In this session, Dipti will introduce the Presto technology and share why it’s becoming so popular – in fact, companies like Facebook, Uber, Twitter, Alibaba, and much more use Presto for interactive ad hoc queries, reporting & dashboarding data lake analytics, and much more. We’ll also show a quick demo on getting Presto running in AWS.
{kind=link}
{kind=link}
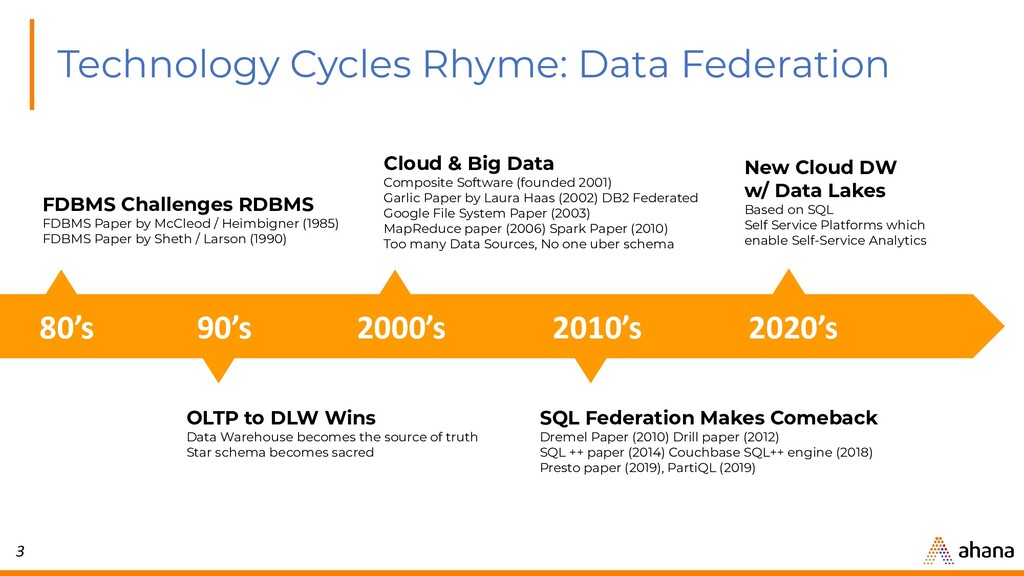{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
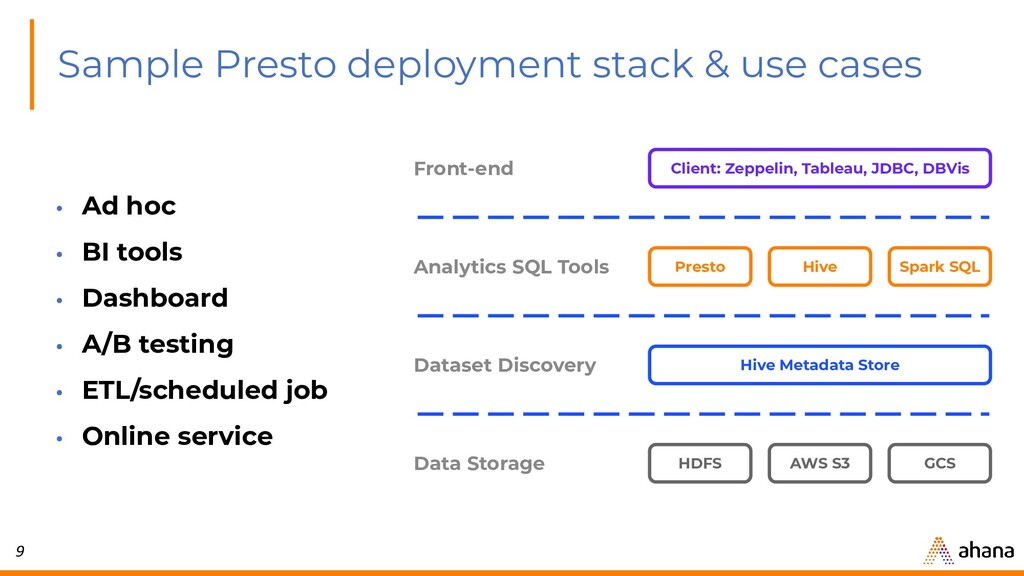{kind=link}
{kind=link}
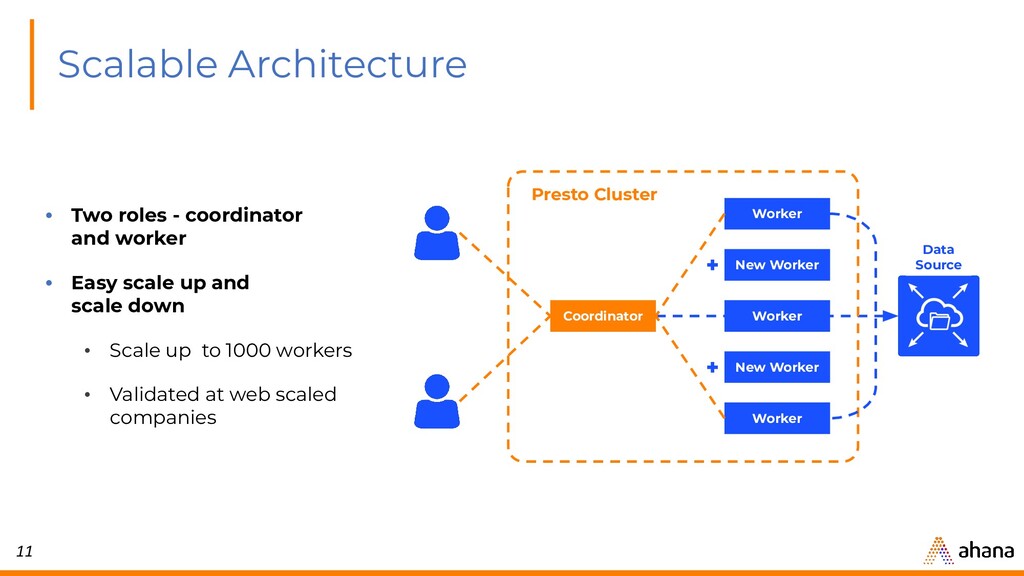{kind=link}
{kind=link}
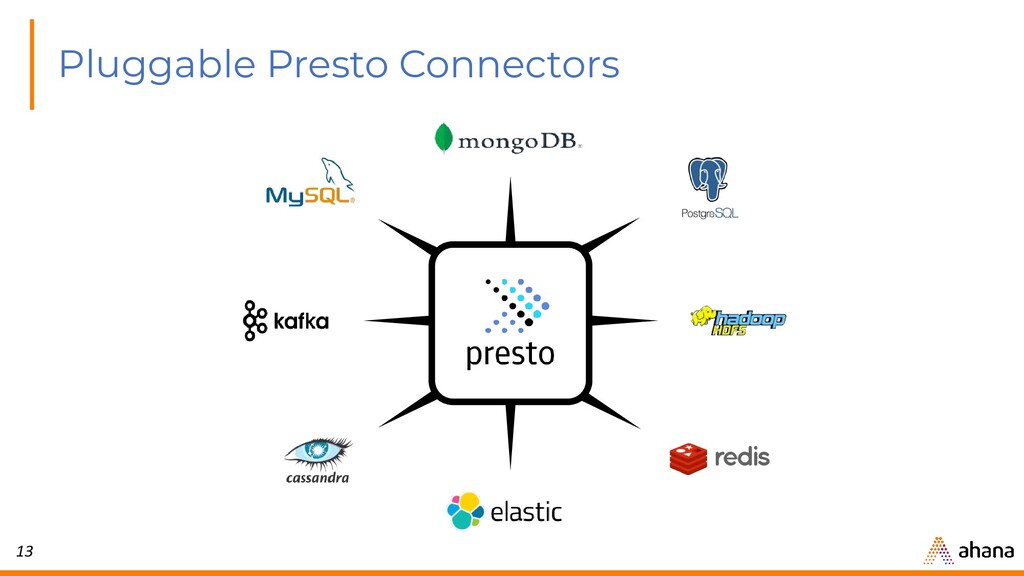{kind=link}
{kind=link}
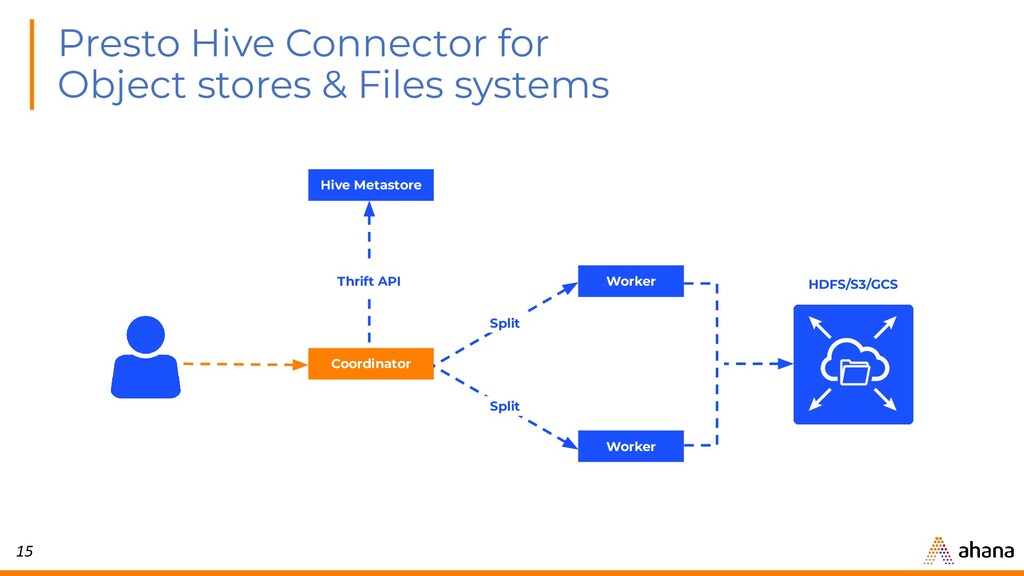{kind=link}
{kind=link}
{kind=link}
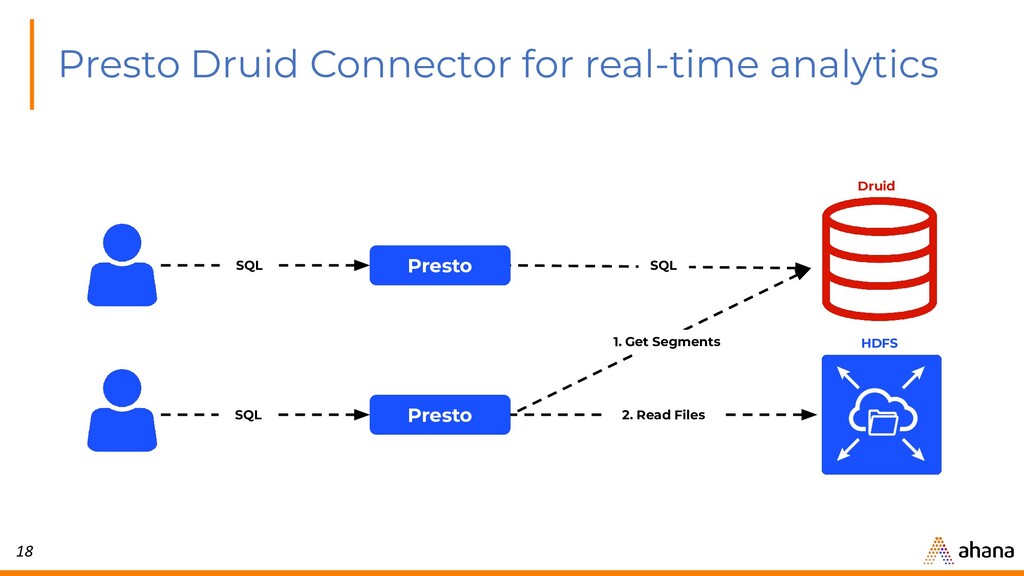{kind=link}
{kind=link}
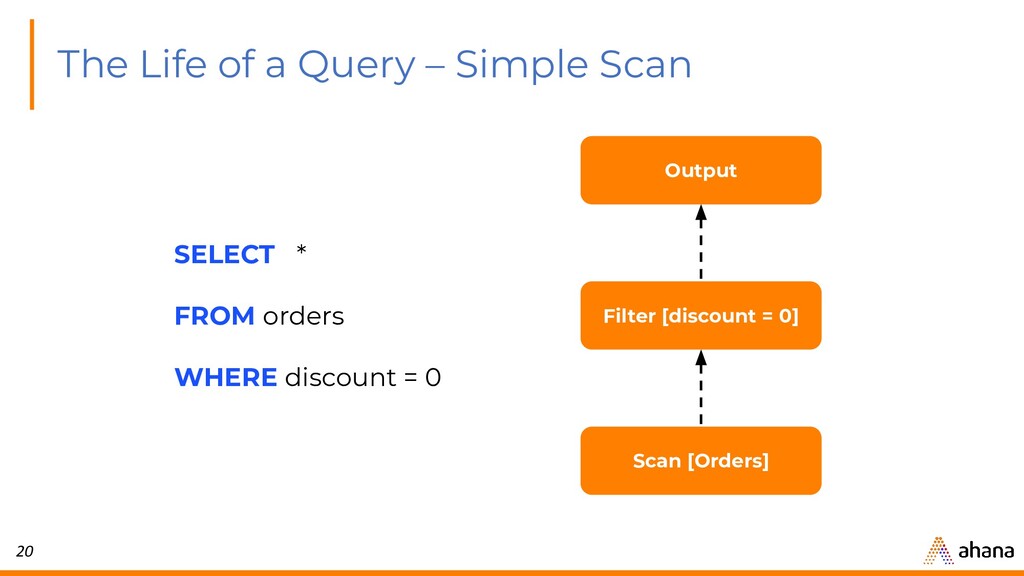{kind=link}
{kind=link}
![22 Logical Plan Aggregate [SUM(tax)] LeftJoin [ON orderkey] Filter [discount=0]](https://files.speakerdeck.com/presentations/43b16b7fee09420fa647a0c3a3900c28/slide_21.jpg){kind=link}
{kind=link}
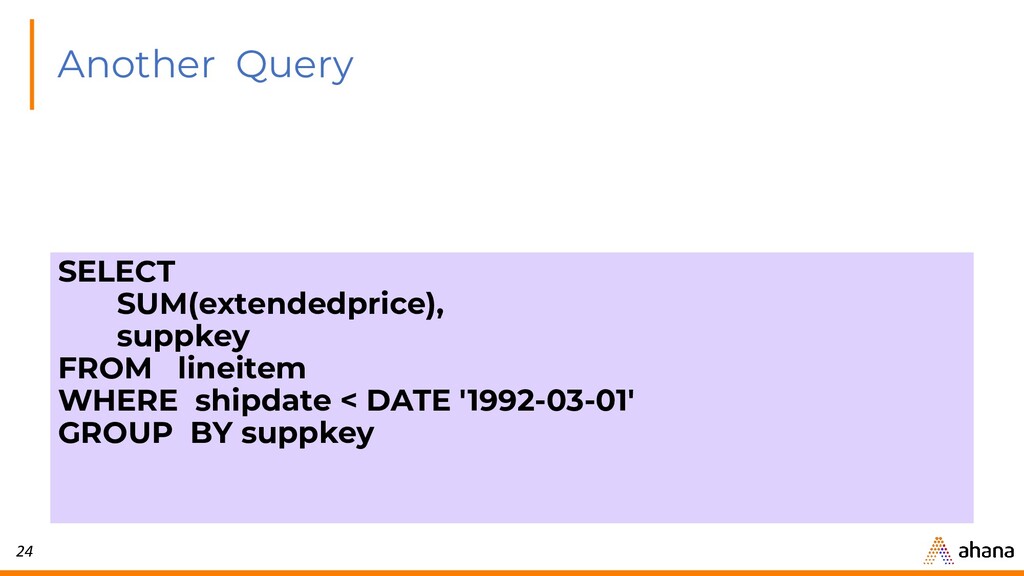{kind=link}
{kind=link}
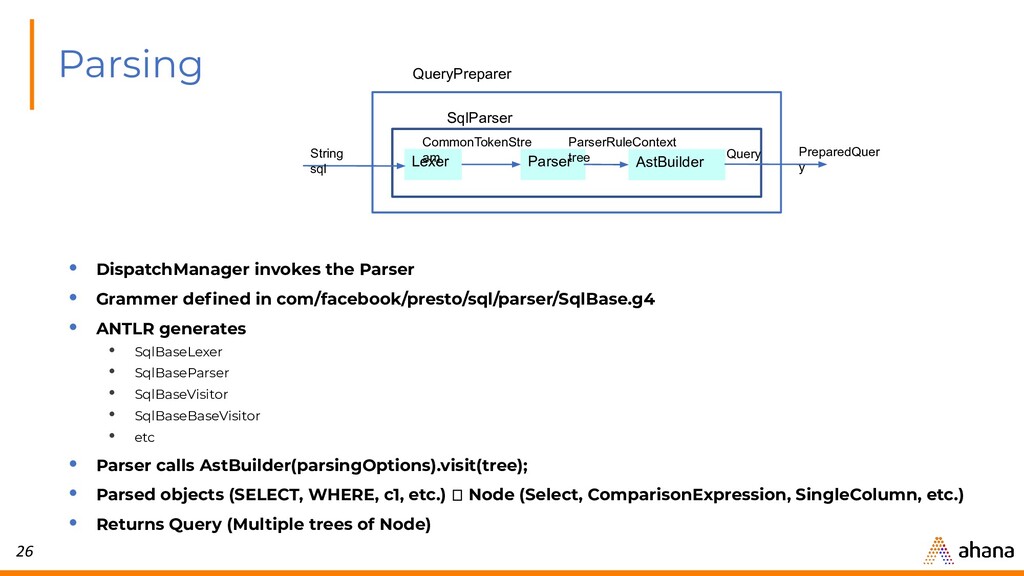{kind=link}
{kind=link}
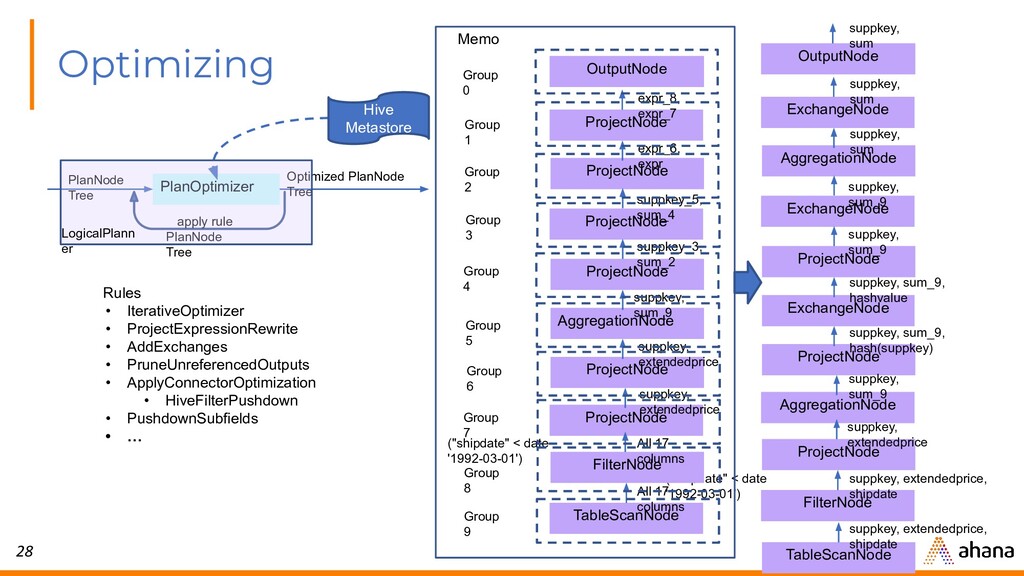{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
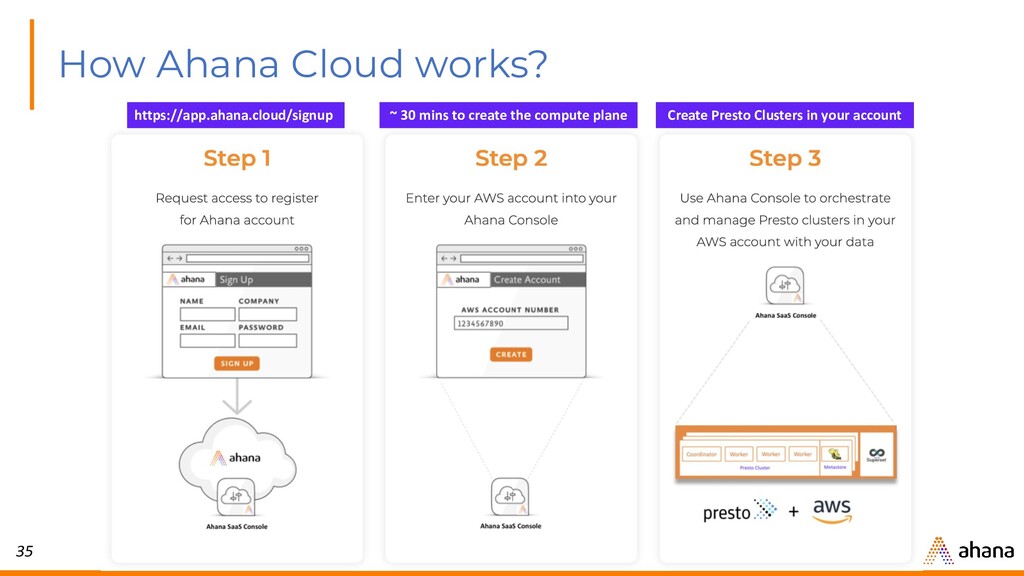{kind=link}
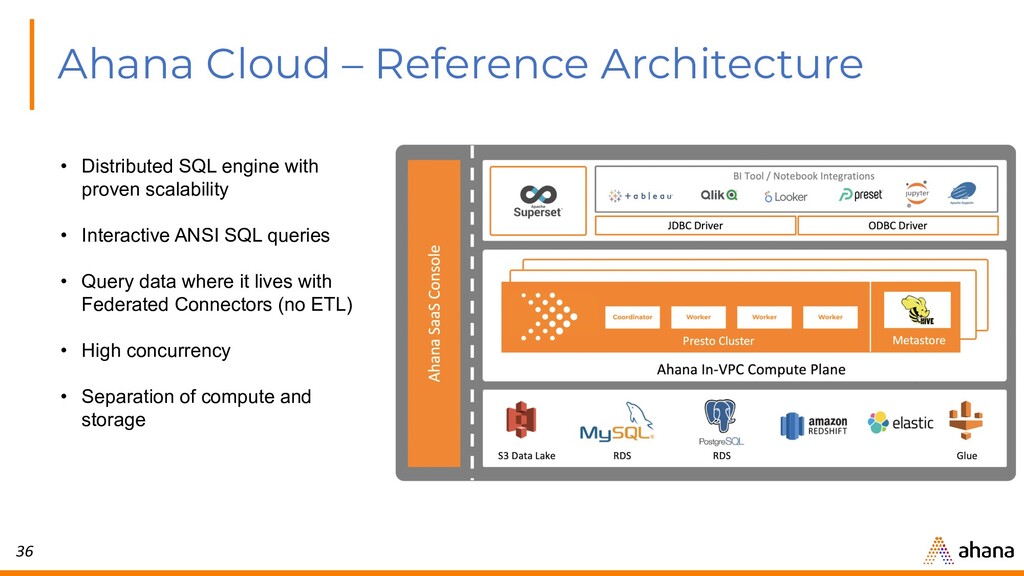{kind=link}
{kind=link}