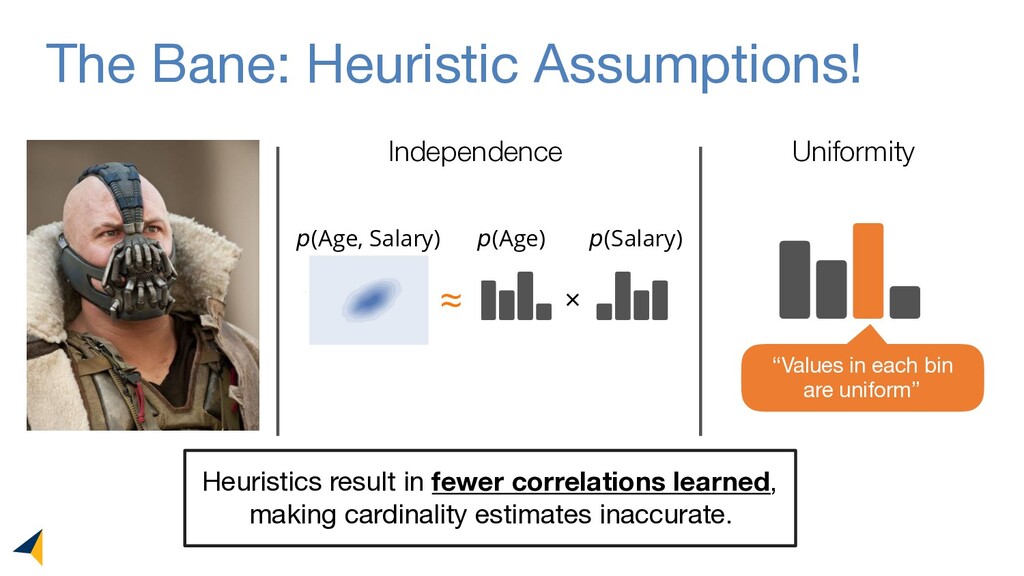
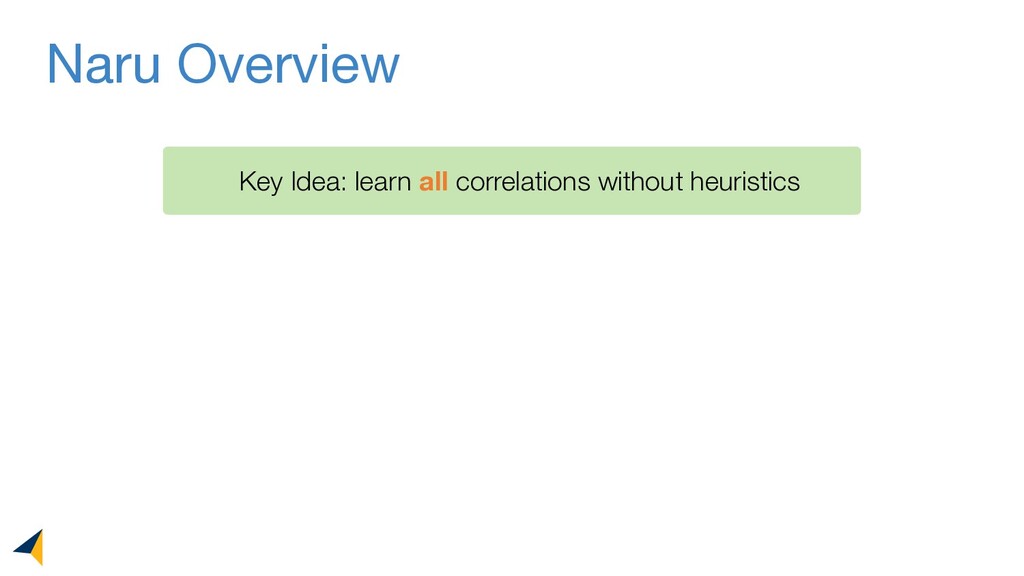
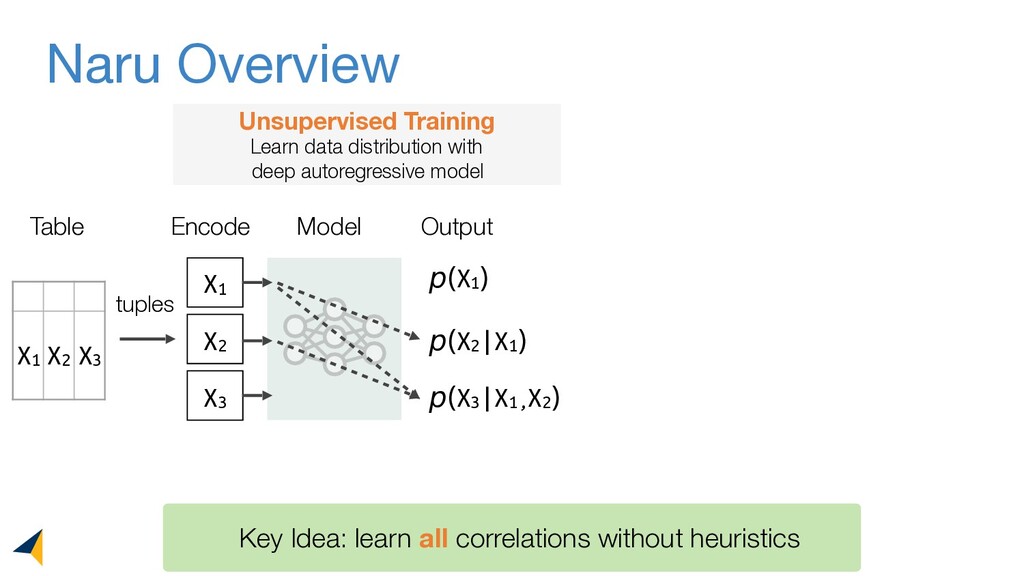
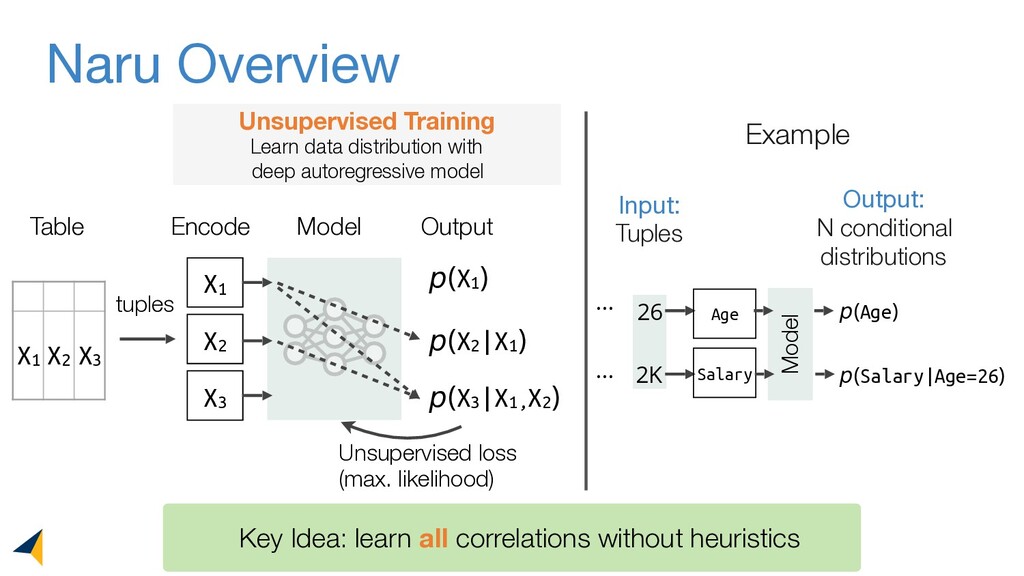
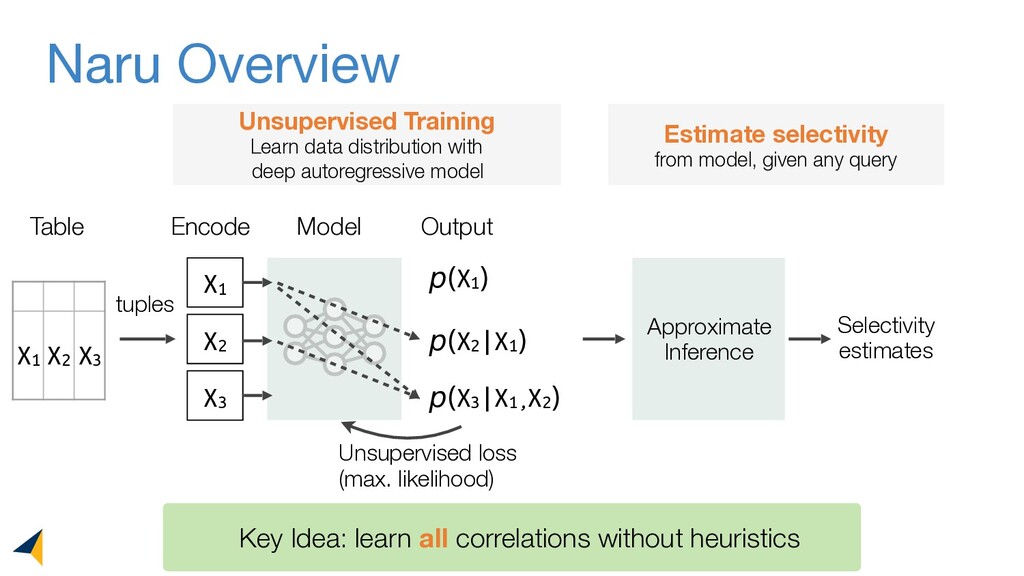
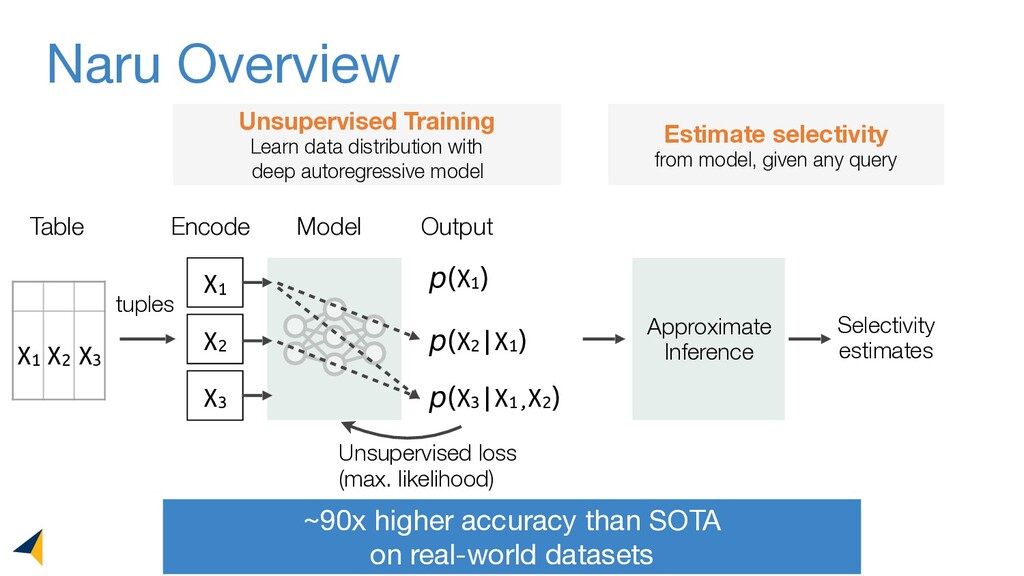
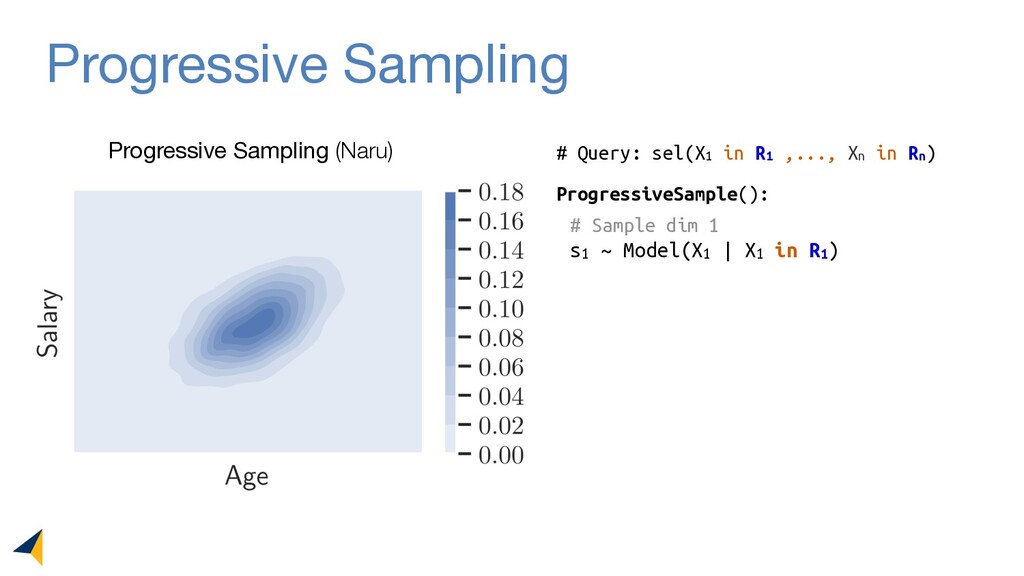
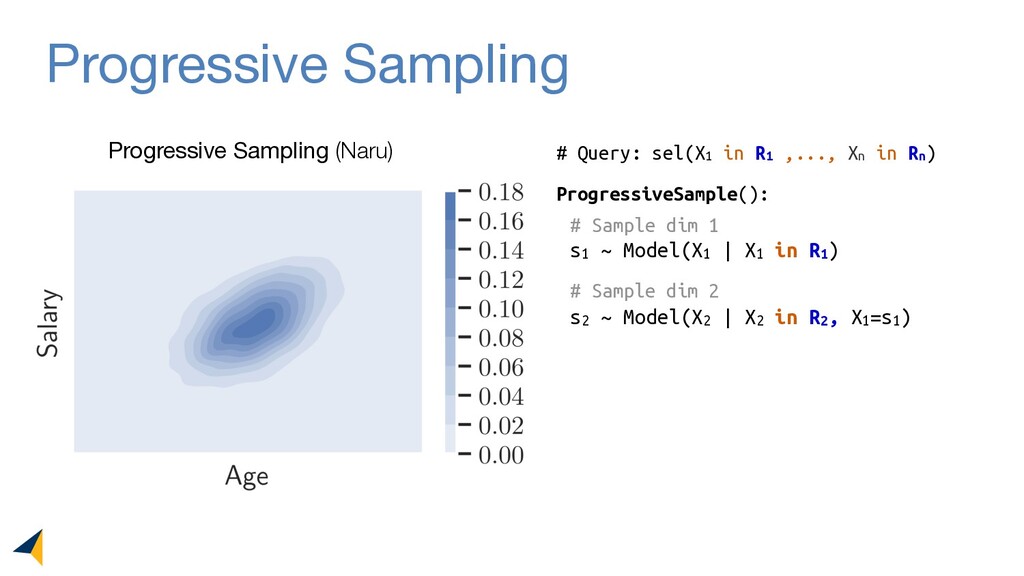
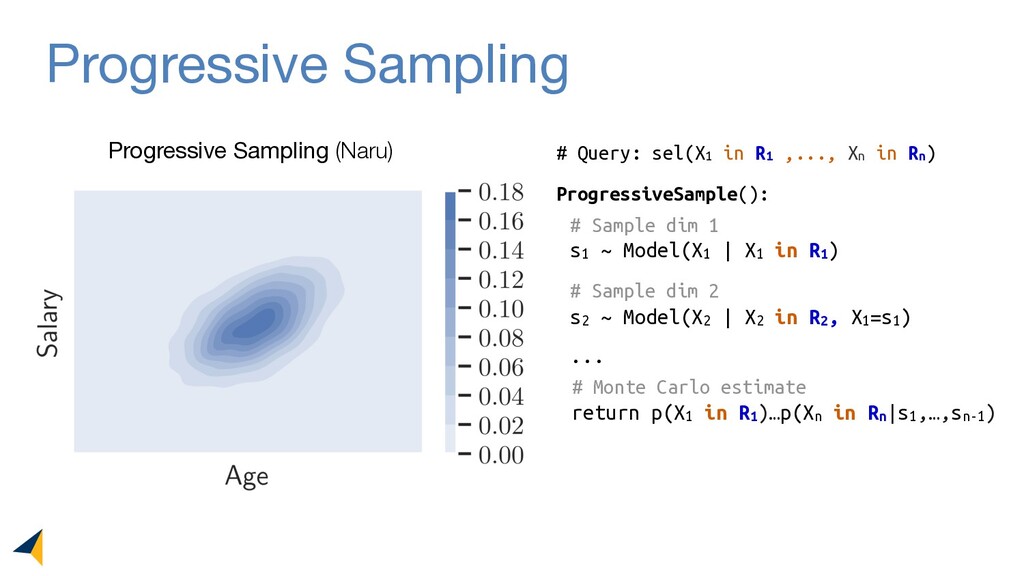
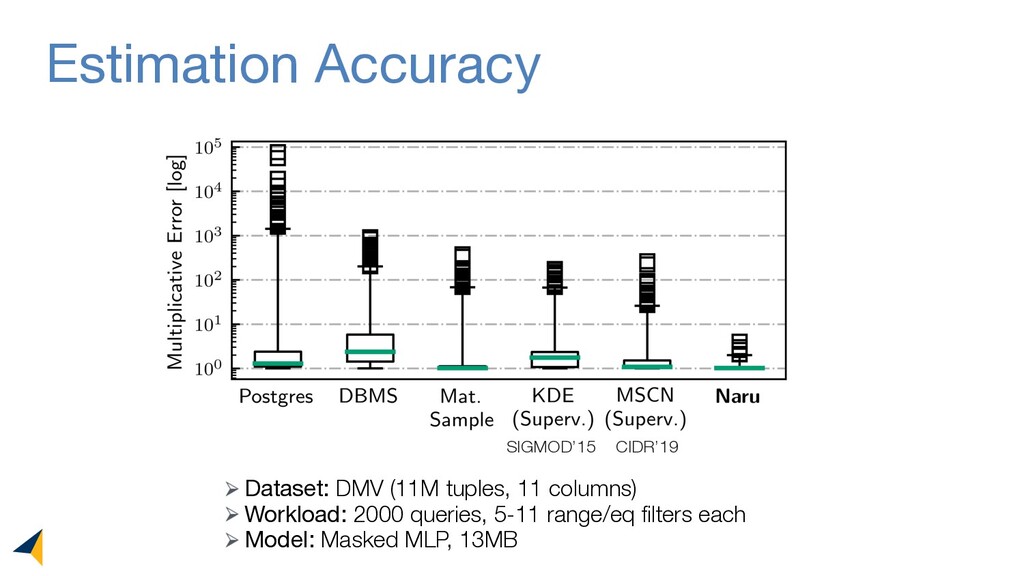
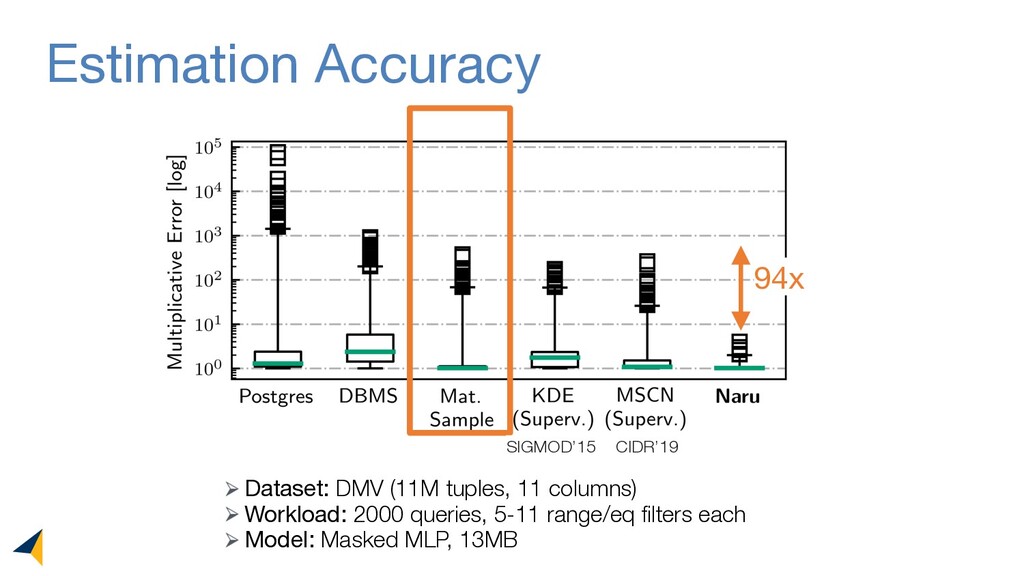
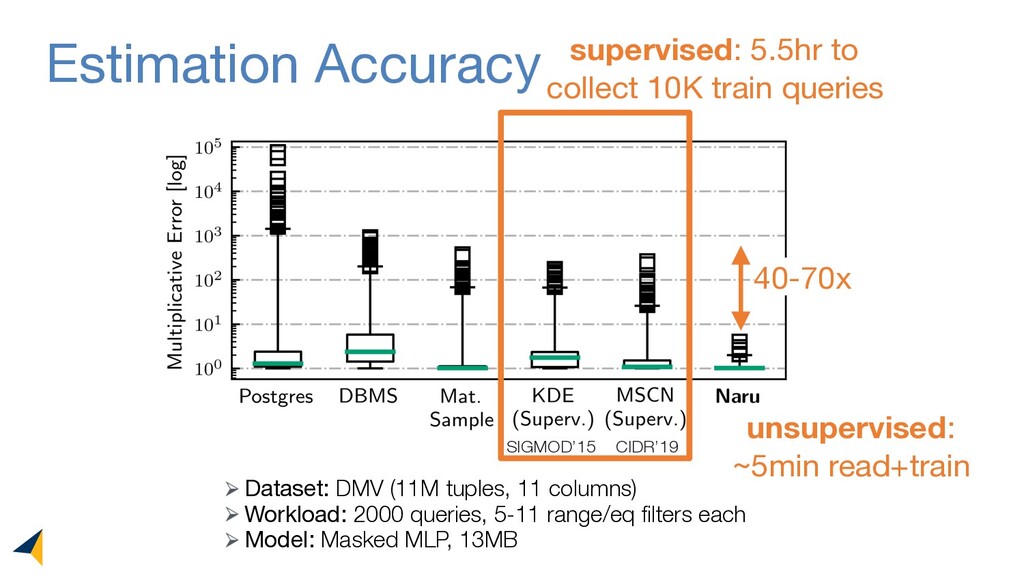
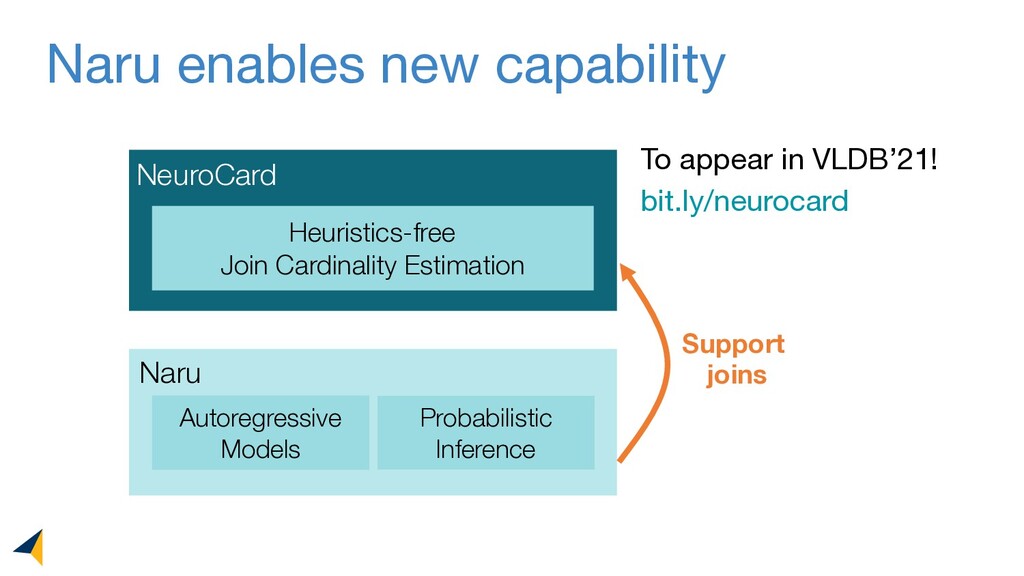
Leveraging deep unsupervised learning, Naru is a new cardinality estimator approach that fully removes heuristic assumptions in this decades-old problem in databases.
Presenter: Zongheng Yang (https://zongheng.me), @zongheng_yang.
Joint work with Eric Liang, Amog Kamsetty, Chenggang wu, Yan Duan, Xi Chen, Pieter Abbeel, Joe Hellerstein, Sanjay Krishnan, and Ion Stoica.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}