PostgreSQL has built-in support for creating hot standby nodes and keeping them up-to-date with streaming replication; alas, there is no out-of-box failover. Patroni is a small Python daemon to fill that niche, enabling anyone in a few simple steps to create high availability PostgreSQL clusters based on hot standby and streaming replication. It manages the PostgreSQL database instance and utilises an external consistency layer (based on either Etcd, Consul, Zookeeper or Kubernetes) for cluster-wide information, such as the list of members and the leader key. Patroni supports on-the-fly addition of new replicas to the existing cluster, can dynamically change the PostgreSQL configuration on all cluster nodes at once, implements both automatic failovers and controlled switchovers (both immediate and scheduled ones). It provides a lot of useful features, such as support for synchronous replication, custom actions fired during the leader switch, reporting and managing of the state of the instance via the REST API, running user-supplied scripts for replica imaging and custom bootstrap of the first node in the cluster, Kubernetes-native mode and much more. We'll go through the architecture of Patroni, provide in-detailed instructions how to configure HA PostgreSQL clusters based on it and describe many additional features. Participants will get hands-on experience in setting up HA PostgreSQL, diagnosing and troubleshooting most common issues happening during that process.
Patroni source code is available on GitHub https://github.com/zalando/patroni
---
This is the presentation from the Patroni tutorial as given by Alexander Kukushkin and Oleksii Kliukin on April 16th, 2018 on PostgreSQL Conference US. You can follow up with examples on your own laptop by using the Docker image or Vagrant box (get the Docker image with 'docker pull kliukin/patroni-training' or look at the slide 23 and 24 for more information.) If you are interested in building the docker image by yourself or using the Vagrant box you may find the source code is on Github at https://github.com/alexeyklyukin/patroni-training)
{kind=link}
{kind=link}
{kind=link}
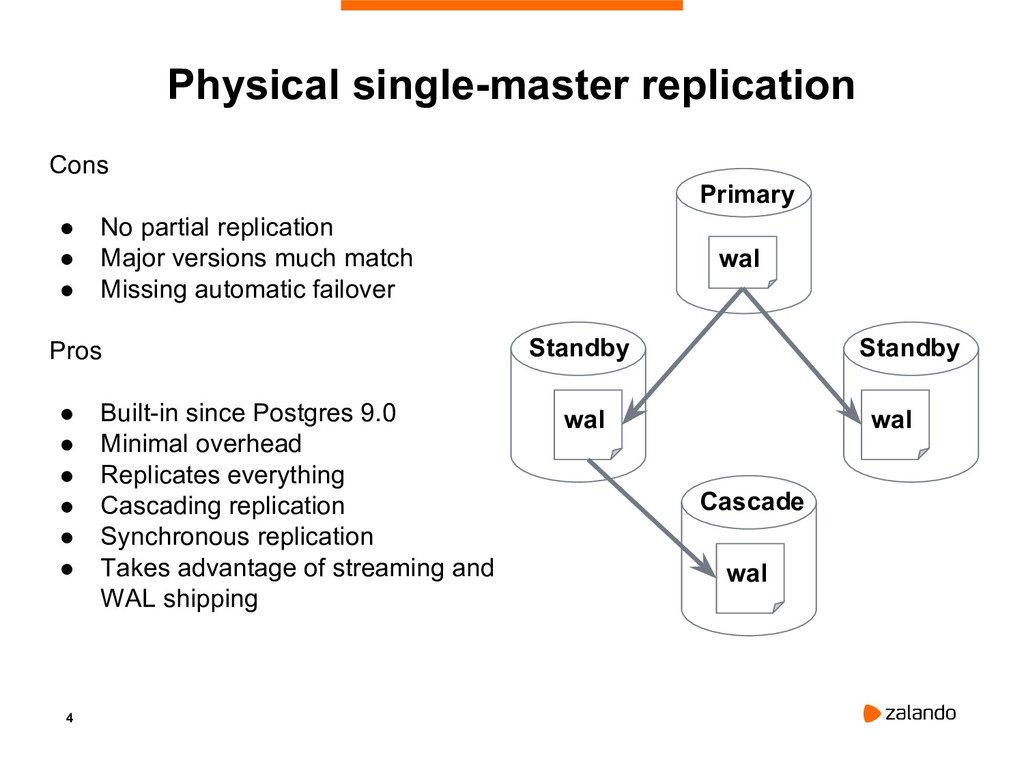{kind=link}
{kind=link}
{kind=link}
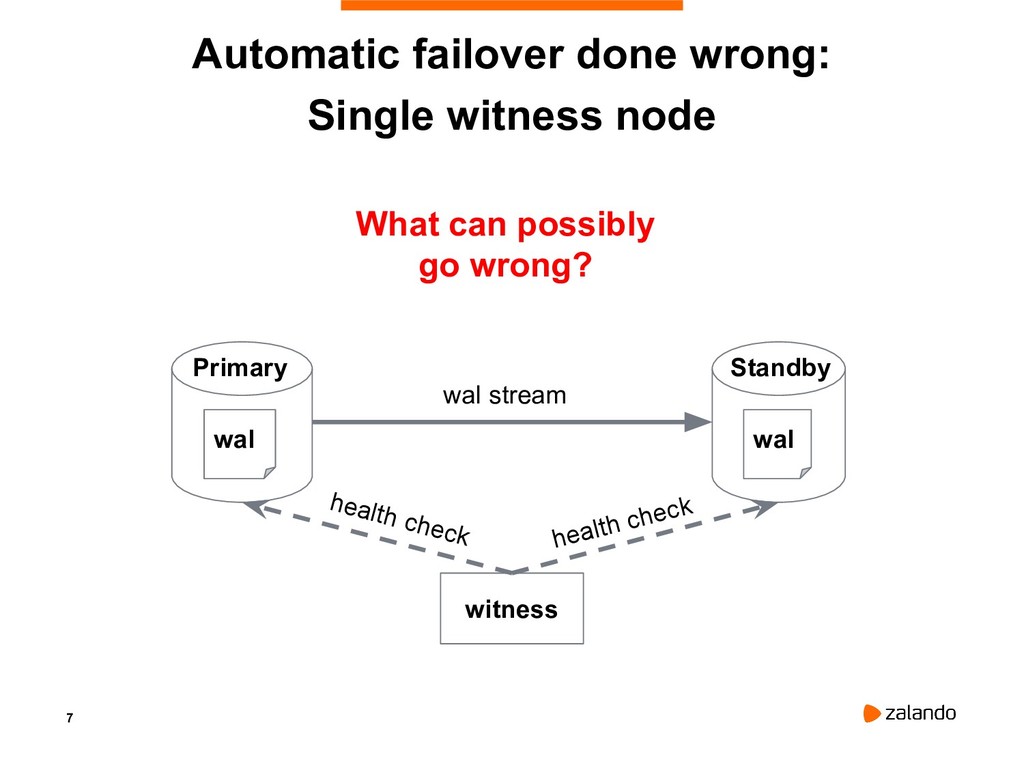{kind=link}
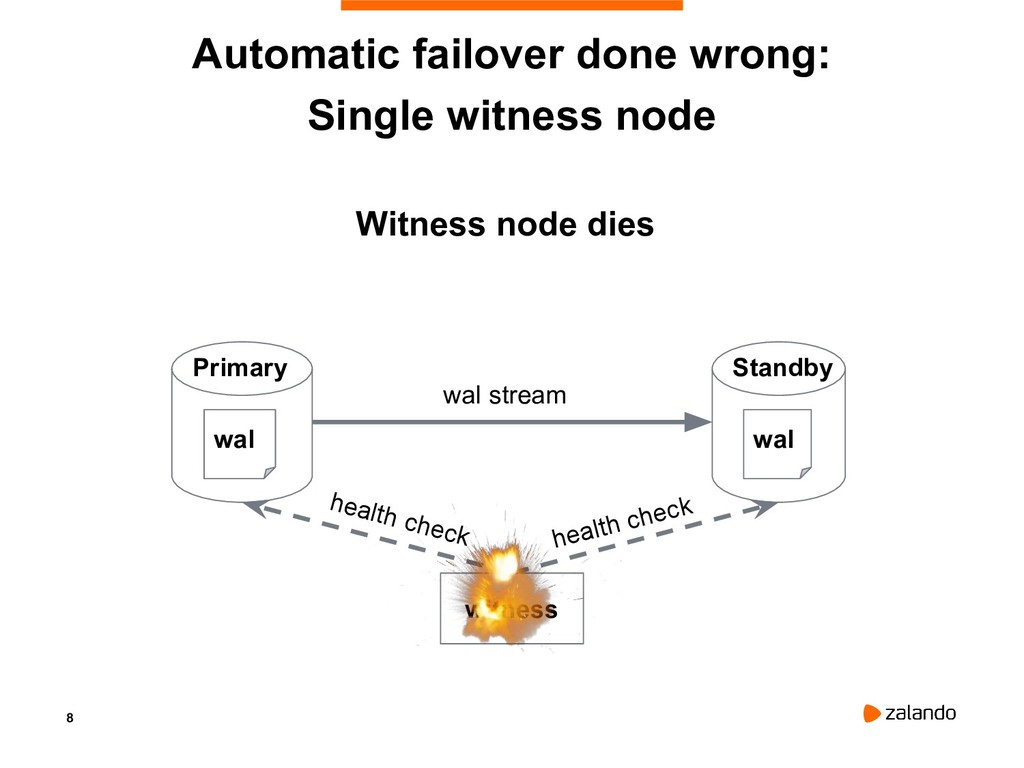{kind=link}
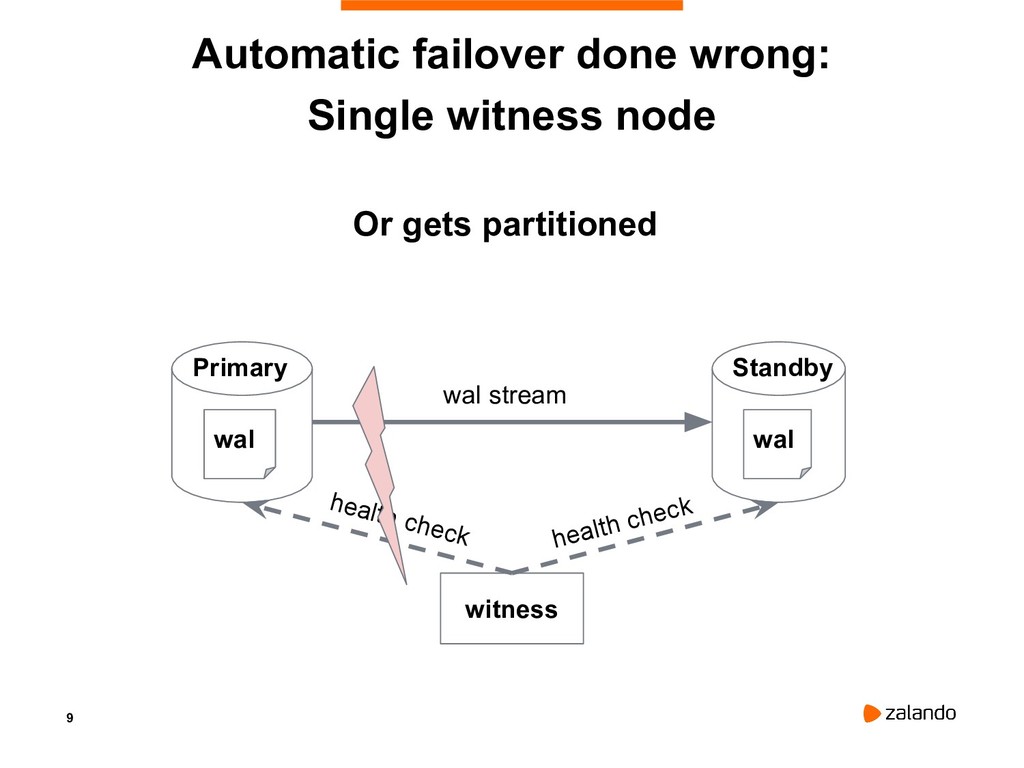{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![65 Switchover with patronictl $ patronictl switchover batman Master [postgresql1]:](https://files.speakerdeck.com/presentations/615f1d22ab57490ba1c7573b5492d072/slide_64.jpg){kind=link}
{kind=link}
![67 Scheduled switchover $ patronictl switchover batman Master [postgresql0]: Candidate](https://files.speakerdeck.com/presentations/615f1d22ab57490ba1c7573b5492d072/slide_66.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
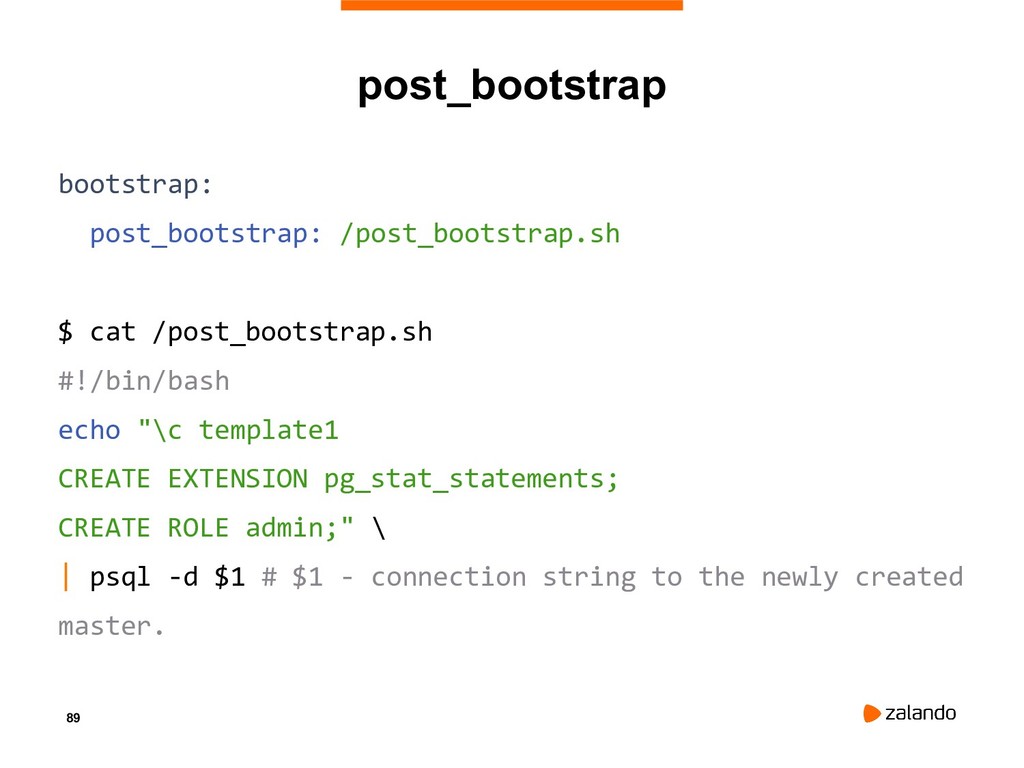{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
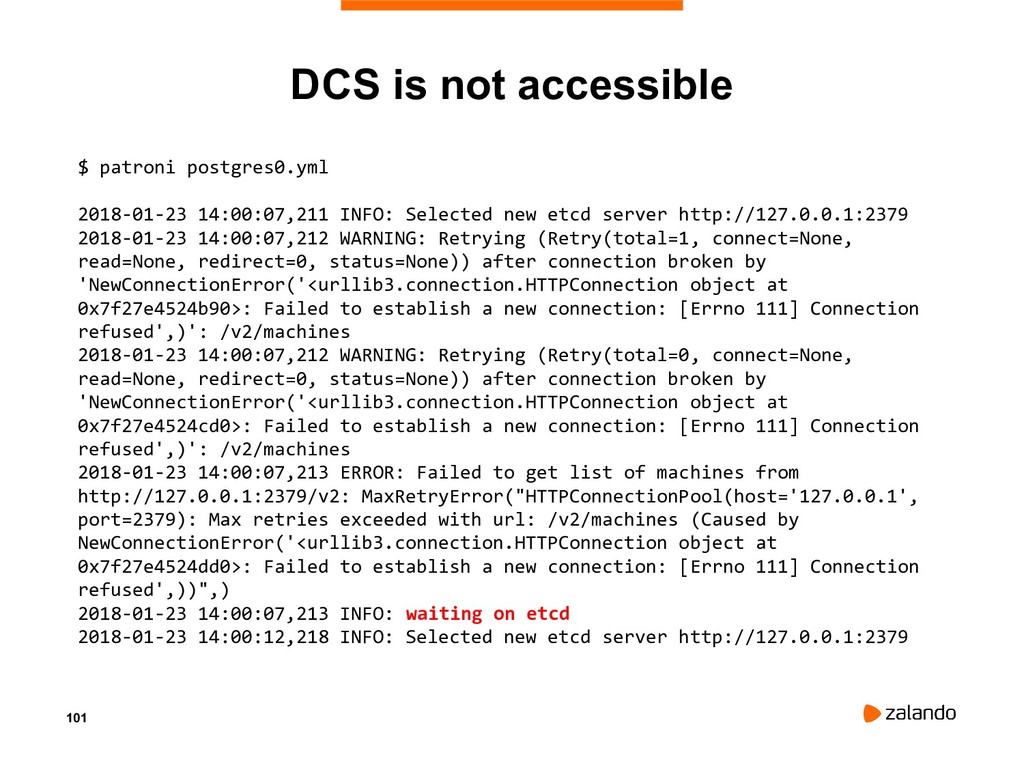{kind=link}
{kind=link}
{kind=link}
{kind=link}
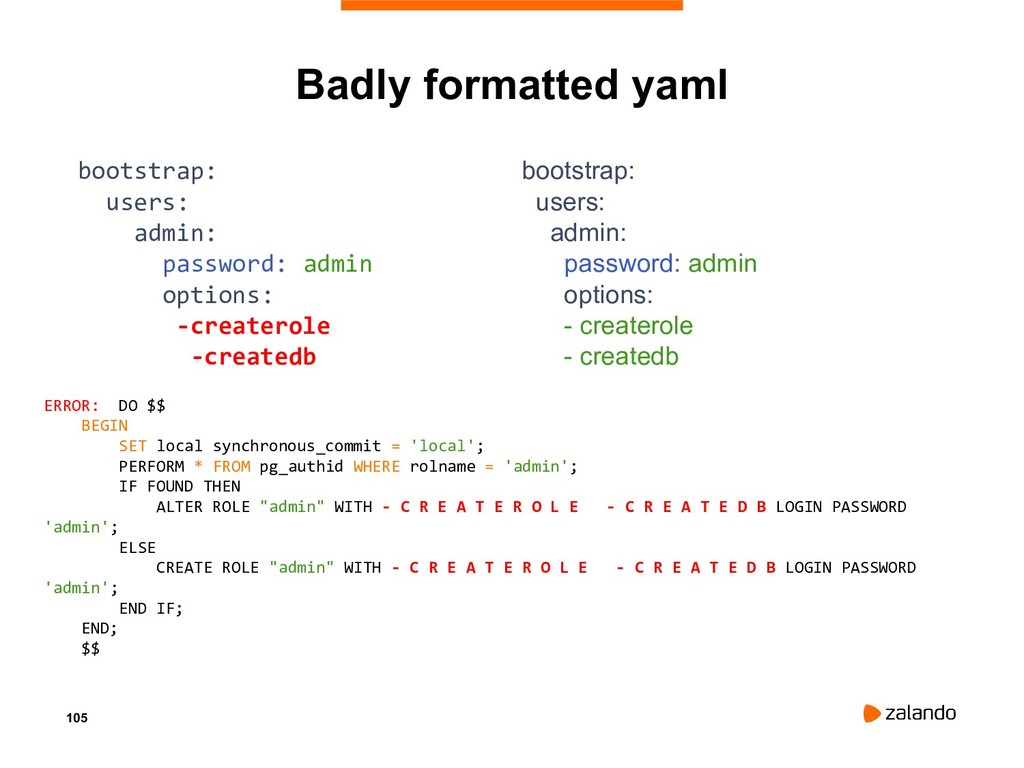{kind=link}
{kind=link}
{kind=link}
{kind=link}