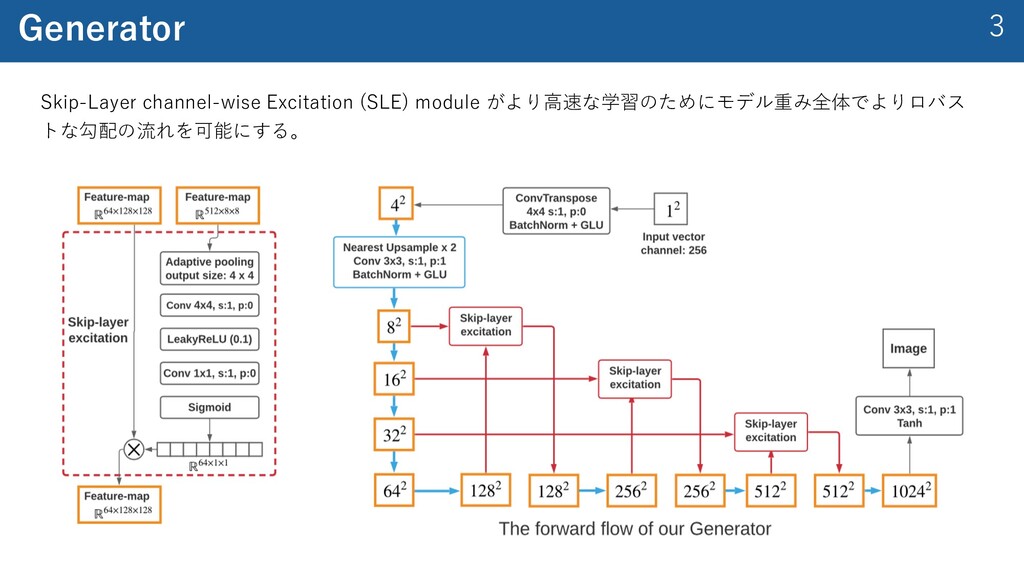
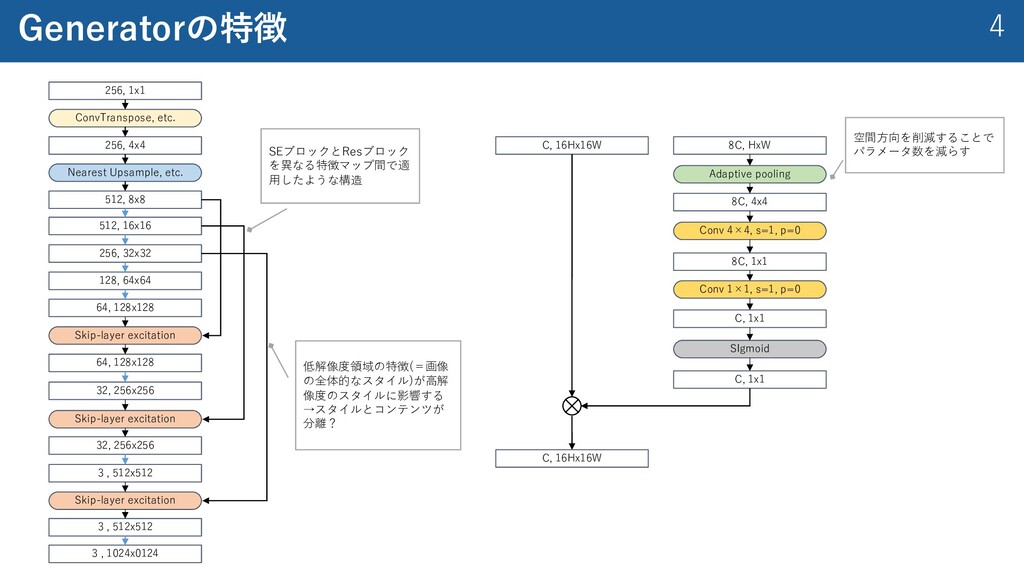
etc. 512, 8x8 512, 16x16 256, 32x32 128, 64x64 64, 128x128 32, 256x256 3 , 512x512 3 , 1024x0124 Skip-layer excitation Skip-layer excitation 64, 128x128 32, 256x256 Skip-layer excitation 3 , 512x512 8C, HxW C, 16Hx16W Adaptive pooling 8C, 4x4 Conv 4×4, s=1, p=0 8C, 1x1 C, 1x1 Conv 1×1, s=1, p=0 SIgmoid C, 1x1 C, 16Hx16W 空間⽅向を削減することで パラメータ数を減らす SEブロックとResブロック を異なる特徴マップ間で適 ⽤したような構造 低解像度領域の特徴(=画像 の全体的なスタイル)が⾼解 像度のスタイルに影響する →スタイルとコンテンツが 分離?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}