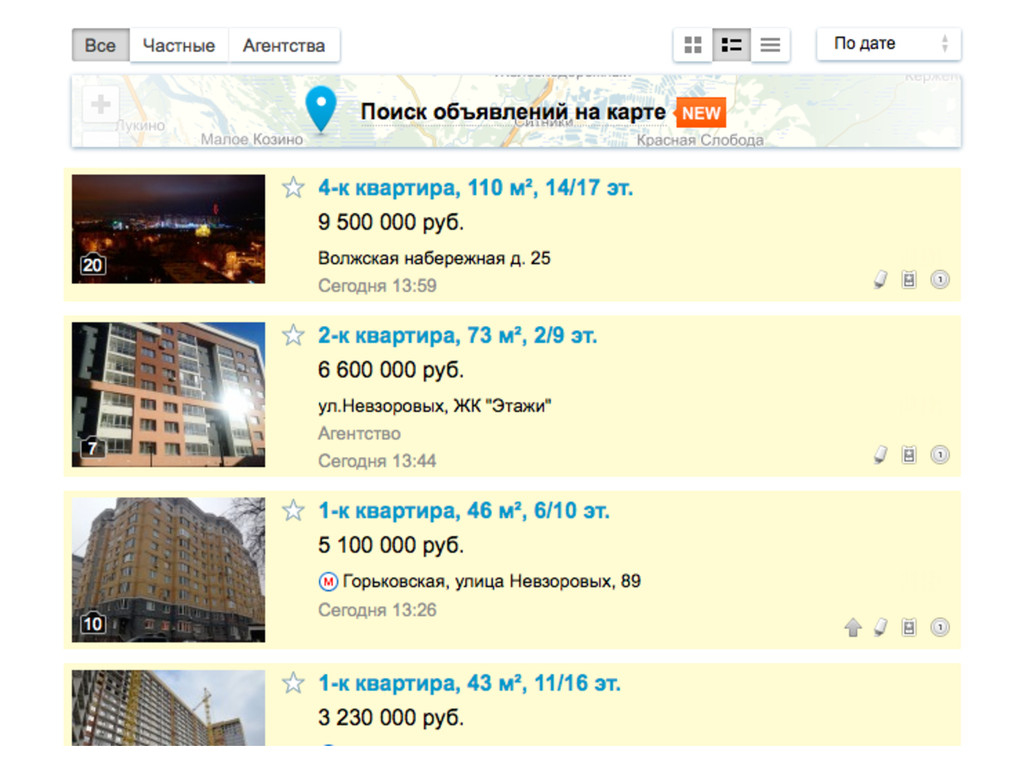
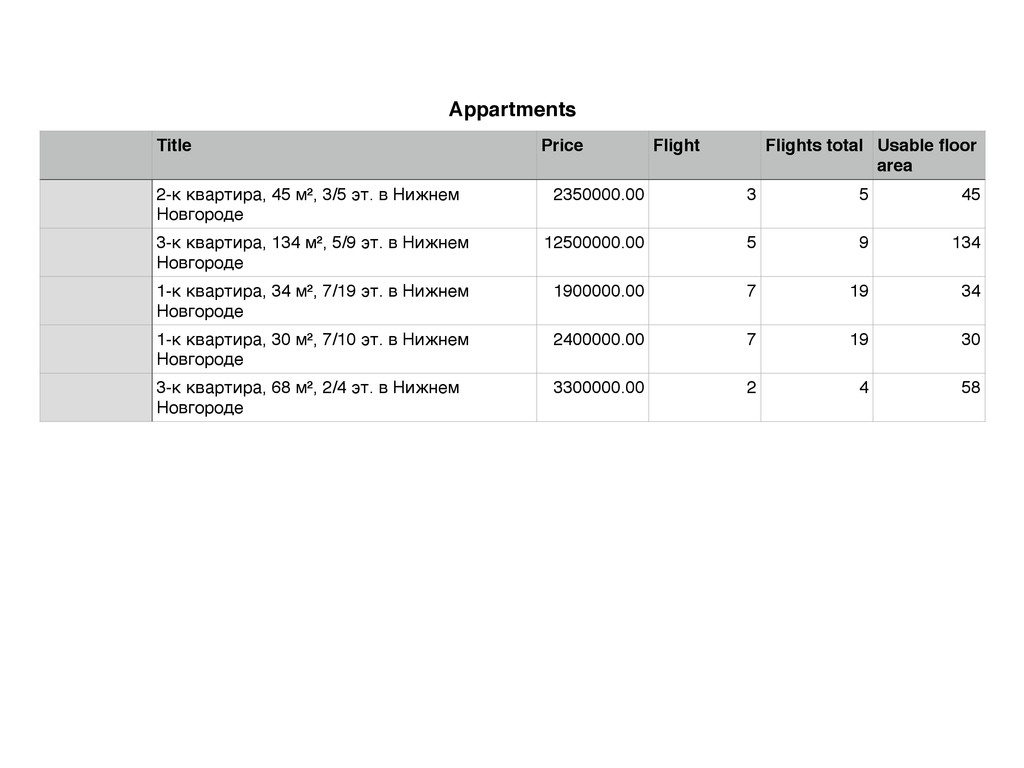
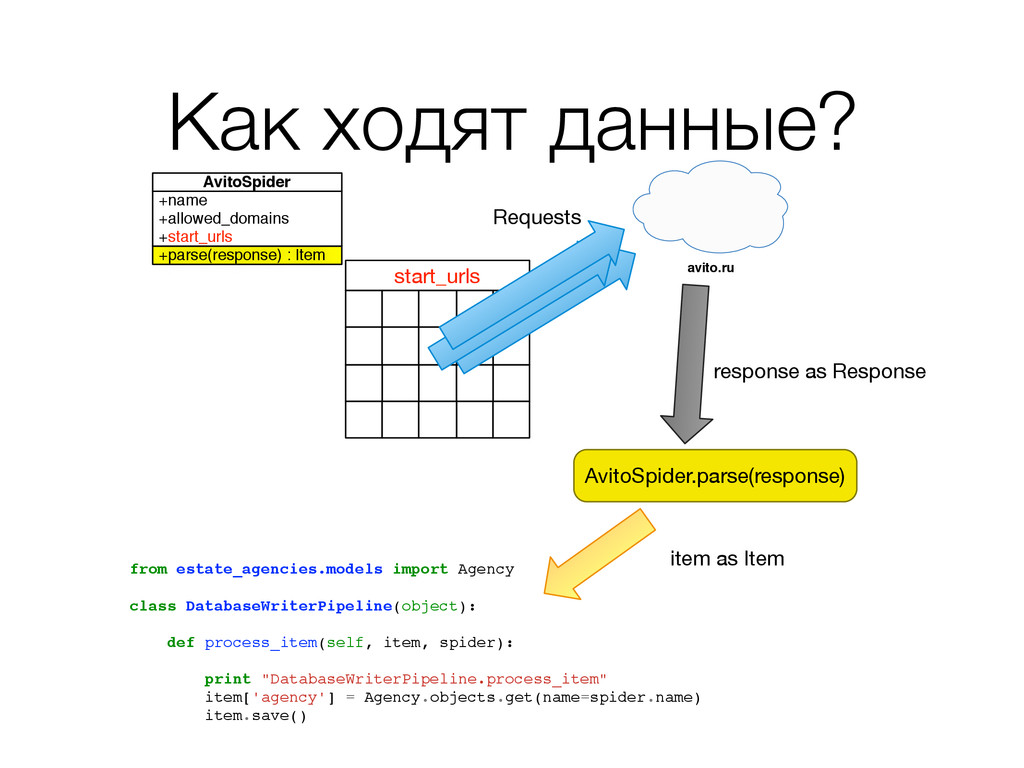
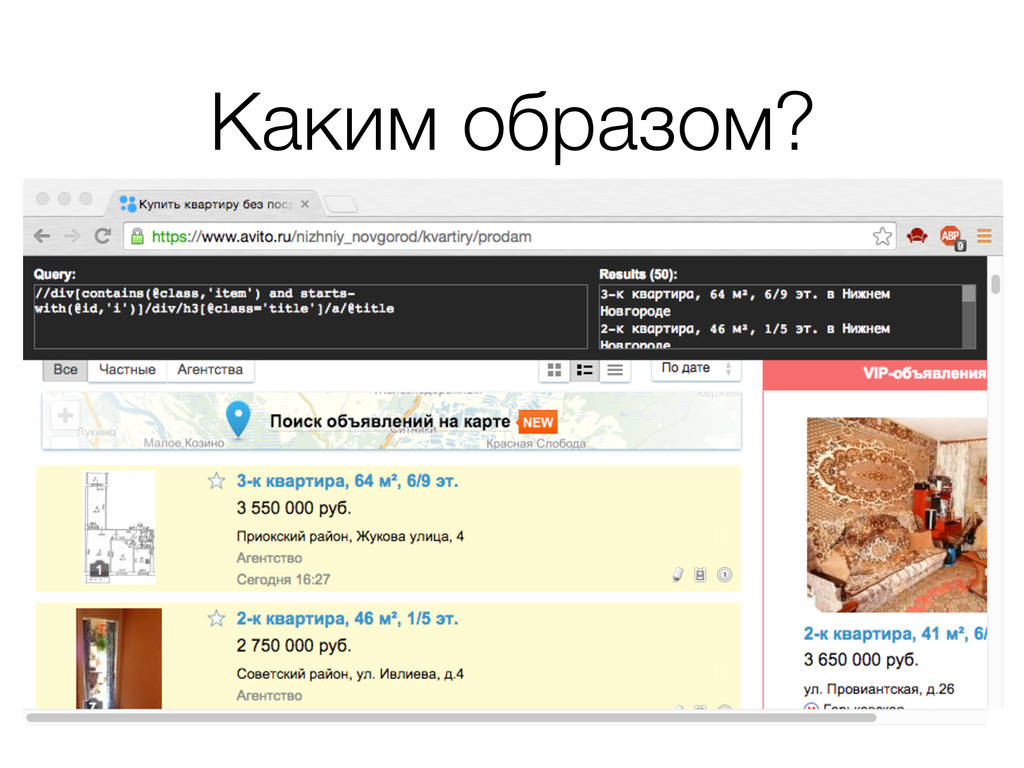
sel.xpath("//div[contains(@class,'item') and starts-with(@id,'i')]") for apartment in apartments: titles = apartment.xpath("./div/h3[@class='title']/a/@title").extract() deeplinks = apartment.xpath("./div/h3[@class='title']/a/@href").extract() prices = apartment.xpath("./div[3]/div[1]/text()").extract() publication_dates = apartment.xpath("./div[3]/div[2]/div/text()").extract() addresses = apartment.xpath("./div[@class='description']/p[@class='address fader']").extract() for title, deeplink, price, date_published, address in \ zip(titles, deeplinks, prices, publication_dates, addresses): item = ApartmentItem() item["title"] = title item["deeplink"] = ''.join(("http://www.avito.ru", deeplink)) ... yield item
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}