[HiPINEB 2016] Exploring Low-latency Interconnect for Scaling-Out Software Routers
About building an optimized interconnection scheme for multi-node software routers using RDMA-capable Ethernet NICs and our own hardware-assisted batching technique
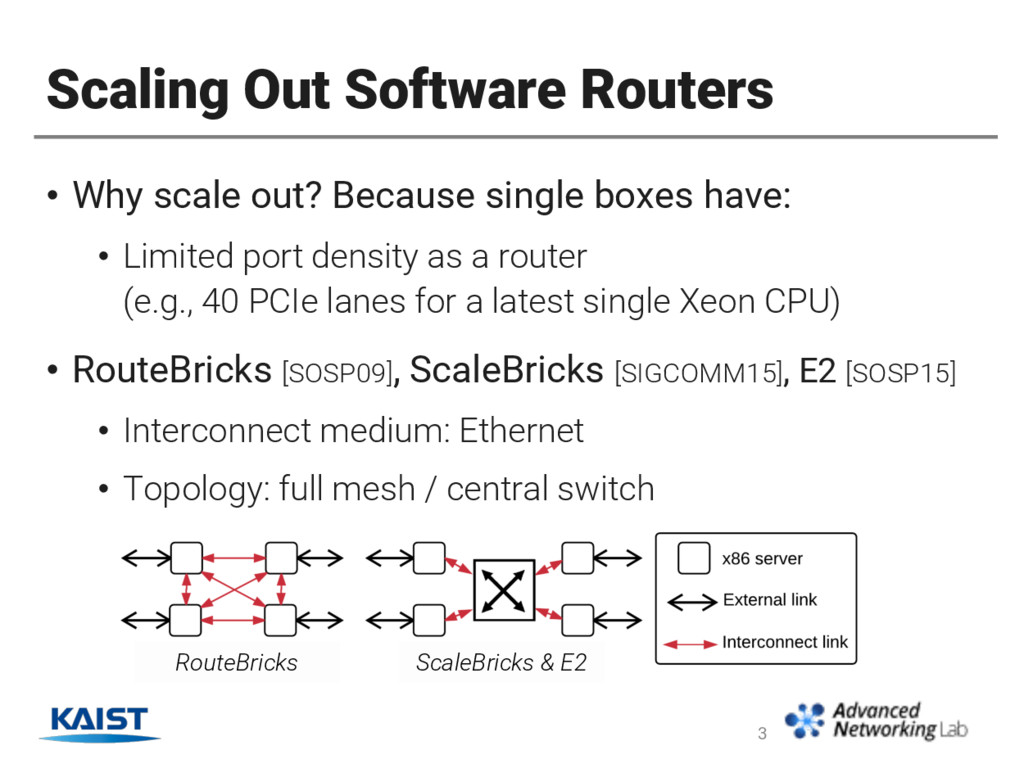
boxes have: • Limited port density as a router (e.g., 40 PCIe lanes for a latest single Xeon CPU) • RouteBricks [SOSP09], ScaleBricks [SIGCOMM15], E2 [SOSP15] • Interconnect medium: Ethernet • Topology: full mesh / central switch 3 RouteBricks ScaleBricks & E2
for routers. • All external connections need to be compatible: Ethernet. • Scaling out opens a new design space: interconnect. • RDMA provides low latency and high throughput. • It reduces the burden of host CPUs, by offloading most functionalities of network stacks to hardware. 6
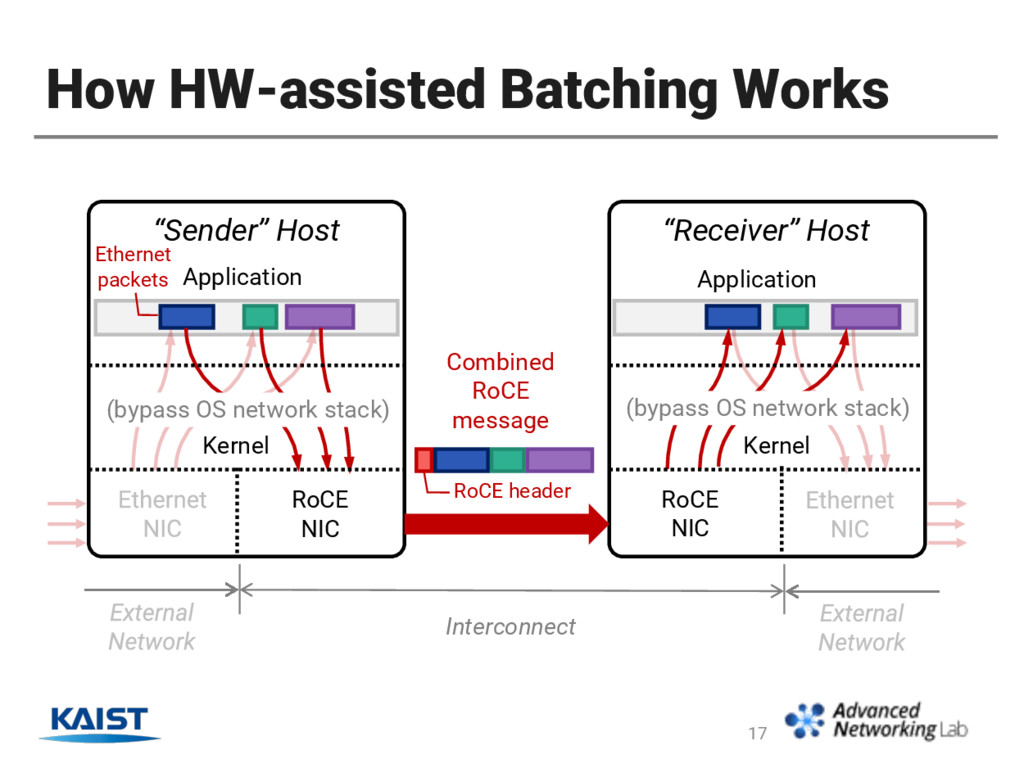
Ethernet: for jumbo-frames that don’t fit with page size • In RDMA: for fast access to remote pages • Batching reduces per-packet overheads. • It saves bandwidth for repeated protocol headers and computations for parsing/generating them. • Doing it in HW leaves more CPU cycles for SW. 7
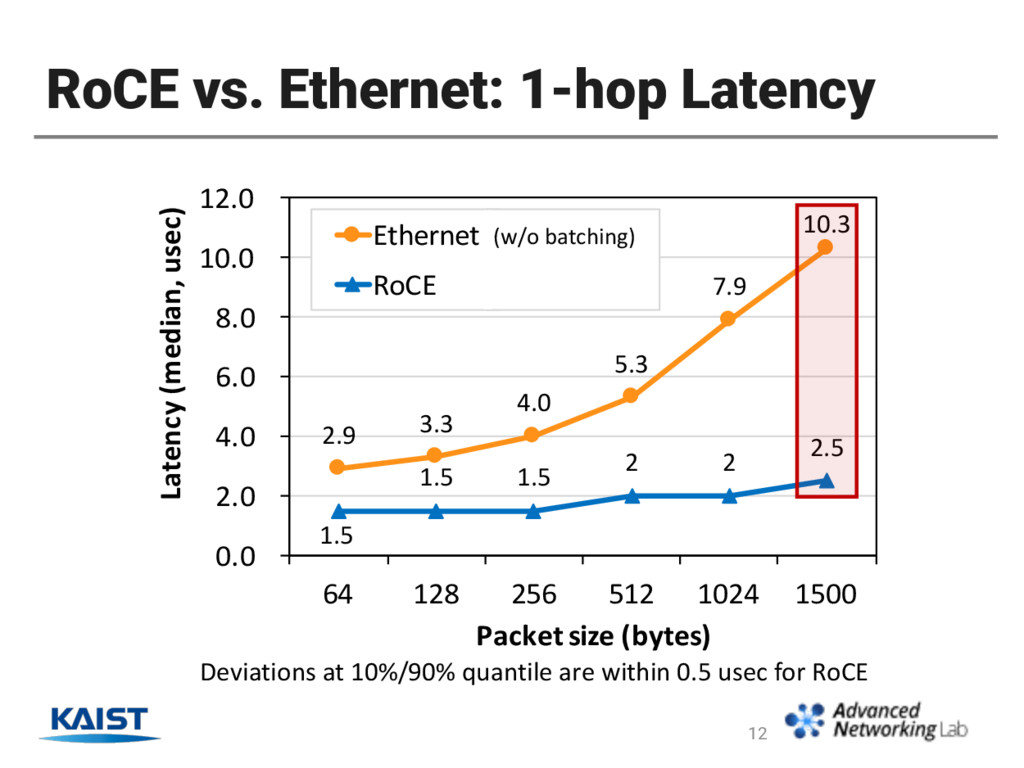
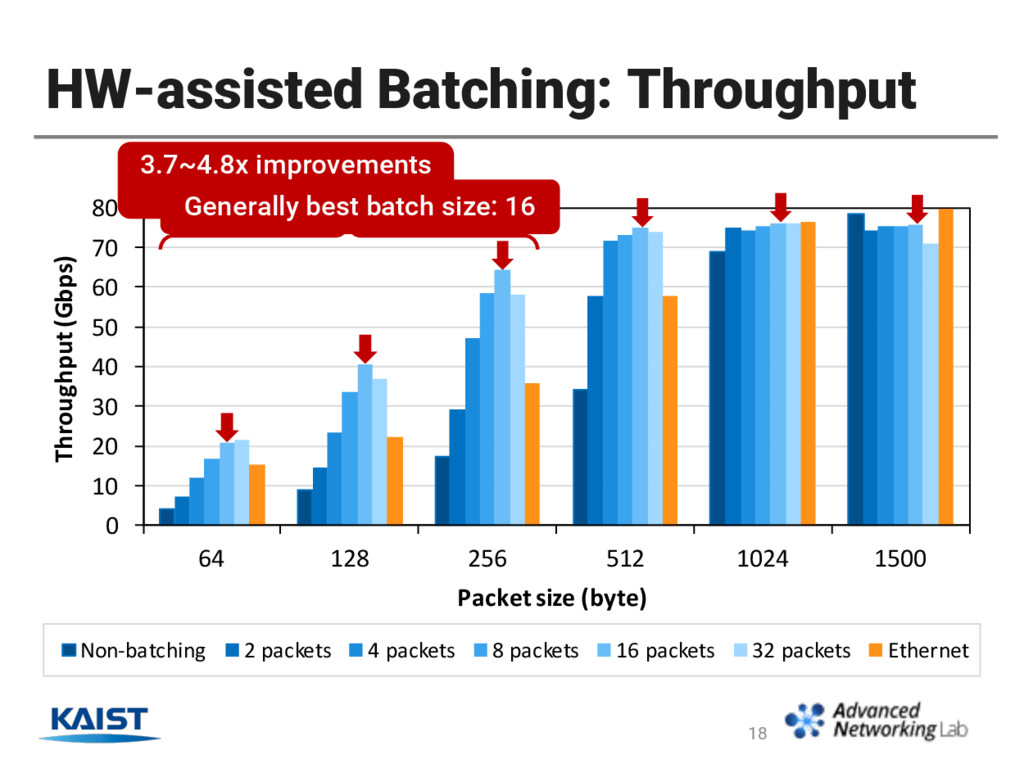
Combinations of different RoCE transport/operation modes • RoCE (RDMA over Converged Ethernet) vs. Ethernet • Result Highlights • In RoCE, UC transport type and SEND/RECV ops offer the maximum performance. • RoCE latency is consistently lower than Ethernet. • RoCE throughput is lower than Ethernet in small packets. • HW-assisted batching improves RoCE throughput for small packets to be comparable to Ethernet. 8
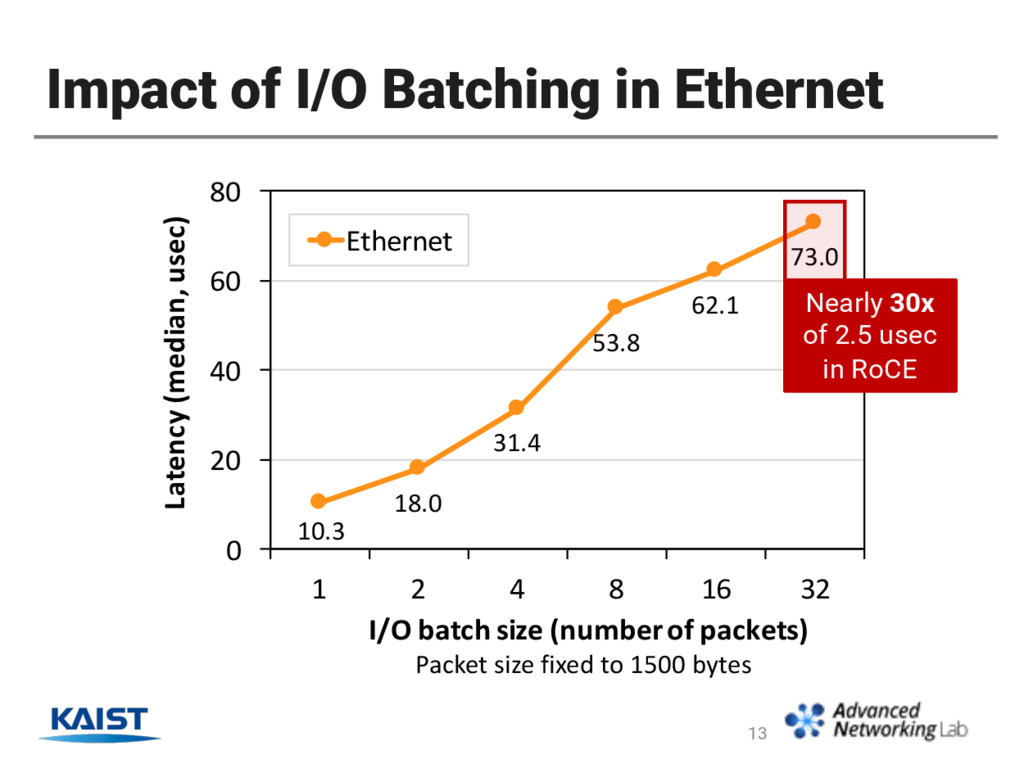
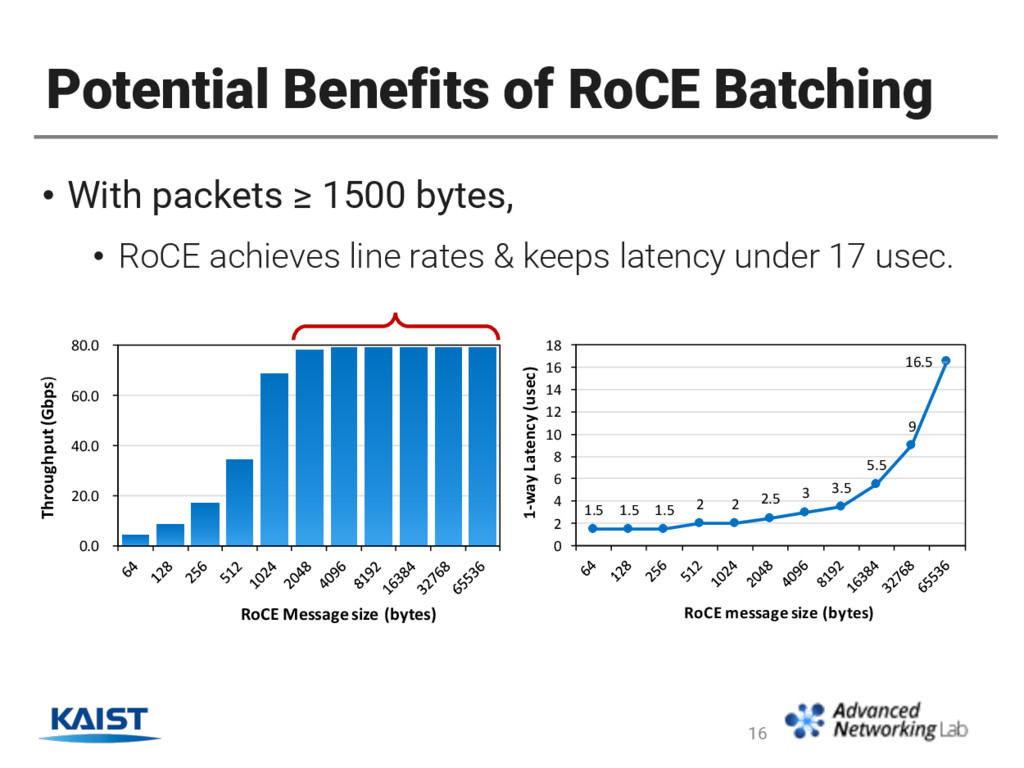
under 3 usec in all packet sizes. • Up to 30x lower than Ethernet in the same conditions • RDMA throughput < Ethernet throughput when packet size ≤ 1500B. 15 Our Breakthrough: Exploit HW-assisted Batching! + -
RoCE NIC Application Combined RoCE message RoCE header Ethernet packets RoCE NIC Interconnect (bypass OS network stack) (bypass OS network stack) Kernel Kernel
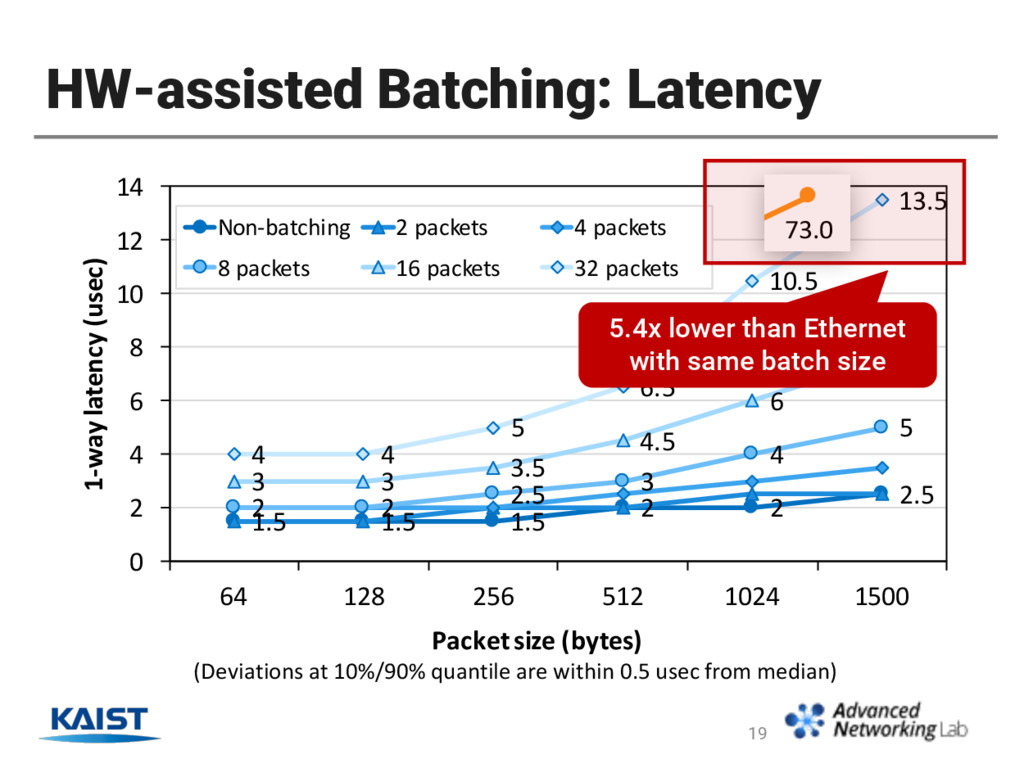
an interconnect of scaled-out SW routers. • It reduces I/O latency up to 30x compared to Ethernet • Challenge is its low throughput in packet sizes ≤ 1500 bytes. • We exploit HW-assisted batching to enhance throughput. • It batches multiple Ethernet packets in a single RoCE message. • Our scheme achieves throughput higher or close to Ethernet while still keeps 1-hop latency under 14 usec. 20
transfer operation • READ, WRITE, SEND and RECV operations • We use SEND & RECV, which is more suitable to latency- critical applications like packet processing. • 3 transport types for RDMA connection • RC (Reliable Connection), UC (Unreliable Connection), UD (Unreliable Datagram) • We choose UC type, which shows highest throughput of all types. 22
operations • One-sided operations: receive side’s CPU is unaware of the transfer • READ “pulls” data from remote memory and WRITE “pushes” data into remote memory. • SEND & RECV operations • Two-sided operations: CPU of both side is involved • Sender sends data using SEND, receiver uses RECV to receive data • We use SEND & RECV, which is more suitable to latency- critical applications like packet processing. 23
RDMA connection • RC (Reliable Connection), UC (Unreliable Connection), UD (Unreliable Datagram) • Connected types (RC & UC) support message sizes up to 2GB but requires fixed sender-receiver connection. • ACK/NACK protocol of RC enables it to guarantee lossless transfer but consumes link bandwidth. • UD type does not require fixed connection but its message size is limited to MTU and requires additional 40-byte protocol overhead. • UC type shows highest throughput of all types and we use it in this work. 24
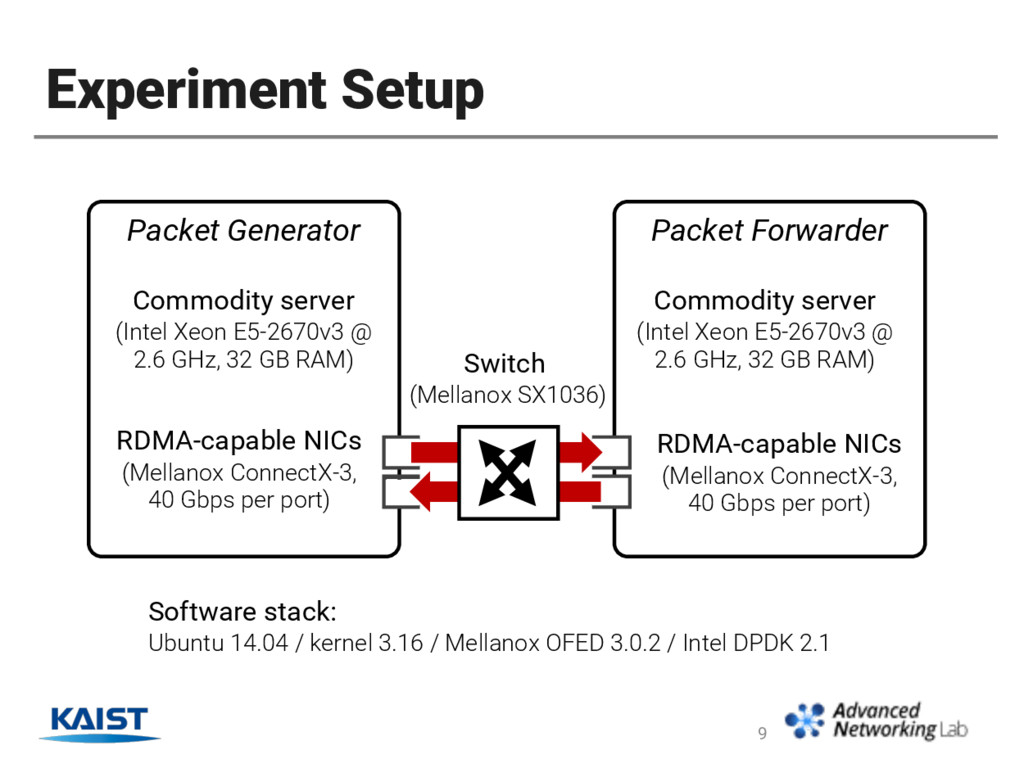
RDMA connections on performance • Measure throughput and latency using real traffic traces • Implement scaled-out SW router prototype using RDMA interconnect • Cluster composed of Ethernet ports for external interface and RoCE ports for interconnect 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}