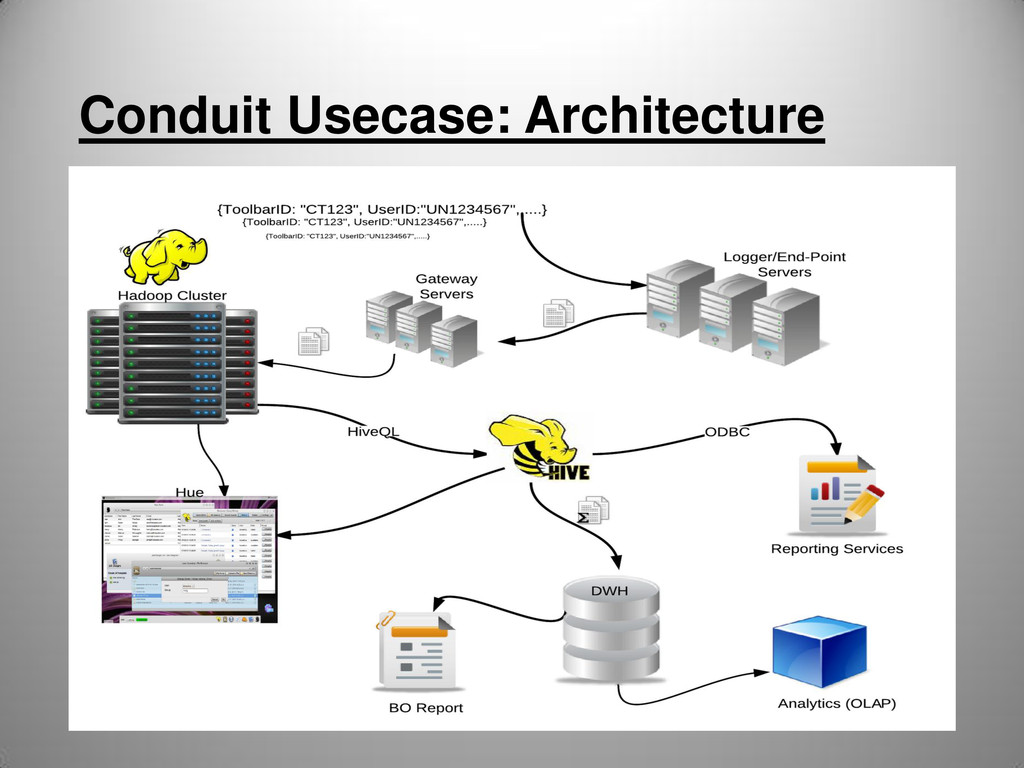
jobs • FileSystem as Data Abstraction? • What if Analyst/BI wants to query RAW data? • Transition of legacy code that connects to plain old SQL DWH – huge cost and effort • Why learn Yet Another Querying language?
box solutions • Most of Analysts/BI are familiar with SQL • Automatically generates MR jobs • Easy porting of SQL-based code • Thrift/ODBC/JDBC • Lets YOU focus on data querying • Open Source and Apache TLP(Apache2 license)!
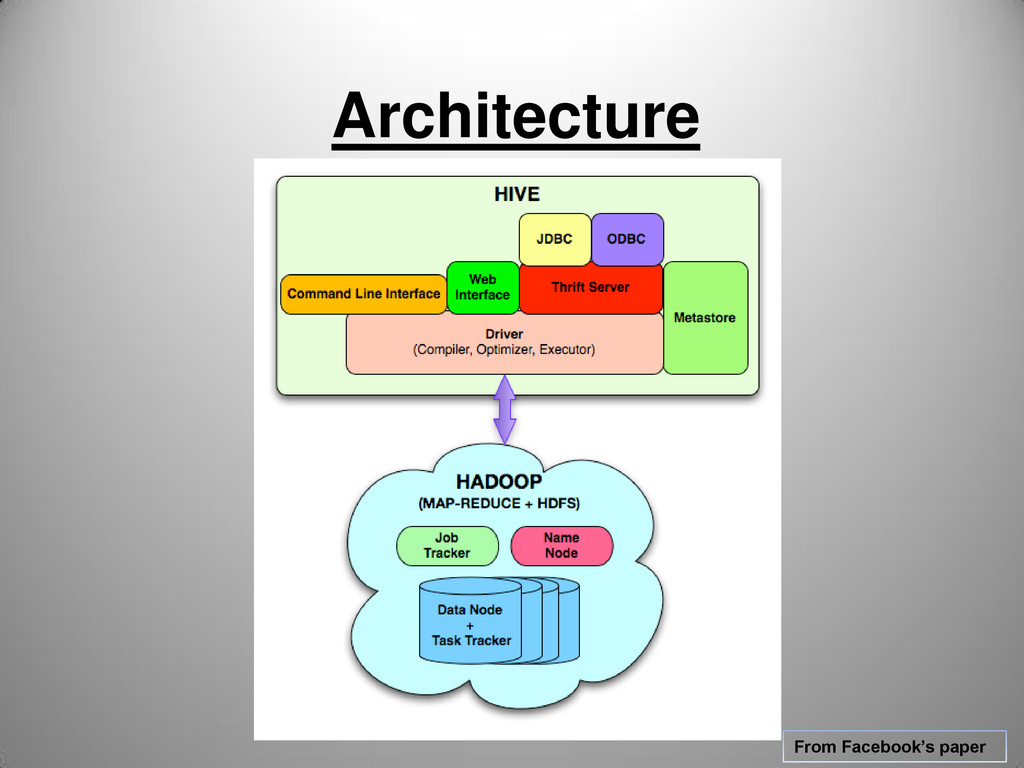
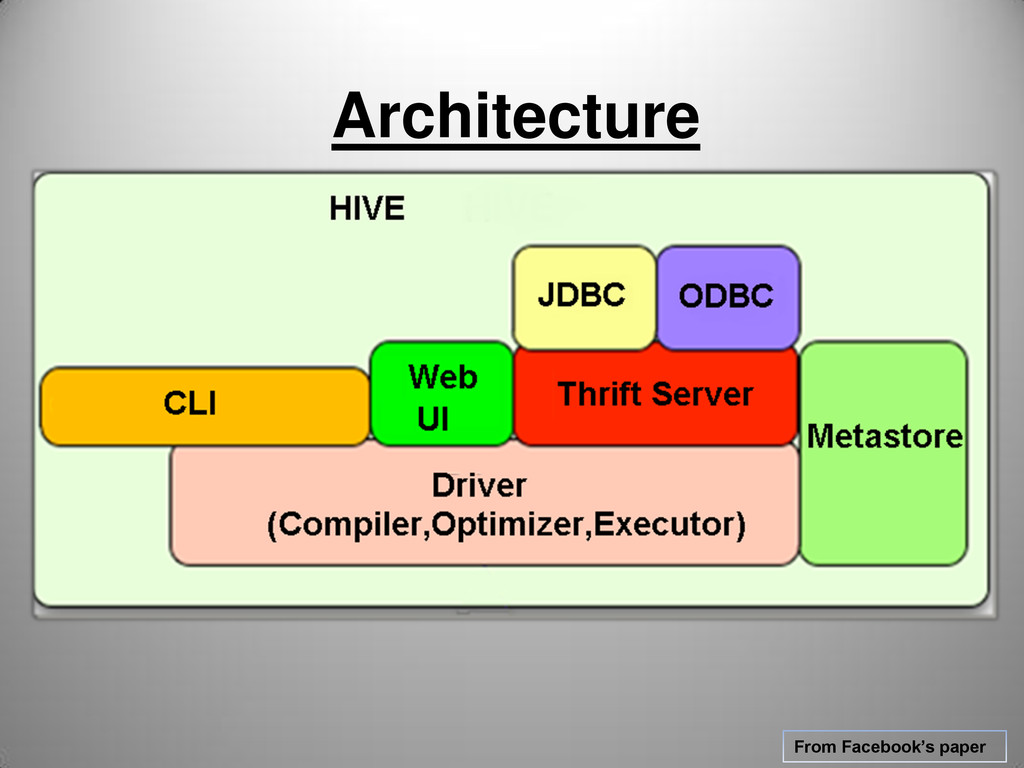
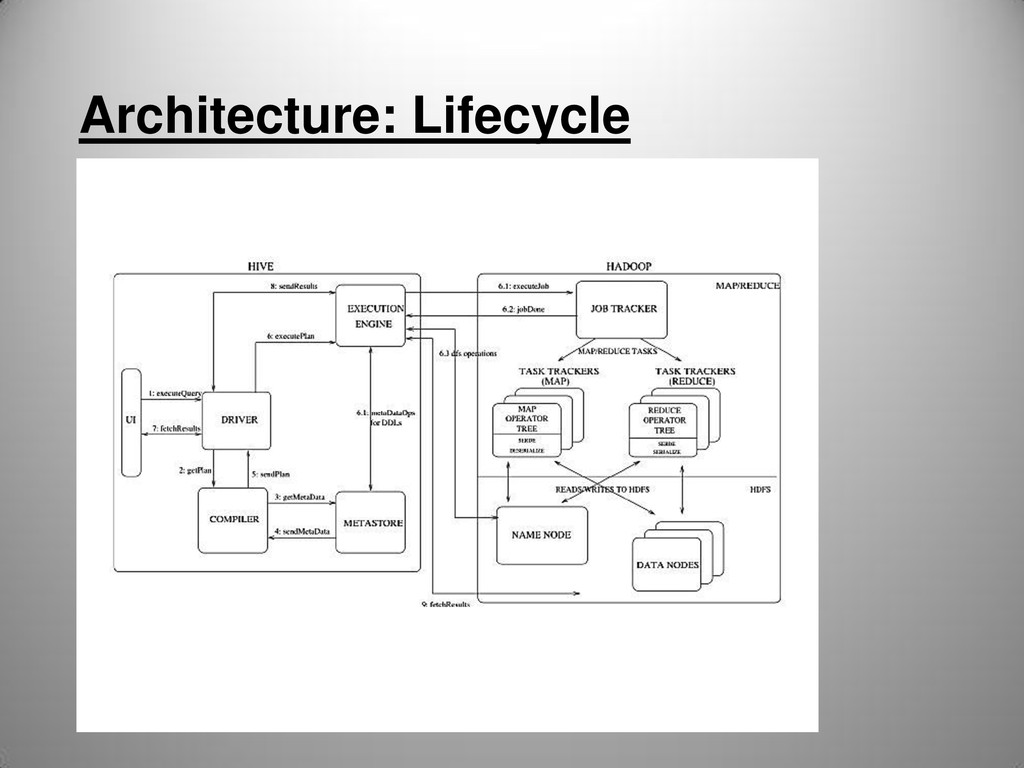
HQL statement . Maintains a session handle and any session statistics. Interoperates with Hadoop for MR / HDFS Query compiler – compiles HQL into a directed acyclic graph(DAG) of M/R tasks Optimizer – optimizes M/R tasks by applying chain of transformations on the DAG Execution Engine – executes the tasks produced by Query compiler in proper dependency order. Actually interacts with underlying Hadoop instance. Hive Server {Thrift,ODBC,JDBC} – provides the following interfaces to allow external applications to integrate with Hive. CLI/Web UI – allows the end user to run queries on Hive. Metastore – Stores the system catalog,statistics,SerDes and metadata about tables/columns/partitions.
• Table row data is stored in subdirectories of warehouse • Partitions are subdirectories of table directories • Actual data – stores in flat files: - char-delimited text - sequence files - custom SerDe allows whatever_you_wish_format files
don’t touch this • (Re)Define conf in $HIVE_HOME/conf/hive-site.xml • Use $HIVE_CONF_DIR – if you have strong will to specify alternative config location. • You can override Hadoop config properties inside Hive config! (e.g. –mapred.reduce.tasks=2)
configuration is located in $HIVE_HOME/conf/hive-log4j.properties • Logs are stored in /tmp/{$username}/hive.log • and of course you can WILL track the M/R logs
as namespaces • TABLES - analogous to Tables in RDBMS. Data is stored in a directory in HDFS. Hive also supports EXTERNAL tables.The rows in a table are organized into typed columns similar to Relational Databases. Typed columns (int, float, string, date,boolean) Advanced types: list, map, struct (for JSON-like data) • PARTITIONS – determine how the data Is stored (directories – remember?), allows the system to prune data based on predicates. (e.g. date as range-partition column) • BUCKETS - each partition may in turn be divided into Buckets based on the hash of a column in the table. Each bucket is stored as a file in the partition dir. Efficiency and speeding up the evaluation).
from any of the primitives, collections or other user defined types. • Typing system is closely tied to the SerDe and object inspector interfaces. • Users can create their own types by implementing their own object inspectors and using these object inspectors they can create their own serdes to serialize and deserialize their data into hdfs files). • Builtin object inspectors like ListObjectInspector, StructObjectInspector and MapObjectInspector provide the necessary primitives to compose richer types in an extensible manner. • For maps(associative arrays) and arrays useful built-in functions like size and index operators are provided.
line $HIVE_HOME/bin/hive -e 'select a.col from tab1 a‘ • Dumping data out from a query into a file using silent mode $HIVE_HOME/bin/hive -S -e 'select a.col from tab1 a' > a.txt • Running a script non-interactively $HIVE_HOME/bin/hive -f /home/my/hive-script.sql • Running an init script before entering cli $HIVE_HOME/bin/hive -i /home/my/hive-init.sql
table using a where clause. • Ability to select certain columns from the table using a select clause. • Ability to do equi-joins between two tables. • Ability to evaluate aggregations on multiple "group by" columns for the data stored in a table. • Ability to store the results of a query into another table. • Ability to download the contents of a table to a local (e.g., nfs) directory. • Ability to store the results of a query in a hadoop dfs directory. • Ability to manage tables and partitions (create, drop and alter). • Ability to plug in custom scripts in the language of choice for custom map/reduce jobs.
y) y - multiple or divisor of the number of buckets • INSERT OVERWRITE TABLE pv_gender_sum_sample SELECT pv_gender_sum.* FROM pv_gender_sum TABLESAMPLE(BUCKET 3 OUT OF 32);
stage of the join, the table to be streamed can be specified via a hint: SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) All the three tables are joined in a single map/reduce job and the values for a particular value of the key for tables b and c are buffered in the memory in the reducers. Then for each row retrieved from a, the join is computed with the buffered rows. • MapSide join, no need in reducer, table b read completely during map step SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key
import org.apache.hadoop.hive.ql.exec.UDF; public final class PreffixStrUdf extends UDF { public String evaluate(final String s, final String preffix) { if (s == null || preffix == null) return null; return preffix+s; }
inside hive shell - run "add jar YOUR_JAR.jar;" 3. still inside shell - run "create temporary function prefix_str as 'com.hiveextensions.udf.PreffixStr';" 4. usage – prefix_str(FIELD_NAME,STRING_TO_ADD)
bad things, absolutely no promises for preventing bad users doing malicious things! • Prerequisites (edit hive-site.xml) <property> <name>hive.security.authorization.enabled</name> <value>true</value> <description>enable or disable the hive client authorization</description> </property> <property> <name>hive.security.authorization.createtable.owner.grants</name> <value>ALL</value> <description>the privileges automatically granted to the owner whenever a table gets created. </description> </property>
being used, • Users and groups are managed by the hive.security.authenticator.manager. • The Metastore will determine the username , and the groups using hive.security.authorization.manager.That information is then used to determine if the user should have access to the metadata being requested, by comparing the required privileges of the Hive operation to the user privileges using the following rules: • User privileges (Has the privilege been granted to the user) • Group privileges (Does the user belong to any groups that the privilege has been granted to) • Role privileges (Does the user or any of the groups that the user belongs to have a role that grants the privilege)
DROP ROLE role_name • Grant/Revoke Roles GRANT ROLE role_name [, role_name] ... TO principal_specification [, principal_specification] ... REVOKE ROLE role_name [, role_name] ... FROM principal_specification [, principal_secification] • Viewing Granted Roles SHOW ROLE GRANT principal_specification
• ALTER - Allows users to modify the metadata of an object • UPDATE - Allows users to modify the physical data of an object • CREATE - Allows users to create objects. For a database, this means users can create tables, and for a table, this means users can create partitions • DROP - Allows users to drop objects • INDEX - Allows users to create indexes on an object (TBD) • LOCK - Allows users to lock or unlock tables when concurrency is enabled • SELECT - Allows users to access data for objects • SHOW_DATABASE - Allows users to view available databases
using Kerberos or user/password validation backed by LDAP. • Earlier versions of HiveServer do not support Kerberos authentication for clients. However, the Hive MetaStoreServer does support Kerberos authentication for Thrift clients.
• Not relational • No joins • No fancy query language • No sophisticated query engine • No transactions out-of-the box • No secondary indices out-of-the box • Not a drop-in replacement for your RDBMS
hundreds of terabytes of data • Automatic and configurable sharding of tables • Automatic failover support (with Zookeeper) • Strictly consistent reads and writes
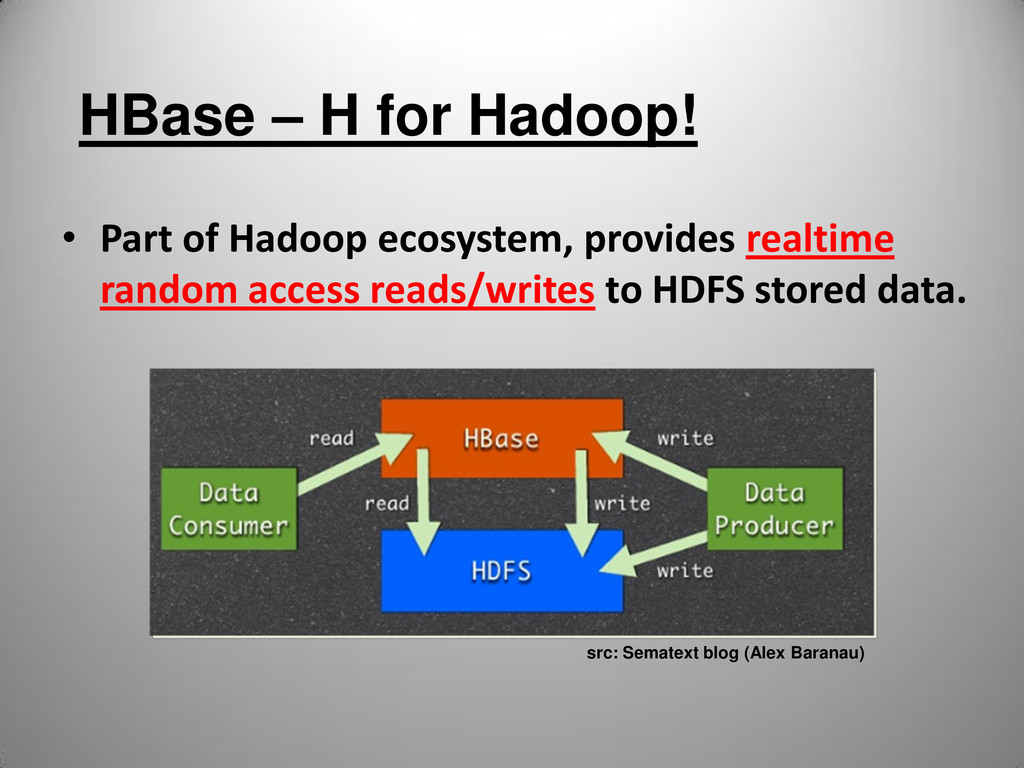
and destination) • Easy Java API for client access • Thrift gateway and REST APIs • Bulk import of large amount of data • Replication across clusters & backup options • Zookeeper to eliminate SPOF • Block cache and Bloom filters for real-time queries • Co-Processors for further flexibility and speedup • and many more... (RTFM – remember ?)
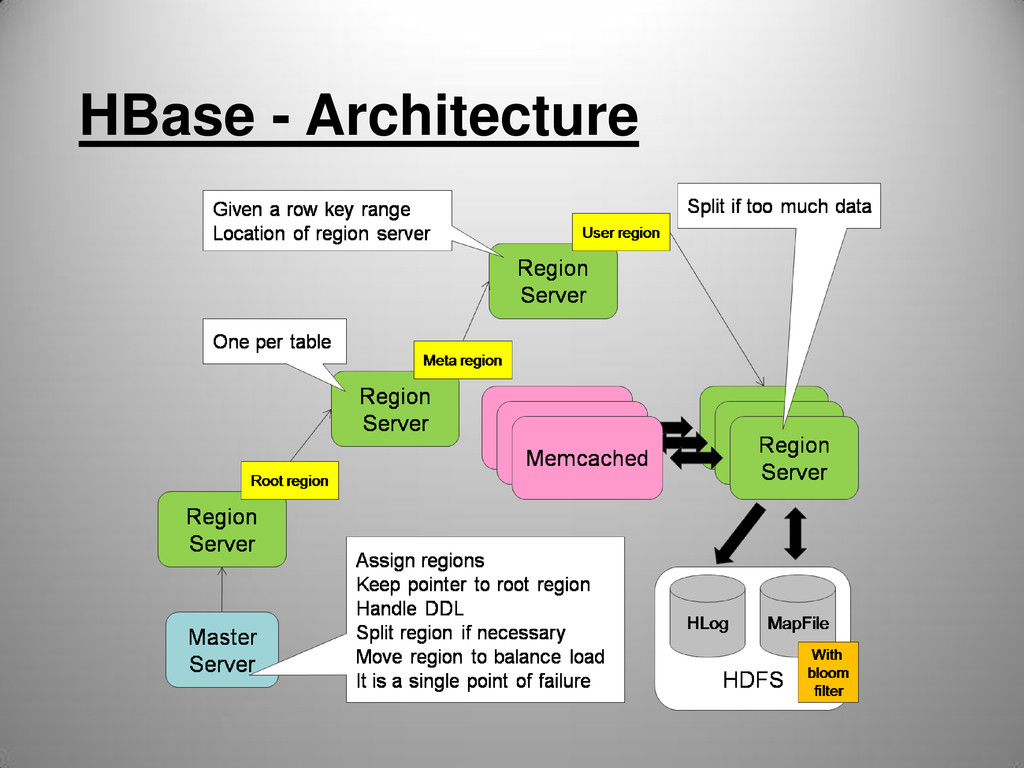
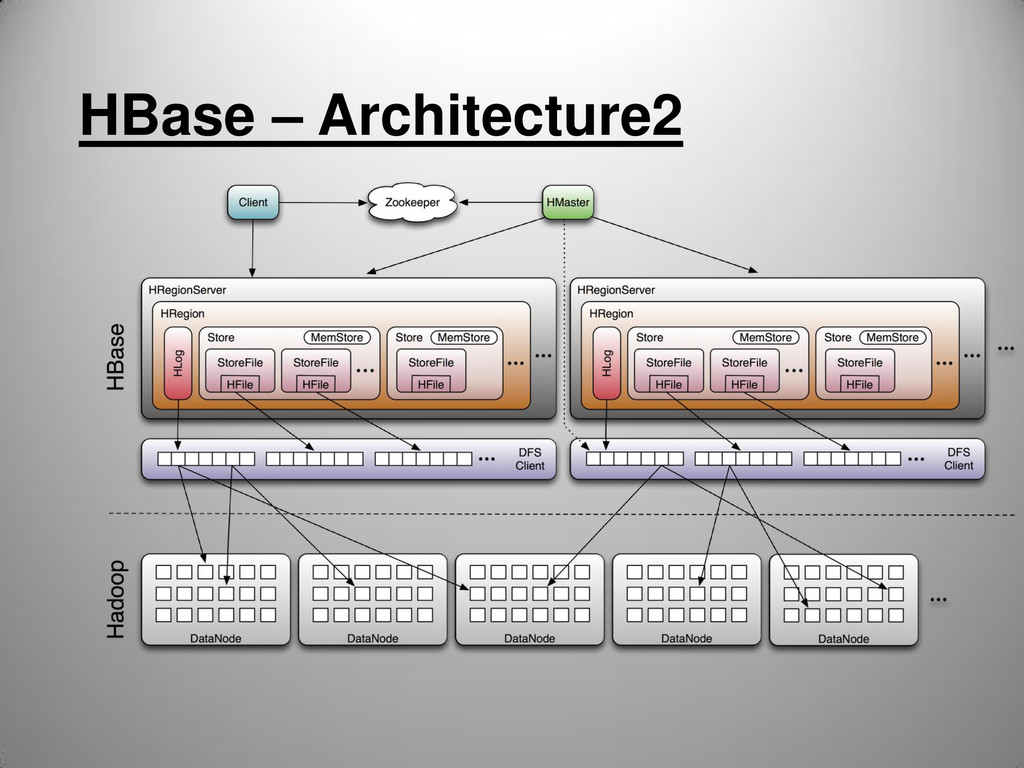
.ROOT and .META • The catalog tables -ROOT- and .META. exist as HBase tables. They are filtered out of the HBase shell's list command, but they are in fact tables just like any other. • -ROOT- keeps track of where the .META. table is • The .META. table keeps a list of all regions in the system
quorum to find the HMaster • HMaster returns the region server that holds a "Root Region" table. • The client contacts the region server who replies the endpoint of a second region server who holds a "Meta Region" table, which contains a mapping from "user table" to "region server". • The client contacts this second region server, passing along the user table name. This second region server will lookup its meta region and reply an endpoint of a third region server who holds a "User Region", which contains a mapping from "key range" to "region server" • The client contacts this third region server, passing along the row key that it wants to lookup. This third region server will lookup its user region and reply the endpoint of a fourth region server who holds the data that the client is looking for. • Client will cache the result along this process.
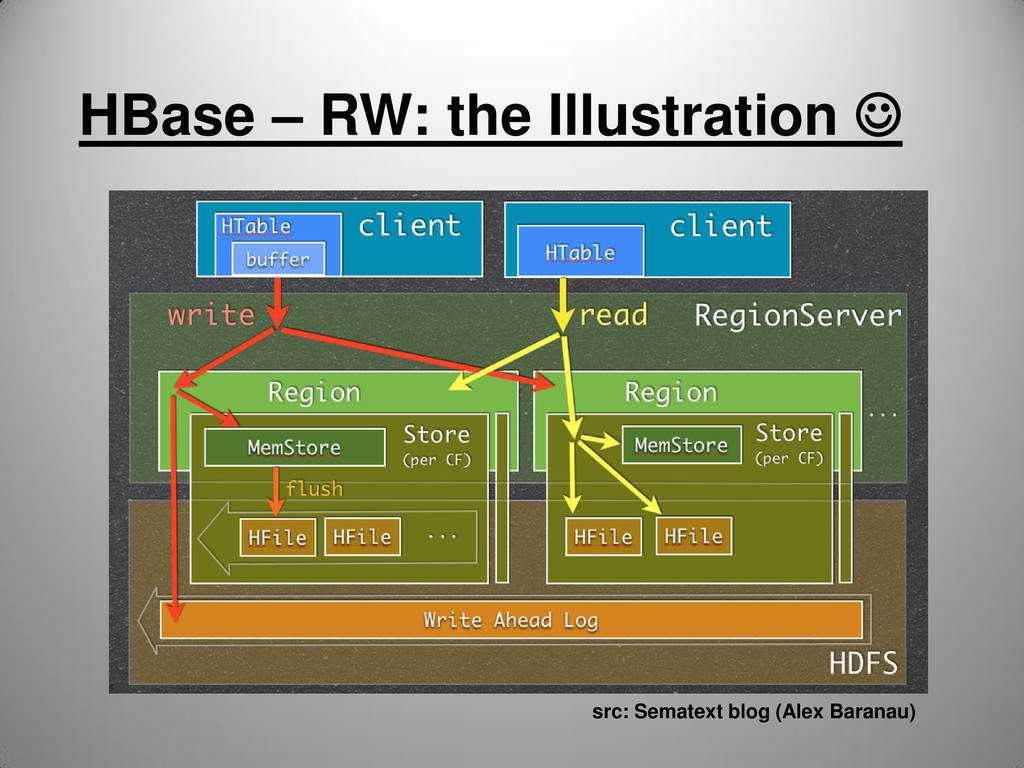
Write Ahead Log • Needed for disaster recovery • Guarantees No Loss of Data • If write to WAL fails – the whole write fails • If disabled – improves writes speed • Implemented by HLog class
arrays • Columns are grouped in columnfamilies (CFs) • CFs defined statically upon table creation • Cell is an uninterpreted byte array and a timestamp • Rows are ordered (speeds up table scans)
last written (and committed) values • Reading single row: Get • Reading multiple rows: Scan • Scan usually defines start key and stop key • Rows are ordered, easy to do partial key scan • Query predicate pushed down via server-side Filters
Updates across multiple rows are NOT atomic • No transaction support out of the box • HBase stores N versions of a cell (default 3) • Tables are usually “sparse”, not all columns populated in a row
with Hadoop MR • Data from HBase table can be source for MR job • MR job can write data into HBase • MR job can write data into HDFS directly (HFile) and then output files can be very quickly loaded into HBase via “Bulk Loading” functionality
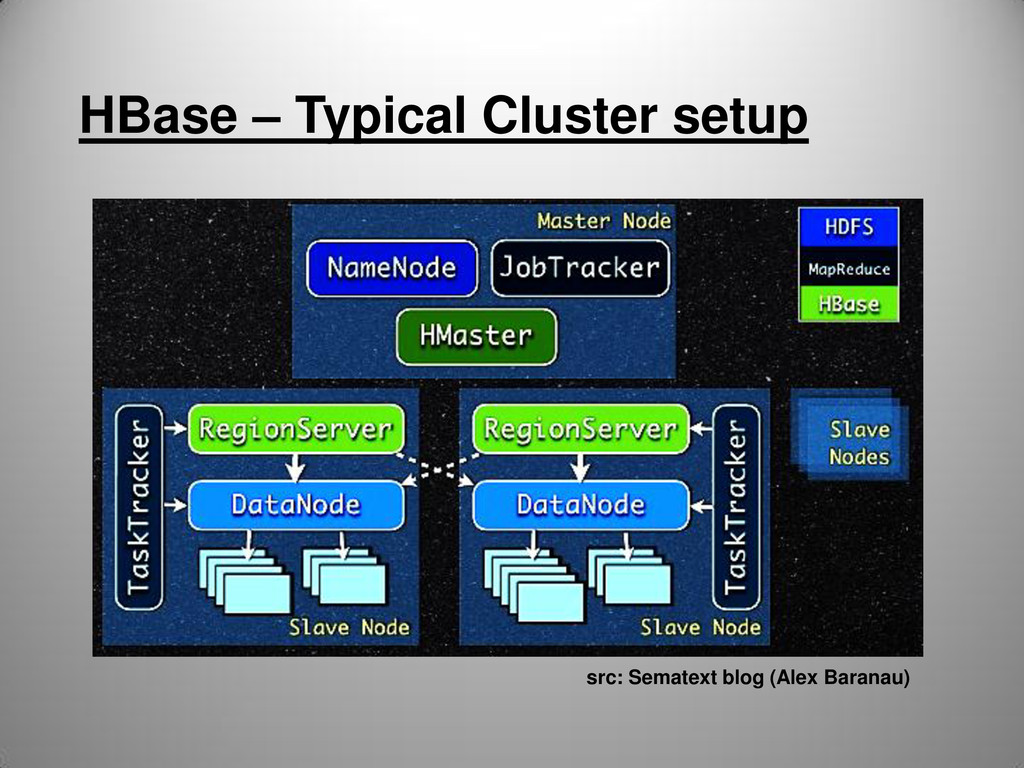
tables • Tables partitioned into Regions • Region defined by start & end row keys • Regions are the smallest units of distribution • Regions are assigned to RegionServers (HBase cluster slaves)
(replication) • RegionServers failures (incl. caused by whole server failure) handled automatically • Master re-assignes Regions to available RSs • HMaster failover: automatic with multiple HMasters, using Zookeeper quorum.
• Built to scale from the get-go • Fast random access to the data • Write-heavy applications* • Append-style writing (insert/overwrite) • When Consistency is preferred over Availability
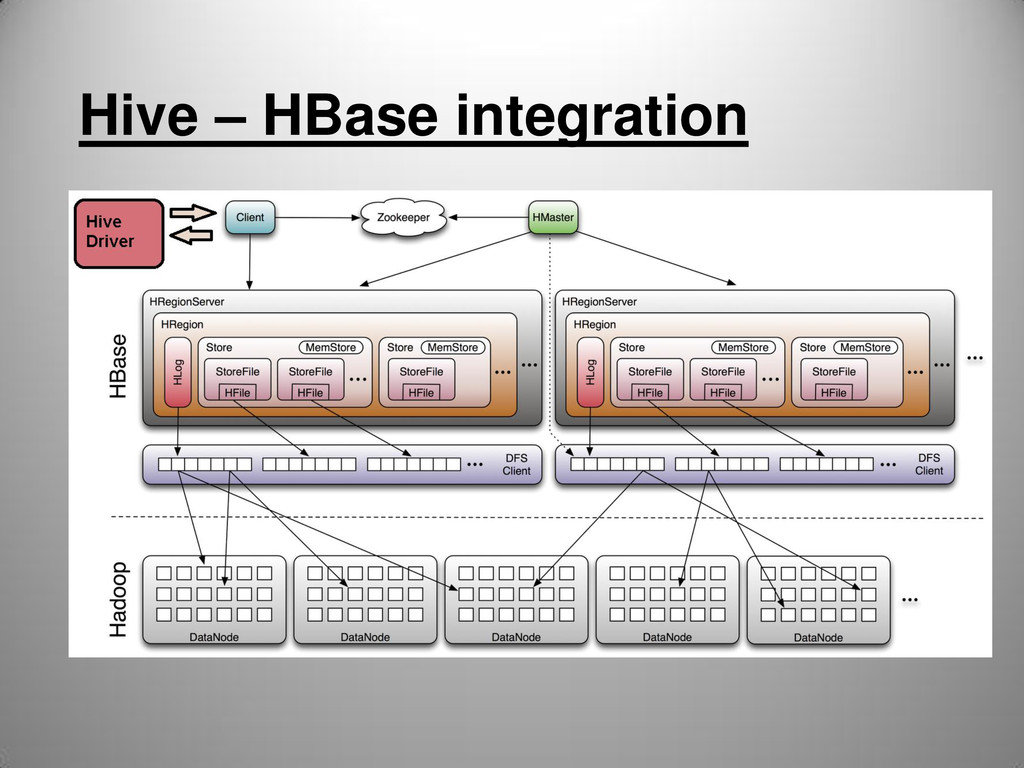
different storage backends: HBase/ Cassandra / MongoDB etc… • Storage Handler has hooks for: input / output formats,Meta data operations hooks: CREATE TABLE, DROP TABLE, etc… • Storage Handler is a table level concept – Does not support Hive partitions, and buckets
whole HBase CF CREATE TABLE hbase_table_1(value map<string,int>, row_key int) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( "hbase.columns.mapping" = "cf:,:key" ); • Mapping a Hive primitive to the whole CF in HBase – is illegal • In HBase – row keys are unique, in Hive no, caution when mixing data.
![Alexander Leibzon Software Engineer Data-Infrastructure @ [email protected] Apache Hive (&HBase)](https://files.speakerdeck.com/presentations/5c2c1e205e2401303574123138156380/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Models • [DATABASE/SCHEMA]– actually mean the same thing, used](https://files.speakerdeck.com/presentations/5c2c1e205e2401303574123138156380/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Hive QL: Built-ins • Complex types [struct,map,array] • Operators [=,!=,<,>,LIKE,REGEXP,etc…]](https://files.speakerdeck.com/presentations/5c2c1e205e2401303574123138156380/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}