Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
輪講資料: パタヘネ 6章
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
190ikp
April 21, 2023
Education
260
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
輪講資料: パタヘネ 6章
研究室の輪講用
190ikp
April 21, 2023
More Decks by 190ikp
See All by 190ikp
輪講資料: A Comprehensive Study on Off-path SmartNIC
190ikp
0
87
自宅鯖はいいぞ 〜InfiniBand編〜
190ikp
0
1.3k
Other Decks in Education
See All in Education
Protecting Patrons with Digital Vendors
dsalo
0
200
Tangible, Embedded and Embodied Interaction - Lecture 7 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
Stardy 会社紹介資料
stardy
0
340
Design Guidelines and Principles - Lecture 7 - Information Visualisation (4019538FNR)
signer
PRO
0
3.1k
プログラミング言語において文字列を複数行にわたって だらだらと記載するアレ
sapi_kawahara
0
160
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
Padlet opetuksessa
matleenalaakso
12
16k
勾配ブースティングと決定木の話 / gradient boosting and decision trees
kaityo256
PRO
6
1.3k
Lectura 1 (PIT : Python Basico)
robintux
0
360
Laura Wilson - The Quarterly PR Pivot
laurawilsonbseo1
1
340
From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features
mfcabrera
0
170
Catecismo 26 #2 - Do Credo; Introdução ao 1º artigo
cm_manaus
0
120
Featured
See All Featured
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
370
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
250
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Color Theory Basics | Prateek | Gurzu
gurzu
0
360
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
230
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Mind Mapping
helmedeiros
PRO
1
240
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
600
Transcript
パタヘネ輪講 6章 クライアントからクラウドまでの並列プロセッサ 植松 郁生
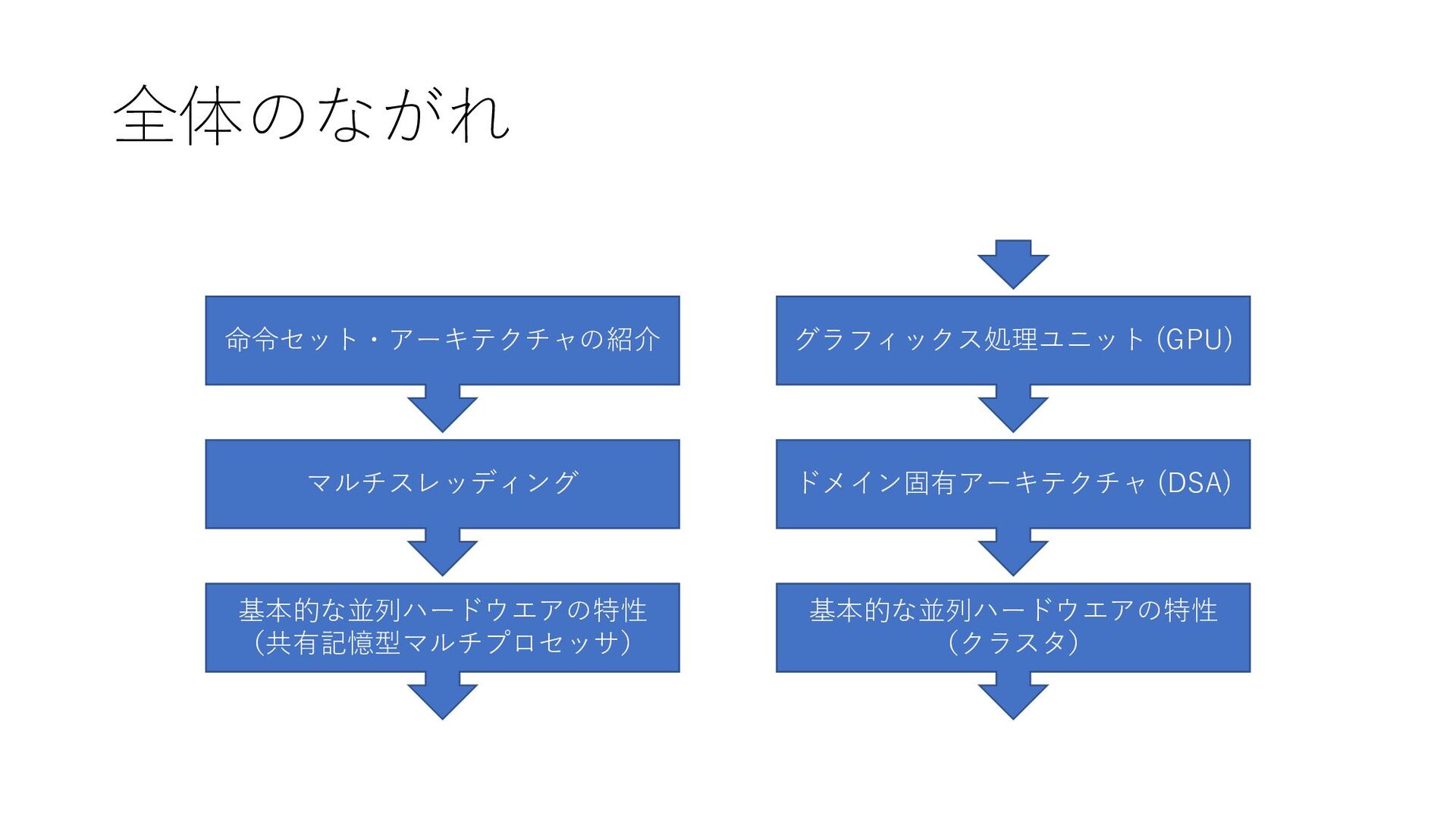
全体のながれ 命令セット・アーキテクチャの紹介 マルチスレッディング 基本的な並列ハードウエアの特性 (共有記憶型マルチプロセッサ) グラフィックス処理ユニット (GPU) ドメイン固有アーキテクチャ (DSA) 基本的な並列ハードウエアの特性
(クラスタ)
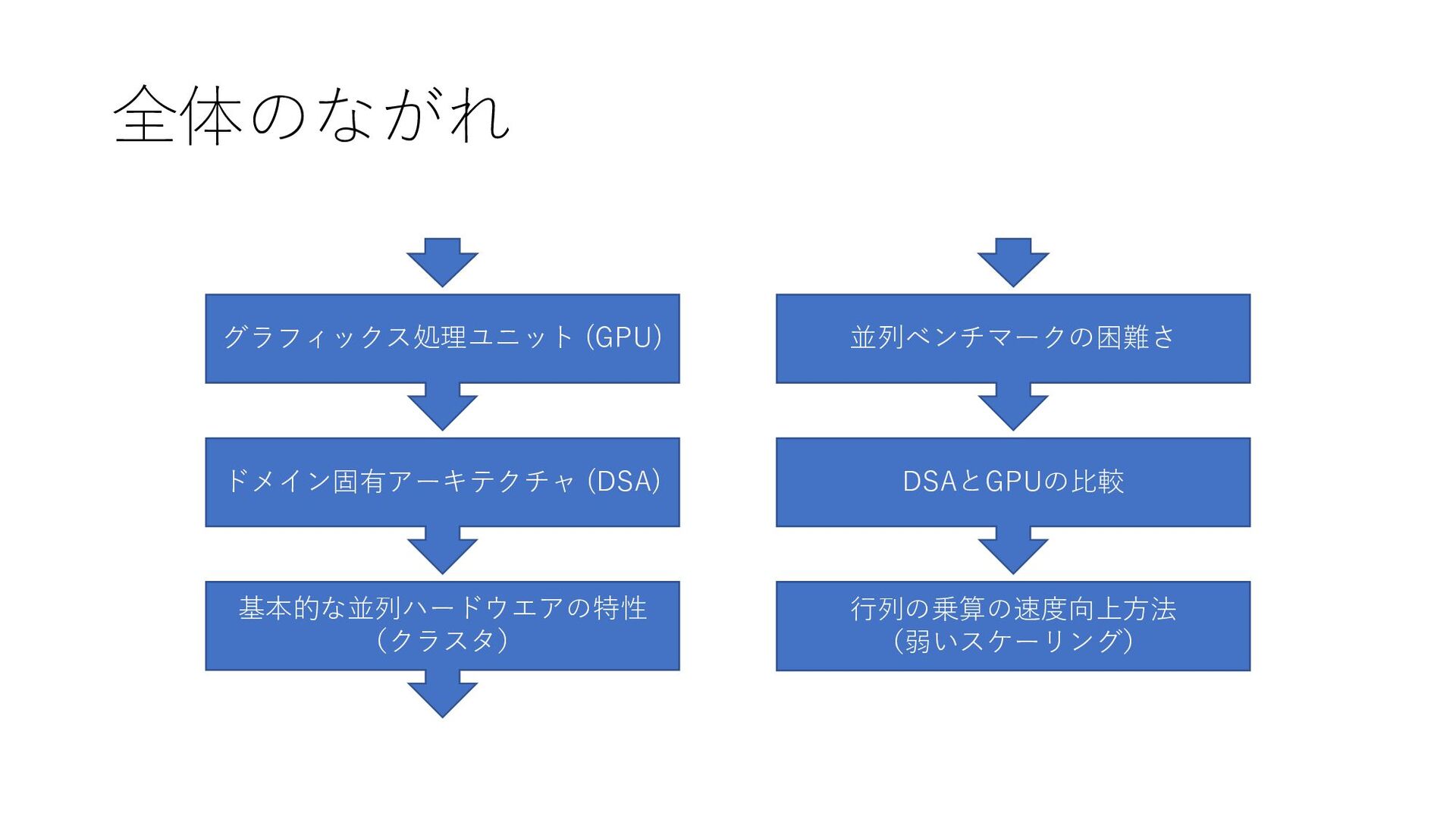
全体のながれ グラフィックス処理ユニット (GPU) ドメイン固有アーキテクチャ (DSA) 基本的な並列ハードウエアの特性 (クラスタ) 並列ベンチマークの困難さ DSAとGPUの比較 行列の乗算の速度向上方法
(弱いスケーリング)
6.1 はじめに
並列性 理想…既存の小型コンピュータを多数接続すると 1つの強力なコンピュータを実現(→マルチプロセッサ) 実現するためには: • 可変な数のプロセッサ上で実行できるようなソフトウェア設計 • 大型で低効率のプロセッサ→小型で高効率のプロセッサ×n個 への置換 →
電力効率,可用性の改善につながる
並列性の意味合い • タスク・レベル並列性(プロセス・レベル並列性) • 独立した複数のアプリケーションを単一のプロセッサで同時に処理 • 「大型で低効率のプロセッサ」 • 並列処理プログラム •
複数プロセッサで単一のプログラムを並列化 • 「小型で高効率のプロセッサ×n個」 • ex. クラスタ (多数の独立なサーバ上に搭載されたマイクロプロセッサ群で構成) → 「マルチプロセッサ・マイクロプロセッサ」 →「マルチコア・マイクロプロセッサ」
並列性の意味合い • マルチコア・チップではプロセッサ→コアと呼称 • 共有記憶型マルチプロセッサ (shared memory processor: SMP) を持つ
• コア間で単一の物理アドレス空間を共有しているため • 詳細は6.5 • ハードウエアだけでなくソフトウエアでの最適化も重要になる
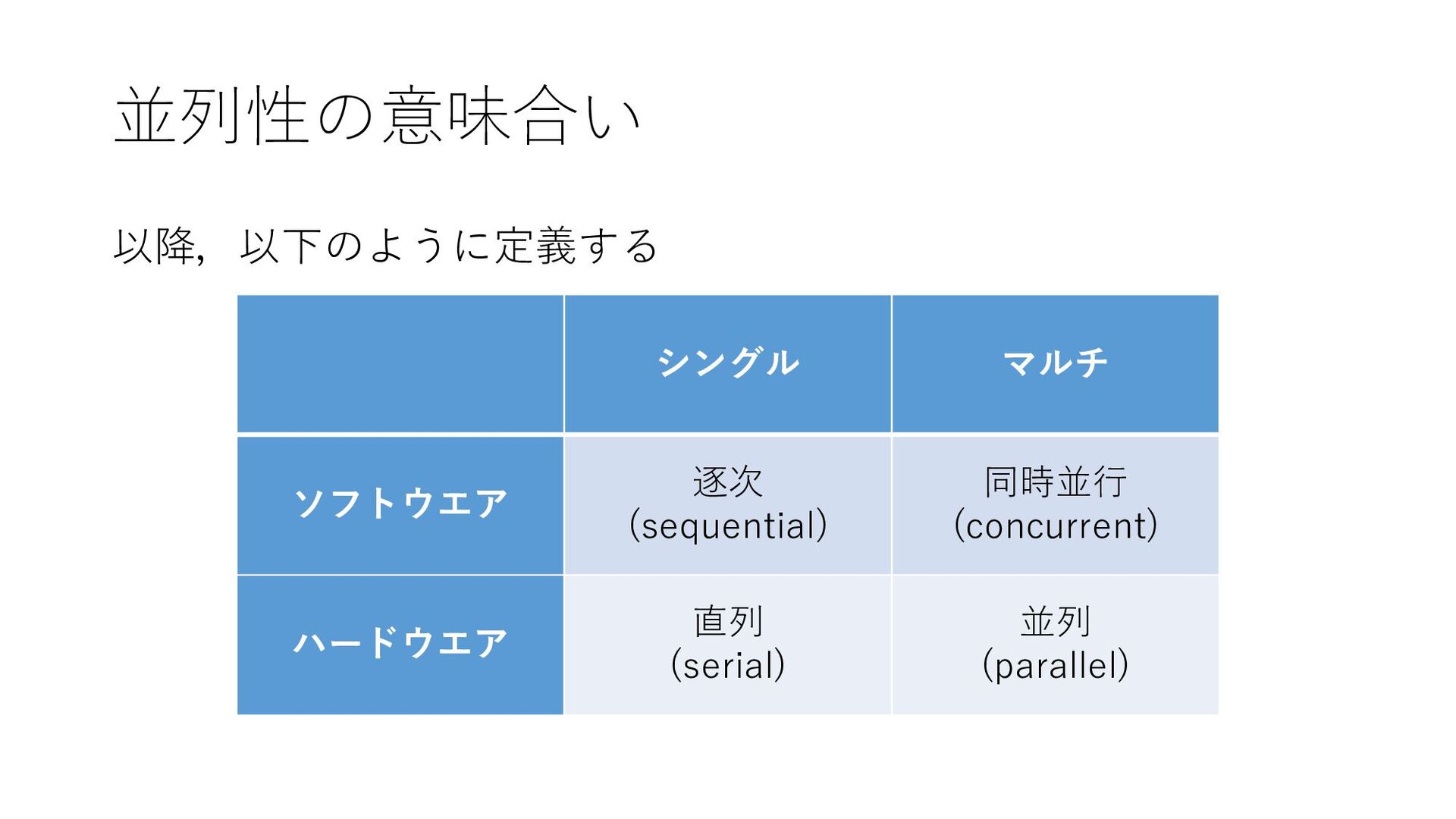
並列性の意味合い シングル マルチ ソフトウエア 逐次 (sequential) 同時並行 (concurrent) ハードウエア 直列
(serial) 並列 (parallel) 以降,以下のように定義する
並列性の意味合い
並列性の意味合い 並列処理における課題: • 逐次的なソフトウエアを並列ハードウエア上で高性能に実行 • 連想されがちなのはこちら • 同時並行なプログラムを並列ハードウエア上で高性能に実行 並列ハードウエア上で実行される逐次/同時並行ソフトウエア →
以降,「並列処理プログラム(並列ソフトウエア)」と呼称
6.2 並列処理プログラム作成 の困難さ
なぜ困難なのか? • マルチプロセッサ上の並列処理プログラムは • 優れた性能 • エネルギー効率 を実現しなくてはならない 実現できない場合… ユーザはこれまでどおり
(実装が容易な)直列ハードウエア上での逐次処理を選択する • e.g. スーパースカラ,アウトオブオーダー実行
なぜ困難なのか? • プロセッサ数の増大により 高速な並列処理プログラムを書くことは困難に • タスクの分割・スケジューリング • プロセッサ間での負荷の平準化・同期処理 • プロセッサ間のすり合わせにかかるオーバヘッド
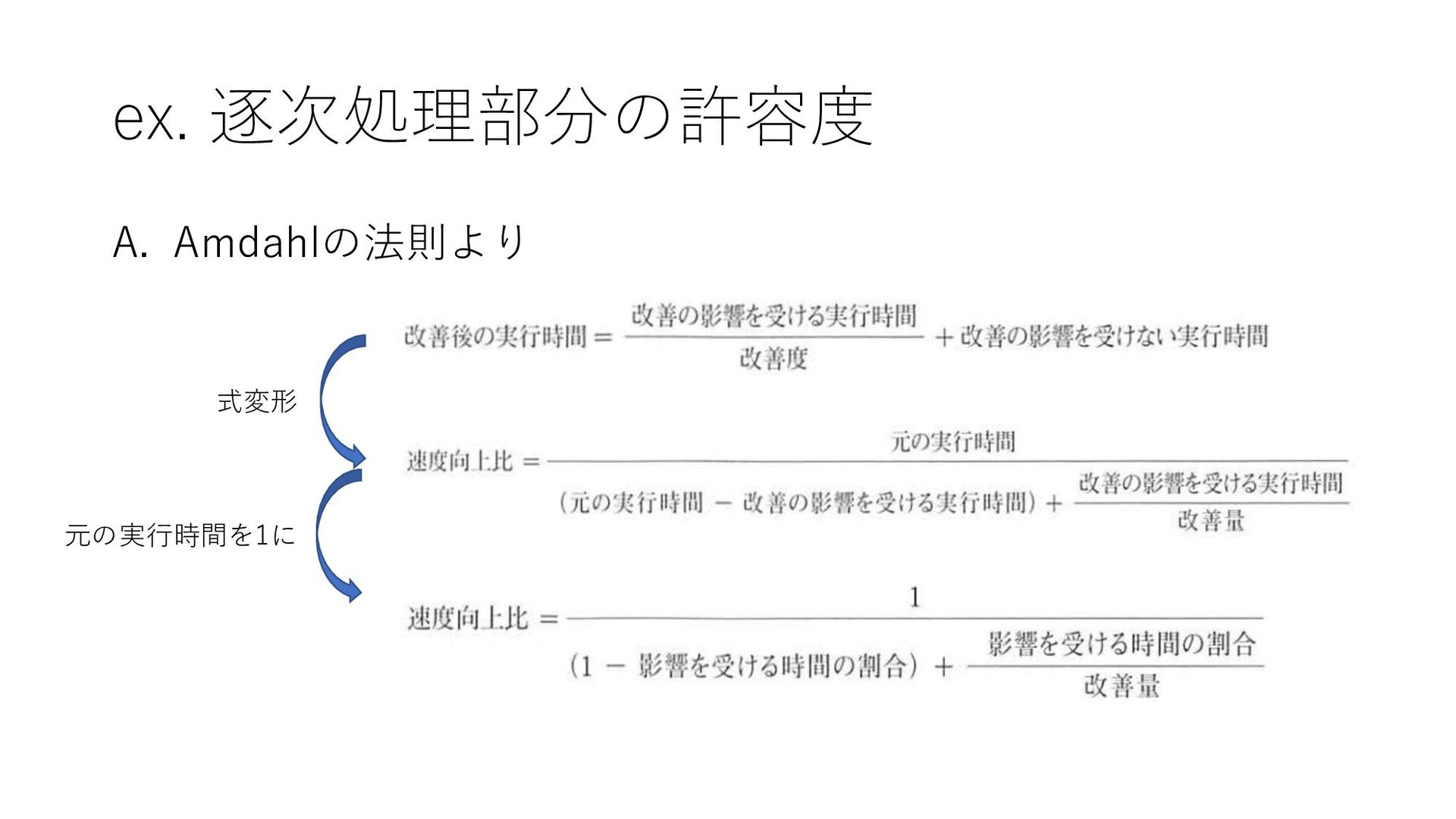
これらを考慮する必要がある • 多くのプロセッサをまんべんなく有効活用するためには プログラムの細部に至るまで並列化が必要 • Amdahlの法則 (1.10)
ex. 逐次処理部分の許容度 Q. プロセッサ数を100個に増やして速度を90倍にする 逐次処理部分は元のプログラムの何%まで許容されるか?
ex. 逐次処理部分の許容度 A. Amdahlの法則より 式変形 元の実行時間を1に
ex. 逐次処理部分の許容度 A. 影響を受ける時間の割合=0.999 →逐次処理部分は0.1%しか許容されない
強いスケーリング / 弱いスケーリング • 強いスケーリング • 問題の規模を固定したままで達成される速度向上 • より困難 •
弱いスケーリング • プロセッサ数の増大に比例して問題の規模も拡大 • 通常は比較的容易に達成可能 • 記憶階層によってはより困難になる (データセットが最下位レベルのキャッシュから溢れる場合など) プロセッサあたりのメモリ量は強いスケーリングなら×1/プロセッサ数
強いスケーリング / 弱いスケーリング • アプリケーションの種類に応じて適切な方を選択 ex. TPC-Cによる現金/信販数データベース・ベンチマーク • 時間当たりのトランザクション数を増やすには… •
顧客一人当たりのトランザクション数を増やす(強いスケーリング) ↑現実に即していない • 顧客数を増やす(弱いスケーリング)
負荷平準化 各プロセッサの負荷を平準化しないと… ex. 40個のプロセッサのうち1個だけに負荷が集中した場合 • 負荷を平準化した場合: 速度向上比=20.5 • 他のプロセッサの2倍の処理を担った場合: 速度向上比=14
• 他のプロセッサの5倍の処理を担った場合: 速度向上比=7 システムの利用効率は大きく低下する
6.3 SISD, MIMD, SIMD, SPMD, ベクトル
並列ハードウエアの分類 • メモリ空間に着目した分類方法 • 共有記憶型,分散記憶型 • ハードウエアの均質性に着目した分類方法 • ホモジニアス型,ヘテロジニアス型 •
命令流とデータ流に着目した分類方法 • SISD,SIMD,MISD,MIMD • ここではこの分類方法について取り上げる
並列ハードウエアの分類 命令流(instruction stream)とデータ流(data stream)の数で分類 e.g. single instruction stream, single data
stream: SISD multiple instruction stream, multiple data stream: MIMD
並列ハードウエアの分類 SPMD (single program multiple data) • ex. MPI (message
passing interface) • 並列処理プログラム作成時のプログラミング・モデルの1種 • MIMD型コンピュータ上で動作するプログラムで通常採用 • 各プロセッサが同じ処理を行う • 各プロセッサが主記憶に持つデータセットは異なる
並列ハードウエアの分類 MISDプロセッサは実在しない (単一のデータセットに対して同時に読み書きが発生するので) →近い存在: ストリーム・プロセッサ • 単一のデータストリームに対してパイプライン(≒逐次)方 式で一連の計算を実行 • 突き詰めるとほぼMIMD
並列ハードウエアの分類 SIMD • アレイ・プロセッサ(ベクトルプロセッサ)から着想 • ex. NEC SXシリーズ • データ流のベクトル(1次元配列)を
単一のプログラム・カウンタからの単一命令で操作 これに対してすべての並列実行ユニットが同期して応答する • ex. 単一のSIMD型命令で64組の数値の加算を行う場合 1. 64本のデータ流を64個のALUにそれぞれ送信 2. 単一のクロック・サイクルで64個の和すべてを計算
SIMD • プログラマから見ると従来のSISD型とほぼ変わらない • コンパイラから見ると変わる (SISD,SIMD向けで別々にコンパイルされる) • 並列実行ユニット毎に別々のアドレス・レジスタを持つため • 複数の並列実行ユニットを1つの制御ユニット下で動かす
→制御ユニットのコスト低減 • 同時に実行されるコードのコピーは1つだけ →命令のバンド幅と(キャッシュ)空間が小さく済む • MIMDではプロセッサ毎にコードのコピーが必要→コスト増
SIMD • forループで高い性能を発揮 • 同一の構造を有する大量のデータの処理=データ・レベル並列性 • データ・レベル並列性: 独立したデータ群に 同一処理を行うことによって得られる並列性 (部分語並列性
(3.6)) • 条件分岐は苦手 • 各実行ユニットによって実行する命令が異なってくるため • 条件分岐による場合の数nに対してSIMDプロセッサの実効性能は1/n
SIMDのマルチメディア拡張 • 幅の狭い整数・浮動小数点データにはデータ・レベル並列性がある • マルチメディア・アプリケーションで利用されがち →SIMD命令で並列化 • x86においては マルチメディア機能拡張 (MMX)
ストリーミングSIMD拡張 (Streaming SIMD Extensions: SSE) ベクトル拡張 (Advanced Vector Extensions: AVX)
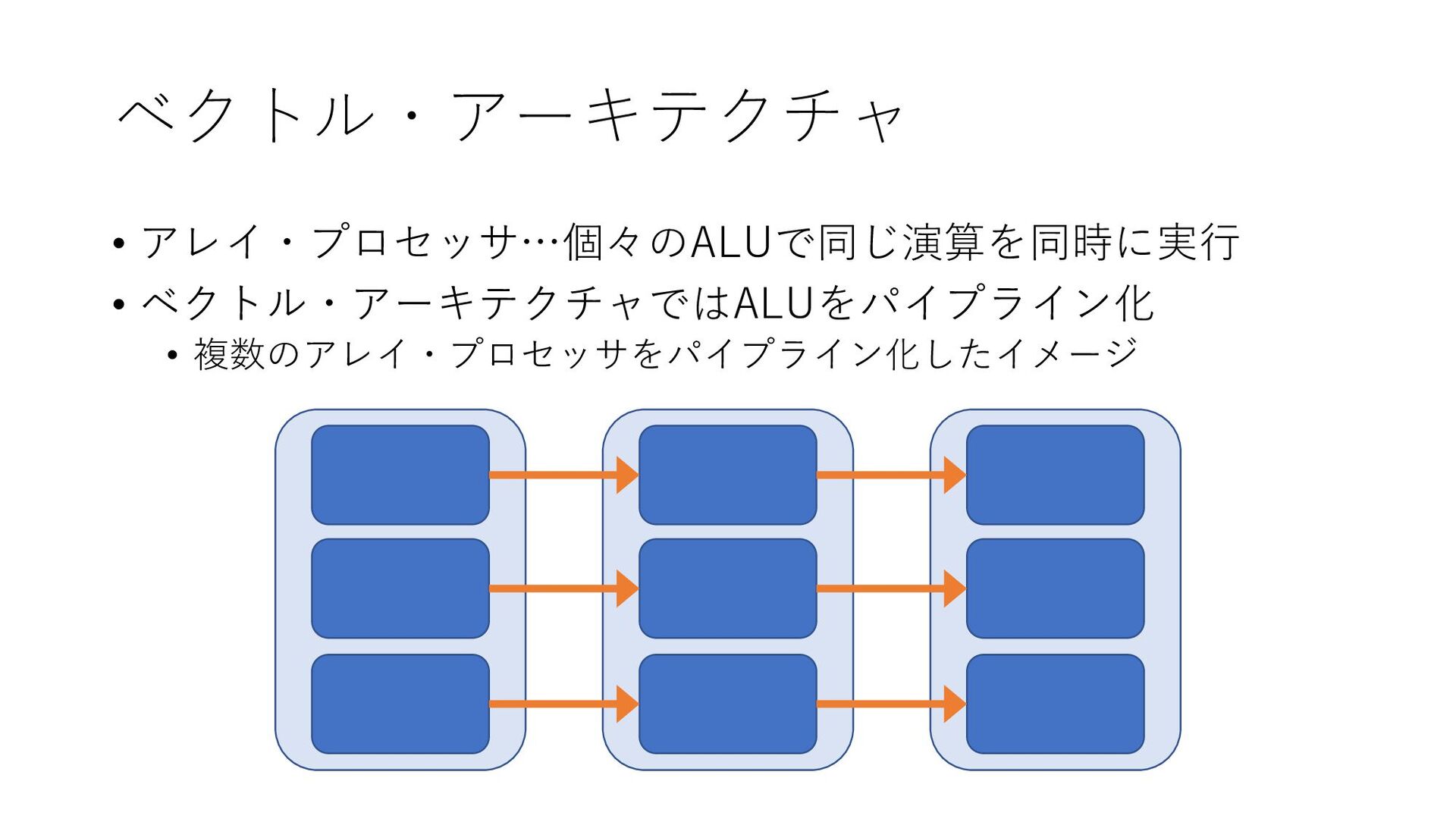
ベクトル・アーキテクチャ • アレイ・プロセッサ…個々のALUで同じ演算を同時に実行 • ベクトル・アーキテクチャではALUをパイプライン化 • 複数のアレイ・プロセッサをパイプライン化したイメージ
ベクトル・アーキテクチャ 処理の流れ 1. 主記憶からデータ要素を収集 2. データセットをベクトル・レジスタ群に格納 3. パイプライン方式の実行ユニットによりデータを逐次処理 4. 処理結果を主記憶に書き戻す
ベクトル対スカラ ex. 倍精度浮動小数点数64個のベクトルX, Yの加算 𝑌 = 𝑎 × 𝑋 +
𝑌 • 動的な命令のバンド幅 (実行される命令数) が大きく削減できる • スカラ命令を繰り返し実行 = 単一のベクトル命令の実行 • オーバヘッド関連の命令が存在しない • 終了判定,インデックス繰り上げ,残ループ数計算,etc... • 場合によってはループ処理の半分近くを占める
ベクトル対スカラ その他の利点 • パイプライン・ハザードの発生頻度低減 • ベクトル内の各要素の計算結果は独立 • ハードウエアによる要素毎のデータ・ハザードのチェックが不要 • 必要なのはベクトル命令間でのデータ・ハザードのチェックのみ
• ループ始点に戻る分岐によって発生する制御ハザードが存在しない • メモリアクセスのコスト低減 • コスト (レイテンシ) がかかるのがデータ要素単位 → ベクトル単位へ → 消費電力およびエネルギーの面で有利
ベクトル対マルチメディア機能拡張 マルチメディア機能拡張 • 複合した1つの操作を指定 • ベクトルの長さ (複合操作数) 毎に命令操作コード群が存在 ベクトル命令 •
単純な操作を複数指定 • ベクトルの長さは可変長 • 演算対象の要素数は別建てのレ ジスタ群に格納 • レジスタを書き換えるだけで OK • コンパイラ技術と相性が良い • 将来的な発展 (機能拡張) がさ せやすい
ベクトル対マルチメディア機能拡張 マルチメディア機能拡張 • データ要素が隣接している必 要がある ベクトル命令 • データ要素が隣接している必 要なし •
ストライド型アクセス • インデックス修飾アクセス の両方をサポート
ベクトル対マルチメディア機能拡張 • ストライド型アクセス • 主記憶内のデータ要素を飛び飛びでロードする • インデックス修飾アクセス • ベクトル・レジスタにロードするデータ要素のアドレスを算出して ロード
• 収集・拡散ともいう • 収集…主記憶から要素を取集して一連の連続したベクトル要素としてロード • 拡散…ベクトル要素を主記憶中に拡散してストア
ベクトル対マルチメディア機能拡張 パイプラインを並列にすることで性能向上が可能 ex. 加算命令 (a) パイプライン1本のみ → 9サイクル必要 (b) パイプラインを4本に
→ 2サイクルで完了!
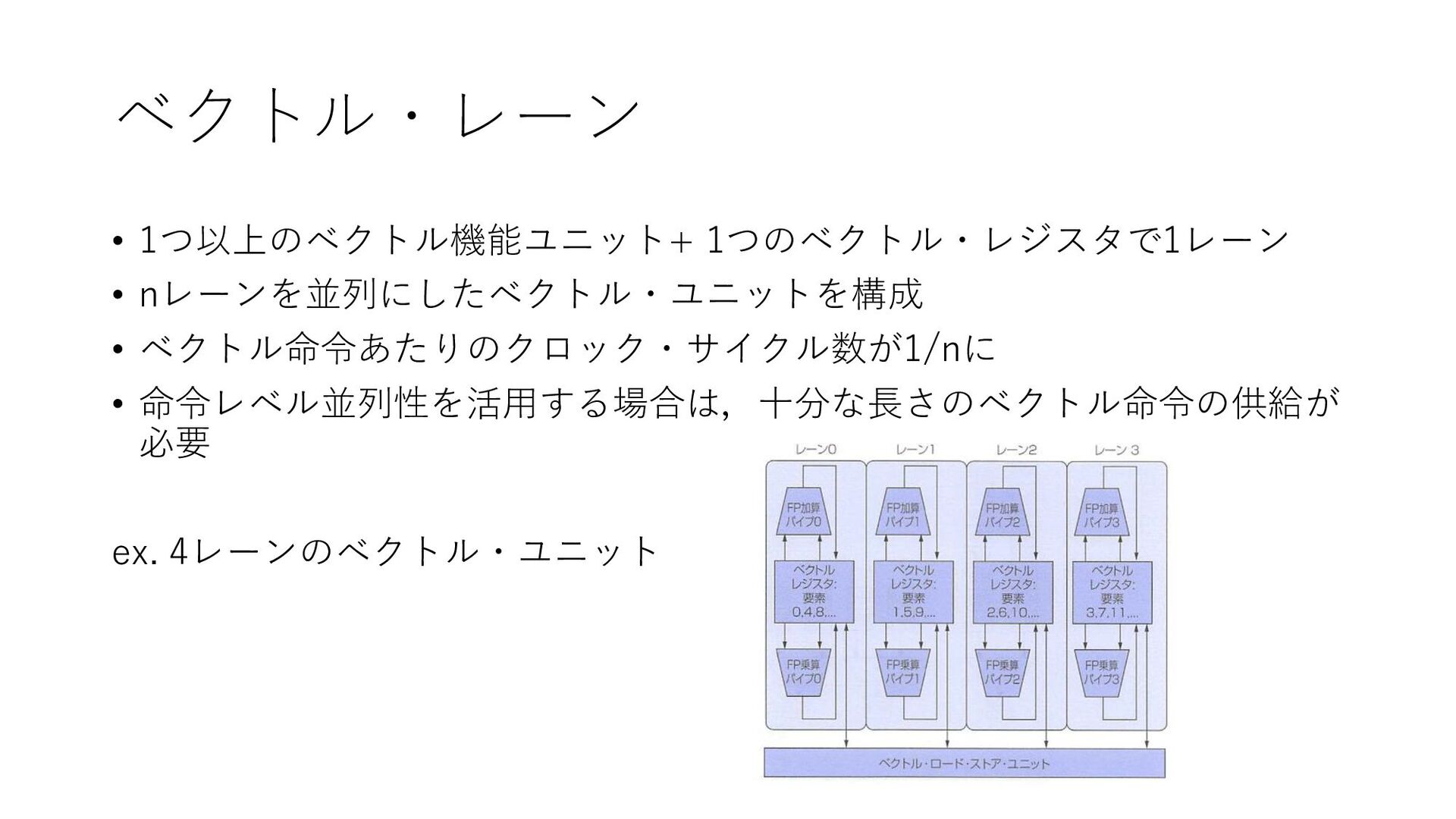
ベクトル・レーン • 1つ以上のベクトル機能ユニット+ 1つのベクトル・レジスタで1レーン • nレーンを並列にしたベクトル・ユニットを構成 • ベクトル命令あたりのクロック・サイクル数が1/nに • 命令レベル並列性を活用する場合は,十分な長さのベクトル命令の供給が
必要 ex. 4レーンのベクトル・ユニット
6.4 ハードウエア・ マルチスレッディング
ハードウエア・マルチスレッディング MIMD: • 複数のプロセスまたはスレッドを利用して複数のプロセッサを作動 ハードウエア・マルチスレッディング: • 複数のスレッドが単一プロセッサ内の機能ユニットを共有
ハードウエア・マルチスレッディング • プロセッサが各スレッドの独立な状態 (ステート) をコピー • レジスタ・ファイル,プログラム・カウンタ • メモリは仮想記憶の仕組みを利用することでスレッド間共有 •
ハードウエア側でのスレッド切替の高速な処理が必要
細粒度 / 粗粒度マルチスレッディング 細粒度 (fine-grained) マルチスレッディング: • 命令毎にスレッド切替が発生,複数のスレッドを満遍なく実行 • 切替先スレッドの選択はラウンドロビン方式が多い
• 切替時のクロック・サイクルでストールしているスレッドはスキップ Pros: • 長時間・短時間どちらのストールにも対応可能 Cons: • 他のスレッドからの切替で待機するスレッドが発生 →個々のスレッドの実行に時間がかかる
細粒度 / 粗粒度マルチスレッディング 粗粒度 (coarse-grained) マルチスレッディング: • 現行のスレッドで長時間のストールが発生した場合にスレッド切替 (最下位 レベルでのキャッシュミスなど)
Pros: • スレッドの高速な切替が不要 • 他のスレッドからの切替を待機する必要がなくなる →個々のスレッドの実行が遅くなる可能性を低減 Cons: • 短時間のストールには対応できない → 全体のスループット低下 • 切替には既存のパイプラインを空にするか一時凍結する必要があるため →切替先のパイプライン起動に時間がかかる • 長時間のストールであればスレッド切替するだけの価値がある
同時マルチスレッディング 同時マルチスレッディング (simultaneous multithreading: SMT) • 命令レベル並列性 (ILP),スレッドレベル並列性 (TLP)を活用 •
独立した別々のスレッドから複数の命令を発行可能 • レジスタ・リネーミングと動的スケジューリングを活用 • 命令間の依存関係は考慮しなくてOK • クロック・サイクル単位でのリソース切替は無し • 命令スロットとリネーミングされたレジスタに適切なスレッド を対応づける処理はハードウエアが担当
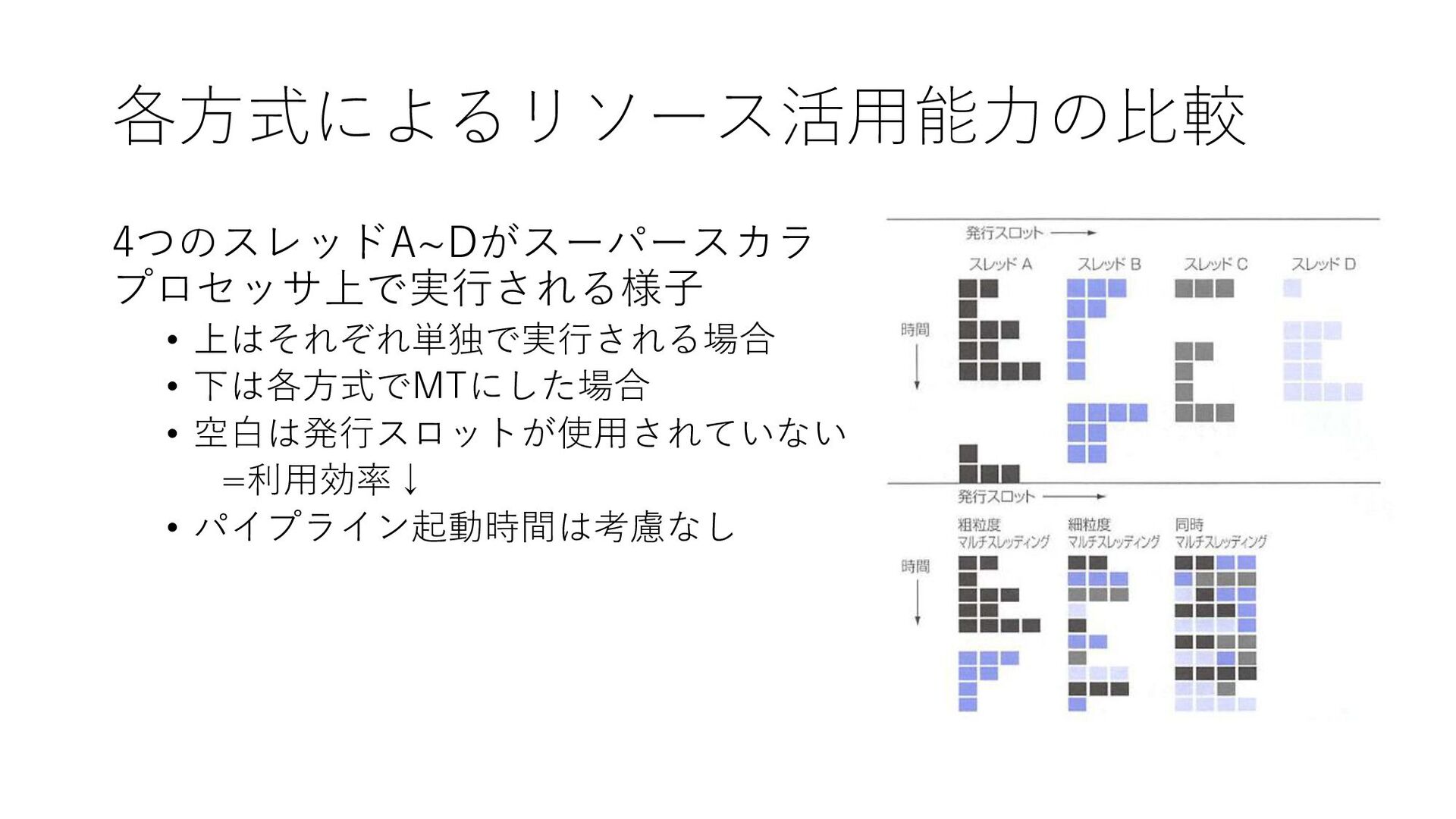
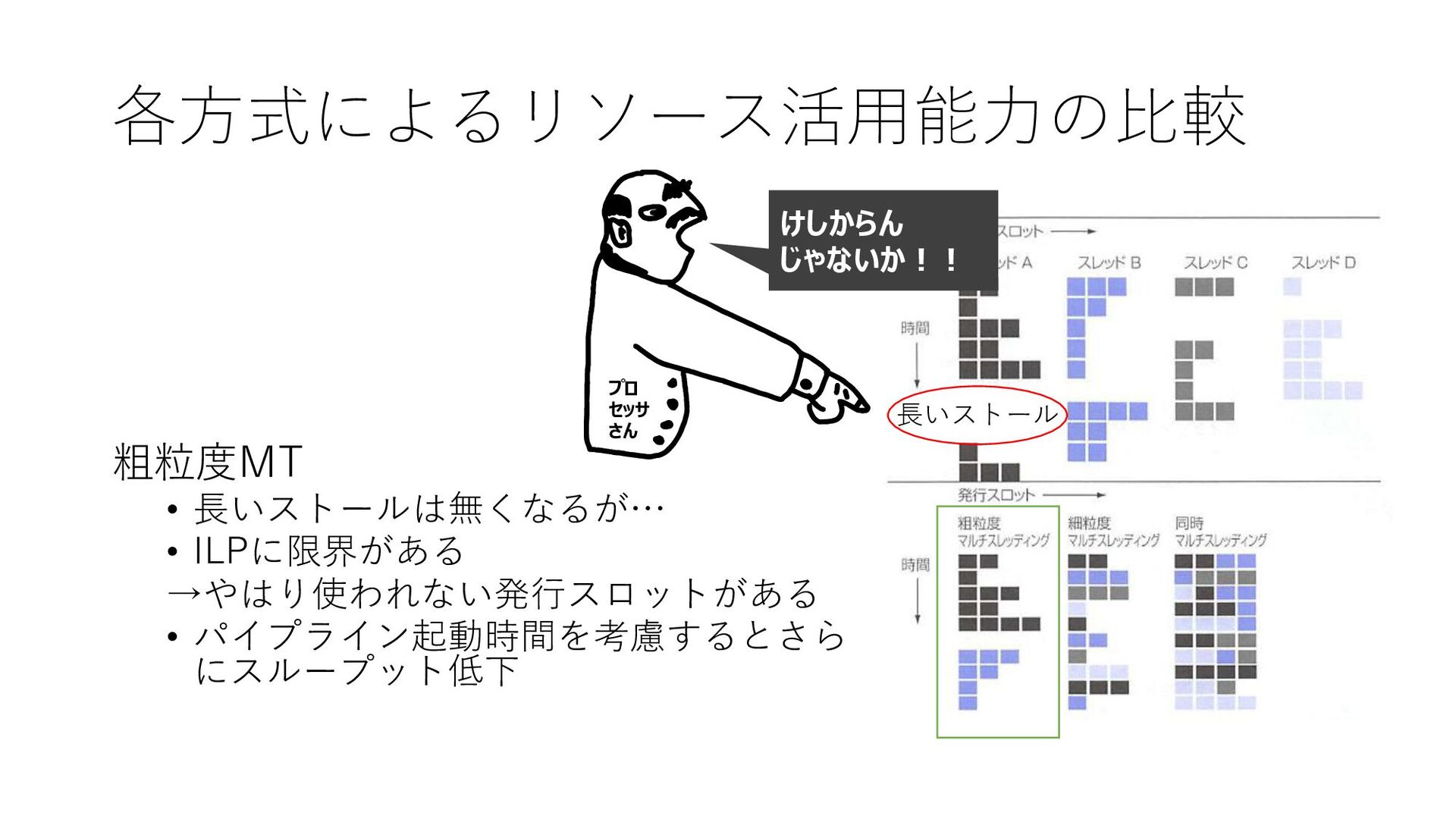
各方式によるリソース活用能力の比較 4つのスレッドA~Dがスーパースカラ プロセッサ上で実行される様子 • 上はそれぞれ単独で実行される場合 • 下は各方式でMTにした場合 • 空白は発行スロットが使用されていない =利用効率↓
• パイプライン起動時間は考慮なし
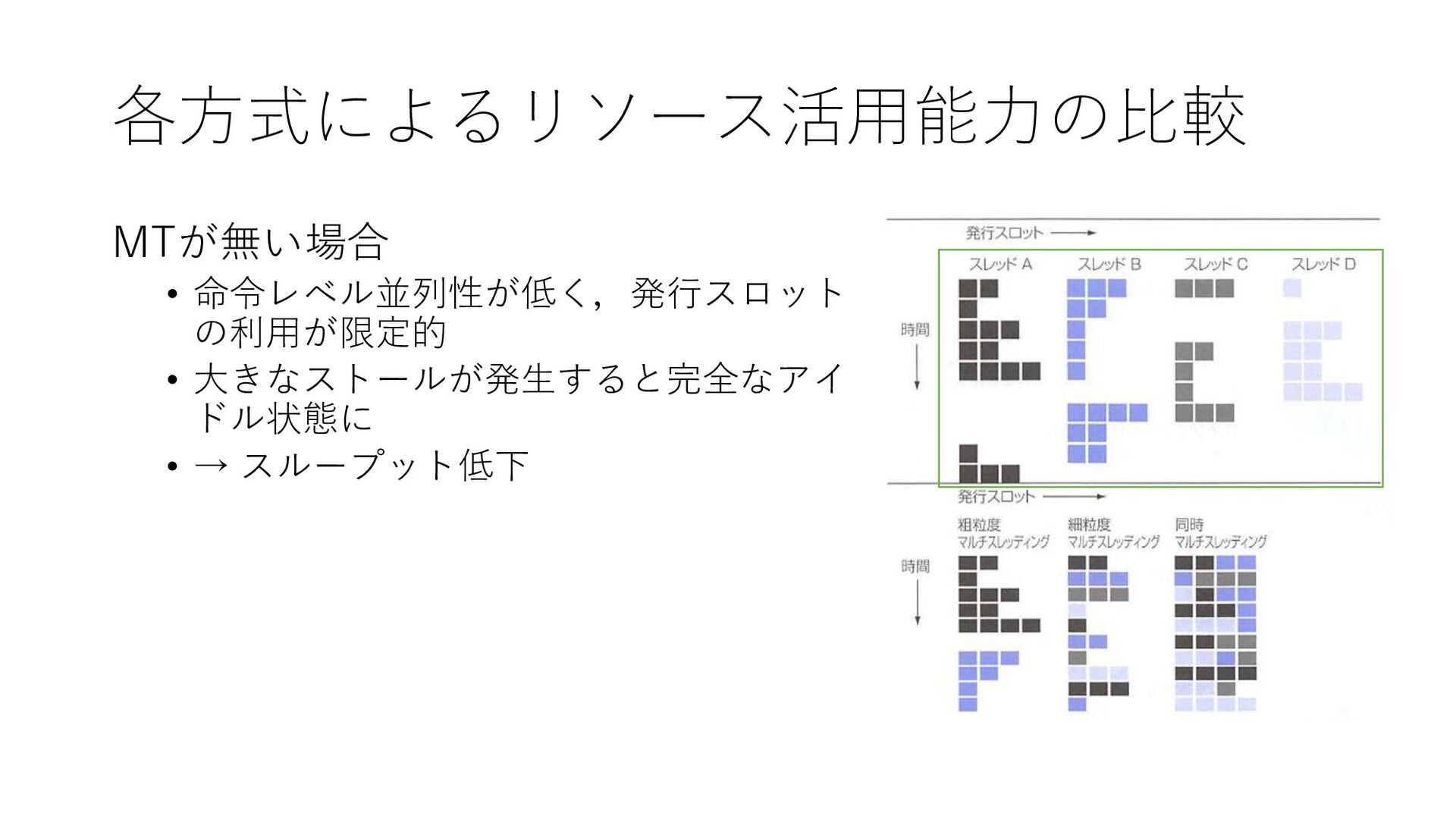
各方式によるリソース活用能力の比較 MTが無い場合 • 命令レベル並列性が低く,発行スロット の利用が限定的 • 大きなストールが発生すると完全なアイ ドル状態に • →
スループット低下
各方式によるリソース活用能力の比較 粗粒度MT • 長いストールは無くなるが… • ILPに限界がある →やはり使われない発行スロットがある • パイプライン起動時間を考慮するとさら にスループット低下
長いストール けしからん じゃないか!! プロ セッサ さん
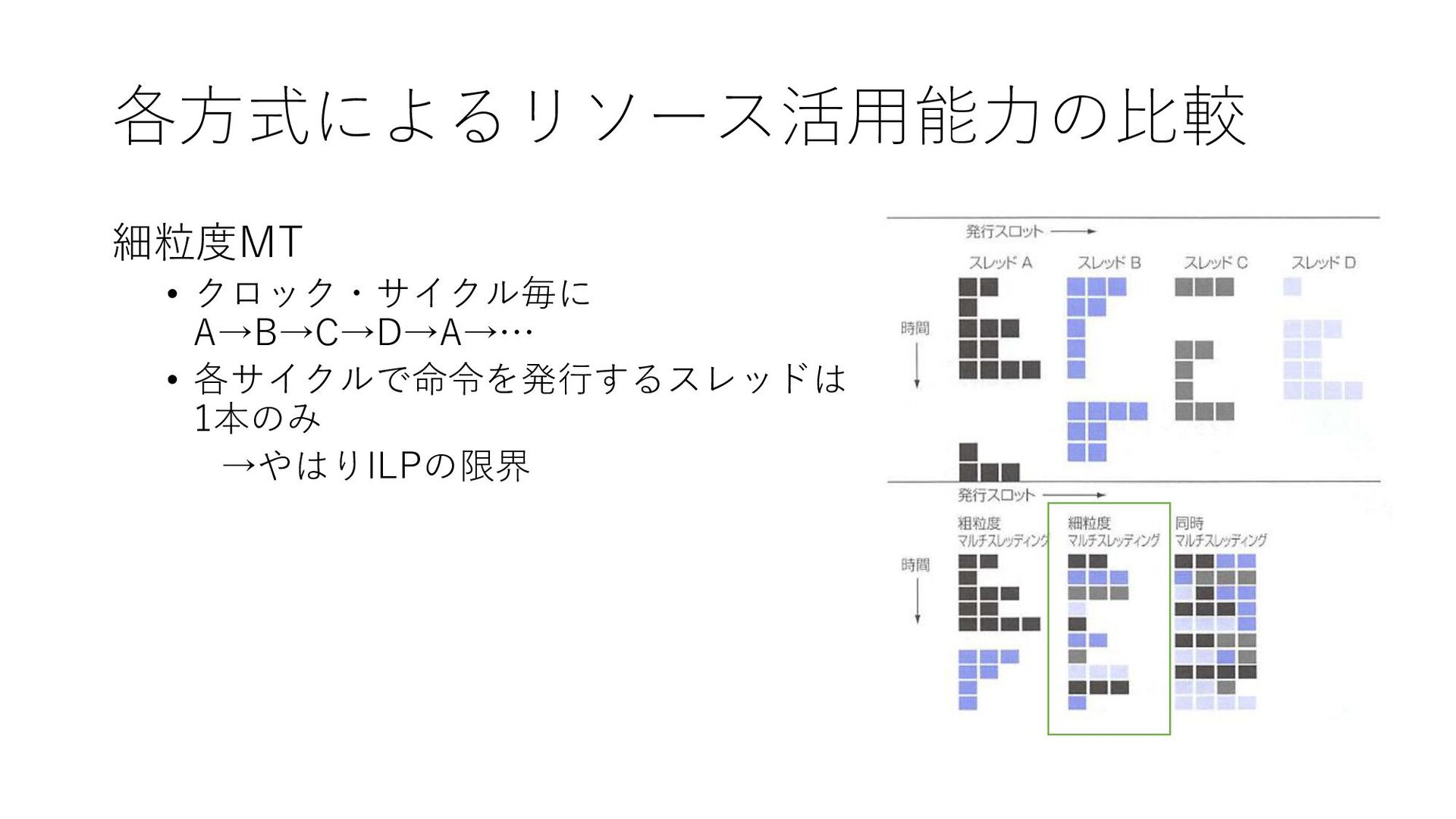
各方式によるリソース活用能力の比較 細粒度MT • クロック・サイクル毎に A→B→C→D→A→… • 各サイクルで命令を発行するスレッドは 1本のみ →やはりILPの限界
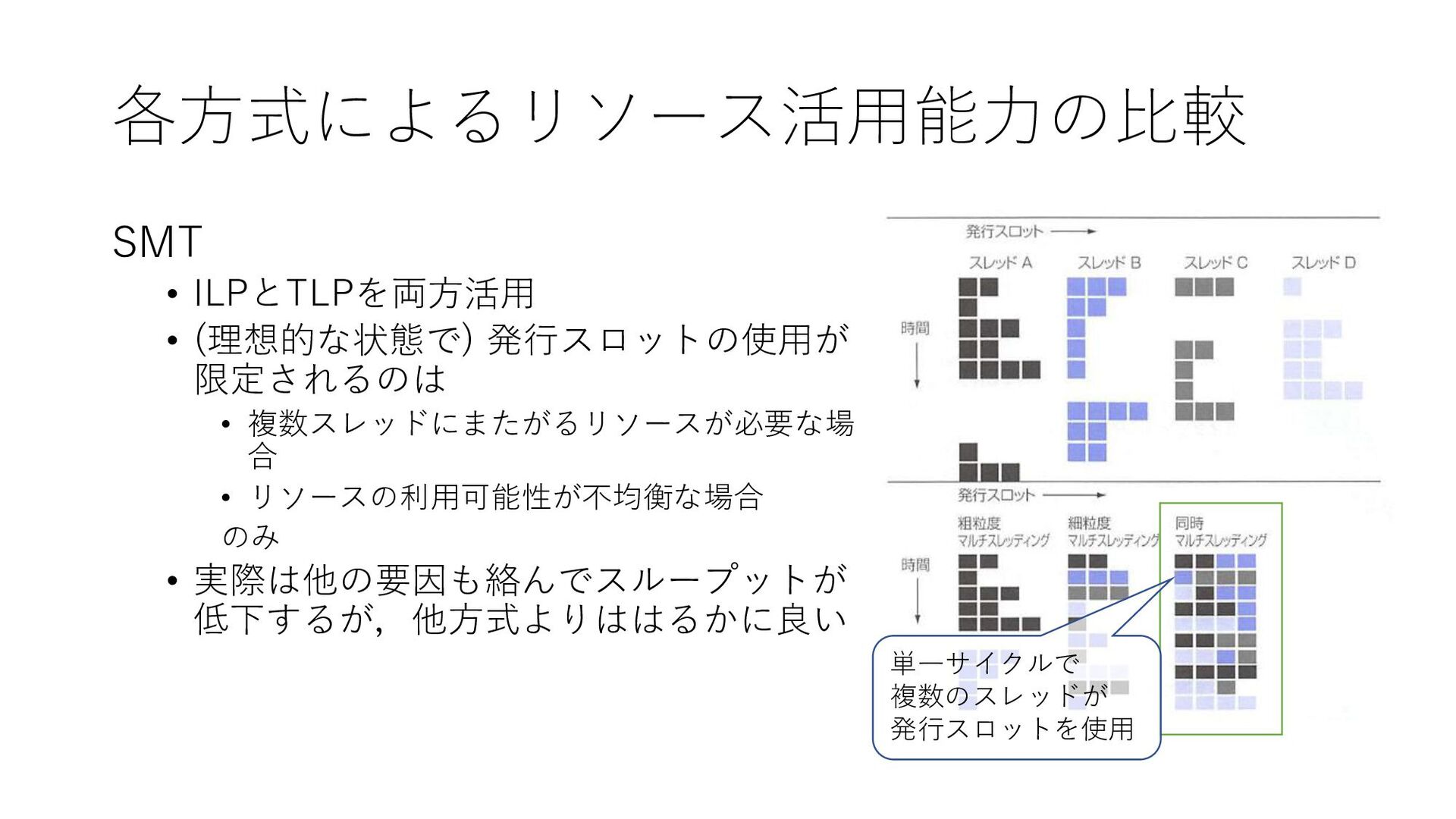
各方式によるリソース活用能力の比較 SMT • ILPとTLPを両方活用 • (理想的な状態で) 発行スロットの使用が 限定されるのは • 複数スレッドにまたがるリソースが必要な場
合 • リソースの利用可能性が不均衡な場合 のみ • 実際は他の要因も絡んでスループットが 低下するが,他方式よりははるかに良い 単一サイクルで 複数のスレッドが 発行スロットを使用
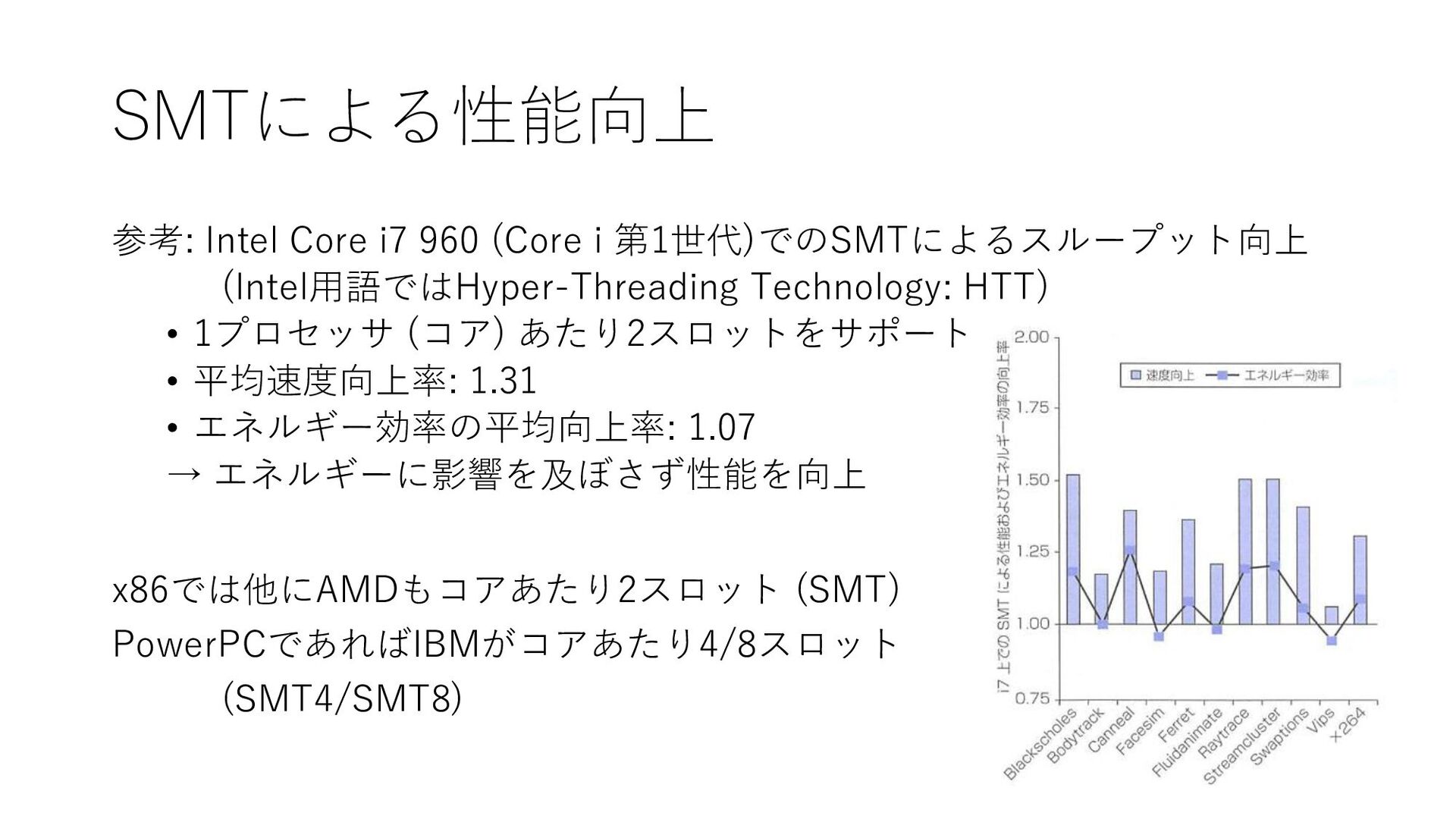
SMTによる性能向上 参考: Intel Core i7 960 (Core i 第1世代)でのSMTによるスループット向上 (Intel用語ではHyper-Threading
Technology: HTT) • 1プロセッサ (コア) あたり2スロットをサポート • 平均速度向上率: 1.31 • エネルギー効率の平均向上率: 1.07 → エネルギーに影響を及ぼさず性能を向上 x86では他にAMDもコアあたり2スロット (SMT) PowerPCであればIBMがコアあたり4/8スロット (SMT4/SMT8)
6.5 マルチコアをはじめとする 共有記憶型 マルチプロセッサ
ここからの話 • ここまでは単一プロセッサ上での性能向上の話 • 最近はチップあたりのプロセッサ数も増大している • 最新のチップ (AMD EPYC Genoa)
では96コア/チップ • チップ上のすべてのプロセッサを効率よく利用することで Mooreの法則の性能向上率を実現したい
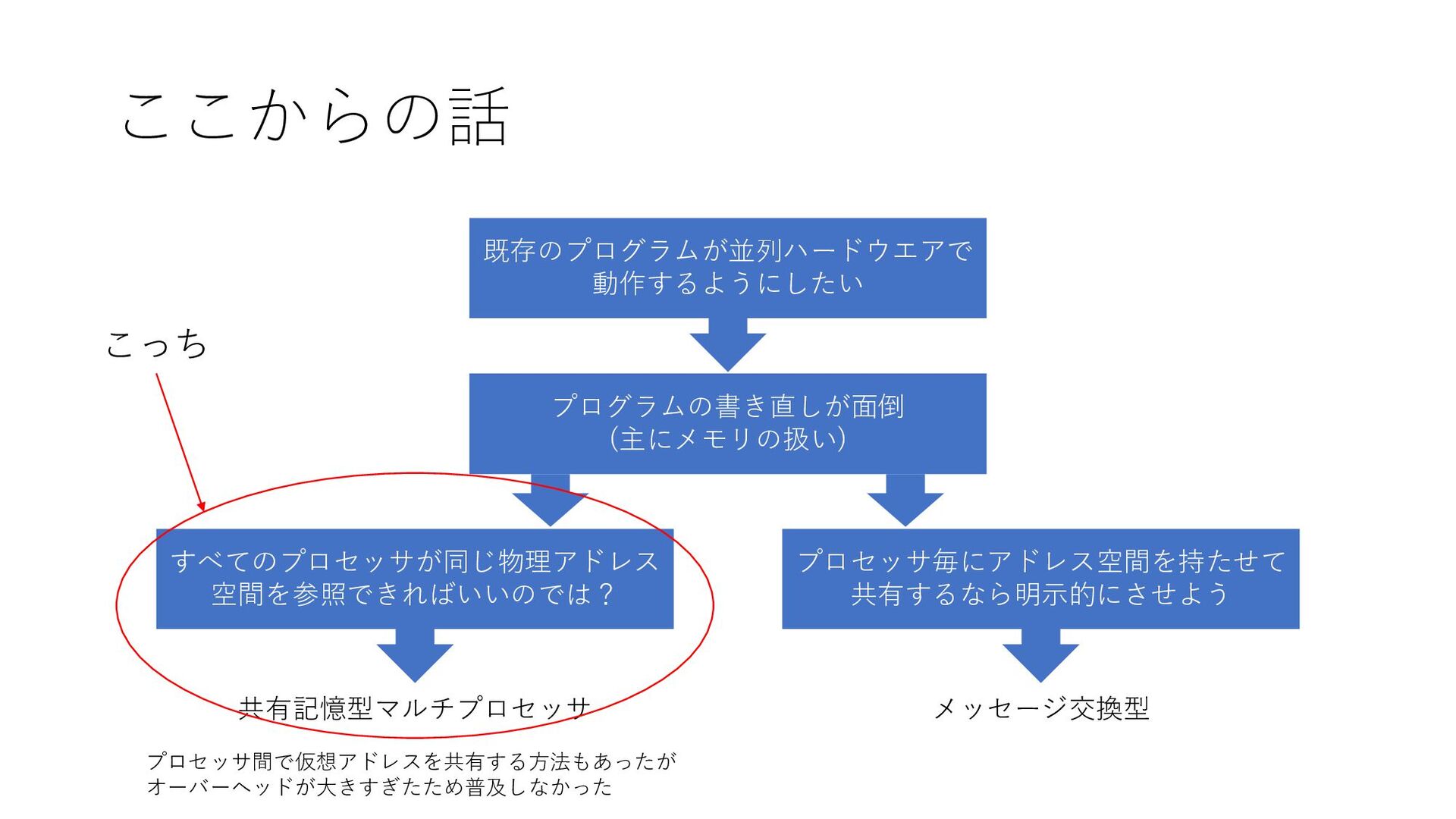
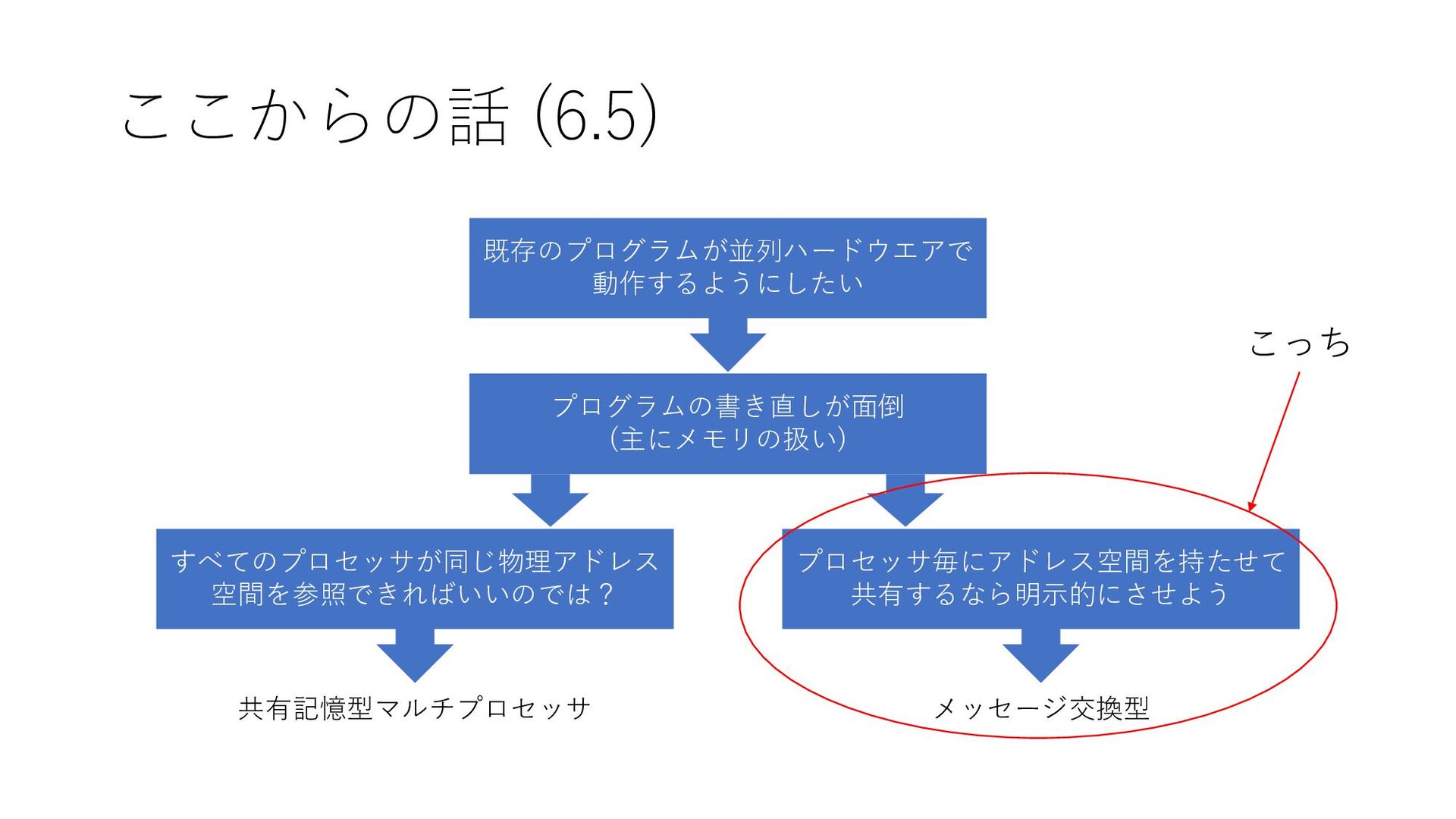
ここからの話 プログラムの書き直しが面倒 (主にメモリの扱い) すべてのプロセッサが同じ物理アドレス 空間を参照できればいいのでは? プロセッサ毎にアドレス空間を持たせて 共有するなら明示的にさせよう 既存のプログラムが並列ハードウエアで 動作するようにしたい 共有記憶型マルチプロセッサ
メッセージ交換型 プロセッサ間で仮想アドレスを共有する方法もあったが オーバーヘッドが大きすぎたため普及しなかった こっち
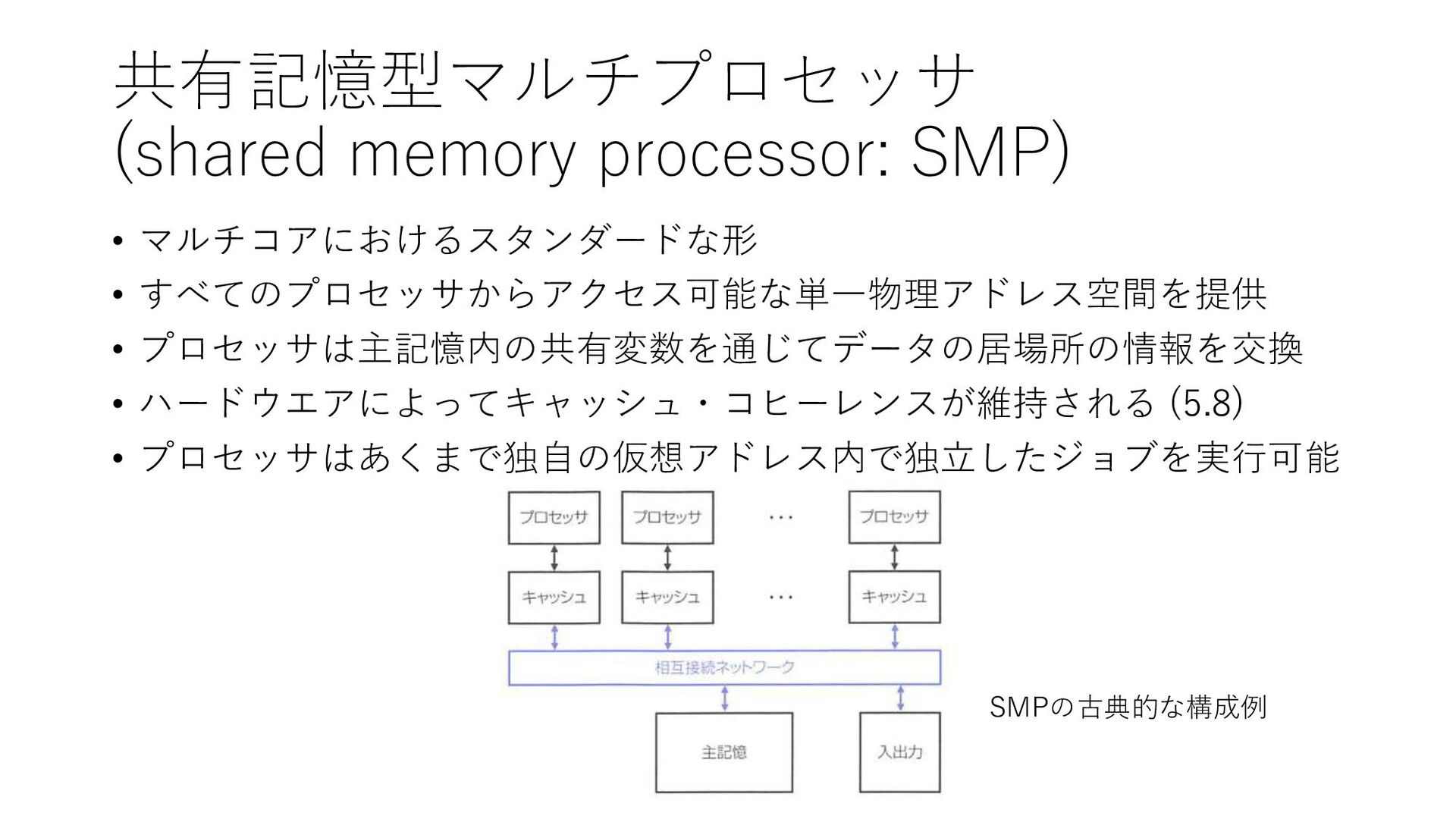
共有記憶型マルチプロセッサ (shared memory processor: SMP) • マルチコアにおけるスタンダードな形 • すべてのプロセッサからアクセス可能な単一物理アドレス空間を提供 •
プロセッサは主記憶内の共有変数を通じてデータの居場所の情報を交換 • ハードウエアによってキャッシュ・コヒーレンスが維持される (5.8) • プロセッサはあくまで独自の仮想アドレス内で独立したジョブを実行可能 SMPの古典的な構成例
SMPの種類 • 均等メモリアクセス(uniform memory access: UMA) • 主記憶中のデータへのアクセス時間がプロセッサに依存しない • 非均等メモリアクセス(non-uniform
memory access: NUMA) • 主記憶が分割されて別々のプロセッサ・メモリコントローラへ割当 • 主記憶中のデータの位置へ近いプロセッサほどアクセスが速い • プログラミングの難度は高いがプロセッサ数の拡大が容易
同期 (synchronization) • 別々のプロセッサが同じデータを同時に操作することがないように する仕組み (2章) • ex. 共有される変数にロック (lock)
を適用 (2.11) • 同時にデータを操作できるプロセッサは1つだけになる • 他のプロセッサは先にロックを取得したプロセッサがロック解除するまで待 機 OpenMP • 共有記憶型マルチプロセッシングのためのAPI • ループの並列化と縮約 (reduction: 各プロセッサでの演算結果の集 計) を行う
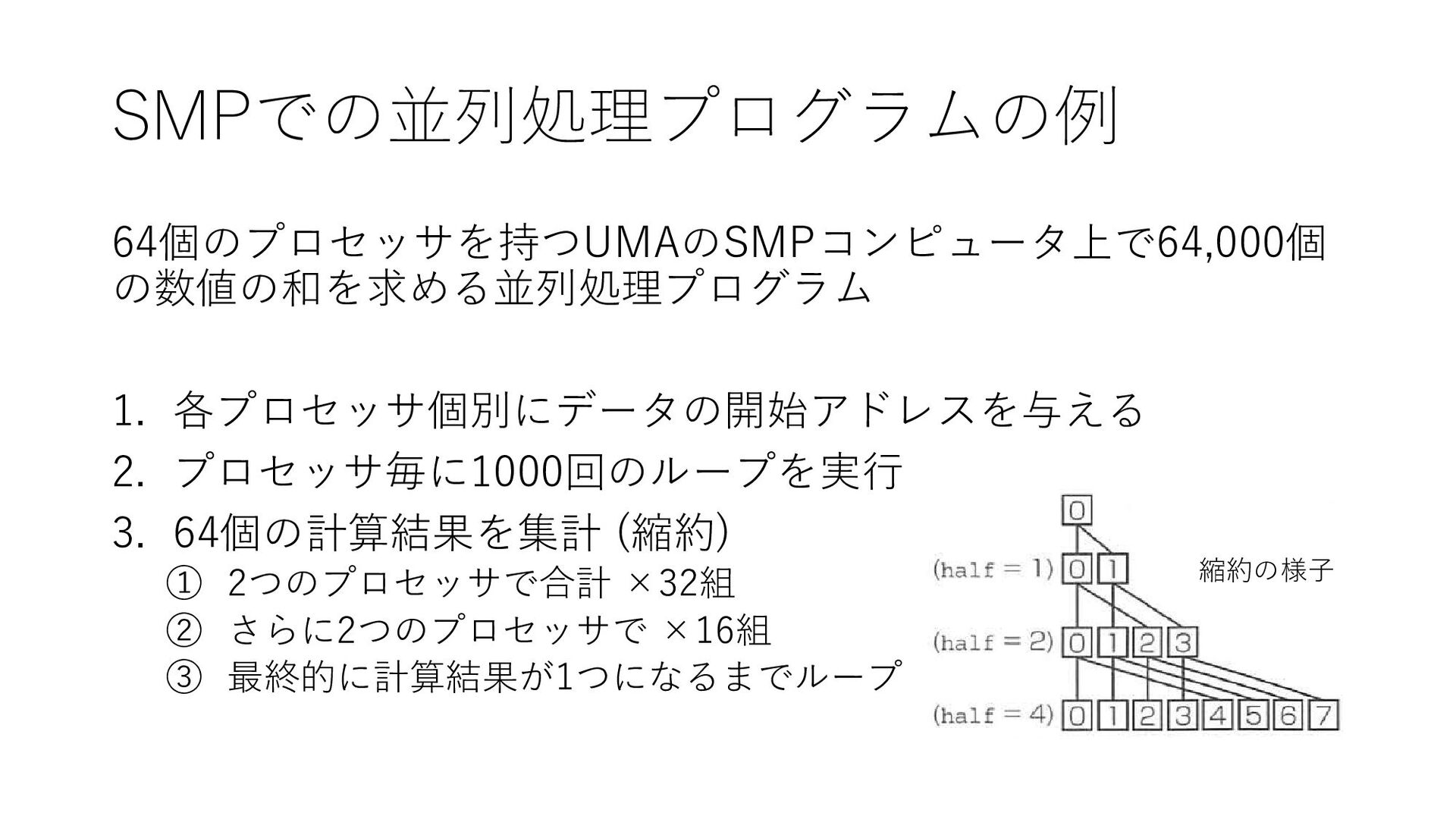
SMPでの並列処理プログラムの例 64個のプロセッサを持つUMAのSMPコンピュータ上で64,000個 の数値の和を求める並列処理プログラム 1. 各プロセッサ個別にデータの開始アドレスを与える 2. プロセッサ毎に1000回のループを実行 3. 64個の計算結果を集計 (縮約)
① 2つのプロセッサで合計 ×32組 ② さらに2つのプロセッサで ×16組 ③ 最終的に計算結果が1つになるまでループ 縮約の様子
6.6 グラフィックス 処理ユニットの概要
GPUの登場 グラフィックス処理ユニット (Graphics Processing Units: GPU) • マイクロプロセッサにSIMD命令を追加するだけでは性能不足 • グラフィックス処理改善のために登場
• コンピュータ・ゲーム市場の拡大を受けてマイクロプロセッサより も速いペースで改善 • 多数の並列処理浮動小数点ユニットを持つ低コストなハードウエア の誕生 →GPUコンピューティング (general-purpose computing on GPU:GPGPU)
GPUとCPUの違い (役割) • GPUはCPUを補完するハードウエア • CPUができるタスクを全てできる必要はない • 純粋にグラフィックス処理に専念して良い • GPUの扱うデータサイズは通常MiB~GiB単位
• 極端に大きなデータ(102GiB~TiB)を扱える必要はない • (ただ最近は深層学習で比較的大きなデータを扱うことがある) これらの違いを踏まえて…
GPUとCPUの違い (アーキテクチャ) • マルチレベル (階層構造) のキャッシュは利用しない • 個々のデータセットが102 MiBと大きく,キャッシュに収まらない •
メモリアクセスの待ち時間はハードウエア・マルチスレッディングに より別のスレッドを実行,レイテンシを隠蔽 • 主記憶のデータ幅,バンド幅重視 • バンド幅: CPU…~460GB/s,GPU…~3TB/s (2023年現在) • 主記憶はCPUより小さい (CPU…~6TiB,GPU…~80GiB) • 多数のスレッドが必要になる → 多数のスレッド,並列プロセッサ (MIMD) に対応する必要がある → CPUよりも高度なマルチスレッド化された多くのプロセッサを搭載
NVIDIA GPUアーキテクチャの概要 ex. Fermiアーキテクチャ (現行の8世代前) • GPUはマルチスレッド方式のSIMDプロセッサで構成されるMIMD • データ・レベル並列性のある問題にのみ効果があるのはベクトル・プ ロセッサ同様
• ベクトル・プロセッサよりレジスタ,並列機能ユニットが多い • SIMDスレッド (=SIMD命令のみを含むスレッド) • GPUが生成,管理,スケジュール,実行するマシン・オブジェクト • 独自のプログラム・カウンタを持つ
NVIDIA GPUアーキテクチャの概要 GPUは2種類のスケジューラを持つ • SIMDスレッド・スケジューラ • SIMDプロセッサに内蔵 • 実行準備ができたSIMDスレッドをSIMDスレッド・スケジューラ内の コントローラが選び,該当スレッドをディスパッチ・ユニットへ送る
• ディスパッチ・ユニットは該当スレッドをSIMDプロセッサ上で実行 • 「実行準備ができたものから」=細粒度マルチスレッディング • スレッド・ブロック・スケジューラ • スレッドのブロックを各SIMDプロセッサに割当 • GPU自体のスケーラビリティ (様々な規模の製品) を提供できる
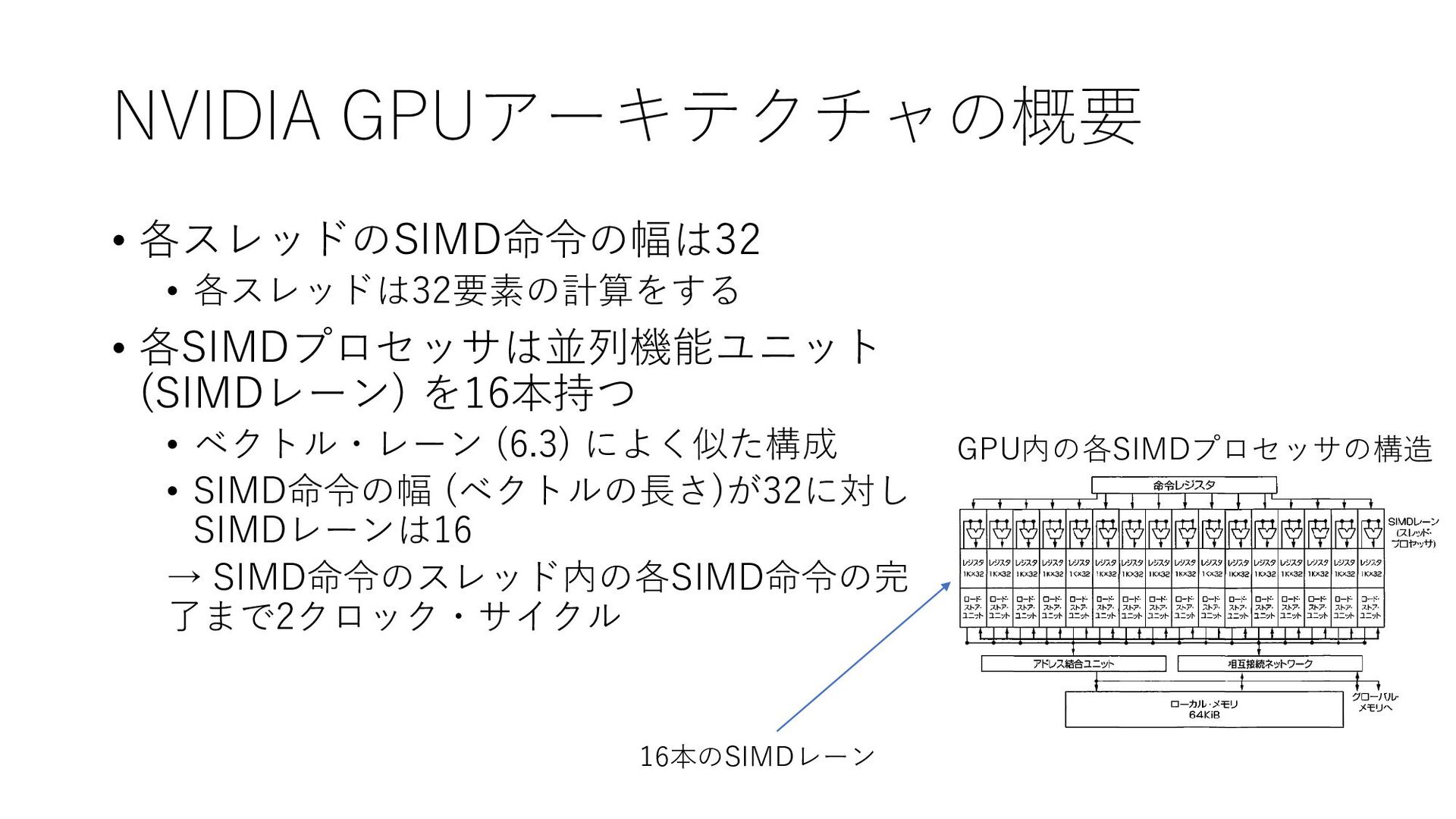
NVIDIA GPUアーキテクチャの概要 • 各スレッドのSIMD命令の幅は32 • 各スレッドは32要素の計算をする • 各SIMDプロセッサは並列機能ユニット (SIMDレーン) を16本持つ
• ベクトル・レーン (6.3) によく似た構成 • SIMD命令の幅 (ベクトルの長さ)が32に対し SIMDレーンは16 → SIMD命令のスレッド内の各SIMD命令の完 了まで2クロック・サイクル 16本のSIMDレーン GPU内の各SIMDプロセッサの構造
補足: CUDA CUDA (Compute Unified Device Archtecture) • (制限はあるものの) NVIDIAのGPU上で実行できるCプログラムを記述可能
• CUDAスレッド • 最下位レベルの並列処理 • POSIXスレッドとは全く異なる (任意にシステム・コールを行ったり同期をとったりできない) • CUDAスレッドを複数束ねてブロック化し,GPU内での並列処理や並列性を活用 • マルチスレッドの各プロセッサが各ブロックを実行 OpenCL (Open Computing Language) • CUDAの利点を活かしつつ,さらに移植性の高いプログラミング言語を開発 するプロジェクト • 他ベンダのGPUでも実行可能
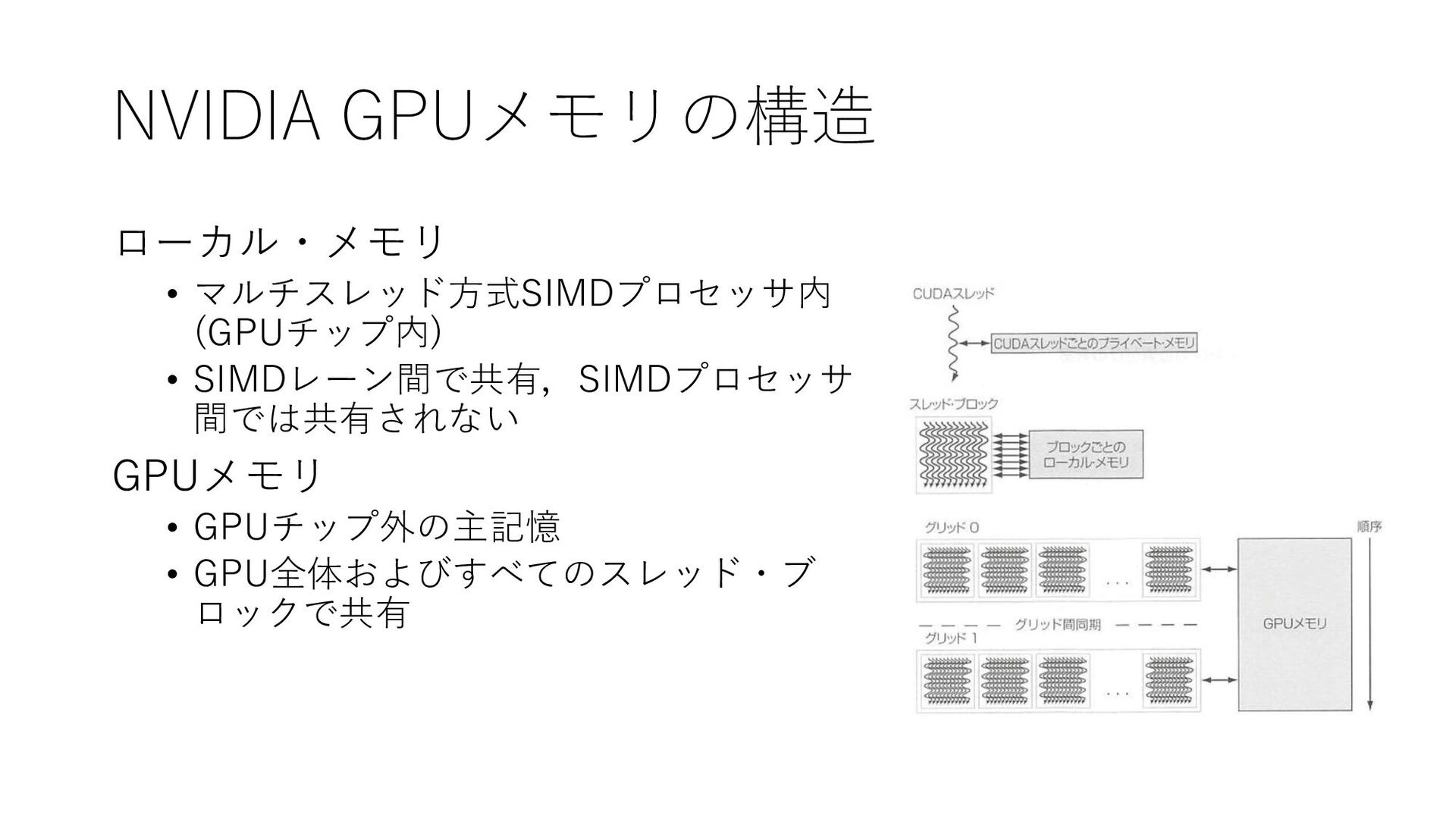
NVIDIA GPUメモリの構造 ローカル・メモリ • マルチスレッド方式SIMDプロセッサ内 (GPUチップ内) • SIMDレーン間で共有,SIMDプロセッサ 間では共有されない GPUメモリ
• GPUチップ外の主記憶 • GPU全体およびすべてのスレッド・ブ ロックで共有
NVIDIA GPUメモリの構造 • CPUでマルチレベルキャッシュに使われていた領域は • より多くのプロセッサの実装 • SIMD命令で実行される多くのスレッドの状態を保持する大量のレジス タ実装 に利用
• 最近のGPUは追加のキャッシュを備えていることがある • GPUメモリへのリクエスト低減 • マルチスレッディングでレイテンシを隠蔽できないようなある種の変 数用のアクセラレータ
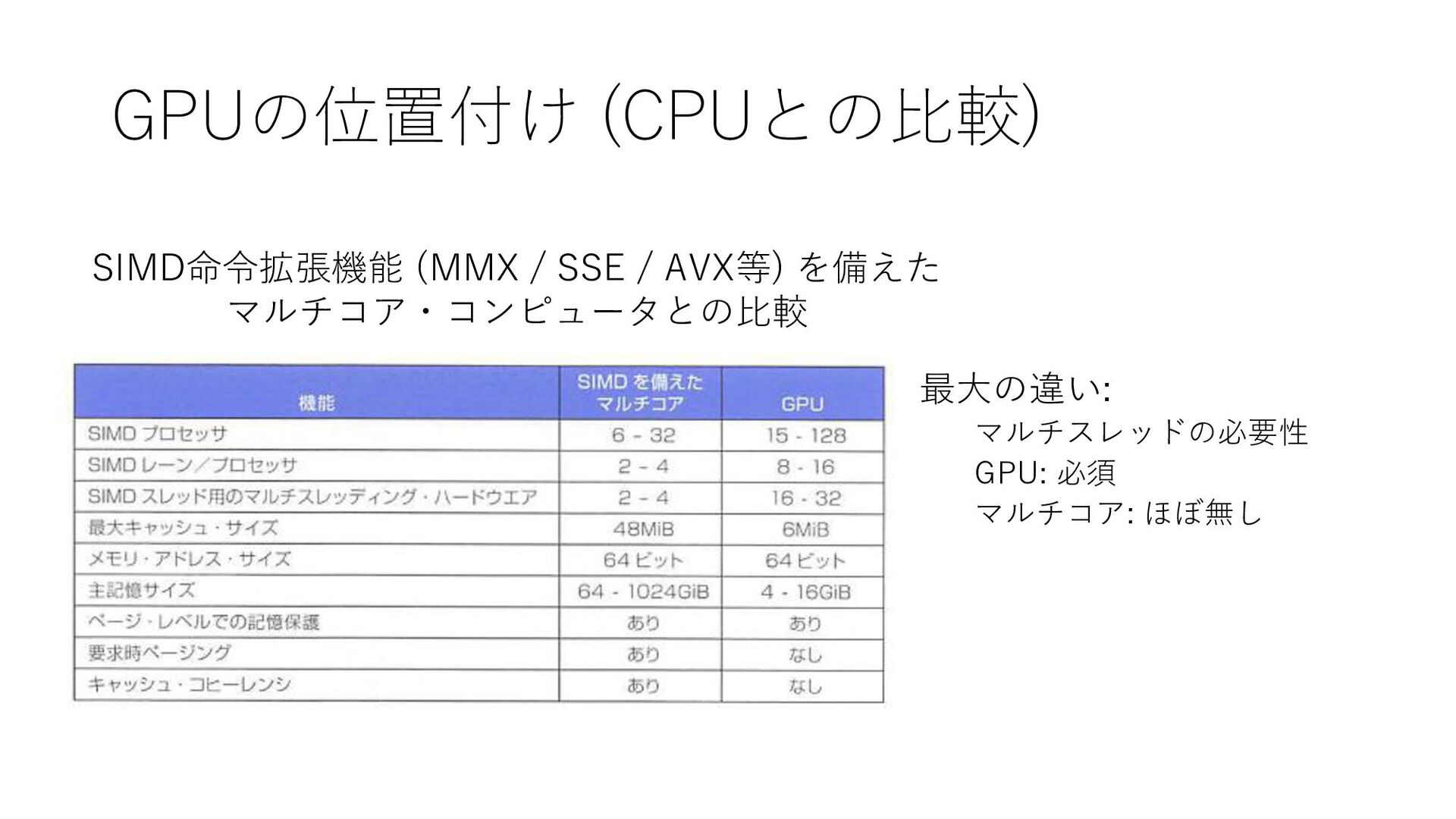
GPUの位置付け (CPUとの比較) 最大の違い: マルチスレッドの必要性 GPU: 必須 マルチコア: ほぼ無し SIMD命令拡張機能 (MMX
/ SSE / AVX等) を備えた マルチコア・コンピュータとの比較
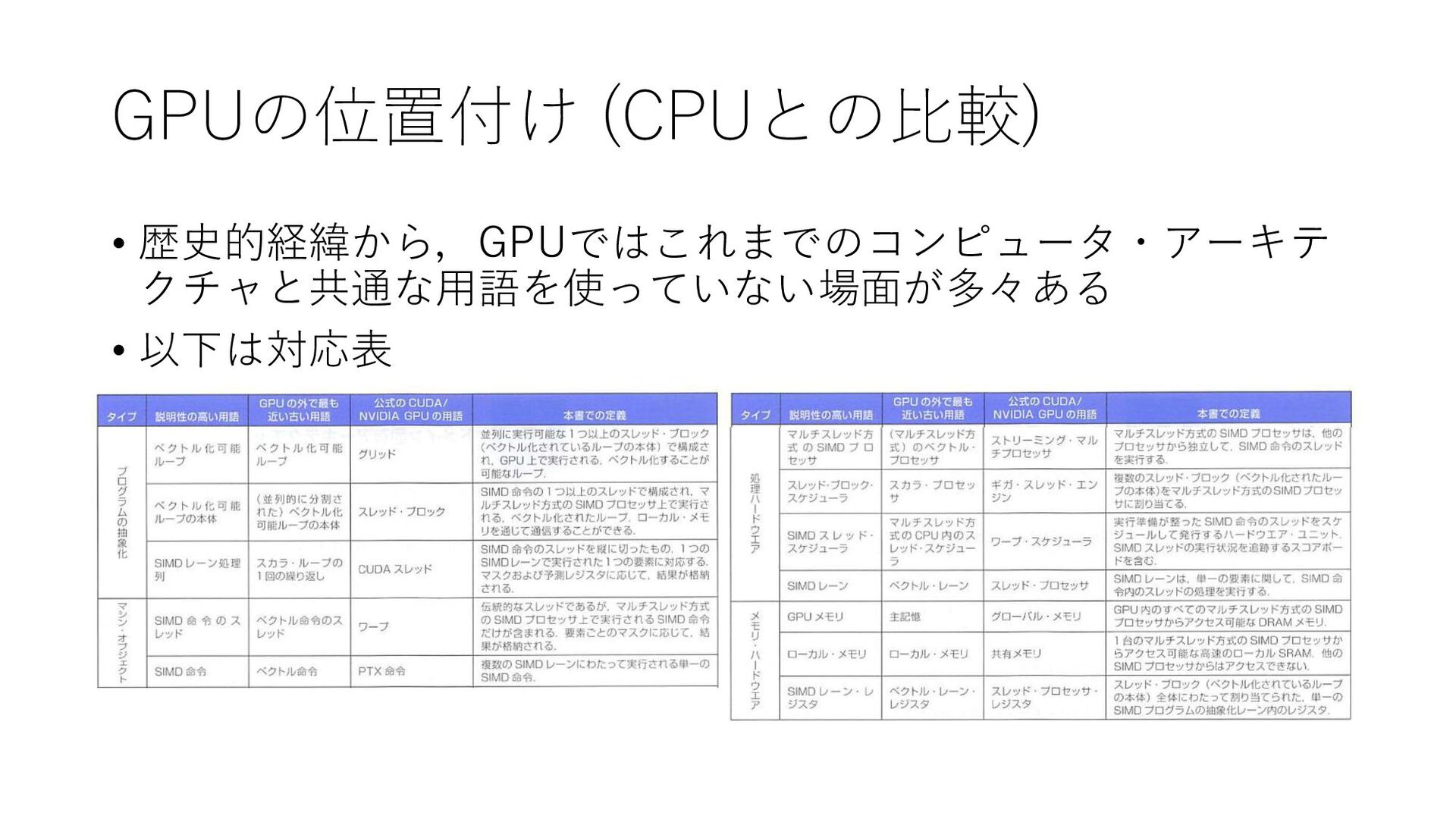
GPUの位置付け (CPUとの比較) • 歴史的経緯から,GPUではこれまでのコンピュータ・アーキテ クチャと共通な用語を使っていない場面が多々ある • 以下は対応表
6.7 ドメイン固有 アーキテクチャ
ドメイン固有アーキテクチャ (domain-specific architecture: DSA) • Mooreの法則の鈍化 • Dennardのスケーリング則の終了 • Amdahlの法則によるマルチコアの性能の限界
→「性能・エネルギー効率向上にはDSAしかない!」
DSAとは あるアプリケーション・ドメイン向けに特化した特殊目的コンピュータ 以下の原理に基づく 1. 専用のメモリを使用 2. 高度なマイクロアーキテクチャ的最適化を止め,そのリソースを算術装 置や主記憶の増強に注ぎ込む 3. ドメインに適合する最も容易な形の並列性を利用する
4. データのサイズとタイプをドメインに必要最低限・単純なものへと削減 5. DSAにプログラムを移植するため,固有のプログラミング言語を使用 (GPUもDSAの1種)
DSAとは? 1. 専用のメモリを使用 • 汎用マイクロプロセッサの多階層キャッシュは領域・エネルギーを多 く消費する • 無駄なキャッシュを排し,メモリをソフトウエア制御することにより 無駄なデータ移送を削減 2.
高度なマイクロアーキテクチャ的最適化を止め,そのリソー スを算術装置や主記憶の増強に注ぎ込む • ドメイン固有の領域では実行されるプログラムがあらかじめわかって いる • 汎用プロセッサ向けの機能に割くリソースは不要になり,それらを処 理装置や専用メモリの拡大に充てられる
DSAとは? 3. ドメインに適合する最も容易な形の並列性を利用する • 対象となるドメインにはほとんどの場合,そのドメイン固有の並列性 がある • その並列性の形態に応じて並列実行できるような形にDSAを設計する 4. データのサイズとタイプをドメインに必要最低限・単純なも
のへと削減 • 多くのドメインではメモリにより制約を受ける(メモリ・バウンド的) ことが多い • 幅の狭いデータ・タイプを使用することで,有効なメモリ・バンド幅 およびオンチップ・メモリの利用効率を高め,同じチップ領域・許容 エネルギーあたりでより多くの処理装置を詰め込むことができる
DSAとは? 5. DSAにプログラムを移植するため,固有のプログラミング言 語を使用 • 全く新しいアーキテクチャ上でアプリケーションを最適に実行するこ とが重要 (ハードウエアが作れても動かせなければ意味がない) • プログラミング抽象化の水準を上げることで,アプリケーションを
DSAに移植する実現可能性がアップ
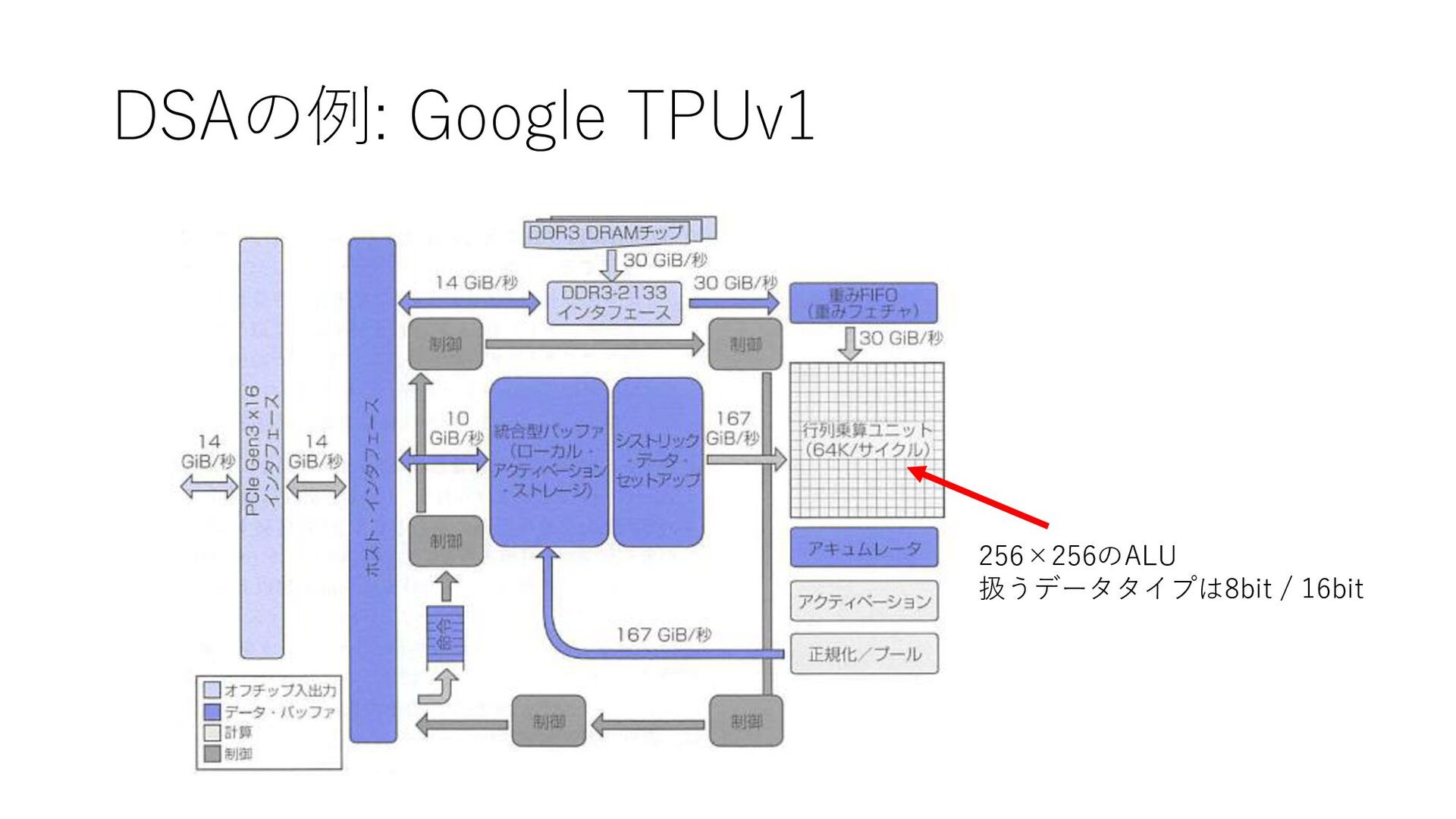
DSAの例: Google TPUv1 256×256のALU 扱うデータタイプは8bit / 16bit
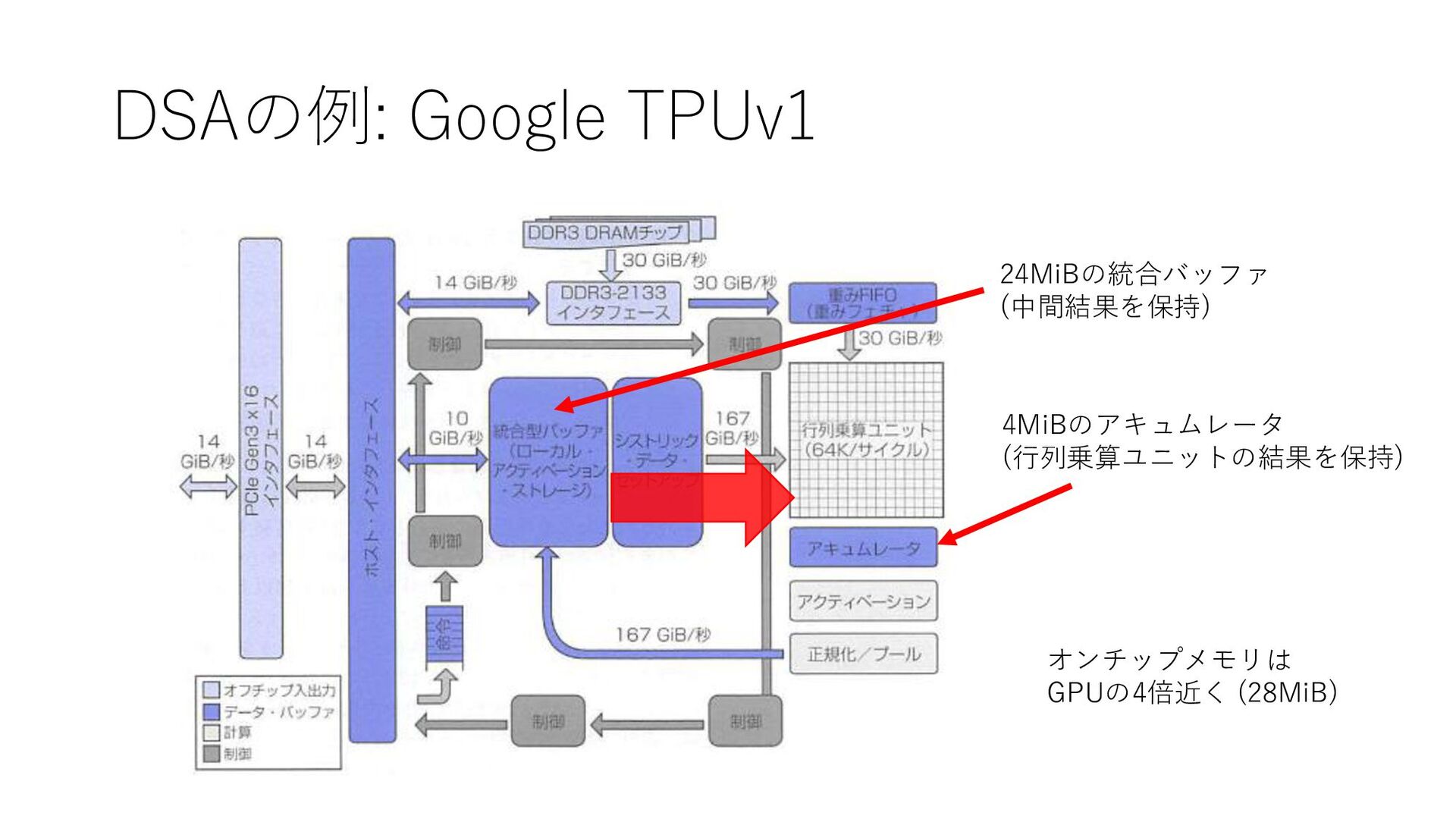
DSAの例: Google TPUv1 4MiBのアキュムレータ (行列乗算ユニットの結果を保持) 24MiBの統合バッファ (中間結果を保持) オンチップメモリは GPUの4倍近く (28MiB)
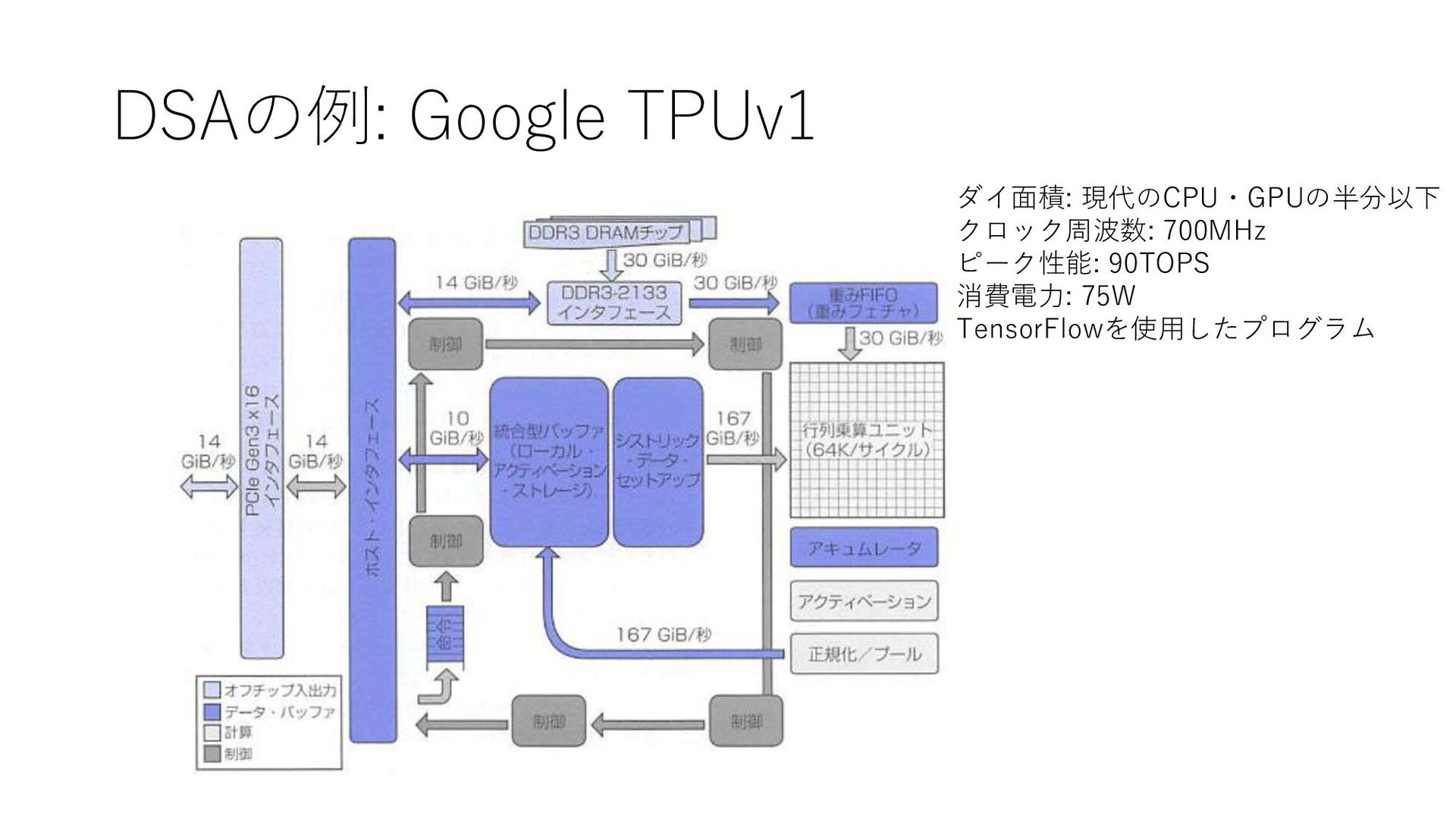
DSAの例: Google TPUv1 ダイ面積: 現代のCPU・GPUの半分以下 クロック周波数: 700MHz ピーク性能: 90TOPS 消費電力:
75W TensorFlowを使用したプログラム
DSAの例: Google TPUv1 具体的な性能 • 6つの実用DNNアプリケーションの平均 • 現代のCPU比: 29.2倍高速 •
現代のGPU比: 15.32倍高速 • コスト性能比 • 総運営費用 (total cost of ownership: TCO) を評価基準に • ハードウエアの購入費用,運用中の電力・冷却・占有面積による運用コスト • 当初の目標: TCOあたりCPU・GPUの10倍の性能 • 消費電力値をTCOの目安として利用 • ワットパフォーマンスでGPUの29倍,CPUの83倍 DSAを開発することで目標を達成できた!
6.8 クラスタ,ウエアハウス・ スケール・コンピュータ および その他のメッセ ージ交換型 マルチプロセッサ
ここからの話 (6.5) プログラムの書き直しが面倒 (主にメモリの扱い) すべてのプロセッサが同じ物理アドレス 空間を参照できればいいのでは? プロセッサ毎にアドレス空間を持たせて 共有するなら明示的にさせよう 既存のプログラムが並列ハードウエアで 動作するようにしたい
共有記憶型マルチプロセッサ メッセージ交換型 こっち
メッセージ交換型マルチプロセッサ メッセージ交換型マルチプロセッサ • 各プロセッサは固有の物理アドレス空間を持 つ • マルチプロセッサ同士は明示的なメッセージ 交換を行う • メッセージ送信ルーチン
/ メッセージ受信 ルーチンの間で調整が行われる • 受信側から送信元に応答することでメッセー ジ到達を確認 (Ackのようなもの) メッセージ交換を行うマルチ プロセッサの古典的な構成
メッセージ交換型マルチプロセッサ • ハードウエア設計が行いやすい • プログラマにとっては • 情報交換のタイミングが明示的 →共有記憶型にありがちな暗黙的な情報交換によって予想外に性能が落ち込む 問題が少ない •
逐次処理プログラムを移植することが難しい • あらゆる情報交換のタイミングを事前に洗い出しておくことが必要になる • 今日では • マルチコア・マイクロプロセッサ間レベルでは共有記憶型 • クラスタ内のノード間レベルではメッセージ交換型 が用いられている
メッセージ交換型マルチプロセッサ • 高性能なメッセージ交換ネットワークをベースに大規模なコン ピュータが開発 • LANを用いるよりも高い情報交換性能 • スパコンなどで利用 • ex.
Infiniband • コスパが非常に悪く,HPC分野以外では採用が厳しい
クラスタ • 標準的なネットワークで結合された単一のメッセージ交換型マ ルチプロセッサとして機能する,コンピュータの集合体 • 通常の汎用マシンなので低コスト • 各ノードではOSの別個のコピーが独立して稼働 • アプリケーションはOSのレイヤ上で稼働
• 主記憶は分割されている • タスク・レベルでの並列性や情報交換がほとんどないアプリケーショ ンであれば実行にアドレス共有を必要とないので問題なし • システムを停止させずにノードの交換,拡張などが可能 →システムの可用性・拡張性向上
クラスタ • 大規模な共有記憶型マルチプロセッサと比較すると通信性能は 劣るが… • 様々なインターネット・サービス・プロバイダで利用 • 低コスト,高可用性,拡張性の高さが大きなメリット • 数万ノードからなるクラスタを備えたデータセンタが各地に存在
• もちろん日本にも IDCフロンティア 白河DC (福島)
グリッド・コンピューティング • クラスタは全ノードがLAN内 • グリッド・コンピューティングはWANに分散 • 情報交換のハードルが高い • 各ワーカーノードである程度計算し,計算結果をマスターに集約 •
具体的なプロジェクト: 最近だとFolding@home • タンパク質のふるまいのシミュレーションを行うプロジェクト • ボランティアとして参加した,インターネット上にあるアイドル状態 のコンピュータの演算能力を活用 • 2.4EFLOPSを達成 (世界初のエクサスケールコンピュータ)
ウエアハウス・スケール・コンピュータ (warehouse-scale computer: WSC) • 数万台ものサーバを収容し,給電,冷却するには巨大な建物が 必要 • 建物,電気・冷却系統,サーバ,ネットワーク機器等を一体と みなした呼び方
• Seymore Cray (1925-1996): WSCのアーキテクトの父
WSCにおける処理の例 MapReduce,Apache Hadoop (OSS) • WSCにおけるバッチ処理で最も普及しているフレームワーク • 並列化されたMapReduceタスクを簡単に実行可能 処理の流れ 1.
プログラマが定義した関数を適用 2. Mapステップ • マスターノードがタスクを分割して数千のワーカーノードに配布して処理させ,中間 結果としてkey, valueの組を生成 3. Reduceステップ: • Mapによる分散タスクの出力をマスターノードで収集し,プログラマが定義した別の 関数を使用して集約
WSCの目標 1. 豊富で容易な並列性 • ターゲットとなるアプリケーションに十分な並列性があるか • 並列性を活用するために必要なネットワークのコストが高すぎないか • ex. 要求レベル並列性
(Request-level Parallelism) • 通常多くの独立した作業を並列して進められ,ノード間通信・同期の必要がほぼ ない • SaaS (Software as a Service)に代表される,独立したユーザが個別に利用する 対話型のインターネット・サービス・アプリケーション (インターネットメール など) • データの読み出し・書き込みに依存関係がない
WSCの目標 2. 運用コストの比重 • 従来のサーバはピーク性能が重要,運用コスト等は二の次 • WSCは耐用・償却年数が長い • 特に建物と電気・冷却系統は10~20年,全体に占めるコストは30%以上 3.
規模及び規模に関連した機会 • 機材の発注数が多いのでベンダから割引を受けられる (規模の経済) →WSCのノード単位コストが低減 →クラウド・コンピューティングの提供コスト低減,価格引き下げ • 規模が大きい →それだけ故障の機会も多い →設計上WSC全体の耐故障性が重要
6.9 マルチプロセッサ・ ネットワ ーク・ トポロジの概要
まえおき • マルチコア・チップやノードの相互接続にはそれに適したネッ トワークが必要 • ネットワークを構成する要素 • スイッチ (全体のスイッチ数,スイッチあたりのリンク数,帯域幅) •
ネットワークをチップに組み込む際のリンク長 • ノード同士の位置関係 • 無負荷・負荷ありでのレイテンシ,スループット,遅延,etc... • 耐故障性 • エネルギー効率の高さ
ネットワーク・トポロジ • 通常はグラフで表現 • トポロジの評価尺度: • 「総合的な」ネットワーク・バンド幅 (network bandwidth) •
各リンクのバンド幅にリンク数を乗算,ピーク・バンド幅を表す • 2分割バンド幅 (bisection bandwidth) • 頂点が半分ずつになるようシステムを2分割 • 一方のグループのノードから他方のノードに伝送したいときのバンド幅に相当 • 対称形でない場合はネットワーク性能が最も最悪になるように分割 • 仮想上の分割線を横切るリンクのバンド幅を計算 • 最悪の場合に近い値を表す • 並列プログラムの性能は最弱のリンクに制約を受けることが多い
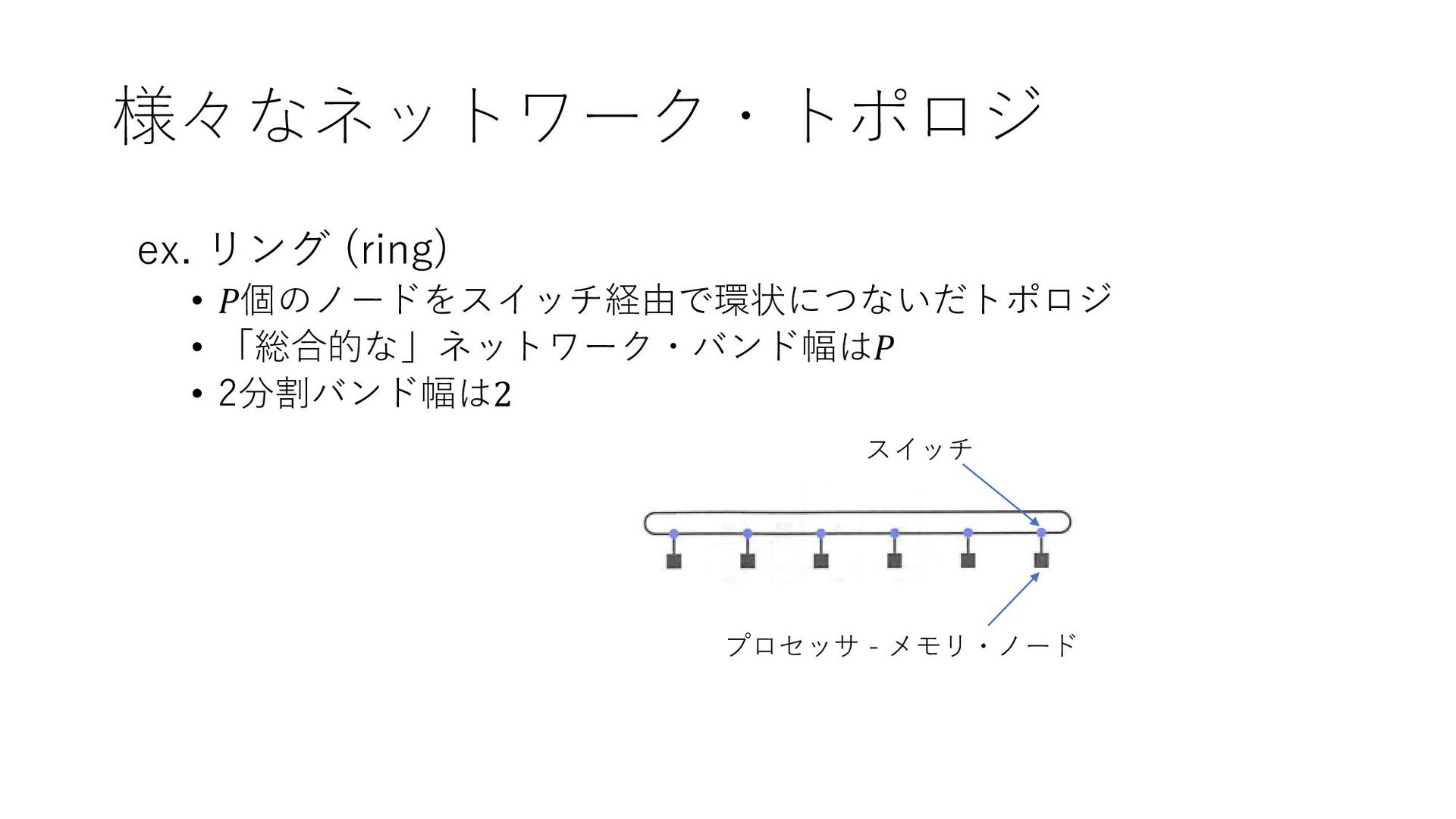
様々なネットワーク・トポロジ ex. リング (ring) • 𝑃個のノードをスイッチ経由で環状につないだトポロジ • 「総合的な」ネットワーク・バンド幅は𝑃 • 2分割バンド幅は2
スイッチ プロセッサ - メモリ・ノード
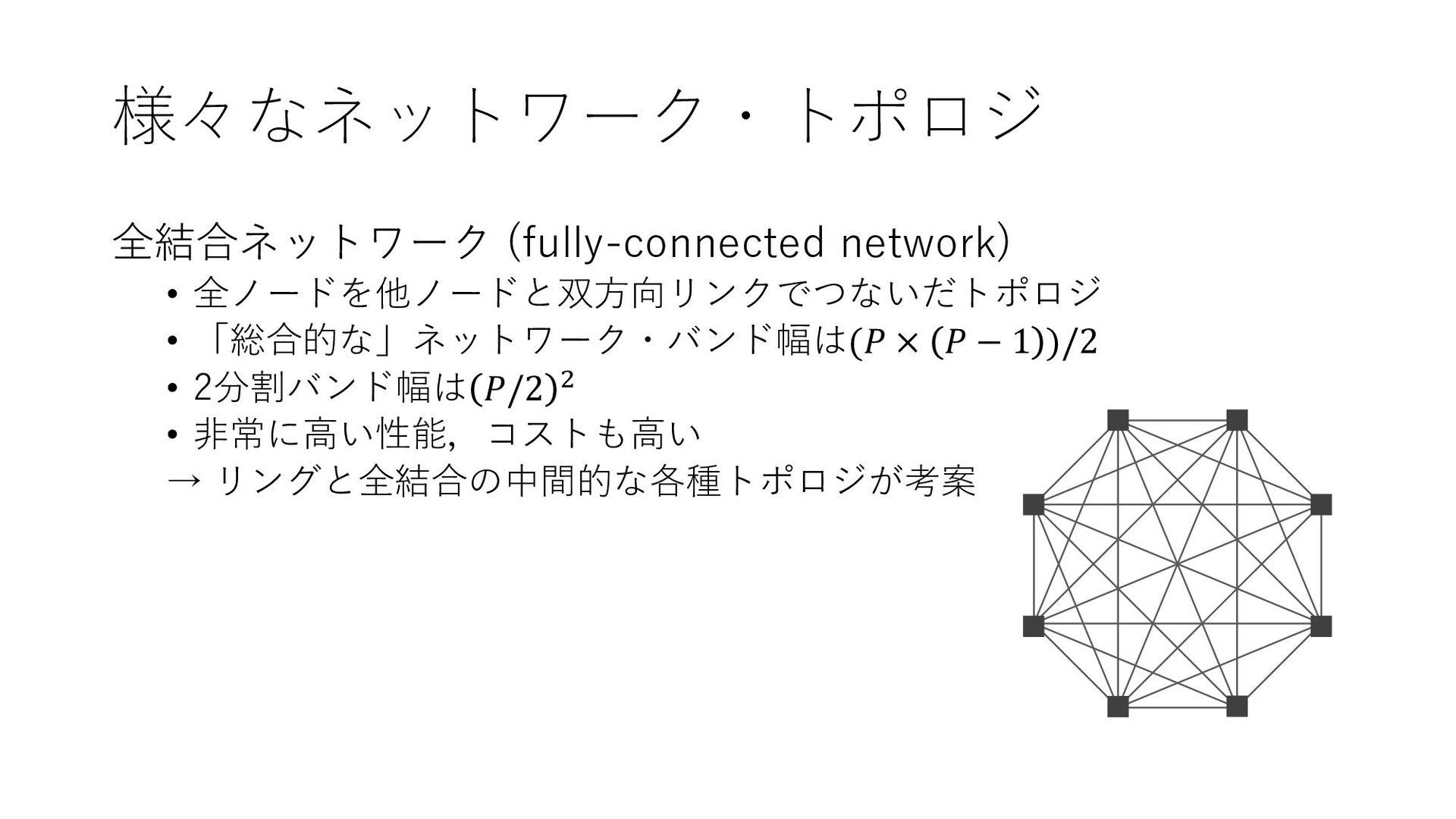
様々なネットワーク・トポロジ 全結合ネットワーク (fully-connected network) • 全ノードを他ノードと双方向リンクでつないだトポロジ • 「総合的な」ネットワーク・バンド幅は(𝑃 × 𝑃
− 1 )/2 • 2分割バンド幅は 𝑃/2 2 • 非常に高い性能,コストも高い → リングと全結合の中間的な各種トポロジが考案
様々なネットワーク・トポロジ 商用の並列プロセッサで使用されている代表的なトポロジ • 各スイッチはノードと1:1接続 • 2次元格子 (メッシュ) • 縦横にリングネットワーク •
これをさらに進化させた多次元トーラス は近年のHPCネットワークで よく利用される • ブーリアンnキューブ・トポロジ • 2𝑛個のノードと𝑛次元空間で相互結合する • 隣接ノード数も𝑛
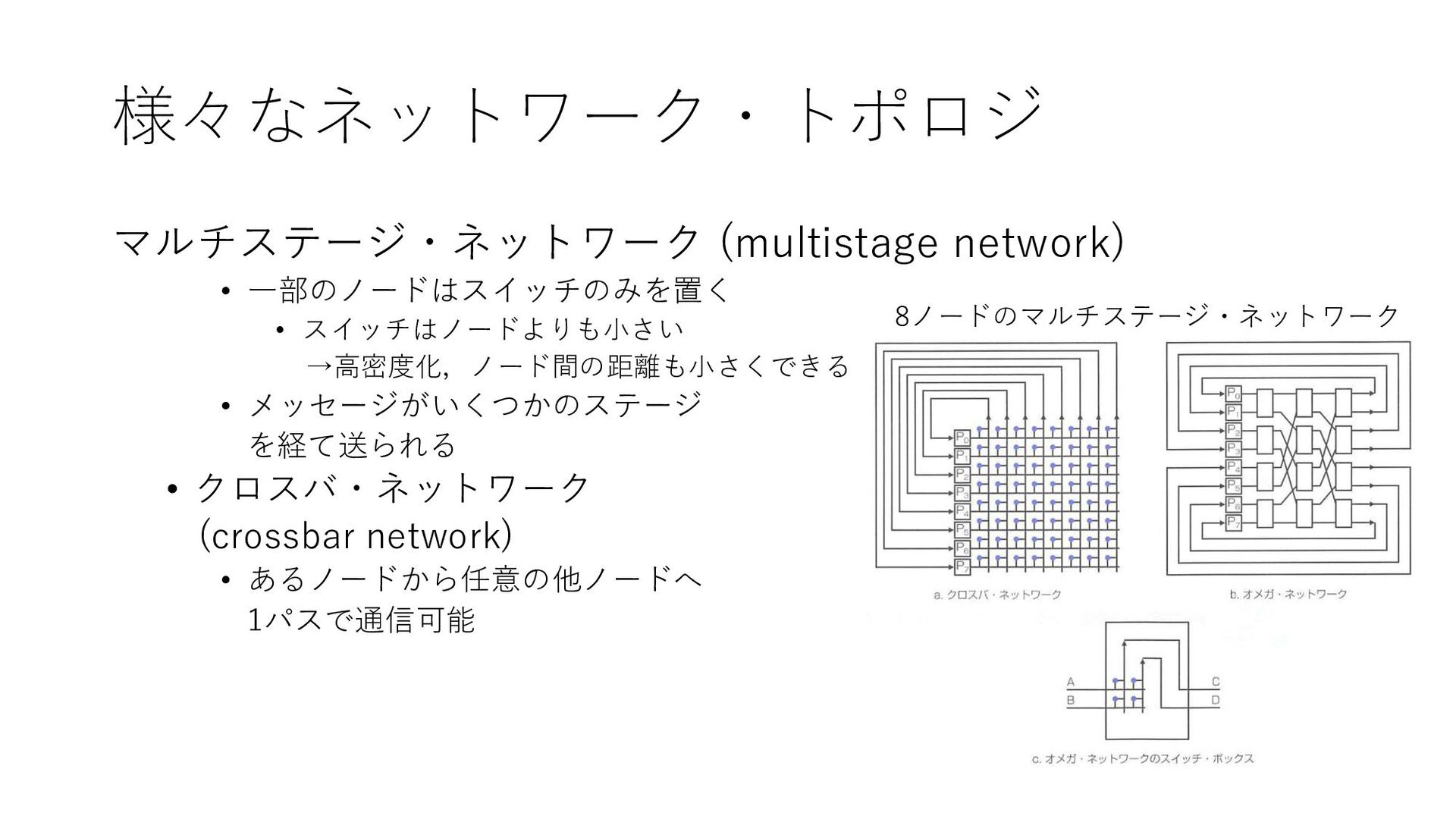
様々なネットワーク・トポロジ マルチステージ・ネットワーク (multistage network) • 一部のノードはスイッチのみを置く • スイッチはノードよりも小さい →高密度化,ノード間の距離も小さくできる •
メッセージがいくつかのステージ を経て送られる • クロスバ・ネットワーク (crossbar network) • あるノードから任意の他ノードへ 1パスで通信可能 8ノードのマルチステージ・ネットワーク
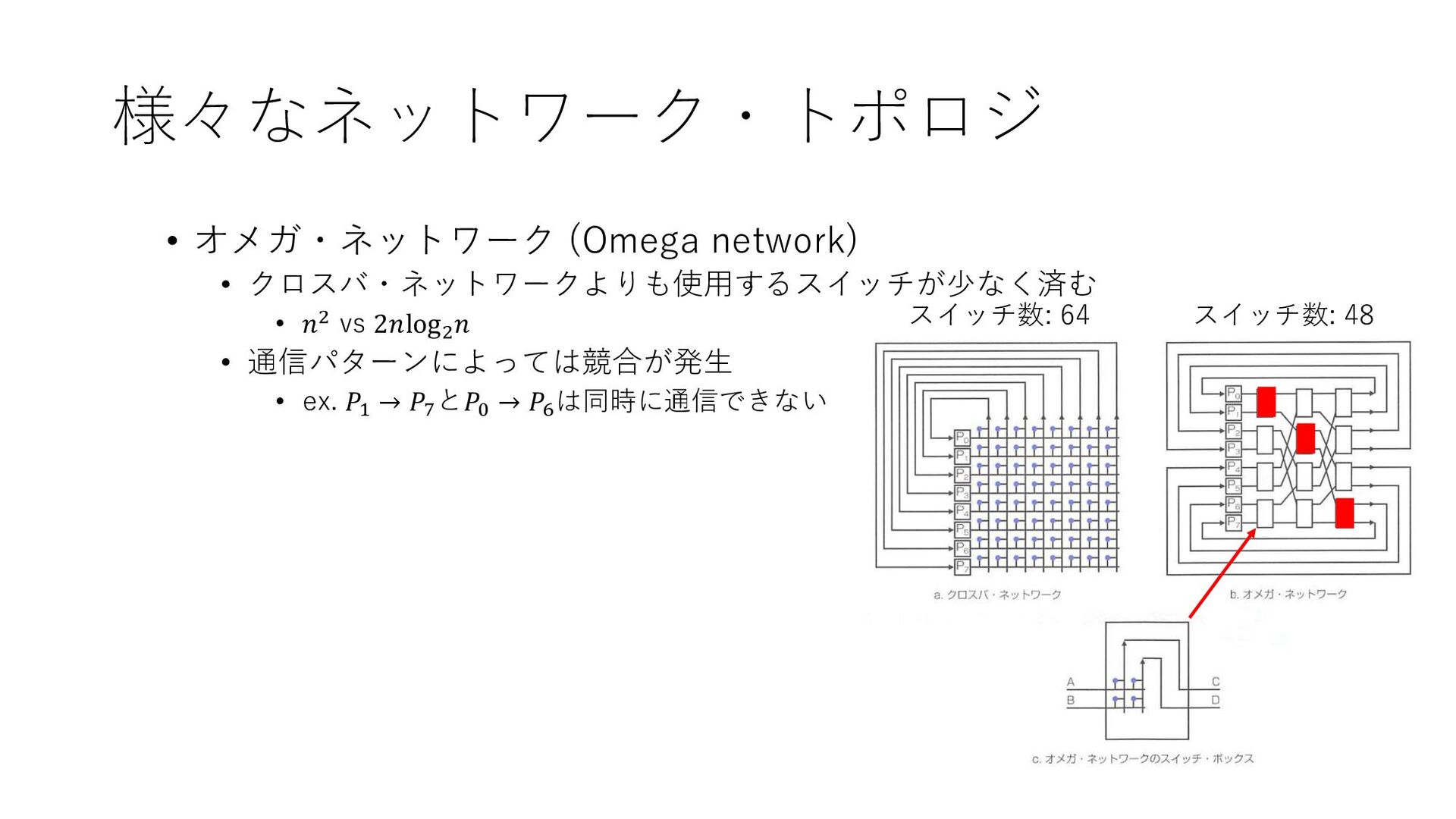
様々なネットワーク・トポロジ • オメガ・ネットワーク (Omega network) • クロスバ・ネットワークよりも使用するスイッチが少なく済む • 𝑛2 vs
2𝑛log2 𝑛 • 通信パターンによっては競合が発生 • ex. 𝑃1 → 𝑃7 と𝑃0 → 𝑃6 は同時に通信できない スイッチ数: 64 スイッチ数: 48
ネットワーク・トポロジの実現 • 実際のネットワークでは • リンクの長さ • 長いリンクで高クロックの通信をするのはコストが高い • 逆に短いと各リンクの配線数を増やすことが容易に・コストも低くなる •
3次元のトポロジをチップやボード (2次元) にマッピングする方法 • エネルギー これらの制約により,理想的なネットワーク・トポロジが実現できない こともある
6.10 外部世界との通信: クラスタ・ ネットワ ーキング
クラスタの相互接続 LANの主流はEthernet • 時代とともに高速化 (2023年現在では800GbEがIEEE 802.3で標準化策定中) • NIC (Network Interface
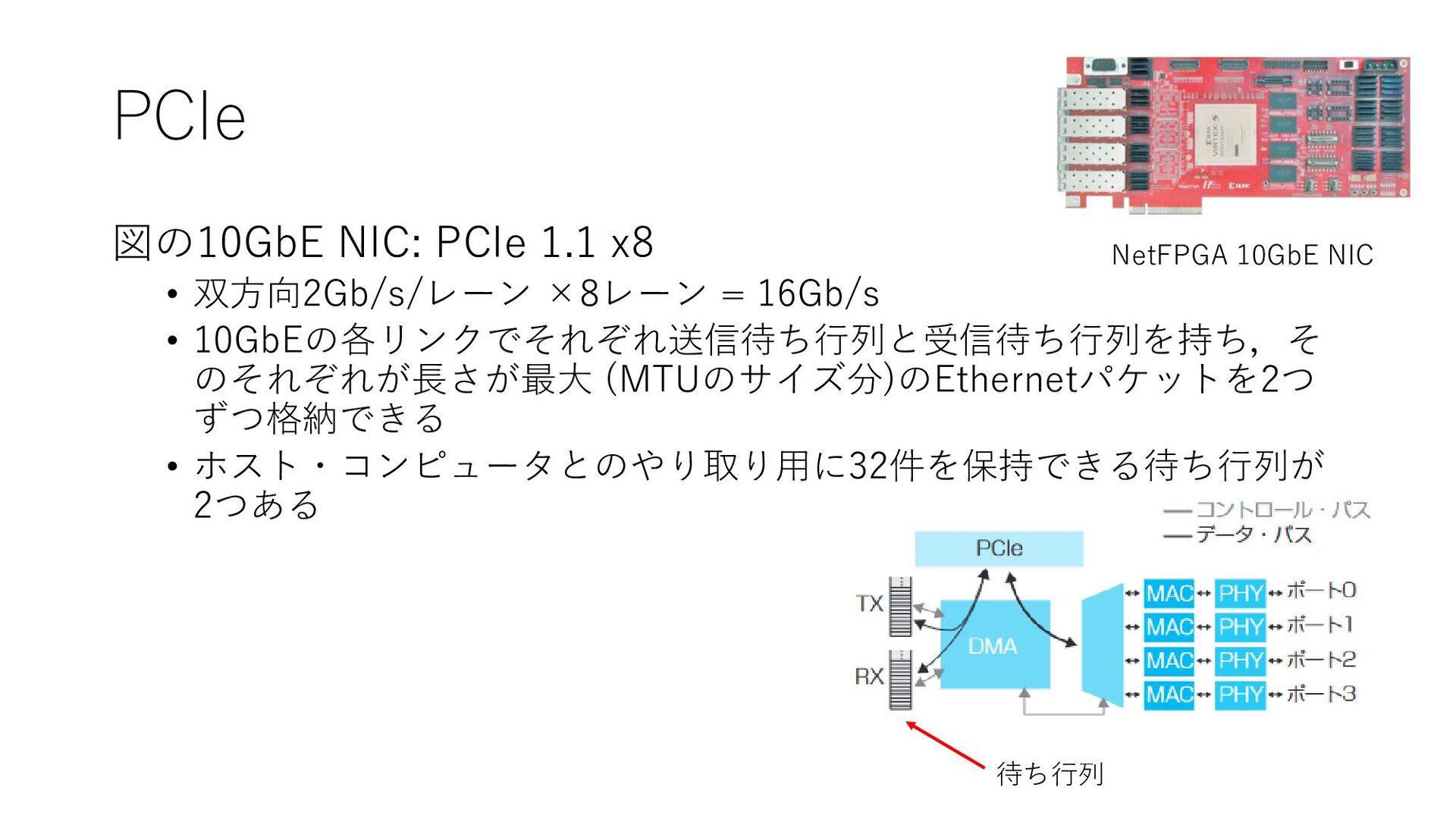
Card) によりノード間を接続 • NICは1つのインタフェースでTX (メッセージの送信) とRX (受信)の両方を行う PCIe (Peripheral Component Interconnect Express) • 高速なI/Oをマイクロプロセッサに接続するための最も一般的なリンク • 基本的な構成要素: シリアルレーン • 4本のレーン: 2×2の全二重 → リンク • リンクを複数レーン束ねて必要な帯域幅を利用 (最大32レーン) • 2023年現在で最新はPCIe 5.0 (双方向32Gb/s/レーン) NetFPGA 10GbE NIC
PCIe 図の10GbE NIC: PCIe 1.1 x8 • 双方向2Gb/s/レーン ×8レーン =
16Gb/s • 10GbEの各リンクでそれぞれ送信待ち行列と受信待ち行列を持ち,そ のそれぞれが長さが最大 (MTUのサイズ分)のEthernetパケットを2つ ずつ格納できる • ホスト・コンピュータとのやり取り用に32件を保持できる待ち行列が 2つある 待ち行列 NetFPGA 10GbE NIC
メモリ・マップI/O • アドレス空間の一部をI/O装置に充てる • NICに命令を与えるために,プロセッサは装置のアドレスを指定して コマンド語を発する ←装置のアドレスが必要 • ブート中にPCIe装置は指定した長さのアドレス領域割当を要求 •
以降は該当アドレス宛のアクセスは各装置に振り向けられる = 各装置への命令 • 割り当てられたアドレス空間にユーザ・プログラムは直接アク セスできない • 代わりにあるアドレスへアクセスすることで利用できる
DMA (ダイレクト・メモリ・アクセス) • デバイス・コントローラがメモリとI/O装置の間でデータを直 に受け渡す仕組み • ユーザ空間からI/O空間へのデータ転送に伴うプロセッサの負 荷をオフロード • データ転送完了をOSに伝達するために入出力割込みを発生
• 例外とは別 • I/Oの入出力割込みは非同期 • 単純な割込みではなく,付加情報がある (データサイズなど)
OSの役割 • 同一のプロセッサを使用している複数のプログラムがネット ワークを共有する • 処理条件に関する情報を交換するために割込みを利用する • 割込みがあったらカーネル・モード or スーパーバイザ・モードに切り
替える必要がある
OSの役割 必要とされる機能 • ユーザ・プログラムがアクセスできるのは該当ユーザが権限を持つI/O の一部分のみであることを保証 • I/Oに対するアクセス操作の抽象化 • I/Oの生成した例外の処理 •
システムのスループットを上げるためのアクセススケジューリング, 共有のI/Oに公平にアクセスできるようにする仕組み
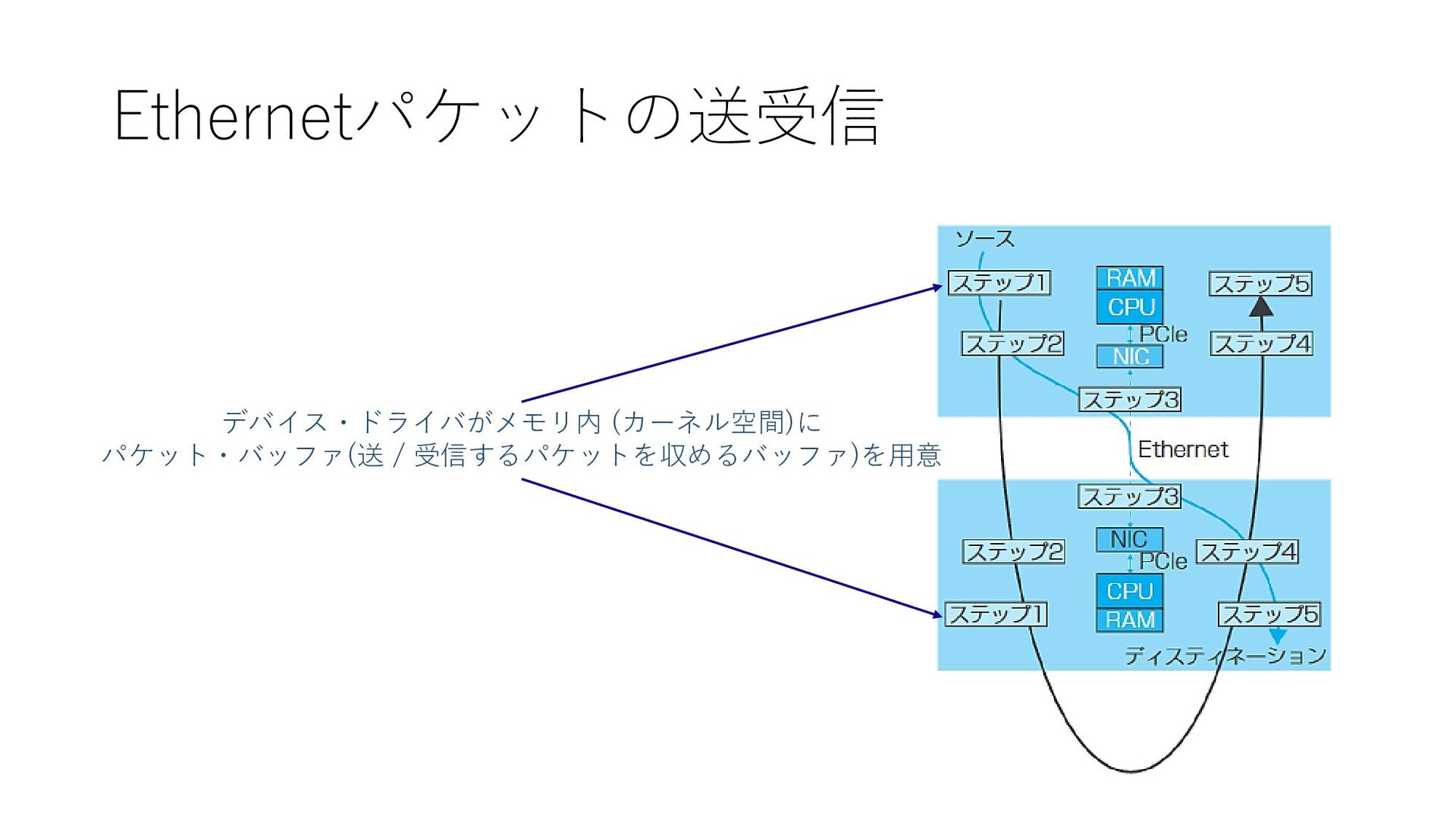
Ethernetパケットの送受信 デバイス・ドライバがメモリ内 (カーネル空間)に パケット・バッファ(送 / 受信するパケットを収めるバッファ)を用意
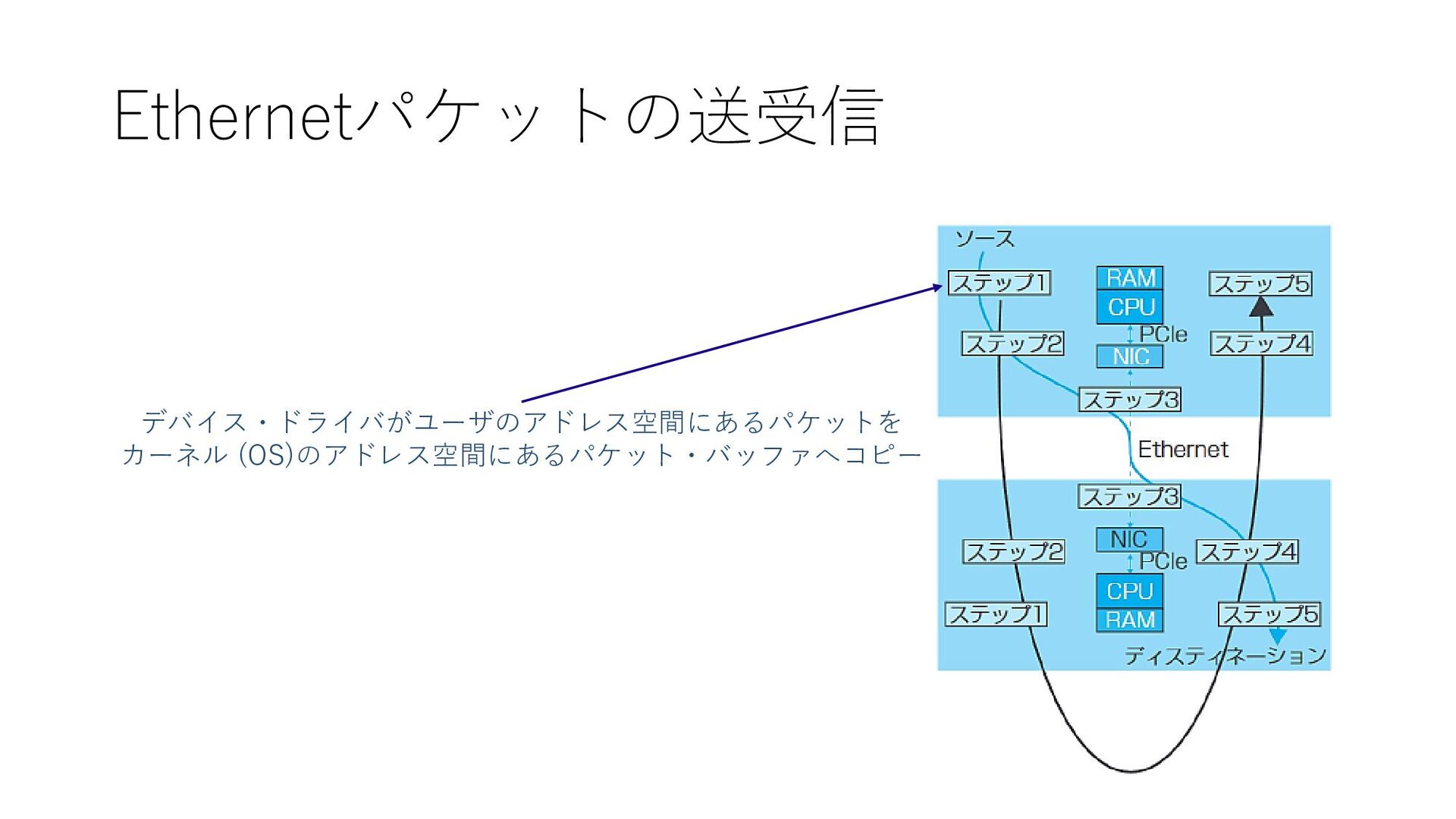
Ethernetパケットの送受信 デバイス・ドライバがユーザのアドレス空間にあるパケットを カーネル (OS)のアドレス空間にあるパケット・バッファへコピー
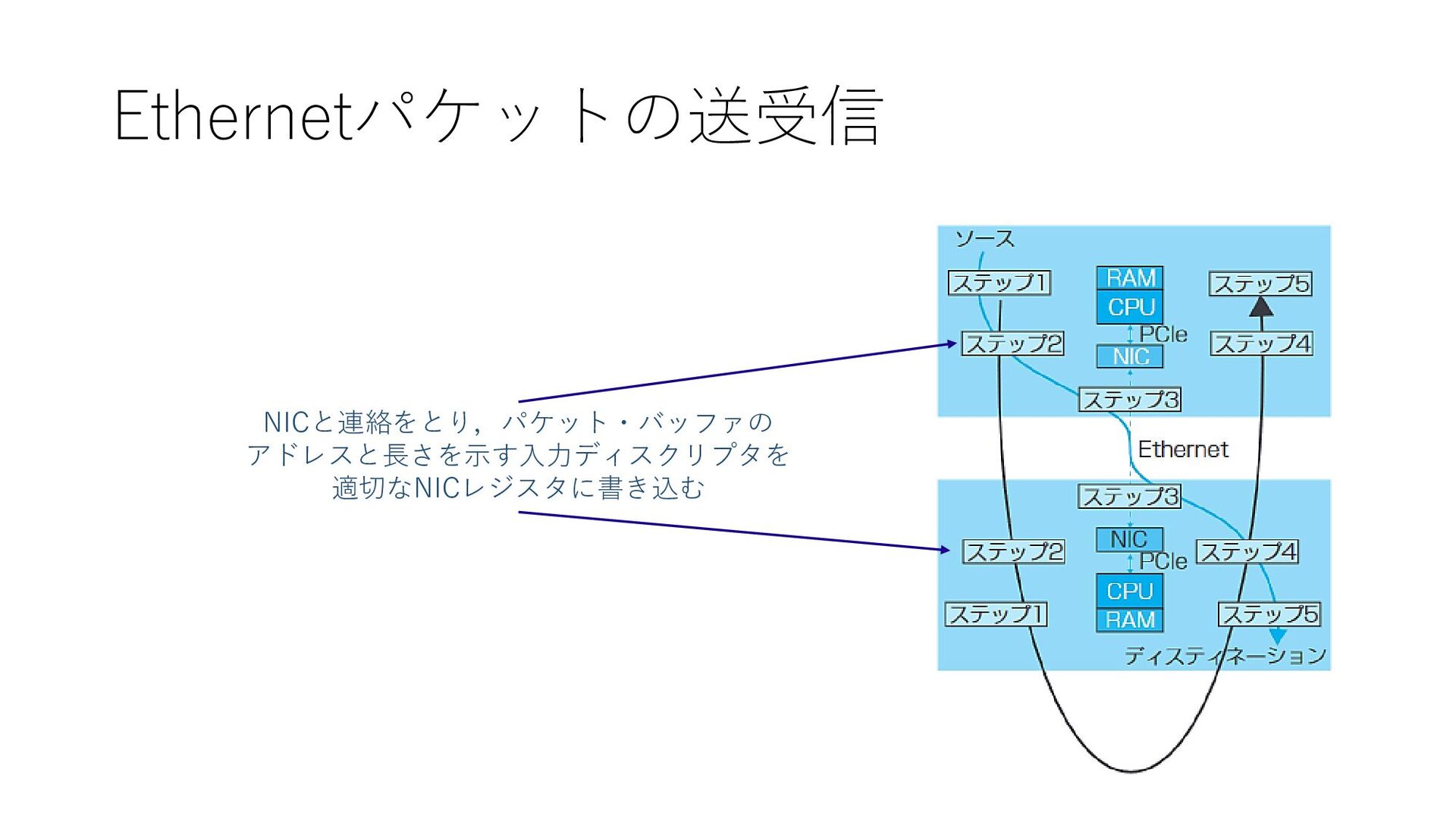
Ethernetパケットの送受信 NICと連絡をとり,パケット・バッファの アドレスと長さを示す入力ディスクリプタを 適切なNICレジスタに書き込む
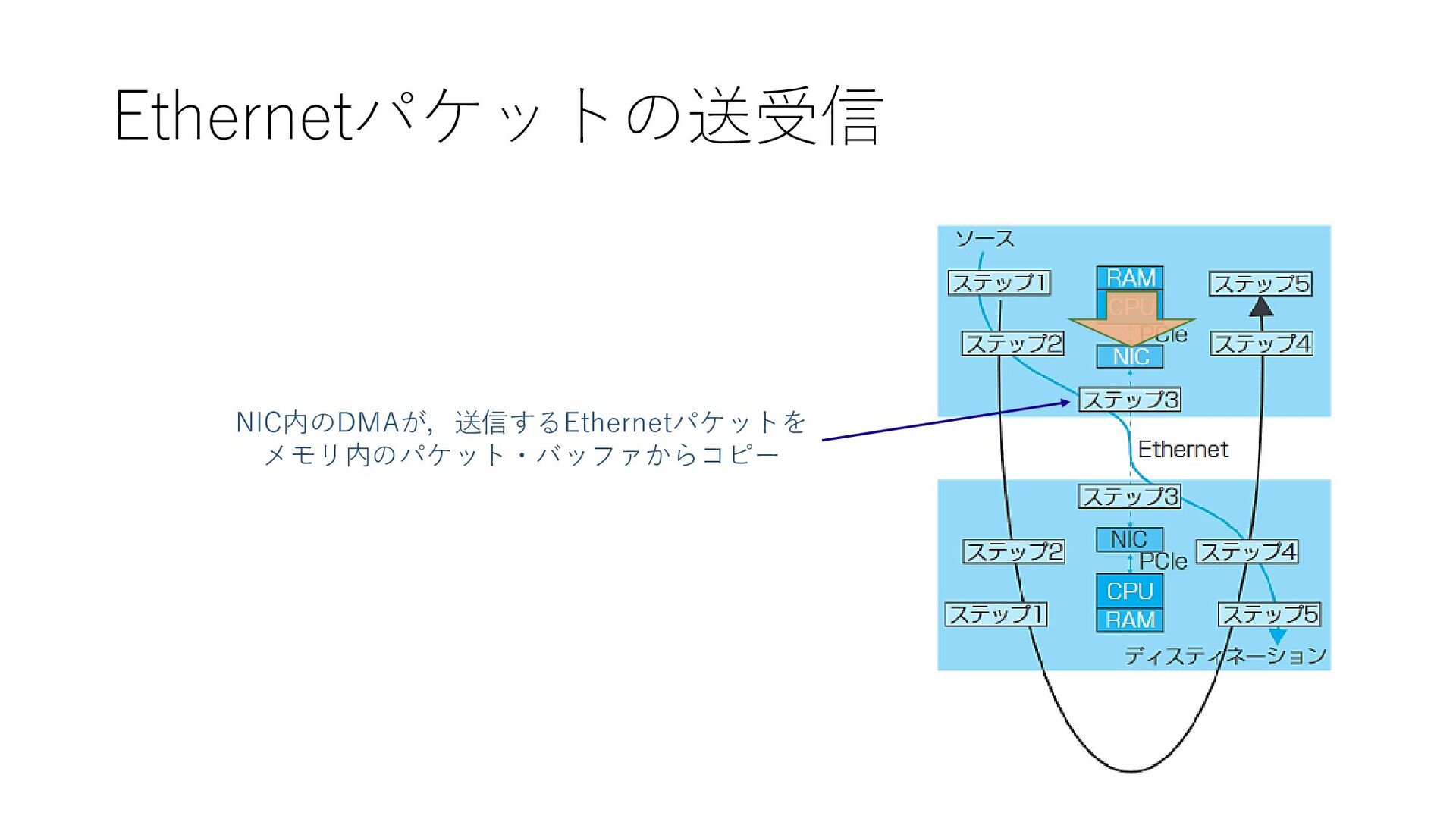
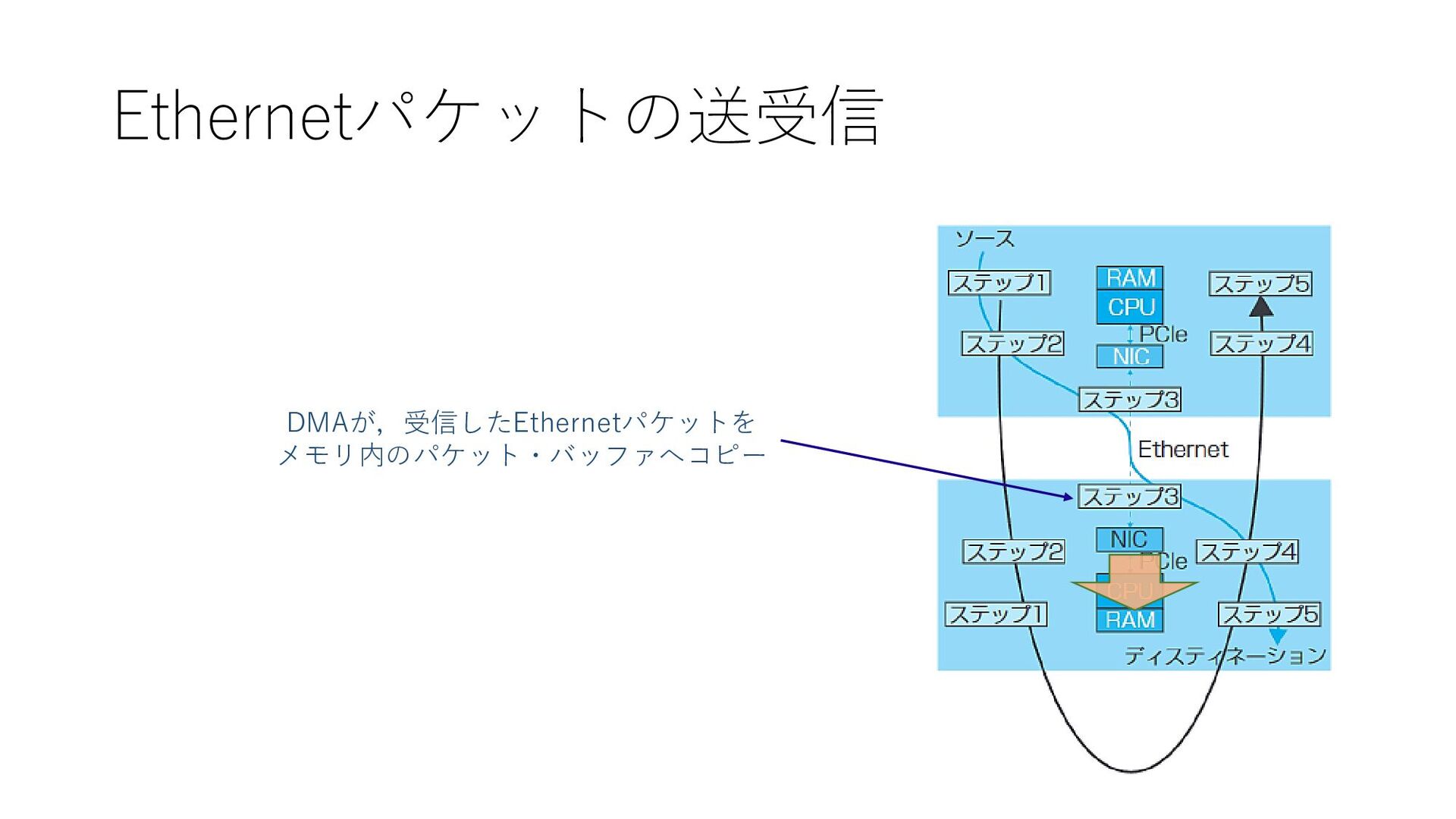
Ethernetパケットの送受信 NIC内のDMAが,送信するEthernetパケットを メモリ内のパケット・バッファからコピー
Ethernetパケットの送受信 DMAが,受信したEthernetパケットを メモリ内のパケット・バッファへコピー
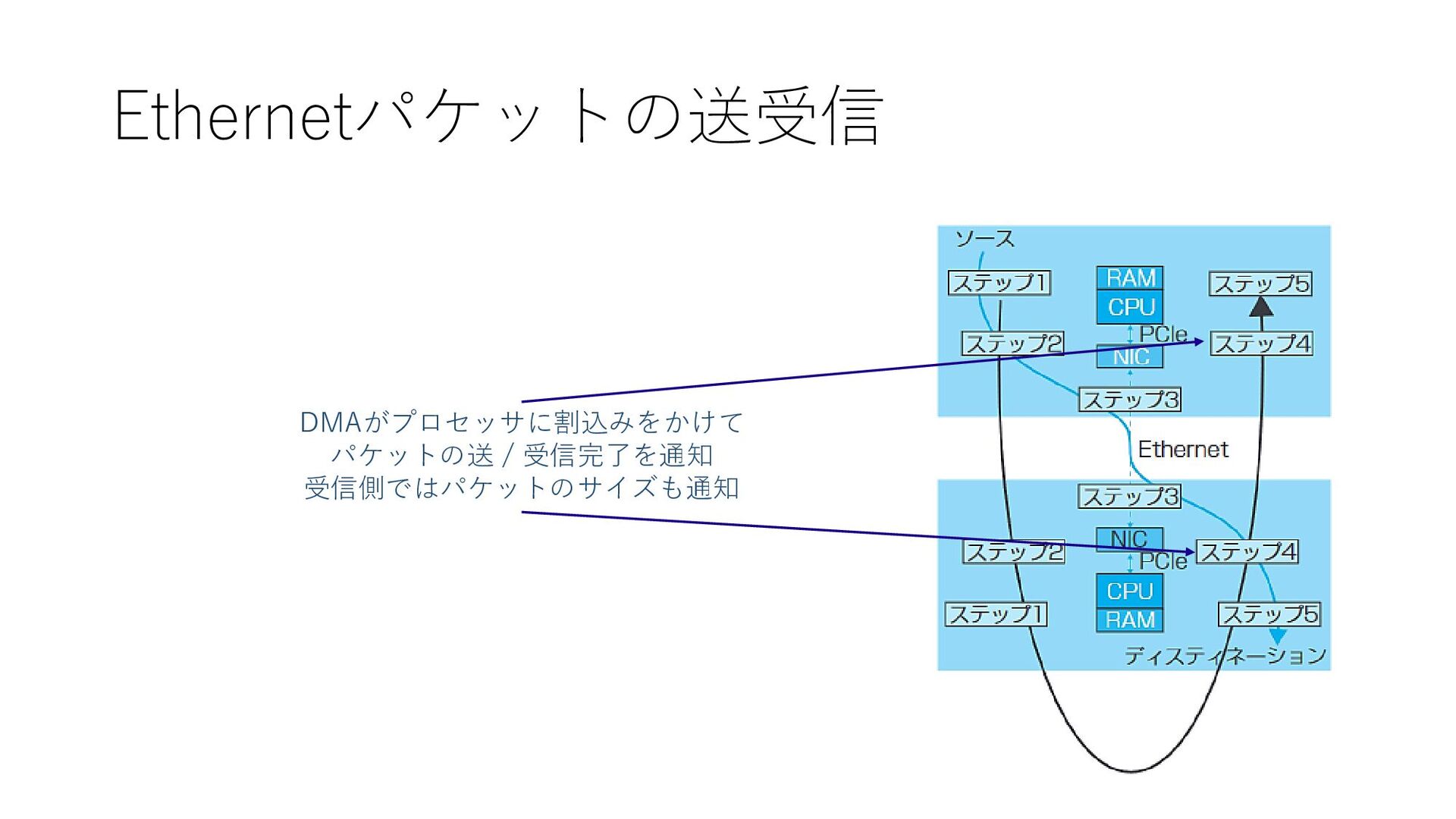
Ethernetパケットの送受信 DMAがプロセッサに割込みをかけて パケットの送 / 受信完了を通知 受信側ではパケットのサイズも通知
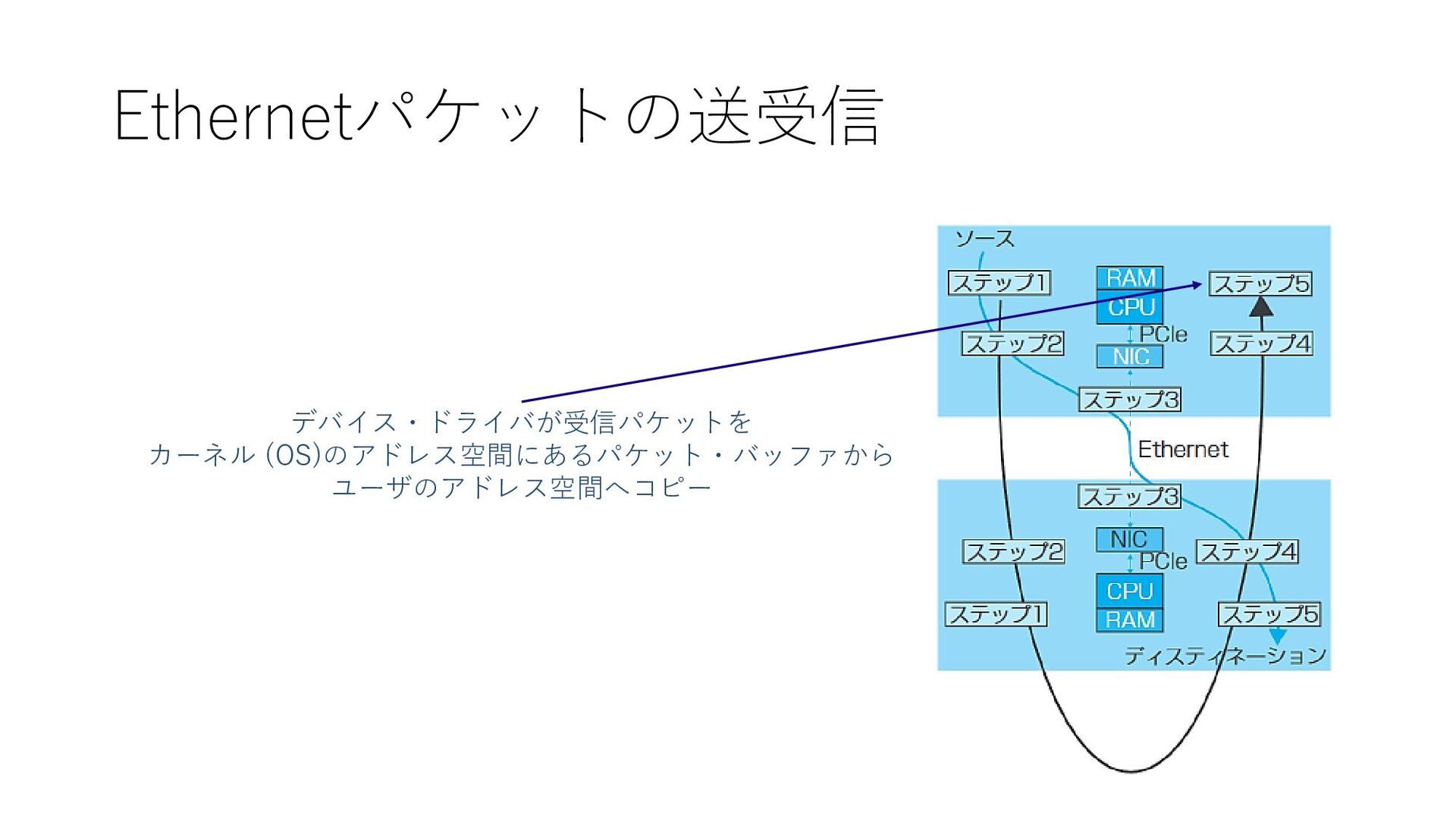
Ethernetパケットの送受信 デバイス・ドライバが受信パケットを カーネル (OS)のアドレス空間にあるパケット・バッファから ユーザのアドレス空間へコピー
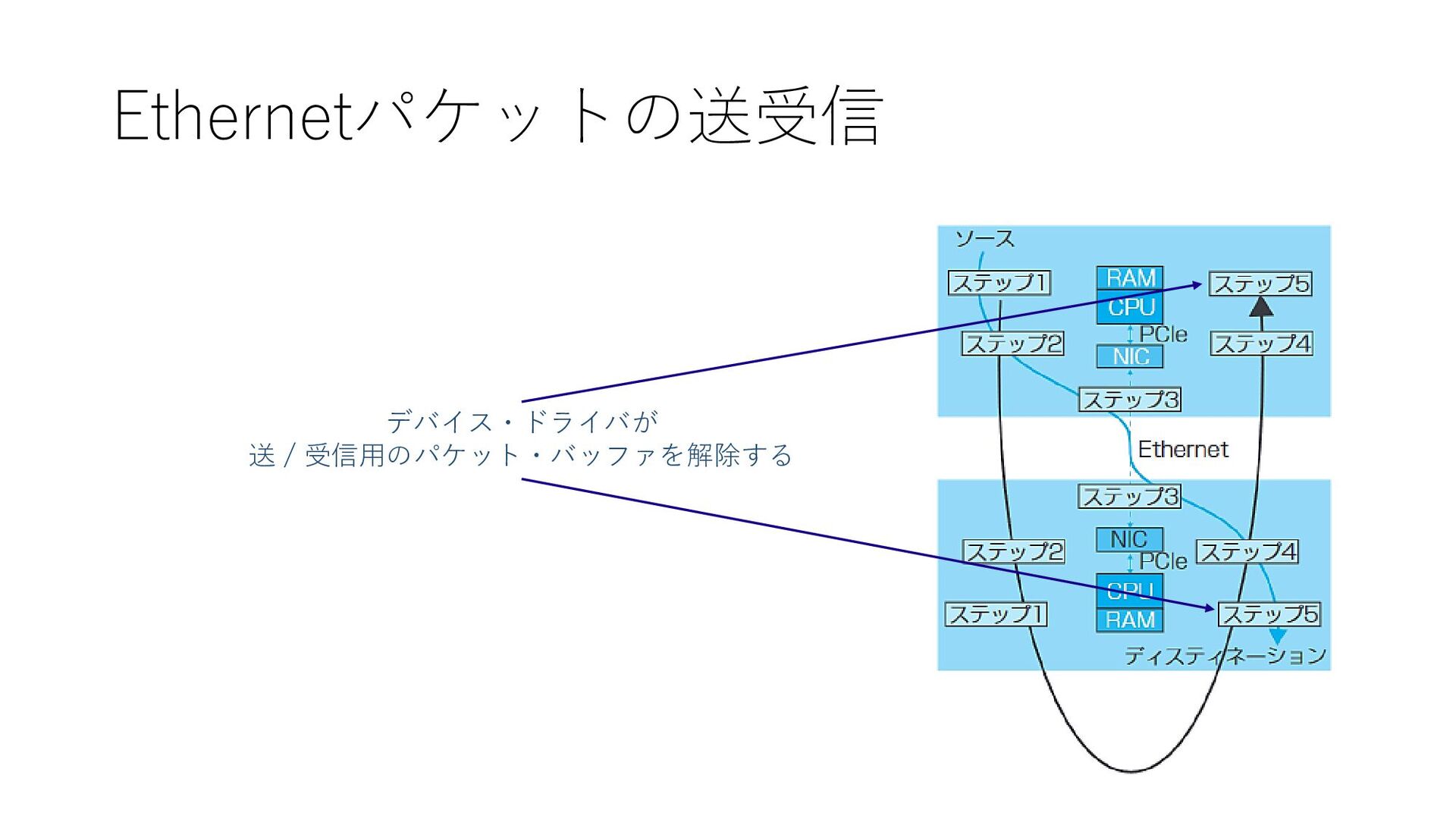
Ethernetパケットの送受信 デバイス・ドライバが 送 / 受信用のパケット・バッファを解除する
ネットワークのパフォーマンス改善 パフォーマンス低下の原因: SW: • OSのアドレス空間 ←→ ユーザのアドレス空間のデータコピー • リソース (メモリ)
が枯渇しないうちに処理を完了させる必要がある • カーネル空間 ←→ ユーザ空間のコンテキストスイッチ切替 • 割込みによるパイプラインの乱れ HW: • Ethernetパケットのフィールドの値計算 • デバイス・ドライバ (CPU) で行うとPCIe経由の通信が発生 → レイテンシ増加 • 記憶階層における無駄なアクセス • 制御用に使用されるデータを主記憶に書くとキャッシュに都度書き込む羽目に
ネットワークのパフォーマンス改善 改善方法 • ゼロコピー最適化,ユーザ空間で処理を完結 • ポーリング • ハードウエア・オフローディング • 記憶階層に関するパフォーマンス向上
ネットワークのパフォーマンス改善 ゼロコピー最適化 送信するときにOS内のパケット・バッファを経由せず,DMAエンジン がユーザ空間からデータを直接取り出して受信側のユーザ空間に収める ユーザ空間で処理を完結 ユーザのアドレス空間のみで通信を完結させる → ex. RDMA (Remote
Direct Memory Access)
ネットワークのパフォーマンス改善 ポーリング 入出力が確認したかを示すステータスビットをプロセッサが定期的に確認しに いく → プロセッサの低電力モードを回避,入出力割込みの処理遅延を回避 ハードウエア・オフローディング ex. Ethernetパケットのフィールドの値計算 (フッタのCRC計算など)
最近はTLSの復号化の計算をできるものも 記憶階層に関するパフォーマンス向上 ex. DDIO (Direct Data I/O, Intel)
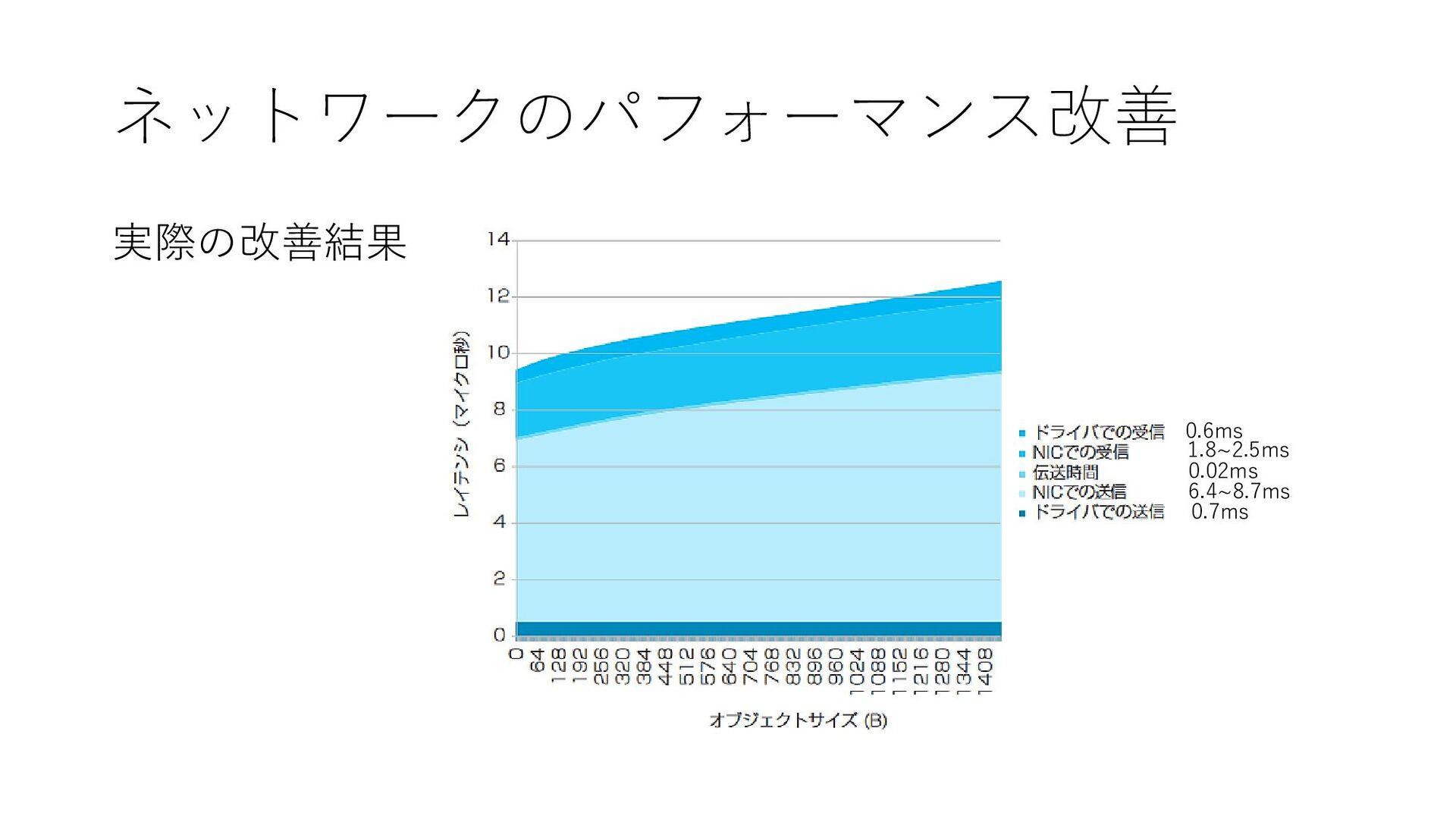
ネットワークのパフォーマンス改善 実際の改善結果 0.7ms 6.4~8.7ms 0.02ms 1.8~2.5ms 0.6ms
6.11 マルチプロセッサの ベンチマーク および性能モデル
ベンチマーキング・システム における注意点 • 意味のある指標になっていなくてはならない • 技術的トリックで勝っても意味がない • 実アプリケーションでも間違いなく優れているか? • システムの良し悪しはシステムの売れ行き,設計者の評判にも影響す
る → 規則が設けられるように
ベンチマーキング・システム における注意点 主に設定されることが多い規則 (逸脱すれば結果は無効となる) • ベンチマーク内容は変更できない • ソース・コード,データ・セット,正解データ等は固定 • ただし,問題の規模を大きくしてもよい
(弱いスケーリング) • プロセッサ数が大きく異なる環境でもベンチマークを実行するため • 強いスケーリングはNG • 規模の異なる問題を対象にベンチマークを実行した結果を比較すると きは注意が必要
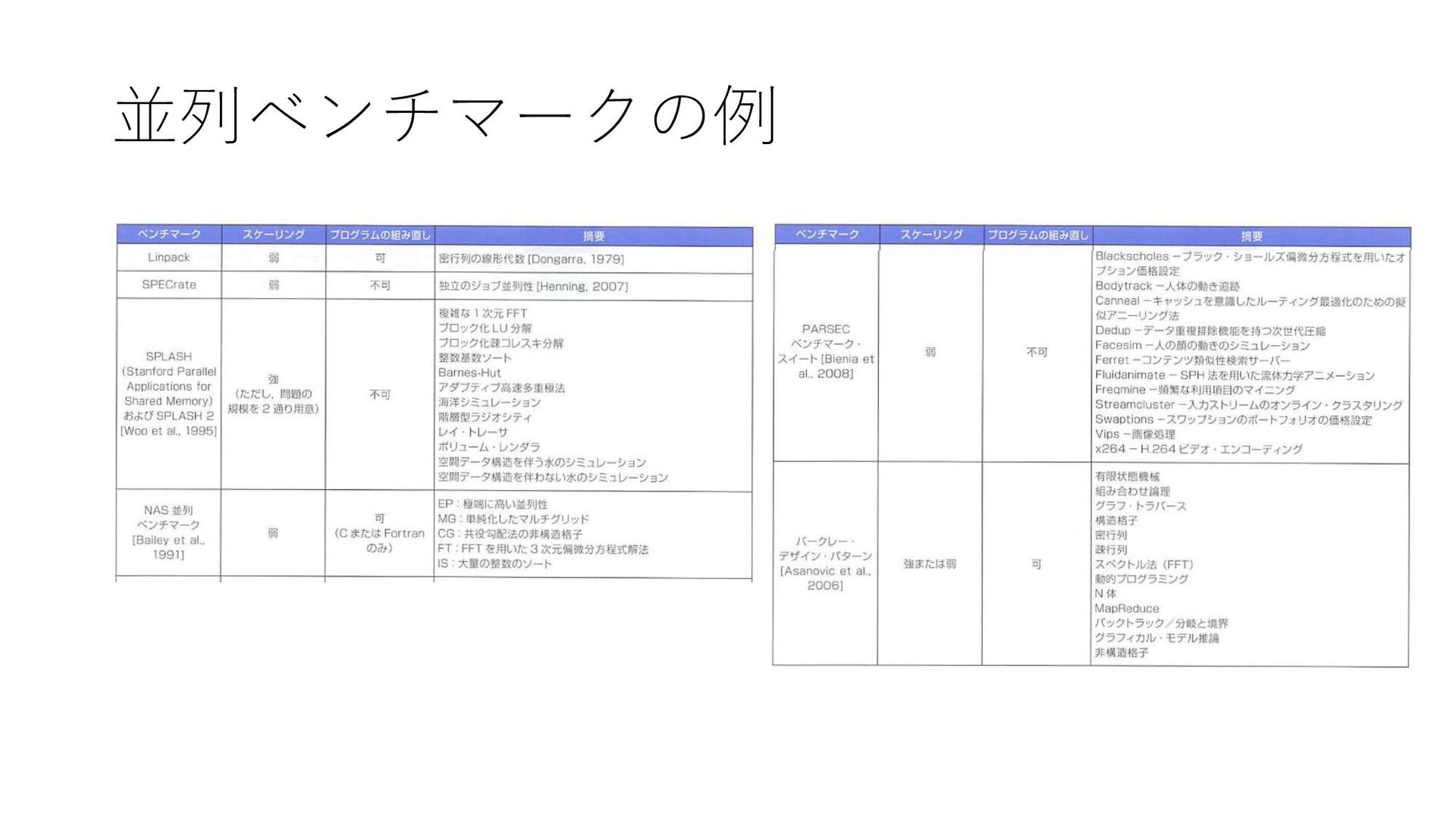
並列ベンチマークの例
ベンチマーキング・システムの変革 先ほどの各ベンチマークには問題がある • 技術革新による性能向上を計測できるのがアーキテクチャとコ ンパイラに限られる • 他にもアルゴリズム,ドメイン固有のプログラミング言語などの要素 もあるのに… • ~2005年あたりまではこのガイドラインは理に適っていたが,
現在は状況が異なる • GPUや様々なDSA,高速なインターコネクト等が出てきた → 別の観点からベンチマークを取るべきでは?
ベンチマーキング・システムの変革 ex. MLPerf • 将来のアプリケーション構成要素として13のデザインパターンを提唱 • 疎行列,構造格子,有限オートマトン,MapReduce,etc... • これらの問題を高速に解くため任意のアーキテクチャ・コンパイラだ けでなく
• データ構造 • アルゴリズム • プログラミング言語 も利用して良い • 規模の異なるシステム間での正規化のため,電力の計測も必要
性能モデル • アーキテクチャが性能にどう影響するかを大まかに示すモデル • ex. 3Cモデル (キャッシュミスについてのモデル化,5.8) • 実環境での様々な要因が無視されており実際に即したモデルではない •
プログラムの振舞いについておおよその見通しが立つので便利 以下ではバークレー・デザイン・パターンを例にとってモデルを構築
性能モデル • 浮動小数点のピーク性能を用いる • マルチコア・チップでは全コアのピーク性能の合計 • マルチプロセッサのシステムではチップあたりピーク性能×チップ数 • 記憶システムに対する要求の高さを1つの指標に •
上記のピーク性能を,アクセスされたバイトあたりの浮動小数点演算 の平均数で割ることで推測できる • ピークの浮動小数点演算数/sec 浮動小数点演算の平均数/Byte = Byte/sec
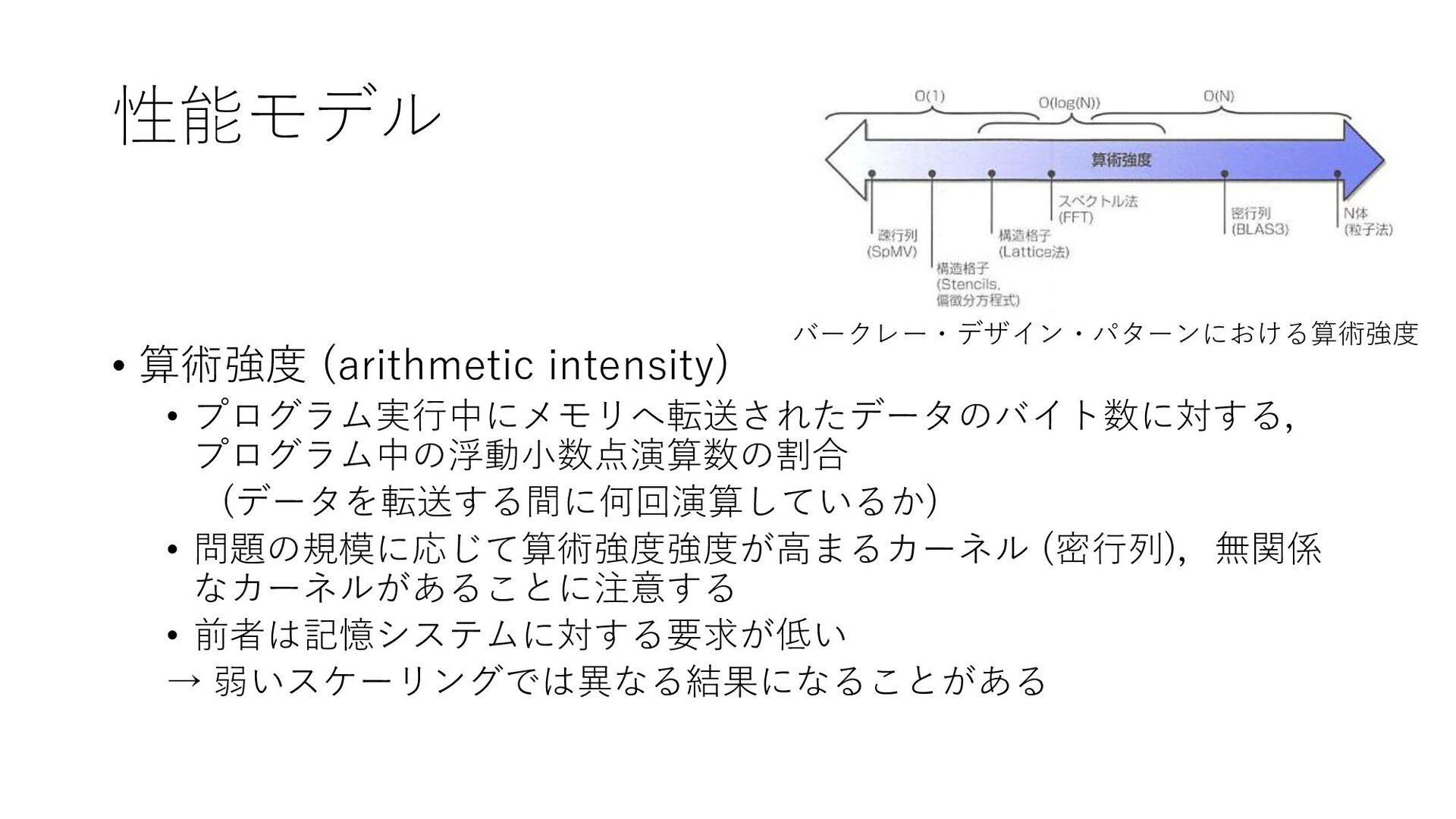
性能モデル • 算術強度 (arithmetic intensity) • プログラム実行中にメモリへ転送されたデータのバイト数に対する, プログラム中の浮動小数点演算数の割合 (データを転送する間に何回演算しているか) •
問題の規模に応じて算術強度強度が高まるカーネル (密行列),無関係 なカーネルがあることに注意する • 前者は記憶システムに対する要求が低い → 弱いスケーリングでは異なる結果になることがある バークレー・デザイン・パターンにおける算術強度
ルーフライン・モデル • 浮動小数点演算のピーク性能はハードウエア仕様から求まる • ピーク性能に達するまでは? →記憶システムに対する要求の高さに依存 • メモリのピーク性能はキャッシュの背後にある記憶システムに 依存する •
カーネルのワーキング・セットはキャッシュに収まらない大きさ • メモリのピーク性能ベンチマーク例: Streamベンチマーク • 長いベクトル演算の性能を測定 • 時間的局所性なし • コンピュータのキャッシュよりも大きな配列にアクセス
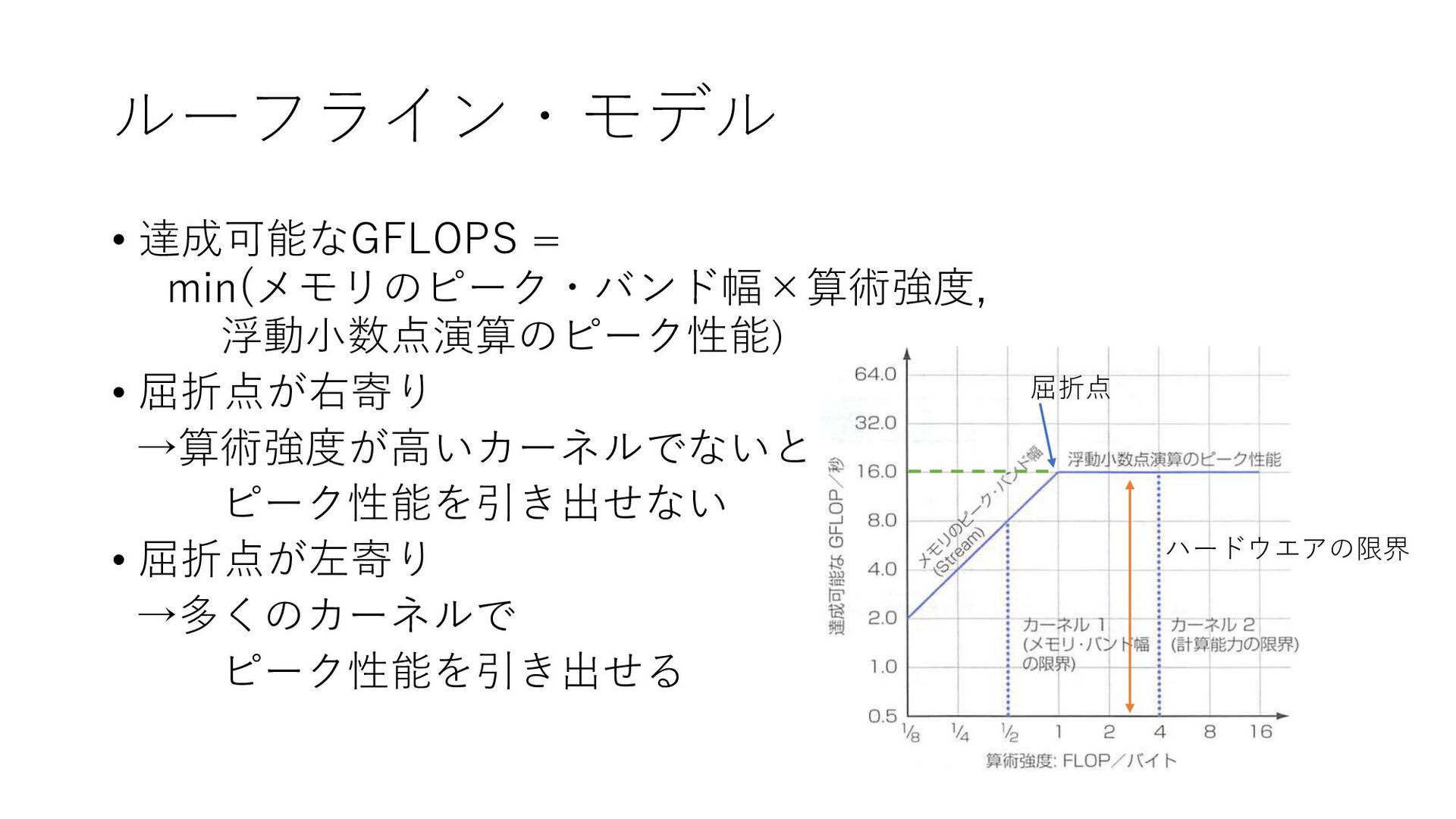
ルーフライン・モデル これらを踏まえて... ルーフライン・モデル • ある算術強度に対して,コンピュータの記憶システムがサポー トできる最大の浮動小数点演算の性能をモデル化 • カーネルに依存しない形
ルーフライン・モデル • 達成可能なGFLOPS = min(メモリのピーク・バンド幅×算術強度, 浮動小数点演算のピーク性能) • 屈折点が右寄り →算術強度が高いカーネルでないと ピーク性能を引き出せない
• 屈折点が左寄り →多くのカーネルで ピーク性能を引き出せる ハードウエアの限界 屈折点
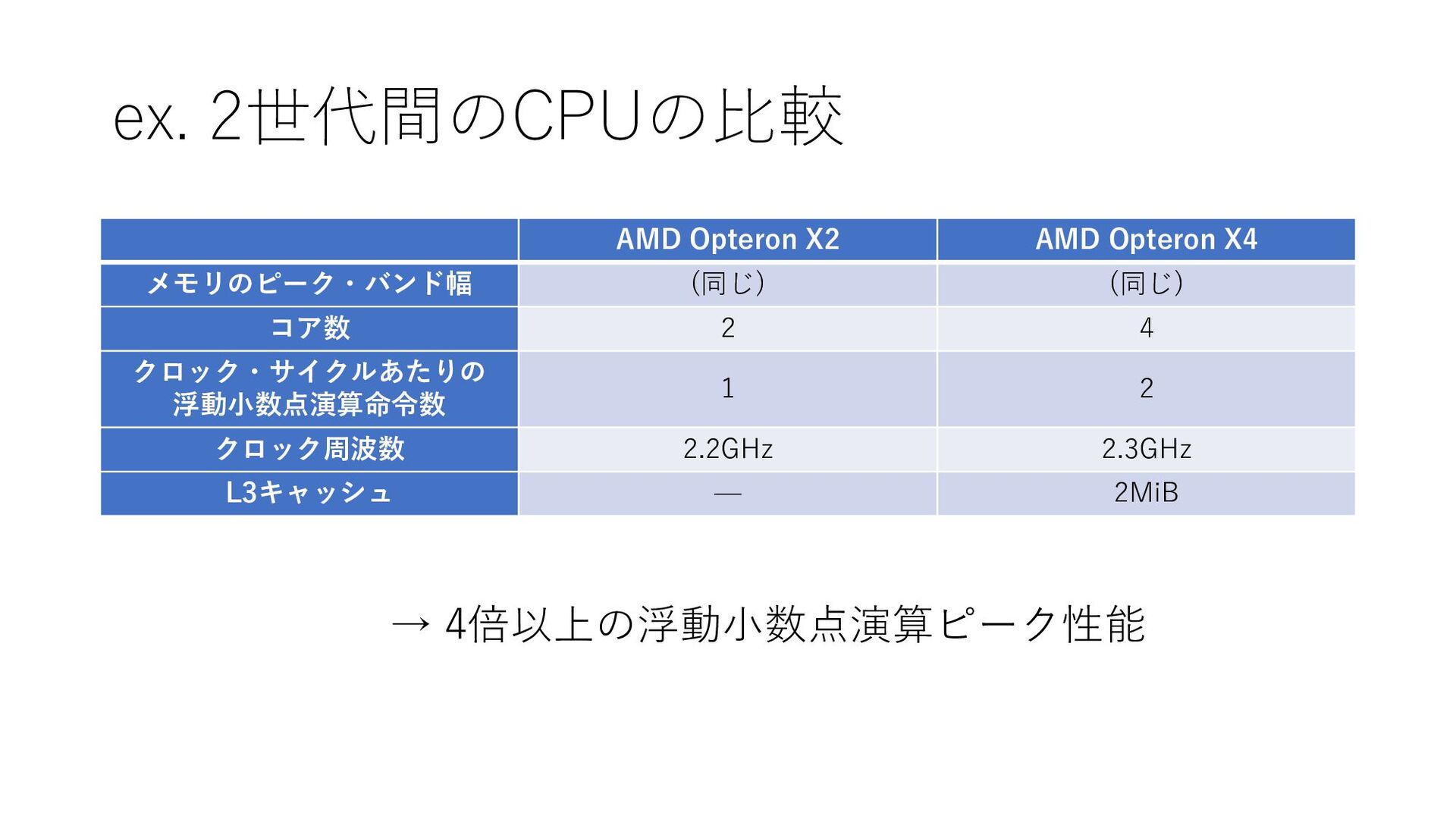
ex. 2世代間のCPUの比較 AMD Opteron X2 AMD Opteron X4 メモリのピーク・バンド幅 (同じ)
(同じ) コア数 2 4 クロック・サイクルあたりの 浮動小数点演算命令数 1 2 クロック周波数 2.2GHz 2.3GHz L3キャッシュ — 2MiB → 4倍以上の浮動小数点演算ピーク性能
ex. 2世代間のCPUの比較 Opteron X2 → Opteron X4の性能改善の効果を得るには • 算術強度が1より高いカーネルを使う •
ワーキング・セットがL3キャッシュに収まる
プログラムの最適化 演算能力上のボトルネック • 浮動小数点演算ミックス • 同じ数の乗算と加算をほぼ同時に行う • 積和命令 (FMA)が実行される (𝑎
= 𝑎 + (𝑏 × 𝑐),3.5のヒューズド積和) • 浮動小数点演算ユニットは同じ個数の加算器と乗算器を備えている • ILP (命令レベル並列性)の改善 & SIMDの適用 • スーパースカラ・アーキテクチャではクロック・サイクル毎に3~4命 令が実行されると最も性能発揮できる • ILPを高めることでこれを達成 (ex. ループ展開) • x86の場合は単一のAVX命令で倍精度オペランドを8つ操作できるので それも用いる
プログラムの最適化 メモリのボトルネック • ソフトウエア・プリフェッチ • メモリ操作にソフトウエア・プリフェッチ命令を活用 • データが計算に必要になるまで待たず,予測に基づくアクセスを実行 • メモリの近接化
• NUMAノードの変更 (より近いメモリをスレッドに割当)
プログラムの最適化 どのアプローチを選択すべきか?→ルーフライン・モデルを活用 • 演算能力の場合 • 浮動小数点演算のピーク性能 • プロセッサのマニュアルを見る • メモリの場合
• メモリのピーク・バンド幅 • Streamベンチマークを実行 • NUMAノードは実験を行って実際のバンド幅との差を把握 最適化手法に対応する「天井」を打ち破る必要がある
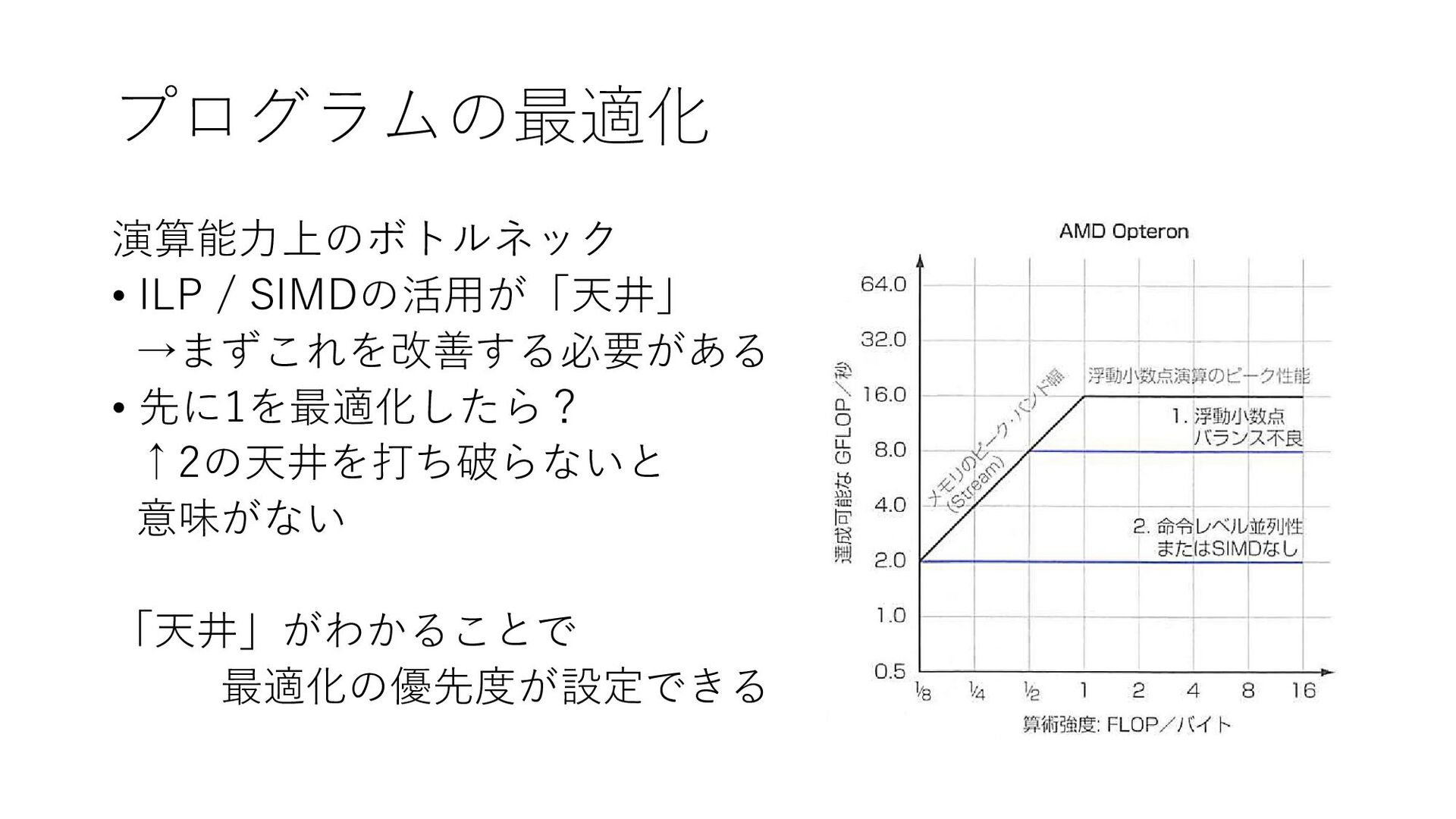
プログラムの最適化 演算能力上のボトルネック • ILP / SIMDの活用が「天井」 →まずこれを改善する必要がある • 先に1を最適化したら? ↑2の天井を打ち破らないと
意味がない 「天井」がわかることで 最適化の優先度が設定できる
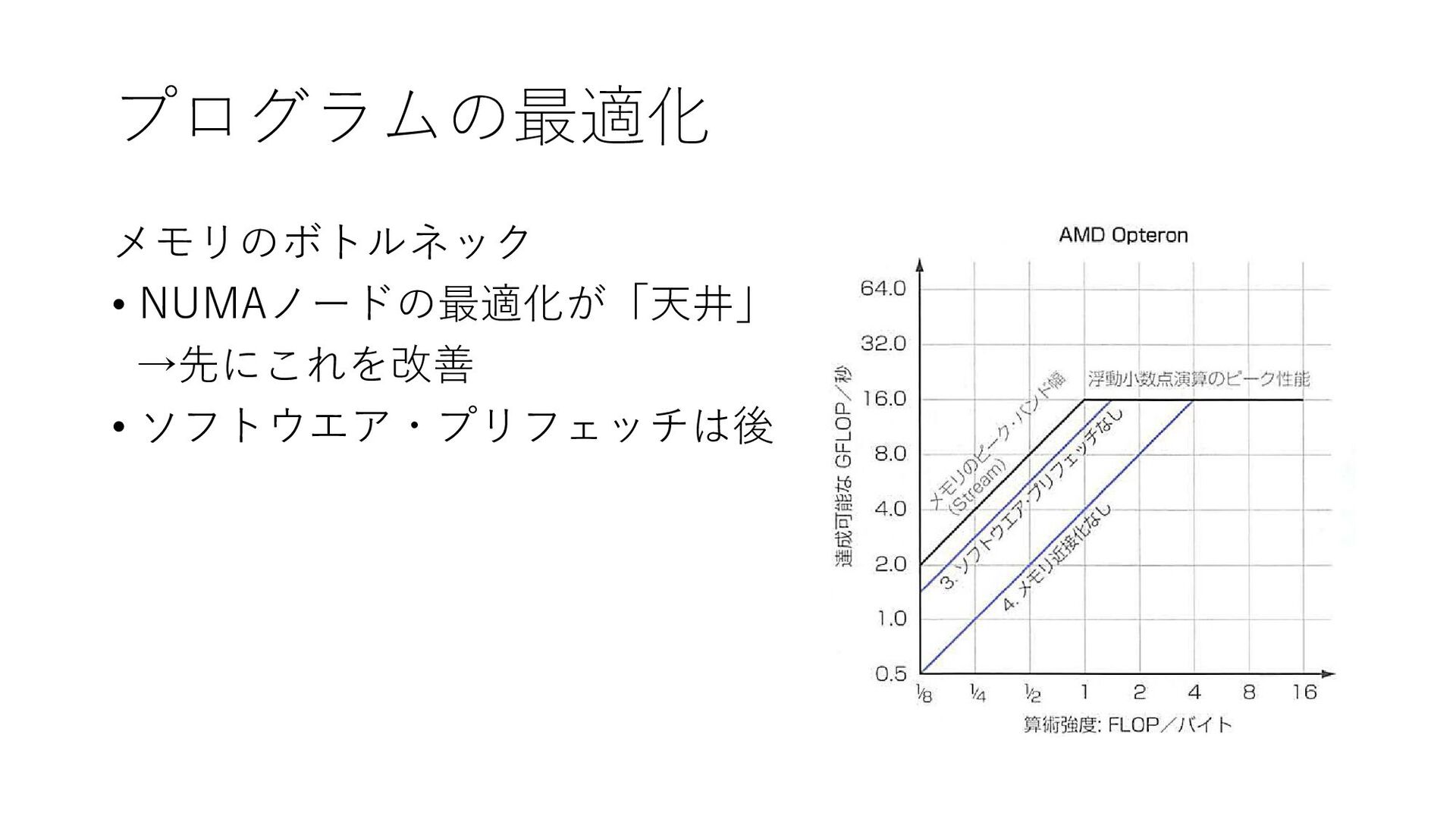
プログラムの最適化 メモリのボトルネック • NUMAノードの最適化が「天井」 →先にこれを改善 • ソフトウエア・プリフェッチは後
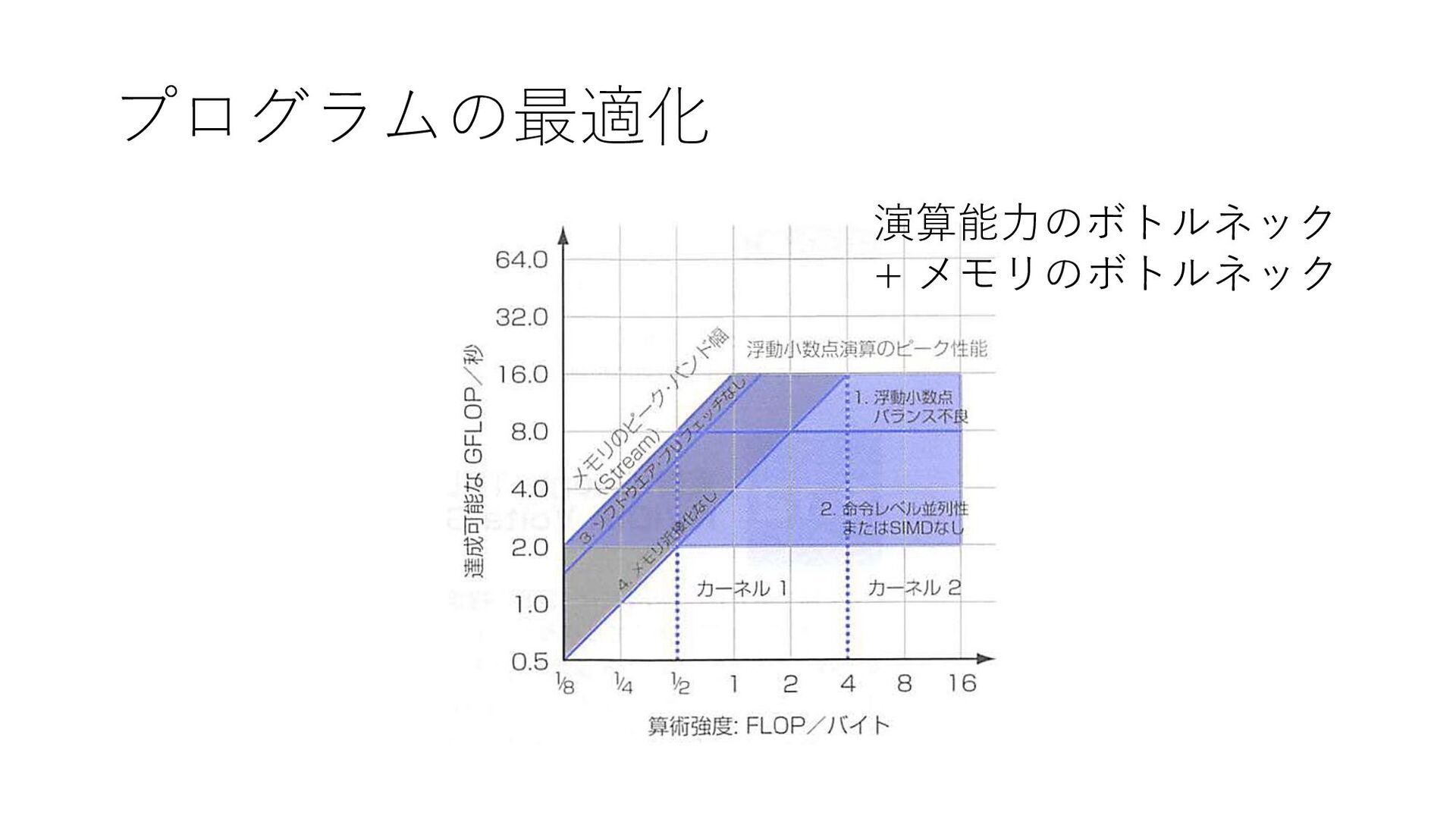
プログラムの最適化 演算能力のボトルネック + メモリのボトルネック
6.12 実例: Google TPUv3 スーパーコンピュータ およびNVIDIA Volta GPU クラスタのベンチマーク
DNNとの訓練と推論 • DNNの訓練 (学習) のフェーズを高速化する • どのようなハードウエアで高速化するか? • GPU •
DSA (Google TPU, NEC SXシリーズ, etc...) ここではGoogle TPUv3を例にとり, NVIDIA Volta GPU (Tesla V100)と比較する
DNNの処理手順 (おさらい) 1. 順伝播 • ランダムに選んだ学習データをモデルの入力に適用し推論結果を算出 • 推論ならここのフェーズで止める 2. 逆伝播
• 各層を出力から順にさかのぼり,それぞれの損失を算出 • ここの処理が重い 3. 重み更新 • 各層の入力と損失を組み合わせて,それぞれの重みの変化 (デルタ) を 計算 • 重みの変化を重みに加算 • この処理の負荷は比較的小さい
スーパーコンピュータ・ネットワーク • スーパーコンピュータではチップ間の通信が性能の鍵となる • リンクの速度,遅延,ジッタ • ネットワークトポロジ • DNNに最適なのは2次元格子トーラストポロジ •
重みの更新の際に全ノードからデルタを受け取り,縮約処理をする • 全縮約処理にはこのトポロジが有効であることがわかっている
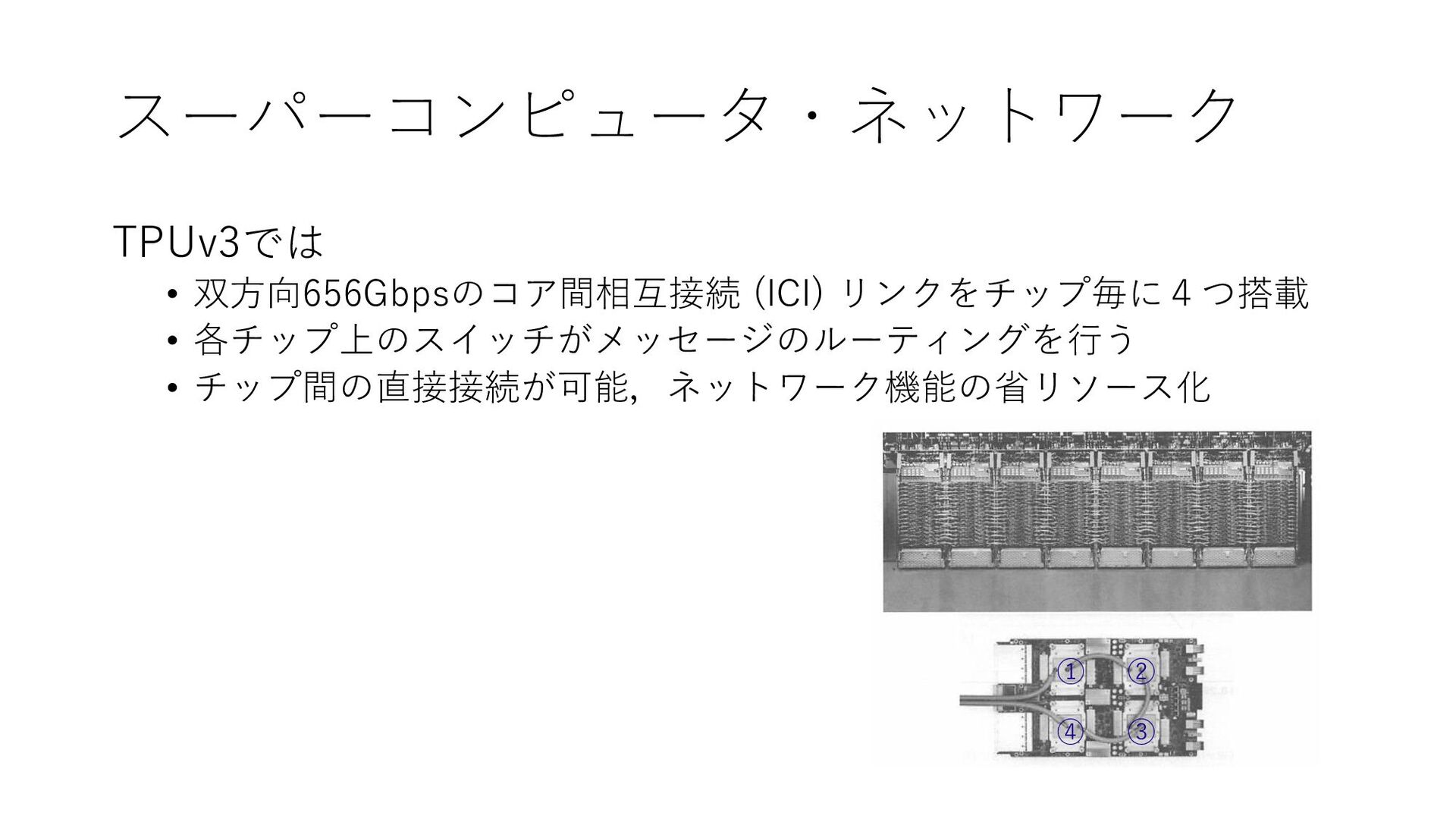
スーパーコンピュータ・ネットワーク TPUv3では • 双方向656Gbpsのコア間相互接続 (ICI) リンクをチップ毎に4つ搭載 • 各チップ上のスイッチがメッセージのルーティングを行う • チップ間の直接接続が可能,ネットワーク機能の省リソース化
① ② ③ ④
スーパーコンピュータ・ネットワーク TPUv3では • 32×32 (1024チップ) のトーラストポロジ • 2分割バンド幅: 64リンク ×
656Gbp = 42.3Tbps • 一方64ノードを接続しているInfiniband HDRのネットワークでは... • 単一の64ポートスイッチで全ノード接続 • 高々64リンク × 100Gbps = 6.4Tbps • 高コスト
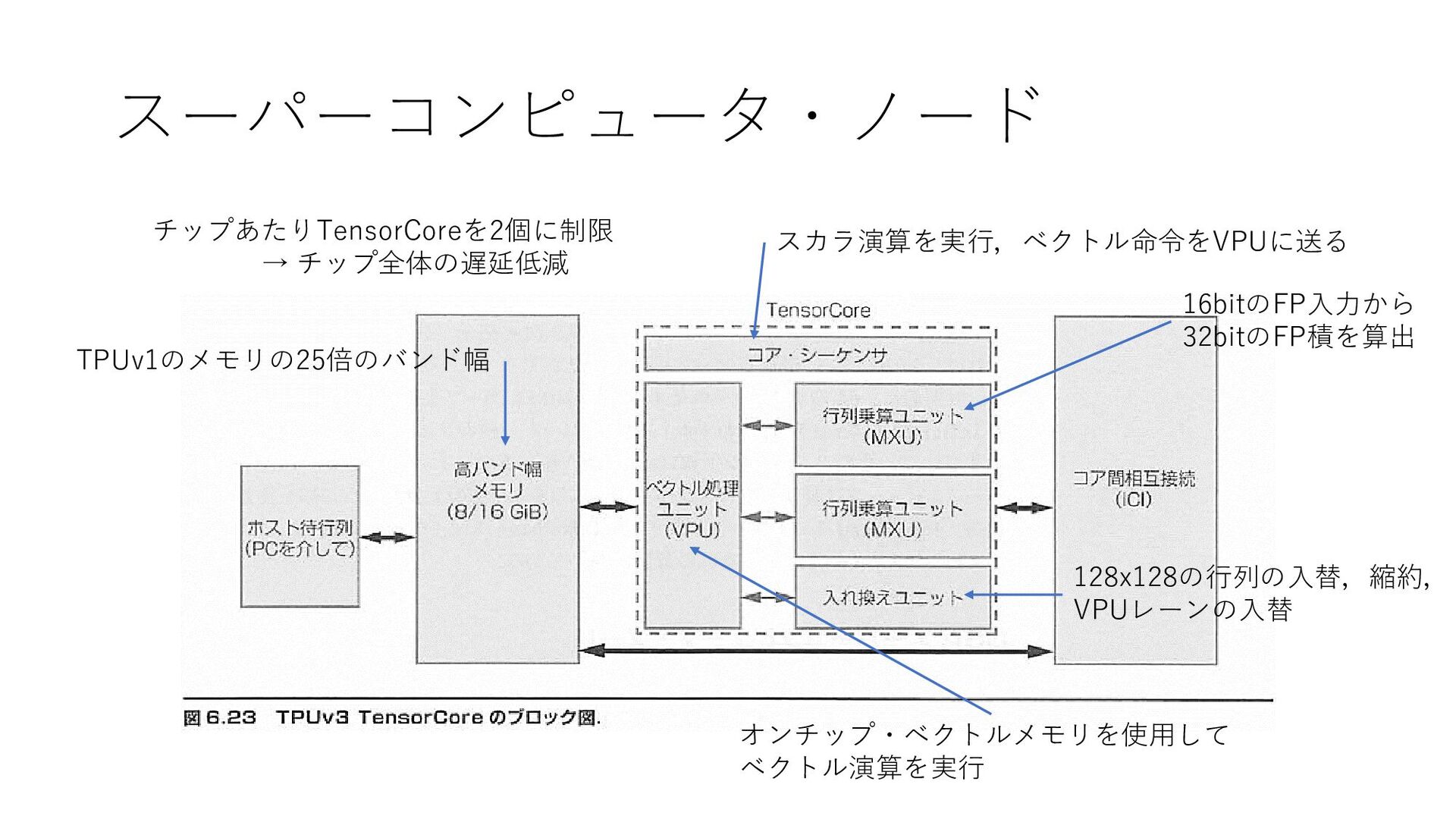
スーパーコンピュータ・ノード TPUv1のメモリの25倍のバンド幅 スカラ演算を実行,ベクトル命令をVPUに送る オンチップ・ベクトルメモリを使用して ベクトル演算を実行 16bitのFP入力から 32bitのFP積を算出 128x128の行列の入替,縮約, VPUレーンの入替 チップあたりTensorCoreを2個に制限
→ チップ全体の遅延低減
GPUとの比較
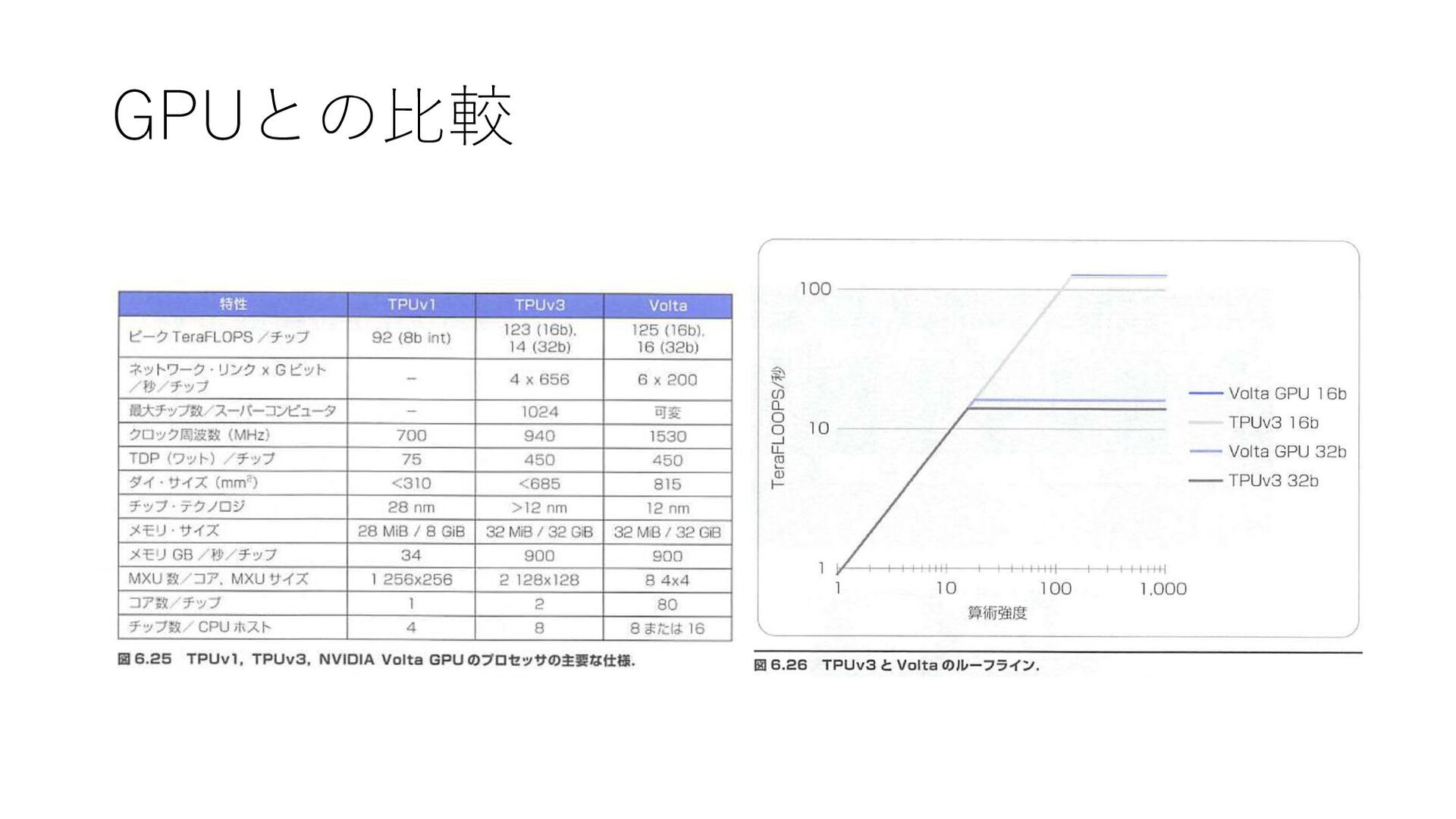
TPUv3の算術演算 • 行列乗算にfp16を使うと,ピーク性能がfp32の8倍 • 従来のfp16をDNNで使うと正確性に問題がある • 行列乗算の出力と内部での和はfp32のままである必要がある • fp16の行列乗算の入力の5bitの指数は小さいので浮動小数点演算のア ンダーフローが発生する可能性がある.
TPUv3の算術演算 → ブレイン浮動小数点フォーマット (bf16)を考案 • 行列乗算の入力の仮数のサイズをfp32の23bitから7bitに減らしても正 確性は損なわれないことがわかった • 指数はfp32と同じ8bit,仮数は7bitに短縮 →
指数が大きいので小さな更新値が失われない fp16では小さな指数にあわせて損失をスケーリングすることで調 整を行う (損失スケーリング)
実際の性能比較 • TPUv3 • ICIによる相互接続,独自コンパイラによる全縮約処理のサポート • 128x128の配列,bf16 • 計算,メモリ,ネットワークはコンパイラが制御 •
V100 • 同一ノード内のNVLink • ノード間のInfiniBandネットワーク • 4x4または16x16,fp16,損失スケーリングが必要 • 多くのスレッドを保持できる巨大なレジスタ・ファイル,CUDAが処 理操作の重ね合わせを制御
実際の性能比較 • TPUv3 • 32MiBのスクラッチパッド・メモリをソフトウエア制御,コンパイラ によってスケジュール • DRAMへの順次アクセスをTPUv3上のDMAコントローラで指示 • V100
• 6MiBをハードウエア制御,7.5MiBをソフトウエア制御 • DRAMへの順次アクセスにマルチスレッディングと結合処理用のハー ドウエアを使用
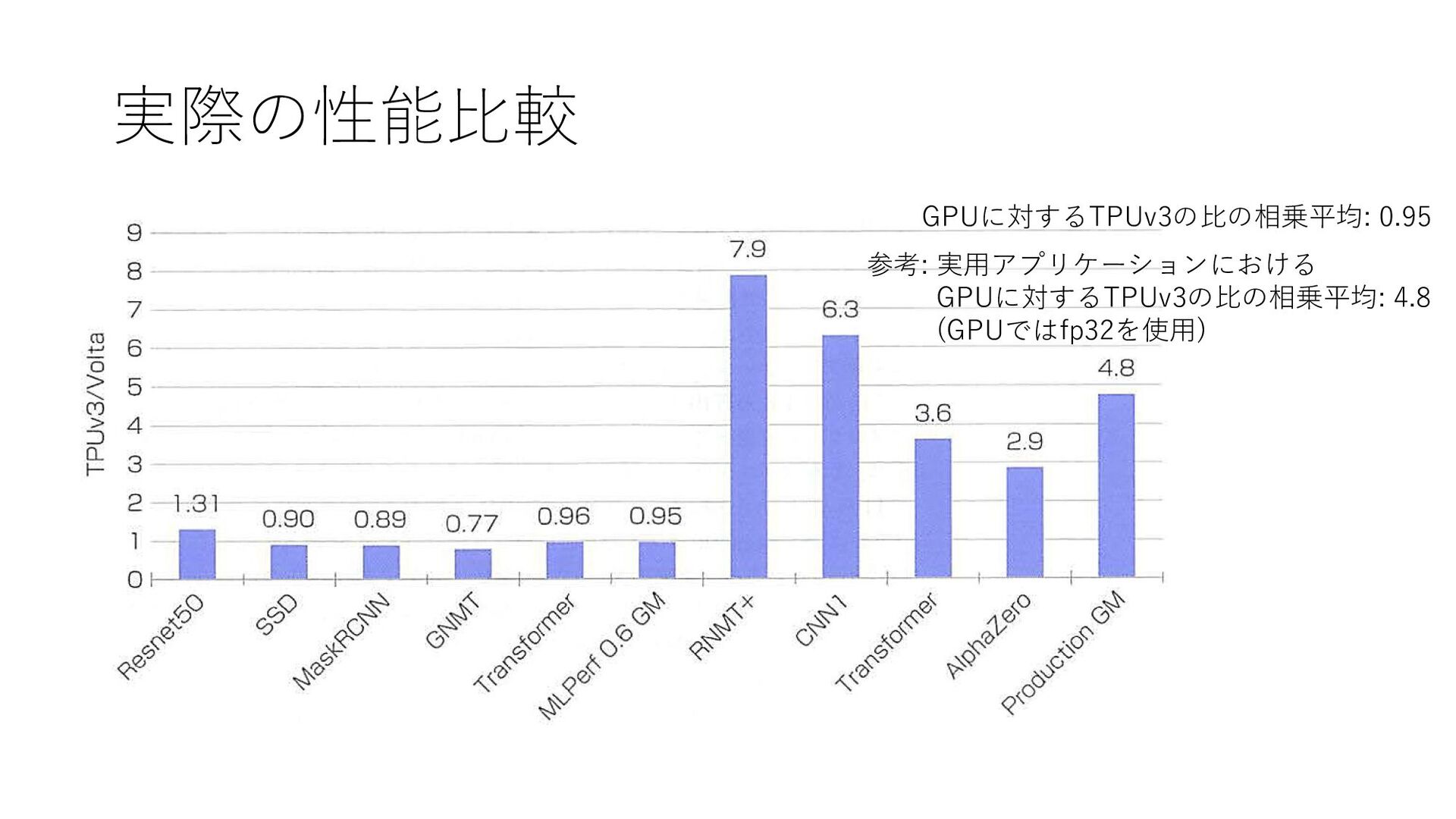
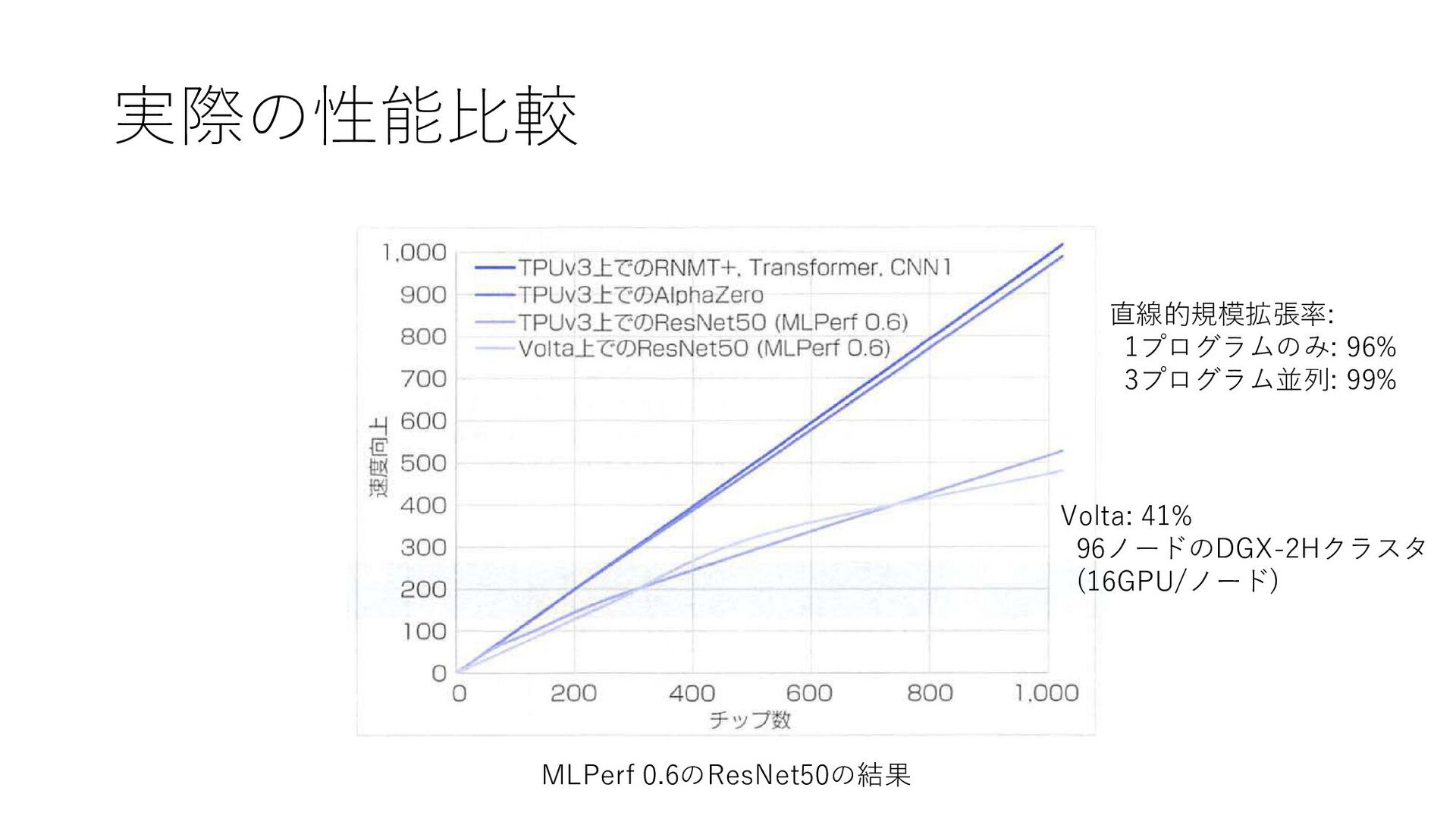
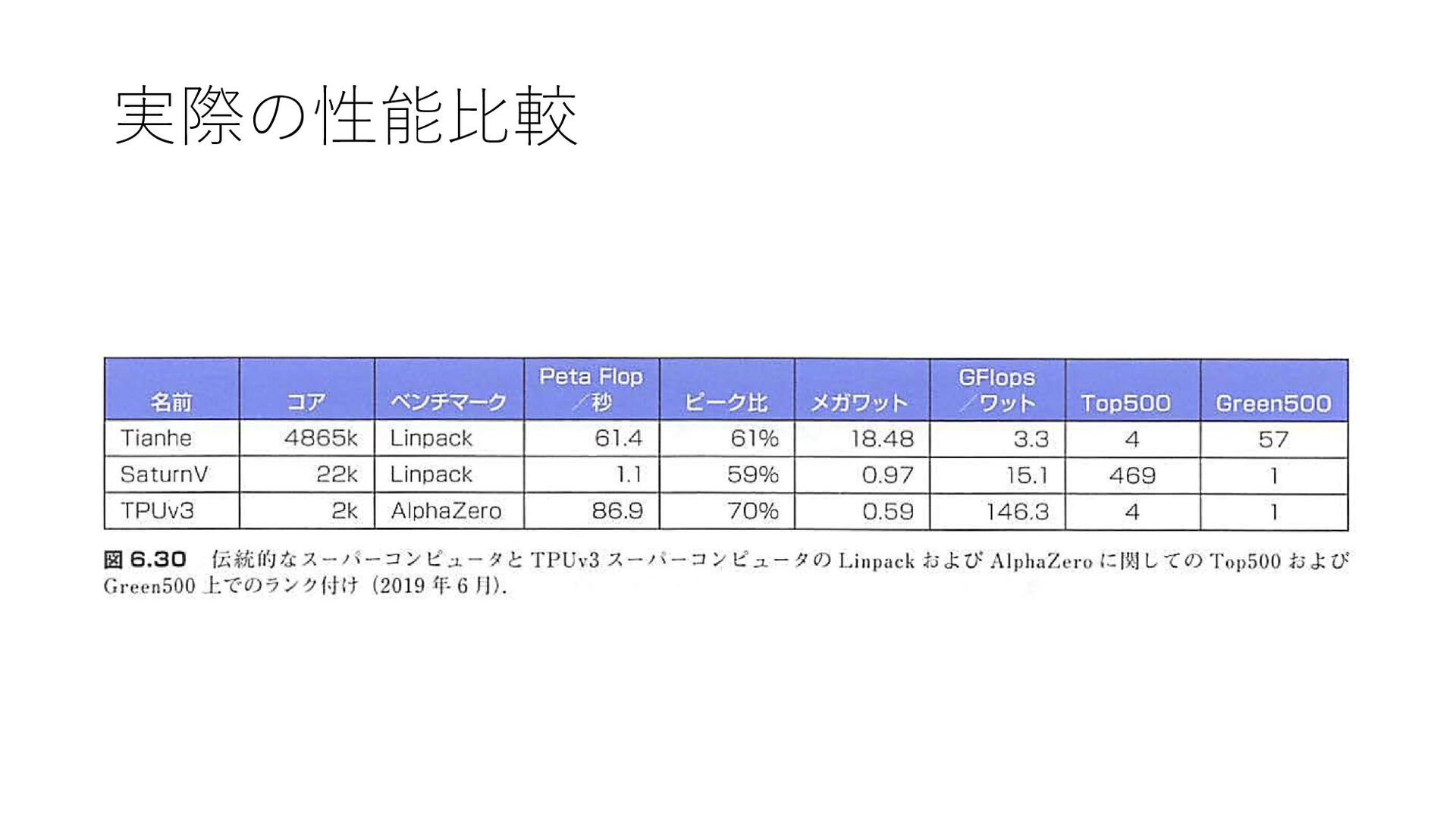
実際の性能比較 GPUに対するTPUv3の比の相乗平均: 0.95 参考: 実用アプリケーションにおける GPUに対するTPUv3の比の相乗平均: 4.8 (GPUではfp32を使用)
実際の性能比較 MLPerf 0.6のResNet50の結果 直線的規模拡張率: 1プログラムのみ: 96% 3プログラム並列: 99% Volta: 41%
96ノードのDGX-2Hクラスタ (16GPU/ノード)
実際の性能比較
6.13 高速化: 複数のプ ロセッサを 応用した行列の乗算
ex. DGEMMの高速化 OpenMPによってforループを 複数スレッドで並列処理させる (プラグマで指定した 一番外側のループを並列化) OpenMPの プラグマ・ディレクティブ
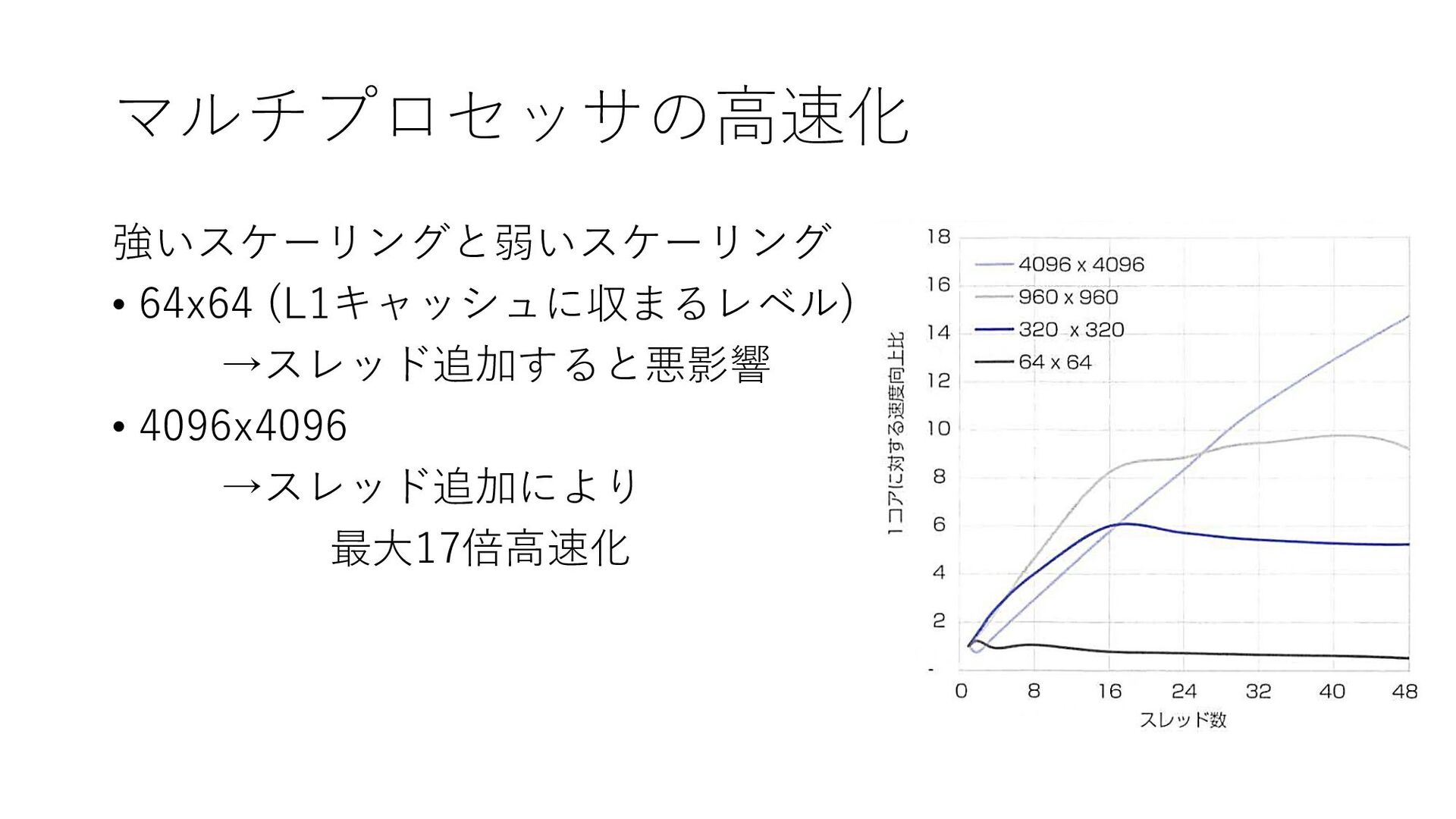
マルチプロセッサの高速化 強いスケーリングと弱いスケーリング • 64x64 (L1キャッシュに収まるレベル) →スレッド追加すると悪影響 • 4096x4096 →スレッド追加により 最大17倍高速化
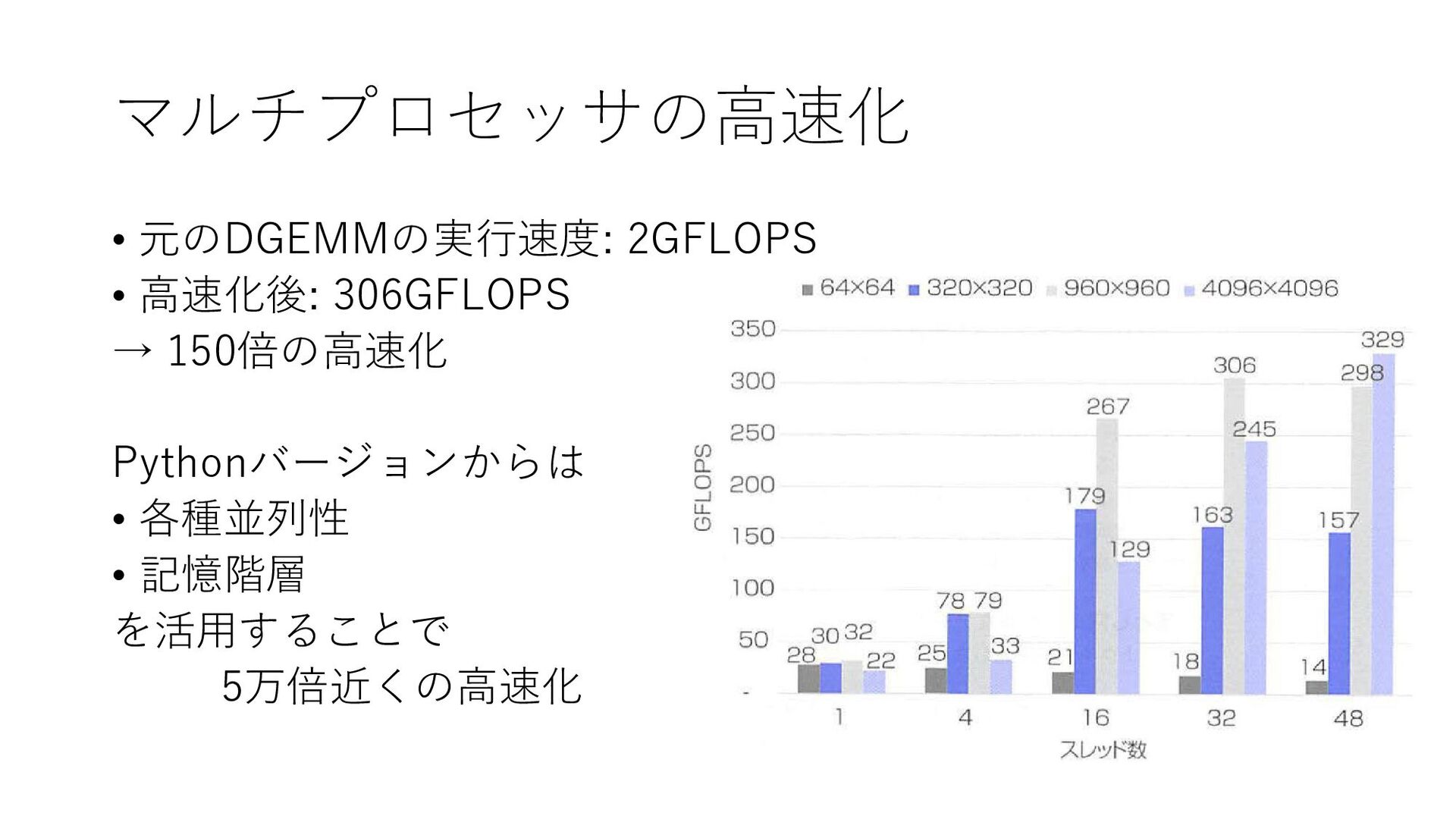
マルチプロセッサの高速化 • 元のDGEMMの実行速度: 2GFLOPS • 高速化後: 306GFLOPS → 150倍の高速化 Pythonバージョンからは
• 各種並列性 • 記憶階層 を活用することで 5万倍近くの高速化
6.14 誤信と落とし穴
1. Amdahlの法則は 並列コンピュータにも適用できる “この時点で,全く明確に以下の結論を出せる.それは,並列処理によっ て得られる性能改善とほぼ同程度の性能改善を逐次処理の部分でも達成 しないと,並列処理のために費やされた労力は無駄になる,ということ である.” (Amdahl, 1967) →「どんなプログラムにも逐次処理の部分が残り,プロセッサ数を増や
しても線形の速度向上にならない限界がある 」 ↑弱いスケーリングだと…
1. Amdahlの法則は 並列コンピュータにも適用できる ex. 同一時間で1000倍の仕事量をこなせるようスケーリング → 逐次処理部分は入力の規模関係なく一定,残りはすべて並列的 → 1000個のプロセッサでも線形の速度向上が実現 →「Amdahlの法則が破られた」
違う,そうじゃない... 強いスケーリングで考えるべき (同一データ・セットに対して1000倍の高速化) ユーザの関心が弱いスケーリングにある場合ももちろんあるので 注意が必要
2. ピーク性能は 現実の性能を反映したものではない • 古今東西やらかしている業界・企業は多々ある • ユニプロセッサであっても理論通りのピーク性能には到達不能 • マルチプロセッサなシステムでは… •
1プロセッサのピーク性能×プロセッサ数では遥かに現実離れした値に • ピーク性能の総合的な解釈にはルーフライン・モデルが有用
3. 斬新なアーキテクチャを十分に活用した, あるいはそれに最適化した ソフトウエアを開発すべきである 斬新なハードウエア ≠ 高速なハードウエア • 高速に動作させるにはソフトウエアによる最適化が必要 •
ex. マルチプロセッサ環境でのOSのアルゴリズム・データ構造 • マルチプロセッサでは複数のプロセスがページ割当 • ページ・テーブルが単一のロックで保護されていると... → 別のプロセスがロック解除するまで使えない → 並列ハードウエアなのに直列化
3. 斬新なアーキテクチャを十分に活用した, あるいはそれに最適化した ソフトウエアを開発すべきである • 最近のDNN分野におけるDSAに関しても見られる • いいハードウエアを開発しても... • ソフトウエアの開発がうまくいかずMLPerfのベンチが伸びない
→ 流行らず廃業... ハードウエア・ソフトウエア両面での最適化・高速化が大事
4. 優れたベクトル性能を得るために メモリのバンド幅は増やすべきである • ルーフライン・モデルをよく思い出してください • DAXPY (Y = 𝑎
× 𝑋 + 𝑌, Double-precision A×X Plus Y) • 浮動小数点演算毎に1.5回のメモリ参照が必要 → メモリによる制約 • ex. Cray-1におけるLinpackベンチマーク • 元々メモリのバンド幅が不足 →値をベクトル・レジスタ中に保持できるよう計算を変更 → FLOPSあたりのメモリ参照回数の低減 → 2倍近くの性能向上 ルーフライン・モデルにより予測できる
5. 命令セット・アーキテクチャ (ISA) は 物理的な実装上の特性を 必ずしも隠ぺいしない CPUのタイミング・チャネルには (実装上の特性として) 脆弱性 があることが知られていた
→ ISAで隠蔽されるから大丈夫! → 大丈夫じゃなかった… (Spectre,Meltdown)
5. 命令セット・アーキテクチャ (ISA) は 物理的な実装上の特性を 必ずしも隠ぺいしない Spectreの攻撃手順 1. 不正な命令をあえて投機的に実行 •
予測は外れ,処理は元に戻されるがキャッシュは復元されない • 後の工程のための手がかりをキャッシュ上に残す 2. 先の手順でキャッシュ上に残した手がかりを追跡し,本来ア クセスできないはずのデータへアクセスする 3. 近傍で実行される攻撃対象のプログラムの命令に紛れ込む • ハードウエア・マルチスレッディングではあるプログラムの命令が他 のプログラムの命令と混ざることは普通にあり得る
6.15 おわりに
おわりに • マルチプロセッサによる並列コンピューティングのアイディア は昔からあった • 大幅な速度向上をする並列プログラムを作ることは難しい (Amdahlの 法則による限界) • 現在のトレンドも並列コンピューティング
• 昔とは状況が違う • (SaaS向けクラスタ,ウエアハウス・スケール・コンピューティング,マルチメ ディア・アプリケーション,機械学習等) • どのベンダも作っているのはマルチプロセッサ • マルチプロセッサがかつてのユニプロセッサと同じ扱いに (非線形の性能向上で 許される) • オープンソース運動の興隆
おわりに 3章~6章にかけてDGEMMを高速化 • 3章: データ・レベル並列性 • 512bit AVX命令のオペランドを利用 (SIMD) •
64bitの浮動小数点演算を8つ並列に実行 → 7.8倍高速化 • 4章: 命令レベル並列性 • ループを4回展開し,アウトオブオーダー実行ハードウエアにスケ ジュールすべき命令を多く供給 → 1.8倍高速化
おわりに 3章~6章にかけてDGEMMを高速化 • 5章: キャッシュ最適化 • キャッシュ・ブロッキングを利用してキャッシュ・ミスを低減 →L1キャッシュに行列が収まらない場合の性能を1.5倍高速化 • 6章:
スレッド・レベル並列性 • OpenMPによりマルチコア・チップのすべてのコアを利用 (MIMD) → 12~17倍高速化 最終的な性能向上は150倍以上
おわりに 今後は汎用コアの性能向上が年数%しかないような時代になる → 並列処理の活用,DSAの開発が重要になってくる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}