contains “forward-looking information”, including “future oriented financial information” and “financial outlook”, under applicable securities laws (collectively referred to herein as forward-looking statements). Except for statements of historical fact, information contained herein constitutes forward-looking statements and includes, but is not limited to, the (i) projected financial performance of the Company; (ii) completion of, and the use of proceeds from, the sale of the shares being offered hereunder; (iii) the expected development of the Company’s business, projects and joint ventures; (iv) execution of the Company’s vision and growth strategy, including with respect to future M&A activity and global growth; (v) sources and availability of third-party financing for the Company’s projects; (vi) completion of the Company’s projects that are currently underway, in development or otherwise under consideration; (vi) renewal of the Company’s current customer, supplier and other material agreements; and (vii) future liquidity, working capital, and capital requirements. Forward-looking statements are provided to allow potential investors the opportunity to understand management’s beliefs and opinions in respect of the future so that they may use such beliefs and opinions as one factor in evaluating an investment. These statements are not guarantees of future performance and undue reliance should not be placed on them. Such forward-looking statements necessarily involve known and unknown risks and uncertainties, which may cause actual performance and financial results in future periods to differ materially from any projections of future performance or result expressed or implied by such forward-looking statements. Although forward-looking statements contained in this presentation are based upon what management of the Company believes are reasonable assumptions, there can be no assurance that forward-looking statements will prove to be accurate, as actual results and future events could differ materially from those anticipated in such statements. The Company undertakes no obligation to update forward-looking statements if circumstances or management’s estimates or opinions should change except as required by applicable securities laws. The reader is cautioned not to place undue reliance on forward-looking statements.
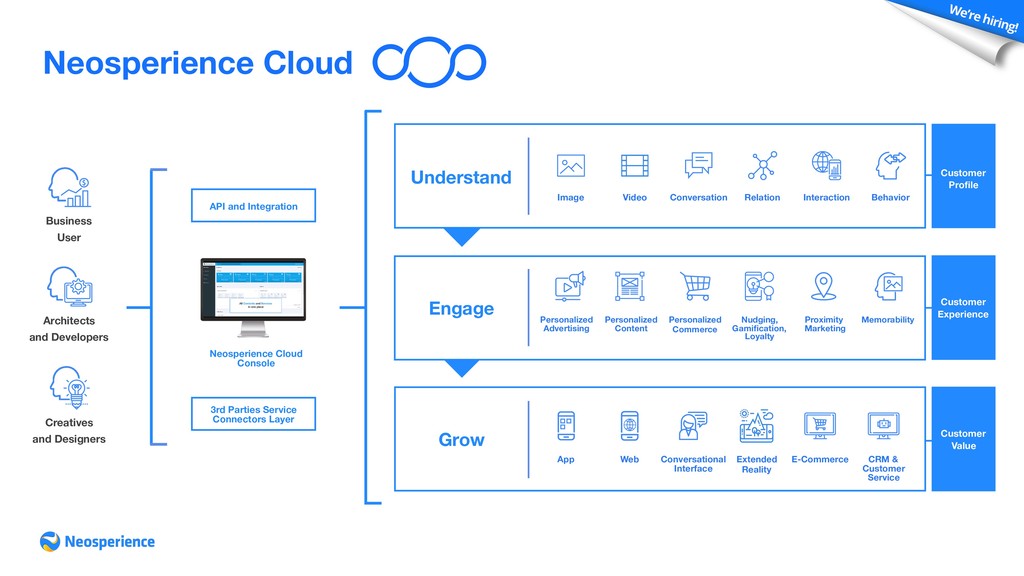
the relationship with the customer across touchpoints: web, app, platforms, point of sale How Neosperience Cloud delivers digital experience innovation The first digital experience platform to establish empathic relationships with customers that takes into account their uniqueness. A set of application modules condensing multi-disciplinary skills: data scientists, designers, software architects, cognitive, behavioral and social psychologists, to unleash your brand’s potential. Increase customer engagement • Tailor storytelling and call-to-action • Grow the value of the customer • Suggest the most suitable products and services • Accelerate on-boarding and increase conversions • Generate recurring revenues, evolving loyalty into membership • Send personalized notifications • Delight the customer with gamification • Make digital experiences come alive in extended reality • Nudge advocacy 01 Understand Listen to customers across channels 02 Engage Deliver relevant experiences at scale 03 Grow Transform prospects into customers for life
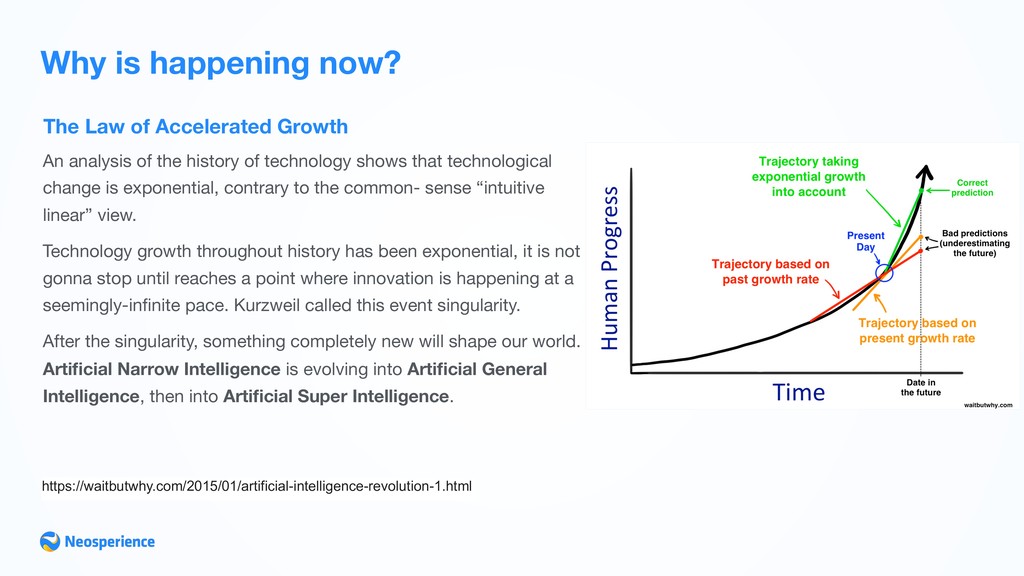
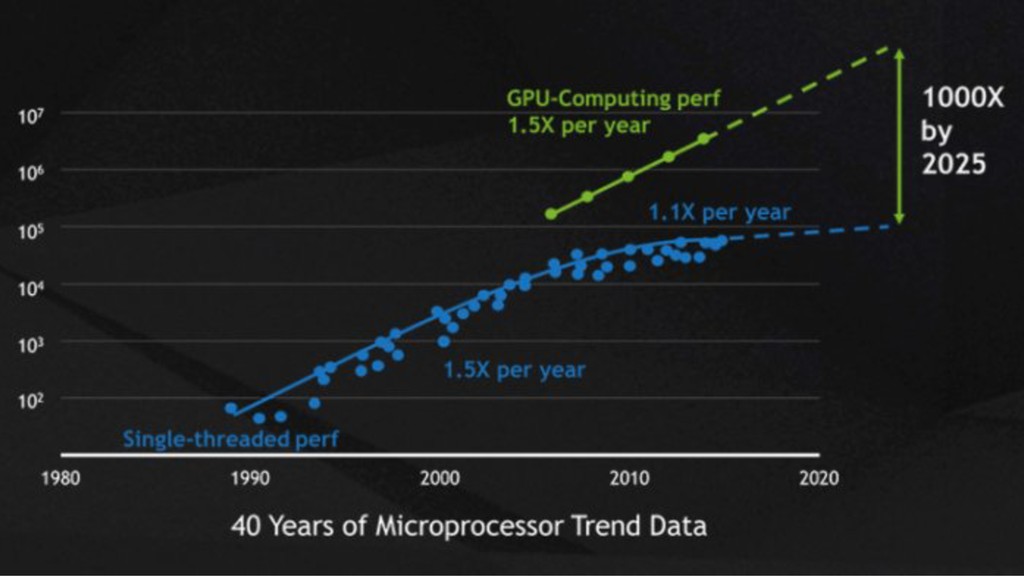
analysis of the history of technology shows that technological change is exponential, contrary to the common- sense “intuitive linear” view. Technology growth throughout history has been exponential, it is not gonna stop until reaches a point where innovation is happening at a seemingly-infinite pace. Kurzweil called this event singularity. After the singularity, something completely new will shape our world. Artificial Narrow Intelligence is evolving into Artificial General Intelligence, then into Artificial Super Intelligence. https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
An AGI would be to fix our world, since many illness can be thought as an Artificial Intelligence problem. Computational biology is fast moving towards self-learning medications, and these are just the beginning of adoption of nano-machines.
with the right inputs and outputs would thereby have a mind in exactly the same sense human beings have minds. Artificial Super Intelligence (ASI) An AGI capable of outsmarting human brains, performing thinking and learning tasks at unprecedented pace. Artificial Narrow Intelligence (ANI) Artificial Intelligence constrained to a narrow task. (Siri, Google Search, Google Car, ESB, etc.).
- our brain - much more powerful than actual HPC servers and is capable of switching between many different “algorithms” to understand reality, each one of them is context- independent. • Filling gaps in Existing Knowledge • Understand and apply Knowledge • Semantically reduce uncertainty • Notice similarity between old/new The most powerful capability of our brain and the common denominator of all these features is the capability humans to learn from experience. Learning is the key.
Rodney Brooks authored a paper entitled Elephants Don’t Play Chess – a ground breaking concept that ushered in an alternative view of Artificial Intelligence. Twenty five years later, he is addressing the misconceptions that now surround AI, allaying the media- fueled fears of robots with evil intentions. Hear him in his own words talk about AI, and how Baxter and Sawyer have common sense – the ability to complete tasks, not just motions. Defining what we mean with “intelligence” is fundamental to set a line to be reached by machines to be considered intelligent. https://youtu.be/bKA6d8u1FKg
to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.”
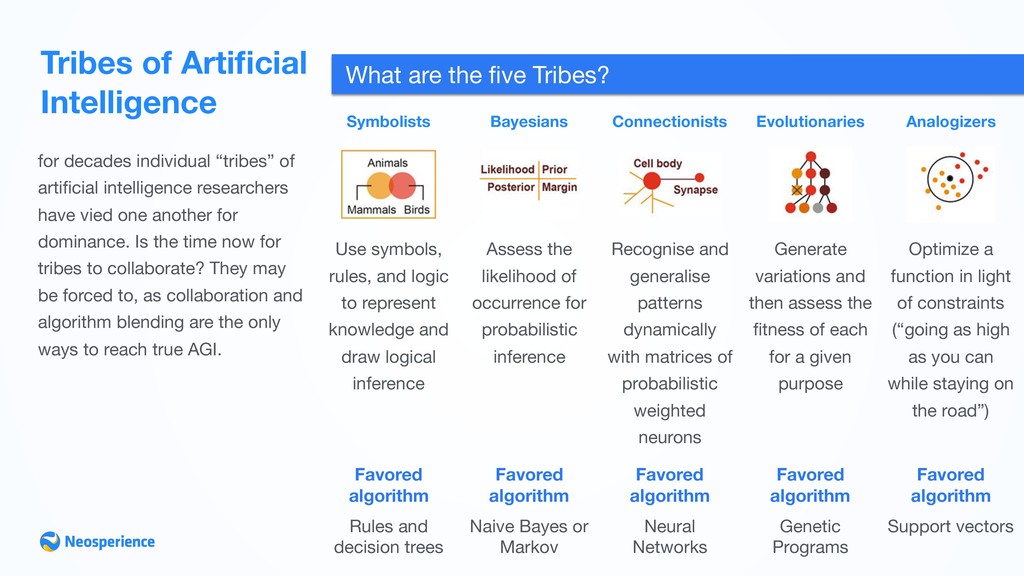
intelligence researchers have vied one another for dominance. Is the time now for tribes to collaborate? They may be forced to, as collaboration and algorithm blending are the only ways to reach true AGI. What are the five Tribes? Symbolists Use symbols, rules, and logic to represent knowledge and draw logical inference Favored algorithm Rules and decision trees Bayesians Assess the likelihood of occurrence for probabilistic inference Favored algorithm Naive Bayes or Markov Connectionists Recognise and generalise patterns dynamically with matrices of probabilistic weighted neurons Favored algorithm Neural Networks Evolutionaries Generate variations and then assess the fitness of each for a given purpose Favored algorithm Genetic Programs Analogizers Optimize a function in light of constraints (“going as high as you can while staying on the road”) Favored algorithm Support vectors
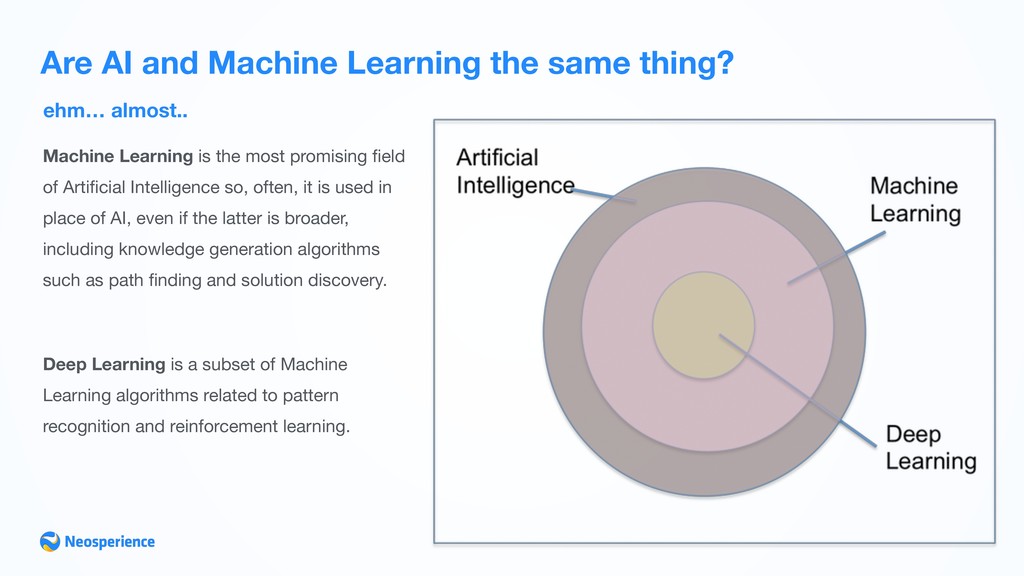
Machine Learning is the most promising field of Artificial Intelligence so, often, it is used in place of AI, even if the latter is broader, including knowledge generation algorithms such as path finding and solution discovery. Deep Learning is a subset of Machine Learning algorithms related to pattern recognition and reinforcement learning.
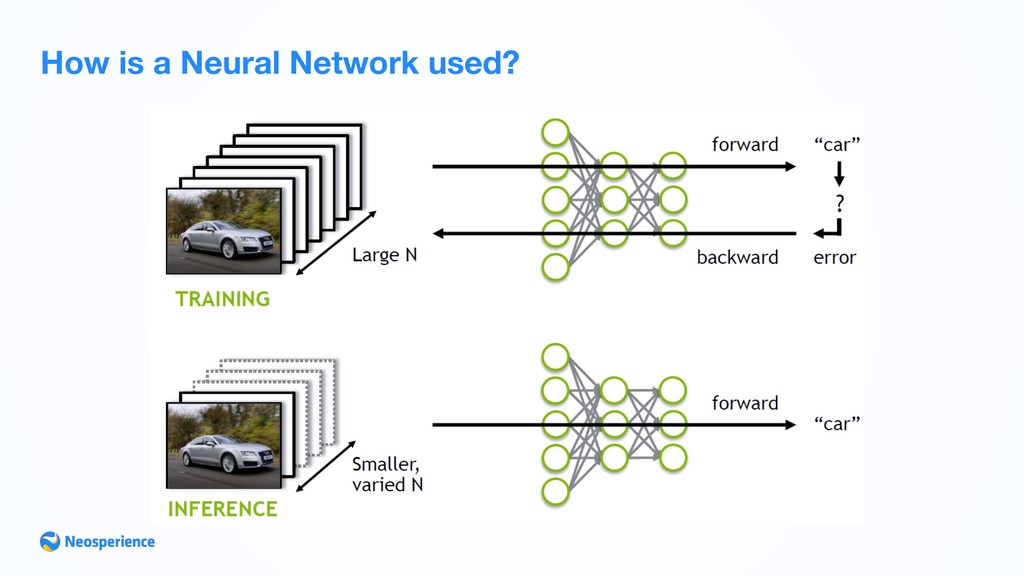
algorithms have data as input, ‘cause data represents the Experience. This is a focal point of Machine Learning: large amount of data is needed to achieve good performances. • The Machine Learning equivalent of program in ML world is called ML model and improves over time as soon as more data is provided, with a process called training. • Data must be prepared (or filtered) to be suitable for training process. Generally input data must be collapsed into a n-dimensional array with every item representing a sample. • ML performances are measured in probabilistic terms, with metrics called accuracy or precision. An operational definition “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E”
Unsupervised Learning • Reinforcement Learning Types of Machine Learning Machine learning tasks are typically classified into three broad categories, depending on the nature of the learning "signal" or "feedback" available to a learning system. Output-based taxonomy • Regression • Classification • Clustering • Density estimation • Dimensionality reduction
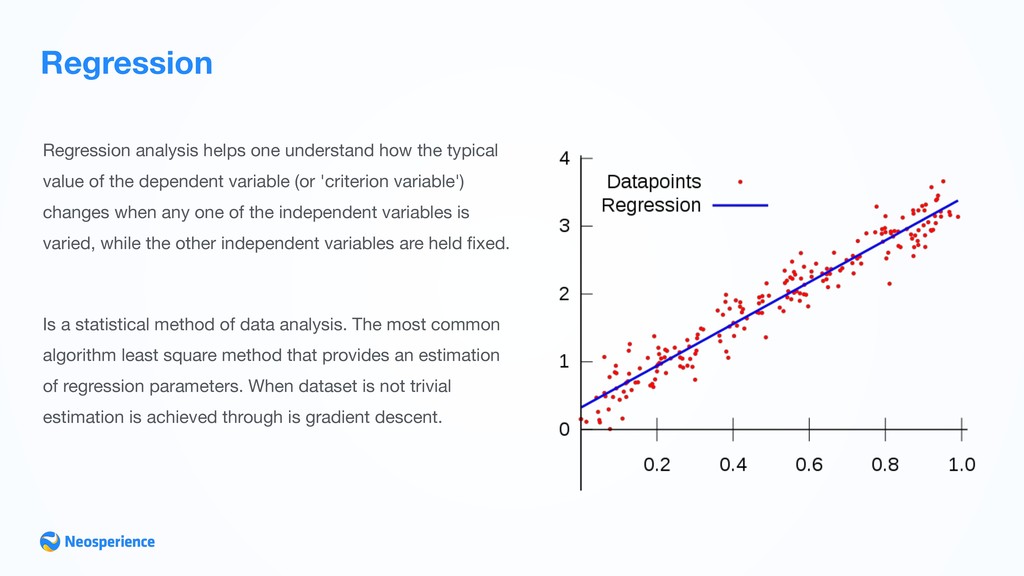
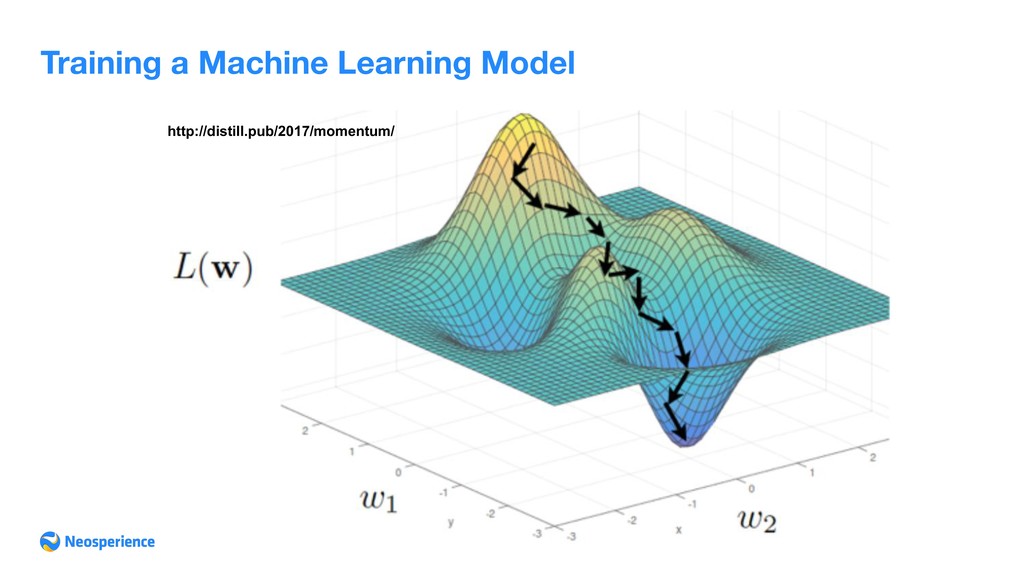
of the dependent variable (or 'criterion variable') changes when any one of the independent variables is varied, while the other independent variables are held fixed. Is a statistical method of data analysis. The most common algorithm least square method that provides an estimation of regression parameters. When dataset is not trivial estimation is achieved through is gradient descent.
Price Estimation •Age estimation •Customer satisfaction rate defining variables such as response-time, resolution-ration we can forecast satisfaction level or churn •Customer Conversion rate estimation (based on click data, origin, timestamp, ...) Statistical regression is used to make predictions about data, filling the gaps Regression, even in the most simple form of Linear Regression is a good tool to learn from data and make predictions based on data trend.
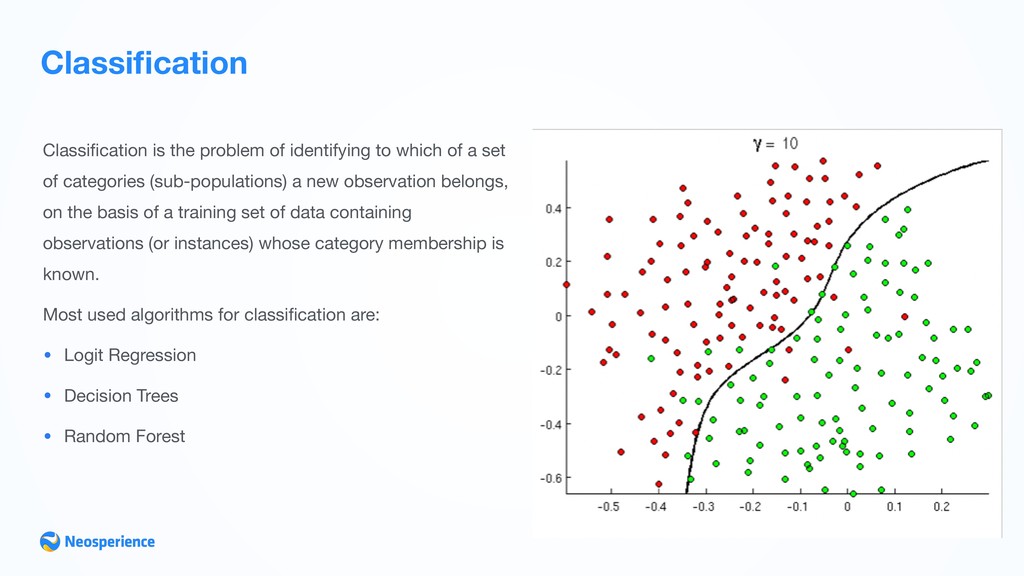
a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known. Most used algorithms for classification are: • Logit Regression • Decision Trees • Random Forest
Recognition •Spam/Not Spam classification •Customer conversion prediction •Customer churn prediction •Customer personas classification Classification is used to detect the binary outcome of a variable Classification is often used to classify people into pre-defined clusters (good-payer/bad-payer, in/out target, etc.)
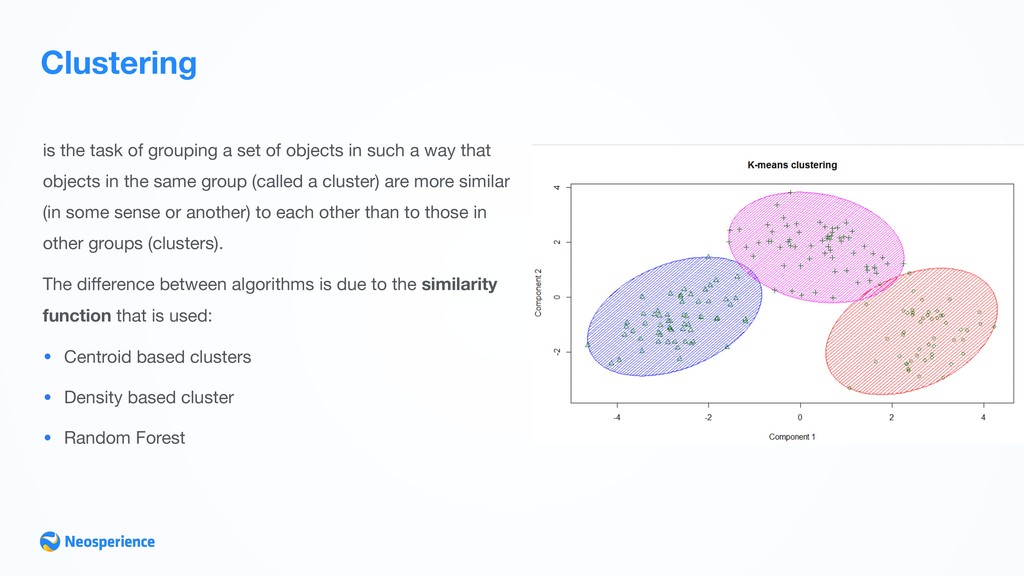
in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters). The difference between algorithms is due to the similarity function that is used: • Centroid based clusters • Density based cluster • Random Forest
detection •Similarity analysis •Customer base segmentation Clustering is used to segment data Clustering labels each sample with a name representing its belonging cluster. Labelling can be exclusive or multiple. Clusters are dynamic structures: they adapt to new sample coming into the model as soon as thy label them.
Learning (DL) is based on non-linear structures that process information. The “deep” in name comes from the contrast with “traditional” ML algorithms that usually use only one layer. What is a layer? • A cost-function receiving data as input and outputting its function weights. • More complex is the data you want to learn from, more layers are usually needed to learn from. The number of layers is called depth of the DL algorithm. An operational definition “A class of machine learning techniques that exploit many layers of non-linear information processing for supervised or unsupervised feature extraction and transforma- tion, and for pattern analysis and classification.”
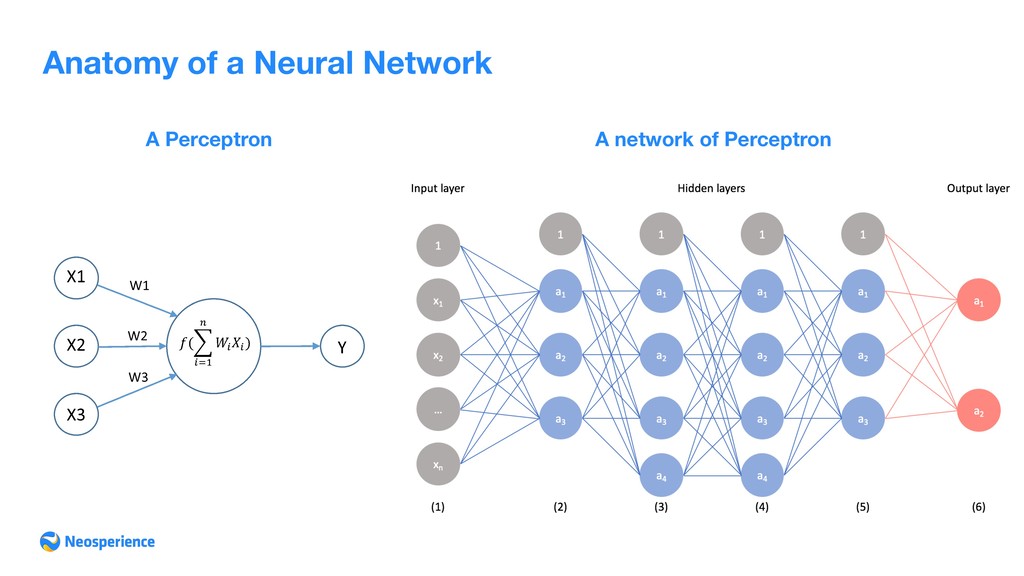
the biological neural networks that constitute animal brains. Such systems learn (progressively improve performance) to do tasks by considering examples, generally without task-specific programming” An ANN is based on a collection of connected units called artificial neurons, (analogous to axons in a biological brain). Each connection (synapse) between neurons can transmit a signal to another neuron. The receiving (postsynaptic) neuron can process the signal(s) and then signal downstream neurons connected to it. Neurons may have state, generally represented by real numbers, typically between 0 and 1. Neurons and synapses may also have a weight that varies as learning proceeds, which can increase or decrease the strength of the signal that it sends downstream. Further, they may have a threshold such that only if the aggregate signal is below (or above) that level is the downstream signal sent. Typically, neurons are organized in layers. Different layers may perform different kinds of transformations on their inputs. Signals travel from the first (input), to the last (output) layer, possibly after traversing the layers multiple times.
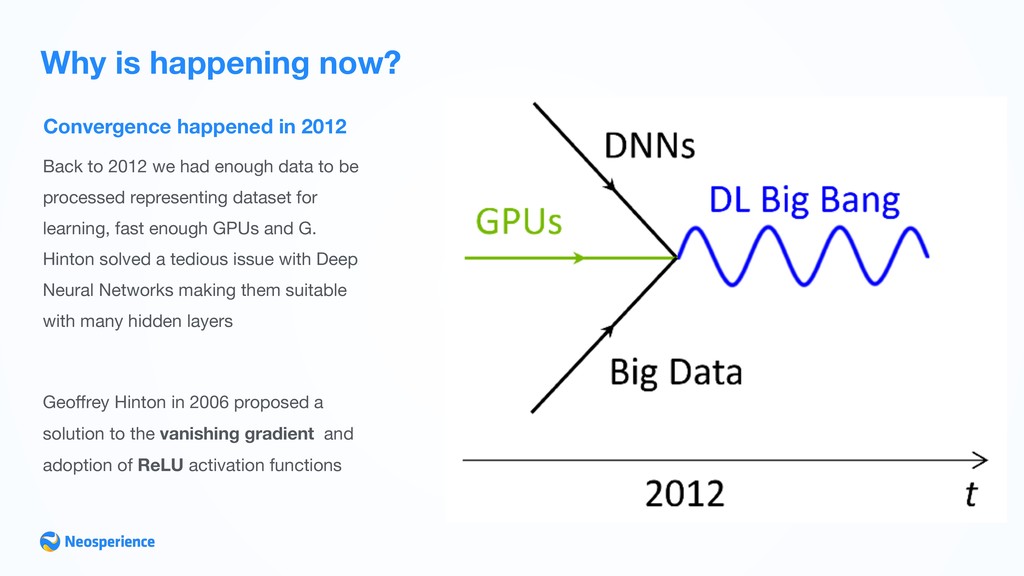
2012 we had enough data to be processed representing dataset for learning, fast enough GPUs and G. Hinton solved a tedious issue with Deep Neural Networks making them suitable with many hidden layers Geoffrey Hinton in 2006 proposed a solution to the vanishing gradient and adoption of ReLU activation functions
Data must be prepared before being feeded into the model for training. To an abstract perspective, data must be reduced to a single value for each sample (in each dimension), made available to NN processing. Data pre-processing (filtering) is a key moment in every Machine/Deep Learning application since can have an impact on performance and (if not done correctly) could introduce some bias. (i.e. filtering out relevant dimensions thus making the model less accurate) Data filtering is a critical step which complexity can tackle the result of the whole process.
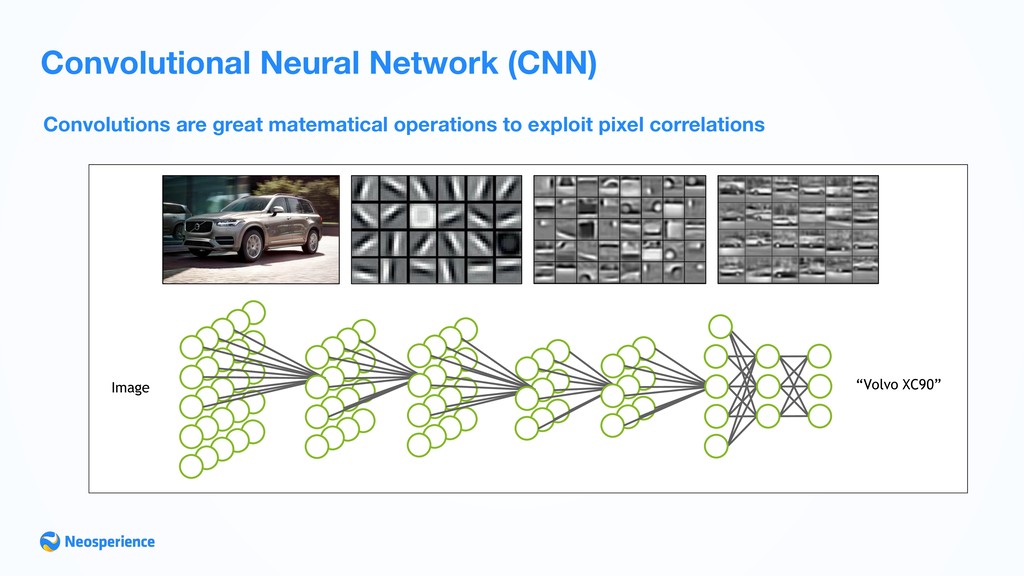
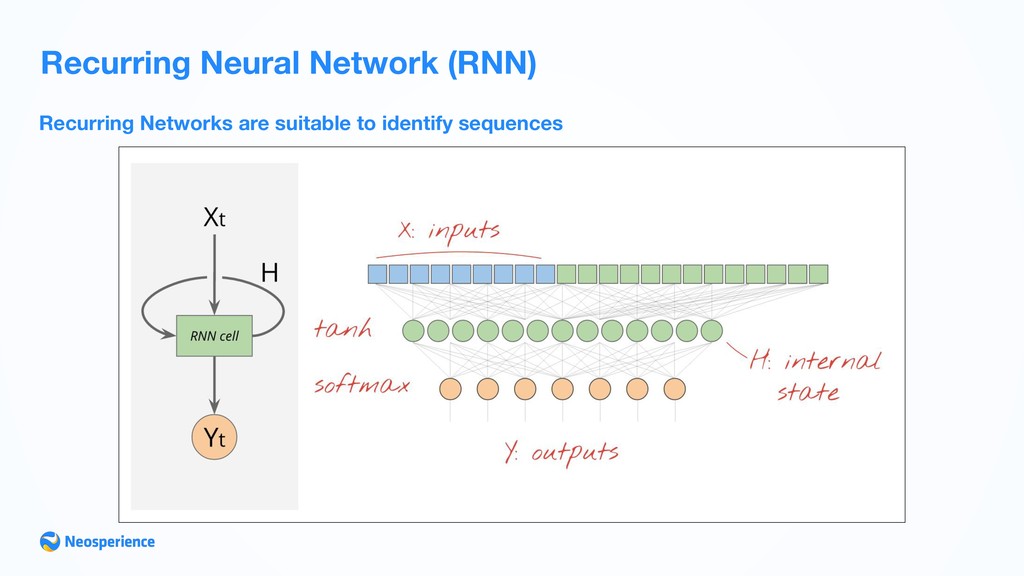
- Classification Neural Networks can be used either for supervised, unsupervised or reinforcement learning, they are the most known expression of Deep Learning (even if not the only one). Neural Networks can be classified on signal propagation method: • Convolutionary Neural Networks (CNN): are the most promising networks, with a wide range of application from Computer Vision to NLP • Recurrent Neural Networks (RNN): used for language translation, content based image processing, word prediction, Language Detection, Text Summarization • Feed-Forward Neural Network (FFNN): used for standard prediction (a powerful alternative to regression/ classification)
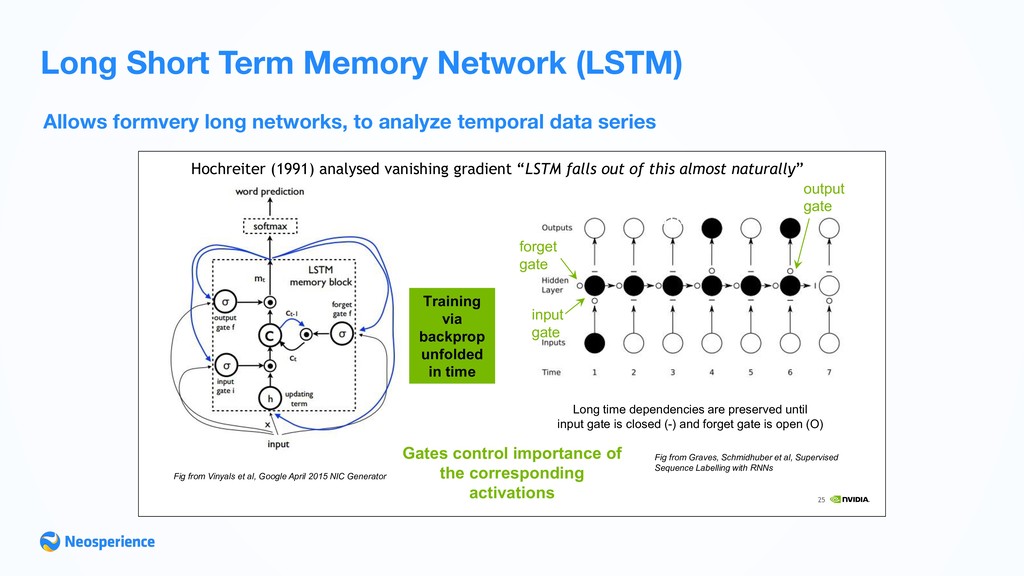
Short Term Memory Network (LSTM) 25 Long short-term memory (LSTM) Hochreiter (1991) analysed vanishing gradient “LSTM falls out of this almost naturally” Gates control importance of the corresponding activations Training via backprop unfolded in time LSTM: input gate output gate Long time dependencies are preserved until input gate is closed (-) and forget gate is open (O) forget gate Fig from Vinyals et al, Google April 2015 NIC Generator Fig from Graves, Schmidhuber et al, Supervised Sequence Labelling with RNNs
to solve this problem: 90k travelers are stranded every day in America across 5,145 airports. How can the hotel ensure that they show up at the right moment for all these people? The solution was to leverage real-time signals like bad weather, flight delays at 5,145 airports, and other such data, combine that with ML powered algorithms to automate ads and messaging in the proximity of local airports. All sans human-control. Result? 60% increase in bookings in targeted areas. ML + Automation = Profit. Marketing budget forecast leverage ML to do the above campaign across Search, Display and Video. AND (are you sitting down?) rather than guessing how much credit to give each marketing strategy from hundreds of thousands of customer touch points, ML powered attribution can magically analyze every individual’s journey and automatically recommend shifts to your budget.
understand common interests between customer belonging to different clusters and push personalized messages. Generate smart content Smart Agents such as Persado generate personalized wording depending on the profile of customer landing on their site, starting from a few words. Customer tracking in store Customers can be tracked down extracting their movements in store. This leads to exploiting their interests, identifying returning customers (through face recognition) and sentiment (through face analysis). i.e. tracking person of interests with AWS Rekognition
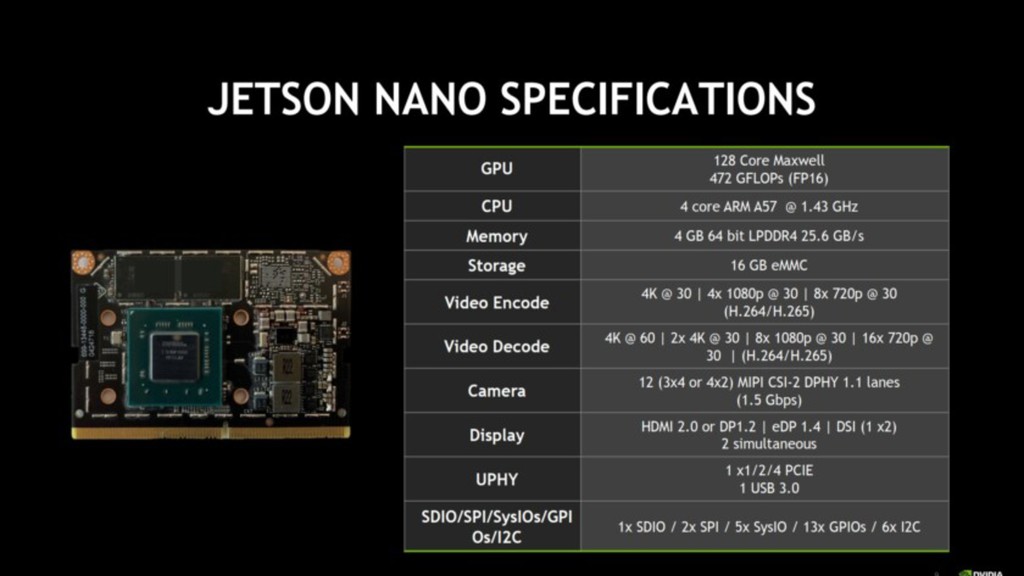
energy efficiency vs. Jetson TX1 maximum performance Max- P operating mode (< 15 watts) delivers up to 2x performance vs. Jetson TX1 maximum performance NVIDIA JETSON TX2 EMBEDDED AI SUPERCOMPUTER Advanced AI at the edge JetPack SDK < 7.5 watts full module Up to 2X performance or 2X energy efficiency
algorithm capable of solving a narrow problem with no need to be developed specifically for a given context. The Master Algorithm The master algorithm is the ultimate learning algorithm. It's an algorithm that can learn anything from data and it's the holy grail of machine learning. It's what we're working towards and the book is about both how we're going to get there and the implications that it's going to have for life. Also, the impact that machine learning is already having.
![www.neosperience.com | blog.neosperience.com | [email protected] Neosperience Academy Artificial Intelligence Hype,](https://files.speakerdeck.com/presentations/bff1258fda434d0896c58691fdbf4684/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you. http://bit.ly/nsp-ai-2019 we’re hiring [email protected]](https://files.speakerdeck.com/presentations/bff1258fda434d0896c58691fdbf4684/slide_70.jpg){kind=link}
![www.neosperience.com | blog.neosperience.com | [email protected]](https://files.speakerdeck.com/presentations/bff1258fda434d0896c58691fdbf4684/slide_71.jpg){kind=link}