My talk from RE 2013. The abstract for the paper follows:
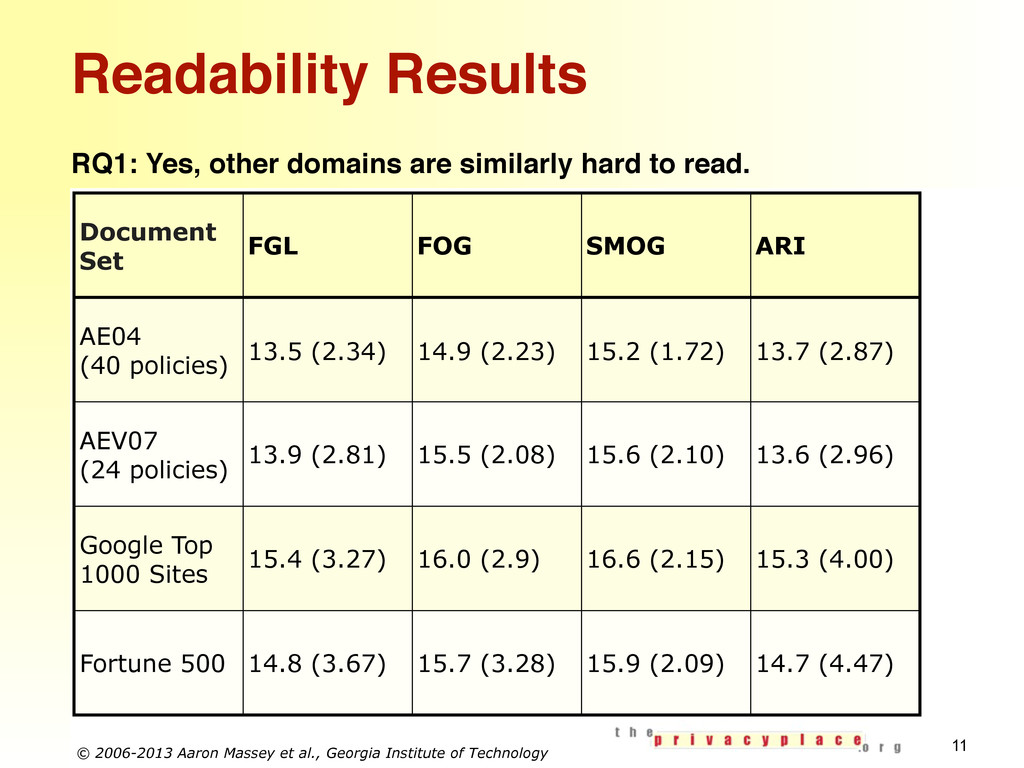
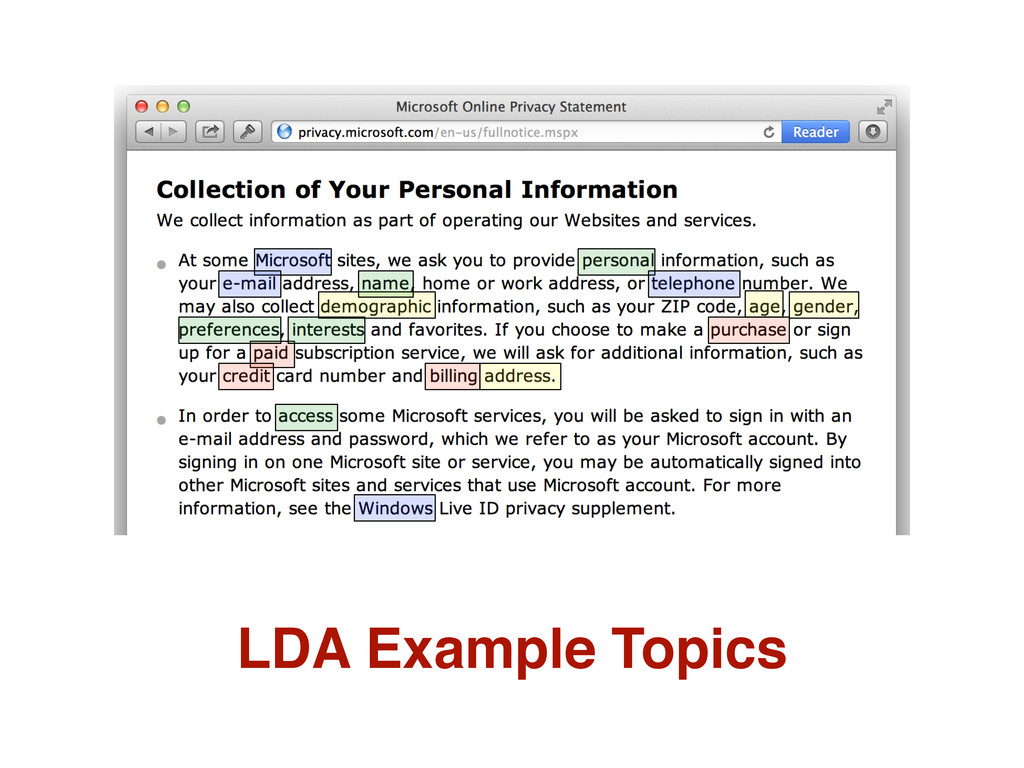
Businesses and organizations in jurisdictions around the world are required by law to provide their customers and users with information about their business practices in the form of policy documents. Requirements engineers analyze these documents as sources of requirements, but this analysis is a time-consuming and mostly manual process. Moreover, policy documents contain legalese and present readability challenges to requirements engineers seeking to analyze them. In this paper, we perform a large-scale analysis of 2,061 policy documents, including policy documents from the Google Top 1000 most visited websites and the Fortune 500 companies, for three purposes: (1) to assess the readability of these policy documents for requirements engineers; (2) to determine if automated text mining can indicate whether a policy document contains require- ments expressed as either privacy protections or vulnerabilities; and (3) to establish the generalizability of prior work in the identification of privacy protections and vulnerabilities from privacy policies to other policy documents. Our results suggest that this requirements analysis technique, developed on a small set of policy documents in two domains, may generalize to other domains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}