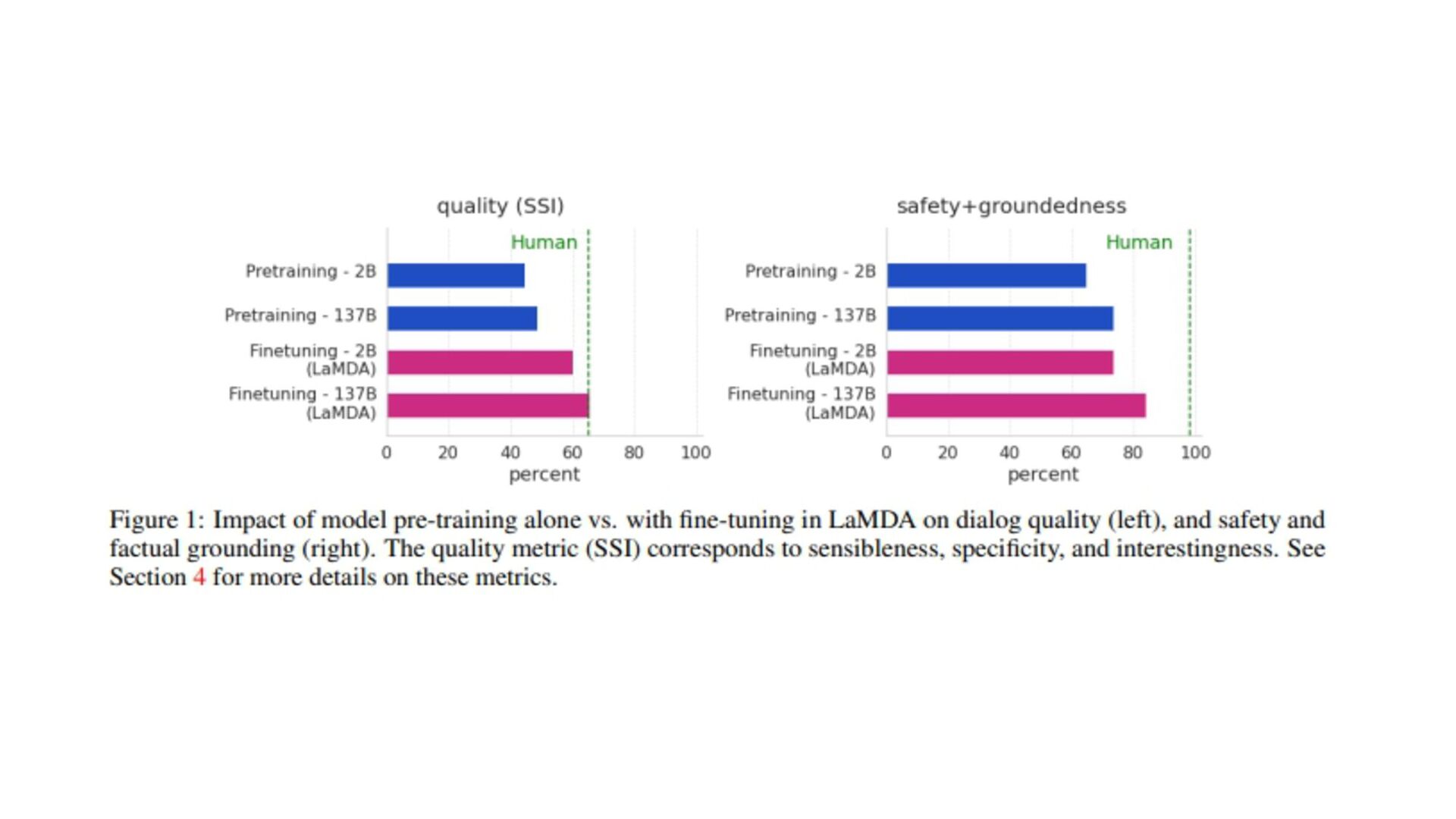
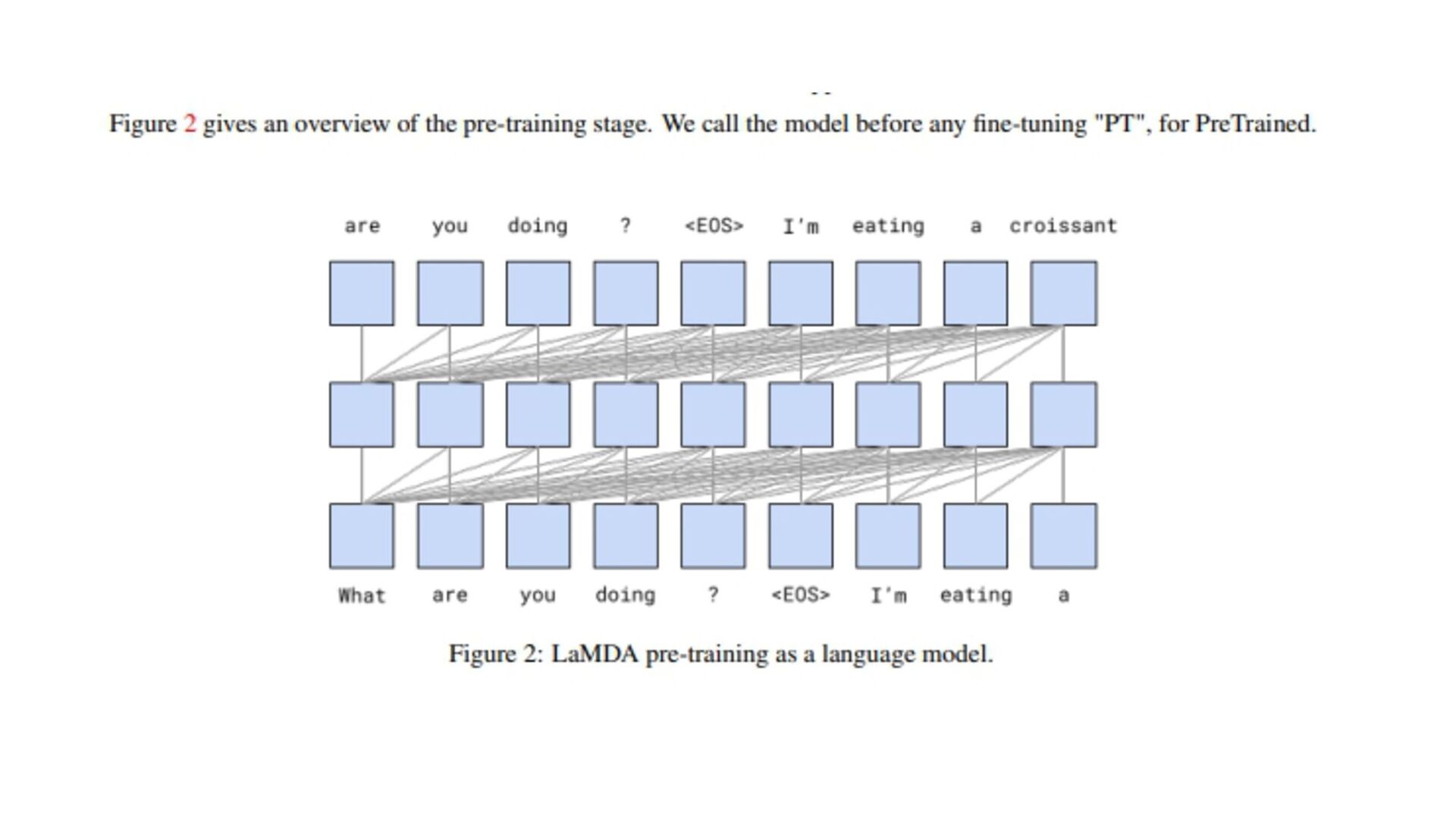
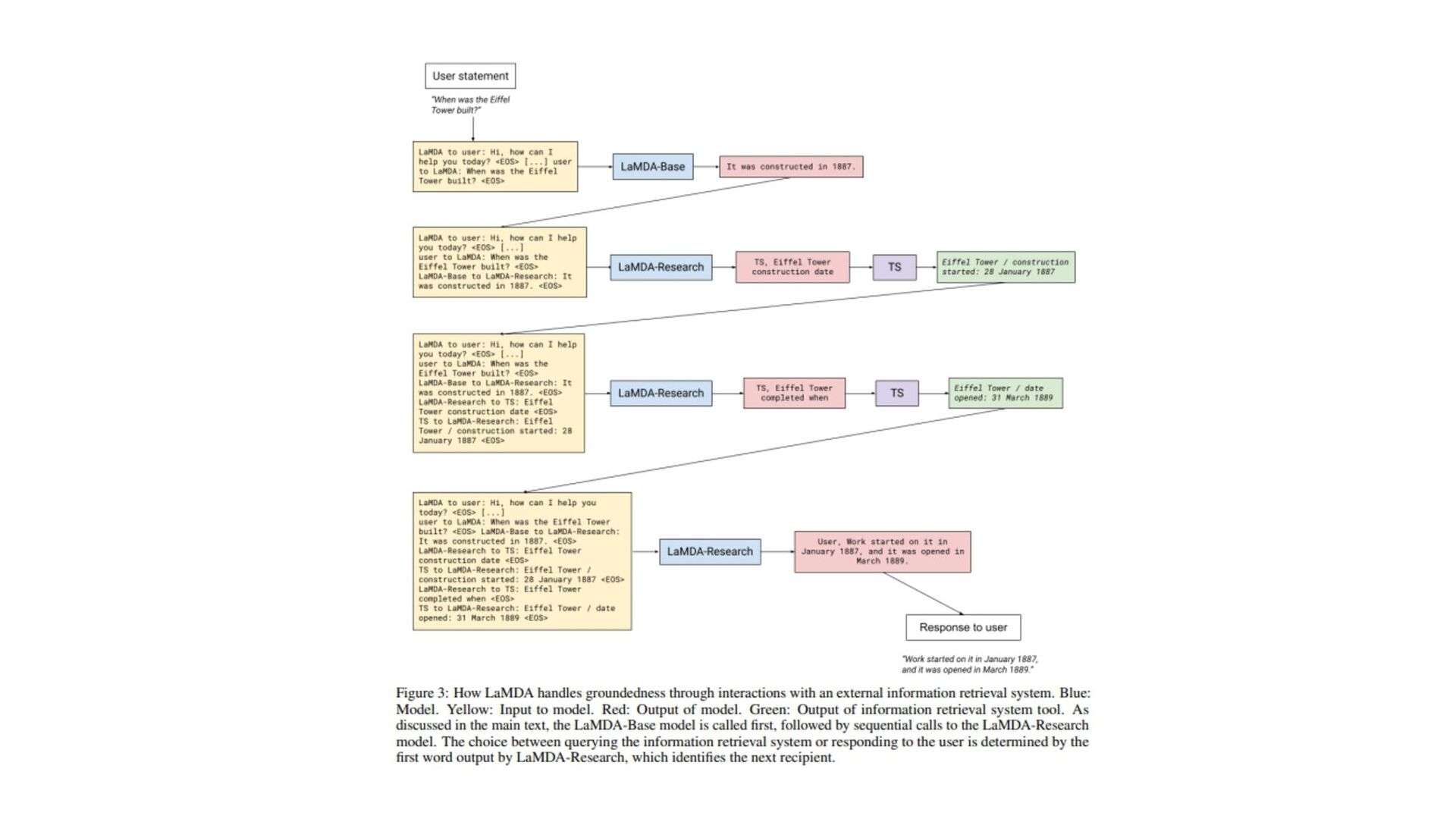
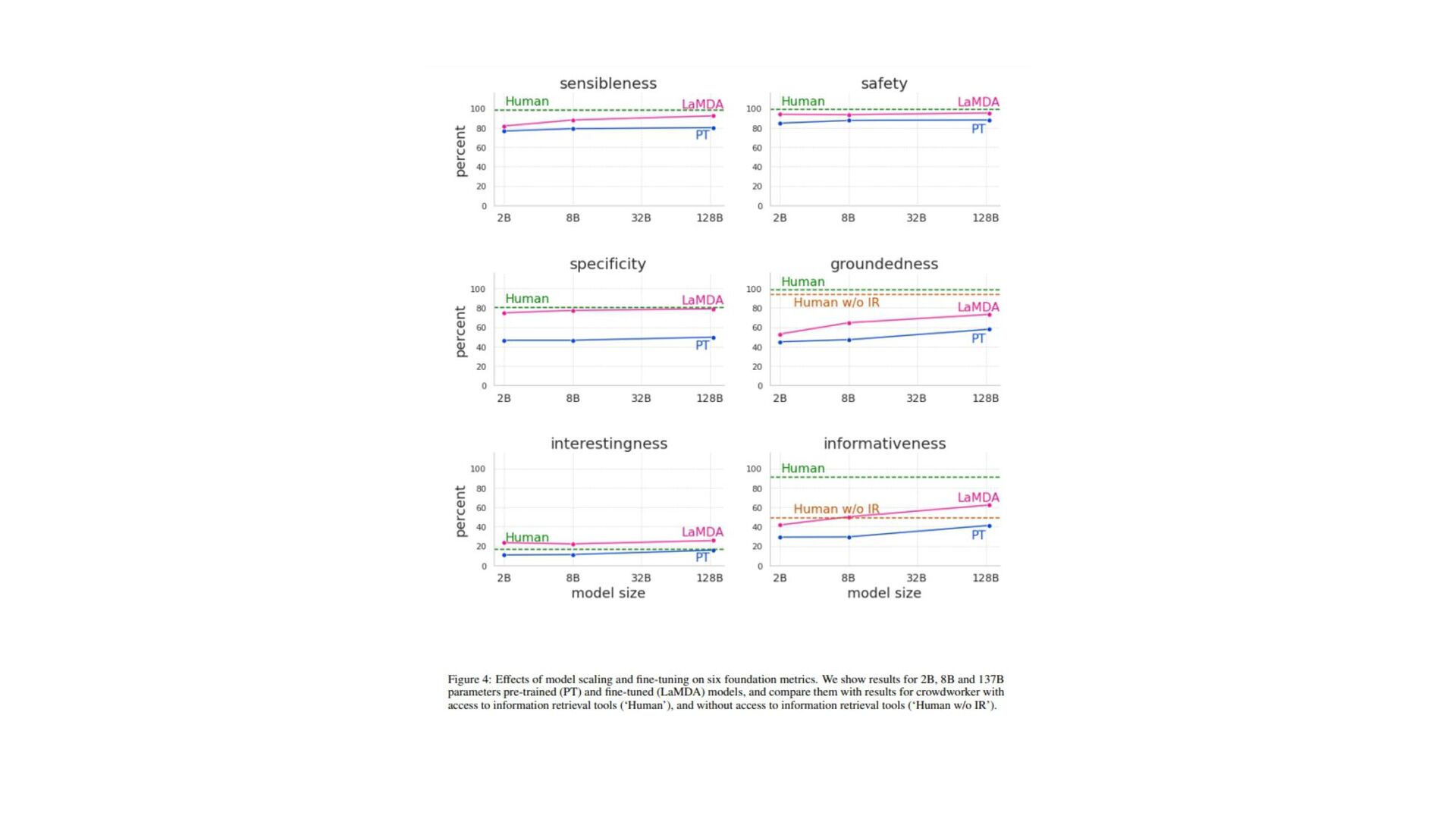
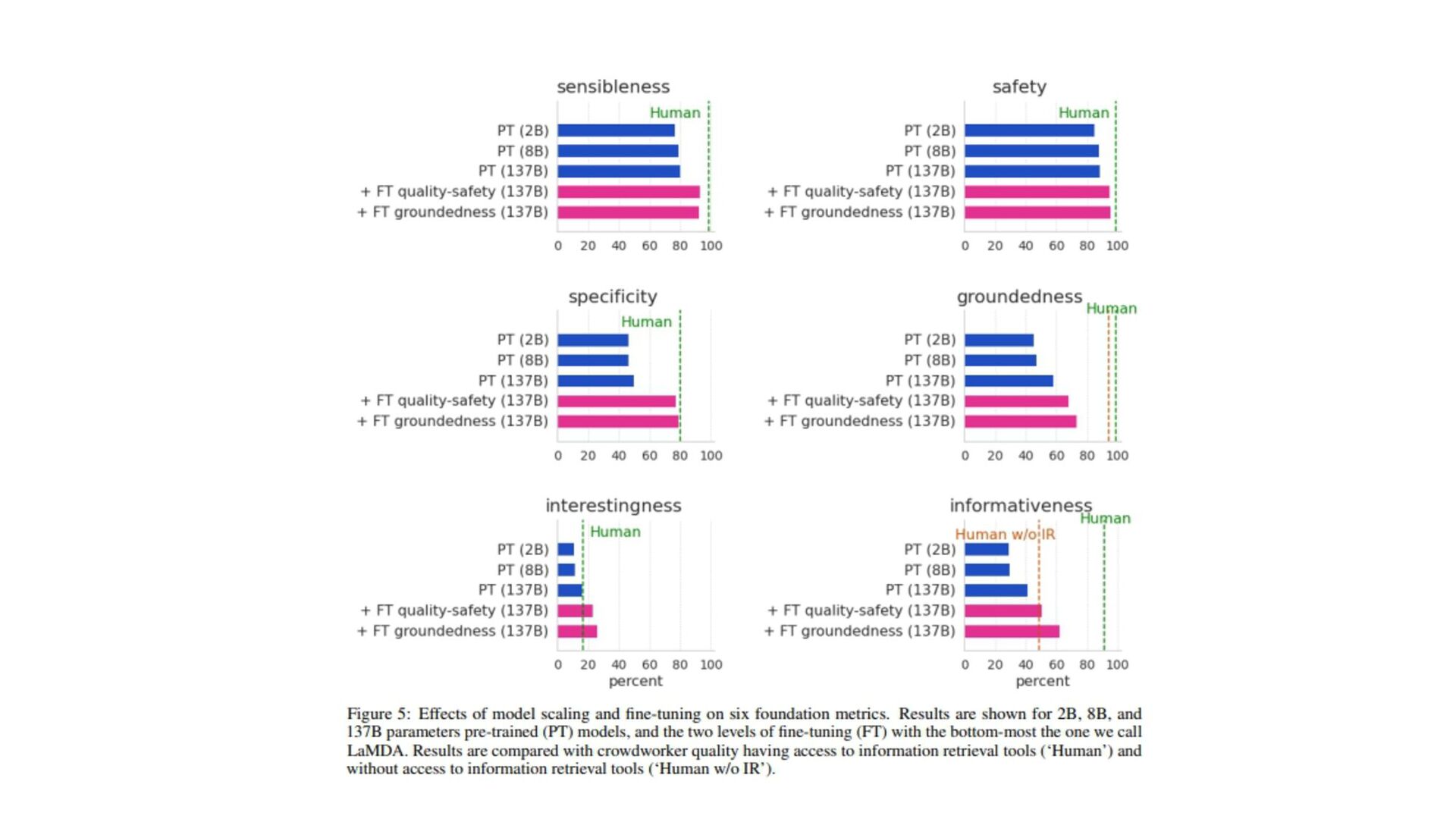
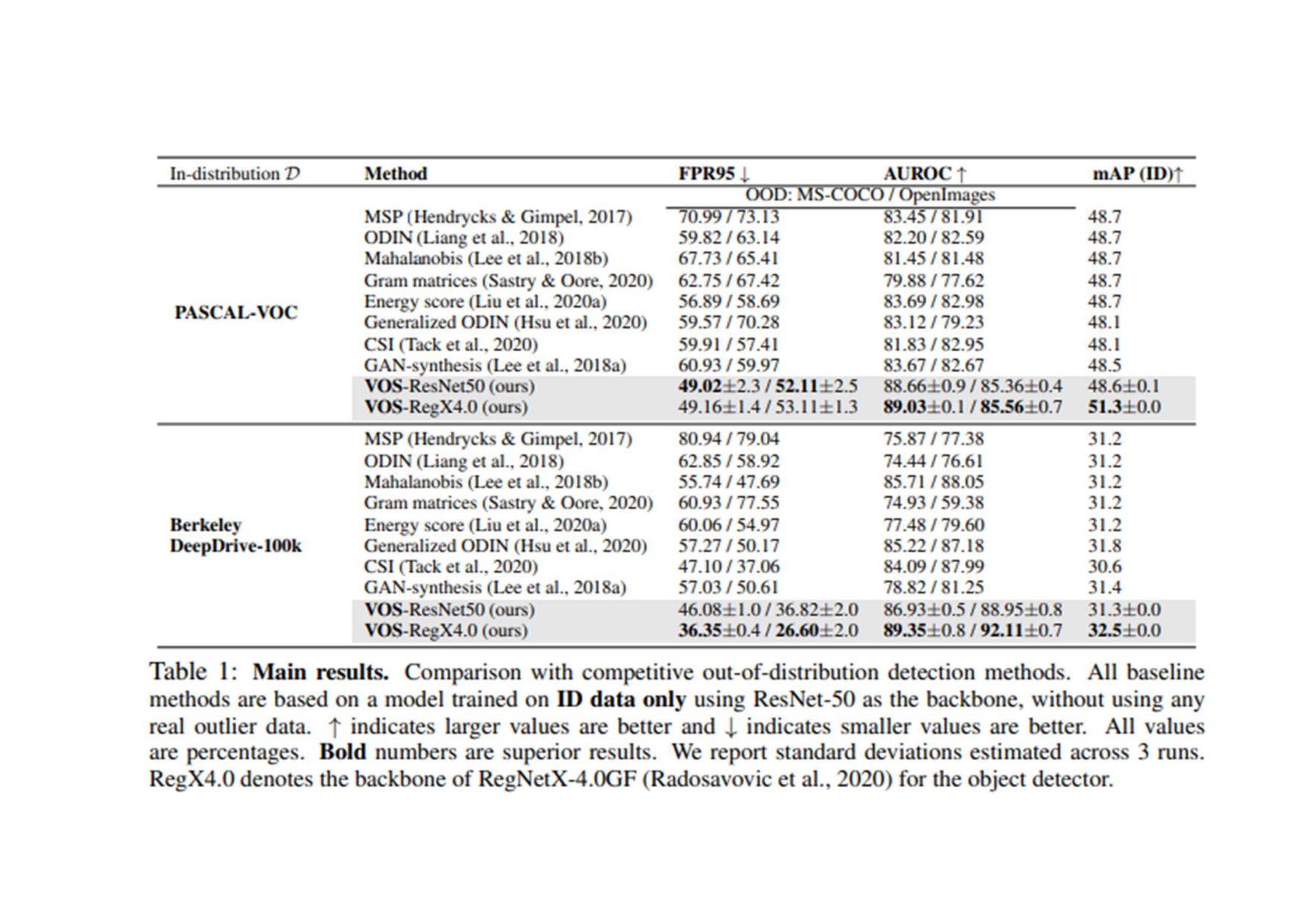
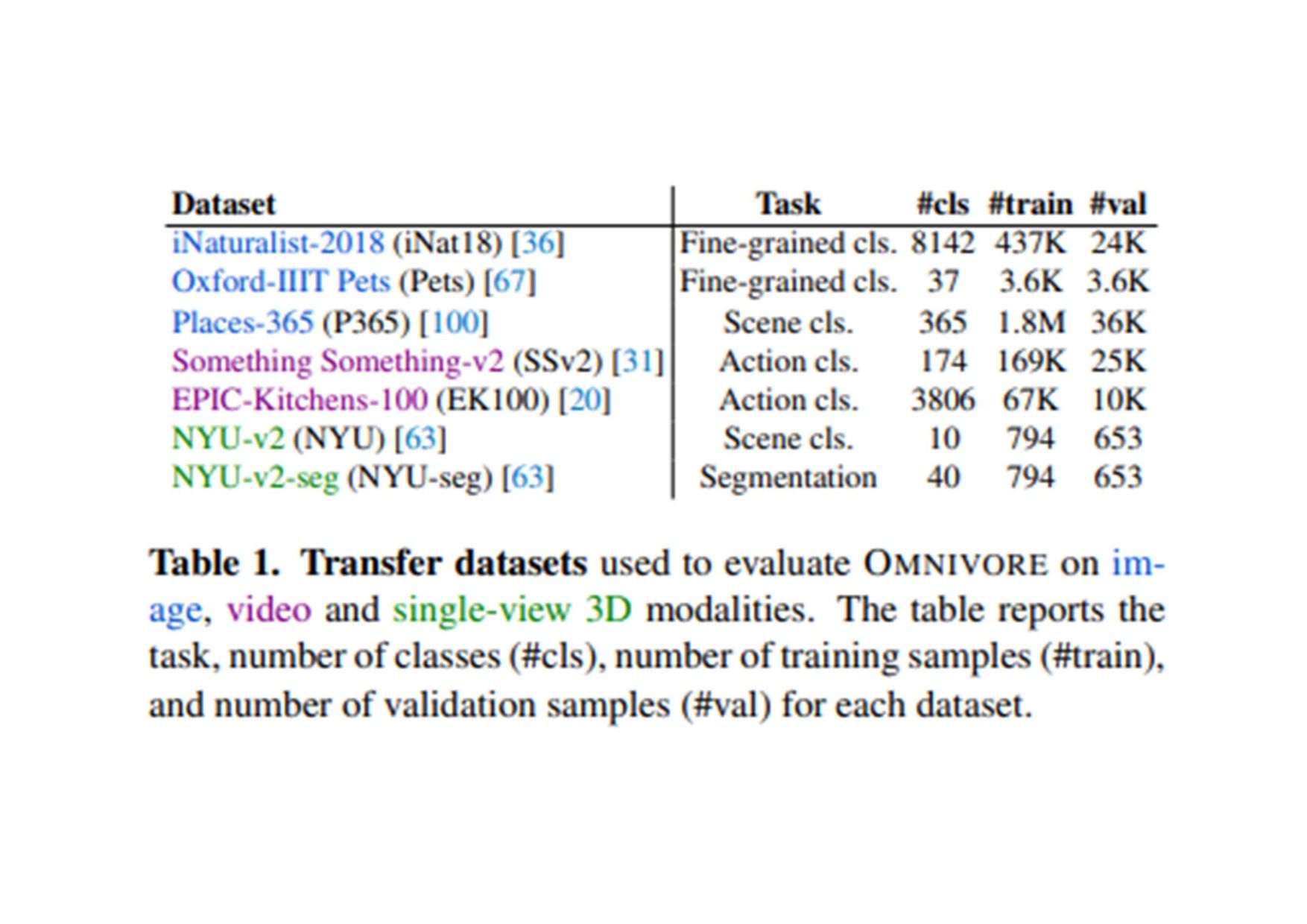
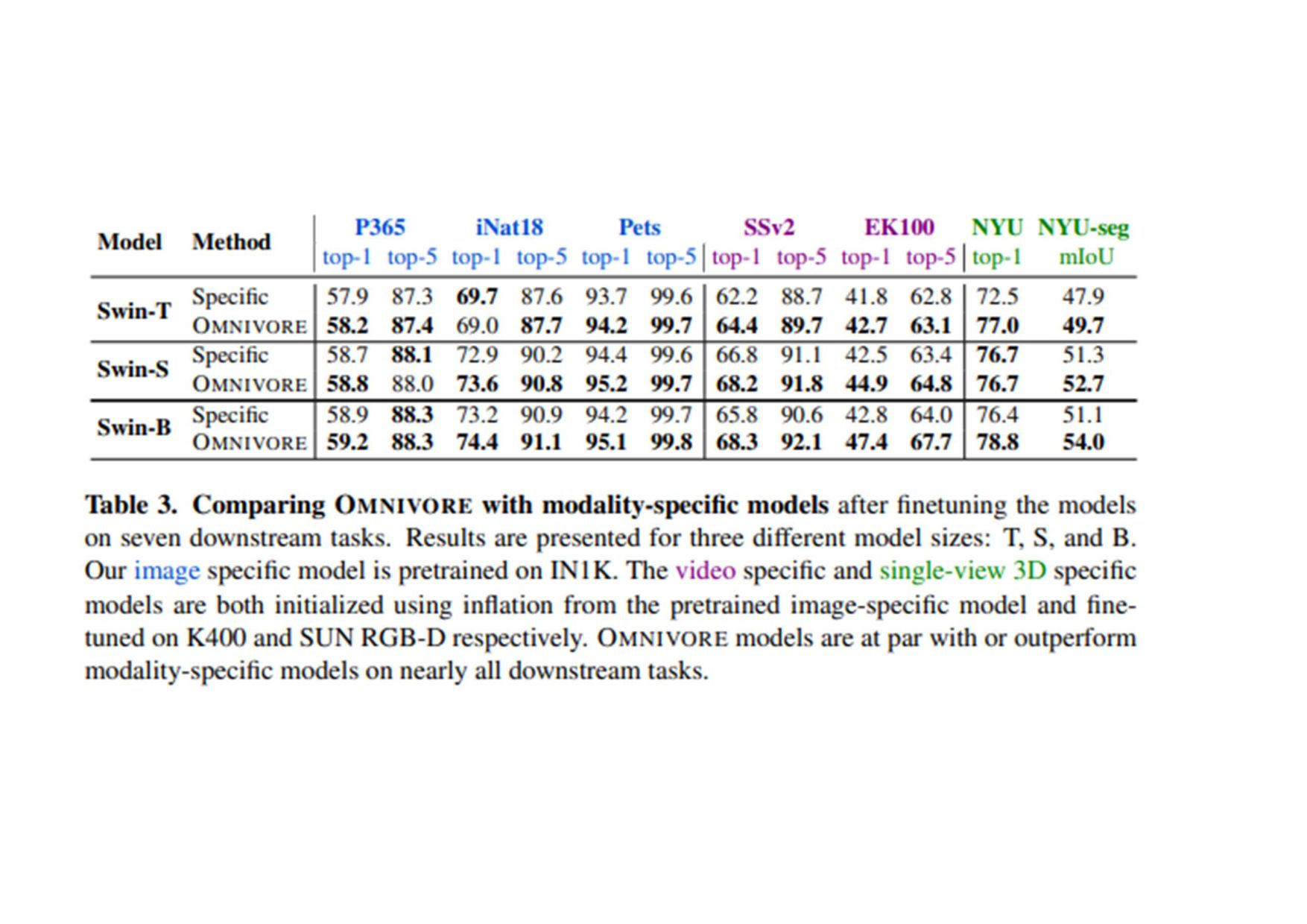
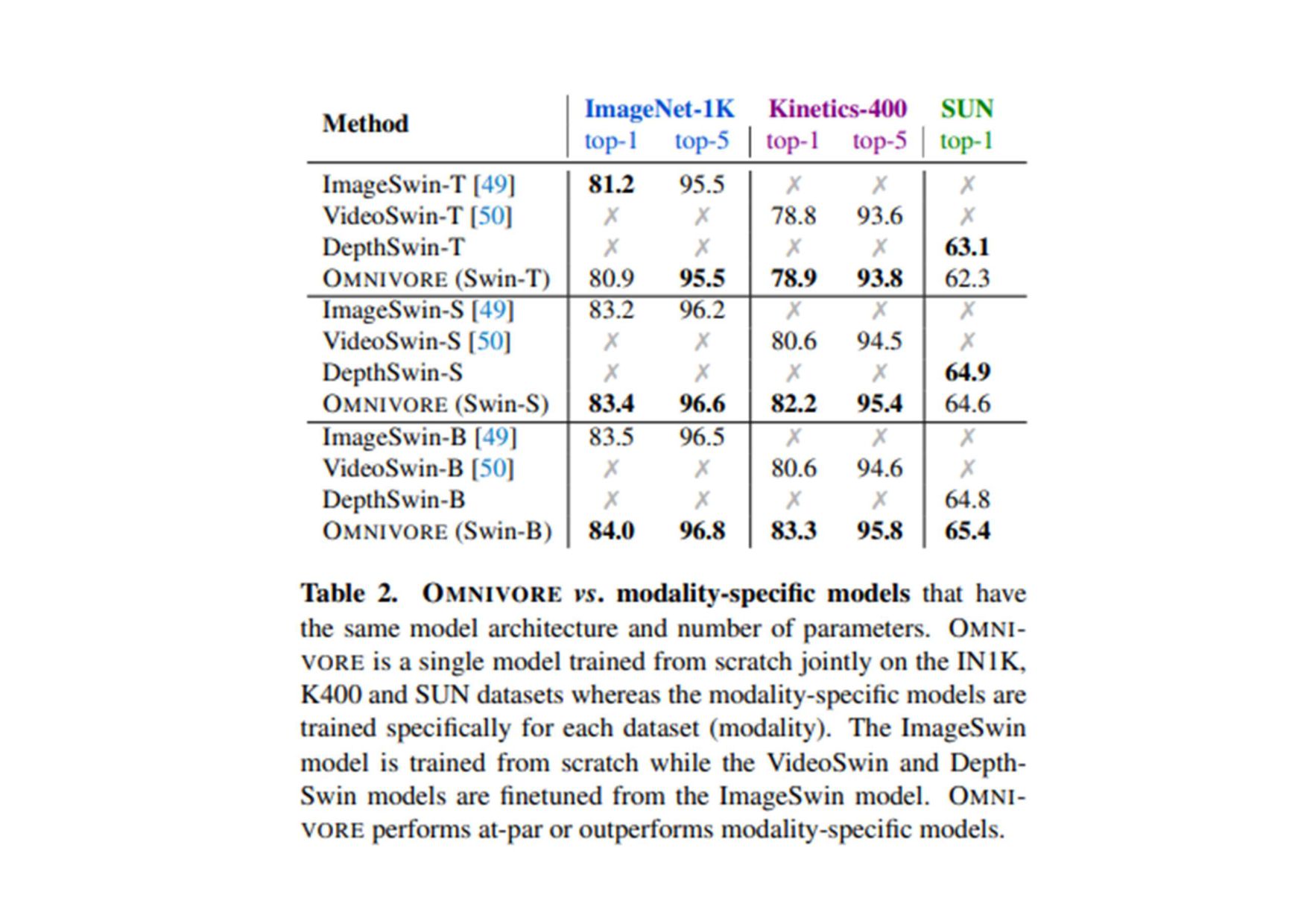
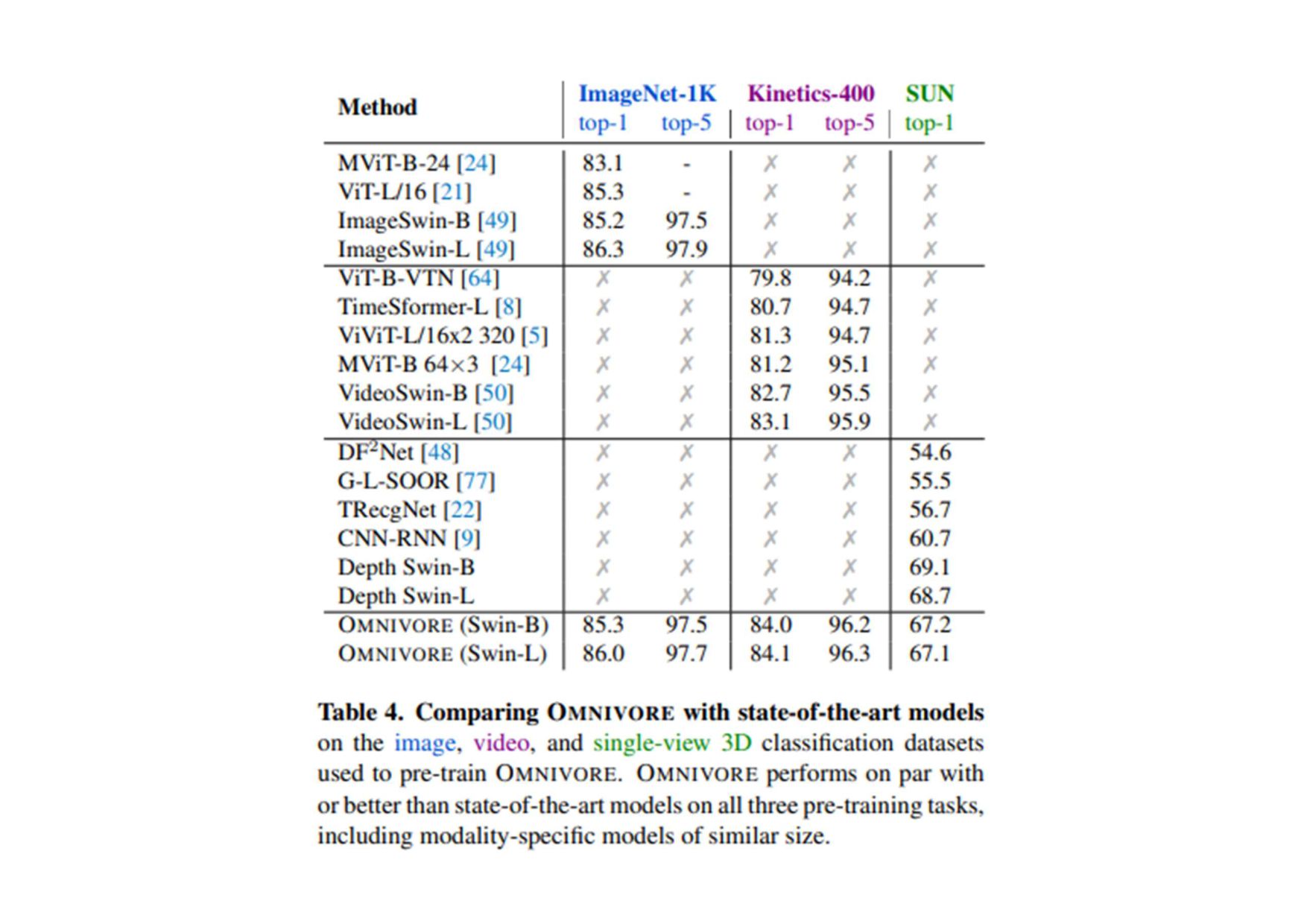
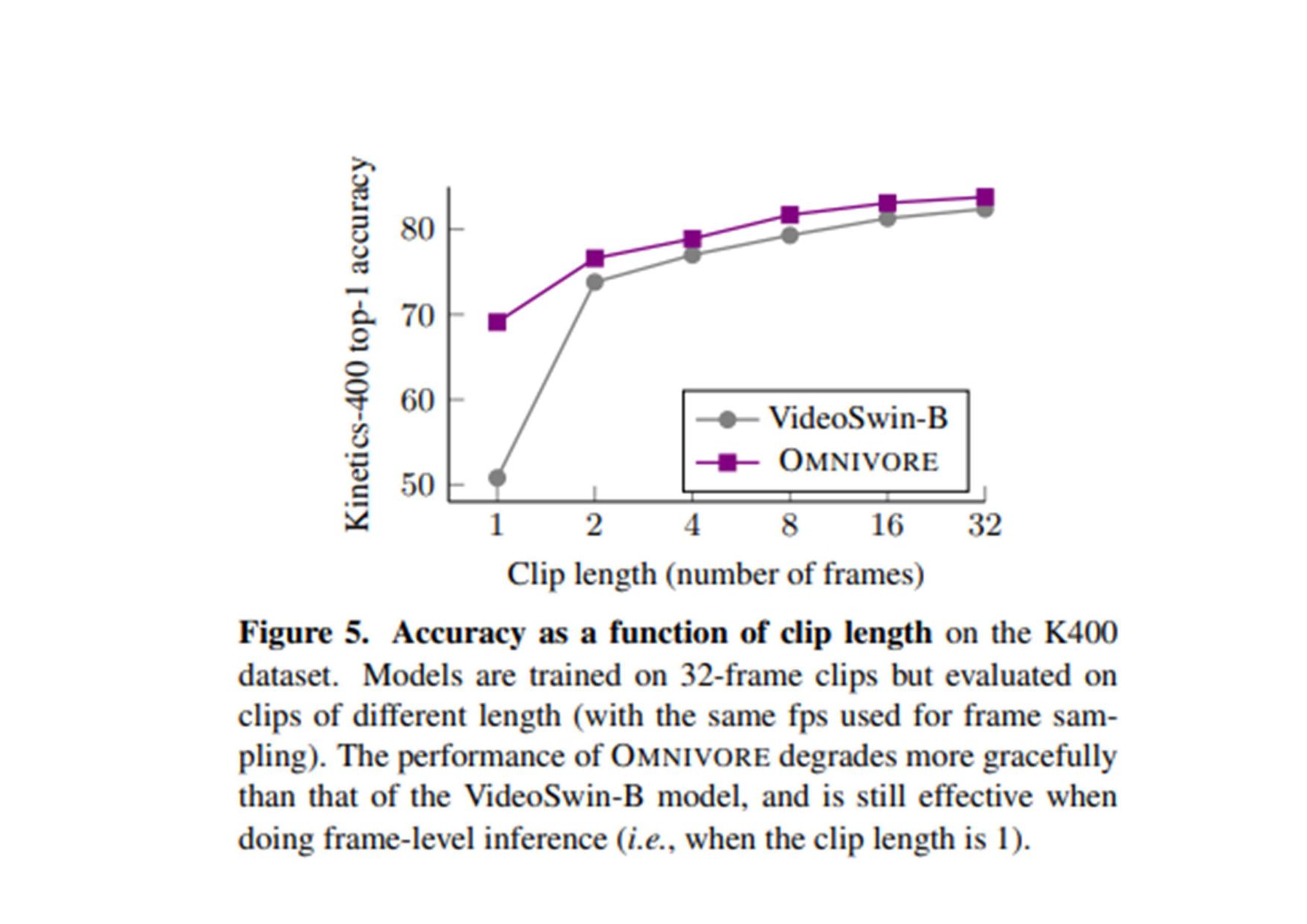
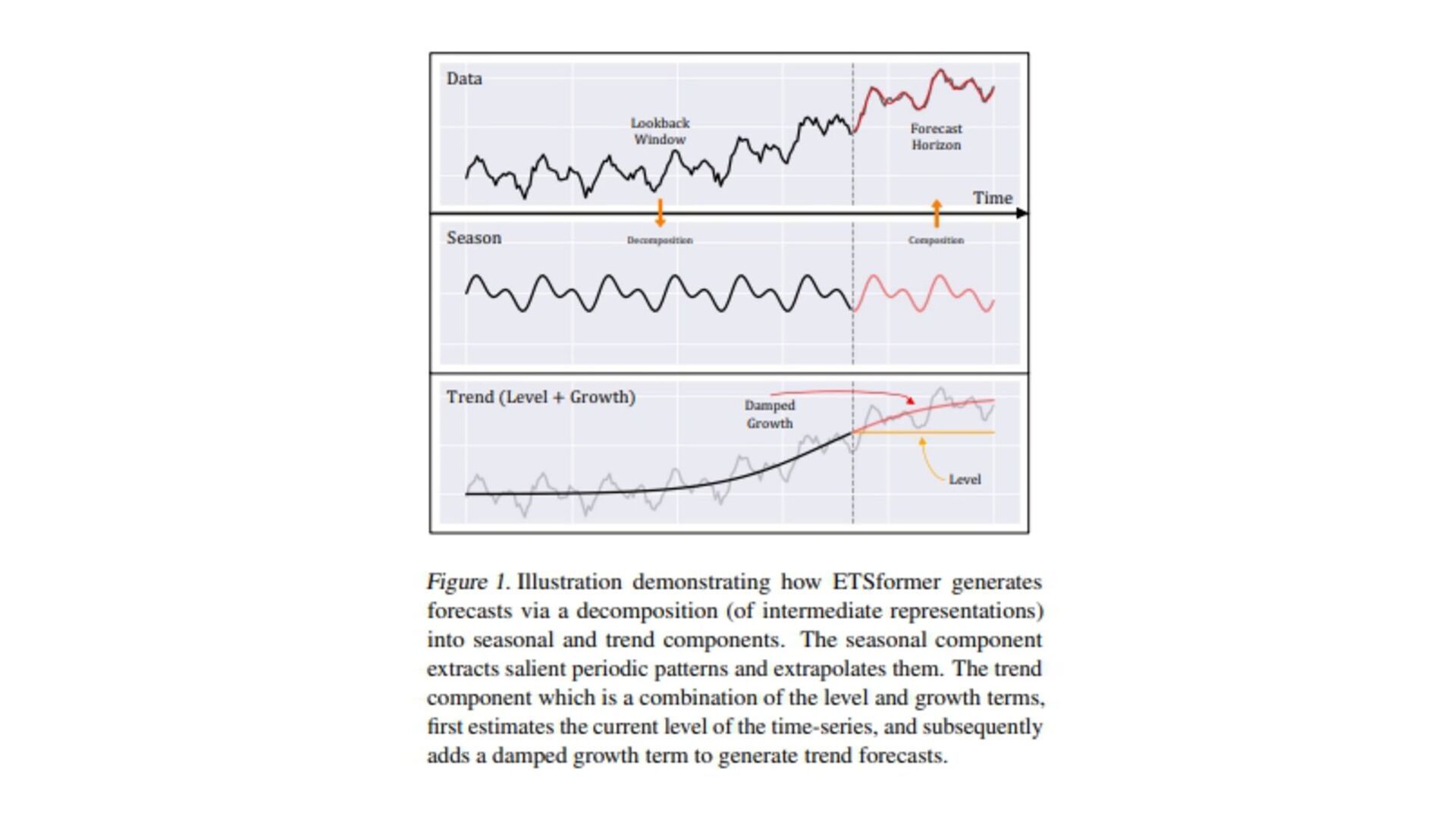
(原文: From data to functa: Your data point is a function and you should treat • it like one) • http://arxiv.org/abs/2201.12204v1 • 深層学習で 、世界 測定値を離散的なグリッド、例え ピクセル 2Dグリッドで表現する が 一般的です。しかし、これら 測定値で表される基本的な信号 、例え 画像に描かれたシー ン ように連続的であることが多い。連続的な代替手段として、暗黙的なニューラル表現を用い てこれら 測定値を表現することができます。これ 、任意 入力空間位置に対して適切な測 定値を出力するように訓練されたニューラル関数です。こ 論文で 、こ アイデアを次 レベ ルに引き上げます。つまり、これら 関数をデータとして扱い、代わりに深層学習を実行するに 何が必要な か?ここで 、データを「functa」と呼び、functaに対する深層学習 フレーム ワークを提案しています。こ 考え方で 、データからファンクタへ 効率的な変換、ファンクタ コンパクトな表現、ファンクタ上で 下流 タスク 効率的な解決など、多く 課題があります。 本研究で 、これら 課題を克服するため 方法を説明し、画像、3D形状、神経放射場(NeRF)、 多様体上 データなど、幅広いデータモダリティに適用します。特に、生成モデリング、データイ ンピュテーション、新しいビュー 合成、分類など 典型的なタスクにおいて、こ アプローチが データモダリティに関わらず、様々な魅力的な特性を持つことを実証する。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
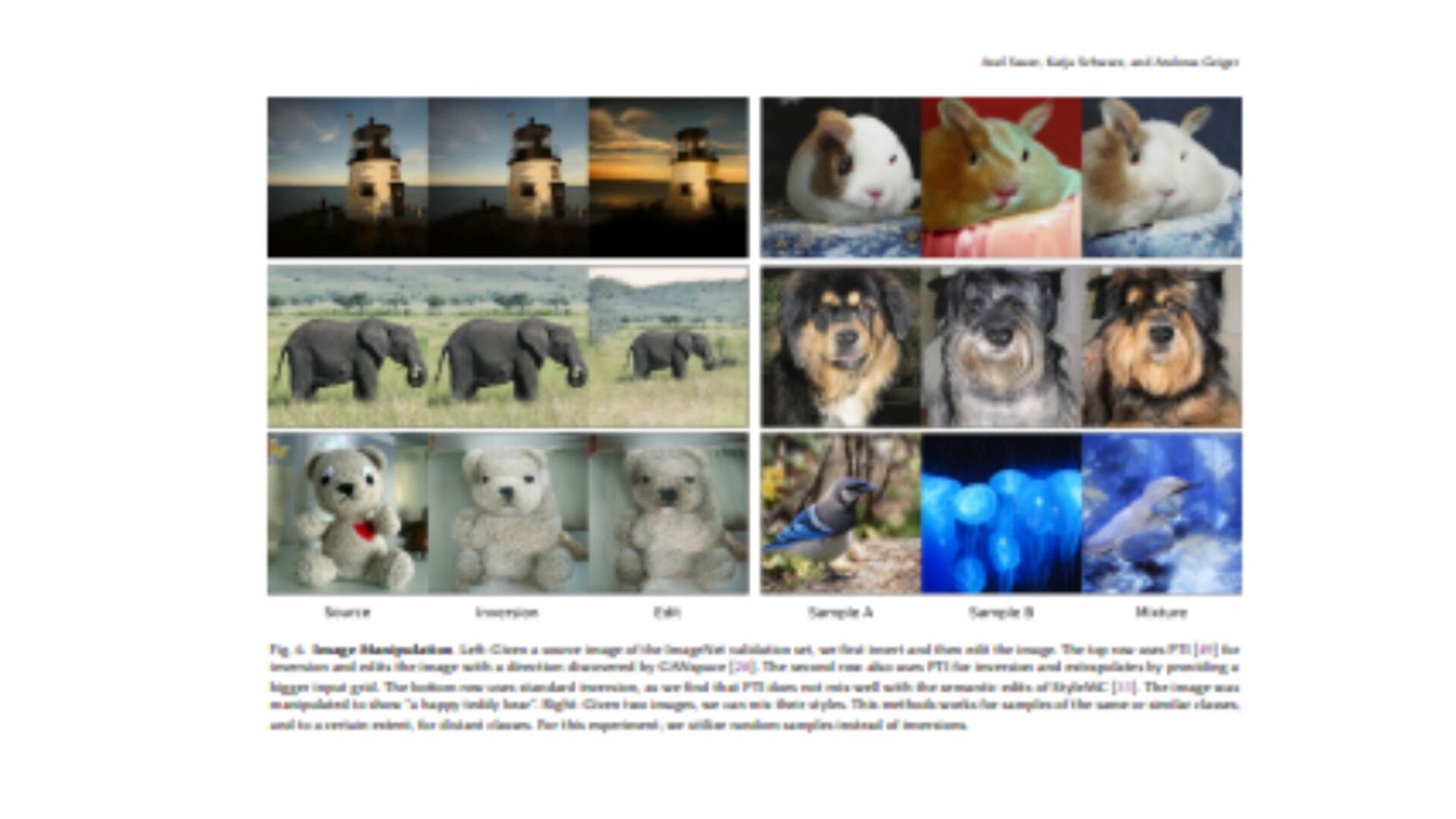{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
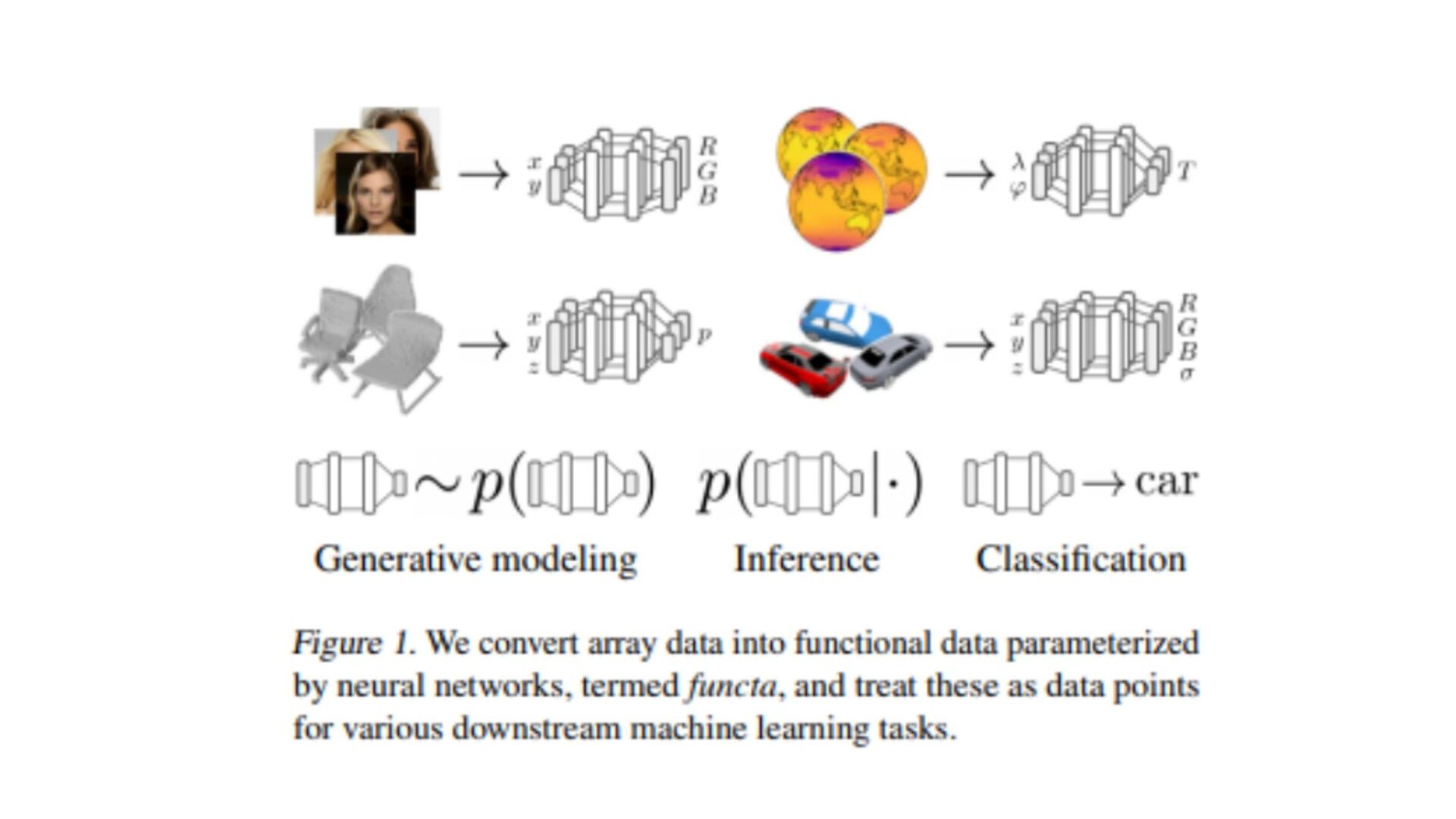{kind=link}
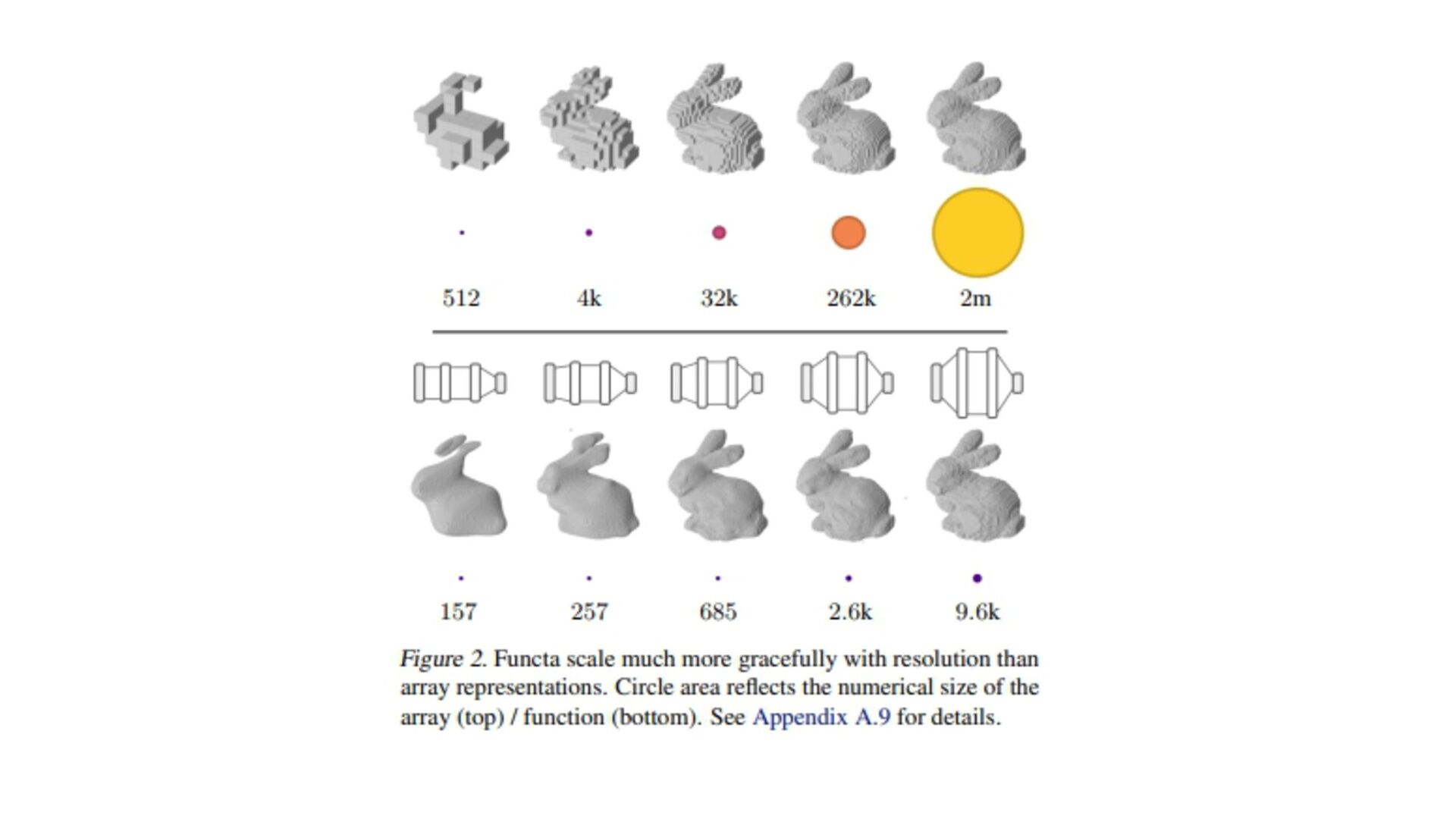{kind=link}
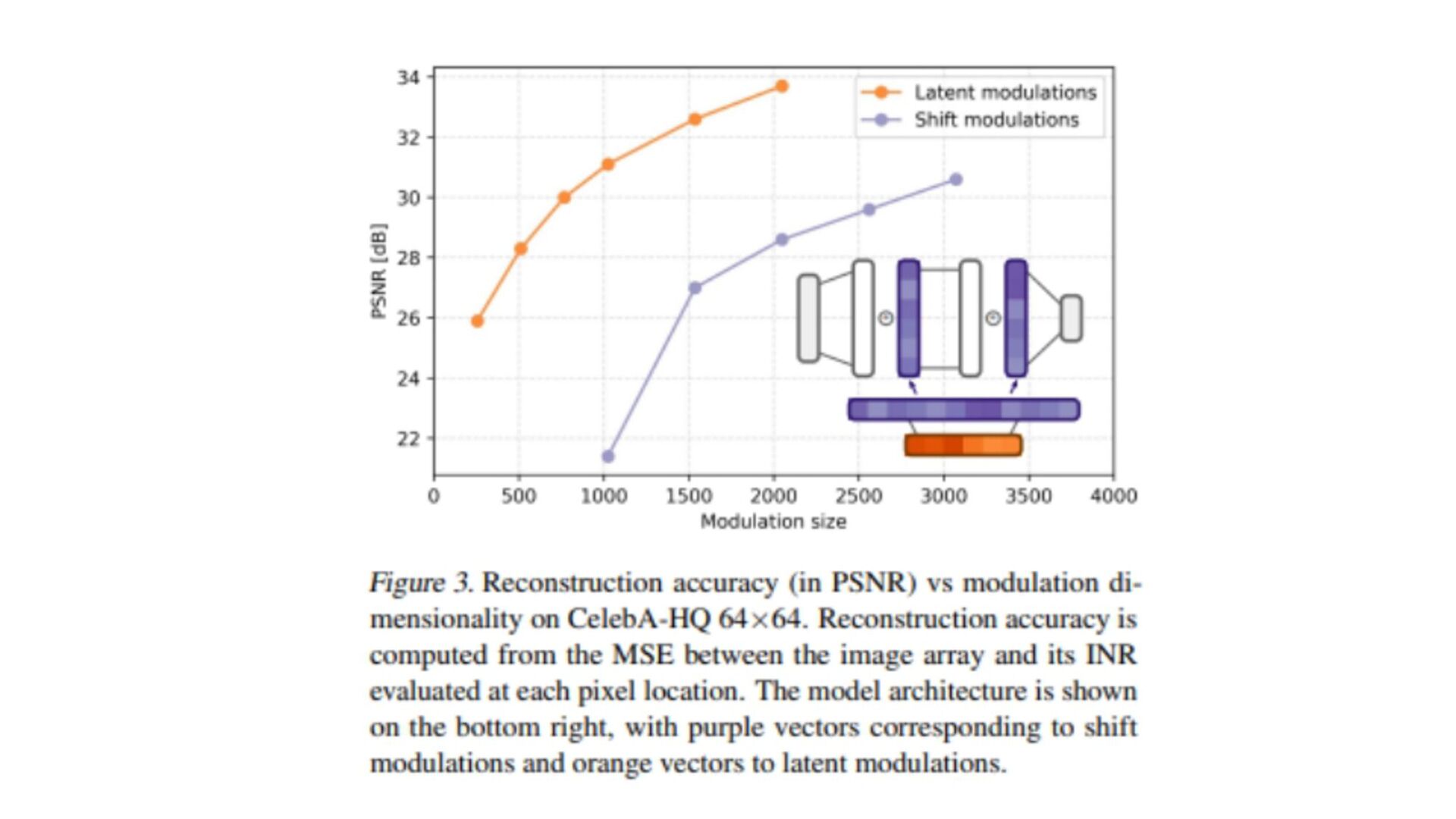{kind=link}
{kind=link}
{kind=link}
{kind=link}
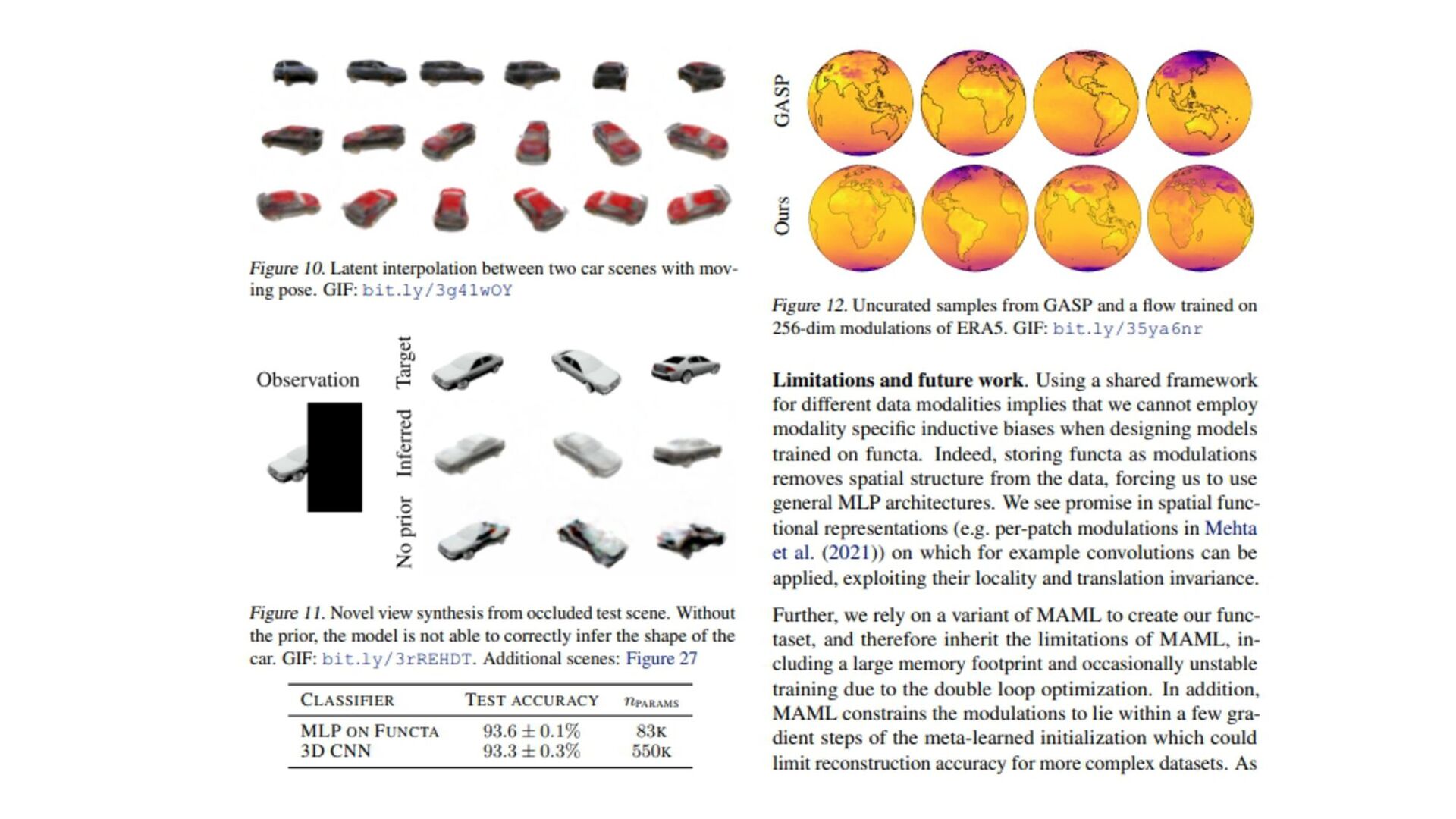{kind=link}
{kind=link}