Technology Of fi cer @ Neosperience Chief Technology Of fi cer @ WizKey Serverless Meetup and ServerlessDays Italy co-organizer www.bianchiluca.com @bianchiluca
events An user navigating the webpage produces events with a fl exible structure that are sent to the backend Three types of events: • low-level: in response to mouse/touch events, agnostic • mid-level: related to webpage actions, domain-speci fi c • high-level: structured customer-speci fi c events Constraints • response time: beacon support is strict on time • volume: millions of events within a single month • throughput: events could peak to thousands within a few seconds
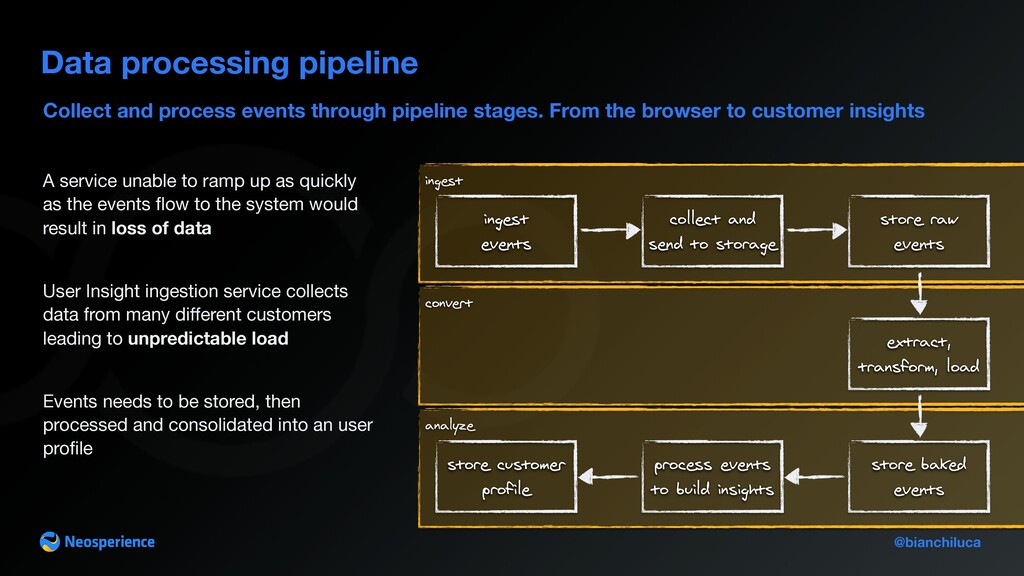
stages. From the browser to customer insights Data processing pipeline A service unable to ramp up as quickly as the events fl ow to the system would result in loss of data User Insight ingestion service collects data from many di ff erent customers leading to unpredictable load Events needs to be stored, then processed and consolidated into an user pro fi le ingest events collect and send to storage store raw events extract, transform, load store baked events process events to build insights store customer profile
serverless microservices architecture Aurora Serverless e ff i ciently scales up within seconds DocumentDB is great to store nested documents DynamoDB is great to handle millions of events, but… API Gateway Lambda Focusing on managed database services, to avoid scaling the cluster and managing data recovery
the most suitable use case for this technology Using DynamoDB as an analytics database The amount of data collected by database grows to millions of data points very quickly. i.e. for a single customer, ~130M events collected in just one month Data access pattern is not well de fi ned (parameters within query) and could change whenever high level events are managed for a customer speci fi c context Pulling data from DynamoDB with no clear access pattern means a full table scan for each query. It is not just slow, but also very expensive.
Data Lake Amazon S3 - an object storage - 99.99% availability - designed from the ground up to handle tra ff i c for any Internet application - multi AZ reliability - cost e ff ective Amazon S3
into Amazon S3. Streaming to S3 API Gateway Lambda - Up to 5000 records/second (can be increased to 10K records/second) - support data bu ff ering (to decouple input / output frequency) - store with partition year=<year> / month=<month> / day=<day> Kinesis Firehose S3
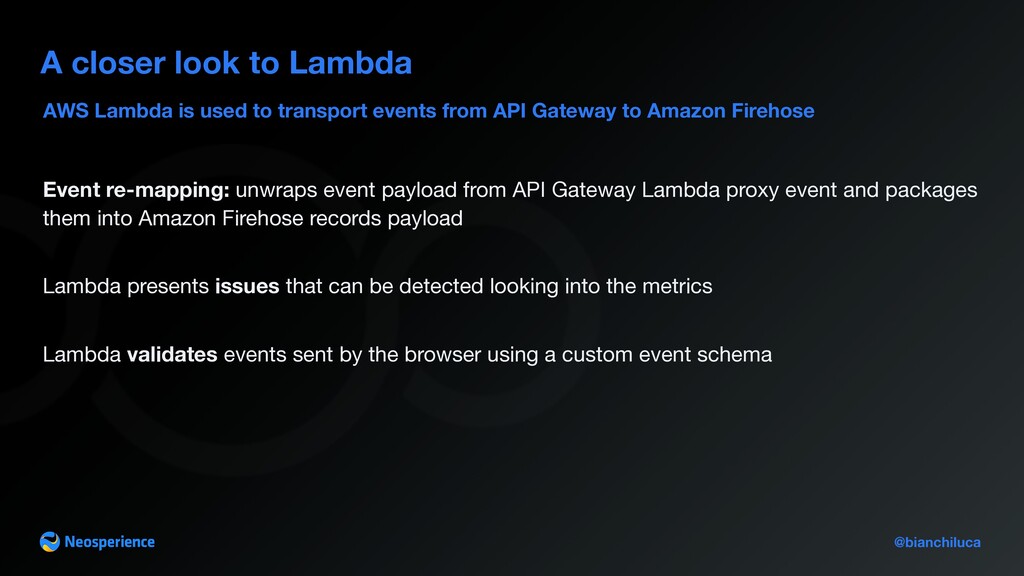
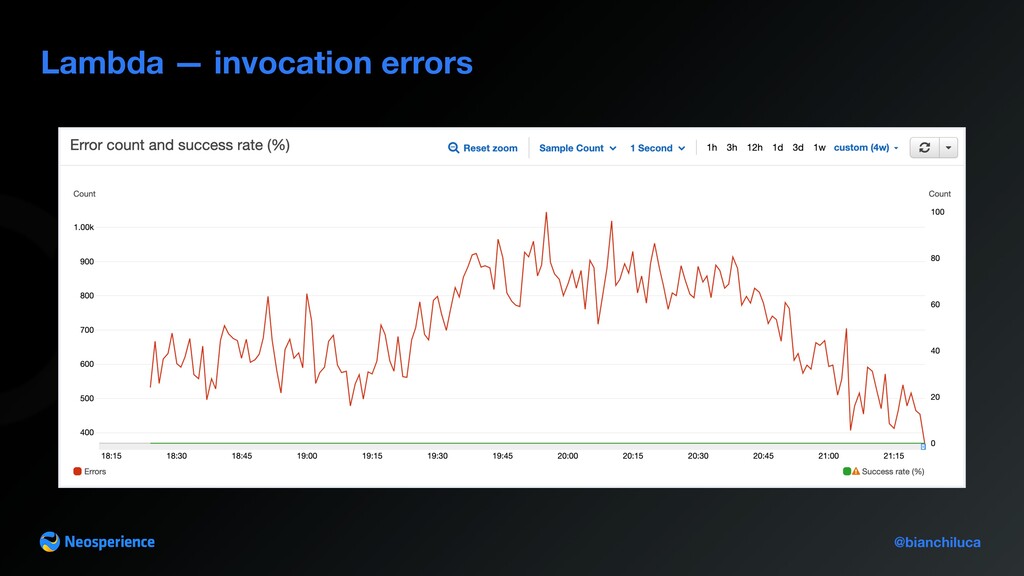
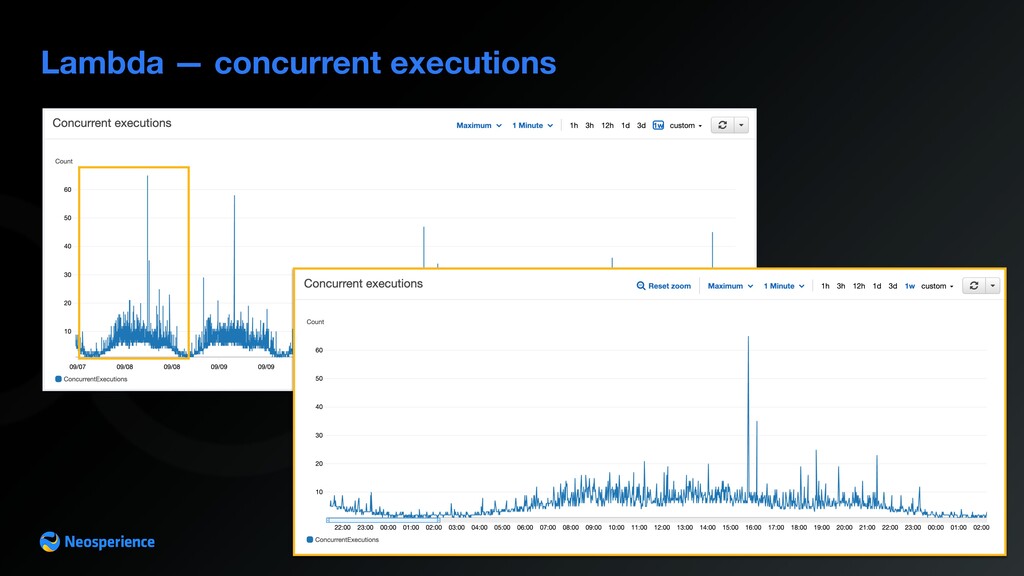
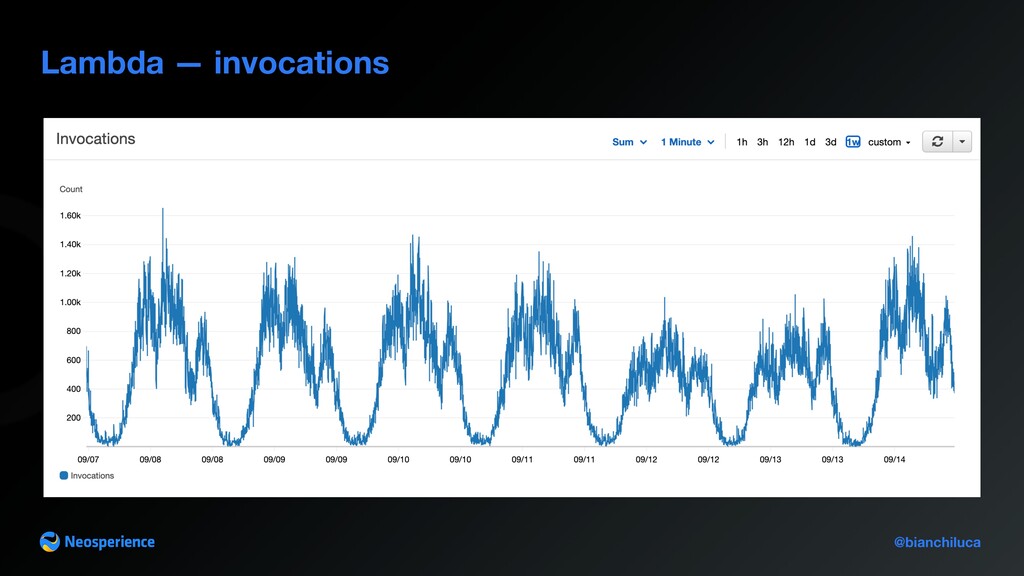
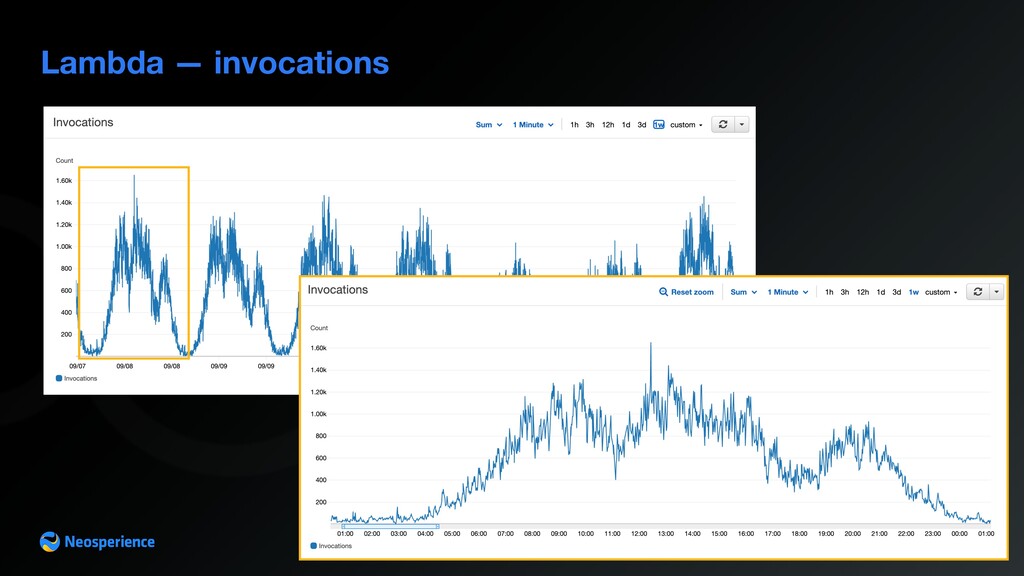
Gateway to Amazon Firehose A closer look to Lambda Event re-mapping: unwraps event payload from API Gateway Lambda proxy event and packages them into Amazon Firehose records payload Lambda presents issues that can be detected looking into the metrics Lambda validates events sent by the browser using a custom event schema
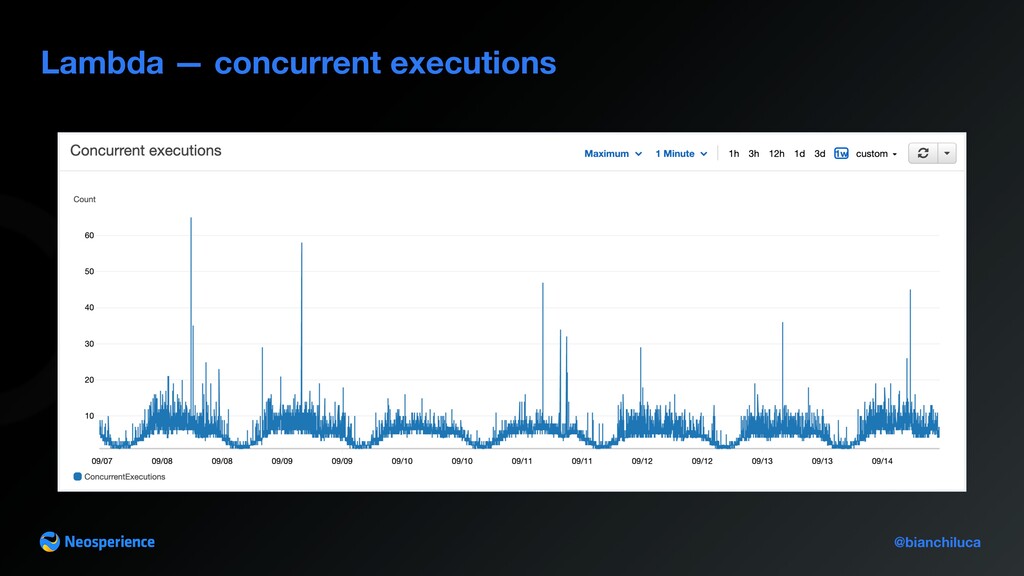
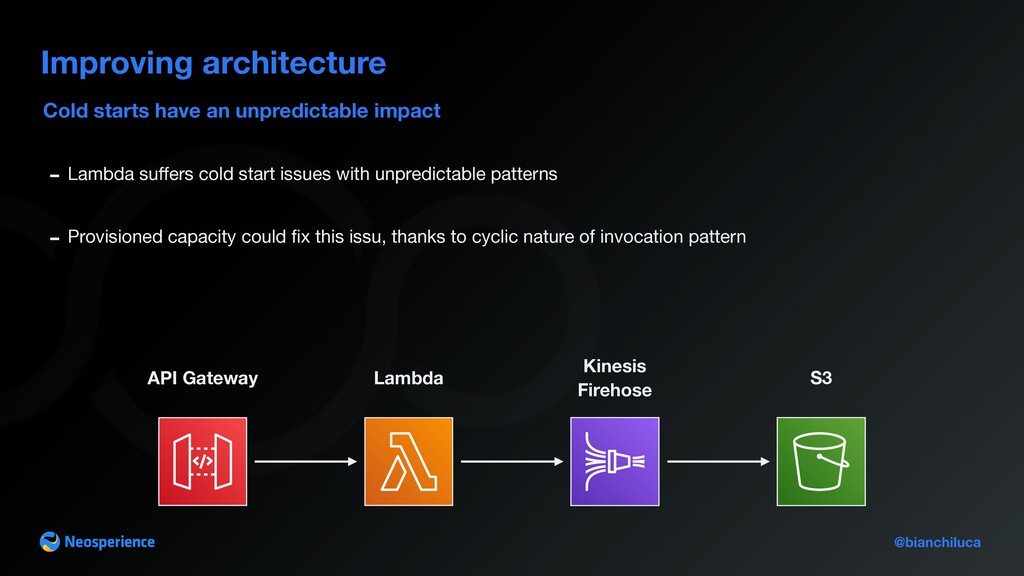
Gateway Lambda - Lambda su ff ers cold start issues with unpredictable patterns - Provisioned capacity could fi x this issu, thanks to cyclic nature of invocation pattern Kinesis Firehose S3
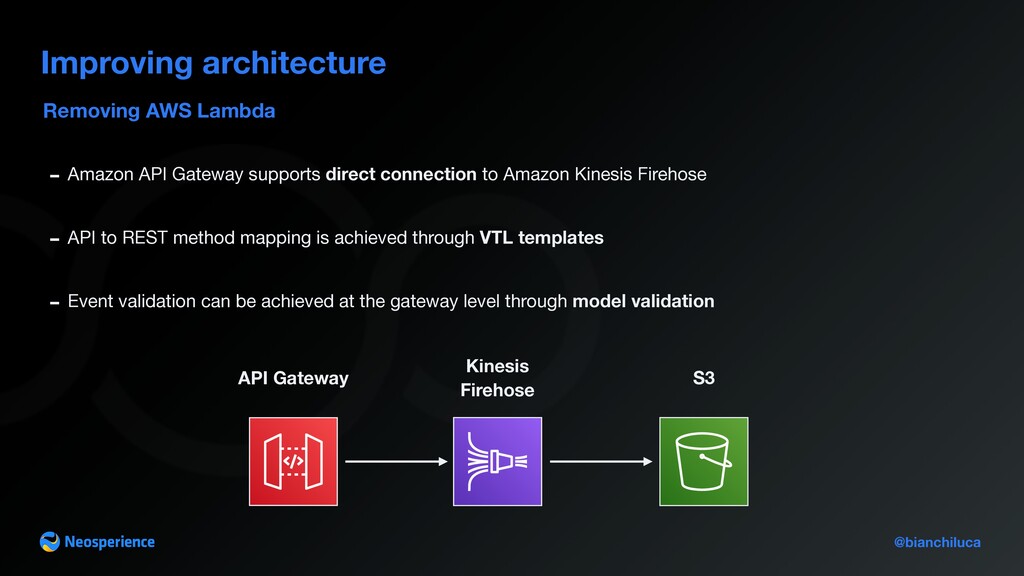
supports direct connection to Amazon Kinesis Firehose - API to REST method mapping is achieved through VTL templates - Event validation can be achieved at the gateway level through model validation API Gateway Kinesis Firehose S3
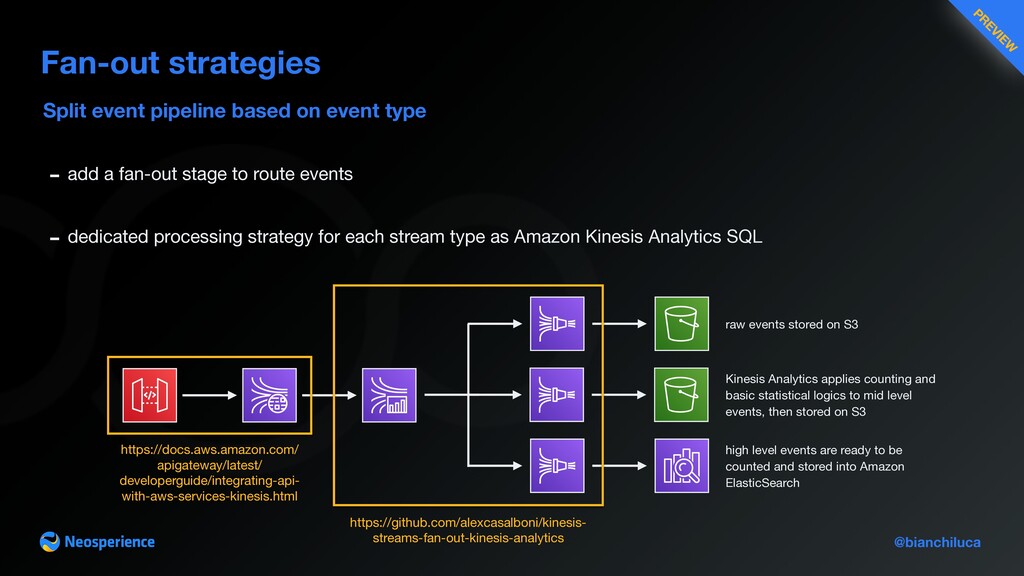
- add a fan-out stage to route events - dedicated processing strategy for each stream type as Amazon Kinesis Analytics SQL https://docs.aws.amazon.com/ apigateway/latest/ developerguide/integrating-api- with-aws-services-kinesis.html https://github.com/alexcasalboni/kinesis- streams-fan-out-kinesis-analytics raw events stored on S3 Kinesis Analytics applies counting and basic statistical logics to mid level events, then stored on S3 high level events are ready to be counted and stored into Amazon ElasticSearch PR EVIEW
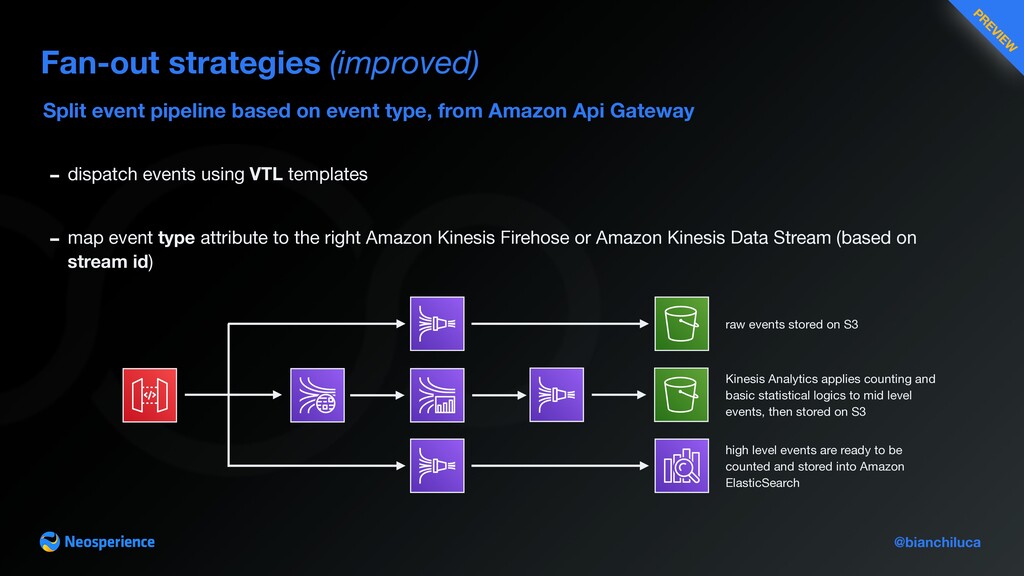
Api Gateway Fan-out strategies (improved) - dispatch events using VTL templates - map event type attribute to the right Amazon Kinesis Firehose or Amazon Kinesis Data Stream (based on stream id) raw events stored on S3 Kinesis Analytics applies counting and basic statistical logics to mid level events, then stored on S3 high level events are ready to be counted and stored into Amazon ElasticSearch PR EVIEW
Api Gateway Fan-out strategies (improved, cost-e ff ective) - use AWS SQS and AWS Lambda instead of Amazon Kinesis Data Stream and Kinesis Data Analytics - make the solution fully serverless (no hourly costs) raw events stored on S3 Kinesis Analytics applies counting and basic statistical logics to mid level events, then stored on S3 high level events are ready to be counted and stored into Amazon ElasticSearch PR EVIEW
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}