Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SKL 2019 Intern Training Data Cleaning and Feat...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Adam
March 18, 2019
Programming
35
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SKL 2019 Intern Training Data Cleaning and Feature Engineering
Data cleaning and feature engineering methods for intern.
Adam
March 18, 2019
More Decks by Adam
See All by Adam
Working Backward Reading Group
adamchang
0
110
Python Data Visualization - PyData Taipei Meetup
adamchang
0
250
SKL data analysis internship lecture 1
adamchang
0
150
SKL 2019 Intern Training Python Data Analysis
adamchang
0
55
Other Decks in Programming
See All in Programming
What's New in Android 2026
veronikapj
0
200
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
Lean は証明の正しさを確認するためだけのツールって思ってませんか?
inoueasei
1
110
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1k
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
540
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
140
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
430
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
340
えっ!!コードを読まずに開発を!?
hananouchi
0
240
Featured
See All Featured
Odyssey Design
rkendrick25
PRO
2
730
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Fireside Chat
paigeccino
42
4k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
A Tale of Four Properties
chriscoyier
163
24k
Rails Girls Zürich Keynote
gr2m
96
14k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Transcript
Data Cleaning And Feature Engineering 打開資料分析中潘朵拉的寶盒
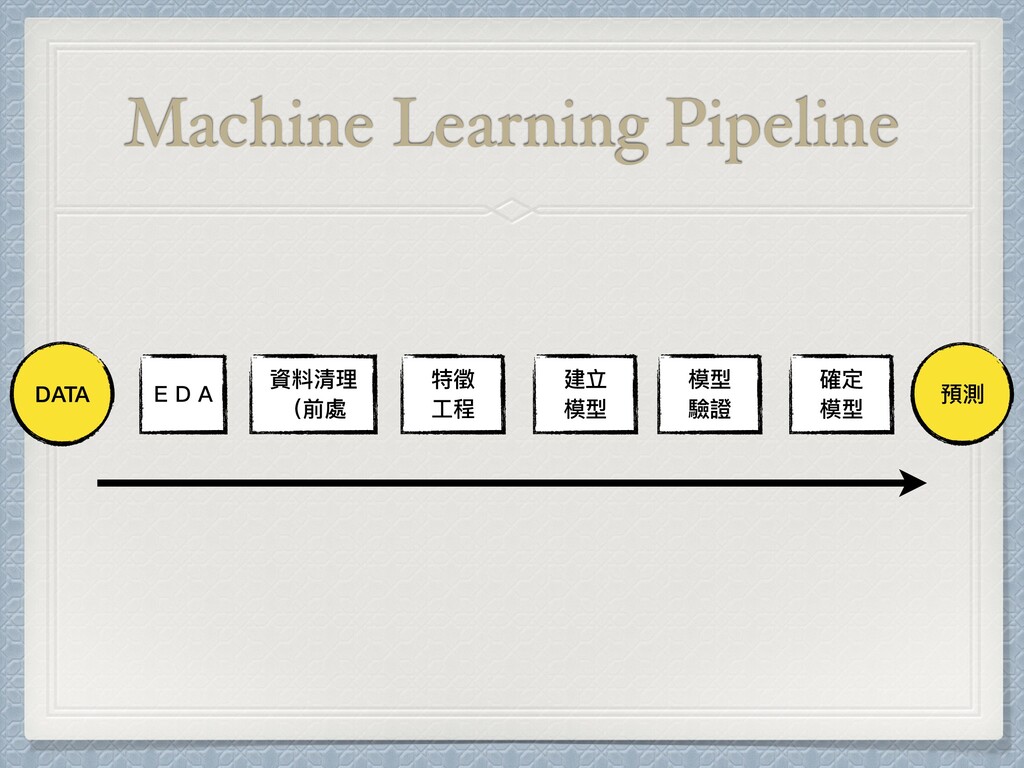
Machine Learning Pipeline DATA 資料清理 (前處 特徵 ⼯程 建立 模型
模型 驗證 確定 模型 預測 EDA
Agenda 1. Data Cleaning 2. Feature Engineering 3. Advance Data
Analysis Using Pandas! 4. Homework
介紹今天推薦的教材
– 缺失的資料無法提供資訊 – 案發現場的還原 「為什麼要做資料清理︖」
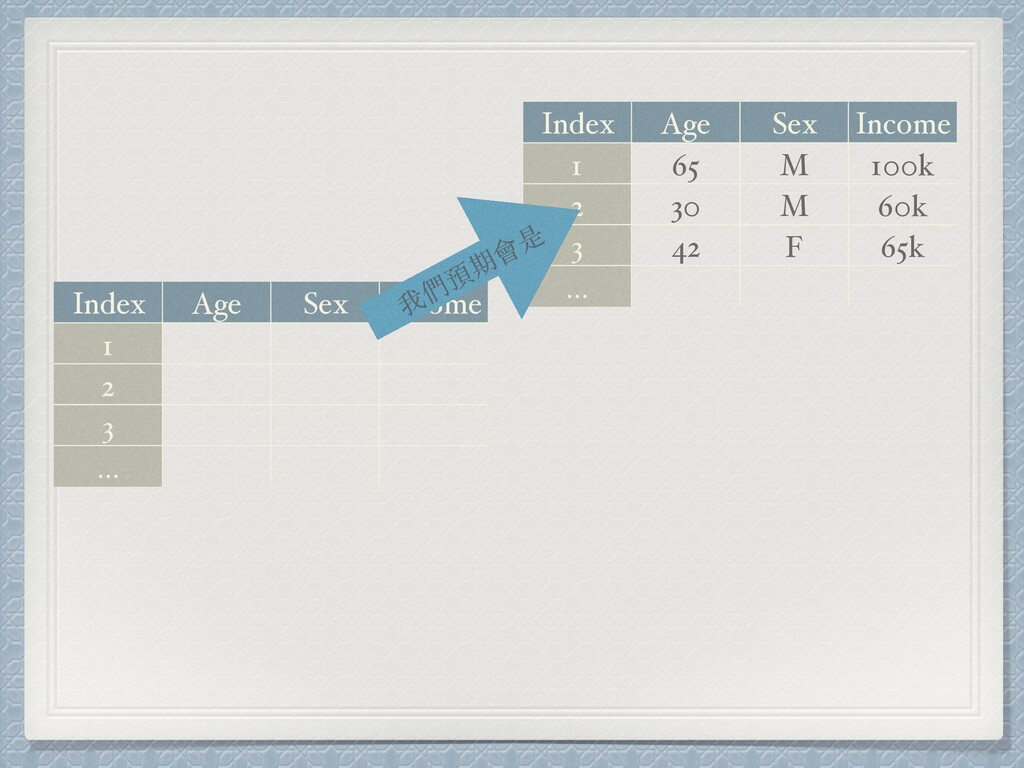
Index Age Sex Income 1 2 3 …
Index Age Sex Income 1 2 3 … Index Age
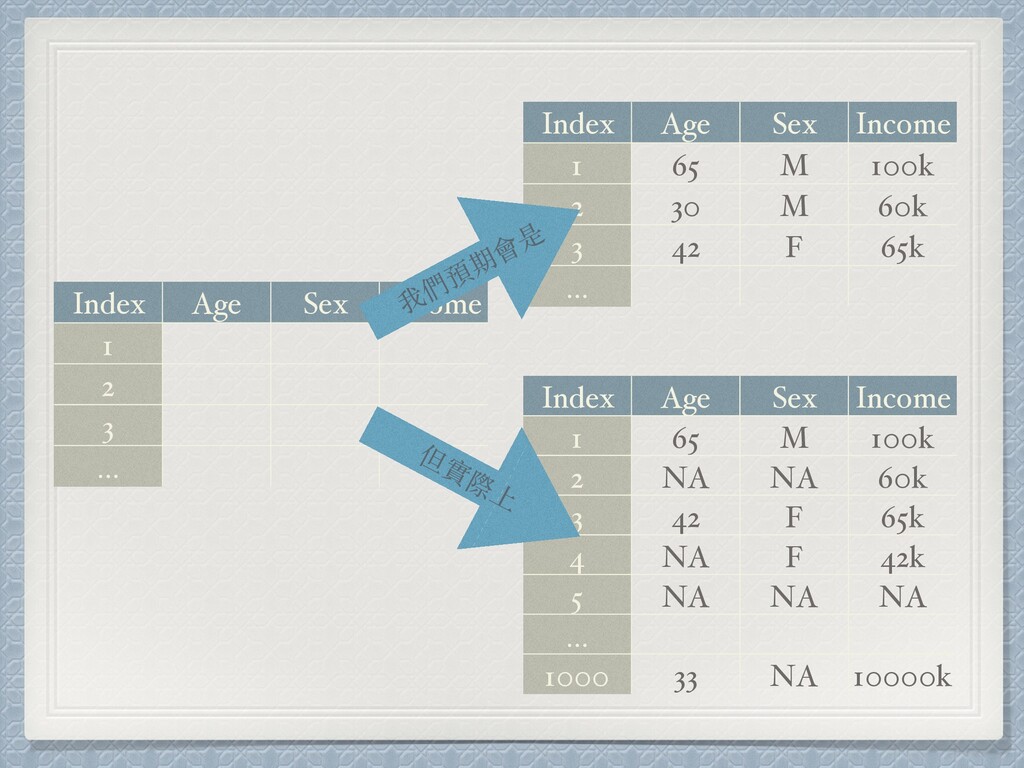
Sex Income 1 65 M 100k 2 30 M 60k 3 42 F 65k … 我們預期會是
Index Age Sex Income 1 2 3 … Index Age
Sex Income 1 65 M 100k 2 30 M 60k 3 42 F 65k … 我們預期會是 Index Age Sex Income 1 65 M 100k 2 NA NA 60k 3 42 F 65k 4 NA F 42k 5 NA NA NA … 1000 33 NA 10000k 但實際上
為什麼會發⽣資料缺失 訪談對象躲起來不讓你找到 填問卷填到睡著 他不想把他的資料跟你講 他虛報或亂掰資料 字跡潦草看不懂 寫問卷的時候不⼩⼼打翻咖啡
「我們不對資料進⾏修正, 我們只會學習處理這些資料」
處理缺失資料的⽅法 A. 想盡辦法避免他發⽣(但總是有莫非定律) B. 忽略他不看 C. 想法⼦處理他
Unit Nonresponse vs Item Nonresponse 1. Unit Nonresponse: 整筆資訊沒有辦法蒐集到 2.
Item Nonresponse: 部分資訊因為某些原因,⽽沒有 蒐集到
Unit Nonresponse vs Item Nonresponse Index Age Sex Income 1
65 M 100k 2 NA NA 60k 3 42 F 65k 4 NA F 42k 5 NA NA NA … 1000 33 NA 10000k
我們如何處理缺失資料 A. Drop Missing V alue B. Deductive Imputation C.
Mean/ Median/ Mode Imputation D. Regression Imputation E. Stochastic Regression Imputation F. Proper Imputation G. Hot-Deck Imputation
Drop Missing Value 直接不看這筆資料啦!!!!!!!!!!!!! Pros ⽤起來超快超爽der Cons 資料會變少...
Deductive Imputation ⽤合理的⽅式去填補資料 推測那筆空值可能是甚麼 比⽅說我們調查⼈壽公司的資料,對象可能都以女性為 主,性別有空值時都補上Female Pros 可以⽤直覺且合理的⽅式把值塞進去 Cons 要對他特別寫⼀⽀code來補︔耗時
Mean/ Median/ Mode Imputation 補平均值、中位數、眾數 Pros 好⽤、快、程式也好寫 Cons 但整體的資料分布可能會失真, 也會影響其他統計數據
Regression Imputation 把其他的欄位當特徵,建⽴模型去預測該筆空值的資料 Pros 比上⼀個⽅法更加「合理」的補值 Cons 資料分布⼀樣可能會失真 還得先建⼀個模型
Stochastic Regression Imputation ⼀樣⽤模型去預測缺失值,但再加入隨機的亂數 Pros 再比上⼀個⽅法更加「合理」,對整體的分佈 影響也較⼩些 Cons 對於變異數的估計容易失真 也是要另外建⼀個模型
Hot-Deck Imputation 從現有的資料選項中,隨機抽⼀種取代缺失值 Pros 使⽤真實資料進⾏取代,真實性較⾼ Cons 但有可能改變特徵之間的關係
Type Of Missingness A. Not missing at random: 受測者主觀的不願意提供某些資料 B.
Missing at random: 可能少數欄位字跡潦草看不懂在寫什麼 C. Missing completely at random: 咖啡倒在問卷上了啊啊啊啊啊啊
Workflow In Missing Data 1. 透過EDA,看看每個欄位缺失值的數量,評估 看看是否需要花時間去處理它 2. 想想對每個特徵來說,可能缺失的原因是什麼︖ 這個特徵會對我有參考價值嗎︖
3. 依據可以投入的精⼒與時間,思考⼀下處理缺失 值的⽅式
– 找到更好的⽅式(指標)去描述我們的對象 那又為什麼要做特徵⼯程呢︖
那麼你會怎麼描述⼀個⼈︖
None
None
Pandas In Jupyter! https://github.com/PacktPublishing/Learning-Pandas-Second-Edition
Recap 1. Data Cleaning (Munging) 2. Feature Engineering 3. Advance
Pandas 1. Tidy Data 2. Data Aggregation 3. Combining, Relating, Reshaping Data
Homework - 資料探索⼤挑戰 Objective: 練習使⽤Python進⾏資料清理&特徵⼯程 1. 針對前⼀天Boston House Price Dataset,有空值的欄位進⾏資料清理
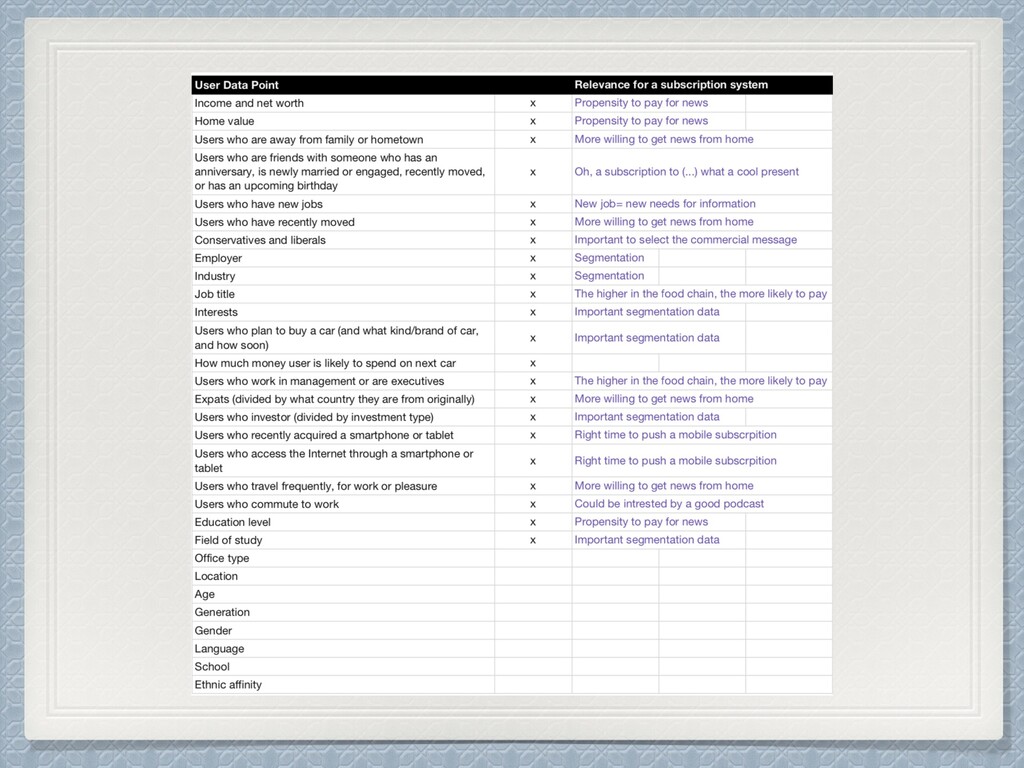
2. 清理後研究看看你的資料,試著⽤Python建⽴15個新的特徵 3. 將你的資料清理&特徵⼯程的策略寫在你昨天的表上,並寫下為什麼你會想 這樣做︖ 4. 將你清理完的資料及與Excel表紀錄好,今天的作業就完成了 :”> 特徵 資料清理⽅式 這樣清理的理由 特徵⼯程 建⽴這特徵的理由 ⽣活區域⾯積 補入Mean 以平均值評估⼀般⼈購 買的坪數 將坪數每5坪分⼀個 級距,ex: 25~30坪 推測⼀般⼈會以這樣的級 距來分類房⼦的⼤⼩
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}