VLDB 2021
Paper: https://bit.ly/neurocard-pdf
Talk video: https://youtu.be/O2VoBHSyEpw
Code: https://github.com/neurocard/neurocard/
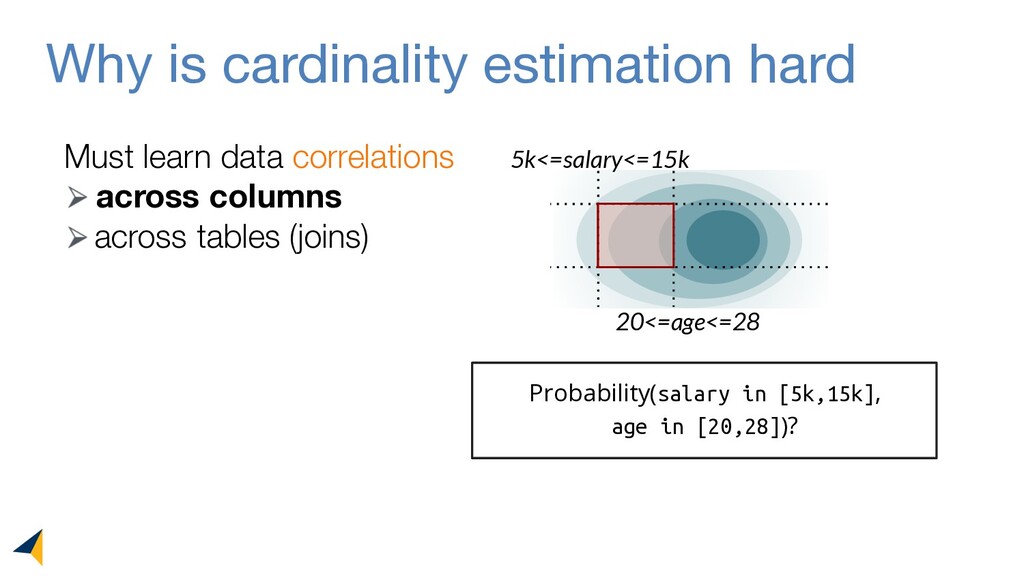
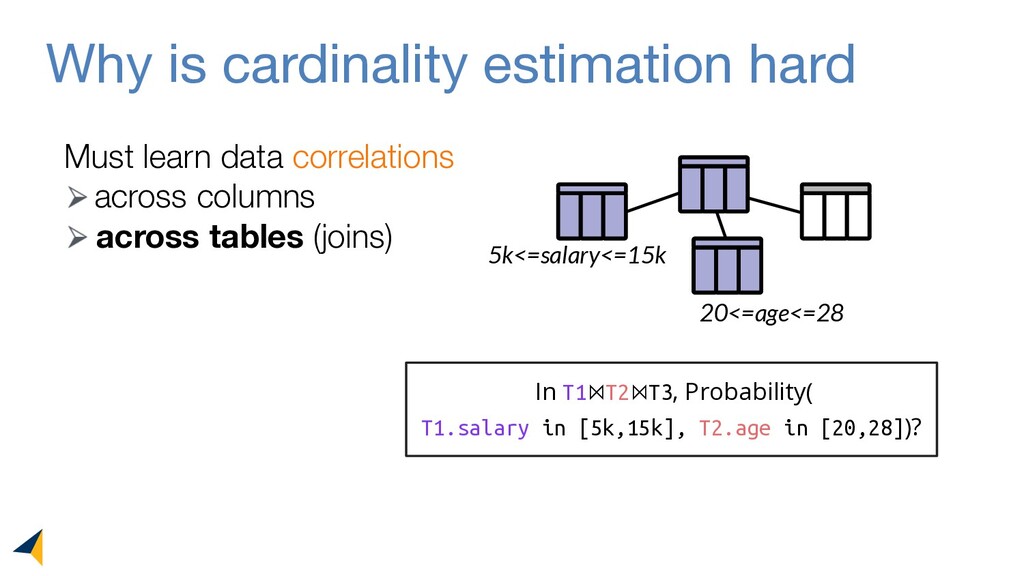
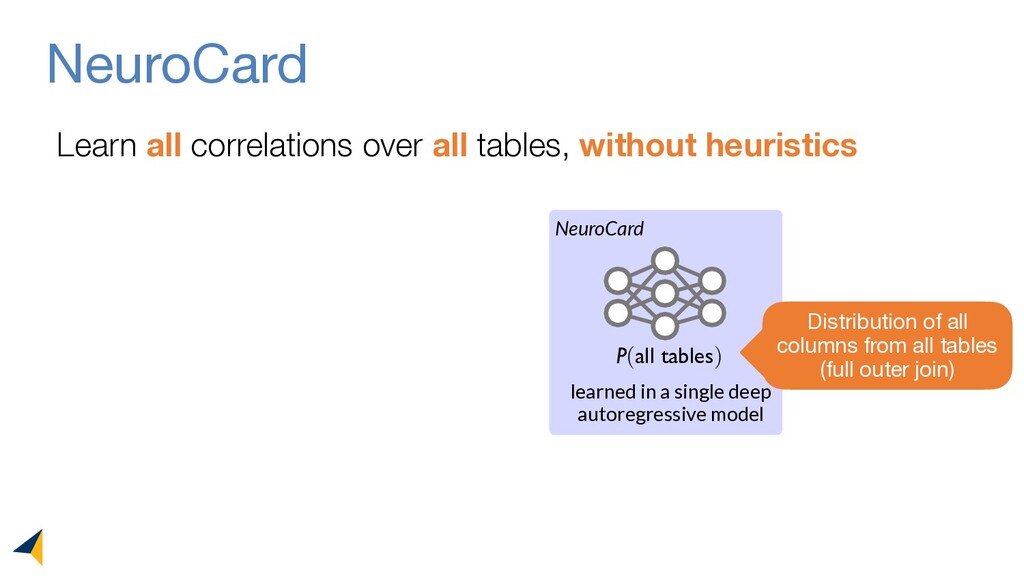
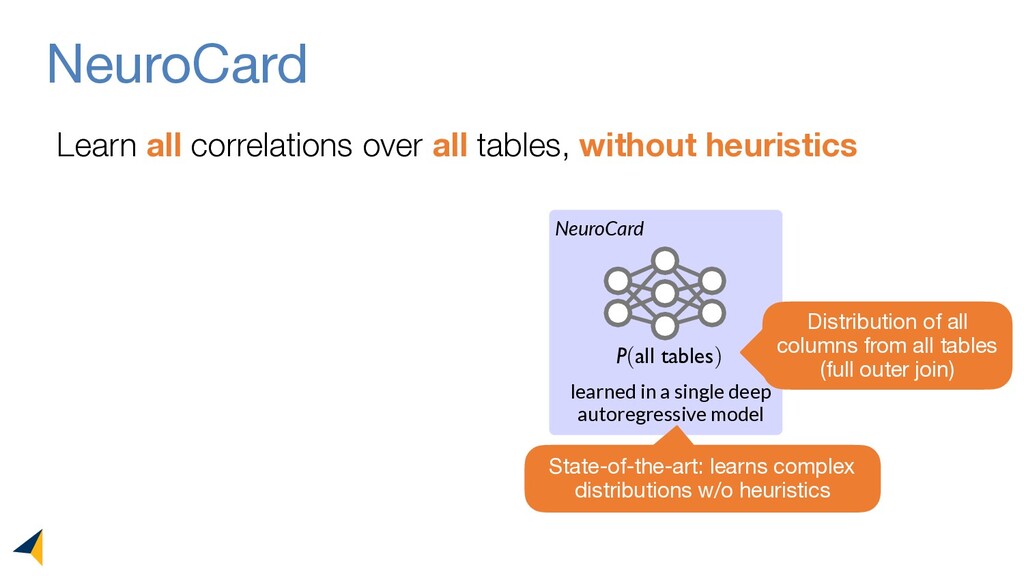
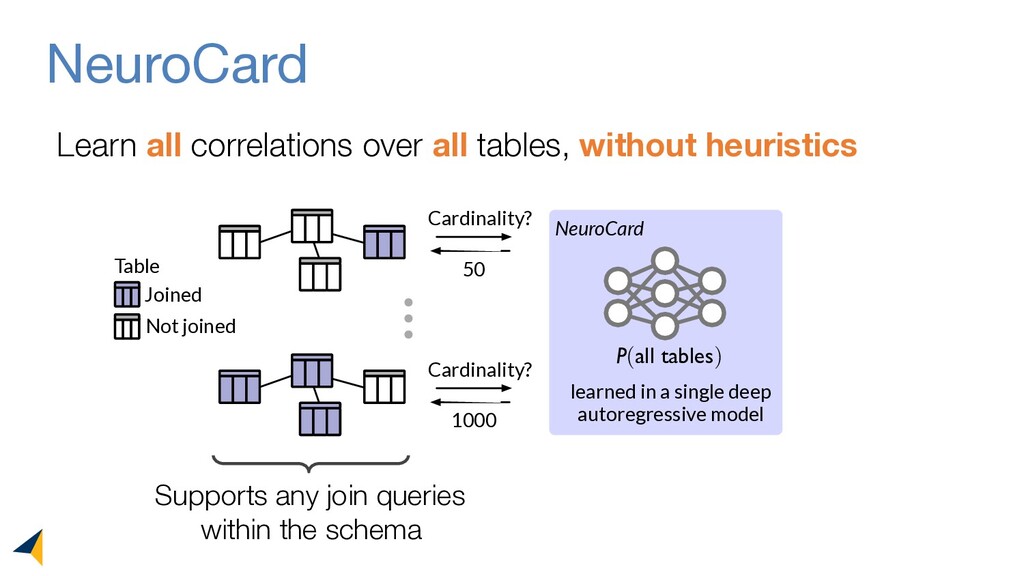
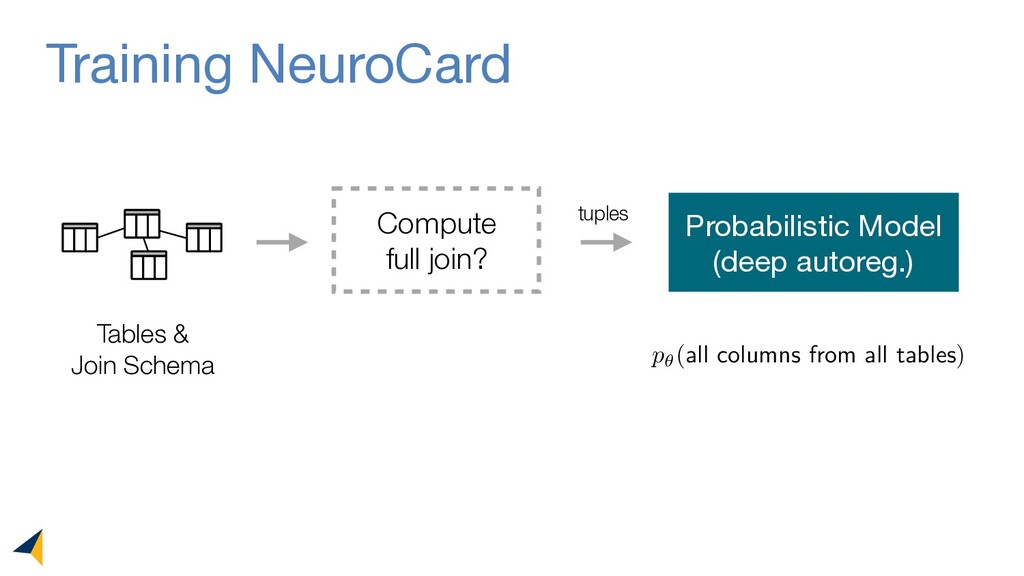
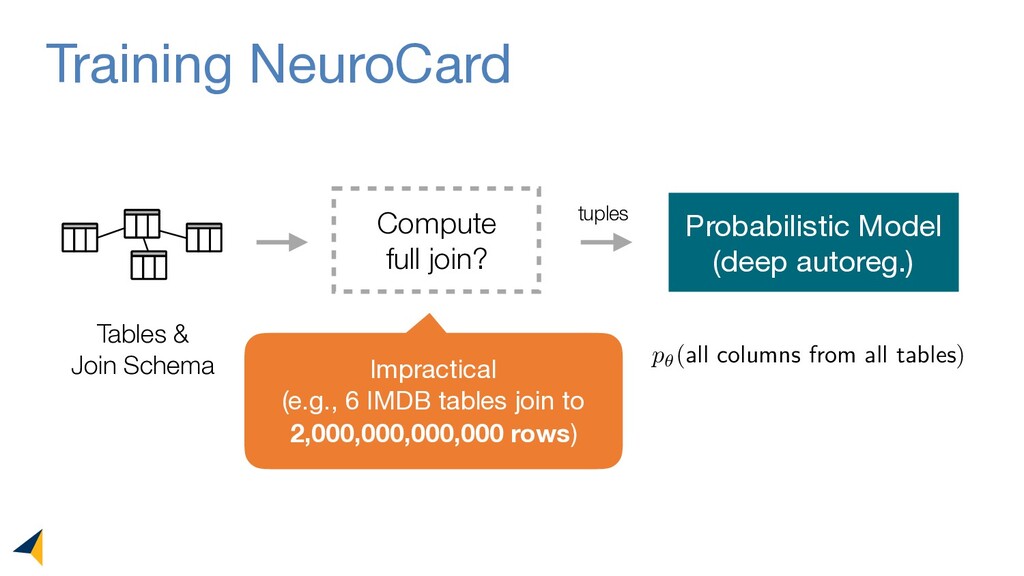
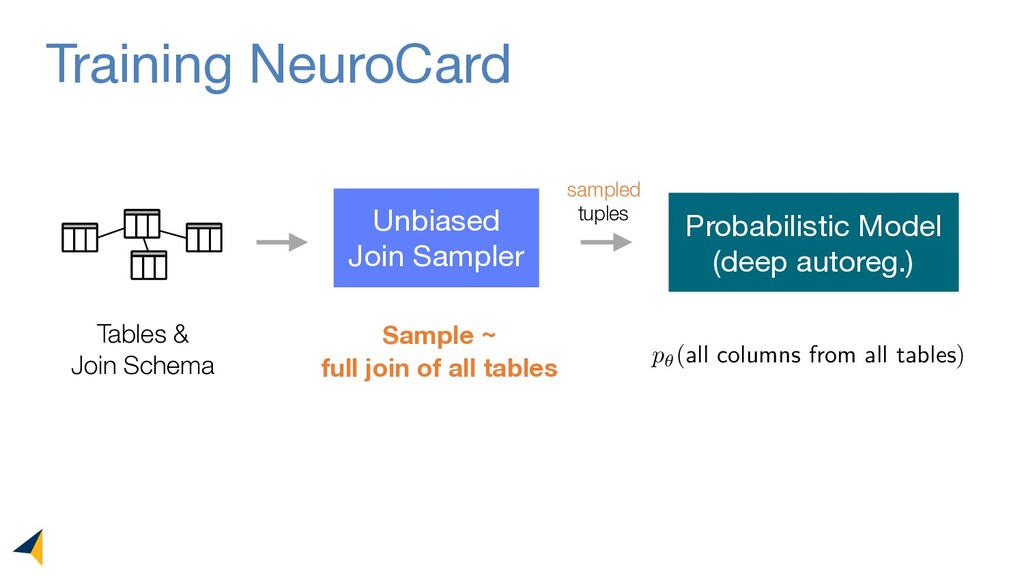
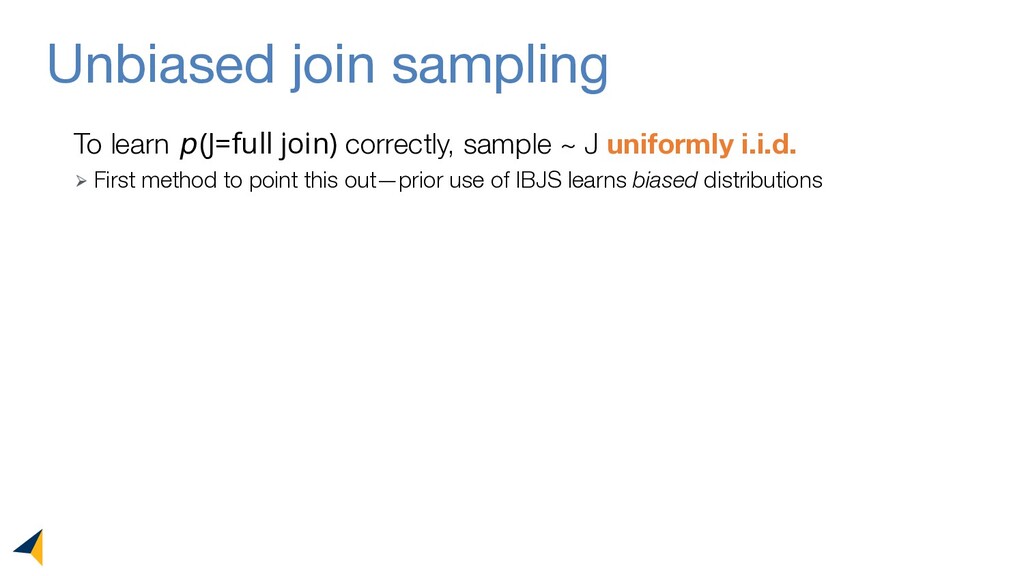
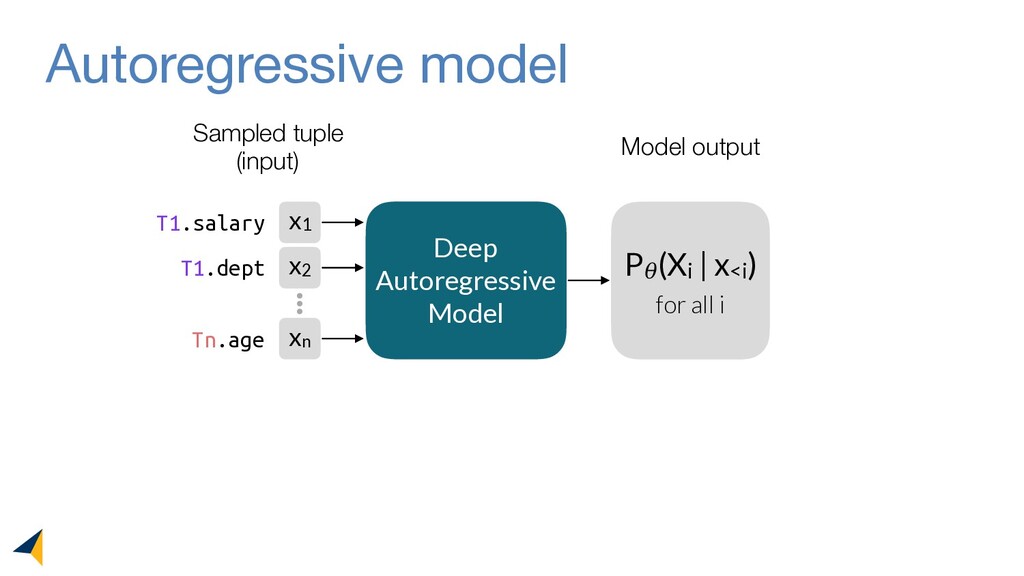
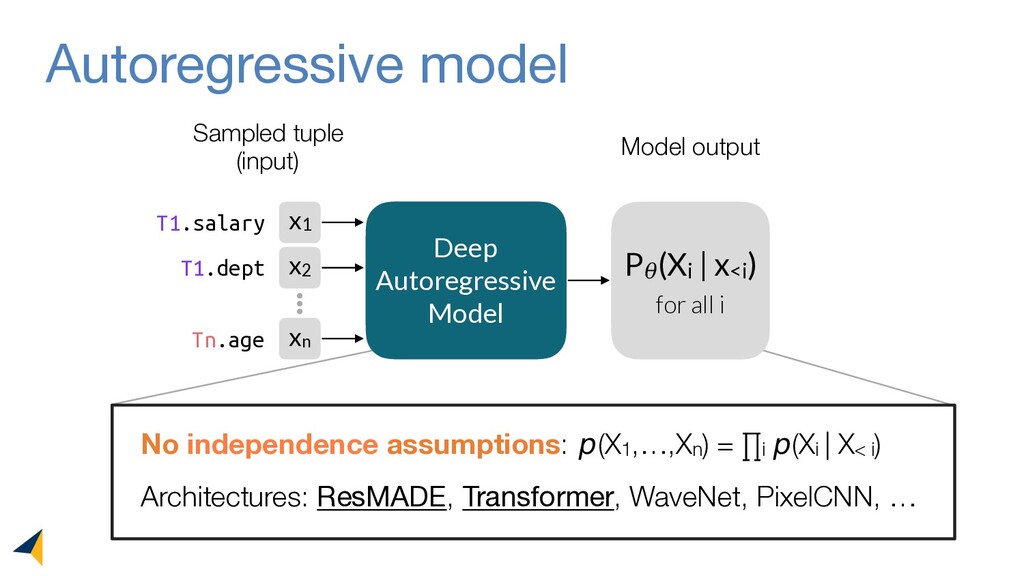
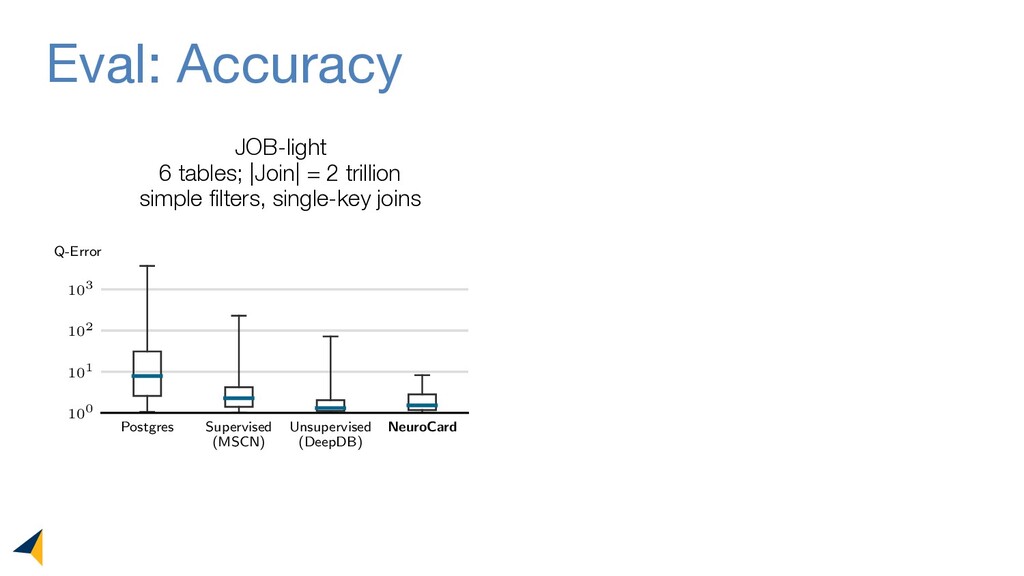
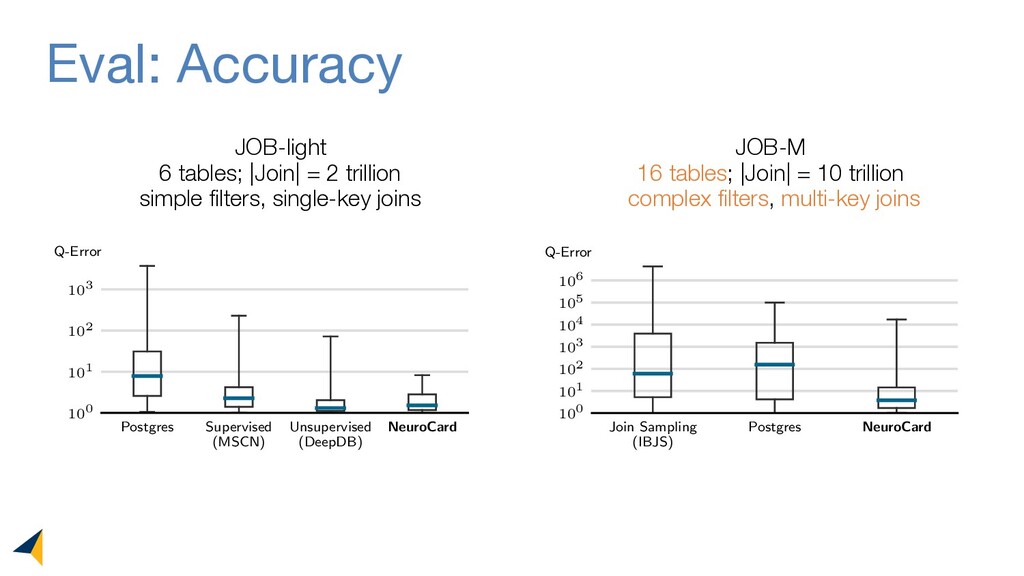
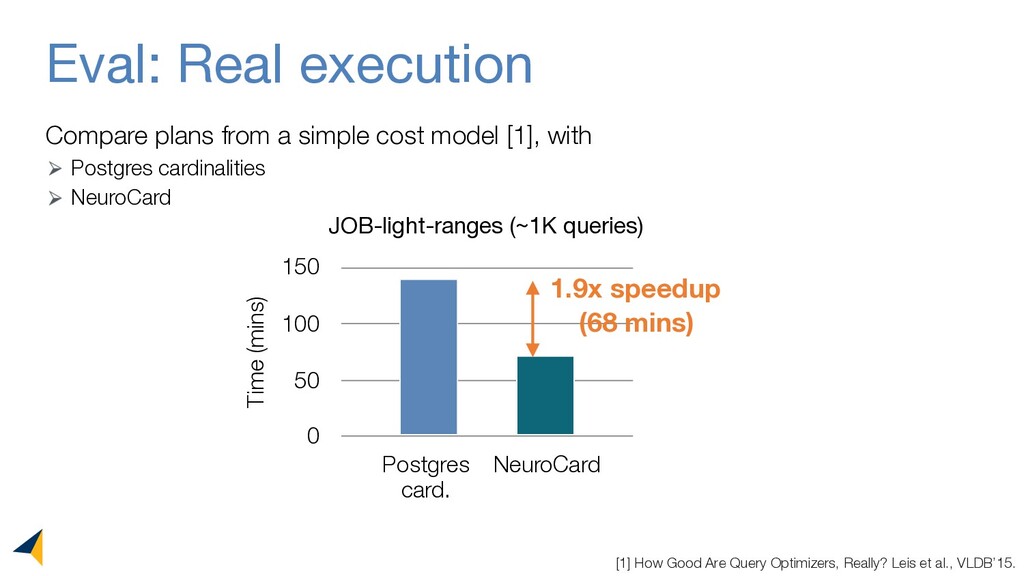
Query optimizers rely on accurate cardinality estimates to produce good execution plans. Despite decades of research, existing cardinality estimators are inaccurate for complex queries, due to making lossy modeling assumptions and not capturing inter-table correlations. In this work, we show that it is possible to learn the correlations across all tables in a database without any independence assumptions. We present NeuroCard, a join cardinality estimator that builds a single neural density estimator over an entire database. Leveraging join sampling and modern deep autoregressive models, NeuroCard makes no inter-table or inter-column independence assumptions in its probabilistic modeling. NeuroCard achieves orders of magnitude higher accuracy than the best prior methods (a new state-of-the-art result of 8.5x maximum error on JOB-light), scales to dozens of tables, while being compact in space (several MBs) and efficient to construct or update (seconds to minutes).
Presenter: Zongheng Yang (https://zongheng.me), @zongheng_yang.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}