1. Зачем сжимать информацию?
2. Сжатие с потерями и без потерь.
3. Алгоритм RLE.
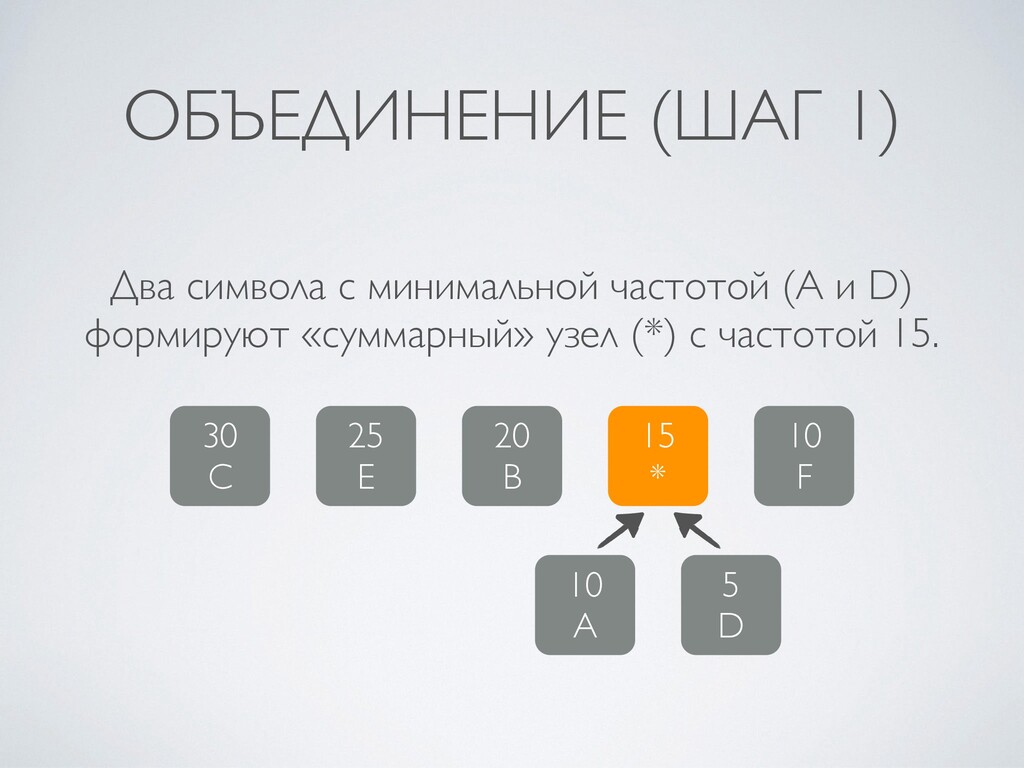
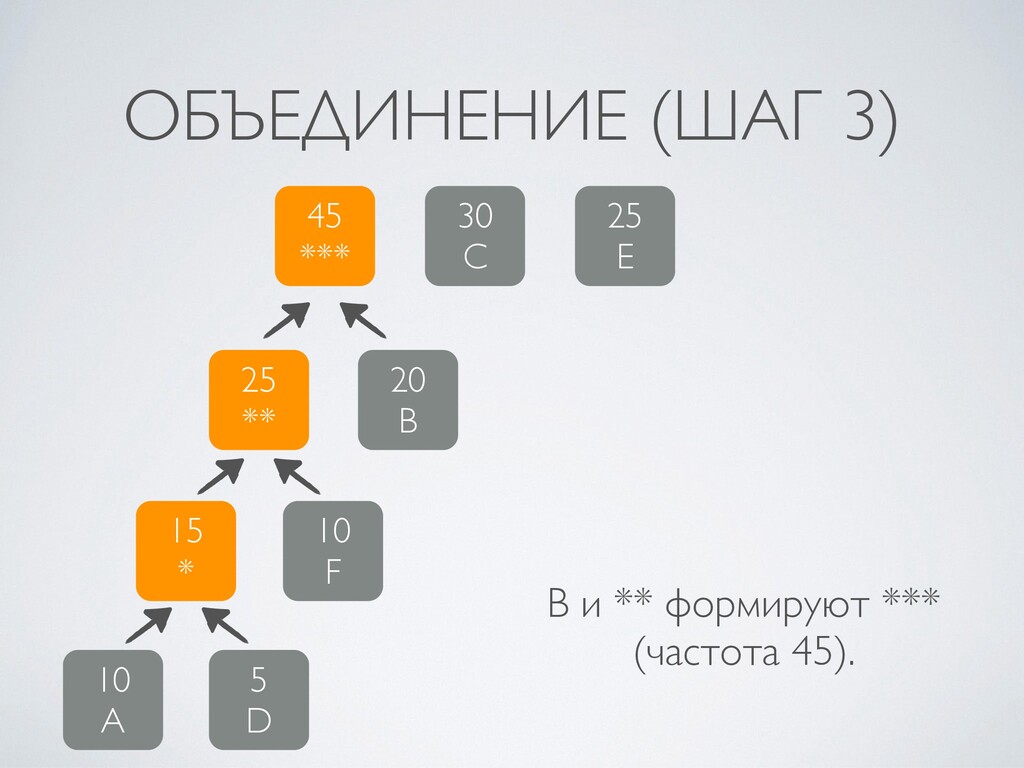
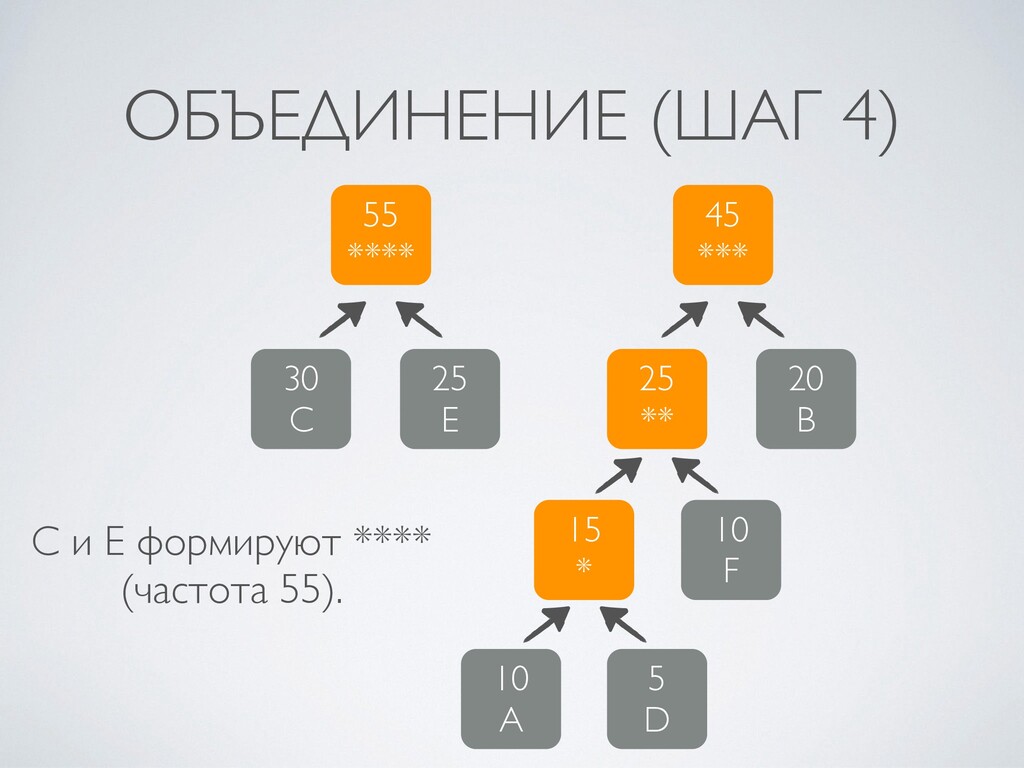
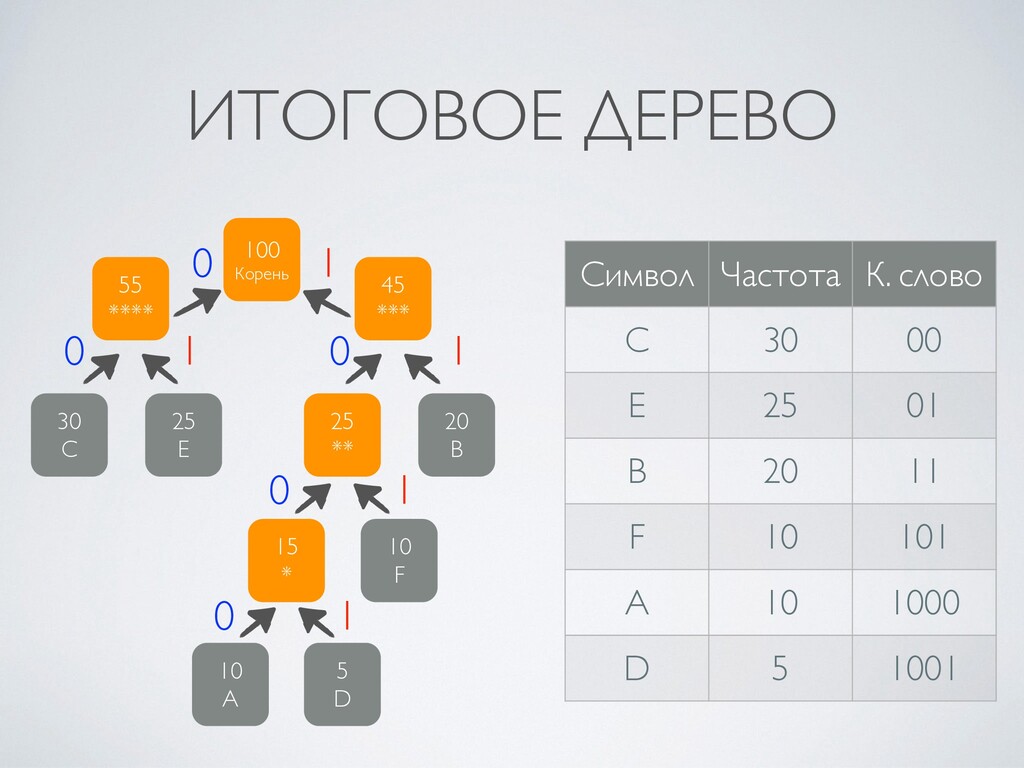
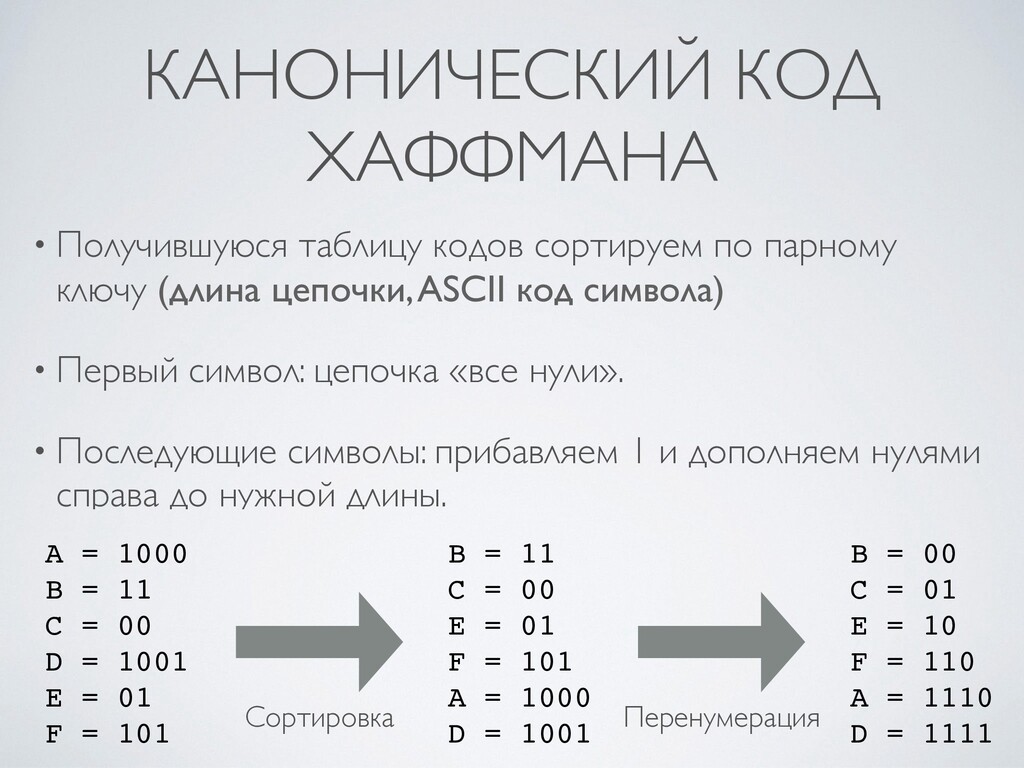
4. Алгоритм Хаффмана: построение кодового дерева, упаковка и распаковка.
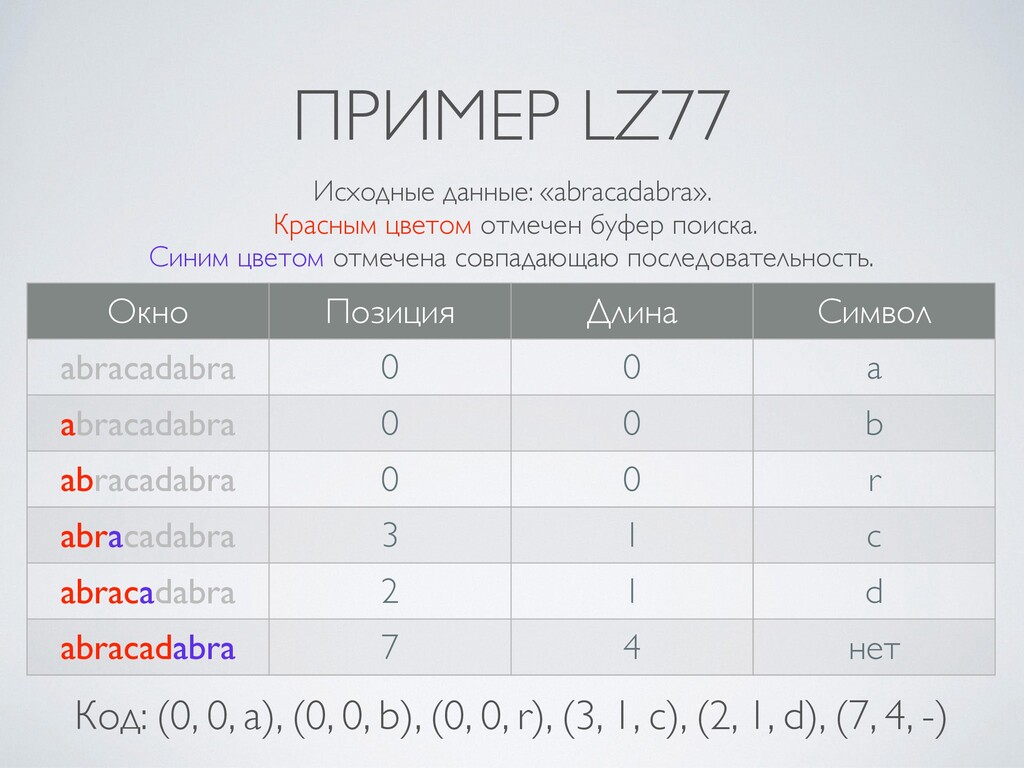
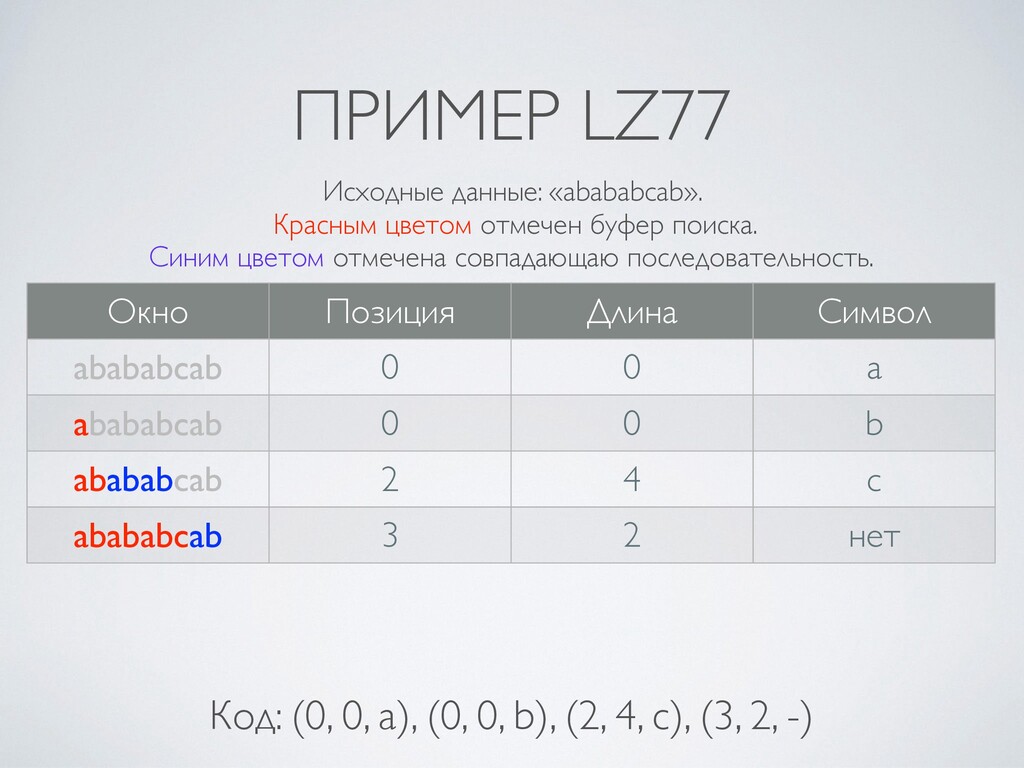
5. Алгоритм LZ77 (скользящее окно).
6. Алгоритм LZW.
7. Исключительный случай при распаковке LZW.
8. Сжатие с потерями и функциональный анализ.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LZW РАСПАКОВКА • Прочитать Код0 из файла и вывести Таблица[Код0]](https://files.speakerdeck.com/presentations/d5ff9ed6e77d413e837aee4611fed6eb/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}