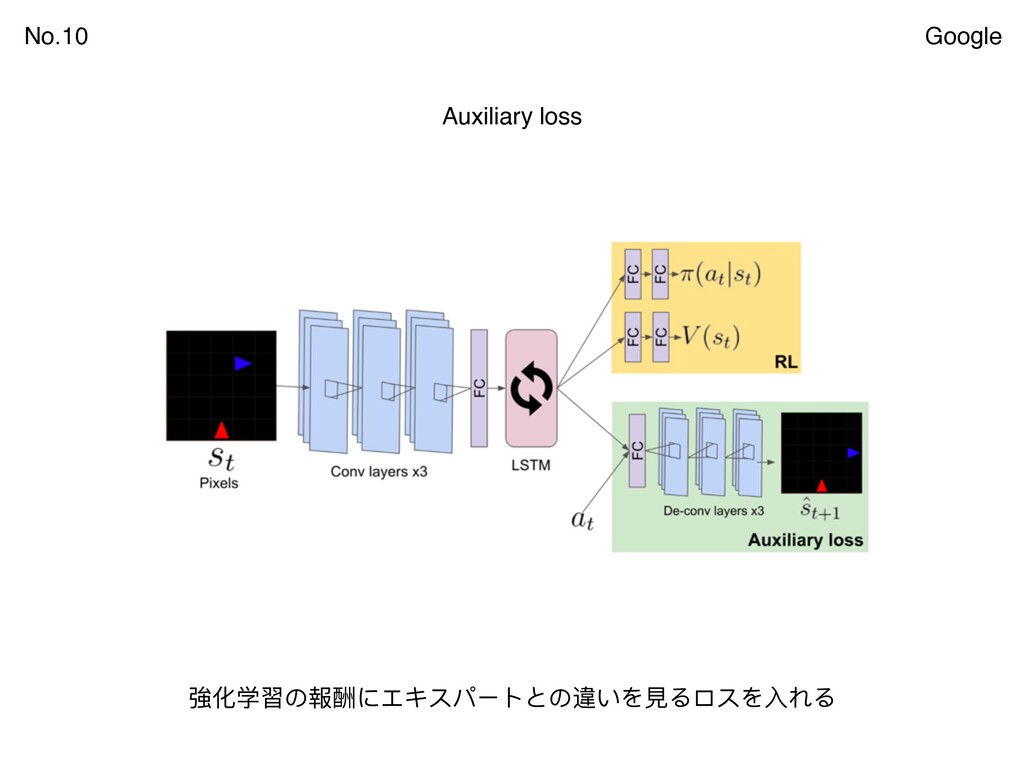
Rethinking Attention with Performers 3. Explaining Deep Neural Networks 4. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 5. Representation Learning via Invariant Causal Mechanisms 6. AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients 7. Neural Databases 8. Fourier Neural Operator for Parametric Partial Differential Equations 9. Auto Seg-Loss: Searching Metric Surrogates for Semantic Segmentation 10.Mind the Pad -- CNNs can Develop Blind Spots Top Recent 10
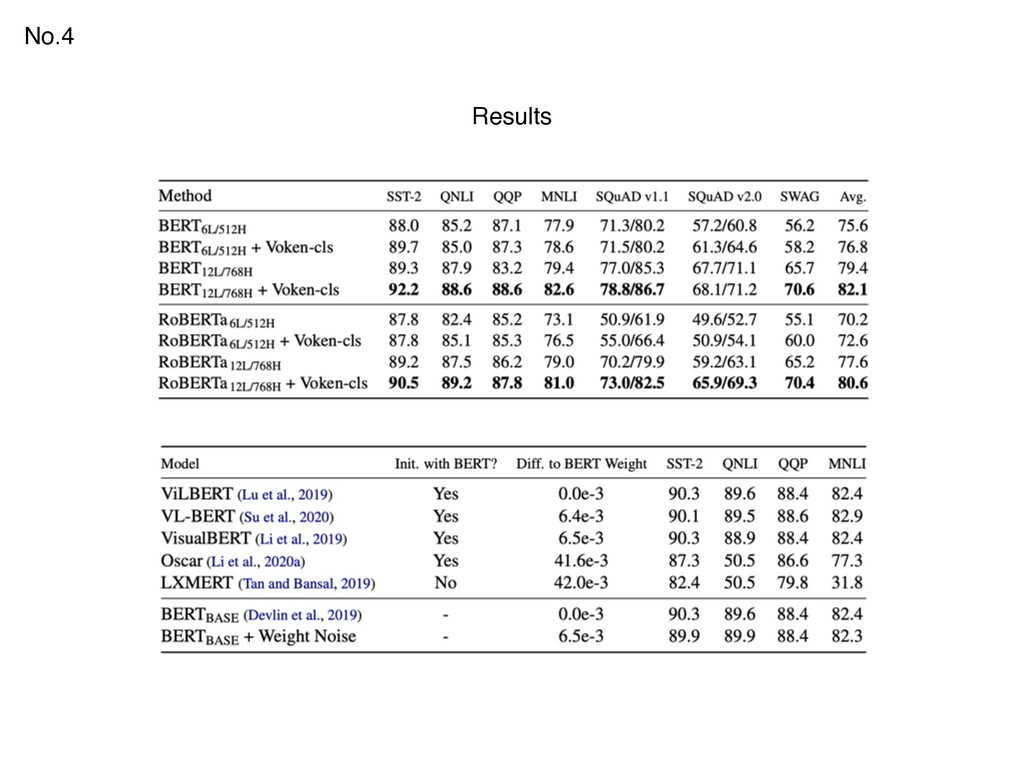
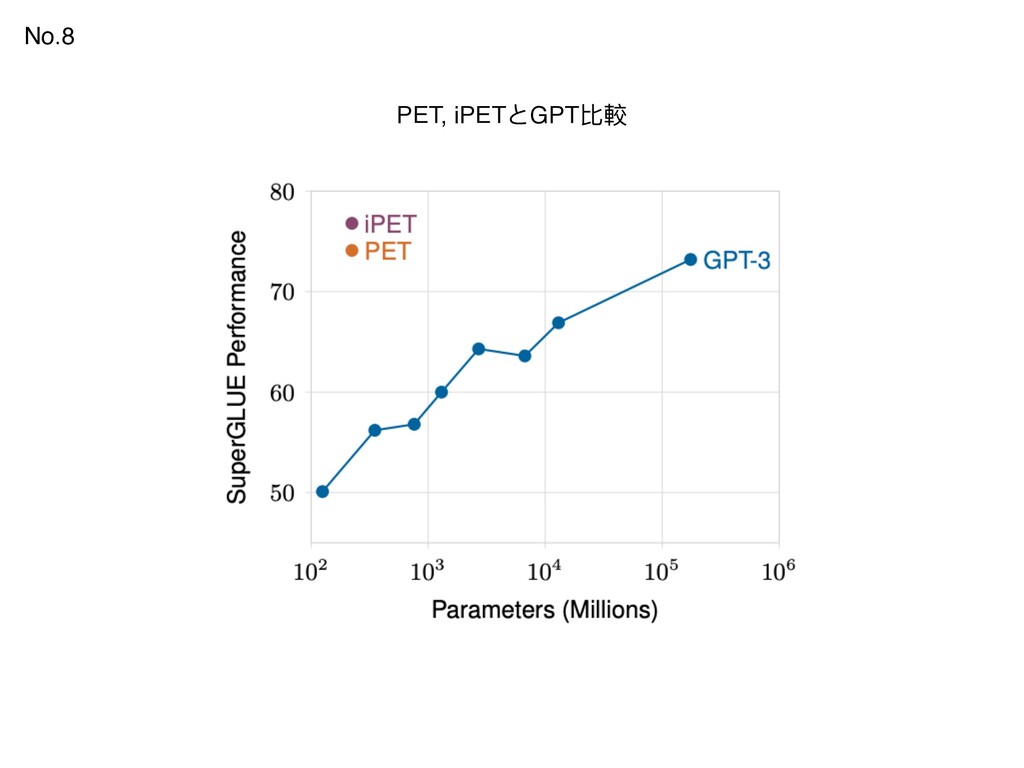
Explaining Deep Neural Networks 3. EigenGame: PCA as a Nash Equilibrium 4. Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision 5. Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking 6. Neural Databases 7. What Can We Do to Improve Peer Review in NLP? 8. It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners 9. Self-supervised Learning: Generative or Contrastive 10.Multi-agent Social Reinforcement Learning Improves Generalization Top Hype 10
Via positive Orthogonal Random Features approach (FAVOR+)を使⽤しています。FAVOR+は、softmaxを超えるカーネル化 可能な注意メカニズムを効率的にモデル化するためにも使⽤できる。この表現⼒は、通常の Transformerでは到達できない⼤規模なタスクで初めてsoftmaxと他のカーネルを正確に⽐較し、最適 な注⽬カーネルを調査するために⾮常に重要である。Performersは通常のTransformerと完全に互換 性のある線形アーキテクチャであり、注⽬⾏列の偏りのない、あるいはほぼ偏りのない推定、⼀様な 収束、低い推定分散などの理論的な保証がある。Performersを、ピクセル予測からテキストモデル、 タンパク質配列モデリングまでの豊富なタスクでテストした。他の効率的なスパースおよび密な注⽬ ⼿法との競合結果を示し、Performersが活⽤した新しい注⽬学習パラダイムの有効性を示す。 →Transformer改良したよ Google
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
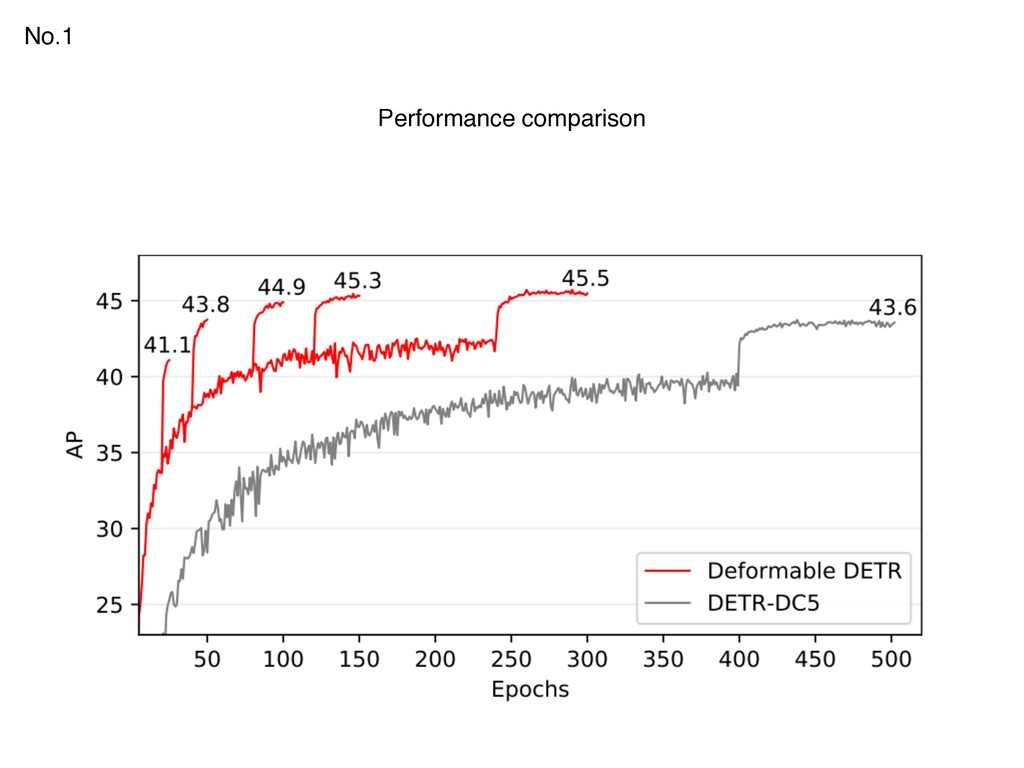
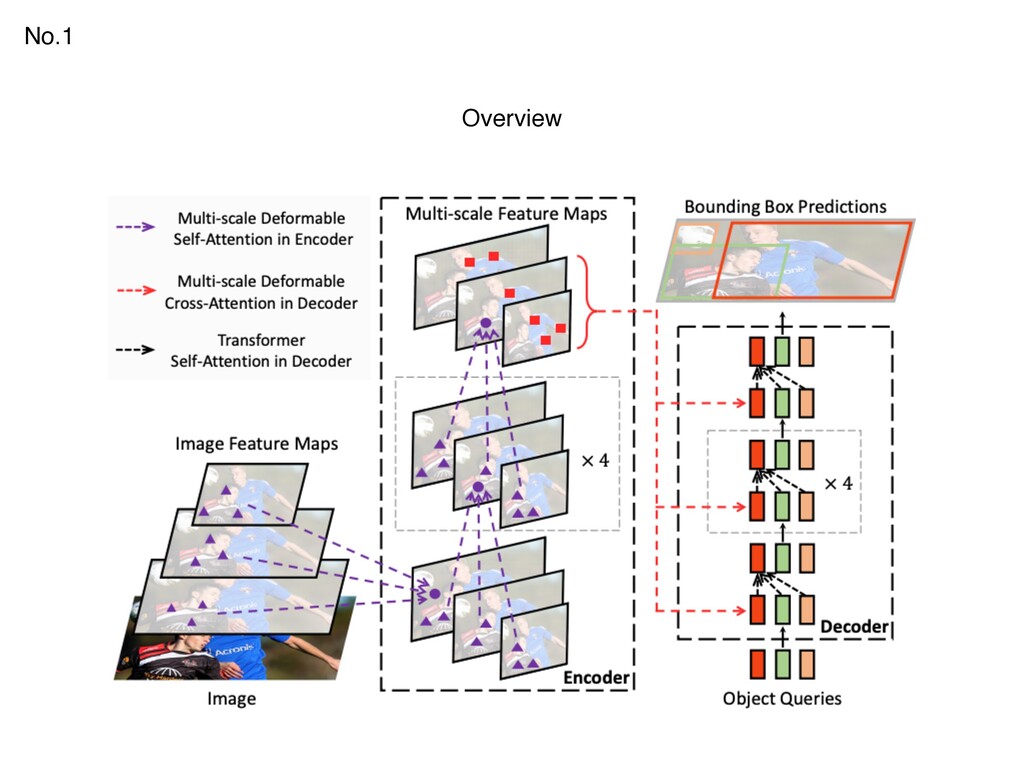{kind=link}
{kind=link}
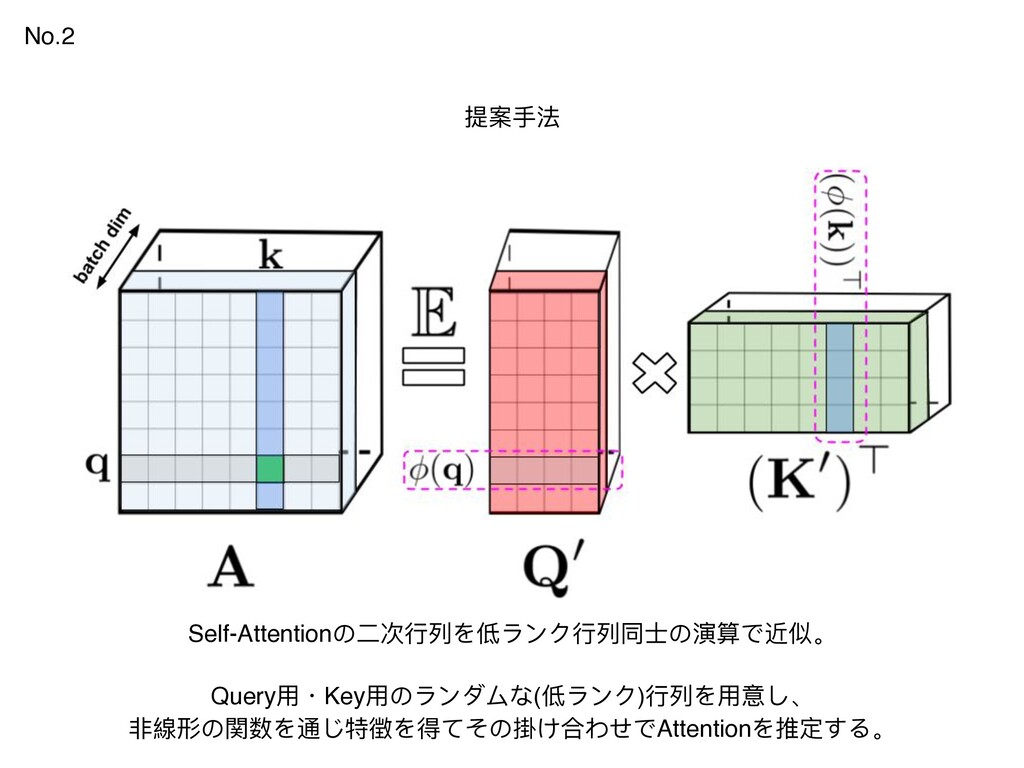
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
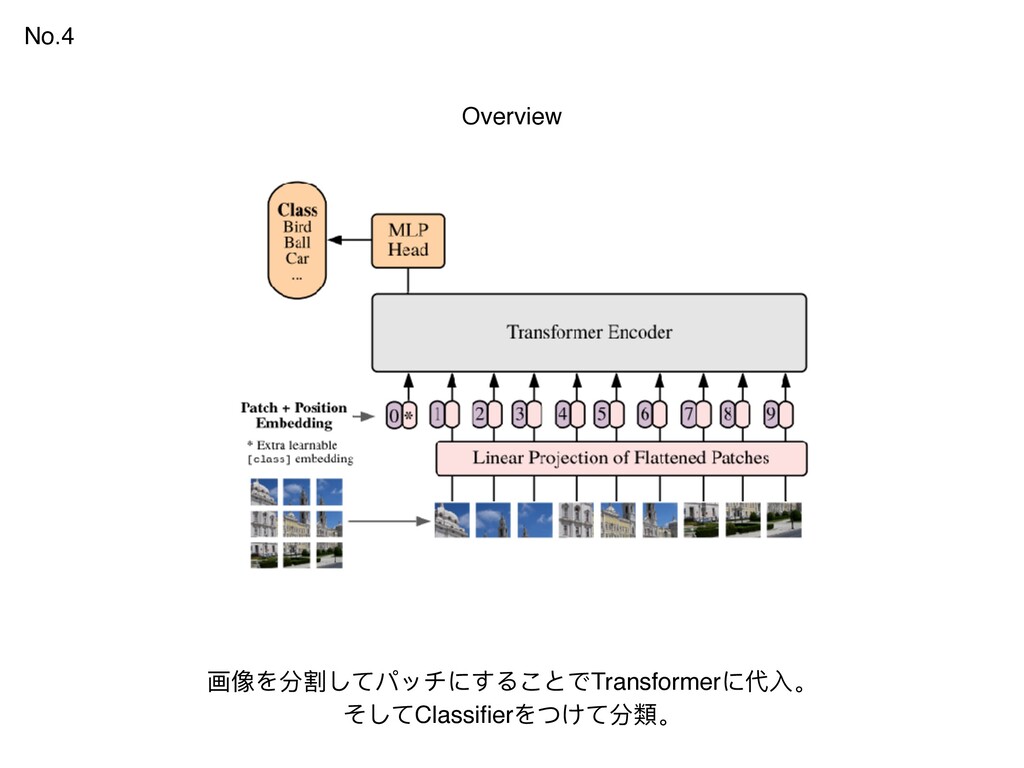{kind=link}
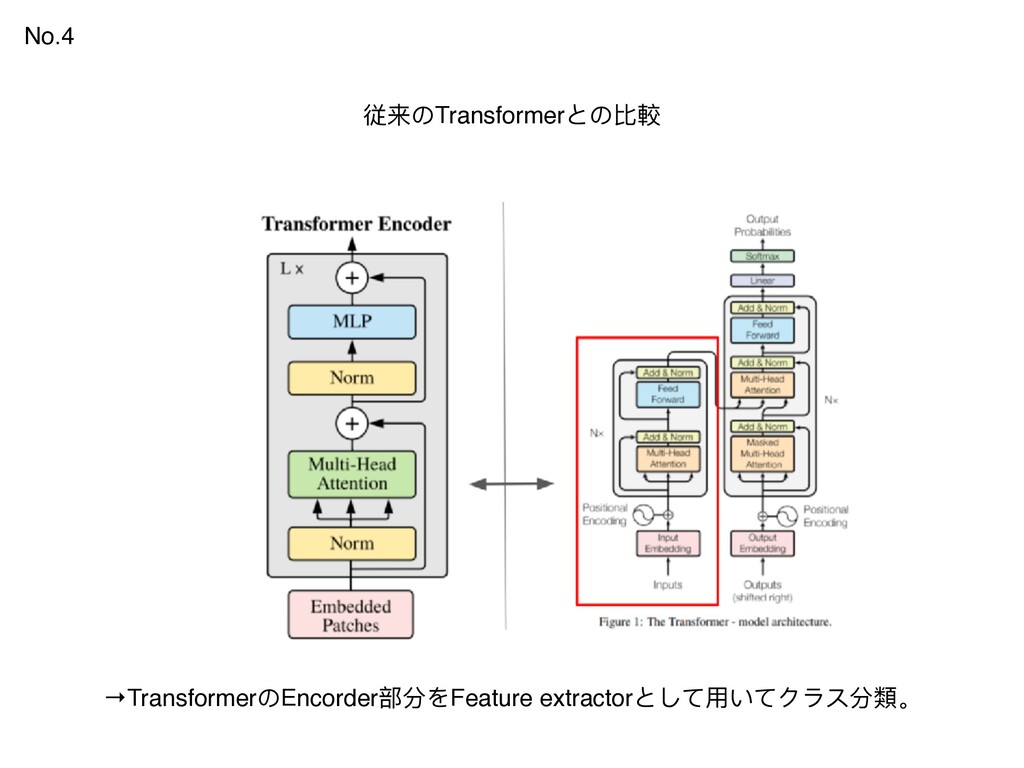{kind=link}
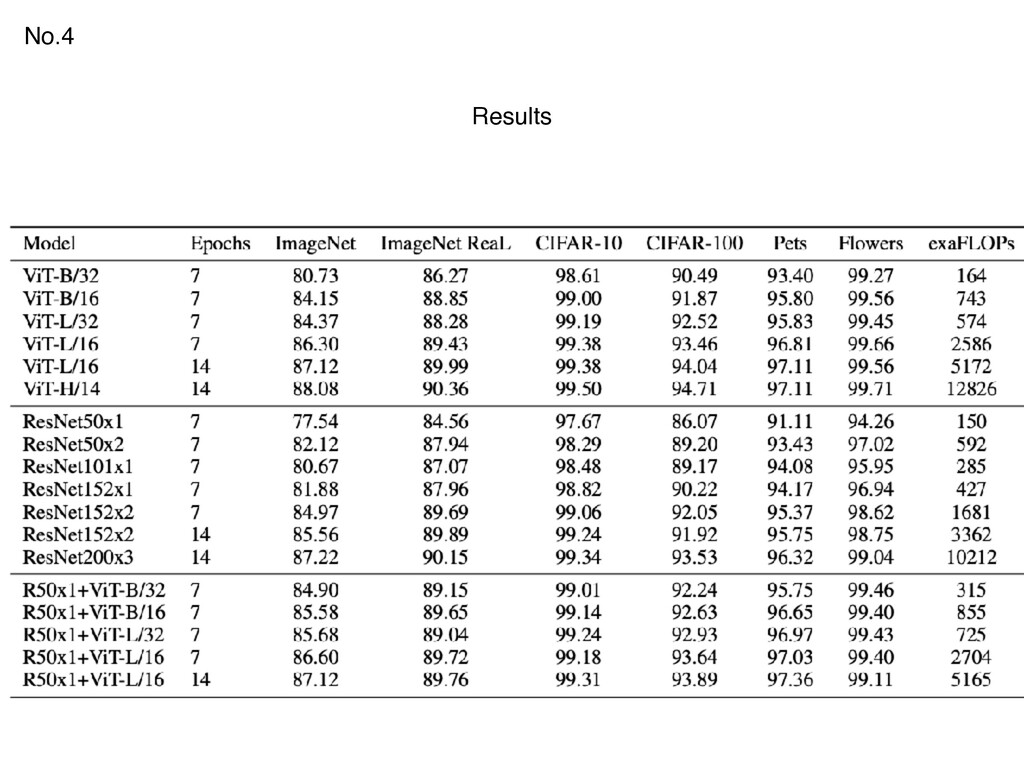{kind=link}
{kind=link}
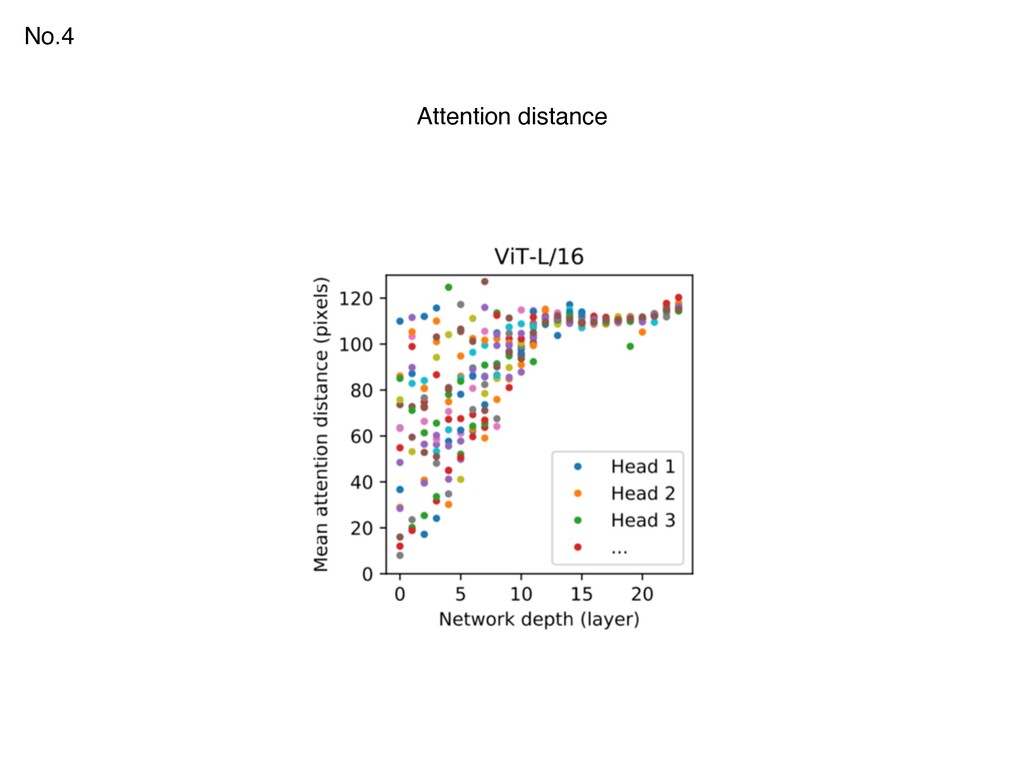{kind=link}
{kind=link}
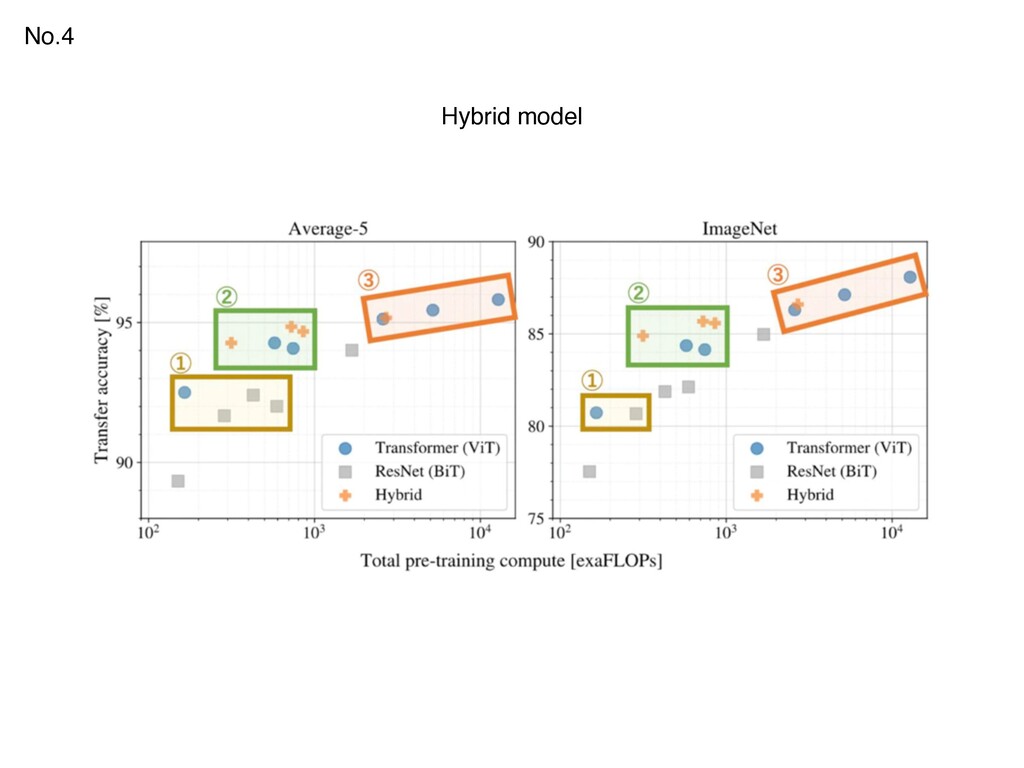{kind=link}
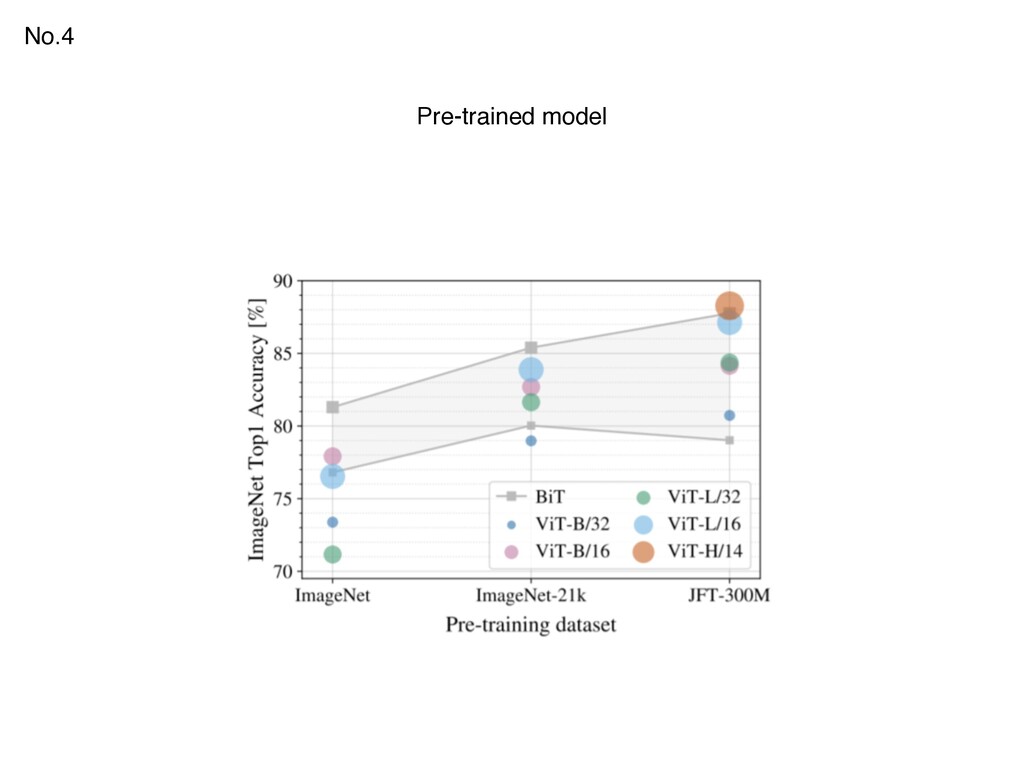{kind=link}
{kind=link}
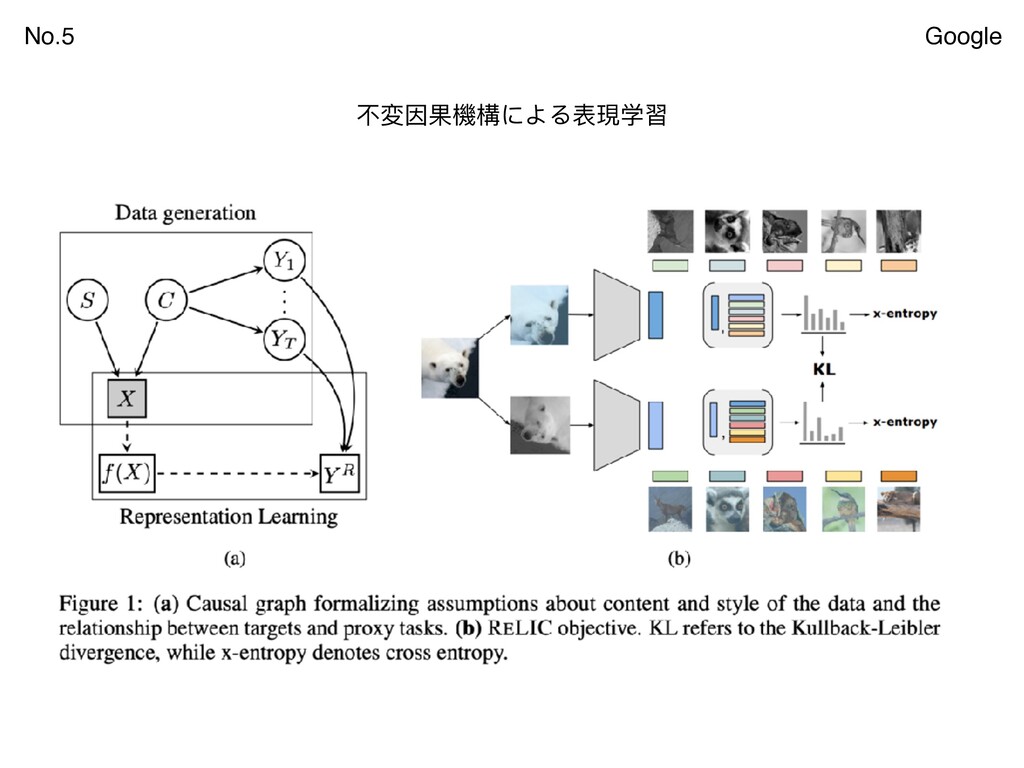{kind=link}
{kind=link}
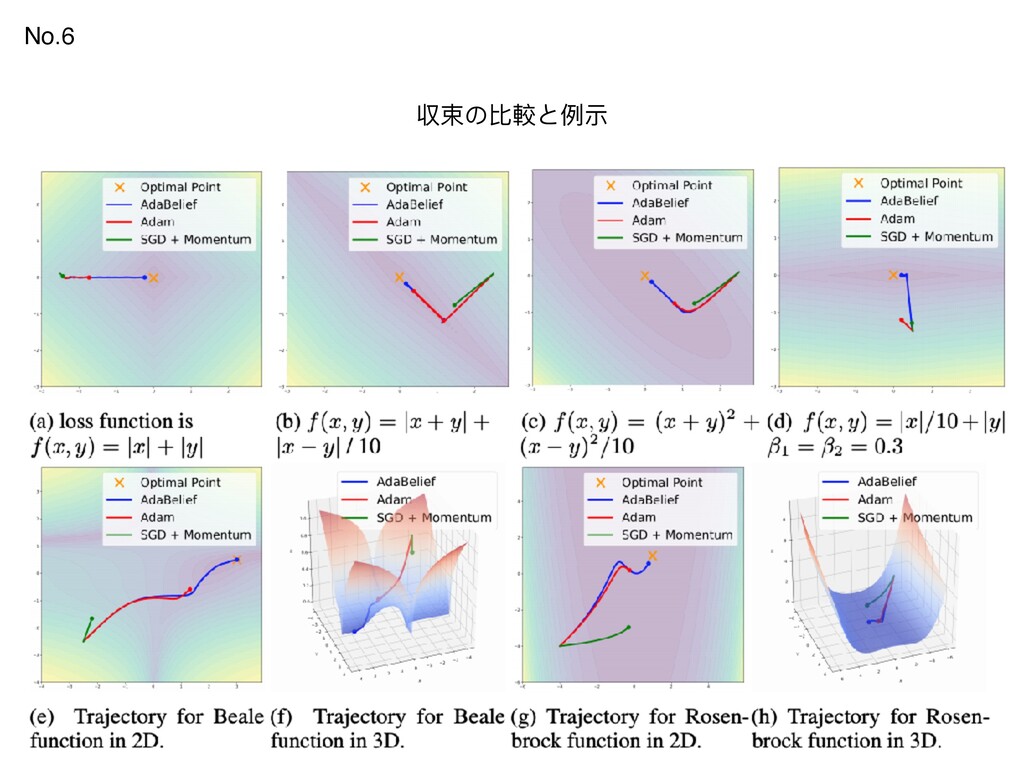{kind=link}
{kind=link}
{kind=link}
{kind=link}
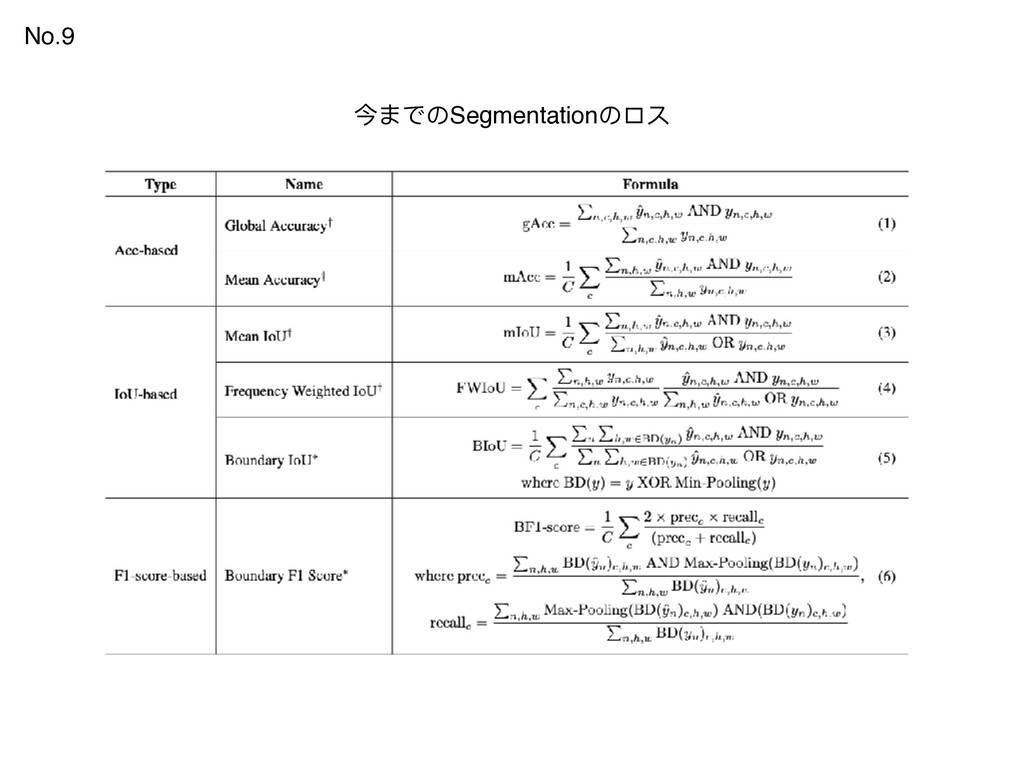{kind=link}
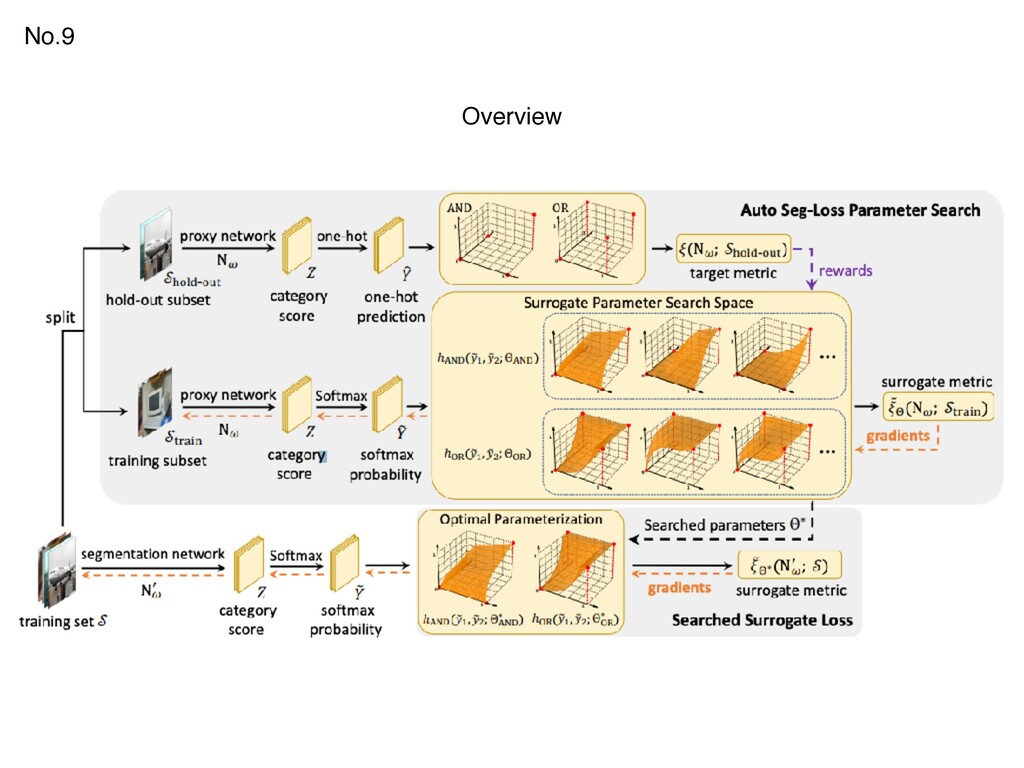{kind=link}
{kind=link}
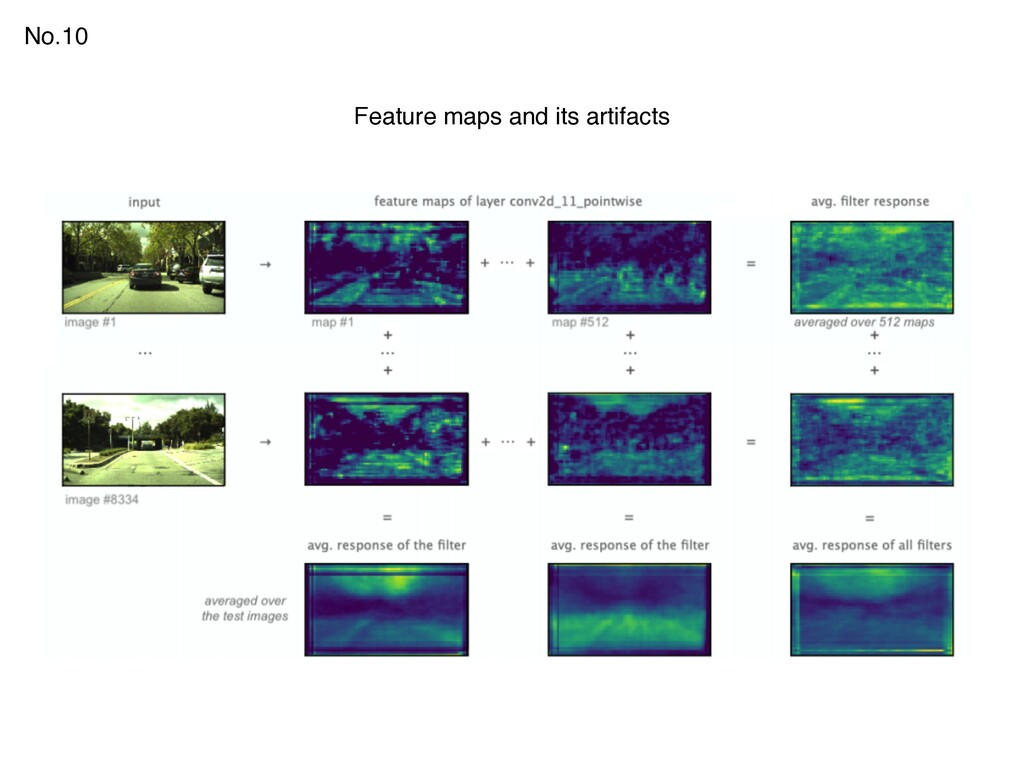{kind=link}
{kind=link}
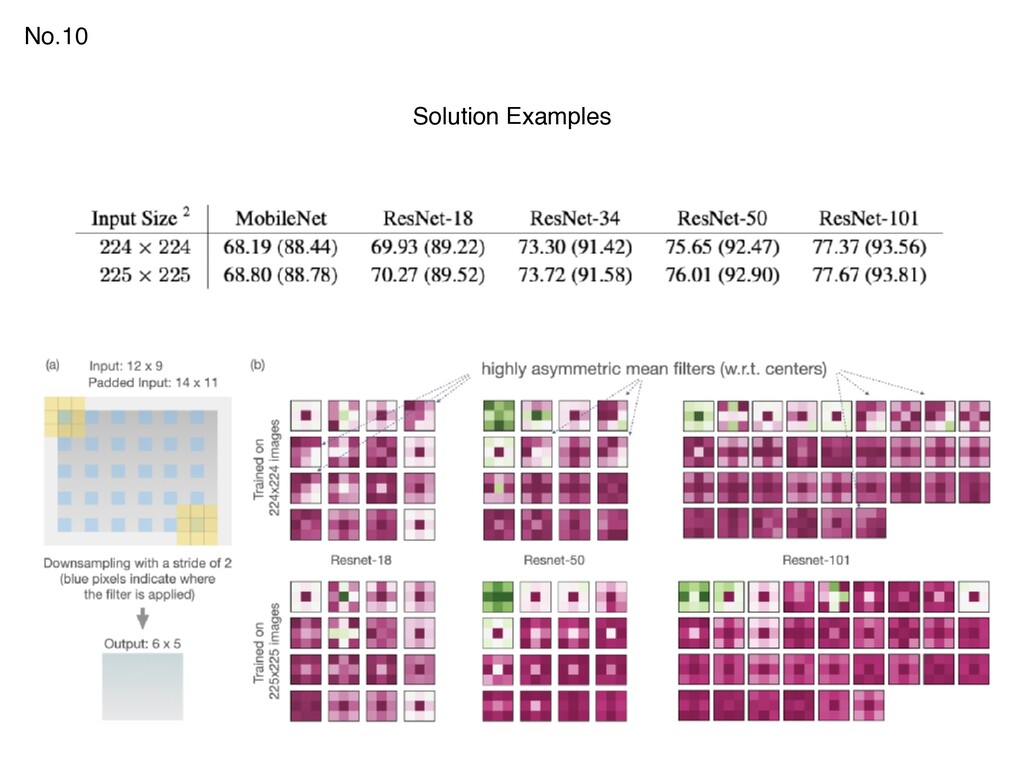{kind=link}
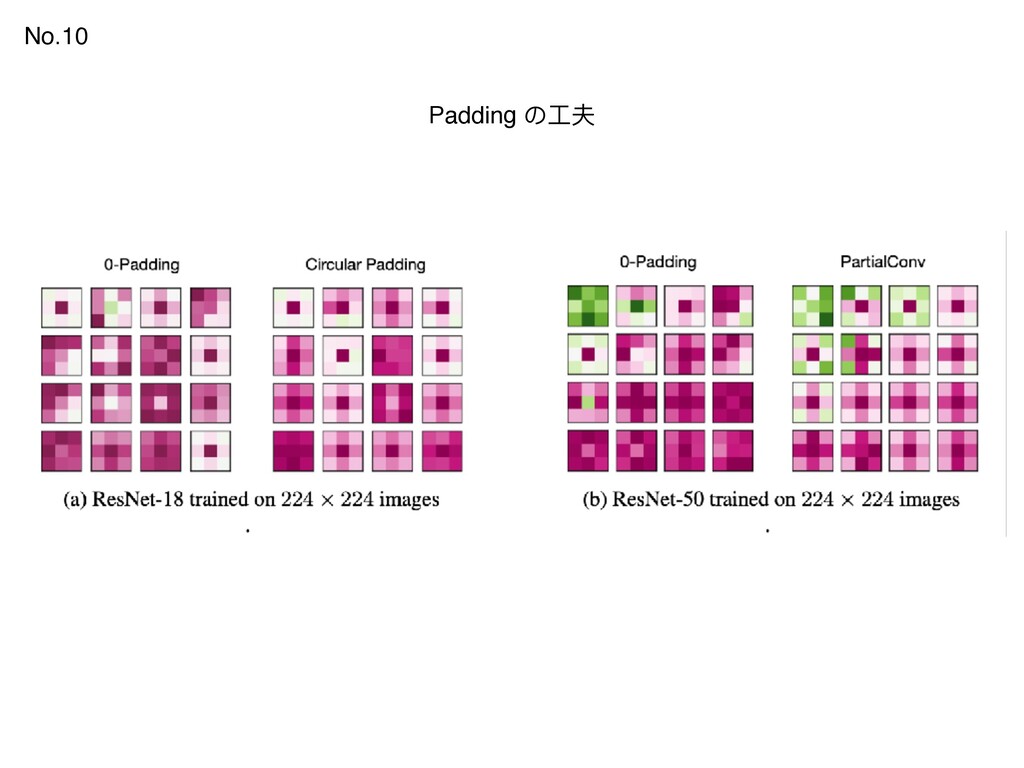{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
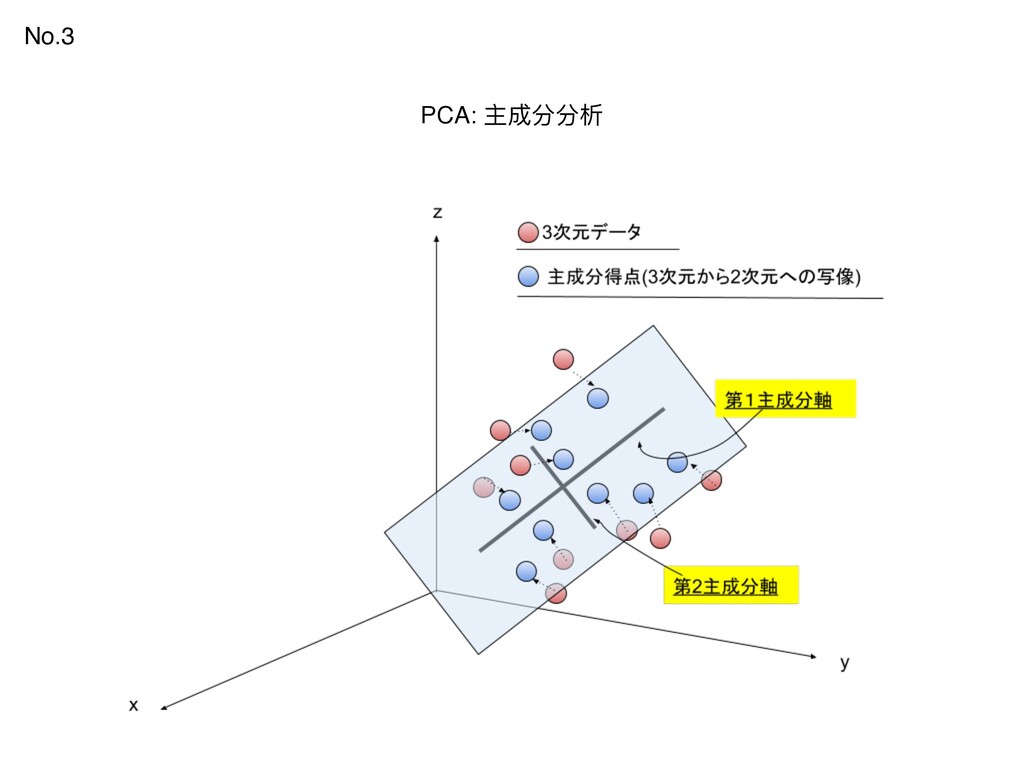{kind=link}
{kind=link}
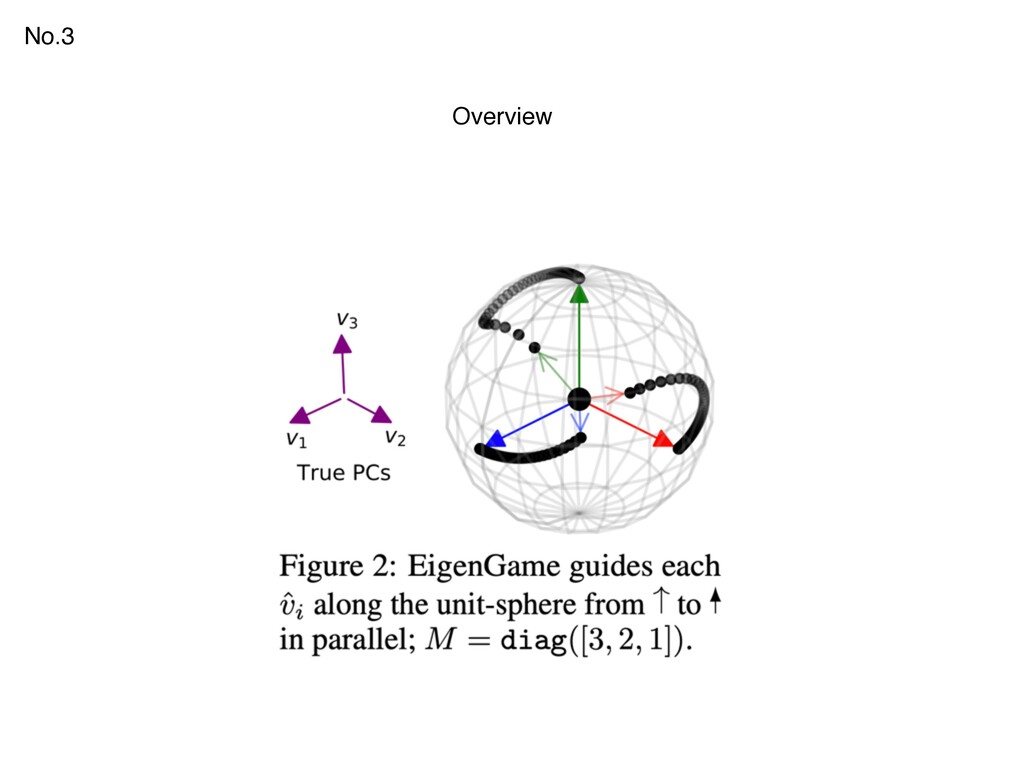{kind=link}
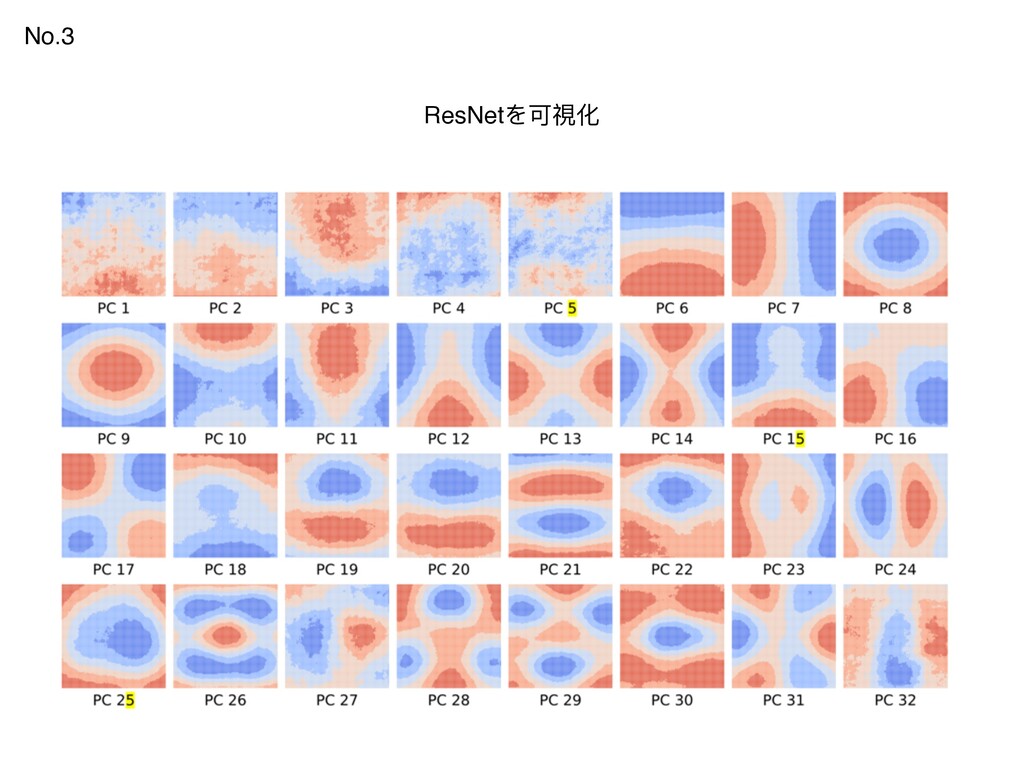{kind=link}
{kind=link}
{kind=link}
{kind=link}
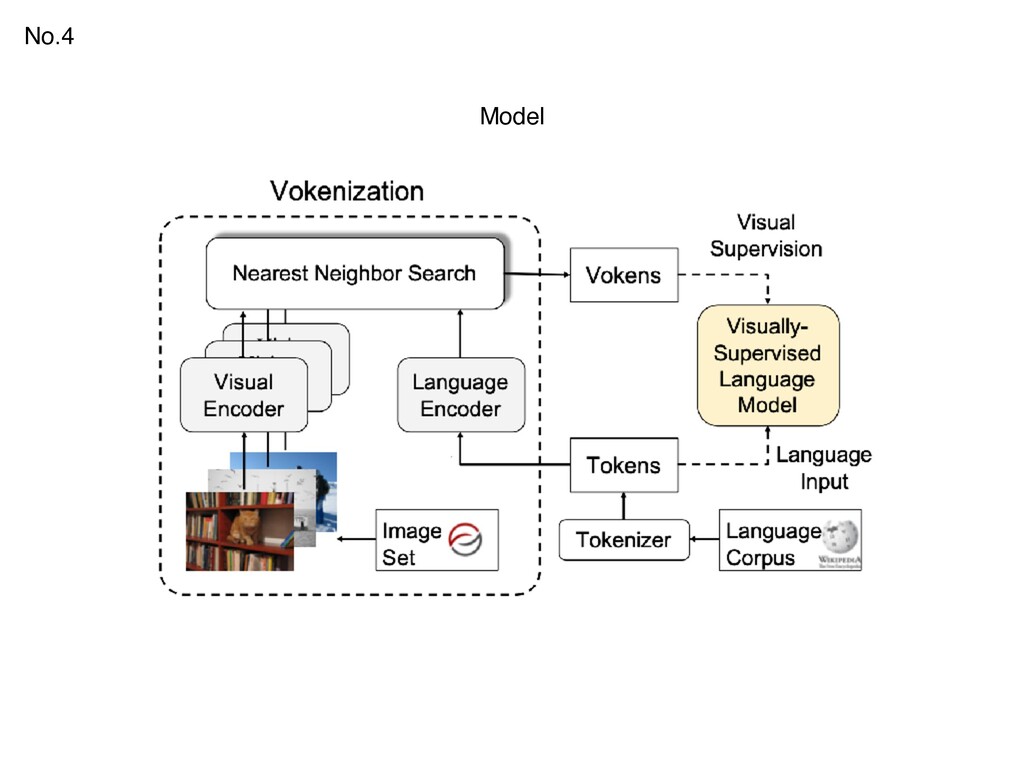{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}