100+ models • Some models over 1000 lines • Many models not managed in code Cron-based scheduling for execution dependencies • Executions are managed by fixed time offset
Team took on the responsibility to migrate this データプラットフォームチームで移行 検討を開始 • No lineage visibility リネージが見えない • No documentation ドキュメントなし • Execution has no model dependency awareness モデル 依存関係と実行が紐づいていない
ドキュメント化済み Limited documentation ドキュメント不足 Well shared business logic ロジック共有済み Tribal knowledge ロジック属人的 Schema/columns described スキーマ定義等あり No metadata メタデータなし The existing system contains many complex, person-dependent models built by few analysts 既存システム 少人数 データアナリストが多様な要件に対応する中で構築されたため、 属人性が高い複雑なモデルが多数あった
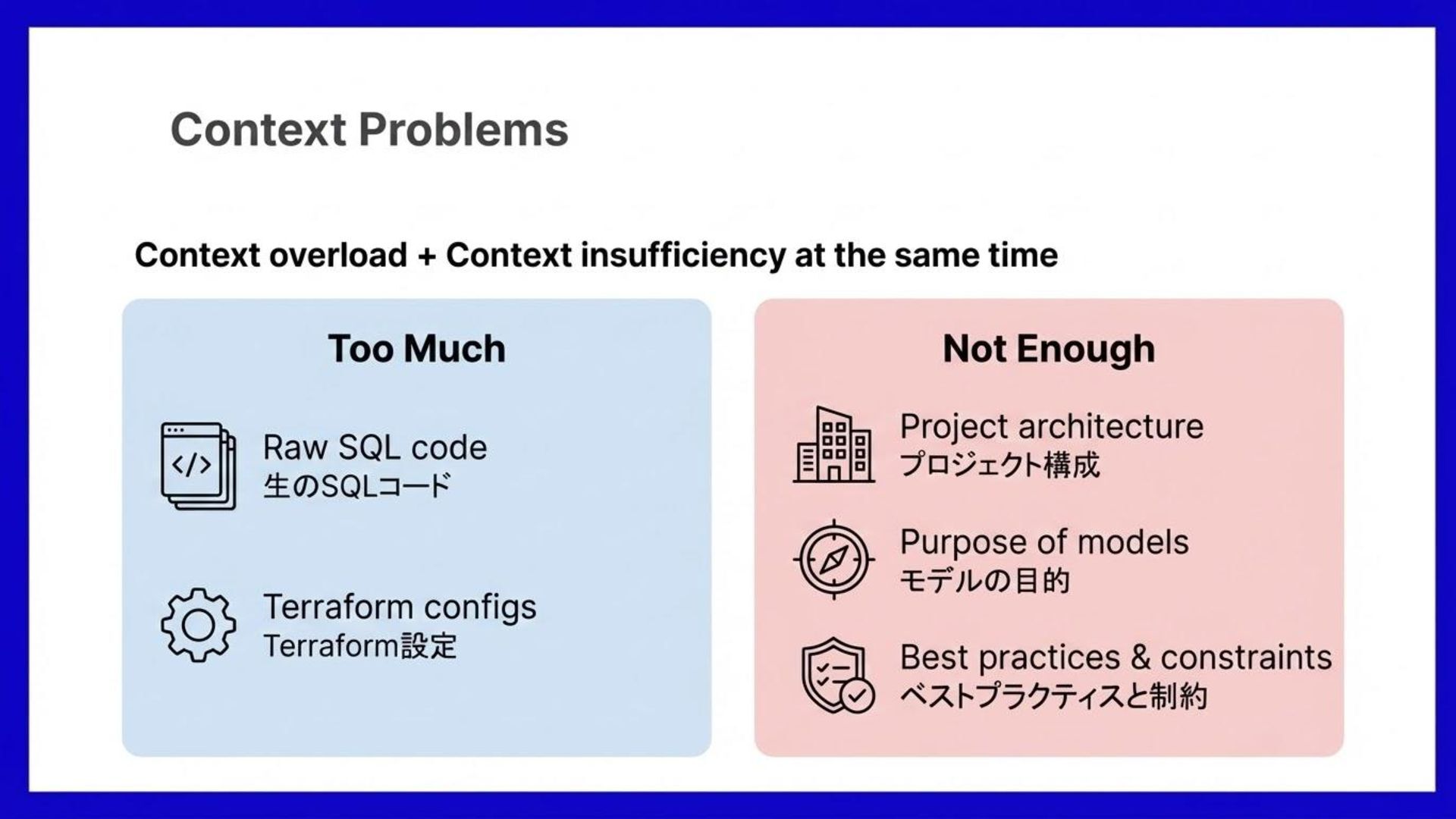
コンテキストにムラがあり、領域によって 大きすぎ No guardrail provided → AI just guessed • ガードレイルを設定しなかったため、AIが勝手に推測 "Just figure it out" approach → Results were inconsistent • 「なんとかして」で 結果に一貫性がなかった What went wrong?
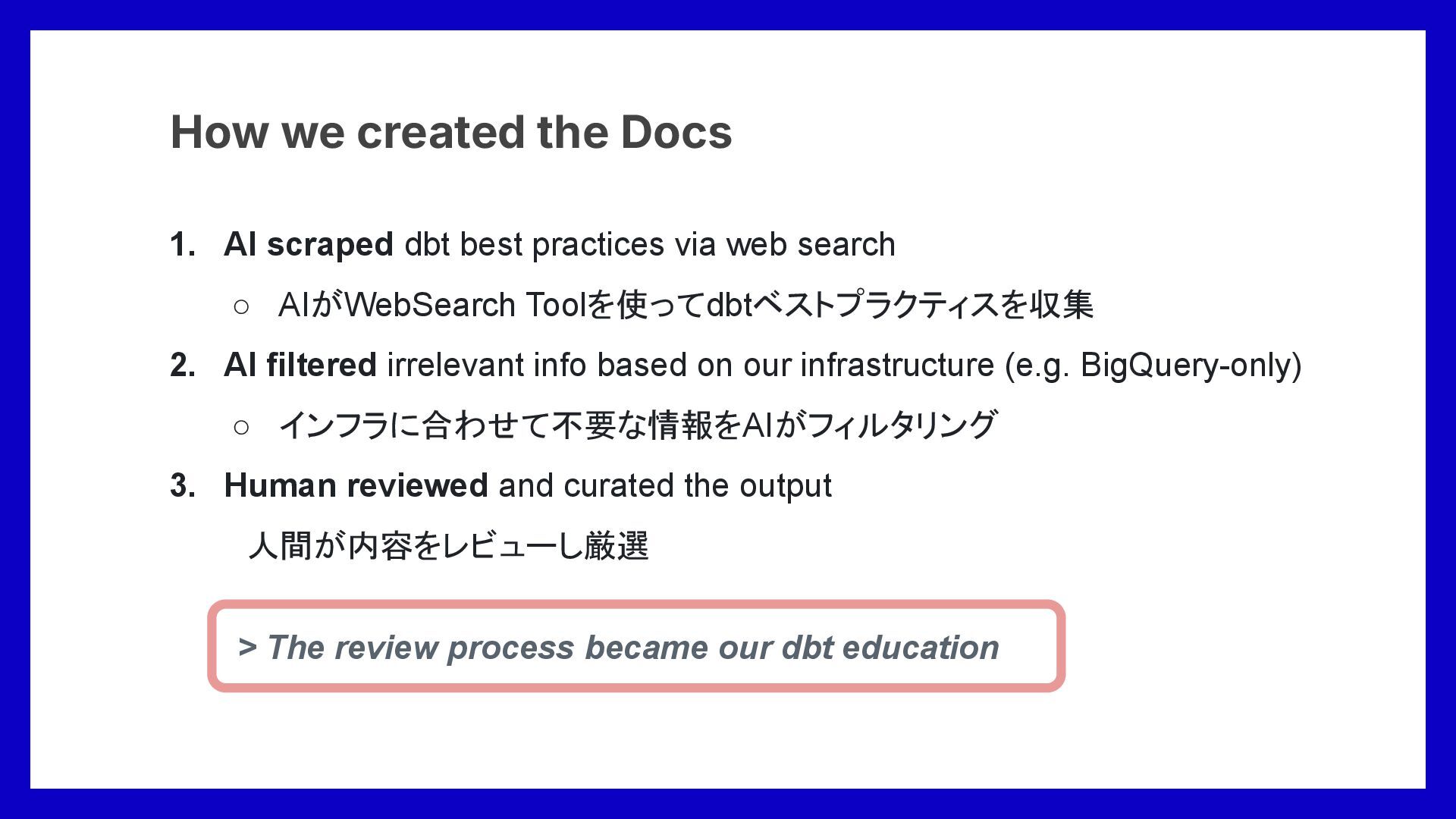
AIがWebSearch Toolを使ってdbtベストプラクティスを収集 2. AI filtered irrelevant info based on our infrastructure (e.g. BigQuery-only) ◦ インフラに合わせて不要な情報をAIがフィルタリング 3. Human reviewed and curated the output 人間が内容をレビューし厳選 How we created the Docs > The review process became our dbt education
2. Architecture Decision Records ◦ Design decisions documented / 設計 記録が残る 3. Developer Handbook ◦ Team learning resource / チーム 学習リソース 3 Purposes of the Docs / ドキュメント 3つ 役割 > AI becomes the coach, not just a code generator
一部を無視し始めた • "Read all" = AI interprets implicitly → inconsistent output ◦ 「全部読め」で AIが暗黙的に解釈し、出力に らつきが出る But this was not enough > Needed structure to guide AI to the right context for each task 最適なコンテキストを割り当てる構造が必要だった
hidden knowledge ◦ 暗黙的なコンテキストが引き出される 3. Prevents AI from going off track - reduces cost of mistake ◦ 手戻りコスト軽減 Human-in-the-Loop Design > Increase overall output predictability with human checkpoints 人間によるチェックポイントを設けることで全体 予測可能性を高める
(joined) ## Transformations - Aggregation: SUM(amount) GROUP BY date - Filter: WHERE status = 'completed' ## Dependencies - Upstream: sales, products - Schedule: Daily 18:00 JST Analysis output format
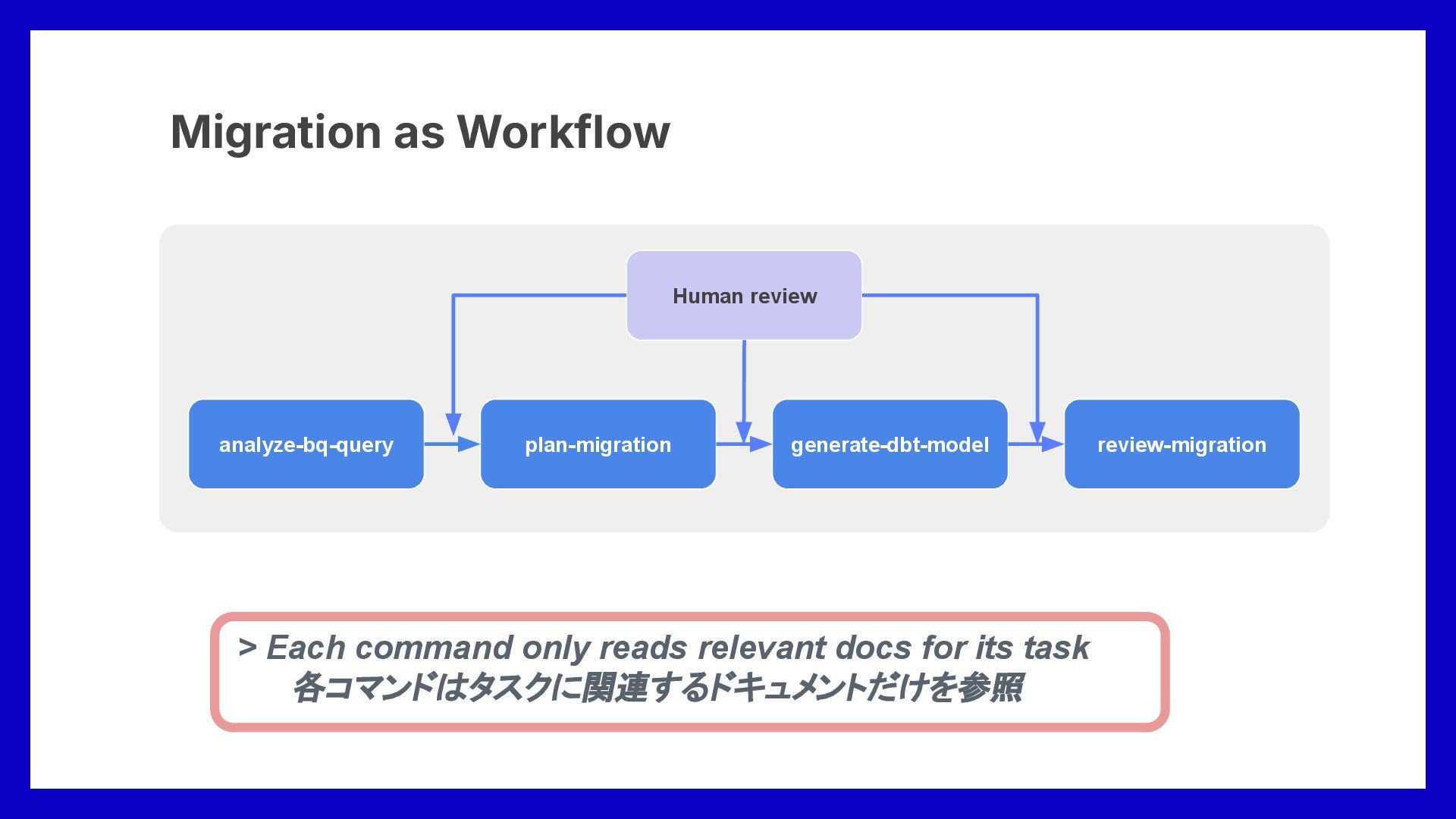
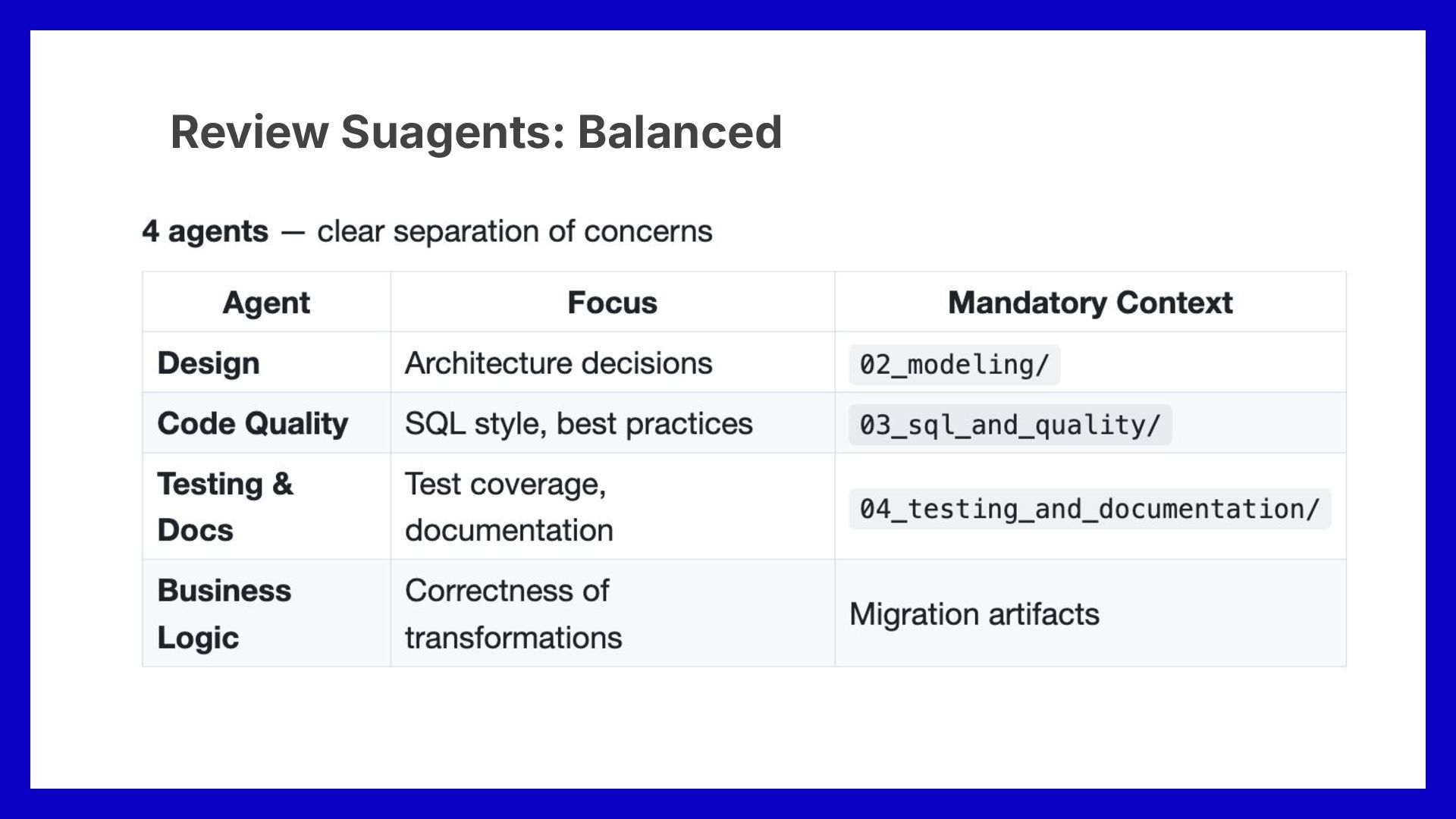
via separate commands for each workflow step 各ワークフロー工程ごとにコマンドを分割してコ ンテキストも分割 • Human reviews intermediate outputs 人間が中間成果物をレビュー Final output needs holistic review 最終成果物 全体的なレビューが必要 • Multiple aspects to check → context overload again 複数 観点をチェックする必要があり、再びコ ンテキスト過多になる • Sub-agents, each focused on one aspect 各観点専用 サブエージェントを導入
• Read through generated documents • Understand generated models • Deepen knowledge of dbt > Don’t just wait, go through documents while AI works 待ち時間も学習 / レビューに Utilize Wait Time / 待ち時間活用
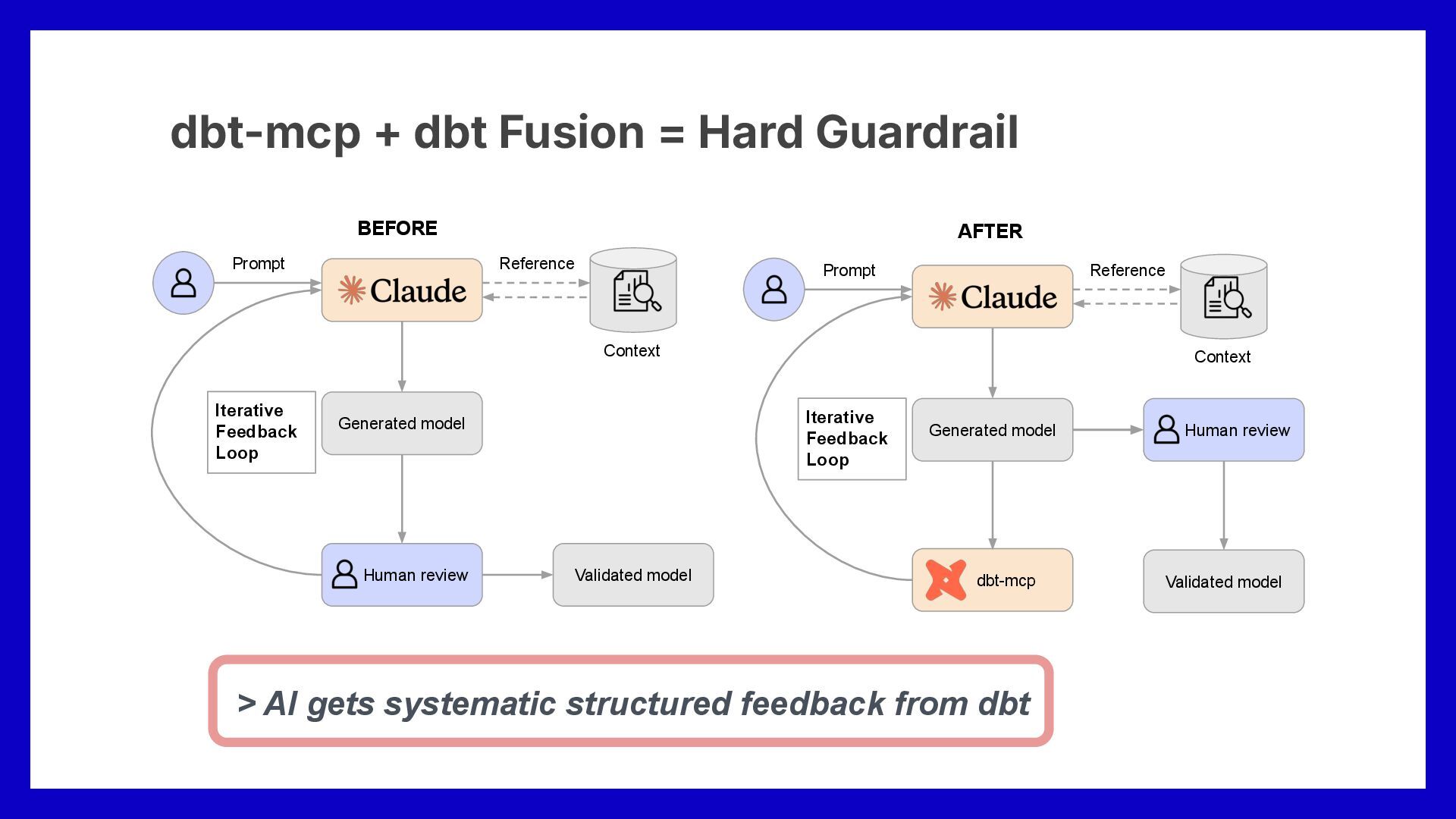
locally • dbt Core's parses Jinja/YAML only • dbt Fusion = full static SQL analysis without warehouse dbt-mcp + dbt Fusion > AI agents get structured feedback 構造化された情報が AI agentに渡される
before human even sees the output 人間が見る前にエラーをキャッチ • No need to run models to find out they don't work モデルを実行して動かないと気づく必要がない dbt-mcp + dbt Fusion = Hard Guardrail Generated model Human review Context Iterative Feedback Loop Prompt Reference Validated model dbt-mcp Generated model Context Iterative Feedback Loop Prompt Reference Validated model Human review > AI gets systematic structured feedback from dbt BEFORE AFTER
now dbt Fusion as quick guardrails is sufficient dbt Fusionで結構まかなえる • Will introduce in refactoring phase リファクタリングフェーズで導入すれ 良い Why not dbt_project_evaluator?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}